Command Palette
Search for a command to run...
عرض توضيحي لأداة استنساخ الصوت وتحويل النص إلى كلام من Fish Speech v1.4
مقدمة البرنامج التعليمي

تتضمن الميزات الرئيسية لبرنامج Fish Speech تحويل النص إلى كلام، ودعم اللغات المتعددة، وتخصيص الصوت، ومكتبة صوتية عالية الجودة، ومصدر مفتوح مجاني. إنه مناسب لمجموعة متنوعة من السيناريوهات، مثل إنشاء المحتوى والتعليم وخدمة العملاء والأدوات المساعدة وما إلى ذلك. يوفر النموذج أيضًا دعمًا لتكامل واجهة برمجة التطبيقات وضبط النموذج بدقة، مما يسمح للمستخدمين بالتخصيص والتحسين وفقًا لاحتياجاتهم.
وقد حقق الإصدار الأحدث 1.4 تقدمًا كبيرًا في دعم اللغات المتعددة والأداء، كما تضاعف حجم بيانات التدريب إلى 700 ألف ساعة.يدعم 8 لغات رئيسية، بما في ذلك الإنجليزية والصينية والألمانية واليابانية والفرنسية والإسبانية والكورية والعربية. ويقدم الإصدار الجديد أيضًا استنساخًا صوتيًا فوريًا، مما يسمح للمستخدمين بتكرار نمط صوت معين بسرعة، ويوفر خيارات نشر مرنة وخدمات API.
لقد قام هذا البرنامج التعليمي بنشر النموذج والبيئة. يمكنك تنفيذ مهام استنساخ الصوت أو تحويل النص إلى كلام بشكل مباشر وفقًا لإرشادات البرنامج التعليمي.
كيفية الركض
1. 首先克隆容器, 按步骤启动容器
2. 复制生成的 API 地址到浏览器即可使用
3. 该教程主要包含 2 个功能:文本转语音和声音克隆
3.1 文本转语音:在「Input Text」输入生成的文本,点击「Generate」即可生成结果

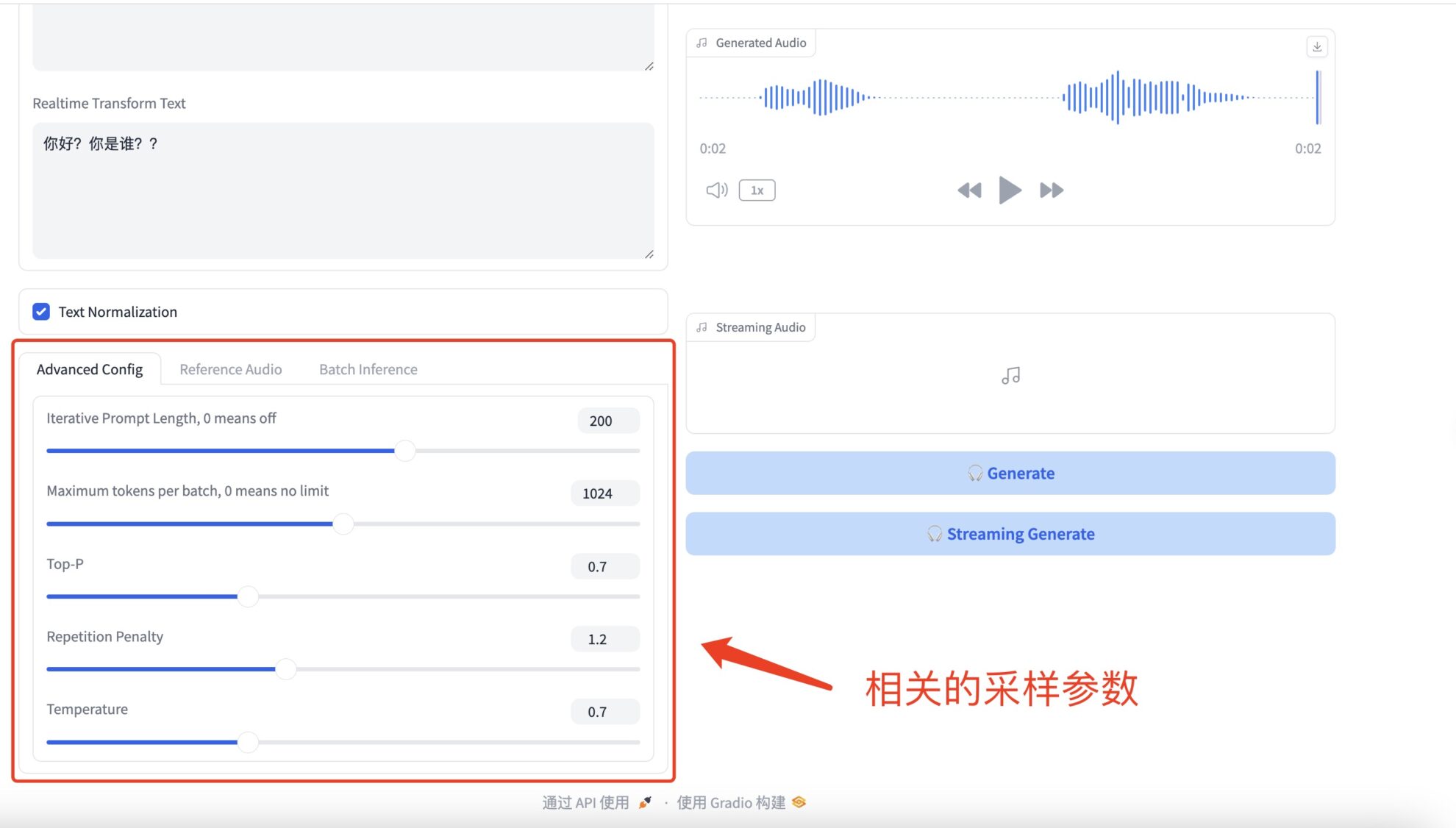
* Advanced Configs
相关的采样参数具体如下:
