Command Palette
Search for a command to run...
دليل البدء في برنامج vLLM: دليل خطوة بخطوة للمبتدئين
التاريخ
الحجم
5.07 MB
الوسوم
الترخيص
Other
GitHub
رابط الورقة البحثية

جدول المحتويات
1. مقدمة البرنامج التعليمي
vLLM (نموذج اللغة الكبير الافتراضي) هو إطار عمل مصمم خصيصًا لتسريع عملية التفكير في نماذج اللغة الكبيرة. وقد حظيت باهتمام واسع النطاق في جميع أنحاء العالم بسبب كفاءتها الممتازة في التفكير وقدراتها على تحسين الموارد. في عام 2023، اقترح فريق بحثي من جامعة كاليفورنيا، بيركلي (UC Berkeley) خوارزمية انتباه رائدة، PagedAttention، والتي يمكنها إدارة مفاتيح وقيم الانتباه بشكل فعال. وعلى هذا الأساس، قام الباحثون ببناء محرك خدمة LLM عالي الإنتاجية vLLM، وحققوا هدرًا شبه معدوم لذاكرة التخزين المؤقت KV، وحلوا مشكلة عنق الزجاجة لإدارة الذاكرة في التفكير في نموذج اللغة الكبير. وبالمقارنة مع محولات Hugging Face Transformers، فإنها تحقق إنتاجية أعلى بمقدار 24 مرة، ولا يتطلب هذا التحسين في الأداء أي تغييرات في بنية النموذج. نتائج الورقة ذات الصلة هيإدارة الذاكرة الفعالة لخدمة نموذج اللغة الكبير باستخدام PagedAttention".
في هذا البرنامج التعليمي، سنوضح لك خطوة بخطوة كيفية تكوين وتشغيل vLLM، وتوفير دليل البدء الكامل من التثبيت إلى بدء التشغيل.
سوف يستخدم هذا البرنامج التعليمي Qwen3-0.6B وللتوضيح، يتم أيضًا توفير نماذج بكميات معلمات أخرى.
2. تثبيت vLLM
تم الانتهاء من هذه المنصة vllm==0.8.5 تثبيت. إذا كنت تعمل على منصة، يرجى تخطي هذه الخطوة. إذا كنت تقوم بالنشر محليًا، فاتبع الخطوات أدناه لتثبيته.
تثبيت vLLM بسيط للغاية:
pip install vllmلاحظ أن vLLM تم تجميعه باستخدام CUDA 12.4، لذا يتعين عليك التأكد من أن جهازك يعمل بهذا الإصدار من CUDA.
للتحقق من إصدار CUDA، قم بتشغيل:
nvcc --versionإذا لم يكن إصدار CUDA لديك هو 12.4، فيمكنك إما تثبيت إصدار من vLLM متوافق مع إصدار CUDA الحالي لديك (راجع تعليمات التثبيت لمزيد من المعلومات)، أو تثبيت CUDA 12.4.
3. ابدأ في الاستخدام
3.1 إعداد النموذج
الطريقة 1: استخدام نموذج المنصة العامة
أولاً، يمكننا التحقق مما إذا كان النموذج العام للمنصة موجودًا بالفعل. إذا تم تحميل النموذج إلى مستودع عام، فيمكنك استخدامه مباشرة. إذا لم يتم العثور عليه، يرجى الرجوع إلى الطريقة 2 للتنزيل.
على سبيل المثال، تم تخزين المنصة Qwen3 نموذج السلسلة. فيما يلي خطوات ربط النموذج (تم ربط هذا النموذج بالفعل في هذا البرنامج التعليمي).
