Command Palette
Search for a command to run...
يقوم برنامج F5-E2 TTS باستنساخ أي صوت في 3 ثوانٍ فقط
التاريخ
الوسوم
رابط الورقة البحثية
الترخيص
CC BY-NC-SA 3.0
GitHub
1. مقدمة البرنامج التعليمي

يتضمن هذا البرنامج التعليمي نموذجين للاستخدام التجريبي، وهما F5-TTS وE2 TTS.
F5-TTS هو نظام عالي الأداء لتحويل النص إلى كلام (TTS)، تم طرحه كمصدر مفتوح في عام 2024 بالتعاون بين جامعة شنغهاي جياو تونغ، وجامعة كامبريدج، ومعهد جيلي لأبحاث السيارات (نينغبو). يعتمد النظام على طريقة توليد غير تراجعية باستخدام مطابقة التدفق، بالإضافة إلى تقنية محول الانتشار (DiT). تتوفر أوراق بحثية ذات صلة. F5-TTS: حكايتي الخيالية التي تتظاهر بالكلام السلس والصادق باستخدام مطابقة التدفق يستطيع هذا النظام توليد كلام طبيعي وسلس ودقيق من النص الأصلي بسرعة فائقة من خلال التعلم الصفري دون إشراف إضافي. يدعم نظام F5-TTS توليف الكلام متعدد اللغات، بما في ذلك الصينية والإنجليزية، ويُمكنه توليف الكلام بكفاءة عالية حتى مع النصوص الطويلة. علاوة على ذلك، يتميز F5-TTS بالتحكم في المشاعر، حيث يُعدّل التعبير العاطفي للكلام المُولَّف بناءً على محتوى النص، كما يدعم التحكم في السرعة، مما يسمح للمستخدمين بتعديل سرعة التشغيل حسب الحاجة. تم تدريب النظام على مجموعة بيانات ضخمة تضم 100,000 ساعة، مما أظهر أداءً ممتازًا وقدرة عالية على التعميم. تشمل الوظائف الرئيسية لنظام F5-TTS استنساخ الصوت الصفري، والتحكم في السرعة، والتحكم في المشاعر، وتوليف النصوص الطويلة، ودعم لغات متعددة. أما مبادئه التقنية فتتضمن مطابقة التدفق، ومحول الانتشار (DiT)، وتحسين تمثيل النص باستخدام ConvNeXt V2، واستراتيجية أخذ العينات Sway، وتصميم النظام المتكامل. يتمتع برنامج F5-TTS بمجموعة واسعة من التطبيقات، بما في ذلك الكتب الصوتية، والمساعدين الصوتيين، وتعلم اللغات، وبث الأخبار، ودبلجة الألعاب، مما يوفر إمكانيات قوية لتوليف الكلام لمختلف الاستخدامات التجارية وغير التجارية.
نظام E2 TTS، اختصارًا لـ "Embarrassingly Easy Text-to-Speech" (تحويل النص إلى كلام بسهولة مُحرجة)، هو نظام متطور لتحويل النص إلى كلام (TTS) يحقق مستوى طبيعيًا يُضاهي البشر في سهولة الكلام وتشابهًا مع المتحدثين من خلال عملية مُبسطة. يكمن جوهر نظام E2 TTS في طبيعته غير التراجعية تمامًا، مما يعني قدرته على توليد تسلسل الكلام بالكامل دفعة واحدة، دون الحاجة إلى توليد تدريجي، وبالتالي تحسين سرعة التوليد بشكل ملحوظ مع الحفاظ على جودة عالية لمخرجات الكلام. تتضمن الأبحاث ذات الصلة... E2 TTS: TTS سهل بشكل محرج وغير تلقائي بالكامل وغير قابل للتراجعيقوم نظام E2 TTS، الذي قُبل في مؤتمر SLT 2024، بتحويل النص المدخل إلى سلسلة من الأحرف مع علامات حشو. ثم يتم تدريب مولد طيف ميل، قائم على مطابقة التدفقات الصوتية، على مهمة حشو الصوت. وعلى عكس العديد من الأعمال السابقة، لا يتطلب هذا النظام أي مكونات إضافية (مثل نماذج المدة، أو تحويل الأحرف إلى أصوات) أو تقنيات معقدة (مثل البحث عن المحاذاة الرتيبة). ورغم بساطته، يحقق E2 TTS أداءً متطورًا في مجال تحويل النص إلى كلام بدون تدريب مسبق، يضاهي أو يتفوق على الأعمال السابقة، بما في ذلك Voicebox وNaturalSpeech 3. كما تتيح بساطة E2 TTS مرونة في تمثيل المدخلات.
