Command Palette
Search for a command to run...
فكّر بصريًا، وتفنّن نصيًا: التآزر بين الرؤية واللغة في ARC
فكّر بصريًا، وتفنّن نصيًا: التآزر بين الرؤية واللغة في ARC
Beichen Zhang Yuhang Zang Xiaoyi Dong Yuhang Cao Haodong Duan Dahua Lin Jiaqi Wang
الملخص
الاستنتاج المجرد من أمثلة قليلة لا يزال مشكلة أساسية غير محلولة بالنسبة للنماذج الأساسية المتقدمة مثل GPT-5 وGrok 4. إذ تفشل هذه النماذج حتى الآن في استخلاص قواعد تحويل منظمة من عدد ضئيل من الأمثلة، وهي صفة رئيسية تميز الذكاء البشري. يوفر مجموعة بيانات الاستنتاج والتفكير التجريدي للذكاء الاصطناعي العام (ARC-AGI) بيئة اختبار صارمة لتقييم هذه القدرة، حيث تتطلب الاستنتاج المفاهيمي للقواعد والانتقال إليها في مهام جديدة. ومعظم الطرق الحالية تتعامل مع ARC-AGI كمهمة استنتاج نصية فقط، مما يتجاهل حقيقة أن البشر يعتمدون بشكل كبير على الاستخلاص البصري عند حل هذه الألغاز. ومع ذلك، تكشف تجاربنا الأولية عن تناقض: فإن تمثيل شبكات ARC-AGI بشكل بصري بشكل مباشر يؤدي إلى تدهور الأداء بسبب تنفيذ غير دقيق للقواعد. وهذا يقود إلى فرضيتنا الأساسية التي تفيد بأن البصر واللغة يمتلكان قدرات مكملة عبر مراحل التفكير المختلفة: فالبصر يعزز الاستخلاص والتحقق من الأنماط الشاملة، بينما يبرز اللغة في صياغة القواعد الرمزية وتنفيذها بدقة. مستندين إلى هذه الرؤية، نقدم استراتيجيتين تكامليتين: (1) التفكير التكاملي بين البصر واللغة (VLSR)، الذي يحلل ARC-AGI إلى مهام فرعية متماشية مع الوسائط؛ و(2) التصحيح الذاتي التبديل بين الوسائط (MSSC)، الذي يستخدم البصر للتحقق من التفكير النصي لتصحيح الأخطاء الداخلية. تُظهر التجارب الواسعة أن نهجنا يحقق تحسناً يصل إلى 4.33% مقارنة بالأساليب النصية الوحيدة عبر نماذج رائدة متنوعة ومهام متعددة في ARC-AGI. تشير نتائجنا إلى أن دمج الاستخلاص البصري مع التفكير اللغوي يمثل خطوة حاسمة نحو تحقيق ذكاء عام قابل للتطبيق، يشبه الذكاء البشري، في النماذج الأساسية المستقبلية. سيتم إصدار الكود المصدري قريبًا.
Summarization
Researchers from The Chinese University of Hong Kong and Shanghai AI Laboratory introduce Vision-Language Synergy Reasoning (VLSR) and Modality-Switch Self-Correction (MSSC) to address the ARC-AGI benchmark, effectively combining visual global abstraction with linguistic symbolic execution to outperform text-only baselines in abstract reasoning tasks.
Introduction
The Abstraction and Reasoning Corpus (ARC-AGI) serves as a critical benchmark for Artificial General Intelligence, assessing a model's ability to "learn how to learn" by identifying abstract rules from minimal examples rather than relying on memorized domain knowledge. While humans naturally rely on visual intuition to solve these 2D grid puzzles, existing state-of-the-art approaches process these tasks purely as text-based nested lists. This text-centric paradigm overlooks vital spatial relationships such as symmetry and rotation, yet naive image-based methods also fail due to a lack of pixel-perfect precision. Consequently, models struggle to balance the global perception needed to understand the rule with the discrete accuracy required to execute it.
The authors propose a novel methodology that integrates visual and textual modalities based on their respective strengths. They decompose abstract reasoning into two distinct stages, utilizing visual inputs to summarize transformation rules and textual representations to apply those rules with element-wise exactness.
Key innovations and advantages include:
- Vision-Language Synergy Reasoning (VLSR): A framework that dynamically switches modalities, employing visual grids to extract global patterns and textual coordinates to execute precise manipulations.