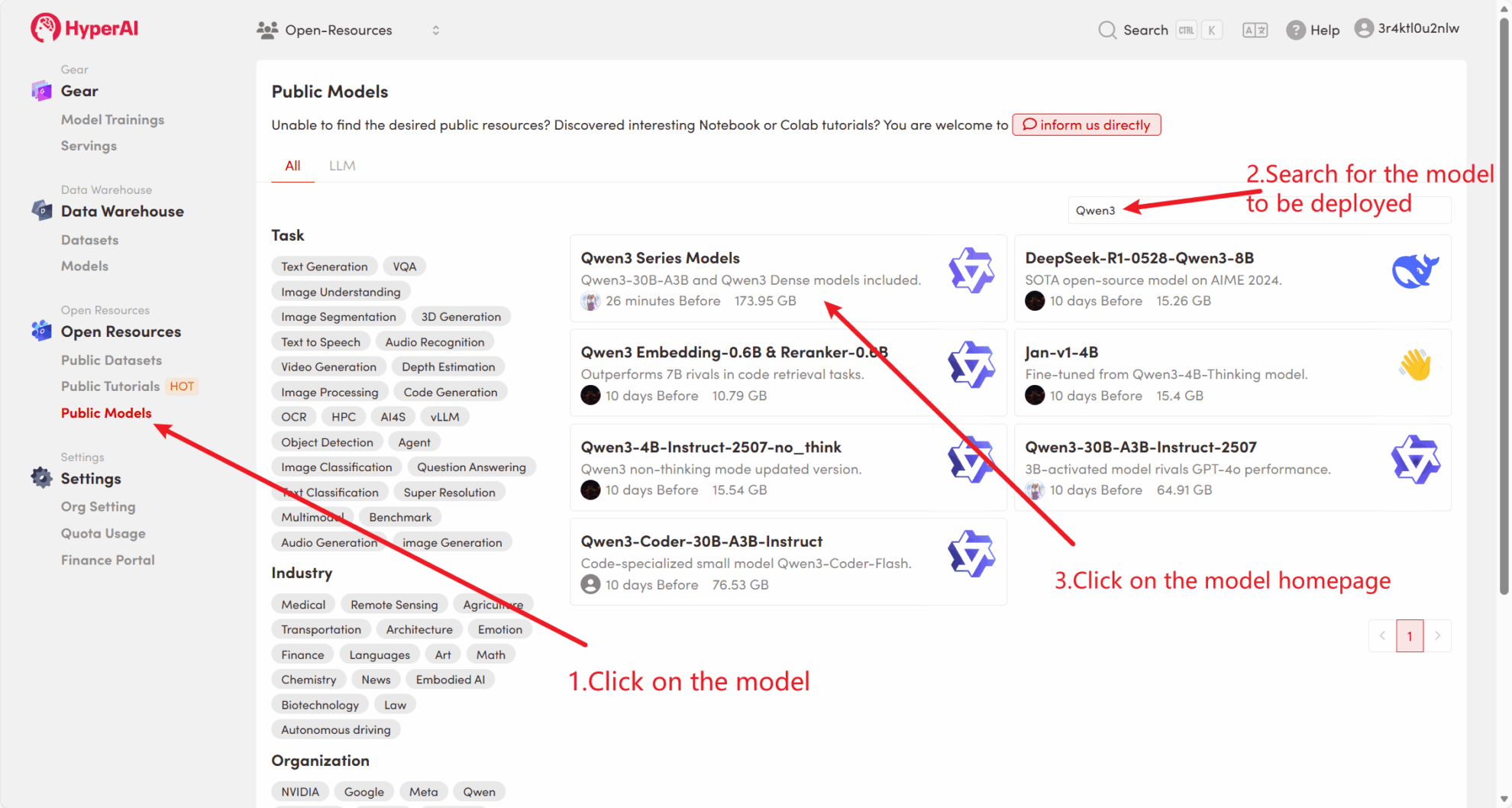
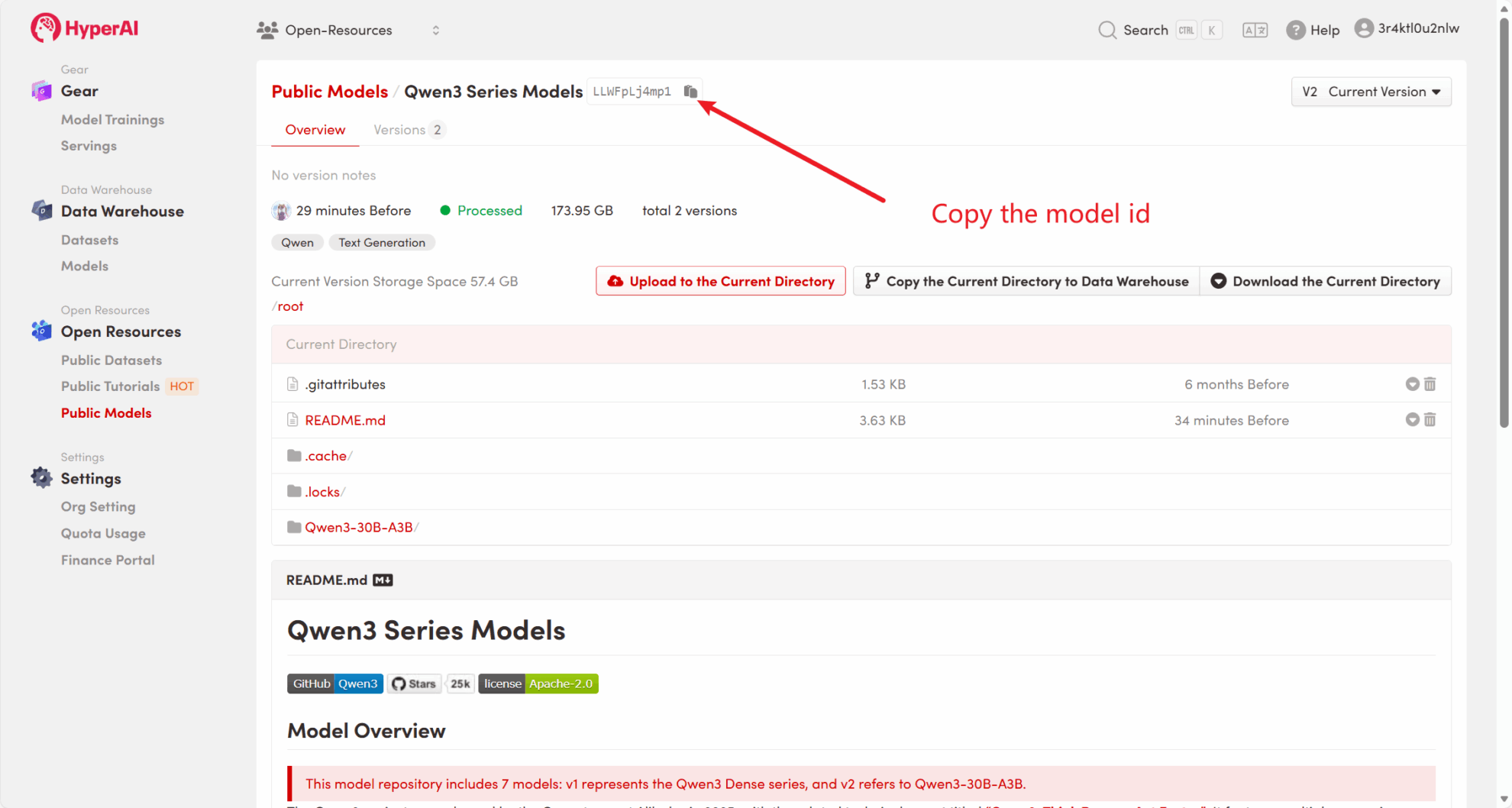
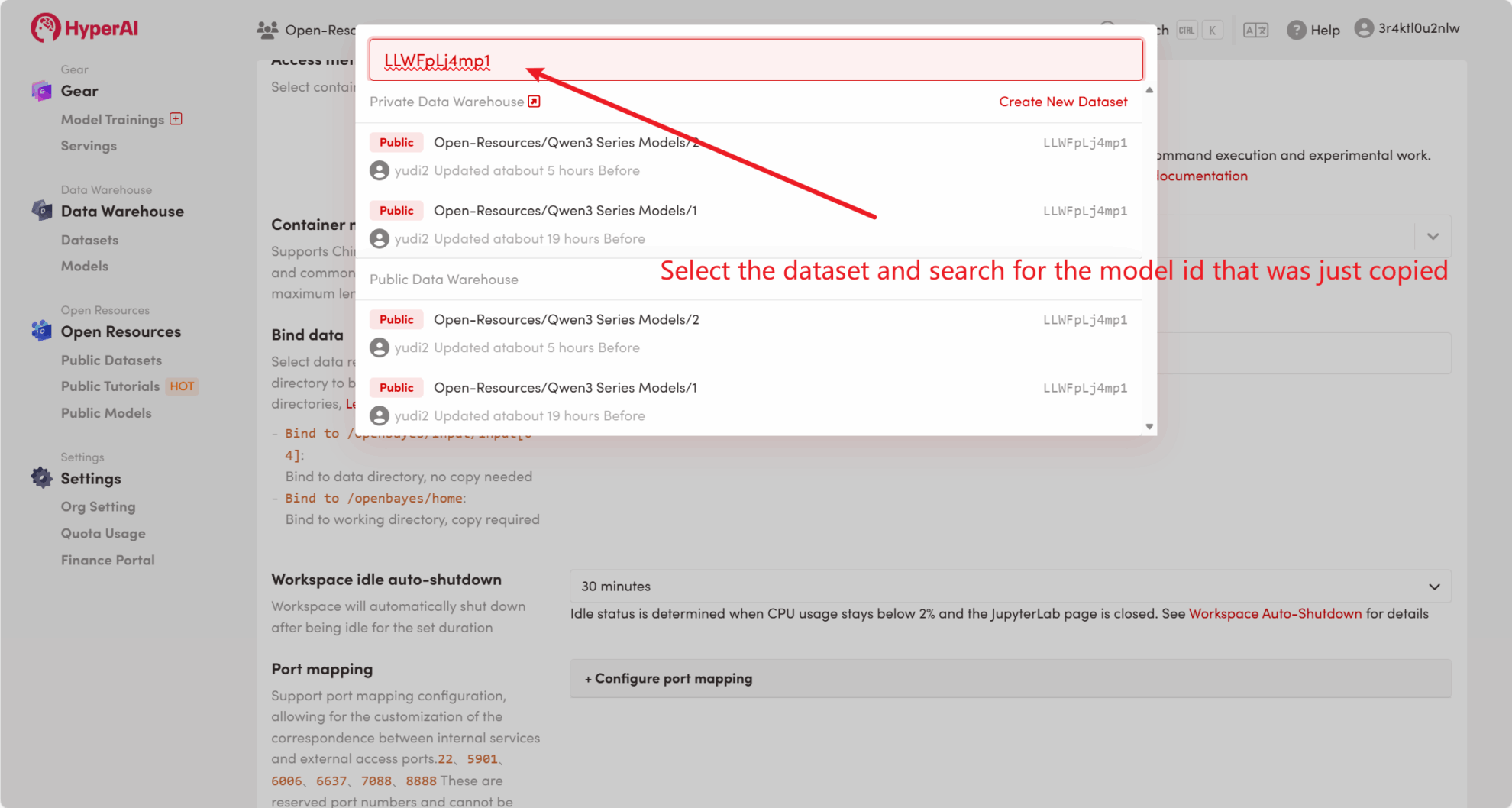
الطريقة 2: قم بالتنزيل من HuggingFace أو اتصل بخدمة العملاء للحصول على مساعدة في التحميل إلى المنصة.
يمكن العثور على معظم النماذج السائدة على HuggingFace. لمعرفة قائمة النماذج التي يدعمها vLLM، يرجى الرجوع إلى الوثائق الرسمية: نماذج مدعومة من vllm .
يرجى اتباع الخطوات أدناه لتنزيل النموذج باستخدام huggingface-cli:
huggingface-cli download --resume-download Qwen/Qwen3-0.6B --local-dir ./input03.2 الاستدلال غير المتصل بالإنترنت
باعتباره مشروعًا مفتوح المصدر، يمكن لـ vLLM إجراء استدلال LLM من خلال واجهة برمجة التطبيقات Python الخاصة به. وفيما يلي مثال بسيط. الرجاء حفظ الكود باسم offline_infer.py وثيقة:
from vllm import LLM, SamplingParams
# 输入几个问题
prompts = [
"مرحبا، من أنت؟؟"، "أين عاصمة فرنسا؟؟",]
# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 加载模型,确保路径正确
llm = LLM(model="/input1/Qwen3-0.6B/", trust_remote_code=True, max_model_len=4096)
# 展示输出结果
outputs = llm.generate(prompts, sampling_params)
# 打印输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
ثم قم بتشغيل البرنامج النصي:
python offline_infer.pyبمجرد تحميل النموذج، سوف ترى الناتج التالي:

4. ابدأ تشغيل خادم vLLM
لتوفير الخدمات عبر الإنترنت باستخدام vLLM، يمكنك تشغيل خادم متوافق مع واجهة برمجة التطبيقات OpenAI. بعد الإطلاق الناجح، يمكنك استخدام النموذج المنشور تمامًا كما تفعل مع GPT.