该教程支持如下模型和功能: 2 个模型检查点: F5-TTS E2 TTS 3 个功能:单人语音生成(Batched TTS): 根据上传的音频进行文本生成。 双人语音生成(Podcast Generation):根据双人音频模拟双人对话。多种语音类型生成(Multiple Speech-Type Generation):可根据同一讲话人不同情绪下的音频,生成不同情绪的音频。
يستخدم هذا البرنامج التعليمي بطاقة RTX 5090 واحدة كمورد.
2. أمثلة المشاريع
1. تحويل النص إلى كلام مجمع
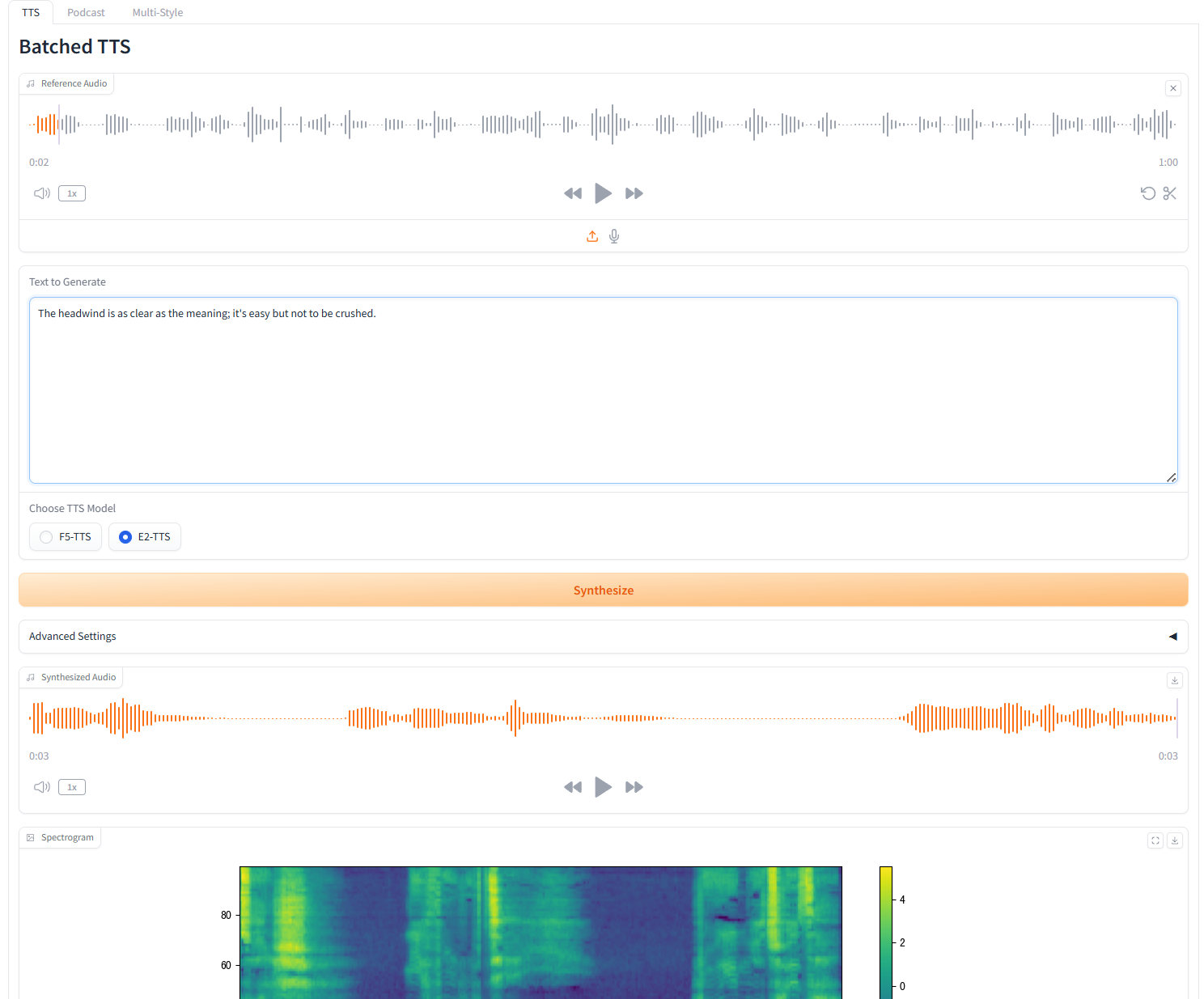
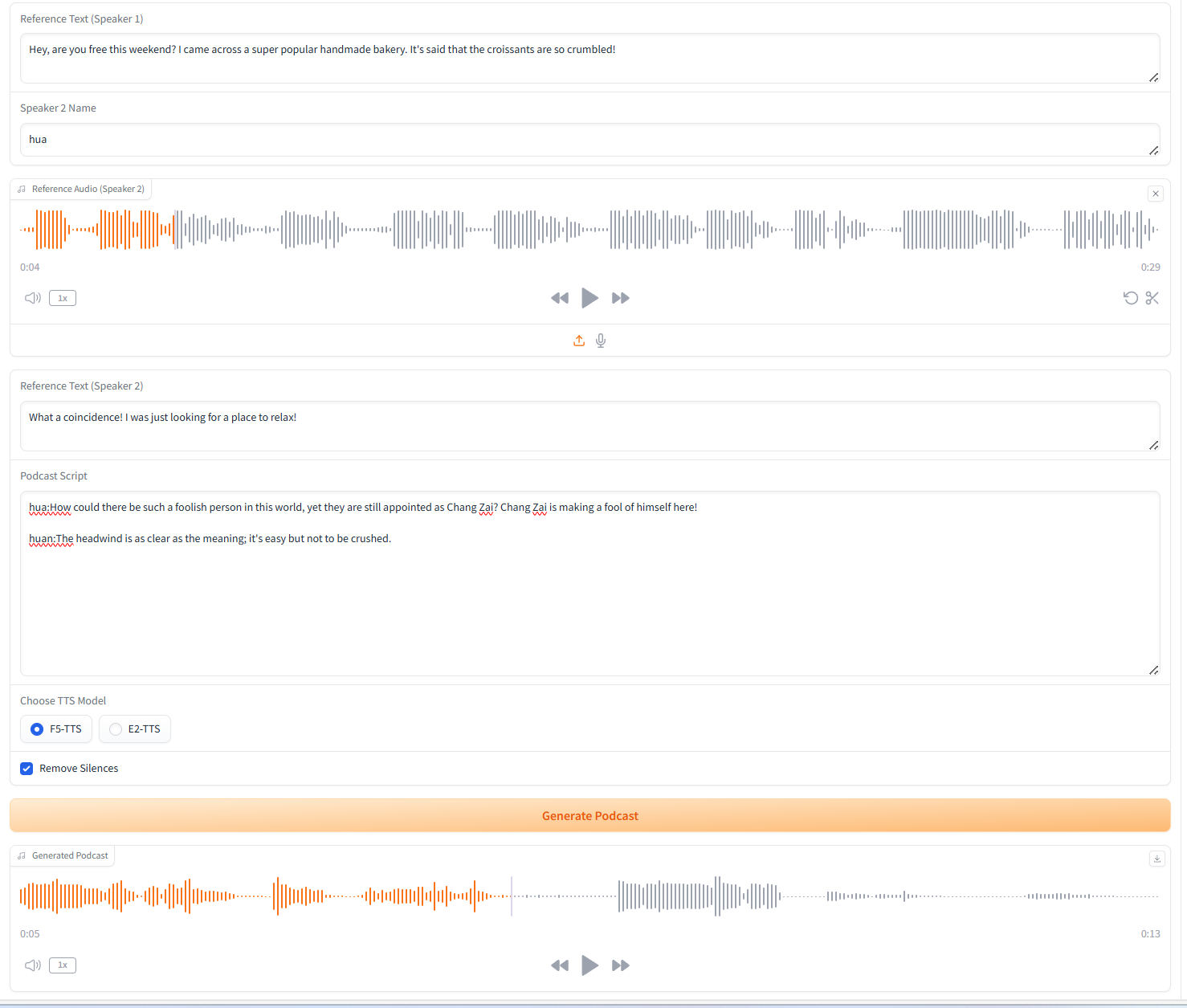
2. إنشاء البودكاست
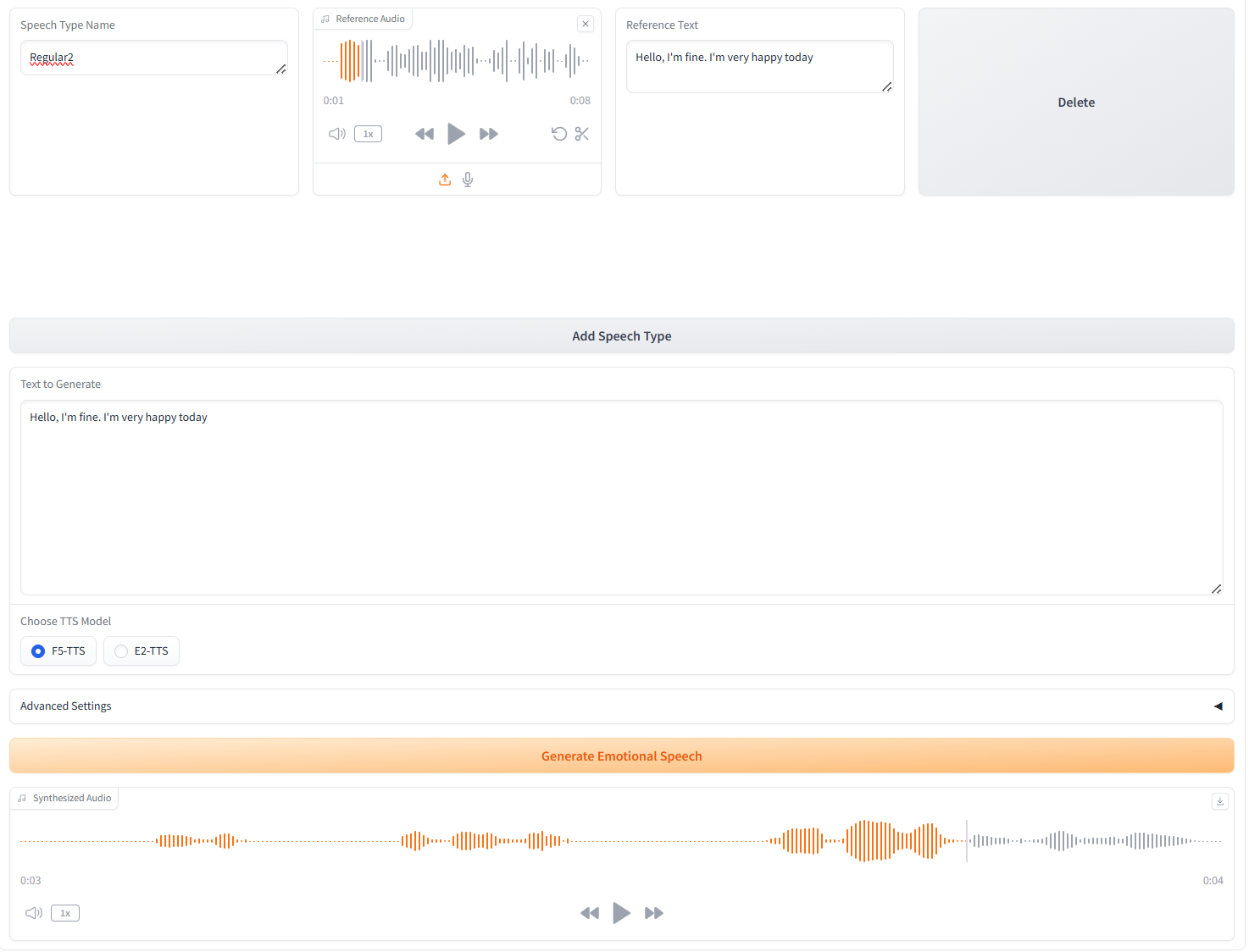
3. توليد أنواع متعددة من الكلام
3. خطوات التشغيل
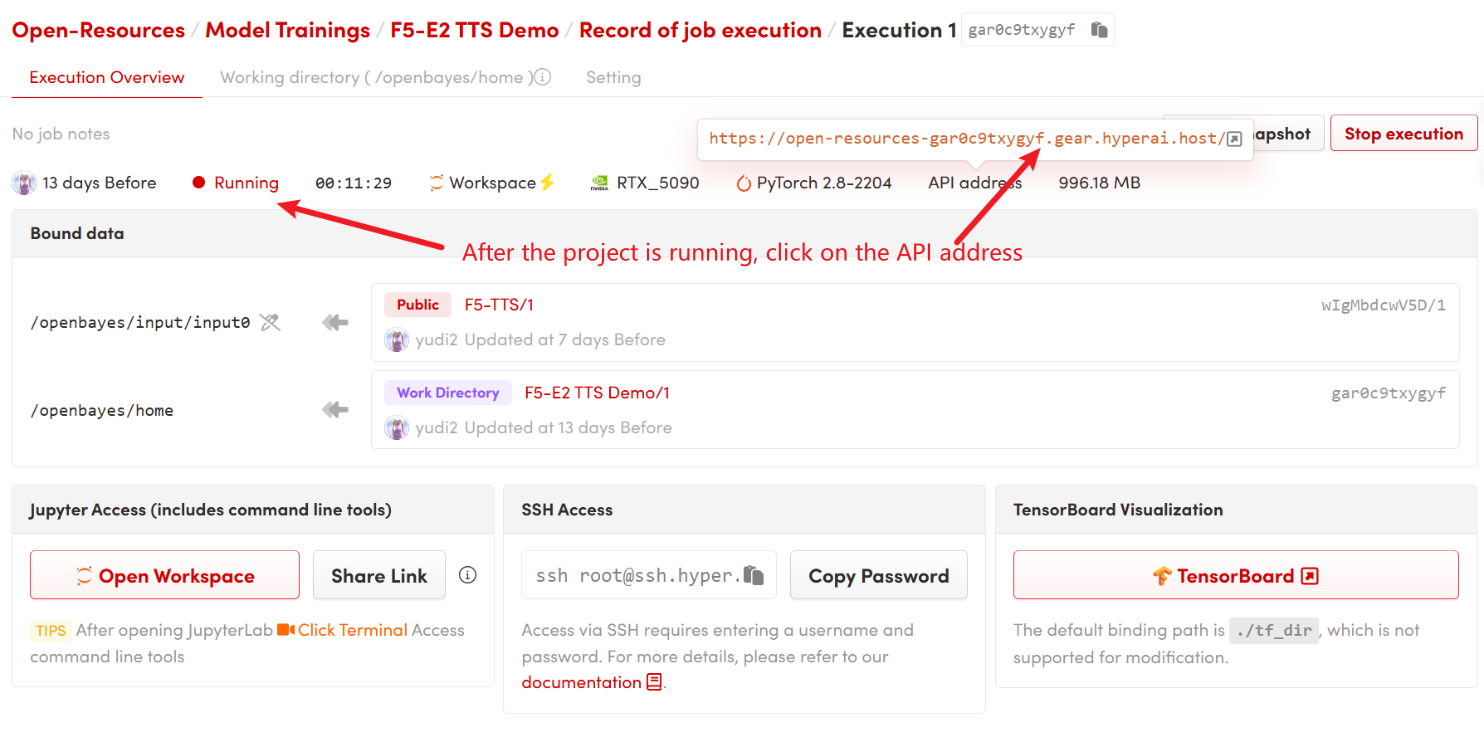
