Command Palette
Search for a command to run...
التقييم متعدد الوسائط للهياكل اللغوية الروسية
التقييم متعدد الوسائط للهياكل اللغوية الروسية
الملخص
تُعد نماذج اللغة الكبيرة متعددة الوسائط (MLLMs) حاليًا في صدارة اهتمامات البحث، حيث تُظهر تقدّمًا سريعًا في الحجم والقدرات، لكن فهم ذكاء هذه النماذج وقيودها ومخاطرها ما زال محدودًا. وللتصدي لهذه التحديات، خصوصًا في سياق اللغة الروسية التي لا توجد بها حاليًا معايير تقييم متعددة الوسائط، نقدّم "Mera Multi"، وهو إطار مفتوح لتقييم النماذج متعددة الوسائط مخصّص للهياكل المُصَمَّمة للغة الروسية. يعتمد هذا المعيار على التعليمات، ويشمل الوسائط الافتراضية النصية والصورة والصوت والفيديو، ويتضمّن 18 مهمة تقييم جديدة تم إنشاؤها من الصفر، مخصصة لكل من النماذج العامة والهياكل المُخصّصة لوسائط معيّنة (تحويل الصورة إلى نص، والفيديو إلى نص، والصوت إلى نص). تتمثل مساهماتنا في: (i) تصنيف عام لقدرات النماذج متعددة الوسائط؛ (ii) 18 مجموعة بيانات تم إنشاؤها من الصفر، مع مراعاة الخصوصية الثقافية واللغوية للغة الروسية، وبنية موحدة للأسئلة والمقاييس؛ (iii) نتائج أساسية لنموذج مغلق المصدر ونموذج مفتوح المصدر؛ (iv) منهجية لمنع تسرب المعايير، تشمل خاصية التشفير المائي (watermarking) وشروط ترخيص للمجموعات الخاصة. وعلى الرغم من تركيزنا الحالي على اللغة الروسية، فإن المعيار المقترح يوفّر منهجية قابلة للتكرار لإنشاء معايير متعددة الوسائط في لغات مختلفة من حيث البنية اللغوية، خاصة ضمن العائلة اللغوية السلافية.
Summarization
The MERA Team introduces MERA Multi, a comprehensive multimodal evaluation framework for Russian-language models that features a universal taxonomy and 18 original datasets across audio, video, and image modalities to enable culturally accurate and leakage-proof assessment of diverse architectures.
Introduction
The rapid evolution of generative AI models like GPT-5 and LLaVa has created a critical need for benchmarks that can rigorously evaluate capabilities across text, image, audio, and video. While English-centric evaluations are well-established, the field lacks comprehensive frameworks for assessing how these models handle the structural complexity and cultural nuances of Slavic languages. Prior work in multimodal benchmarking predominantly focuses on English or Chinese, while existing Russian-specific benchmarks are restricted exclusively to text-based tasks.
To bridge this gap, the authors introduce MERA Multi, the first multimodal benchmark designed specifically for evaluating Multimodal Large Language Models (MLLMs) in Russian. This framework assesses performance across 18 tasks spanning four modalities and serves as a scalable blueprint for developing culturally aware evaluations for other morphologically rich languages.
Key innovations include:
- Unified Taxonomy: The authors propose a standardized methodology and taxonomy for assessing MLLMs across text, image, audio, and video modalities.
- Cultural Specificity: The benchmark incorporates 18 novel datasets that capture Russian cultural contexts, such as folklore and media, alongside linguistic nuances often missed by direct translation.
- Evaluation Integrity: The study establishes a data leakage analysis and watermarking strategy to protect private evaluation datasets, ensuring valid baselines for both open-source and closed-source models.
Dataset
Dataset Composition and Sources
The authors introduce MERA Multi, a benchmark designed to evaluate Russian Multimodal Large Language Models (MLLMs). The dataset is structured around three core competencies: perception, knowledge, and reasoning. It comprises the following elements:
- Modalities: The benchmark spans four modalities, including text, image (11 datasets), audio (4 datasets), and video (3 datasets).
- Source Mix: To balance reproducibility with novelty, the authors utilize a mix of 7 publicly available datasets curated from open sources and 11 private datasets collected specifically for this study.
- Task Formats: Tasks are presented as either multiple-choice questions or open-ended questions requiring short free-form answers.
