Command Palette
Search for a command to run...
نموذج تجريبي لتوليد الفيديو Pusa-VidGen
التاريخ
رابط الورقة البحثية
الترخيص
Apache 2.0
GitHub
1. مقدمة البرنامج التعليمي

يُعدّ Pusa V1، الذي اقترحه فريق ياوفانغ-ليو في 25 يوليو 2025، نموذجًا عالي الكفاءة لتوليد الفيديو متعدد الوسائط. يعتمد هذا النموذج على تقنية التكيف الزمني المتجهي (VTA)، ويعالج المشكلات الأساسية المتمثلة في ارتفاع تكلفة التدريب، وانخفاض كفاءة الاستدلال، وضعف التناسق الزمني في نماذج توليد الفيديو التقليدية. على عكس الطرق التقليدية التي تعتمد على كميات هائلة من البيانات وقوة الحوسبة، يحقق Pusa V1 تحسينات جذرية بالاعتماد على Wan2.1-T2V-14B من خلال استراتيجية ضبط دقيق وبسيطة: إذ تبلغ تكلفة تدريبه 500 دولار فقط (1/200 من تكلفة النماذج المماثلة)، ولا تتطلب مجموعة البيانات سوى 4K عينة (1/2500 من مجموعة البيانات في النماذج المماثلة)، ويمكن إتمام التدريب على ثماني وحدات معالجة رسومية (GPU) بسعة 80 جيجابايت، مما يُخفّض بشكل كبير عتبة تطبيق تقنية توليد الفيديو. في الوقت نفسه، يتمتع هذا النظام بقدرات فائقة على تعدد المهام، فهو لا يدعم فقط الفيديو المُعتمد على النصوص (T2V) والفيديو المُعتمد على الصور (I2V)، بل يدعم أيضًا مهامًا لا تتطلب تدريبًا مسبقًا، مثل إكمال الفيديو، وتوليد الإطارين الأول والأخير، والانتقالات بين المشاهد، دون الحاجة إلى تدريب إضافي لمشاهد محددة. والأهم من ذلك، أن أداء توليد الصور فيه متميز للغاية. فباستخدام استراتيجية استدلال قصيرة الخطوات (متجاوزًا النموذج الأساسي في 10 خطوات فقط)، حقق النظام مجموع نقاط 87.32% على منصة VBench-I2V، مما يدل على أداء ممتاز في إعادة إنتاج التفاصيل الديناميكية (مثل حركات الأطراف وتغيرات الإضاءة) والتماسك الزمني. علاوة على ذلك، تعمل آلية التكيف غير المدمرة، المُطبقة من خلال تقنية VTA، على إدخال قدرات ديناميكية زمنية في النموذج الأساسي مع الحفاظ على جودة توليد الصور الأصلية، مما يحقق تأثيرًا مضاعفًا. على مستوى التطبيق، يلبي زمن الاستجابة المنخفض للاستدلال احتياجات متنوعة، بدءًا من المعاينة السريعة وصولًا إلى الإخراج عالي الدقة، مما يجعله مناسبًا للتصميم الإبداعي وإنتاج مقاطع الفيديو القصيرة وغيرها من السيناريوهات. نتائج الأبحاث ذات الصلة هي... PUSA V1.0: تجاوز Wan-I2V بتكلفة تدريب $500 من خلال التكيف الزمني المتجهي .
يستخدم هذا البرنامج التعليمي موارد RTX A6000 ثنائية البطاقة.
