Command Palette
Search for a command to run...
DeCo: انتشار البكسل منفصل التردد لتوليد الصور من الطرف إلى الطرف
DeCo: انتشار البكسل منفصل التردد لتوليد الصور من الطرف إلى الطرف
Zehong Ma Longhui Wei Shuai Wang Shiliang Zhang Qi Tian
الملخص
يهدف "انتشار البكسل" (Pixel diffusion) إلى إنشاء الصور مباشرة في فضاء البكسل بأسلوب متكامل (End-to-End). ويتجنب هذا النهج القيود التي تفرضها المرمزات التلقائية المتغيرة (VAE) في نماذج الانتشار الكامن ذي المرحلتين (Two-stage latent diffusion)، مما يوفر سعة أكبر للنموذج. ومع ذلك، تعاني نماذج انتشار البكسل الحالية من بطء في عمليات التدريب والاستدلال، نظراً لأنها تقوم عادةً بنمذجة كل من الإشارات عالية التردد والدلالات الدلالية منخفضة التردد داخل "محول انتشار" (Diffusion Transformer - DiT) واحد.وسعياً نحو نموذج أكثر كفاءة لانتشار البكسل، نقترح إطار عمل "انتشار البكسل مفصول التردد" (Frequency-DeCoupled Pixel Diffusion). وانطلاقاً من فكرة فصل عملية توليد المكونات عالية التردد عن المكونات منخفضة التردد، فإننا نستفيد من "وحدة فك ترميز بكسل" (Pixel Decoder) خفيفة الوزن لتوليد تفاصيل عالية التردد مشروطة بالتوجيه الدلالي من محول الانتشار (DiT). وهذا بدوره يحرر محول الانتشار ليتخصص في نمذجة الدلالات الدلالية منخفضة التردد.بالإضافة إلى ذلك، نقدم "دالة خسارة لمطابقة التدفق واعية بالتردد" (Frequency-aware flow-matching loss) تركز على الترددات البارزة بصرياً مع تحييد/قمع الترددات غير المهمة. وتُظهر التجارب المكثفة أن نموذج "DeCo" يحقق أداءً متفوقاً بين نماذج انتشار البكسل، حيث سجل مؤشر مسافة فريد شيت (FID) قيم 1.62 (للدقة 256×256) و 2.22 (للدقة 512×512) على مجموعة بيانات ImageNet، مما يسد الفجوة مع طرق الانتشار الكامن. علاوة على ذلك، يحقق نموذجنا المدرب مسبقاً لتحويل النص إلى صورة درجة إجمالية رائدة تبلغ 0.86 على مقياس GenEval في المقارنة على مستوى النظام. الأكواد البرمجية متاحة للعامة على الرابط: https://github.com/Zehong-Ma/DeCo.
Summarization
Researchers from Peking University, Huawei Inc., and Nanjing University introduce DeCo, a frequency-decoupled pixel diffusion framework that closes the performance gap with latent diffusion methods by employing a lightweight decoder for high-frequency details and a frequency-aware flow-matching loss to enable efficient semantic modeling.
Introduction
High-fidelity image generation is currently dominated by diffusion models, typically categorized into latent diffusion (which compresses images via VAEs) and pixel diffusion (which models raw pixels directly). While pixel diffusion avoids the compression artifacts and training instability associated with VAEs, it faces a significant computational hurdle: jointly modeling complex high-frequency details and low-frequency semantics within a massive pixel space is inefficient and prone to noise interference.
Current pixel diffusion methods often rely on a single Diffusion Transformer (DiT) to handle all frequency components simultaneously. The authors identify that high-frequency noise in this setup distracts the model, preventing it from effectively learning low-frequency semantic structures and leading to degraded image quality.
To address this, the authors introduce DeCo, a frequency-decoupled framework that splits the generation process based on frequency components. By assigning semantic modeling to the DiT and detail reconstruction to a specialized decoder, the system optimizes both aspects independently.
Key innovations include:
- Decoupled Architecture: The model utilizes a DiT to capture low-frequency semantics from downsampled inputs, while a lightweight pixel decoder uses these semantic cues to reconstruct high-frequency details from high-resolution inputs.
- Frequency-Aware Loss: The authors implement a novel Flow-Matching loss inspired by JPEG compression, which uses Discrete Cosine Transform (DCT) and adaptive weighting to prioritize visually salient frequencies while suppressing imperceptible high-frequency noise.