- Modality-Switch Self-Correction (MSSC): A verification mechanism that converts text-generated solutions back into images, allowing the model to visually detect inconsistencies that are invisible in text format.
- Versatile Performance Gains: The approach functions as both an inference strategy and a training paradigm, delivering significant accuracy improvements across flagship models like GPT-4o and Gemini without requiring external ground truth.
Dataset
Based on the provided text, the authors employ a specific processing strategy to visualize data as follows:
- Matrix-to-Image Conversion: The authors convert input-output matrices into color-coded 2D grids to preserve 2D spatial information and offer a global view of the data.
- Color Mapping: Each numerical value is mapped to a specific color to create distinct visual elements:
- 0: Black
- 1: Blue
- 2: Red
- 3: Green
- 4: Yellow
- 5: Grey
- 6: Pink
- 7: Orange
- 8: Light blue
- 9: Brown
- Structural Formatting: White dividing lines are inserted between the colored elements (small squares) to clearly indicate specific numbers and define the structure within each block.
Method
The authors leverage a two-phase framework that strategically combines visual and textual modalities to address the challenges of reasoning over structured grid-based tasks in the ARC-AGI benchmark. This approach, termed Vision-Language Synergy Reasoning (VLSR), decomposes the task into two distinct subtasks: rule summarization and rule application, each optimized for the strengths of a specific modality. The overall framework is designed to overcome the limitations of purely textual approaches, which often fail to capture the inherent 2D structural information of the input matrices.
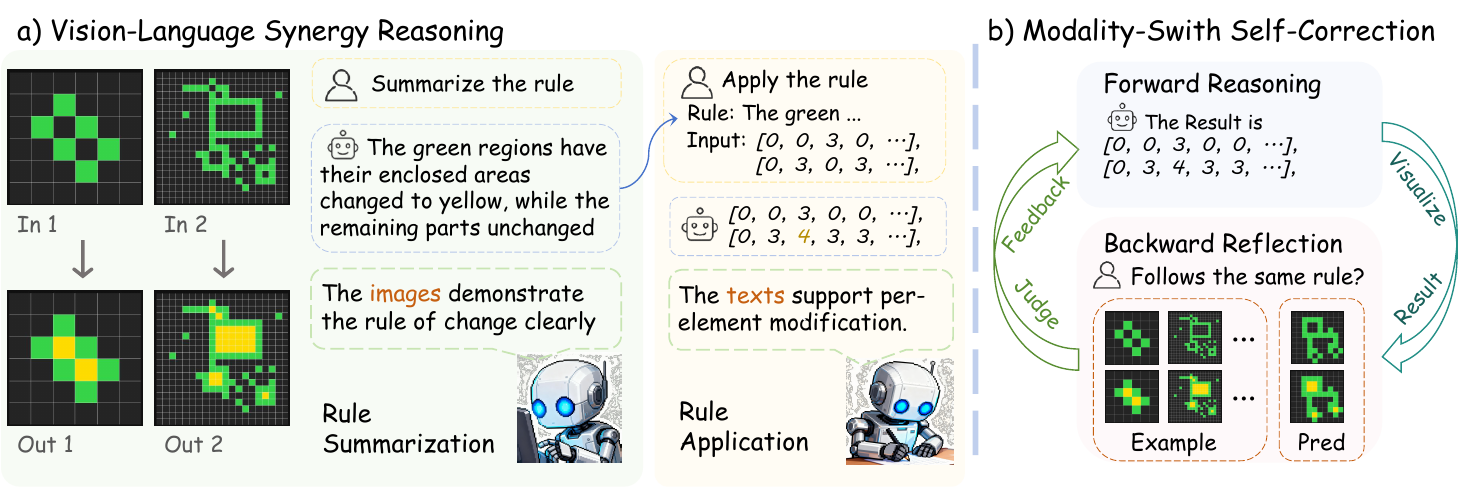 As shown in the figure below, the first phase, Vision-Language Synergy Reasoning, begins by converting all provided input-output example pairs into their visual representations. Each matrix m is transformed into an image i=V(m), where each cell value is mapped to a distinct color, creating a grid layout that preserves the spatial relationships between elements. This visual representation is then fed to a large vision-language model (LVLM) to perform rule summarization. The model analyzes the visual patterns across the examples to derive an explicit transformation rule, rpred, expressed in natural language. This phase leverages the model's ability to perform global pattern recognition and understand 2D structural relationships, which is crucial for identifying complex spatial transformations.