- طول المطالبة التكرارية: يشير إلى طول النص السابق الذي سيأخذه النموذج في الاعتبار عند إنشاء النص. إذا تم ضبطها على قيمة غير صفرية، فسوف يأخذ النموذج في الاعتبار العدد المحدد من الكلمات أو الرموز الحديثة كسياق في كل خطوة من خطوات التوليد. إذا تم ضبطه على 0، يتم إيقاف تشغيل هذه الميزة وقد يأخذ النموذج في الاعتبار كل السياقات المتاحة أو يقرر طول السياق استنادًا إلى معلمات أخرى مثل حجم نافذة النموذج.
- يحدد الحد الأقصى لعدد الرموز لكل دفعة الحد الأقصى لعدد الرموز التي يمكن للنموذج إنشاؤها في كل دفعة. تشير العلامات عادةً إلى الكلمات وعلامات الترقيم وما إلى ذلك. إذا تم ضبطها على 0، فلا يوجد حد وسوف يقوم النموذج بإنشاء نص بالقدر اللازم من الطول، أو حتى يتم الوصول إلى الحد الأقصى لطول النموذج الداخلي.
- Top-P (المعروف أيضًا باسم أخذ العينات الأساسية أو أخذ العينات الاحتمالية) هي استراتيجية لتوليد النص حيث يأخذ النموذج في الاعتبار فقط أصغر مجموعة من الكلمات التي يكون احتمالها التراكمي أكبر من P عند توليد كل كلمة جديدة. وهذا يعني أن النموذج سوف يختار الكلمة التالية من هذه المجموعة بشكل عشوائي، مما يزيد من تنوع النص الناتج مع تجنب توليد كلمات غير ذات صلة باحتمالية منخفضة.
- يتم استخدام عقوبة التكرار لتقليل المحتوى المتكرر في النص المُنشأ. عندما يميل النموذج إلى تكرار الكلمات أو العبارات التي تم إنشاؤها بالفعل، فإن تطبيق هذه المعلمة يمكن أن يقلل من احتمالية تحديد هذه الكلمات. ويتم ذلك عن طريق تعديل (خفض عادة) درجات احتمالية الكلمات التي تم إنشاؤها بالفعل، وبالتالي تشجيع النموذج على اختيار كلمات مختلفة.
- تتحكم درجة الحرارة في عشوائية النص الناتج.
