Command Palette
Search for a command to run...
BAPO: تثبيت التعلم التعزيزي خارج النمط لنموذجات اللغة الكبيرة من خلال تحسين السياسة المتوازنة مع قص تكيفي
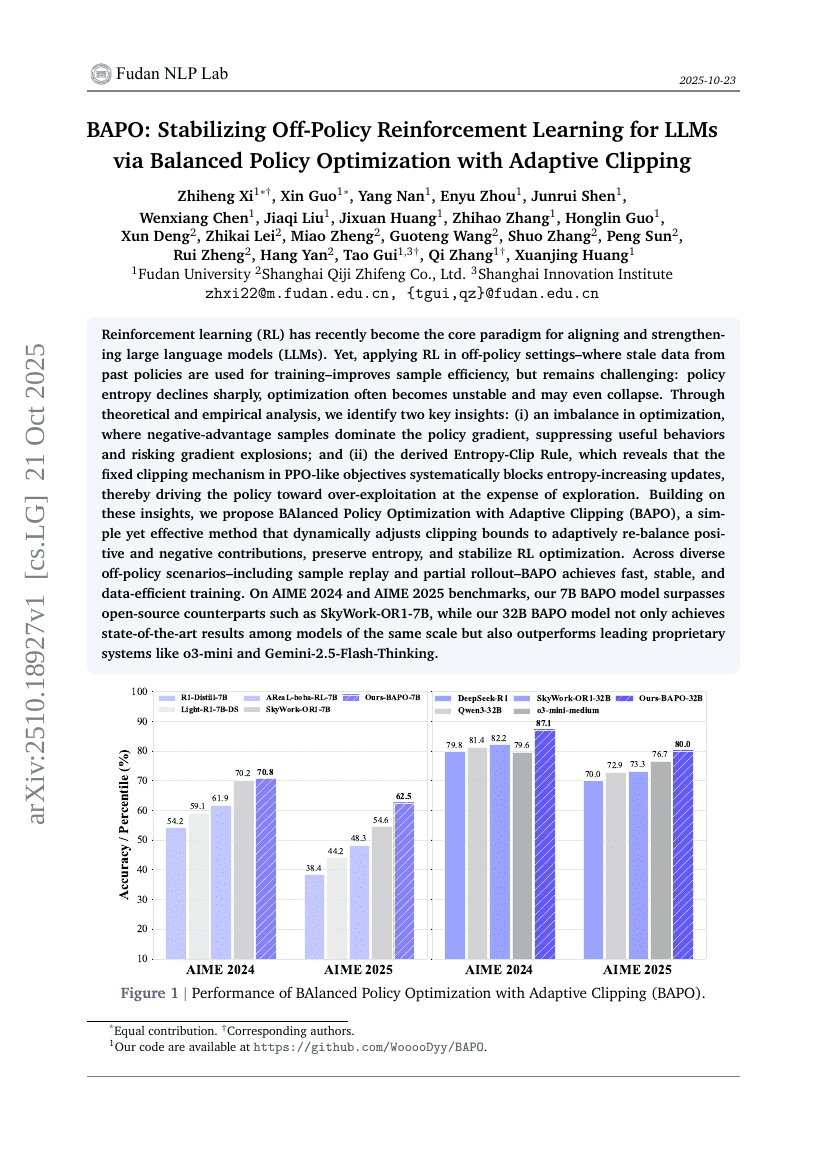
الملخص
لقد أصبح التعلم بالتعزيز (RL) في الآونة الأخيرة النموذج المحوري لتوحيد وتعزيز النماذج اللغوية الكبيرة (LLMs). ومع ذلك، يظل تطبيق التعلم بالتعزيز في السياقات غير المُتَبَعَة (off-policy)، حيث تُستخدم بيانات قديمة مُستمدة من سياسات سابقة لتدريب النموذج، مُحَدِّدًا لتحسين كفاءة الاستخدام، لكنه يظل يُعاني من صعوبات: إذ تنخفض الانتروبيا الخاصة بالسياسة بشكل حاد، وغالبًا ما تصبح عملية التحسين غير مستقرة، بل قد تنهار بالكامل. من خلال تحليل نظري وتجريبي، نُحدِّد رأيين رئيسيين: (أ) وجود عدم توازن في عملية التحسين، حيث تُهيمن عينات الميزة السلبية على متجه التحسين، مما يُكَبِّد السلوكيات المفيدة ويُعرِّض النموذج لانفجارات في المتجهات؛ و(ب) قاعدة التقييد بالانتروبيا (Entropy-Clip Rule) الناتجة، التي تُبيِّن أن آلية التقييد الثابتة في الأهداف المماثلة لـ PPO تُعَرِّض بشكل منهجي التحديثات التي تزيد الانتروبيا، ما يؤدي إلى تفضيل الاستغلال المفرط على حساب التوسع والاستكشاف. بناءً على هذه الرؤى، نُقدِّم طريقة BAlanced Policy Optimization with Adaptive Clipping (BAPO)، وهي طريقة بسيطة وفعّالة تُعدِّل حدود التقييد ديناميكيًا لاستعادة التوازن التلقائي بين المساهمات الموجبة والسلبية، وتحافظ على الانتروبيا، وتحسّن استقرار عملية تحسين التعلم بالتعزيز. وتمثّل BAPO أداءً سريعًا ومستقرًا وكفؤًا من حيث استخدام البيانات في سيناريوهات غير مُتَبَعَة متنوعة، بما في ذلك إعادة تجربة العينات (sample replay) والانطلاق الجزئي (partial rollout). على معايير AIME 2024 وAIME 2025، تفوق نموذج BAPO بسعة 7 بِلْيُون (7B) نماذج مفتوحة المصدر مثل SkyWork-OR1-7B، في حين أن نموذج BAPO بسعة 32 بِلْيُون (32B) لم يحقق أداءً مُتَقَدِّمًا في فئة النماذج ذات الحجم نفسه فحسب، بل تفوق أيضًا على الأنظمة المُرَتَّبة القيمة البارزة مثل o3-mini وGemini-2.5-Flash-Thinking.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — عجّل تطوير الذكاء الاصطناعي الخاص بك من خلال البرمجة المشتركة المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.