As shown in the figure below, the first phase, Vision-Language Synergy Reasoning, begins by converting all provided input-output example pairs into their visual representations. Each matrix m is transformed into an image i=V(m), where each cell value is mapped to a distinct color, creating a grid layout that preserves the spatial relationships between elements. This visual representation is then fed to a large vision-language model (LVLM) to perform rule summarization. The model analyzes the visual patterns across the examples to derive an explicit transformation rule, rpred, expressed in natural language. This phase leverages the model's ability to perform global pattern recognition and understand 2D structural relationships, which is crucial for identifying complex spatial transformations.
 The second phase, rule application, shifts to the textual modality. The derived rule rpred is used to guide the transformation of the test input. All matrices, including the test input and the examples, are converted into their textual representations t=T(m), which are nested lists of integers. The same LVLM, now operating in text mode with a rule application prompt, performs element-wise reasoning to generate the predicted output matrix tpred. This phase exploits the precision of textual representation for manipulating individual elements according to the summarized rule. The authors emphasize that the same base model is used for both phases, with the only difference being the input modality and the specific prompting strategy, ensuring a consistent reasoning process.
The second phase, rule application, shifts to the textual modality. The derived rule rpred is used to guide the transformation of the test input. All matrices, including the test input and the examples, are converted into their textual representations t=T(m), which are nested lists of integers. The same LVLM, now operating in text mode with a rule application prompt, performs element-wise reasoning to generate the predicted output matrix tpred. This phase exploits the precision of textual representation for manipulating individual elements according to the summarized rule. The authors emphasize that the same base model is used for both phases, with the only difference being the input modality and the specific prompting strategy, ensuring a consistent reasoning process.
To further enhance the reliability of the output, the authors introduce a Modality-Switch Self-Correction (MSSC) mechanism. This strategy addresses the challenge of intrinsic self-correction by using different modalities for reasoning and verification. After the initial textual rule application produces a candidate output tpred, the model first converts this textual output back into a visual representation ipred. This visualized output is then presented to the LVLM, which acts as a critic to assess the consistency of the predicted transformation with the provided examples. The model evaluates whether the test input-output pair (itestinput,ipred) follows the same pattern as the training examples. If the model determines the output is inconsistent, it receives feedback and performs an iterative refinement step, using the previous attempt's information to generate a new candidate output. This process repeats until the output is deemed consistent or a maximum number of iterations is reached. This modality switch provides a fresh perspective, breaking the model's confirmation bias and enabling it to identify errors that are imperceptible when using the same modality for both reasoning and verification.
Experiment
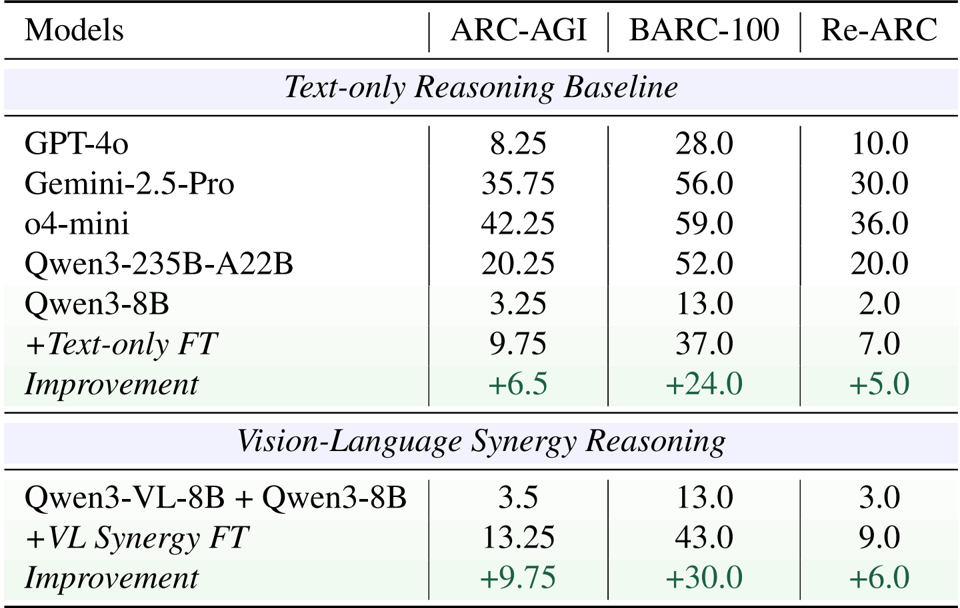
- Modality isolation experiments validated that visual representations excel at rule summarization (yielding a 3.2% average improvement), while textual representations are superior for rule application, where visual methods caused a 15.0% performance drop.
