Command Palette
Search for a command to run...
GLM-4-Voice نموذج محادثة شاملة باللغتين الصينية والإنجليزية
التاريخ
الحجم
1.91 GB
1. مقدمة البرنامج التعليمي
GLM-4-Voice هو نموذج صوتي متكامل أطلقته شركة Zhipu AI في عام 2024. يمكن لـ GLM-4-Voice فهم وتوليد الكلام الصيني والإنجليزي بشكل مباشر، وإجراء محادثات صوتية في الوقت الفعلي، ويمكنه اتباع تعليمات المستخدم لتغيير عاطفة الكلام ونبرته وسرعة التحدث واللهجة وغيرها من السمات.
يحتوي هذا العرض التوضيحي التعليمي على تنفيذين وظيفيين للنموذج: "المحادثة الصوتية" و"المحادثة النصية".
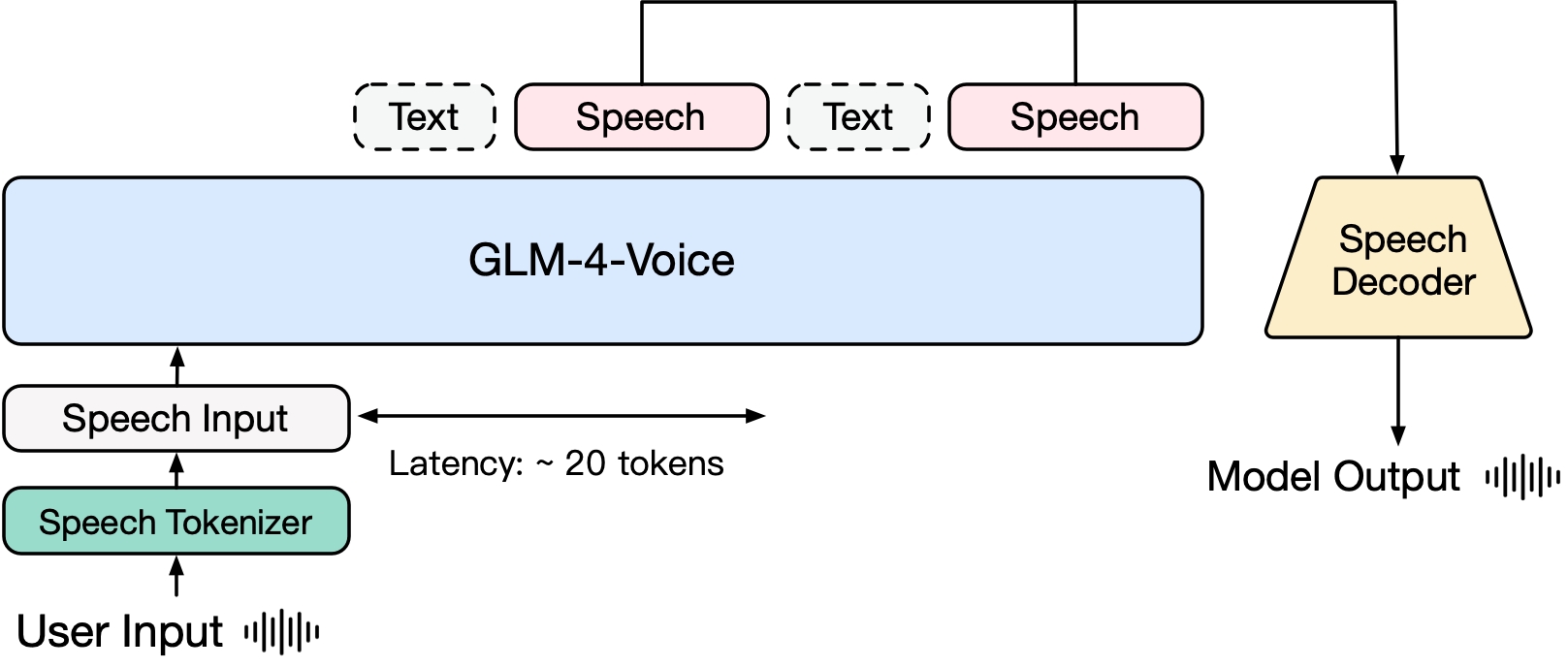
يتكون GLM-4-Voice من ثلاثة أجزاء:
- GLM-4-Voice-Tokenizer: يحول إدخال الكلام المستمر إلى رموز منفصلة عن طريق إضافة كمية المتجهات إلى جزء Encoder من Whisper والتدريب المشرف على بيانات ASR. في المتوسط، هناك حاجة إلى 12.5 رمزًا منفصلًا فقط لتمثيل كل ثانية من الصوت.