4.1 إعدادات المعلمات الرئيسية
فيما يلي بعض المعلمات الشائعة عند بدء تشغيل خادم vLLM:
--model: اسم نموذج HuggingFace أو المسار الذي سيتم استخدامه (افتراضي:facebook/opt-125m).--hostو--port:حدد عنوان الخادم والمنفذ.--dtype:نوع الدقة لأوزان النموذج والتنشيطات. القيم الممكنة:auto،half،float16،bfloat16،float،float32. القيمة الافتراضية:auto.--tokenizer:اسم أو مسار أداة HuggingFace المراد استخدامها. إذا لم يتم تحديد ذلك، فسيتم استخدام اسم النموذج أو المسار بشكل افتراضي.--max-num-seqs:الحد الأقصى لعدد التسلسلات لكل تكرار.--max-model-len:طول سياق النموذج. يتم الحصول على القيمة الافتراضية تلقائيًا من تكوين النموذج.--tensor-parallel-size،-tp:عدد النسخ المتوازية للموتر (بالنسبة لوحدة معالجة الرسومات). القيمة الافتراضية:1.--distributed-executor-backend=ray:يحدد الواجهة الخلفية للخدمة الموزعة. القيم الممكنة:ray،mp. القيمة الافتراضية:ray(عند استخدام أكثر من وحدة معالجة رسومية واحدة، يتم ضبطها تلقائيًا علىray).
4.2 بدء سطر الأوامر
إنشاء خادم متوافق مع واجهة OpenAI API. قم بتشغيل الأمر التالي لبدء تشغيل الخادم:
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-codeعند بدء التشغيل الناجح، ستشاهد إخراجًا مشابهًا لما يلي:

يمكن الآن نشر vLLM كخادم ينفذ بروتوكول OpenAI API، وسيكون متاحًا بشكل افتراضي في http://localhost:8080 بدء تشغيل الخادم. أنت تستطيع --host و --port تحدد المعلمة عنوانًا مختلفًا.
5. قدم طلبًا
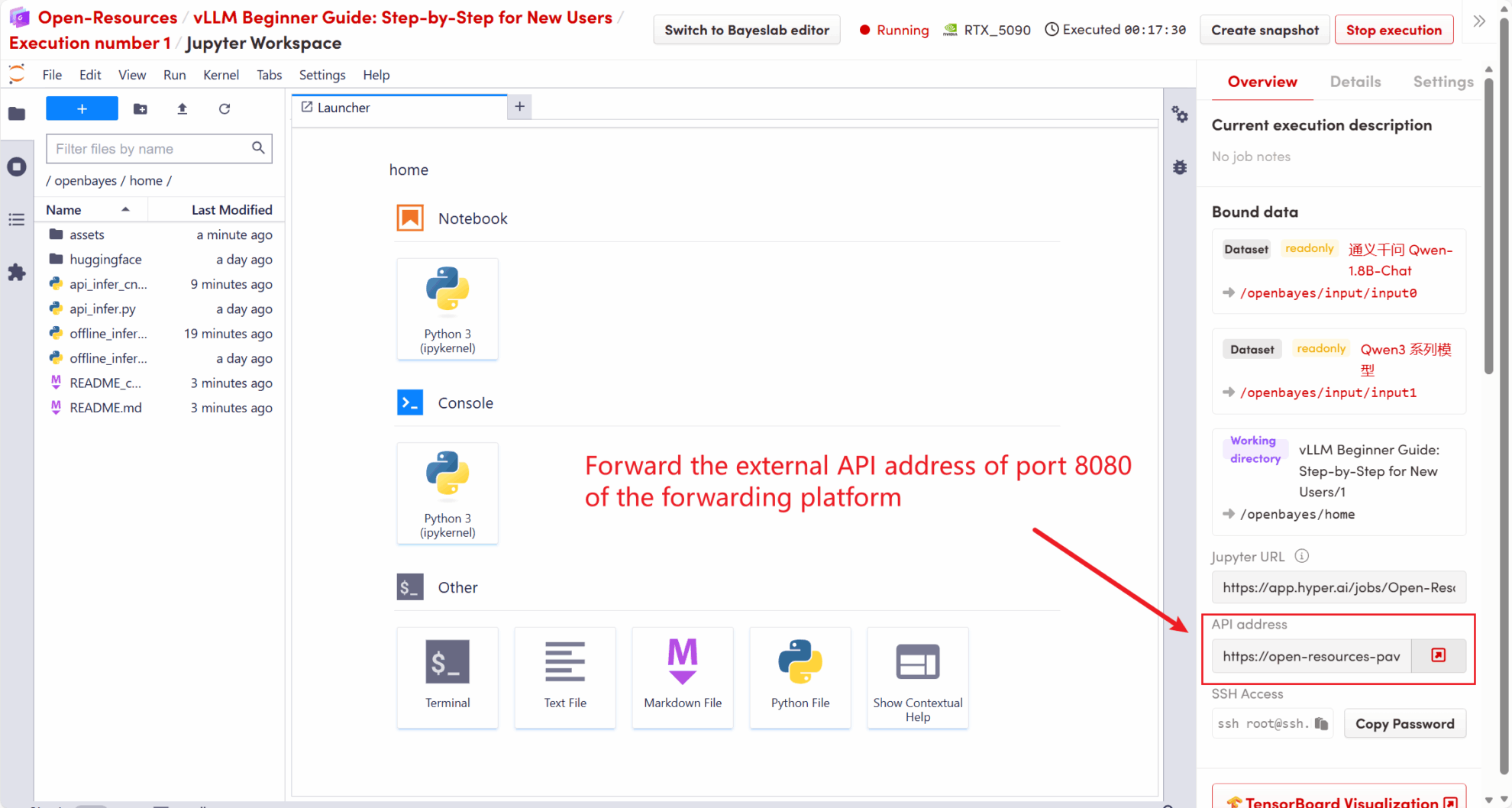