2. أمثلة المشاريع
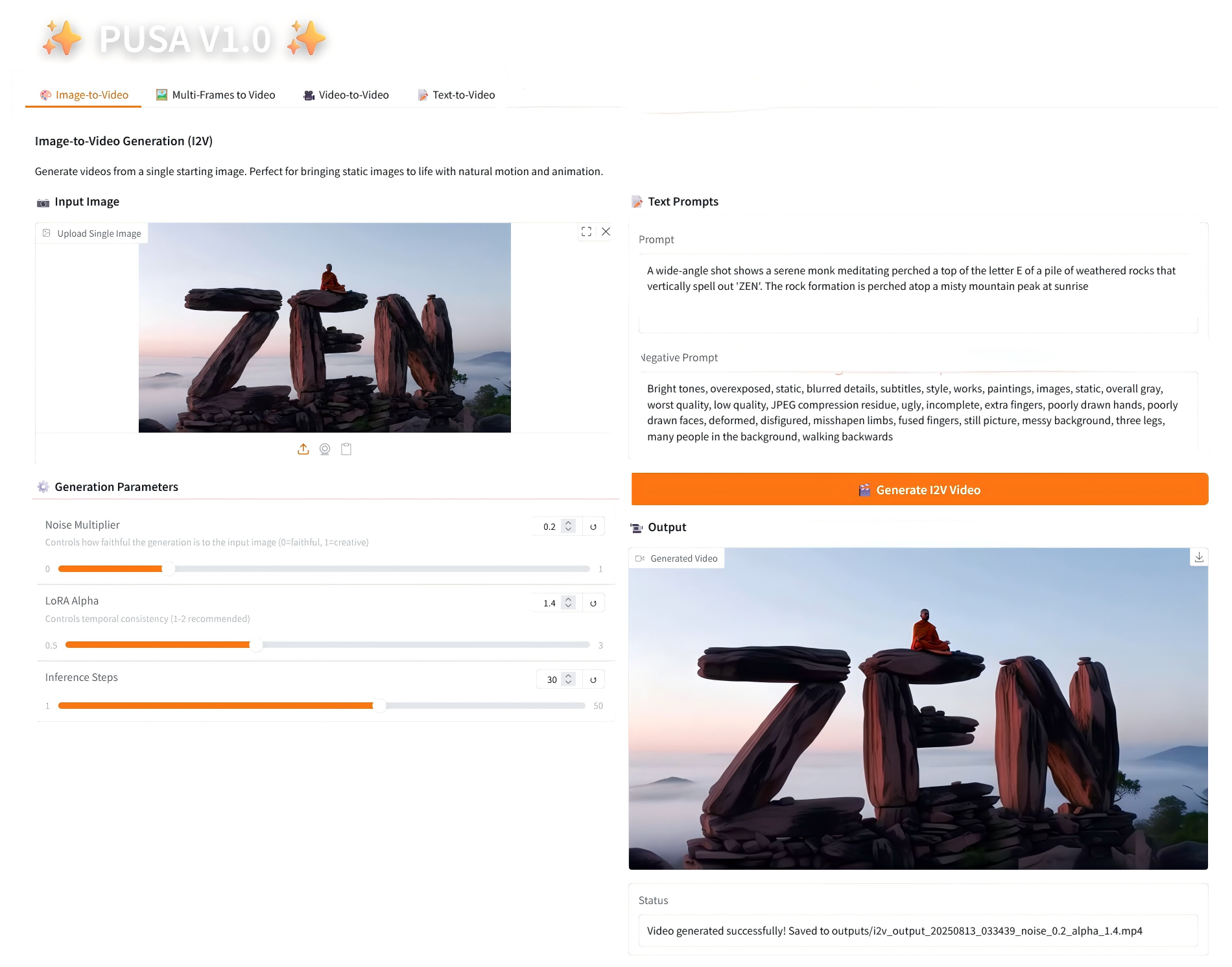
1. تحويل الصورة إلى فيديو
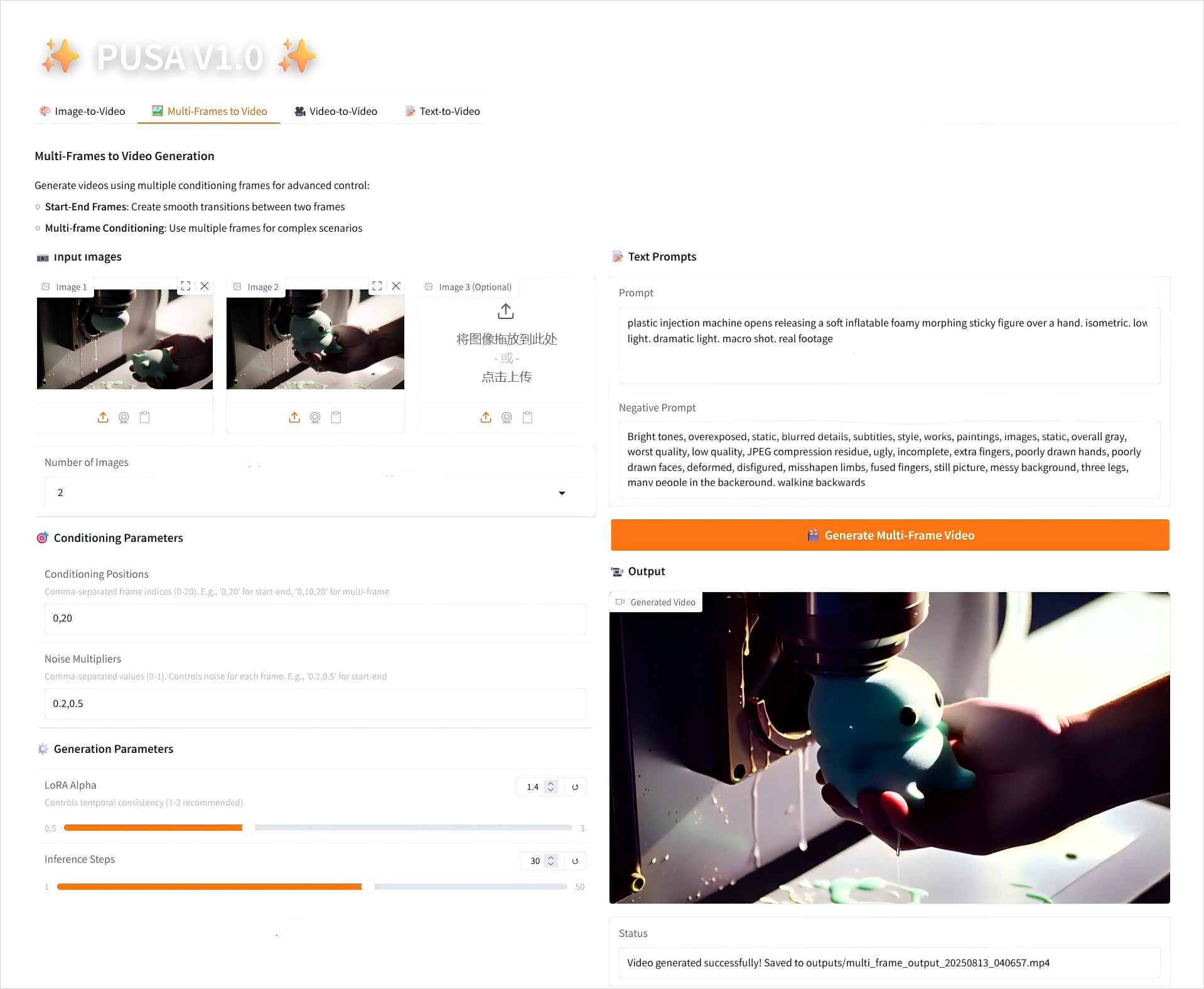