3.2 声音克隆:选择「Reference Audio」并点击「Enable Reference Audio」,
上传「Reference Audio(参考音频)」,以及「Reference Text(参考文本)」,在「Input Text」输入生成的文本,点击「Generate」即可生成声音克隆结果

4. 其他参数说明
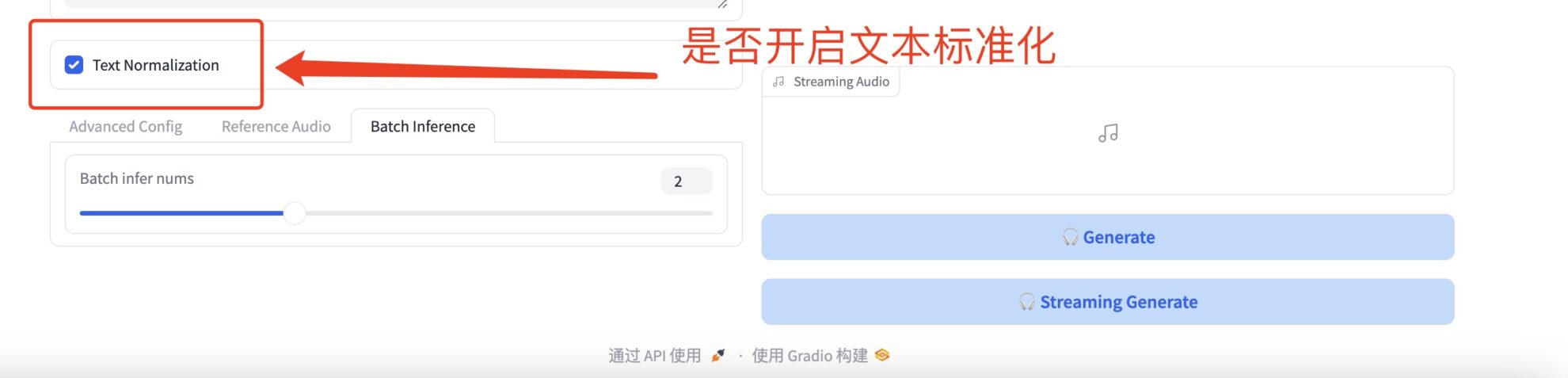
* Text Normalization
是否开启文本标准化(例如日期、固话、金钱等等)
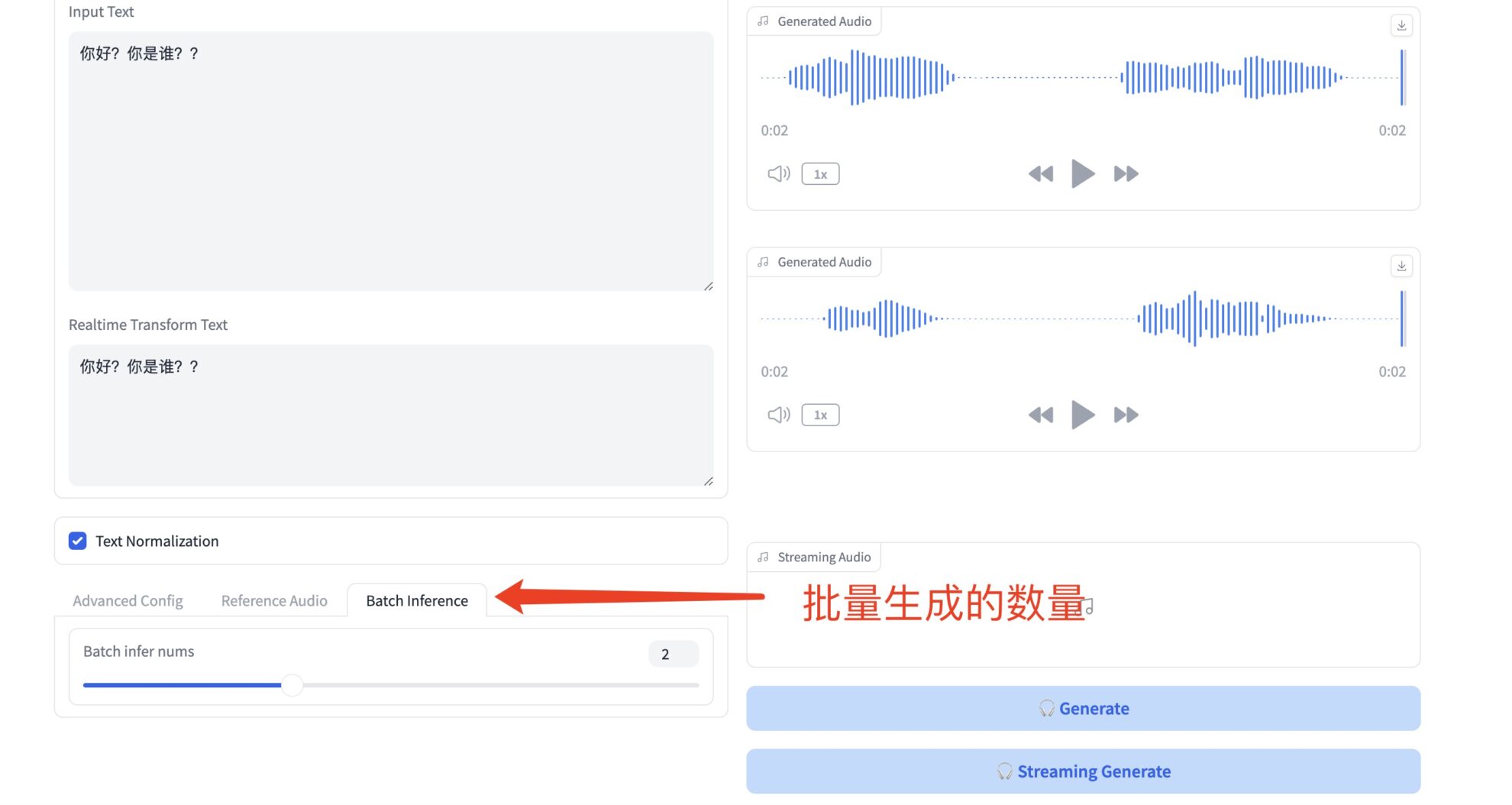
* Batch Inference
设置生成语音数量
التبادل والمناقشة
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓

بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.