- GLM-4-Voice-Decoder: جهاز فك تشفير صوتي يدعم التفكير المتدفق ويتم تدريبه على أساس بنية نموذج مطابقة التدفق في CosyVoice، وتحويل رموز الصوت المنفصلة إلى إخراج صوتي مستمر. كل ما تحتاجه هو 10 رموز صوتية فقط لبدء التوليد، مما يقلل من زمن انتقال المحادثة من البداية إلى النهاية.
- GLM-4-Voice-9B: يقوم بتدريب ومواءمة نمط الكلام بناءً على GLM-4-9B، حتى يتمكن من فهم وتوليد رموز الكلام المنفصلة.
من حيث التدريب المسبق، من أجل التغلب على صعوبتي ذكاء النموذج والتعبير الاصطناعي في نمط الصوت، قام فريق البحث بفصل مهمة Speech2Speech إلى مهمتين: "إنشاء ردود نصية بناءً على صوت المستخدم" و"توليف كلام الرد بناءً على ردود النص وصوت المستخدم"، وصمم هدفين للتدريب المسبق، توليف بيانات متداخلة بين الكلام والنص بناءً على بيانات التدريب المسبق للنص وبيانات الصوت غير الخاضعة للإشراف للتكيف مع هذين النموذجين من المهام. يعتمد GLM-4-Voice-9B على النموذج الأساسي لـ GLM-4-9B. لقد تم تدريبه مسبقًا بملايين الساعات من الصوت ومئات المليارات من رموز البيانات المتداخلة بين الصوت والنص، كما يتمتع بقدرات قوية على فهم الصوت والنمذجة.
من حيث المحاذاة، من أجل دعم المحادثات الصوتية عالية الجودة، صمم فريق البحث بنية تفكير متدفقة: بناءً على صوت المستخدم، يمكن لـ GLM-4-Voice بث وإخراج محتوى كل من أوضاع النص والصوت بالتناوب. يستخدم وضع الصوت النص كمرجع لضمان الجودة العالية لمحتوى الرد، ويقوم بإجراء تغييرات صوتية مقابلة وفقًا لمتطلبات أوامر صوت المستخدم. لا يزال لديه القدرة على النمذجة الشاملة مع الاحتفاظ بذكاء نموذج اللغة إلى أقصى حد، ولديه زمن انتقال منخفض. كل ما يحتاجه الأمر هو إخراج 20 رمزًا على الأقل لتوليف الكلام.
