Command Palette
Search for a command to run...
نشر DeepSeek-R1-70B بنقرة واحدة
التاريخ
الحجم
890.53 MB
الوسوم
الترخيص
MIT
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

DeepSeek-R1-Distill-Llama-70B هو نموذج لغة مفتوح المصدر كبير الحجم، أصدرته DeepSeek في عام 2025، ويتميز بمقياس معاملات يبلغ 70 مليار. تم تدريبه على Llama3.3-70B-Instruct، ويستخدم تقنيات التعلم التعزيزي والتقطير لتحسين أداء الاستدلال. لا يقتصر هذا النموذج على اكتساب مزايا نماذج سلسلة Llama فحسب، بل يُحسّن أيضًا قدرات الاستدلال بشكل أكبر، ويتفوق بشكل خاص في المهام الرياضية والبرمجية والمنطقية. وبصفته إصدارًا عالي الأداء من سلسلة DeepSeek، فإنه يحقق أداءً استثنائيًا في اختبارات معيارية متعددة. علاوة على ذلك، يُعد هذا النموذج نموذجًا مُحسّنًا للاستدلال مُقدمًا من DeepSeek AI، ويدعم سيناريوهات تطبيقية متنوعة مثل الأجهزة المحمولة والحوسبة الطرفية وخدمات الاستدلال عبر الإنترنت، لتحسين سرعة الاستجابة وخفض تكاليف التشغيل. يمتلك قدرات استدلال واتخاذ قرارات قوية للغاية. في مجالات مثل مساعدي الذكاء الاصطناعي المتقدمين وتحليل البحث العلمي، يمكنه تقديم نتائج تحليلية احترافية ومتعمقة للغاية. على سبيل المثال، في مجال البحث الطبي، يمكن للإصدار 70B تحليل كميات كبيرة من البيانات الطبية، مما يوفر مراجع قيمة لأبحاث الأمراض.
本教程使用 Ollama + Open WebUI 部署 DeepSeek-R1-Distill-Qwen-70B 作为演示,算力资源采用「单卡 A6000」。
2. خطوات التشغيل
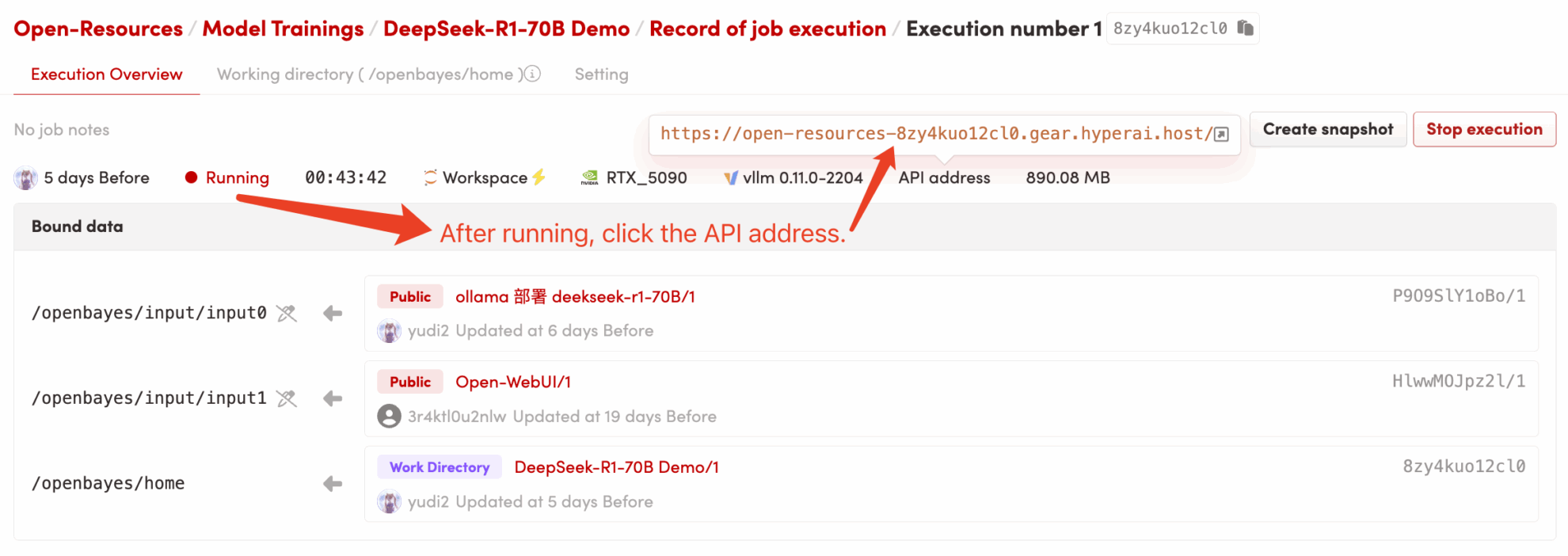
1. بعد بدء تشغيل الحاوية، انقر على عنوان API للدخول إلى واجهة الويب (إذا ظهرت رسالة "Bad Gateway"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لكبر حجم النموذج، يُرجى الانتظار حوالي 5 دقائق ثم المحاولة مرة أخرى). 2. بعد الدخول إلى صفحة الويب، يمكنك بدء محادثة مع النموذج!