2. تحويل الإطارات المتعددة إلى فيديو
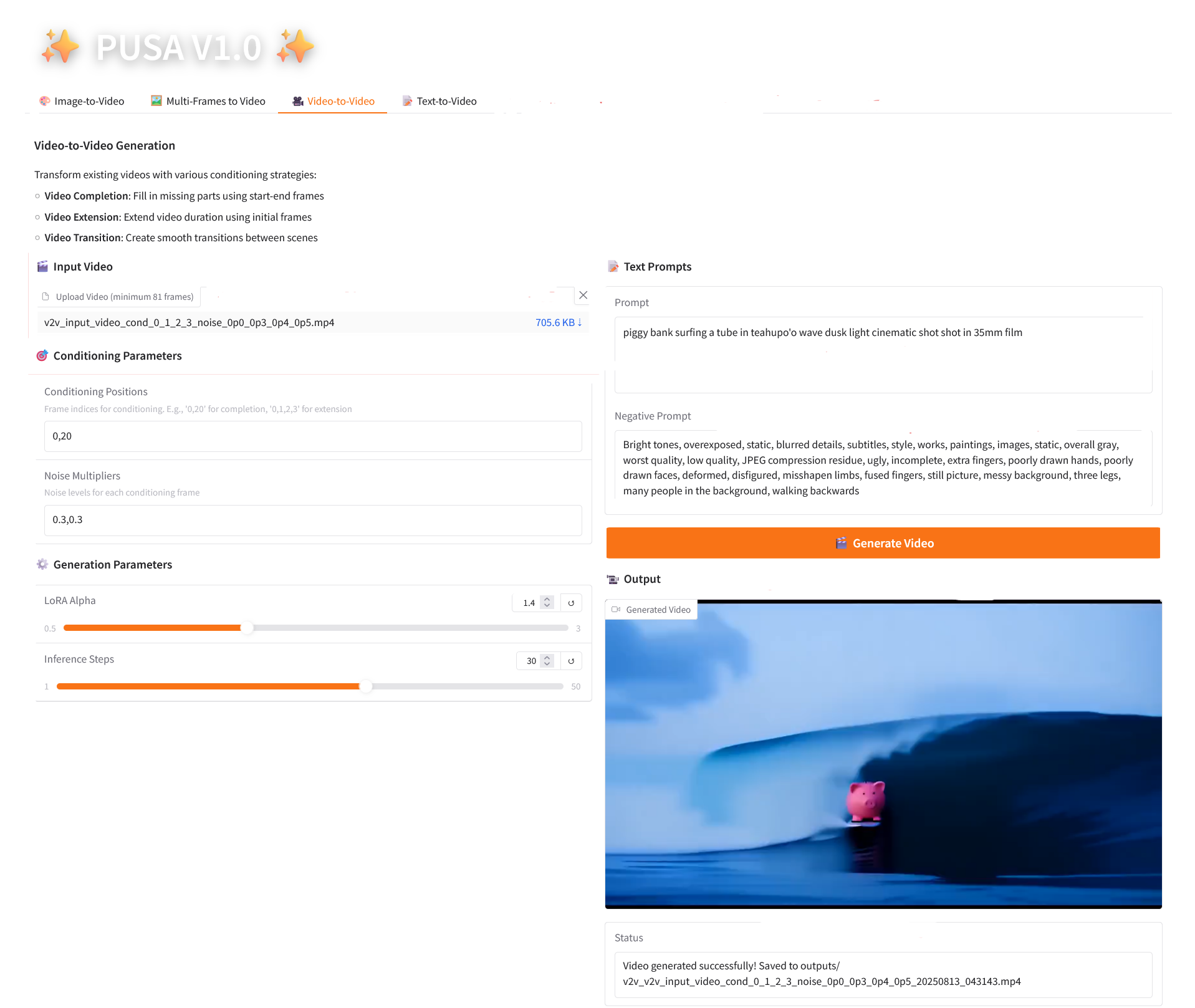
3. فيديو إلى فيديو
