Command Palette
Search for a command to run...
تحديد كمية محولات الرؤية (Vit) من أجل النشر الفعال: الاستراتيجيات وأفضل الممارسات
يوصي هذا البرنامج التعليمي باستخدام pytorch الإصدار 2.0 ووحدة معالجة رسومية واحدة 4090. لتسهيل الاستخدام، تم تنزيل النماذج المستخدمة في البرنامج التعليمي. من فضلك قم بتشغيلهم واحدا تلو الآخر.
1. المقدمة
مع استمرار ارتفاع الطلب على أنظمة الرؤية الحاسوبية المتقدمة عبر الصناعات، أصبح نشر محولات الرؤية محط اهتمام الباحثين والممارسين. ومع ذلك، فإن تحقيق الإمكانات الكاملة لهذه النماذج يتطلب فهمًا عميقًا لهندستها المعمارية. وبالإضافة إلى ذلك، فمن المهم بنفس القدر تطوير استراتيجيات التحسين لنشر هذه النماذج بشكل فعال.
تهدف هذه المقالة إلى تقديم نظرة عامة على Vision Transformer، واستكشاف بنيته ومكوناته الرئيسية والأساسيات التي تجعله فريدًا. في نهاية المقال، سنناقش بعض استراتيجيات التحسين مع عروض توضيحية للكود لجعل النموذج أكثر إحكاما لتسهيل النشر.
2. نظرة عامة على فيتامين
ViT هو نوع خاص من الشبكات العصبية التي تستخدم بشكل أساسي لتصنيف الصور واكتشاف الكائنات. لقد تجاوزت دقة ViT دقة شبكات CNN التقليدية، والعامل الرئيسي الذي ساهم في ذلك هو أنها تعتمد على بنية المحول. ما هو هذا العمارة الآن؟
في عام 2017، فاسواني وآخرون. "الاهتمام هو كل ما تحتاجه"تم تقديم هندسة الشبكة العصبية المحولة في . تستخدم الشبكة بنية ترميز وفك تشفير مشابهة جدًا للشبكة العصبية المتكررة (RNN). في هذا النموذج، لا يوجد مفهوم لطوابع الوقت على المدخلات؛ يتم تمرير جميع الكلمات في نفس الوقت، ويتم تحديد تضمينات الكلمات الخاصة بها في نفس الوقت.
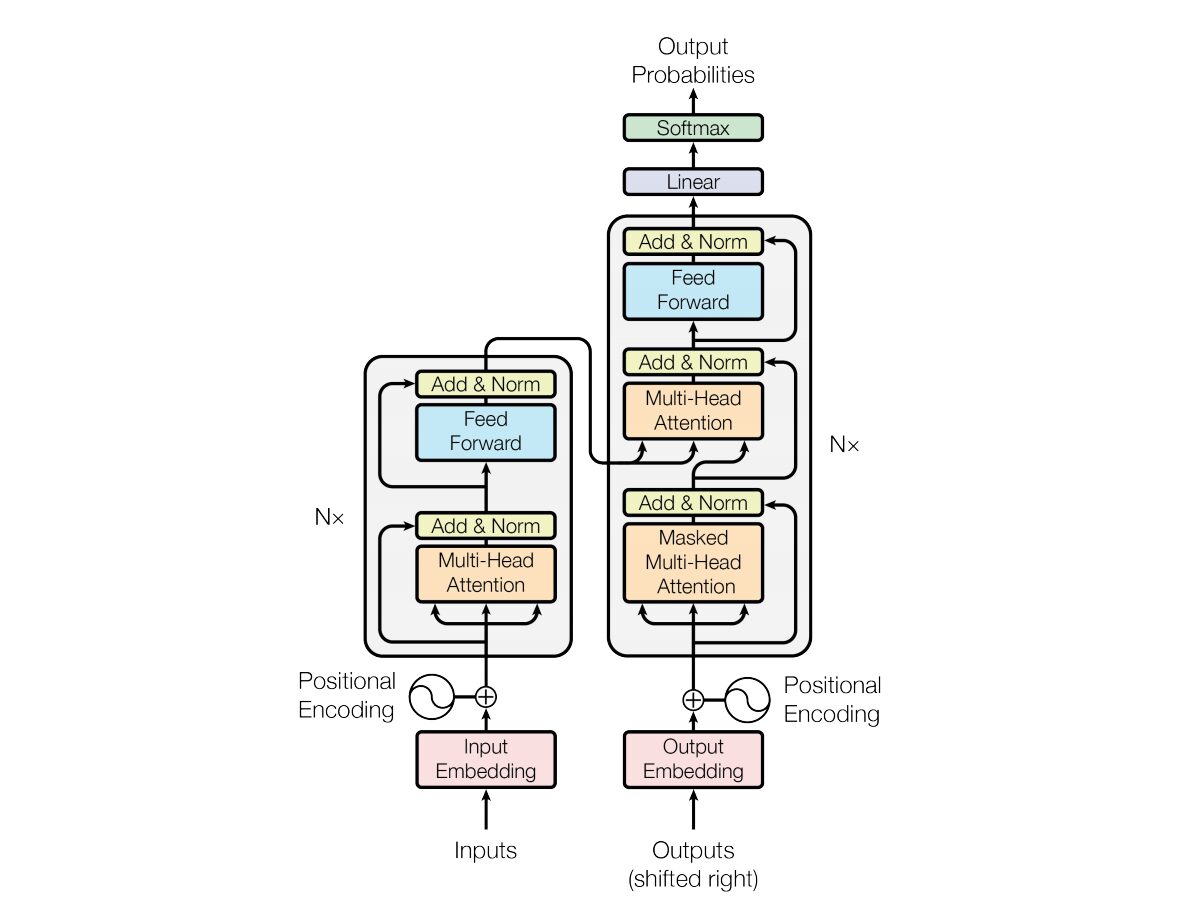
يعتمد هذا النوع من بنية الشبكة العصبية على آلية تسمى الاهتمام الذاتي.
فيما يلي شرح عالي المستوى للمكونات الرئيسية لهندسة المحول:
- تضمين الإدخال: يعد تضمين الإدخال الخطوة الأولى في تمرير الإدخال إلى المحول. يشير تضمين الإدخال إلى عملية تحويل رموز الإدخال أو الكلمات إلى متجه ذي حجم ثابت يمكن إدخاله في النموذج. تعتبر خطوة التضمين هذه بالغة الأهمية لأنها تحول تمثيل الرمز المنفصل إلى تمثيل متجه مستمر بطريقة تلتقط العلاقات الدلالية بين الكلمات. تعمل خطوة التضمين هذه على ربط الكلمة بمتجه، ولكن الكلمة نفسها قد يكون لها معانٍ مختلفة في جمل مختلفة. هذا هو المكان الذي تأتي فيه أجهزة ترميز الموضع.
- الترميزات الموضعية: نظرًا لأن المحول نفسه لا يفهم ترتيب العناصر في التسلسل، تتم إضافة الترميزات الموضعية إلى تضمينات الإدخال لتزويد النموذج بمعلومات حول موضع العنصر في التسلسل. باختصار، توفر تضمينات الموضع متجهًا يعتمد سياقيًا على موضع الكلمة في الجملة. استخدمت الورقة الأصلية وظائف الجيب وجيب التمام لتوليد هذا المتجه. يتم تمرير هذه المعلومات إلى كتلة التشفير.
- بنية المشفر-الفك: يستخدم المحول بشكل أساسي للمهام المتسلسلة إلى المتسلسلة مثل الترجمة الآلية. يتكون من جهاز ترميز وجهاز فك ترميز. يقوم المشفر بمعالجة تسلسل الإدخال ويقوم فك التشفير بإنشاء تسلسل الإخراج.
- الاهتمام الذاتي متعدد الرؤوس: يسمح الاهتمام الذاتي للنموذج بترجيح أجزاء مختلفة من تسلسل الإدخال بشكل مختلف عند إجراء التنبؤات. الابتكار الرئيسي في Transformer هو استخدام رؤوس انتباه متعددة، مما يتيح للنموذج التركيز على جوانب مختلفة من الإدخال في وقت واحد. يتم تدريب كل رأس انتباه على التركيز على نمط مختلف.
- حاصل ضرب النقاط المقاس: تحسب آلية الانتباه مجموعة من درجات الانتباه عن طريق أخذ حاصل ضرب النقاط لتسلسل الإدخال ومتجه الوزن القابل للتعلم. يتم قياس هذه النتائج وتمريرها من خلال دالة softmax للحصول على أوزان الاهتمام. المجموع المرجح لتسلسل الإدخال باستخدام أوزان الانتباه هذه هو مخرجات آلية الانتباه.
- الشبكة العصبية التغذية الأمامية: بعد طبقة الانتباه، عادةً ما تتضمن كل كتلة ترميز وفك تشفير شبكة عصبية تغذية أمامية مع وظيفة تنشيط مثل ReLu. يتم تطبيق الشبكة بشكل مستقل على كل موضع في التسلسل.
