Command Palette
Search for a command to run...
استخدام انتشار جيبس لإزالة الضوضاء العمياء من الصور
إزالة الضوضاء العمياء للصورة استنادًا إلى انتشار جيبس

مقدمة البرنامج التعليمي
GDiff، اختصارًا لـ Gibbs-Diffusion، هي طريقة بايزية لإزالة التشويش، تعالج مشكلة أخذ العينات اللاحقة لمعاملات الإشارة والتشويش. تعتمد هذه الطريقة على مُستخلص عينات جيبس الذي يتناوب بين خطوات أخذ العينات باستخدام نموذج انتشار مُدرَّب مسبقًا (يُحدد التوزيع الاحتمالي المسبق للإشارة) ومُستخلص عينات مونت كارلو هاميلتوني. تُقدم هذه الورقة تطبيقاتها في إزالة التشويش من الصور الطبيعية وعلم الكونيات (تحليل إشعاع الخلفية الكونية الميكروي). نتائج هذه الورقة هي... الاستماع إلى الضوضاء: إزالة الضوضاء العمياء باستخدام تقنية انتشار جيبس
الوثيقة الرسمية تعطي فقط طريقة الاختبار، والتي تتمثل في تمرير صورة أصلية واضحة، وفرض الضوضاء، ثم إجراء مقارنة بين إزالة الضوضاء غير العمياء وإزالة الضوضاء العمياء.
عرض التأثير
في العرض التوضيحي الرسمي للتأثير، يتم إدخال صورة أصلية واضحة، ويتم فرض ضوضاء بمعلمات معينة عليها، ثم يتم إجراء إزالة الضوضاء العمياء.
الأشكال التالية من اليسار إلى اليمين: الصورة بعد تراكب الضوضاء، والصورة الأصلية، وتأثير إزالة الضوضاء العمياء، والمتوسط الخلفي الذي تمت إزالة الضوضاء منه

مقدمة لإزالة الضوضاء العمياء وغير العمياء
إزالة الضوضاء العمياء وإزالة الضوضاء غير العمياء هما طريقتان لإزالة الضوضاء في معالجة الصور ومعالجة الإشارات. الفرق الرئيسي بينهما يكمن في درجة التنبؤ بمعلومات الضوضاء.
إزالة الضوضاء العمياء
التعريف: يشير مصطلح إزالة الضوضاء العمياء إلى إزالة الضوضاء دون معرفة خصائص الضوضاء أو نموذج الضوضاء. لا تعتمد هذه الطريقة على المعرفة المسبقة بالضوضاء، بل تستخدم معلومات الصورة أو الإشارة نفسها لإزالة الضوضاء.
سمات:
- مستقل عن نموذج الضوضاء: ليست هناك حاجة لمعرفة نوع أو توزيع أو شدة الضوضاء.
- قدرة قوية على التكيف: يمكن تطبيقها على أنواع مختلفة من بيئات الضوضاء والإشارات.
- تعقيد عالي: نظرًا لعدم وجود مساعدة من نموذج الضوضاء، فإن إزالة الضوضاء العمياء تتطلب عادةً خوارزميات أكثر تعقيدًا وموارد حوسبة أكبر.
إزالة الضوضاء غير العمياء
التعريف: يشير مصطلح إزالة الضوضاء غير العمياء إلى إزالة الضوضاء عندما تكون خصائص الضوضاء أو نموذج الضوضاء معروفة. تستخدم هذه الطريقة المعرفة المسبقة بالضوضاء لتحسين عملية إزالة الضوضاء.
سمات:
- الاعتماد على نموذج الضوضاء: يتطلب معرفة مسبقة بنوع الضوضاء وتوزيعها وشدتها.
- تأثير أفضل: عندما يكون نموذج الضوضاء معروفًا، يمكن تحسينه لأنواع معينة من الضوضاء لتحقيق تأثير إزالة الضوضاء بشكل أفضل.
- نطاق تطبيق محدود: هناك حاجة إلى نماذج ومعلمات مختلفة لأنواع مختلفة من الضوضاء، ونطاق التطبيق أضيق من إزالة الضوضاء العمياء.
كيفية تشغيل البرنامج التعليمي
ينقسم هذا البرنامج التعليمي إلى قسمين. الجزء الأول هو "إزالة الضوضاء العمياء للصور غير الواضحة"، والذي يمكن تشغيله في ملف start.ipynb (هذا الملف). هنا، يمكنك تمرير صورة ضبابية مع ضوضاء لإزالة الضوضاء العمياء. الجزء الثاني هو "صورة واضحة مع الضوضاء المتراكبة وإزالة الضوضاء"، والذي يتم تشغيله في ملف test.ipynb. هذا تبسيط للوثيقة الرسمية ويمكن استخدامه لتمرير صور واضحة مع ضوضاء متراكبة لمقارنة الفرق بين نموذج إزالة الضوضاء الأعمى ونموذج إزالة الضوضاء غير الأعمى.