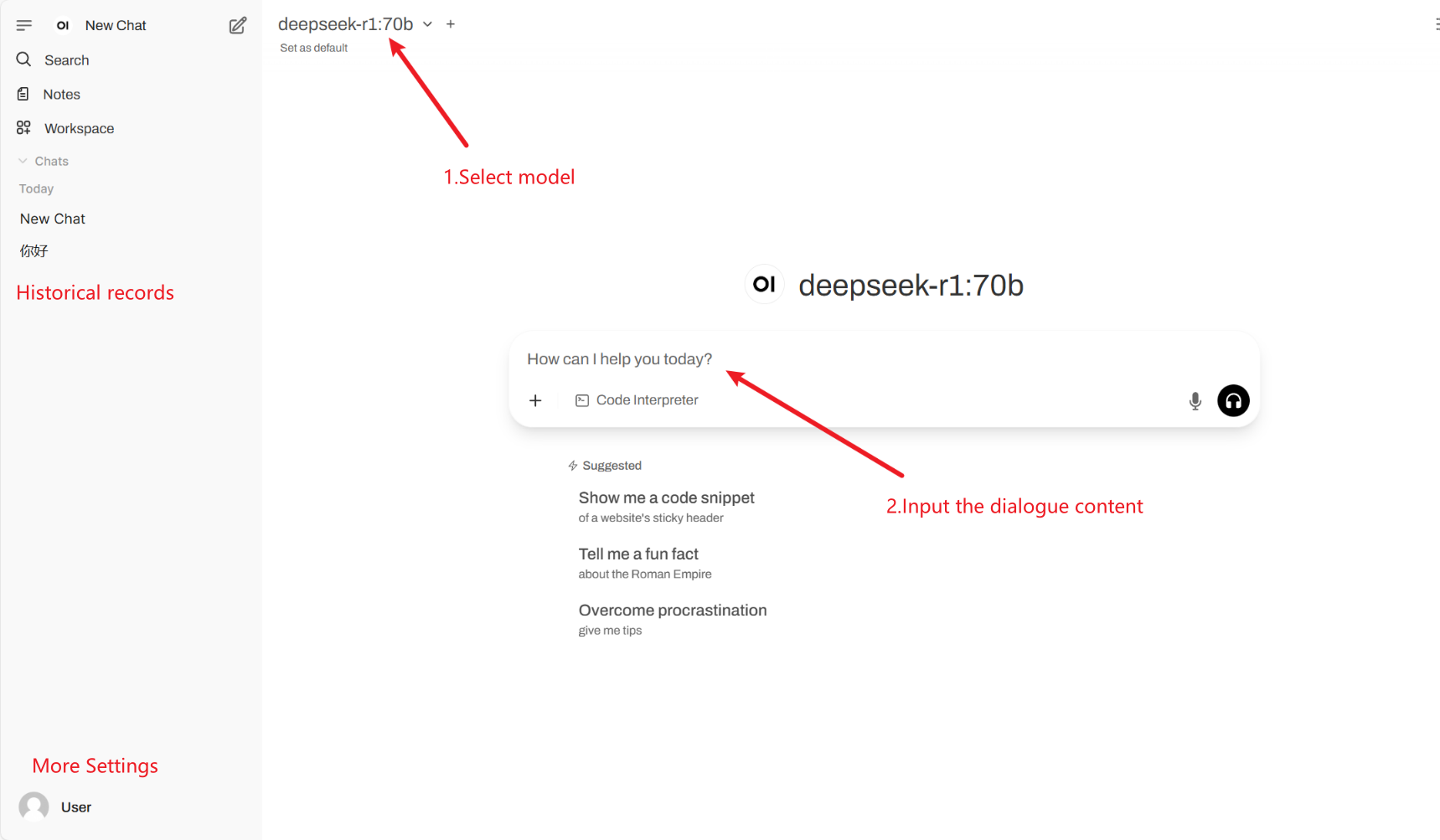
2. بعد الدخول إلى صفحة الويب، يمكنك بدء محادثة مع النموذج
إعدادات المحادثة الشائعة
1. درجة الحرارة
- يتحكم في عشوائية الإخراج، عادةً في النطاق من 0.0 إلى 2.0.
- قيمة منخفضة (مثل 0.1):أكثر يقينًا، متحيزًا نحو الكلمات الشائعة.
- قيمة عالية (مثل 1.5):محتوى أكثر عشوائية، وربما أكثر إبداعًا ولكنه غير منتظم.
2. أخذ العينات من أعلى إلى أسفل
- عينة فقط من الكلمات k ذات الاحتمالية الأعلى، باستثناء الكلمات ذات الاحتمالية المنخفضة.
- k صغير (على سبيل المثال 10):مزيد من اليقين، وأقل عشوائية.
- k كبير (على سبيل المثال 50):مزيد من التنوع، ومزيد من الابتكار.
3. أخذ العينات من أعلى p (أخذ العينات من النواة، أخذ العينات من أعلى p)
- قم باختيار مجموعة الكلمات التي يصل احتمالها التراكمي إلى p، ولا تقم بتثبيت قيمة k.
- قيمة منخفضة (مثل 0.3):مزيد من اليقين، وأقل عشوائية.
- قيمة عالية (مثل 0.9):مزيد من التنوع، وتحسين الطلاقة.
4. عقوبة التكرار
- يتحكم في معدل تكرار النص، عادةً ما يكون بين 1.0-2.0.
- قيمة عالية (مثل 1.5):تقليل التكرار وتحسين قابلية القراءة.
- قيمة منخفضة (مثل 1.0):لا توجد عقوبة، قد يتسبب ذلك في تكرار النموذج للكلمات والجمل.
5. الحد الأقصى للرموز (الحد الأقصى لطول الجيل)
- قم بتحديد الحد الأقصى لعدد الرموز التي يولدها النموذج لتجنب الإخراج الطويل للغاية.
- النطاق النموذجي: 50-4096 (اعتمادًا على الطراز المحدد).
يقتبس
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.