عنوان API الذي بدأ في هذا البرنامج التعليمي هو http://localhost:8080يمكنك استخدام واجهة برمجة التطبيقات (API) بزيارة هذا العنوان. localhost يشير إلى المنصة نفسها،8080 هو رقم المنفذ الذي تستمع إليه خدمة API.
على الجانب الأيمن من مساحة العمل، سيتم إعادة توجيه عنوان API إلى الخدمة المحلية 8080، ويمكن إجراء الطلبات من خلال المضيف الحقيقي، كما هو موضح في الشكل التالي:
5.1 استخدام عميل OpenAI
بعد بدء تشغيل خدمة vLLM في الخطوة 4، يمكنك استدعاء واجهة برمجة التطبيقات (API) من خلال عميل OpenAI. وهنا مثال بسيط:
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI
# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
models = client.models.list()
model = models.data[0].id
prompt = "Describe the autumn in Beijing"
# Completion API 调用
completion
= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")تنفيذ الأمر:
python api_infer.pyسوف ترى إخراجًا مشابهًا لما يلي:

5.2 استخدام طلب أمر Curl
يمكنك أيضًا إرسال الطلب مباشرةً باستخدام الأمر التالي. عند الدخول إلى المنصة، أدخل الأمر التالي:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 512
}'سوف تحصل على الرد مثل هذا:

إذا كنت تستخدم منصة OpenBayes، فأدخل الأمر التالي:
curl https://hyperai-tutorials-8tozg9y9ref9.gear-c1.openbayes.net/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 128
}'وكانت نتيجة الاستجابة على النحو التالي:

بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.