إذا كنت بحاجة إلى استخدام صور مخصصة، فما عليك سوى تحميل الصور وتعديل مسارات الصور التي تريد معالجتها وتشغيلها واحدة تلو الأخرى. (يجب أن يكون اسم الصورة باللغة الإنجليزية)
الجزء الأول: إزالة الضوضاء العمياء من الصور الضبابية (start.ipynb)
استيراد الحزم المطلوبة
import sys, time
import torch
import numpy as np
import matplotlib.pyplot as plt
import corner
import arviz as az
from PIL import Image
sys.path.append('..')
from gdiff.data import ImageDataset, get_colored_noise_2d
from gdiff.model import load_model
import gdiff.hmc_utils as iut
from gdiff.utils import ssim, psnr, plot_power_spectrum, plot_list_of_images
plt.rcParams.update(
{
'text.usetex': False,
'font.family': 'stixgeneral',
'mathtext.fontset': 'stix',
}
)تأتي وظائف قراءة الصور ومعالجتها المسبقة وطرق الاستخدام من الوثيقة الرسمية data.py
#图片读取与预处理,方法来自官方文档 data.py
def readimg(filename):
from torchvision import transforms
img=Image.open(filename)
trans = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
img=trans(img)
return imgفيما يلي الطريقة الرسمية لقراءة مجموعات البيانات، والتي لم يتم استخدامها في هذه الوثيقة. يمكن للمستخدمين وضع مجموعات البيانات الخاصة بهم في مجلداتهم وإجراء بعض التعديلات الطفيفة لتحقيق المعالجة الدفعية (يمكن تحديد عدد قليل فقط من أسماء المجلدات في مجلد البيانات)
#
# PARAMETERS 官方数据读取与噪声参数,模型选择
#
# Dataset and sample 读取官方数据集
dataset_name = "CBSD68" # Choices among "imagenet_train", "imagenet_val", "CBSD68", "McMaster", "Kodak24"
dataset = ImageDataset(dataset_name, data_dir='./data')
sample_id = 0 # np.random.randint(len(dataset))
# Noise 准备叠在在清晰图片上的噪声
phi_true = -0.4 # Spectral index -> between -1 and 1 (\varphi in the paper)
sigma_true = 0.1 # Noise level
# Device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Model 选择模型,有 5000 与 10000 步迭代模型可选
diffusion_steps = 5000 # Number of diffusion steps: 5000 or 10000
model = load_model(diffusion_steps=diffusion_steps,
device=device,
root_dir='./model_checkpoints')
model.eval()
# Inference
num_chains = 4 # Number of HMC chains
n_it_gibbs = 50 # Number of Gibbs iterations after burn-in
n_it_burnin = 25 # Number of burn-in iterationsبعد ذلك، اقرأ الصورة التي تحتاج إلى إزالة الضوضاء منها. على سبيل المثال، الصورة المستخدمة في هذا البرنامج التعليمي هي '3_noisy.png' في الدليل الرئيسي. في img=readimg('3_noisy.png')، قم ببساطة بتغيير المسار إلى '3_noisy.png'.
في حالة A6000 مع بطاقة واحدة، يستغرق الأمر عدة دقائق لمعالجة صورة واحدة.
#
# DENOISING 在此处读入的图片为高噪声图,在此处进行降噪处理
#
# 读取自己的高噪声图片,用于去噪
img=readimg('3_noisy.png')
x = img.to(device).unsqueeze(0)
# Our DDPM has discrete timestepping -> we get the time step closest to the chosen noise level
sigma_true_timestep, sigma_true = model.get_closest_timestep(torch.tensor([sigma_true]), ret_sigma=True)
alpha_bar_t = model.alpha_bar_t[sigma_true_timestep.cpu()].reshape(-1, 1, 1, 1).to(device)
print(f"Time step corresponding to noise level {sigma_true.item():.3f}: {sigma_true_timestep.item()}")
yt = torch.sqrt(alpha_bar_t) * x # Noisy image normalized for the diffusion model 归一化图像
# Non-blind denoising (for reference) 非盲去噪 即已知噪声参数的情况下去噪
print("Denoising in non-blind setting...")
t0 = time.time()
x_hat_nonblind = model.denoise_samples_batch_time(yt,
sigma_true_timestep.unsqueeze(0),
phi_ps=phi_true)
t1 = time.time()
print(f"Non-blind denoising took {t1-t0:.2f} seconds")
# Blind denoising with GDiff 基于 GDiff 的盲去噪
print("Denoising in blind setting (GDiff)...")