- Enhanced Pixel Fidelity: By removing the reliance on VAE compression and specializing the model components, DeCo achieves superior FID scores on ImageNet, effectively closing the performance gap between pixel-space and latent-space diffusion models.
Method
The authors leverage a frequency-decoupled framework, DeCo, to improve pixel diffusion by separating the modeling of low-frequency semantics from high-frequency signal generation. The overall architecture, as illustrated in the framework diagram, consists of two primary components: a Diffusion Transformer (DiT) and a lightweight pixel decoder. The DiT operates on downsampled, small-scale inputs to model low-frequency semantics, while the pixel decoder generates high-frequency details conditioned on the semantic cues from the DiT. This decoupling allows the DiT to specialize in semantic modeling without being distracted by high-frequency noise, leading to more efficient training and improved visual fidelity.
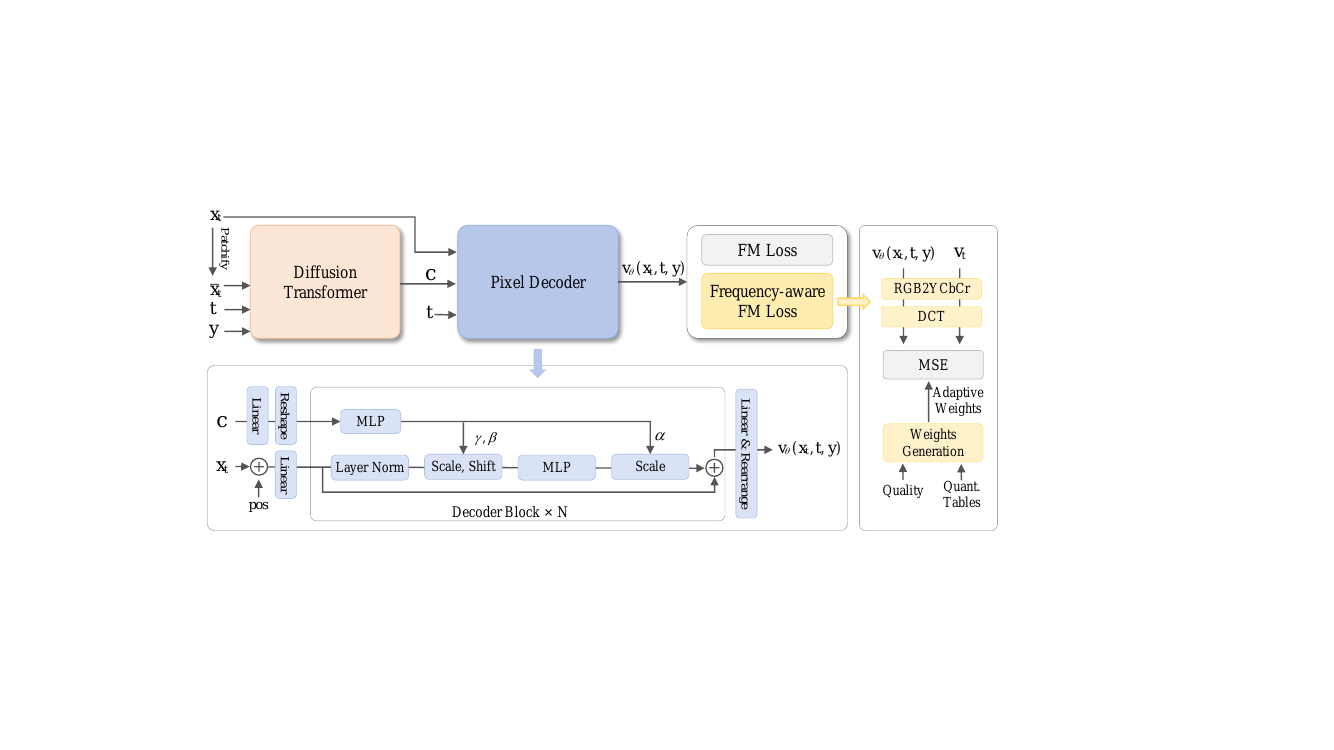
The pixel decoder is a lightweight, attention-free network composed of N linear decoder blocks and several linear projection layers. It directly processes the full-resolution noised image xt without downsampling. All operations are local and linear, enabling efficient high-frequency modeling. The dense query construction begins by concatenating the noised pixels with their corresponding positional embeddings pos and linearly projecting them with Win to form dense query vectors h0. For each decoder block, the DiT output c is linearly upsampled and reshaped to match the spatial resolution of xt, yielding cup. A multi-layer perceptron (MLP) generates modulation parameters α,β,γ for adaptive layer norm (AdaLN), which are used to modulate the dense decoder queries. The final output of the decoder is mapped to the pixel space via a linear projection and rearrangement operation to predict the pixel velocity vθ(xt,t,y).