2. خطوات التشغيل
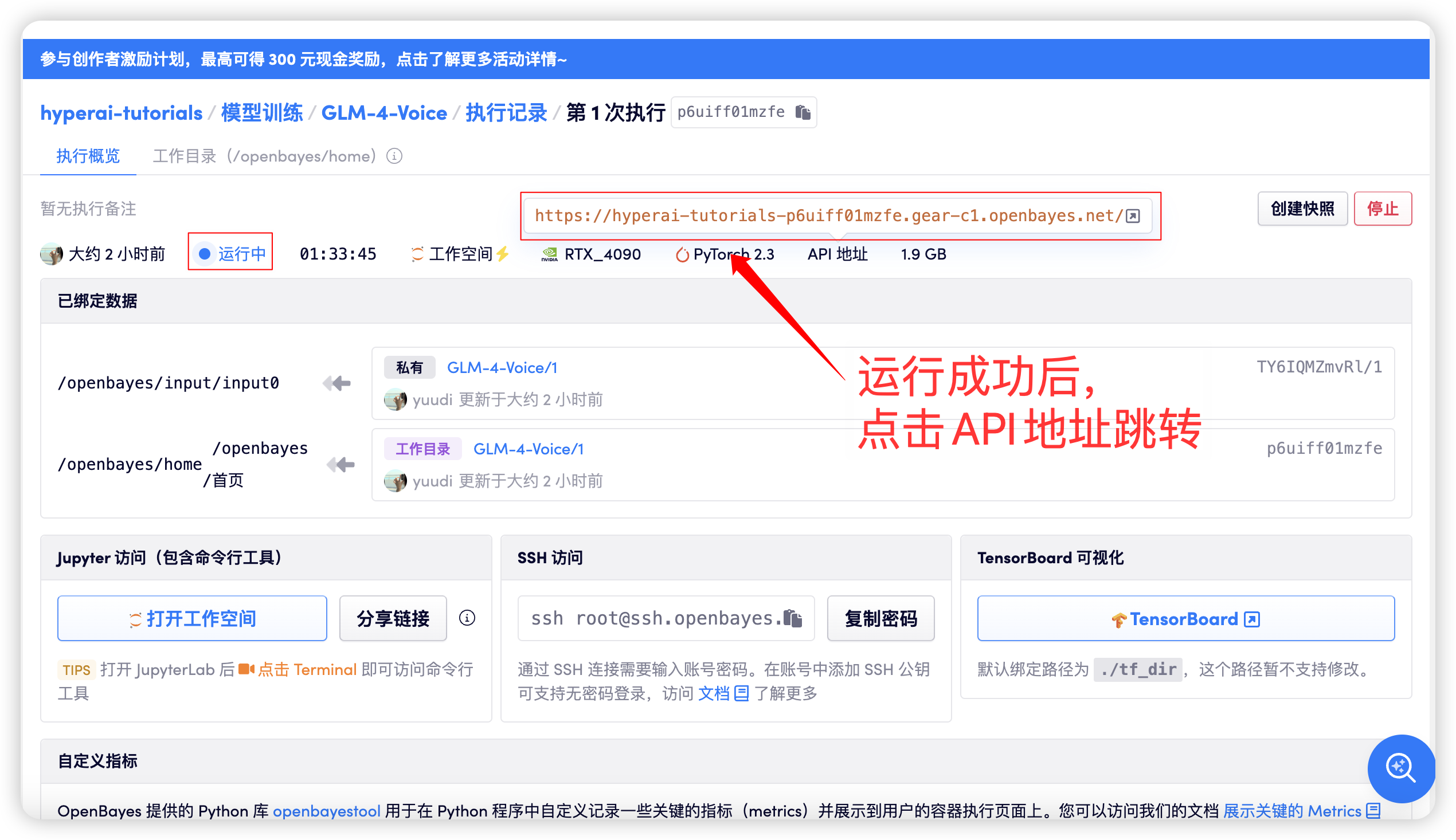
بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
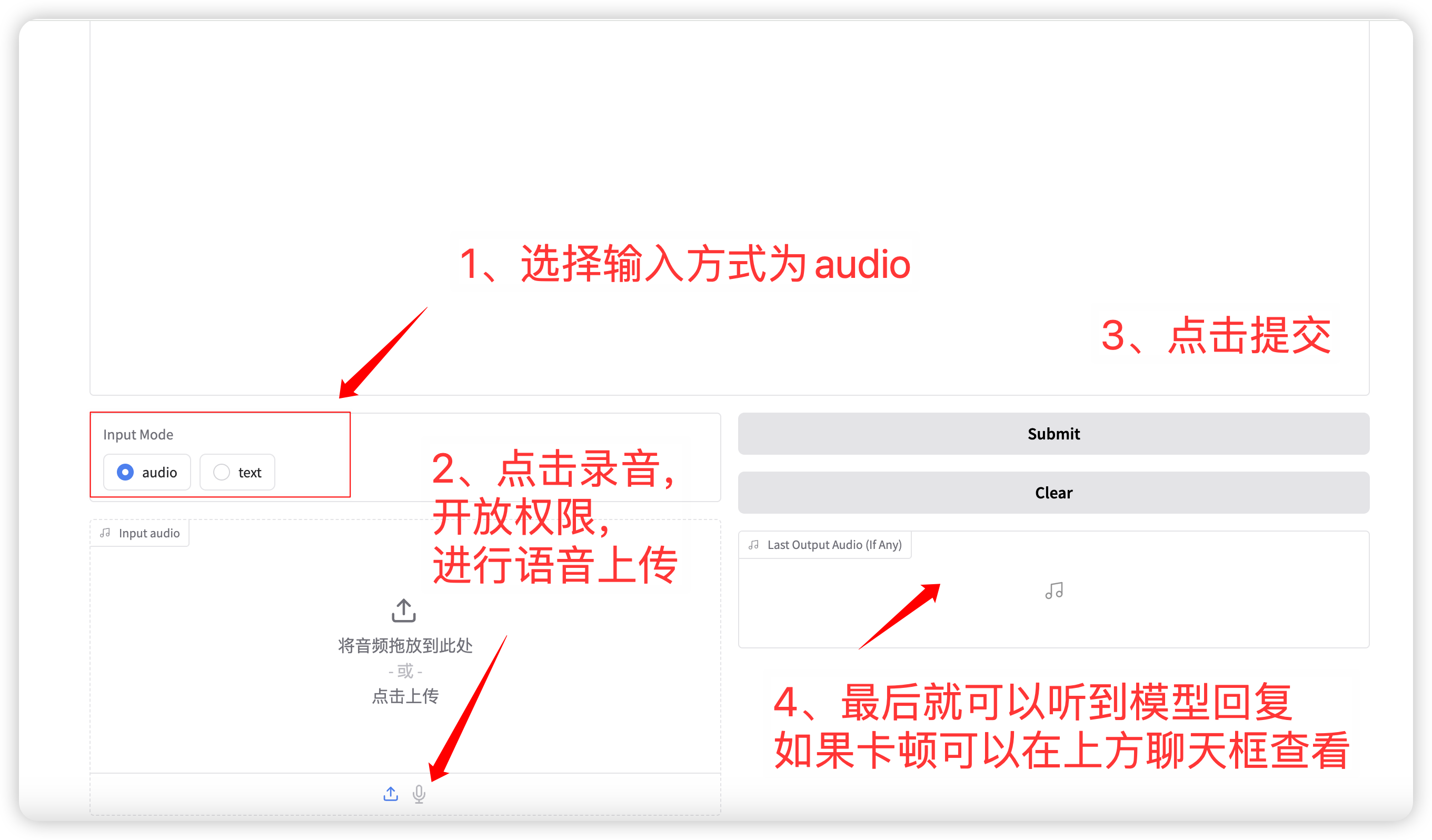
1. الحوار الصوتي
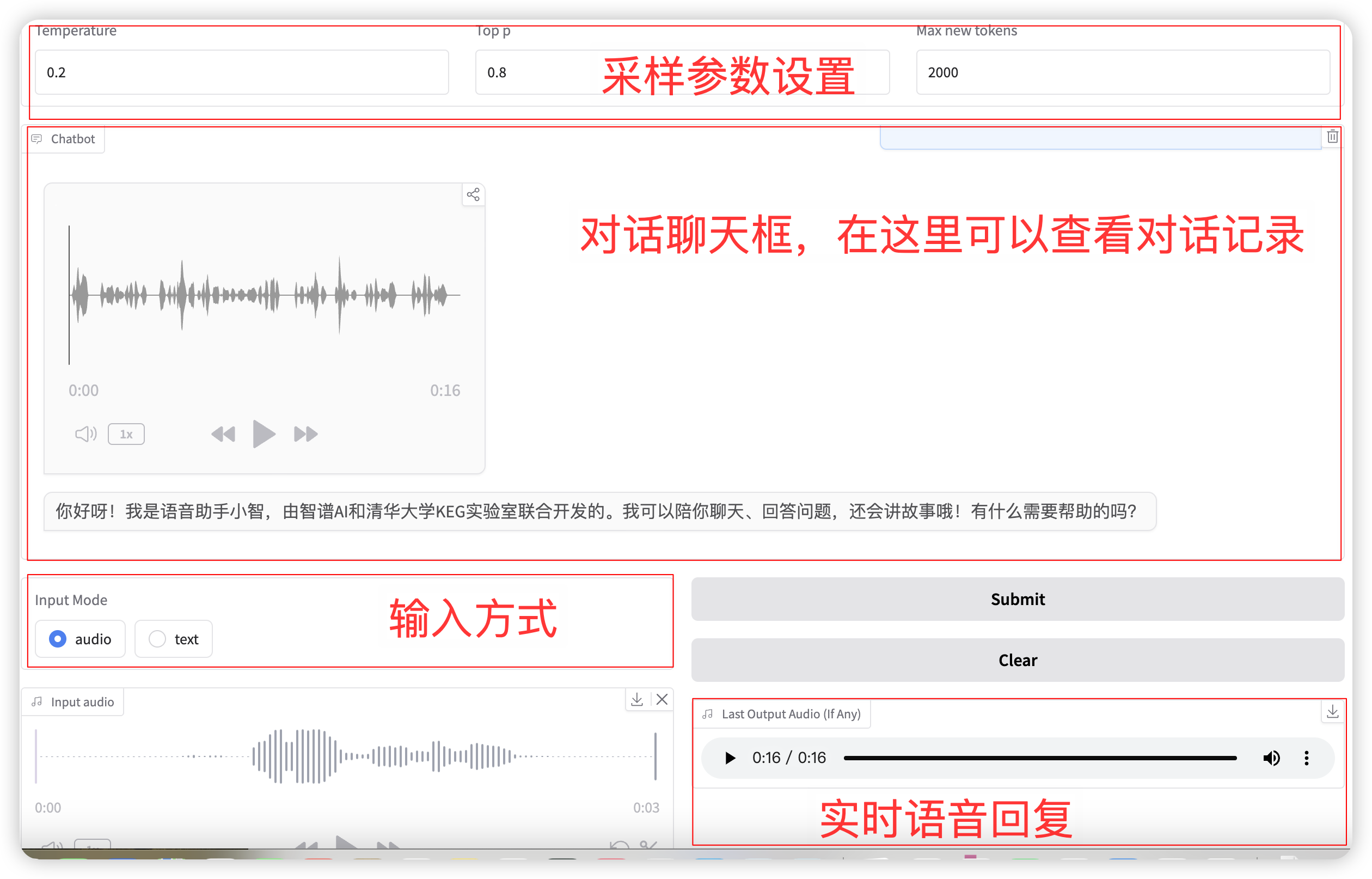
اختيار وضع الإدخال صوتي الوظيفة، انقر لتسجيل أو تحميل ملف صوتي. معلمات أخذ العينات ذات الصلة هي:
- درجة الحرارة: النطاق 0-1، كلما ارتفعت درجة الحرارة، كلما زادت عشوائية الجيل!
- أعلى p: يستخدم لتحديد أنه سيتم أخذ خيارات أعلى p فقط ذات الاحتمالية الأعلى في الاعتبار عند تحديد الكلمة التالية أثناء عملية التوليد. يساعد هذا في الحفاظ على التنوع عند إنشاء النص ويتجنب دائمًا تحديد نتائج التنبؤ ذات الاحتمالية الأعلى، مما يجعل النص الناتج أكثر ثراءً وتنوعًا.
- الحد الأقصى للرموز الجديدة: الحد الأقصى لعدد الرموز التي تم إنشاؤها.