- The proposed VLSR and MSSC strategies consistently improved performance across ARC-AGI, Re-ARC, and BARC benchmarks, boosting baseline results by up to 6.25% for GPT-4o and 7.25% for Gemini-2.5-Pro on ARC-AGI.
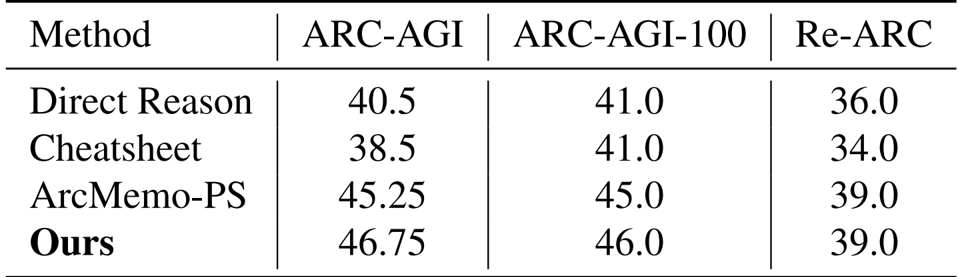
- In comparative evaluations using o4-mini, the method achieved the highest accuracy across all test sets, surpassing the strongest training-free baseline (ArcMemo-PS) by 1.5% on ARC-AGI.
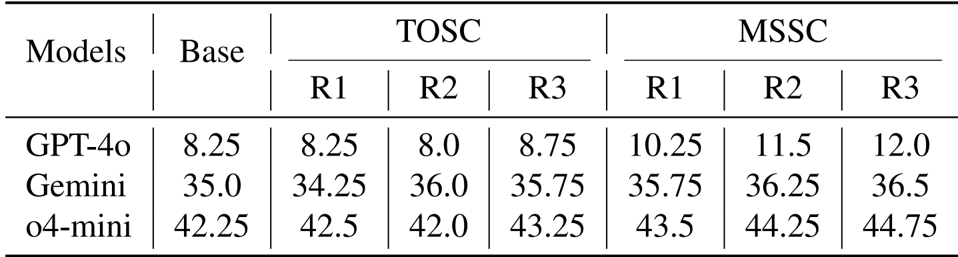
- Analysis of self-correction mechanisms showed that Modality-Switch Self-Correction (MSSC) achieved consistent monotonic gains (e.g., improving GPT-4o scores from 8.25 to 12.0), whereas text-only self-correction provided minimal or negative value.
- Fine-tuning experiments on ARC-Heavy-200k demonstrated that vision-language synergy achieved 13.25% accuracy on ARC-AGI, significantly outperforming text-centric fine-tuning (9.75%) and the closed-source GPT-4o baseline (8.25%).
Results show that using visual modality for rule summarization improves performance across all models, with GPT-4o increasing from 8.25 to 13.5, Gemini-2.5 from 35.0 to 38.75, and o4-mini from 42.25 to 45.5. However, applying rules using visual representations in the rule application phase leads to significant performance drops, with GPT-4o decreasing from 13.5 to 6.25, Gemini-2.5 from 38.75 to 23.75, and o4-mini from 45.5 to 25.0.
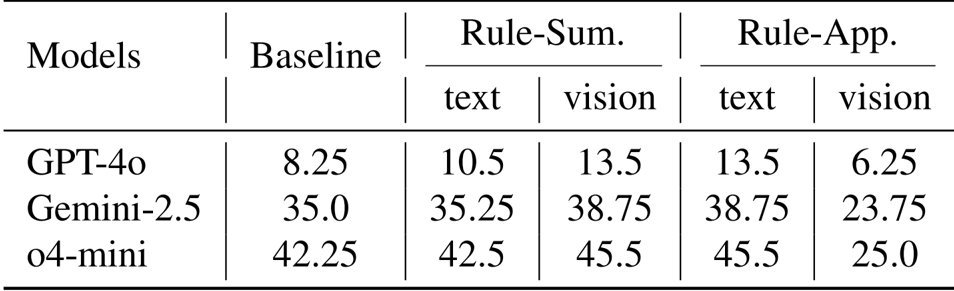
The authors use a modality-switching approach to improve abstract reasoning, where visual representations are used for rule summarization and textual representations for rule application. Results show that combining both methods consistently improves performance across all models and benchmarks, with the best results achieved when both VLSR and MSSC are applied.