To further emphasize visually salient frequencies and suppress insignificant high-frequency components, the authors introduce a frequency-aware flow-matching (FM) loss. This loss reweights different frequency components using adaptive weights derived from JPEG perceptual priors. The transformation from the spatial domain to the frequency domain is achieved by converting the color space to YCbCr and applying a block-wise 8×8 discrete cosine transform (DCT). The adaptive weights are generated from the normalized reciprocal of the scaled quantization tables Qcur, which are designed based on the human visual system's sensitivity to different frequencies. Frequencies with smaller quantization intervals are considered more perceptually important and are assigned higher weights. The frequency-aware FM loss is defined as the expectation of the weighted squared difference between the predicted and ground-truth frequency-domain velocities. The overall training objective combines the standard pixel-level flow-matching loss, the frequency-aware FM loss, and the REPA alignment loss.
Experiment
- DCT Energy Spectra Analysis: Validates that DeCo effectively decouples frequencies by maintaining high-frequency components in the pixel decoder while shifting them away from the DiT, which focuses on low-frequency semantics.
- Ablation Studies: Confirm the critical role of the multi-scale input strategy and AdaLN-based interaction, identifying optimal settings with a pixel decoder hidden size of 32, depth of 3, and patch size of 1.
- Class-to-Image Generation (ImageNet 256x256): The model achieves a leading FID of 1.62 and an inference latency of 1.05s, significantly surpassing RDM (38.4s) and PixelFlow (9.78s) in efficiency while matching two-stage latent diffusion models.
- Training Efficiency: DeCo demonstrates a 10x improvement in training efficiency, achieving an FID of 2.57 in just 80 epochs, which exceeds the baseline's performance at 800 epochs.
- Class-to-Image Generation (ImageNet 512x512): The method attains a superior FID of 2.22, delivering performance comparable to DiT-XL/2 and SiT-XL/2.
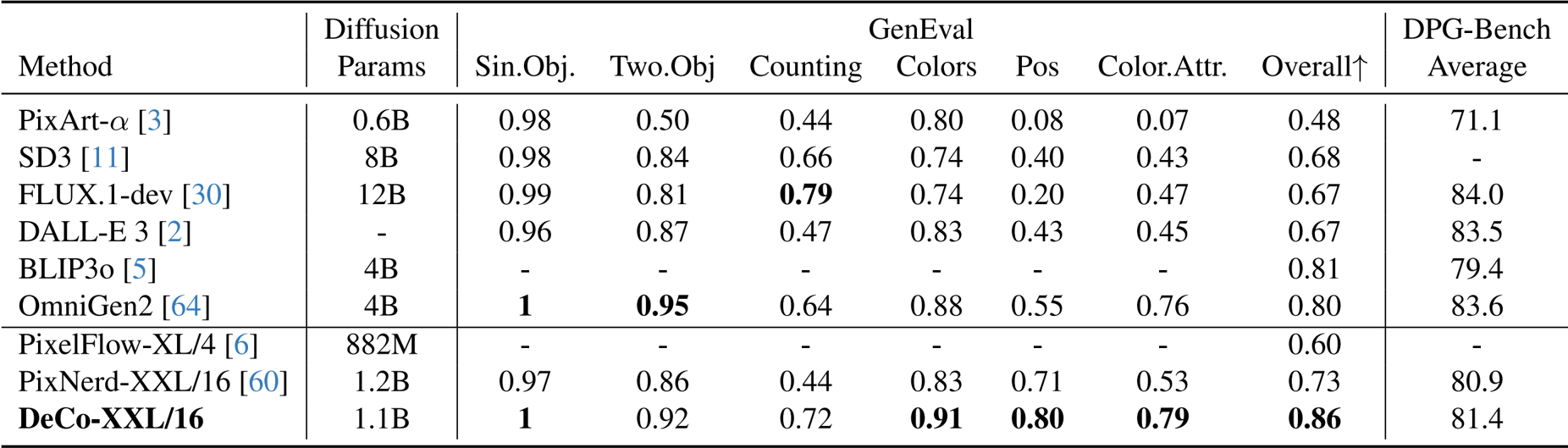
- Text-to-Image Generation: On the GenEval benchmark, DeCo achieves an overall score of 0.86, outperforming prominent models such as SD3, FLUX.1-dev, and BLIP3o, as well as pixel diffusion methods like PixNerd.