Key Subsets and Details
The benchmark is divided into specific subsets based on modality and task type:
-
Audio Datasets:
- AQUARIA: A private dataset with 9 task types (e.g., emotion recognition, sound QA) featuring studio-recorded scenarios and generative music.
- ruEnvAQA: Based on English datasets Clotho-AQA and MUSIC-AVQA, this subset focuses on non-verbal signals and music, with questions translated into Russian.
- ruSLUn: A Spoken Language Understanding dataset adapted from xSID, featuring audio recorded by non-professional speakers to capture natural background noise.
- ruTiE-Audio: A Turing test emulation consisting of coherent dialogues requiring context retention up to 500 turns.
-
Video Datasets:
- CommonVideoQA: Sourced from public repositories like EPIC-KITCHENS and Kinetics, focusing on general video comprehension without audio requirements.
- RealVideoQA: A closed dataset collected via crowdsourcing (Telegram), ensuring videos are not publicly available.
- ruHHH-Video: The first Russian-specific dataset designed to evaluate ethical reasoning in video contexts.
-
Image and VQA Datasets:
- ruCommonVQA: Combines images from COCO and VQA v2 with crowdsourced unique photos to test fine-grained perception.
- ruCLEVR: A visual reasoning dataset featuring synthetic 3D objects generated via Blender, adapted from the CLEVR methodology.
- RealVQA: A crowdsourced dataset containing "trick" questions (distractors) where the answer cannot be derived from the image, testing hallucination resistance.
- LabTabVQA: Consists of anonymized medical table screenshots and photos from a telemedicine platform, annotated using GPT-4o Mini and experts.
- Scientific VQA: Includes ruMathVQA (school math), ruNaturalScienceVQA (adapted from ScienceQA), SchoolScienceVQA (expert-created reasoning tasks), and UniScienceVQA (university-level expert knowledge).
- ruHHH-Image: An ethical evaluation dataset based on the HHH (Honest, Helpful, Harmless) framework, expanded with categories for empathy and etiquette.
- WEIRD: Focuses on commonsense violations, extending the WHOOPS! benchmark with synthetically generated images and descriptions.
Data Usage and Model Training
The authors utilize the data for both benchmarking and training specific evaluation models:
- Evaluation Taxonomy: Tasks are mapped to a skill taxonomy covering perception (e.g., OCR, object localization), knowledge (common and domain-specific), and reasoning (inductive, deductive, math).
- Judge Model Training: A separate dataset was constructed to train a "Judge" model. This comprises triplets of (question, gold answer, model prediction) sourced from Russian benchmarks.
- Splitting Strategy: To prevent bias, data for the Judge model is split by source dataset, ensuring that no dataset appears in both training and testing splits.
- Quality Control: Only items with 100% inter-annotator agreement regarding semantic correctness were used for the Judge model training.
Processing and Metadata
The authors implemented several processing strategies to ensure data integrity and standardized evaluation:
- Watermarking: To detect data leakage, the authors embed imperceptible watermarks. They use AudioSeal for audio and visual overlays for images and video frames.
- Prompt Engineering: The evaluation uses a structured prompt system with 13 fixed blocks (e.g., attention hooks, reasoning formats). Variable blocks are used for task-specific descriptions.
- Human Baselines: Human performance was established using crowd annotators (via the ABC Elementary platform) and domain experts for specialized tasks.
- Leakage Prevention: Private datasets are protected under a custom license that permits research use but strictly prohibits inclusion in model training sets.