- تطبيع الطبقة والاتصالات المتبقية: يتم استخدام تطبيع الطبقة والاتصالات المتبقية لتحقيق استقرار التدريب. تتمتع كل طبقة فرعية (الانتباه أو التغذية الأمامية) في كل من المشفر وفك التشفير بتطبيع الطبقة، ويتم تمرير خرج كل طبقة فرعية من خلال اتصال متبقي.
- مجموعة المشفر وفك التشفير: تتكون مجموعة المشفر وفك التشفير من عدة طبقات متطابقة مكدسة فوق بعضها البعض. عدد الطبقات هو معلمة فائقة.
- الاهتمام الذاتي المقنع في جهاز فك التشفير: أثناء التدريب، في جهاز فك التشفير، يتم تعديل آلية الاهتمام الذاتي لمنع الاهتمام بالرموز المستقبلية. يتم ذلك باستخدام تقنيات الإخفاء لضمان أن كل موضع يمكنه معالجة الموضع الذي يسبقه فقط.
- الطبقات الخطية النهائية وطبقات Softmax: يتم تحويل مخرجات مجموعة فك التشفير إلى احتمالات التنبؤ النهائية (على سبيل المثال، باستخدام طبقة خطية يتبعها تنشيط Softmax) لإنتاج تسلسل المخرجات.
3. فهم بنية مُحوِّل الرؤية
تعتبر CNN الحل الأفضل لمهام تصنيف الصور. إذا كانت مجموعة البيانات الخاصة بالتدريب المسبق كبيرة بدرجة كافية، فإن ViT يتفوق باستمرار على CNN في مثل هذه المهام. حققت ViT نجاحًا كبيرًا من خلال تدريب مشفر Transformer على ImageNet بنجاح، مما أظهر نتائج مبهرة مقارنة بالهندسة التلافيفية المعروفة.
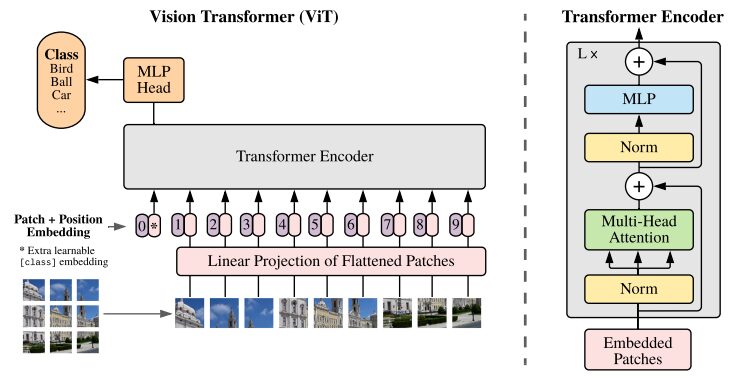
رسم توضيحي لعمارة ViT من ورقة البحث الأصلية
تعمل نماذج المحولات عادةً على معالجة الصور والكلمات التي يتم تمريرها بشكل تسلسلي إلى جهاز ترميز وفك ترميز. فيما يلي نظرة عامة مبسطة على ViT:
- استخراج التصحيح: يتم تغذية الصورة إلى مشفر المحول على شكل تسلسل من التصحيحات. الرقعة هي جزء مستطيل صغير من الصورة، وعادة ما يكون حجمها 16×16 بكسل.

- بعد تقسيم الصورة إلى كتل غير متداخلة (عادةً شبكة 16×16)، يتم تحويل كل كتلة إلى متجه يمثل ميزاتها. يتم استخراج هذه الميزات عادةً باستخدام شبكة عصبية ملتوية (CNN)، والتي تم تدريبها على تحديد الميزات المهمة اللازمة لتصنيف الصور.
- التضمين الخطي: يتم تضمين هذه الرقع المستخرجة خطيًا في متجهات مستوية. يتم بعد ذلك التعامل مع هذه المتجهات باعتبارها تسلسل الإدخال للمحول، والمعروف أيضًا باسم الإسقاط الخطي للرقعة المسطحة.
- مُشفِّر المحول: يتم تمرير متجه التصحيح المضمَّن عبر مجموعة طبقات مُشفِّر المحول. تتكون كل طبقة ترميز من آلية الاهتمام الذاتي وشبكة عصبية تغذية أمامية.