بعد الانتهاء من الإعداد، سيقوم النموذج بإخراج الصوت والنص في الوقت الفعلي، ولكن قد يكون ذلك متقطعًا بسبب زمن الوصول إلى الشبكة. يمكنك الاستماع إلى الصوت في مربع الدردشة. التخطيط العام للصفحة هو كما يلي:
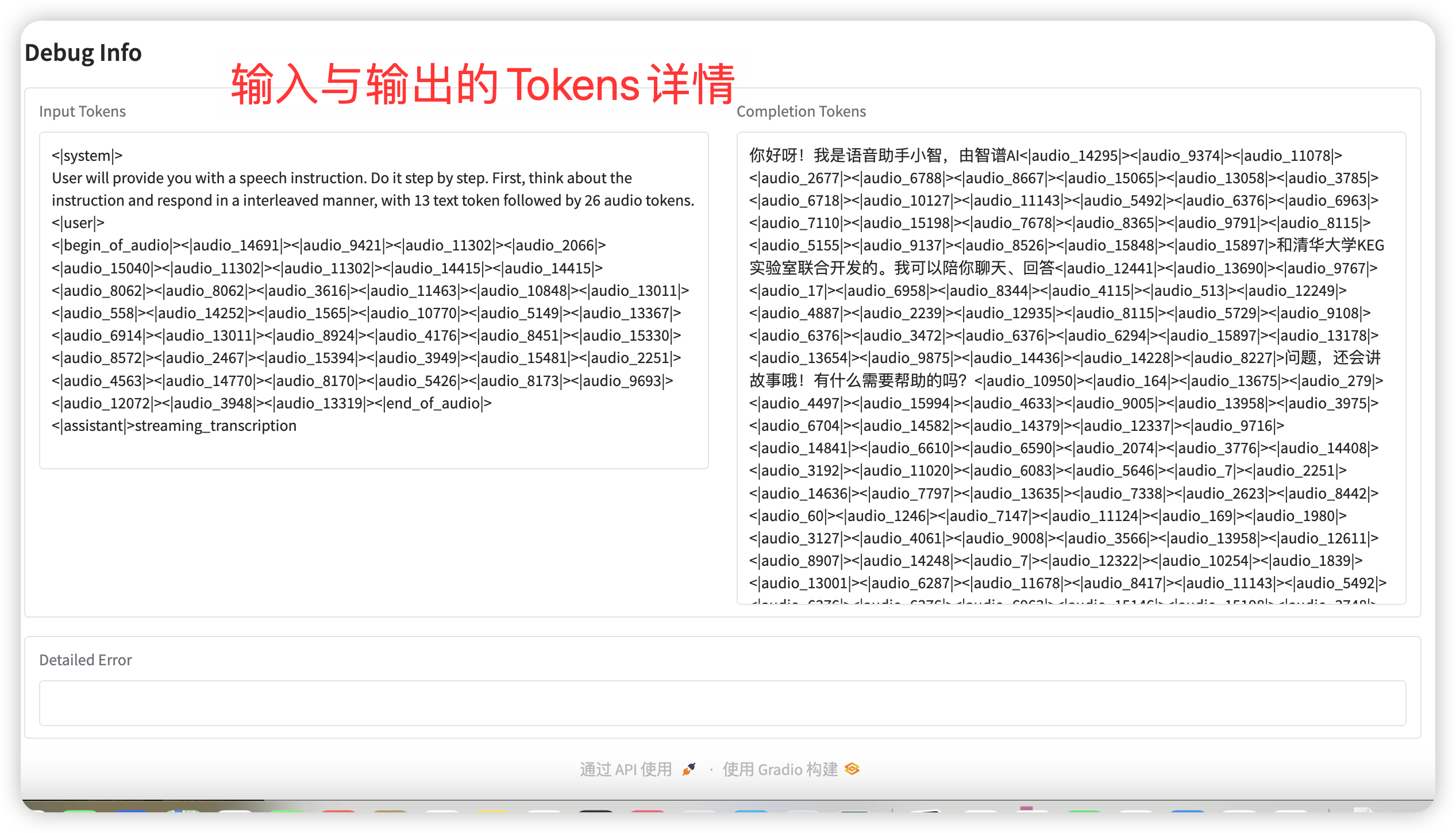
语音对话流程
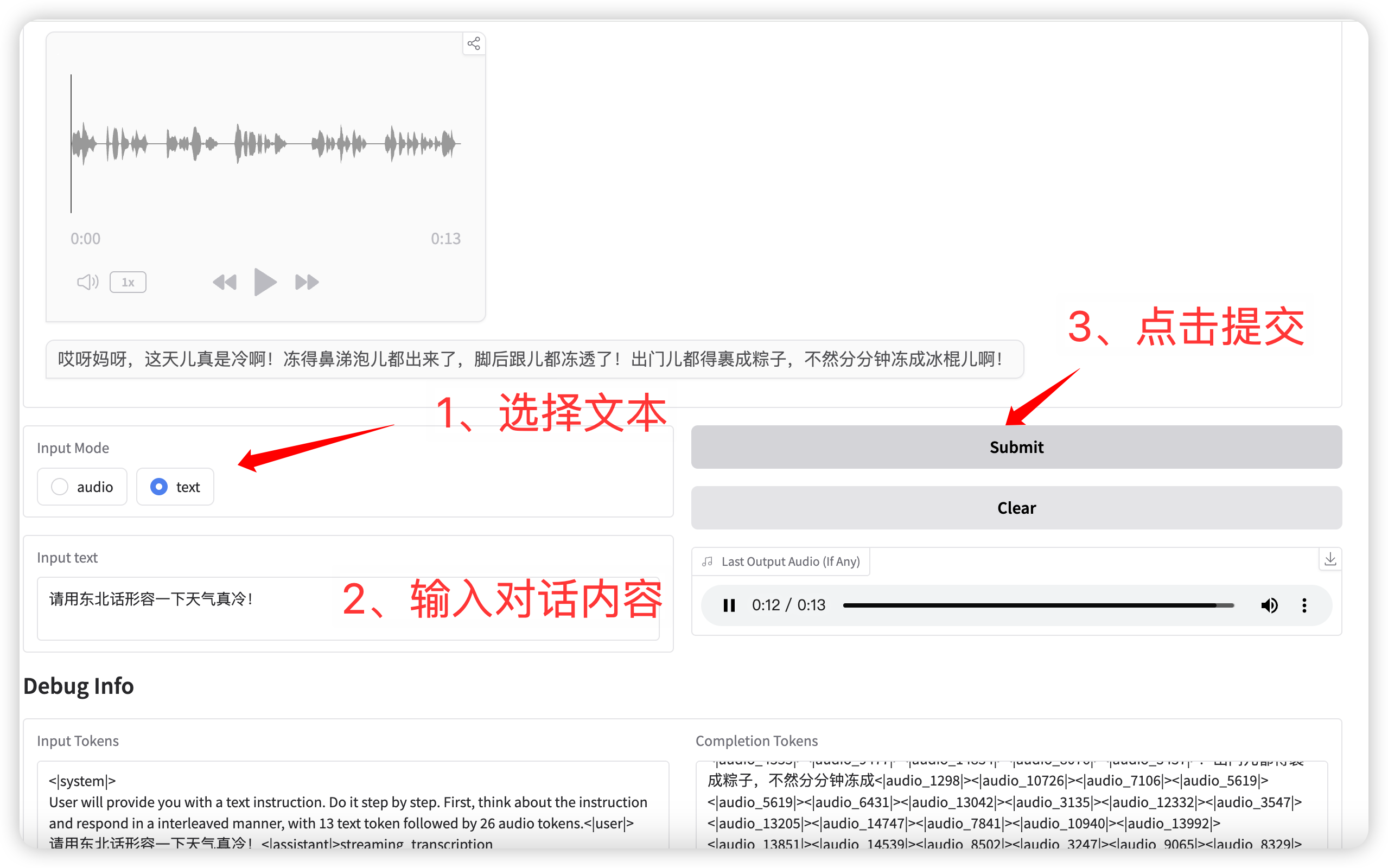
2. محادثة نصية
输入模式选择 **text** 功能,输入对话文本。
点击提交后,模型同时输出文本和语音。
语音对话(输入为文本)
التبادل والمناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.