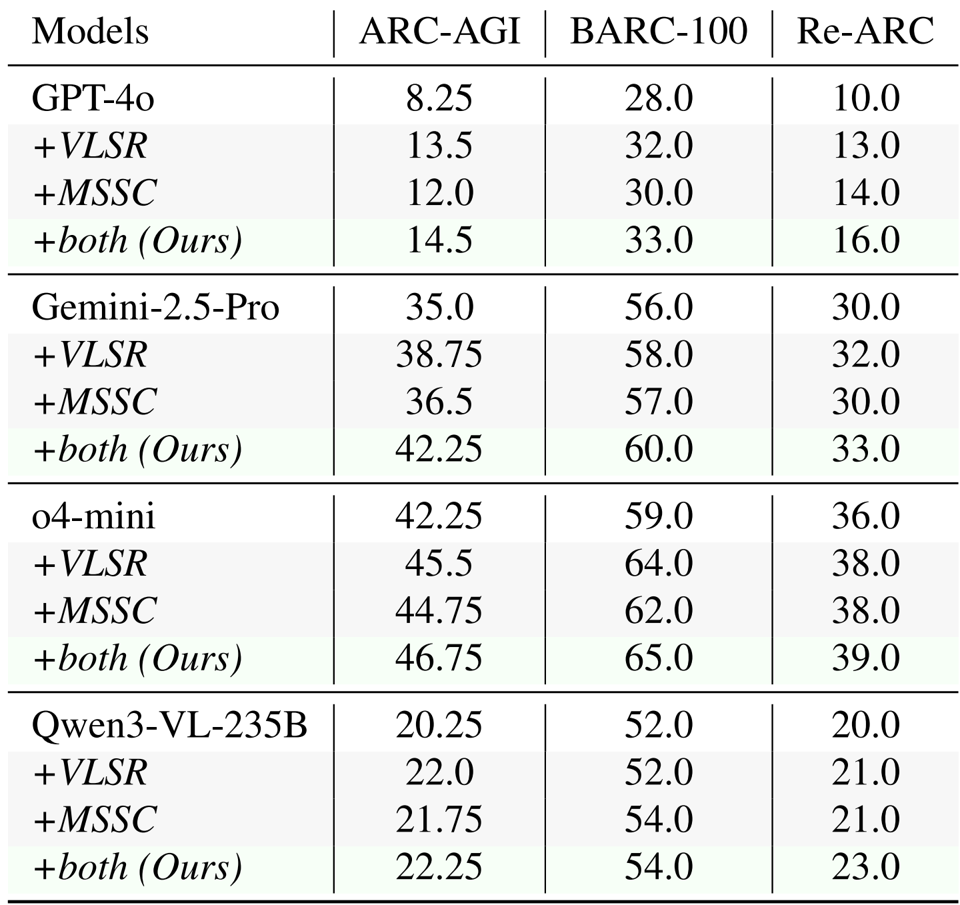
Results show that the proposed method achieves higher accuracy than baseline approaches across all benchmarks, with an improvement of 1.5% over the strongest baseline ArcMemo-PS on ARC-AGI. This demonstrates that visual information provides complementary benefits that text-based memory retrieval alone cannot capture.
Results show that Modality-Switch Self-Correction (MSSC) consistently improves performance over text-only self-correction (TOSC) across all models and iterations, with GPT-4o achieving a 3.75-point increase from Round 1 to Round 3, while TOSC shows minimal gains and even degrades in some rounds. The improvement is attributed to visual verification providing a fresh perspective that helps detect spatial inconsistencies missed during text-only reasoning.
The authors use a vision-language synergy approach to improve abstract reasoning, where visual representations are used for rule summarization and text for rule application. Results show that combining these modalities significantly boosts performance, with the vision-language synergy method achieving an average improvement of 9.75% on ARC-AGI compared to text-only fine-tuning.