- آلية الاهتمام الذاتي: تسمح آلية الاهتمام الذاتي للنموذج بالتقاط العلاقة بين البقع المختلفة في الصورة، مما يتيح له تعلم التبعيات والعلاقات طويلة المدى. تتيح آلية الانتباه في المحول للنموذج التقاط المعلومات السياقية المحلية والعالمية، مما يمكّنه من أداء مهام الرؤية المختلفة بشكل فعال.
- ترميز الموضع: نظرًا لأن المحول نفسه لا يفهم العلاقة المكانية بين الرقع، تتم إضافة ترميز الموضع إلى تضمين الإدخال لتوفير معلومات حول موقع الرقعة في الصورة الأصلية.
- طبقات ترميز متعددة: يستخدم ViT عادةً طبقات ترميز محول متعددة لالتقاط الميزات الهرمية والمجردة من صورة الإدخال.
- تجميع المتوسط العالمي: عادةً ما يخضع خرج مشفر المحول لتجميع المتوسط العالمي، والذي يجمع المعلومات من بقع مختلفة في تمثيل بحجم ثابت.
- رأس التصنيف: يتم بعد ذلك تغذية التمثيل المدمج إلى رأس التصنيف (يتكون عادةً من طبقة واحدة أو أكثر متصلة بالكامل) لتوليد الناتج النهائي لمهمة رؤية كمبيوترية محددة (على سبيل المثال تصنيف الصور).
نوصيك بشدة بمشاهدة النسخة الأصليةأوراق بحثية، لفهم أعمق لهندسة ViT.
4. كيفية الاستخدام
يمكن الوصول إلى جميع الأكواد التالية وتنفيذها في pre_ViT.ipynb! ! ! !
4.1 تصنيف الصور باستخدام نموذج ViT المدرب مسبقًا
يتم تدريب نماذج ViT المدربة مسبقًا باستخدام ImageNet-21k الشهير، وهي مجموعة بيانات تحتوي على 14 مليون صورة و21 ألف فئة، ويتم ضبطها بدقة على مجموعة بيانات ImageNet التي تحتوي على مليون صورة و1 ألف فئة.
العرض التوضيحي:
- ستكون المكتبتان التاليتان مفقودتين عند بدء تشغيل النظام الأساسي لأول مرة. استخدم pip لتثبيت التبعيات. أضف المعلمة الإضافية --user عند تثبيت التبعيات باستخدام pip. سيتم بعد ذلك حفظ التبعيات المثبتة في مساحة عمل الحاوية ولن يتم إبطالها عند إعادة التشغيل في المرة التالية.
!pip install --user -q transformers timm- استيراد الفئات اللازمة من مكتبة Transformer. يتم استخدام ViTFeatureExtractor لاستخراج الميزات من الصور، وViTForImageClassification هو نموذج ViT مدرب مسبقًا لتصنيف الصور.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球تفاصيل الكود:
- ViTFeatureExtractor.from_pretrained: المسؤول عن تحويل صورة الإدخال إلى تنسيق مناسب لنموذج ViT.
- ViTForImageClassification.from_pretrained: يقوم بتحميل نموذج ViT المدرب مسبقًا لتصنيف الصور.
- feature_extractor: معالجة صورة الإدخال باستخدام مستخرج ميزات ViT، وتحويلها إلى تنسيق مناسب لنموذج ViT.
- النموذج: يقوم النموذج المدرب مسبقًا بمعالجة المدخلات وإنشاء سجلات الإخراج، والتي تمثل تنبؤات النموذج لفئات مختلفة. الخطوة التالية هي العثور على مؤشر الفصل الذي يحتوي على أعلى درجة لوجيت. إنشاء متغير لتخزين مؤشر الفئة المتوقعة.
- model.config.id2label[predicted_class_idx]: يقوم بربط مؤشرات الفئة المتوقعة مع العلامات المقابلة لها.
4.2 تصنيف الصور باستخدام DeiT
يوضح DeiT التطبيق الناجح للمحولات في مهام الرؤية الحاسوبية حتى مع توفر البيانات والموارد المحدودة.
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())تفاصيل الكود:
- تثبيت المكتبات: الخطوة الأولى الضرورية هي تثبيت المكتبات المطلوبة. نوصي المستخدمين بشدة بدراسة هذه المكتبات لفهمها بشكل أفضل.
- تحميل النموذج المدرب مسبقًا:: model=torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True) يقوم بتحميل نموذج DeiT المدرب مسبقًا المسمى 'deit_base_patch16_224' من مستودع DeiT.