The authors use a baseline DiT model and compare it to their DeCo framework, which replaces the final two DiT blocks with a pixel decoder. Results show that DeCo achieves significantly better generation quality, reducing FID from 61.10 to 31.35 and increasing IS from 16.81 to 48.35, while maintaining comparable training and inference costs.
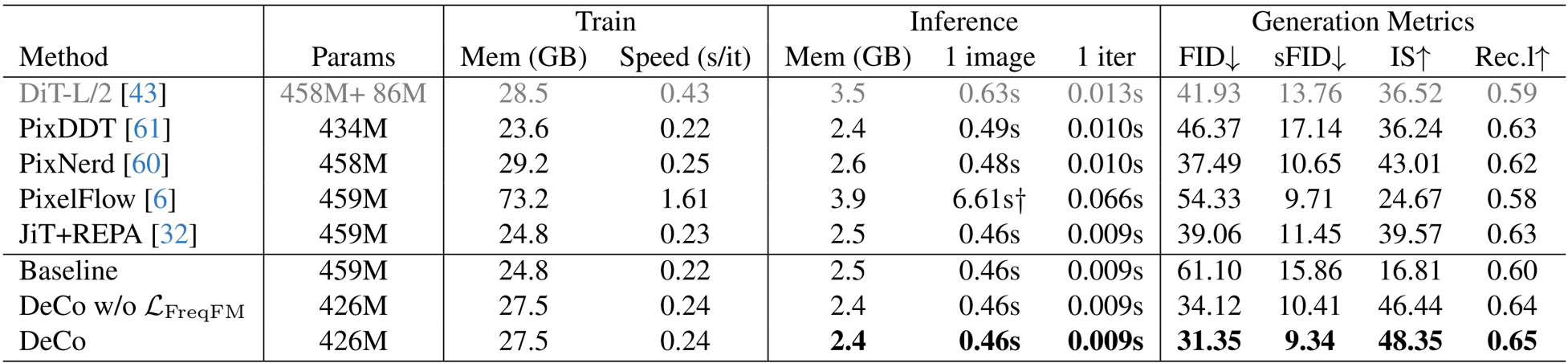
The authors use a multi-scale input strategy and AdaLN-based interaction to effectively decouple high-frequency signals from the DiT, allowing the pixel decoder to model fine details while the DiT focuses on low-frequency semantics. Results show that DeCo achieves superior performance on both class-to-image and text-to-image generation tasks, outperforming existing pixel diffusion models and achieving competitive results with two-stage latent diffusion methods.