Method
The MERA Multi benchmark employs a comprehensive evaluation framework designed to assess multimodal large language models (MLLMs) across reasoning, perception, and knowledge capabilities in the Russian language context. The overall architecture integrates four key components: a block-prompting structure, a compound scoring system, an evaluation pipeline with dual-level metrics, and a data leakage detection methodology. Refer to the framework diagram 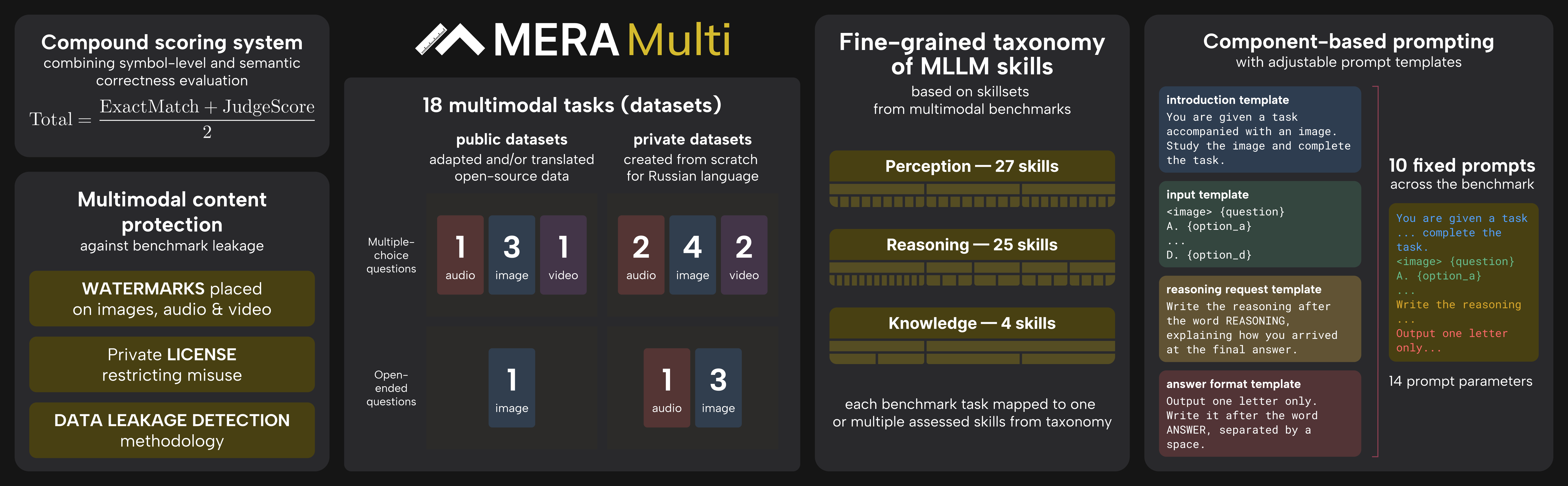 for a visual overview of the system.
for a visual overview of the system.
The evaluation begins with a standardized prompt design that ensures consistency and diversity across tasks. The authors leverage a block-prompting scheme, where each task is instantiated using a predefined set of 10 prompts derived from fixed block layouts. These blocks include structured templates such as an introduction, input, reasoning request, and answer format, enabling a uniform yet flexible task formulation. This approach avoids hard-coding task-specific prompts and allows for controlled variation, such as the inclusion or exclusion of reasoning requests, to mitigate benchmark saturation. The prompt templates are designed to be modality-agnostic, supporting image, audio, and video inputs, and are applied uniformly across dataset samples to average performance over prompt variants and reduce bias.
Central to the evaluation is a compound scoring system that combines symbolic and semantic correctness. The total score for each task is computed as the average of an exact match metric and a judge score, where the judge score is derived from a learned LLM-as-a-judge model. This model is trained on a diverse, human-annotated dataset of model outputs and is based on the RuModernBERT encoder. It frames evaluation as a binary classification task—determining the semantic equivalence of a model's prediction relative to the ground truth—conditioned on the input question. The judge model achieves high reliability, with an F1 score of 0.96 on a held-out test set and 99.6% agreement with exact match on identical answers.
The evaluation pipeline computes three primary metrics: Attempted Score, Coverage, and Total Score. The Attempted Score measures the quality of performance on the tasks a model actually attempts, normalized by the number of tasks attempted per modality. Coverage quantifies the breadth of evaluation as the fraction of the benchmark attempted across all modalities. The Total Score is the product of Attempted Score and Coverage, enabling a fair, single leaderboard that separates quality from breadth and remains stable under task growth. This design ensures that models are not penalized for missing tasks and allows for both joint and modality-specific rankings.
Finally, the framework incorporates a data leakage detection methodology to protect benchmark integrity. This involves generating perturbed text neighbors for each data point using techniques such as masking, deletion, duplication, and swapping, while keeping the modality data unchanged. Text embeddings are extracted using a fixed encoder, and multimodal losses are computed for both the target model and a reference model. A binary classifier, the MSMIA detector, is trained to distinguish between models that have seen the data and those that have not, based on feature differences in loss and embedding space. This component ensures robustness against overfitting and maintains the validity of the evaluation.