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
2. خطوات الاستخدام
إذا ظهرت رسالة "بوابة غير صالحة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لكبر حجم النموذج، يُرجى الانتظار حوالي 9 دقائق ثم تحديث الصفحة.
عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
1. تحويل النص إلى كلام مجمع
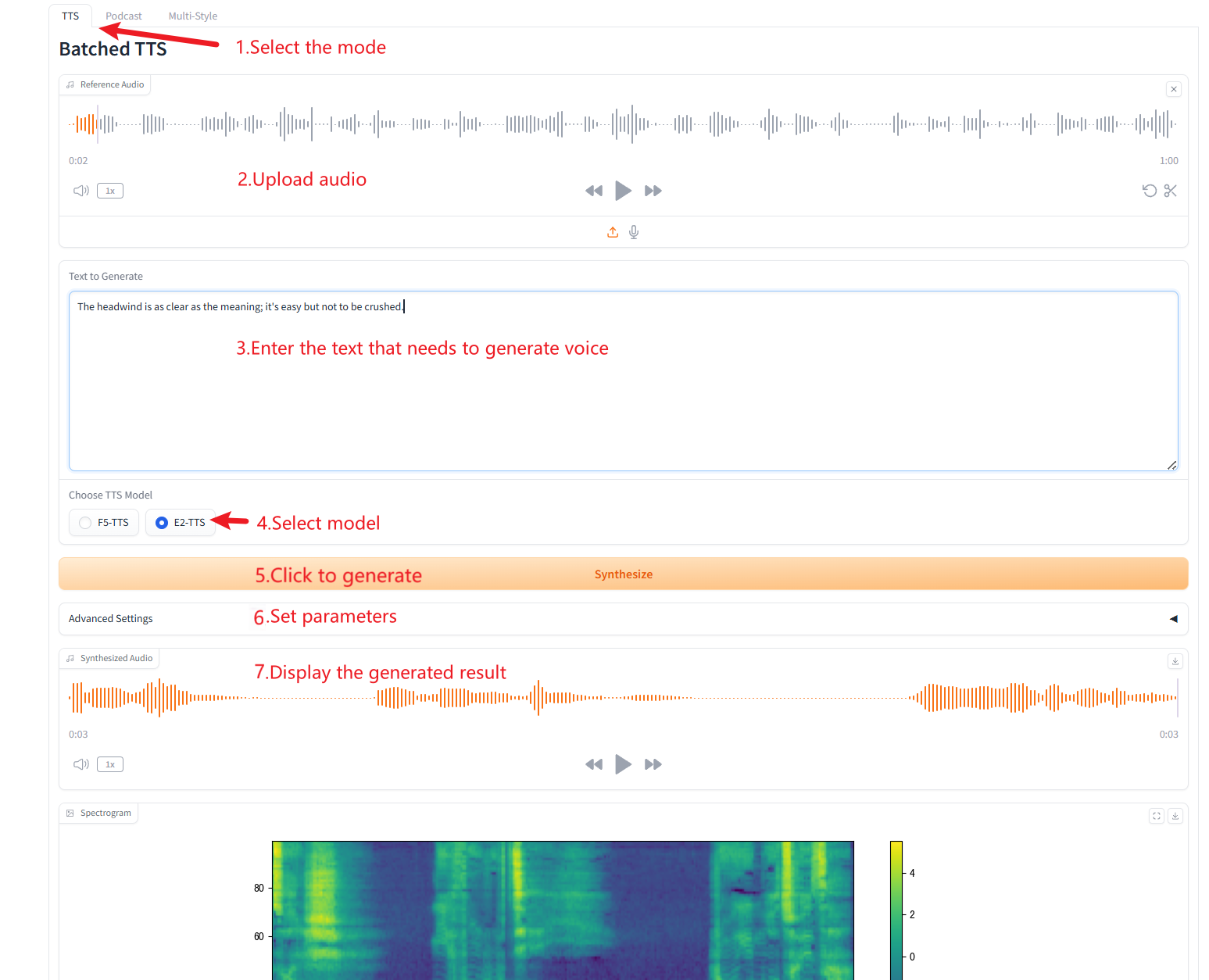
وصف المعلمة
- نص مرجعي:اتركه فارغًا ليتم نسخ الصوت المرجعي تلقائيًا. إذا قمت بإدخال نص، فسيتم إلغاء النسخ التلقائي.
- إزالة الصمت:يميل هذا النموذج إلى إنتاج الصمت، وخاصة في الصوت الأطول. يمكننا إزالة الصمت يدويًا إذا لزم الأمر. يرجى ملاحظة أن هذه ميزة تجريبية وقد تؤدي إلى نتائج غريبة. سيؤدي هذا أيضًا إلى زيادة وقت البناء.
- كلمات مقسمة مخصصة:أدخل الكلمات المخصصة التي تريد تقسيمها، مفصولة بفاصلات. اتركه فارغًا لاستخدام القائمة الافتراضية.