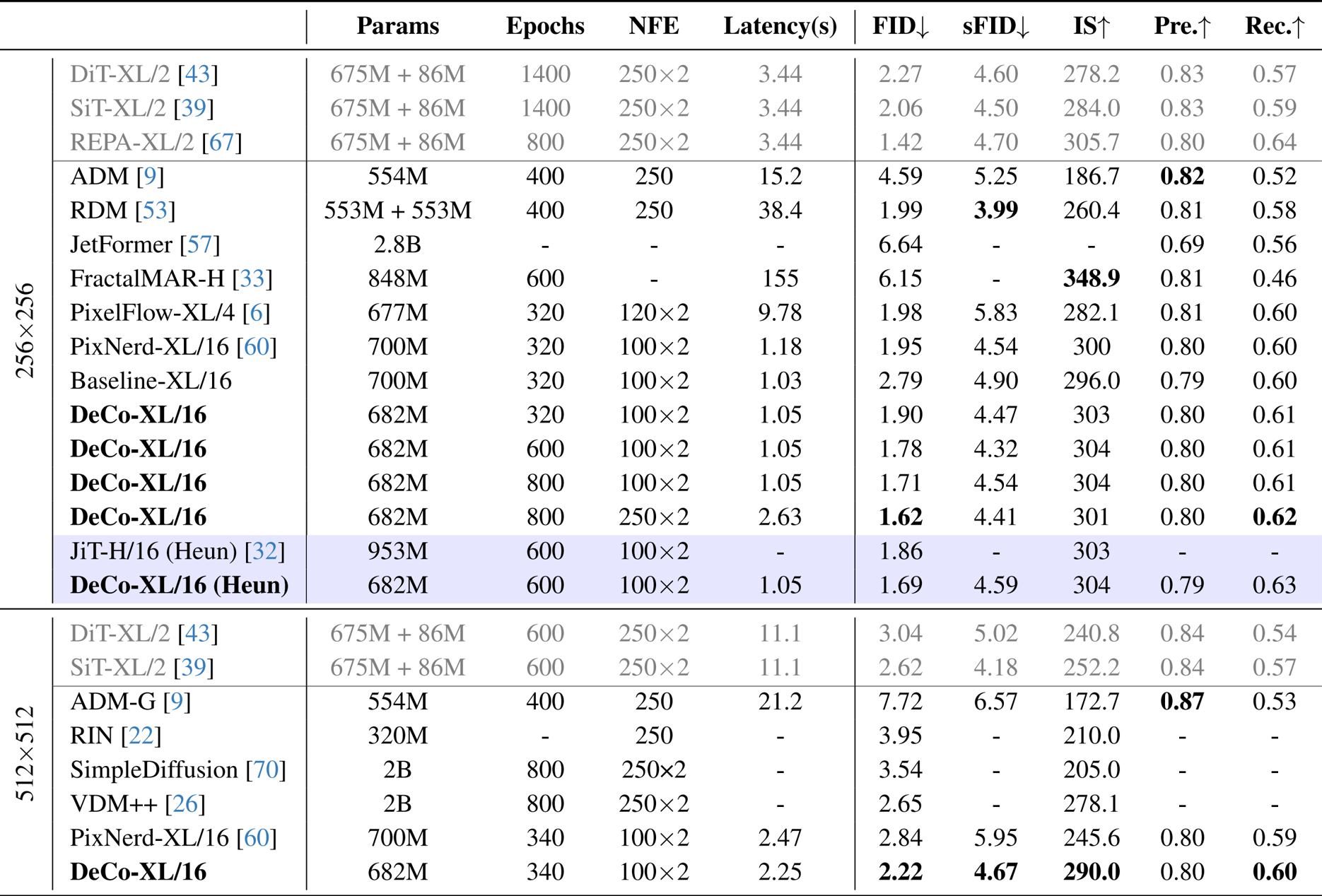
The authors use DeCo to achieve state-of-the-art performance in text-to-image generation, outperforming models like SD3 and FLUX.1-dev on the GenEval benchmark with an overall score of 0.86, while also achieving competitive results on DPG-Bench. DeCo surpasses other end-to-end pixel diffusion methods such as PixelFlow and PixNerd, demonstrating that pixel-based diffusion can match two-stage models in quality with lower computational costs.
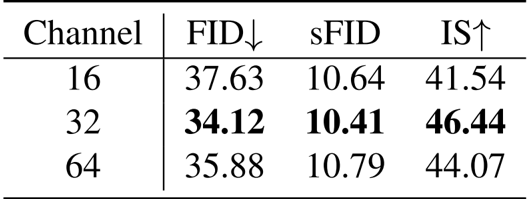
The authors analyze the impact of the pixel decoder's hidden size on performance, showing that a hidden size of 32 achieves the best results with an FID of 34.12, sFID of 10.41, and IS of 46.44. A smaller size of 16 leads to lower performance, while increasing to 64 provides no further improvement.
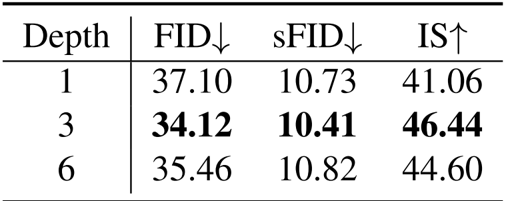
Results show that the pixel decoder depth of 3 achieves the best performance, with a FID of 34.12, sFID of 10.41, and IS of 46.44, outperforming both shallower and deeper configurations.