Experiment
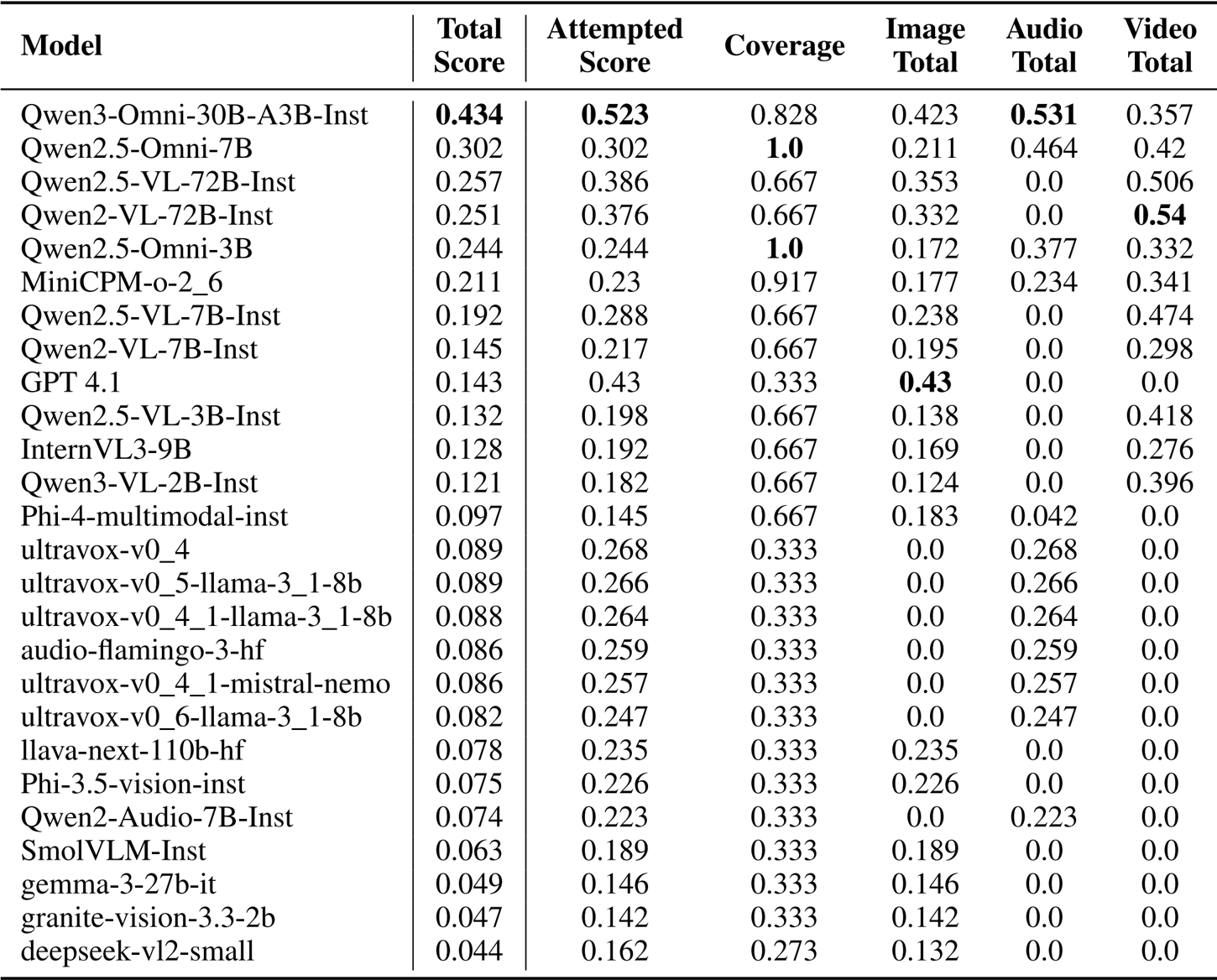
- Evaluation of over 50 multimodal models (1B to 110B parameters) on the MERA Multi benchmark validated performance across image, audio, and video modalities using Exact Match (EM) and Judge Score (JS).
- Qwen3-Omni-30B-A3B-Instruct achieved the highest Total Score of 0.434, driven by broad modality coverage and strong capabilities across all inputs.
- In specific modalities, GPT 4.1 led image evaluation with a score of 0.43, while Qwen2-VL-72B-Instruct achieved the best Video Total Score (0.54) and Qwen2.5-Omni-7B led the audio section (0.464).