- سرعة:التحكم في سرعة الكلام الناتج
2. إنشاء البودكاست
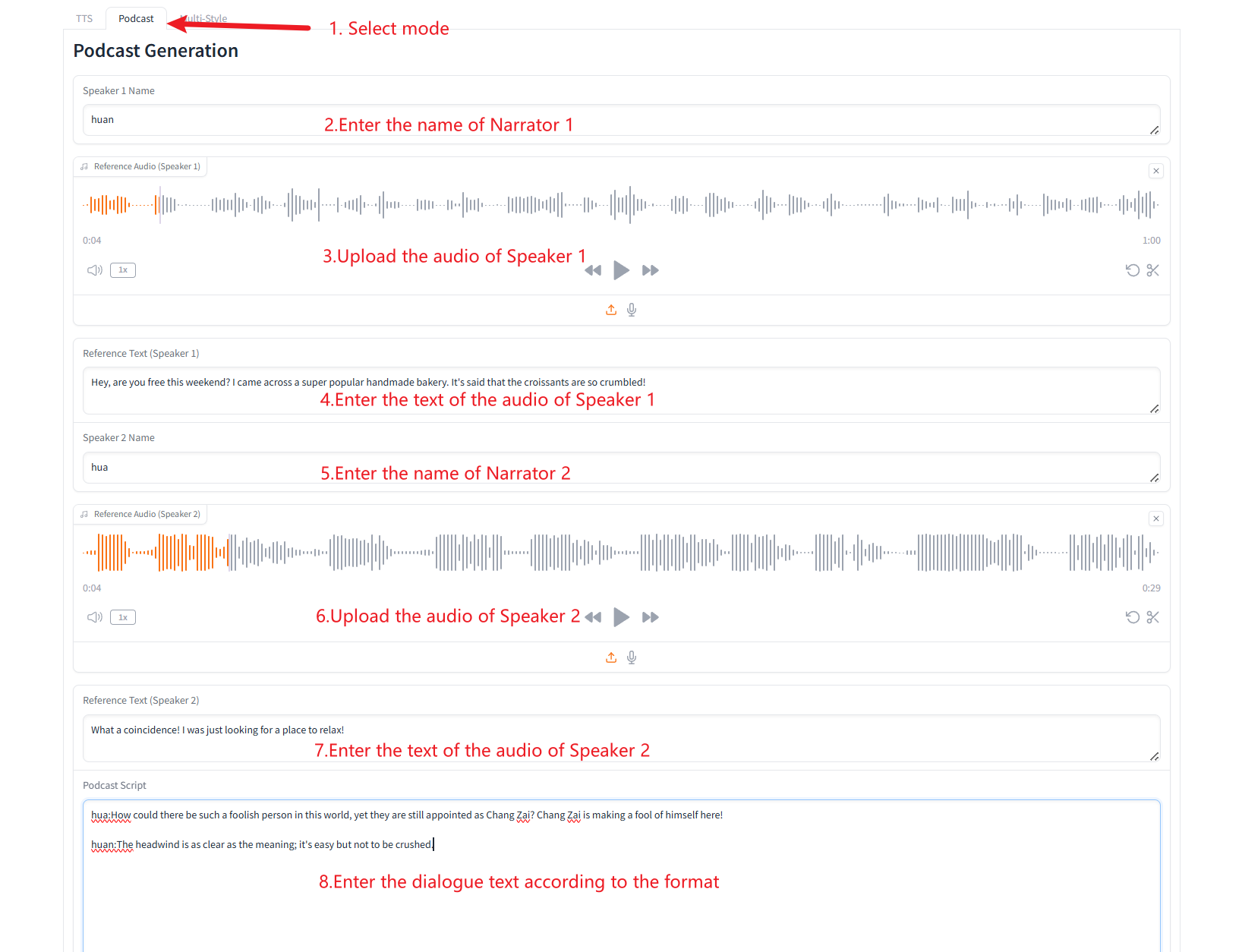
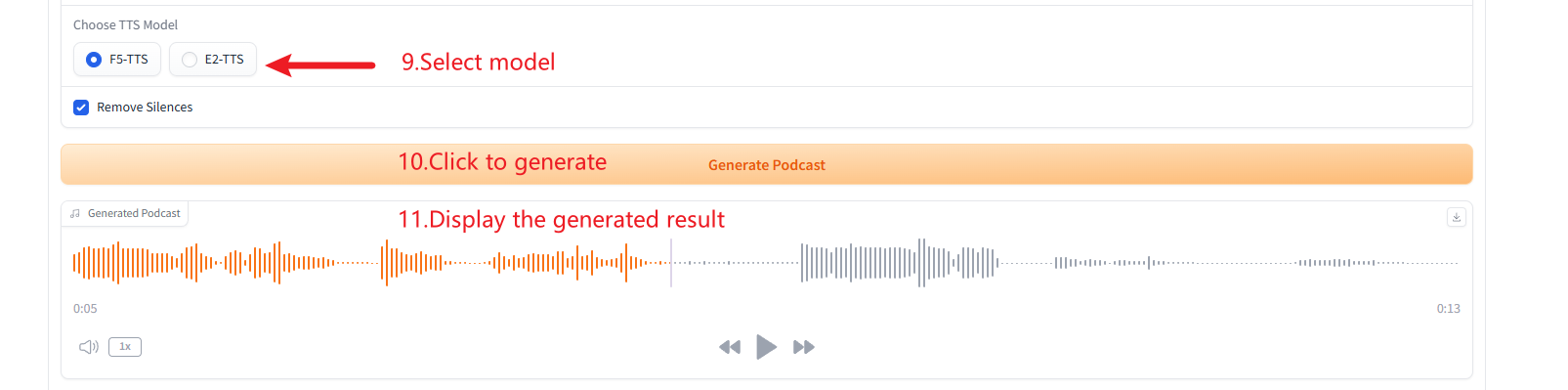
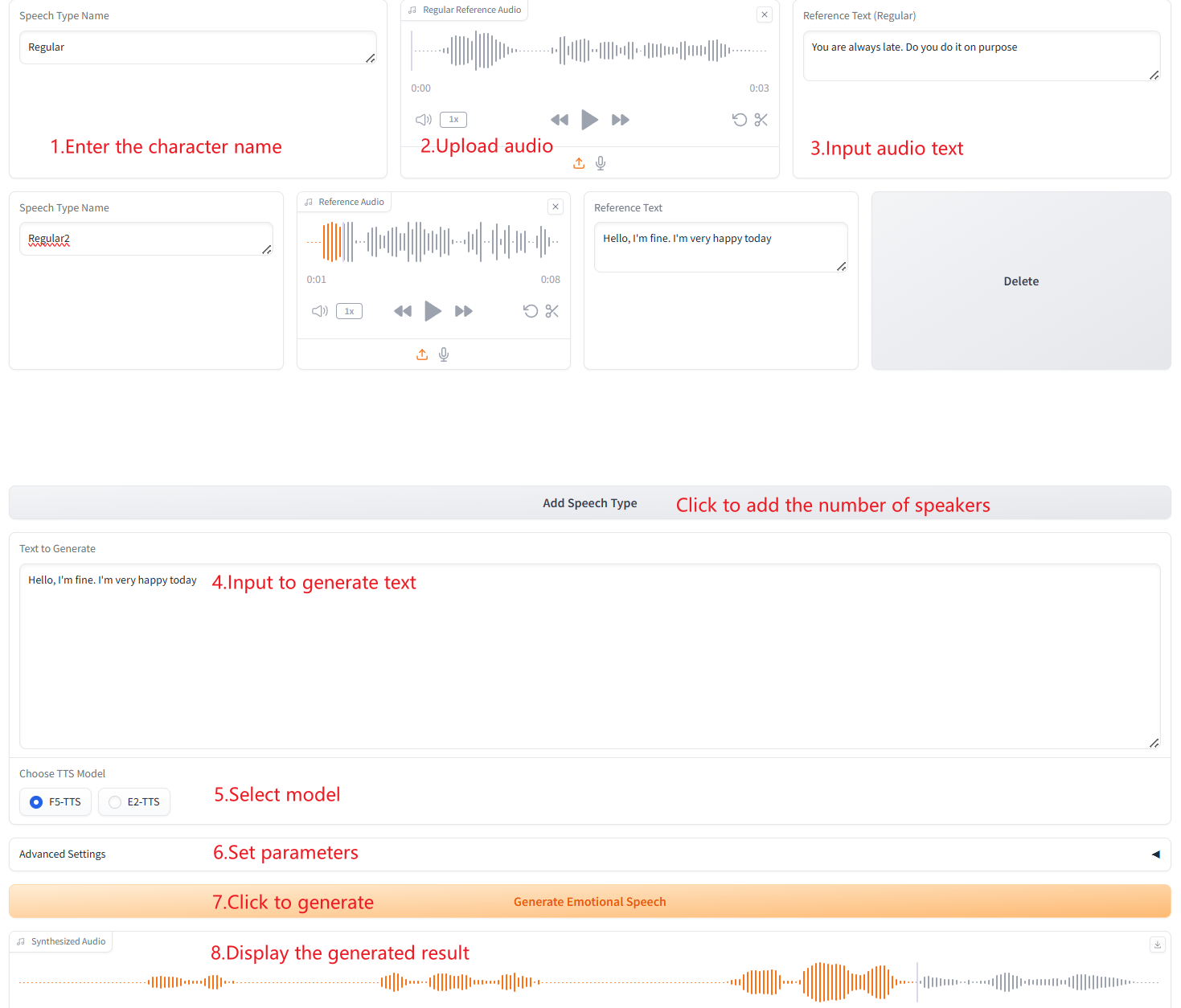
3. توليد أنواع متعددة من الكلام
معلومات الاستشهاد
@article{chen-etal-2024-f5tts,
title={F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching},
author={Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen},
journal={arXiv preprint arXiv:2410.06885},
year={2024},
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.