- تعيين النموذج إلى وضع التقييم: model.eval(): تعيين النموذج إلى وضع التقييم، وهو أمر مهم للغاية عند استخدام نموذج مدرب مسبقًا للاستدلال.
- تحويلات الصورة: تحدد سلسلة من التحويلات التي سيتم تطبيقها على صورة. على سبيل المثال، تغيير الحجم، وقص المركز، وتحويل الصور إلى موتر PyTorch، وتطبيع الصور باستخدام قيم المتوسط والانحراف المعياري المستخدمة بشكل شائع بواسطة بيانات ImageNet. تنزيل الصورة وتحويلها: تتضمن الخطوة التالية تنزيل الصورة من عنوان URL وتحويلها. تؤدي إضافة الحجة [None,] إلى إضافة بُعد إضافي لمحاكاة دفعات بحجم 1.
- استنتاج النموذج والتنبؤ به: out = model(img) سيسمح باستنتاج الصورة المعالجة مسبقًا من خلال نموذج DeiT. سيقوم clsidx = torch.argmax(out) بالعثور على مؤشر الفصل الذي يحتوي على أعلى احتمال. بعد ذلك، قم بطباعة مؤشر الفئة المتوقعة.
4.3 نموذج التكميم
لتقليل حجم النموذج، يتم تطبيق التكميم. تؤدي هذه العملية إلى تقليل الحجم دون المساس بدقة النموذج.
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")تفاصيل الكود:
- شعلة.الكمية.الكمية الديناميكية (النموذج، qconfig_spec={torch.nn.Linear}، نوع البيانات=torch.qint8)
- يحدد qconfig_spec أنه ينبغي تطبيق التكميم فقط على الطبقات الخطية (المتصلة بالكامل). نوع بيانات التكميم المستخدم هو torch.qint8 (تكميم عدد صحيح مكون من 8 بت).
4.4 نموذج التحسين
تعمل وظيفة optimize_for_mobile على تحسينها خصيصًا للنشر عبر الأجهزة المحمولة وتحفظ النموذج المحسن الناتج في ملف.
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())إصدار 4.5 لايت
يعد هذا أمرًا مهمًا لنشر النماذج على الأجهزة المحمولة أو الأجهزة الطرفية التي تدعم PyTorch Lite لضمان التوافق وكفاءة بيئة التشغيل الخاصة بهذه الأجهزة.
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 مقارنة سرعة الاستدلال
لمقارنة سرعة الاستدلال لمتغيرات النموذج المختلفة، قم بتنفيذ الكود المقدم:
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
يمكن الوصول إلى جميع الأكواد المذكورة أعلاه وتنفيذها في pre_ViT.ipynb! ! ! !
الخاتمة والأفكار
في هذه المقالة، قمنا بتغطية كل ما تحتاج إليه للبدء في استخدام Visual Converter واستكشاف النموذج باستخدام وحدة التحكم Paperspace. لقد استكشفنا أحد التطبيقات المهمة لهذا النموذج: التعرف على الصور. للمقارنة والتفسير الأسهل لـ ViT، قمنا أيضًا بتضمين بنية المحول.
تقدم ورقة Vision Transformer نموذجًا واعدًا وبسيطًا كبديل لشبكات CNN. بعد تدريبه مسبقًا على ImageNet من ILSVRC ومجموعة ImageNet-21M الخاصة به، حقق النموذج معايير متطورة على مجموعات بيانات تصنيف الصور الشهيرة بما في ذلك Oxford-IIIT Pets وOxford Flowers وJFT-300M من Google Brain.
باختصار، تمثل محولات الرؤية (ViTs) وDeiT تقدمًا كبيرًا في مجال الرؤية الحاسوبية. أثبتت ViT فعالية نموذج المحول لفهم الصور من خلال بنيته القائمة على الانتباه، مما يشكل تحديًا للطرق التلافيفية التقليدية.
ويتناول DeiT بشكل خاص التحديات التي تواجه ViT من خلال تقديم تقطير المعرفة. من خلال الاستفادة من نموذج تدريب المعلم والطالب، يوضح DeiT إمكانية تحقيق أداء تنافسي باستخدام بيانات أقل تصنيفًا بشكل كبير، مما يجعله حلاً قيمًا في السيناريوهات التي لا تتوفر فيها مجموعات البيانات الكبيرة بسهولة.
ومع استمرار التقدم في الأبحاث في هذا المجال، فإن هذه الابتكارات تمهد الطريق أمام نماذج أكثر كفاءة وقوة، مما يفتح إمكانيات مثيرة لمستقبل تطبيقات الرؤية الحاسوبية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.