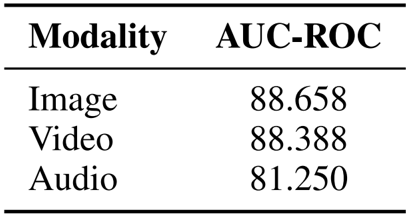
- Data leakage detection experiments using the Multimodal Semantic Membership Inference Attack (MSMIA) yielded high AUC-ROC scores, effectively identifying models trained on test data with low false-positive rates.
- Judge model selection experiments compared fine-tuned encoders against zero-shot decoders, with the encoder-based RuModernBERT-base achieving an F1 score of 0.964 and proving superior for binary classification.
- Statistical analysis of prompt formulations indicated that no single prompt dominates across all datasets, with metric sensitivity varying significantly by task (shifts of 0.1 to 0.2).
The authors use a multimodal evaluation framework that combines exact match and judge score metrics to assess model performance across image, audio, and video tasks. Results show that omni-models achieve higher total scores due to broader coverage, with Qwen3-Omni-30B-A3B-Instruct leading the leaderboard with a total score of 0.434, driven by strong performance in image, audio, and video modalities.
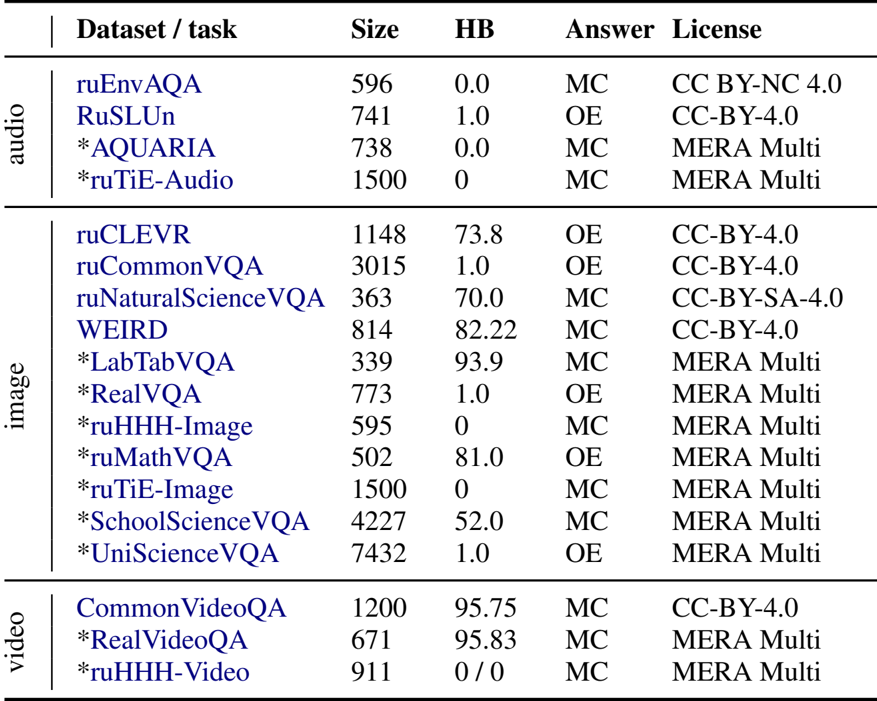
The authors use a confidence interval analysis to assess the statistical significance of model performance differences across modalities. For the image modality, models like Qwen2-VL-7B-Instruct and llava-1.5-13b-hf show wide confidence intervals, indicating high variability in performance. In the video modality, LLaVA-NeXT-Video-DPO has a notably high lower bound, suggesting strong performance, while Qwen2-VL-7B-Instruct shows a very narrow interval, indicating consistent results. For audio, ultravox-v0_2 and ultravox-v0_4 have wide intervals, reflecting uncertainty, whereas Qwen2-Audio-7B-Instruct and MiniCPM-o-2_6 have zero intervals, indicating no observed variation in their performance.
The authors use a Multimodal Semantic Membership Inference Attack (MSMIA) to detect data leakage in multimodal models, evaluating its performance across image, video, and audio modalities. Results show that the method achieves high AUC-ROC scores, indicating strong capability in distinguishing whether a model has been trained on specific multimodal data samples, with the highest performance observed in image and video modalities.
The authors use a multimodal evaluation framework to assess over 50 models across image, audio, and video modalities, with scores derived from Exact Match and Judge Score metrics. Results show that Qwen3-Omni-30B-A3B-Instruct leads with a Total Score of 0.434, driven by high Attempted Score and broad Coverage, while models with higher Coverage and strong performance in multiple modalities generally achieve higher Total Scores.