t0 = time.time()
phi_hat_blind, x_hat_blind = model.blind_denoising(x, yt,
num_chains_per_sample=num_chains,
n_it_gibbs=n_it_gibbs,
n_it_burnin=n_it_burnin)
t1 = time.time()
print(f"Blind denoising took {t1-t0:.2f} seconds")
# Denoised posterior mean estimate 去噪的后验均值估计
x_hat_blind_pmean = x_hat_blind[:, n_it_burnin:].mean(dim=(0, 1))خطوة زمنية تتوافق مع مستوى الضوضاء 0.100: 134 إزالة الضوضاء في وضع غير أعمى... استغرقت إزالة الضوضاء غير الأعمى 4.48 ثانية إزالة الضوضاء في وضع أعمى (GDiff)...
0%| | 0/75 [00:00
تكييف حجم الخطوة باستخدام 300 تكرار تم إصلاح حجم الخطوة إلى: tensor([0.0179, 0.0181, 0.0179, 0.0194], device='cuda:0')
100%|██████████| 75/75 [08:52<00:00، 7.10 ثانية/ثانية]
استغرقت عملية إزالة الضوضاء العمياء 532.30 ثانية
#
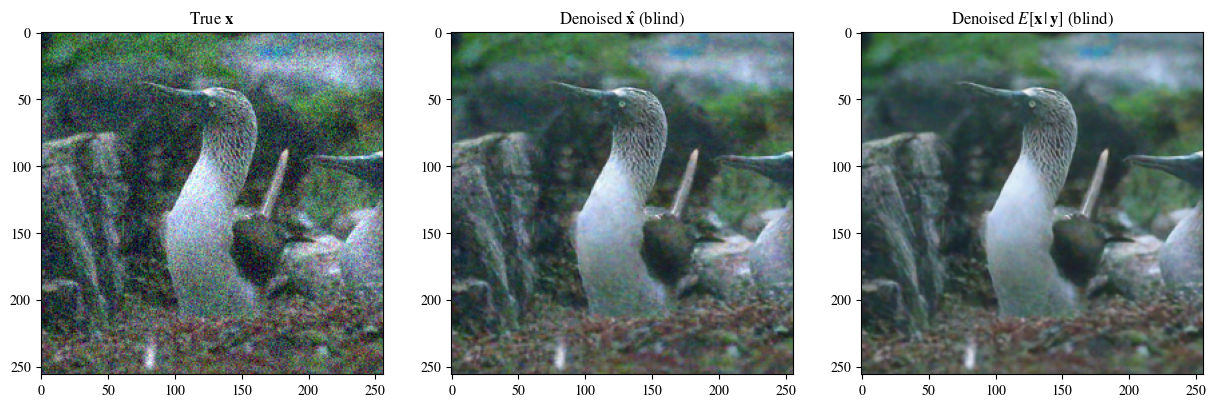
# Plot of a reconstruction 展示结果 顺序为:原始图片 非盲去噪 盲去噪 去噪的后验均值
#
data = [x[0],
x_hat_blind[0, -1],
x_hat_blind_pmean]
data = [d.to(device) for d in data]
labels_base = [r"True $\mathbf{x}$",
r"Denoised $\hat{\mathbf{x}}$ (blind)",
r"Denoised $E[\mathbf{x}\,|\,\mathbf{y}]$ (blind)"]
labels = [labels_base[0] ,
labels_base[1] ,
labels_base[2] ]
plot_list_of_images(data, labels)
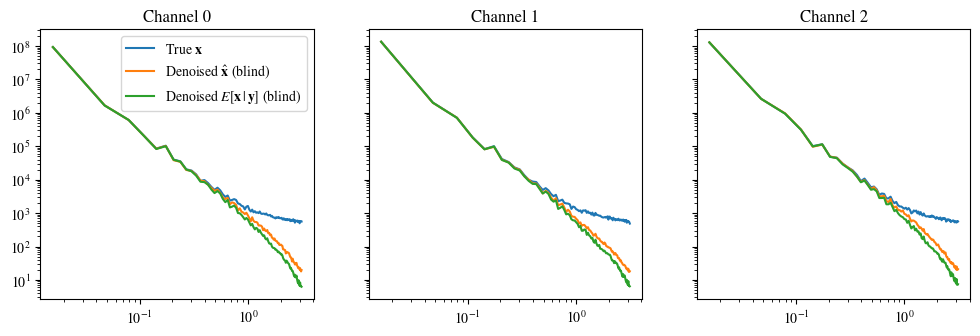
plot_power_spectrum(data, labels_base, figsize=(12, 3.5))قص بيانات الإدخال إلى النطاق الصحيح لـ imshow باستخدام بيانات RGB ([0..1] للأعداد العشرية أو [0..255] للأعداد الصحيحة).
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.