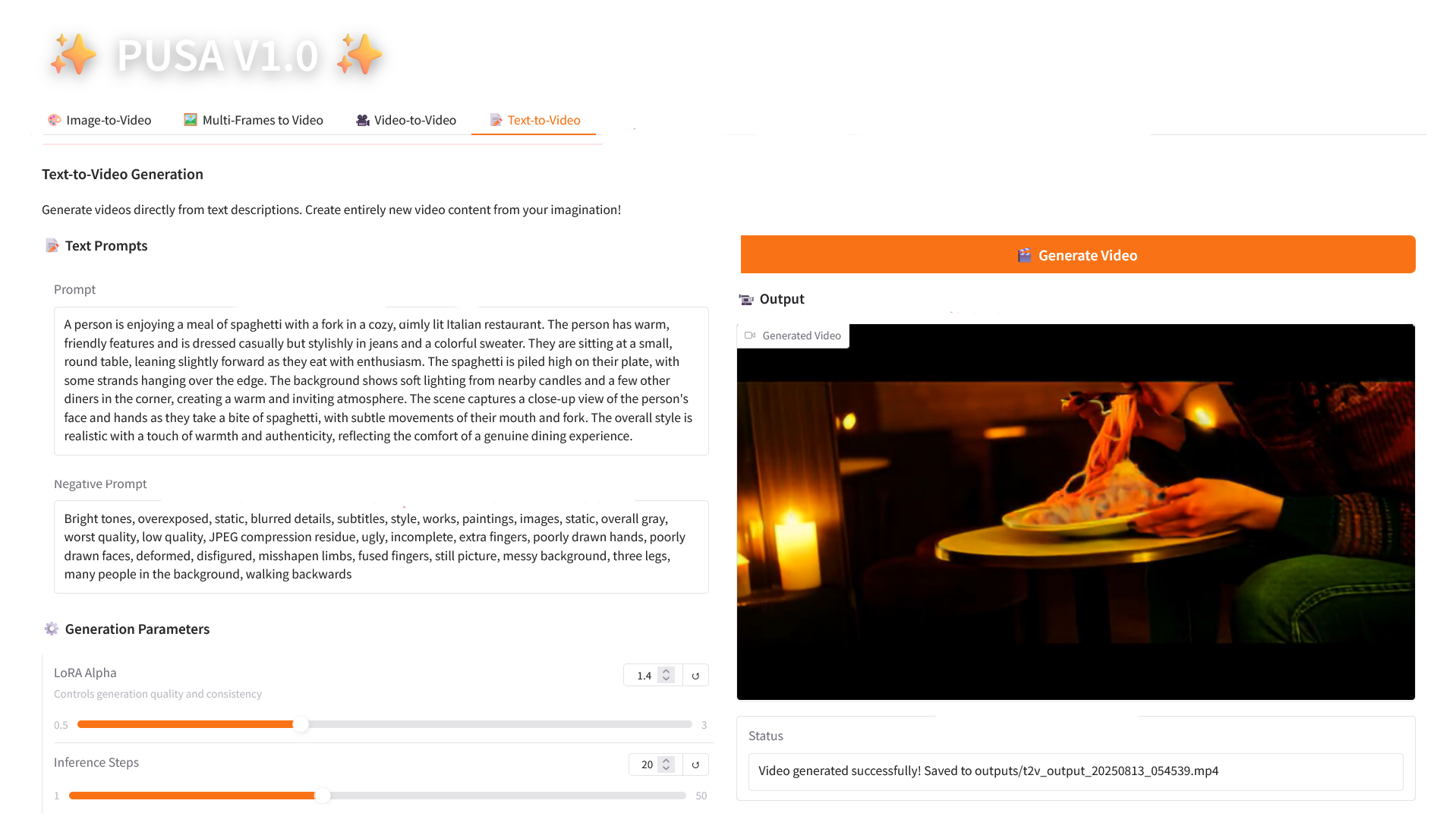
4. تحويل النص إلى فيديو
3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
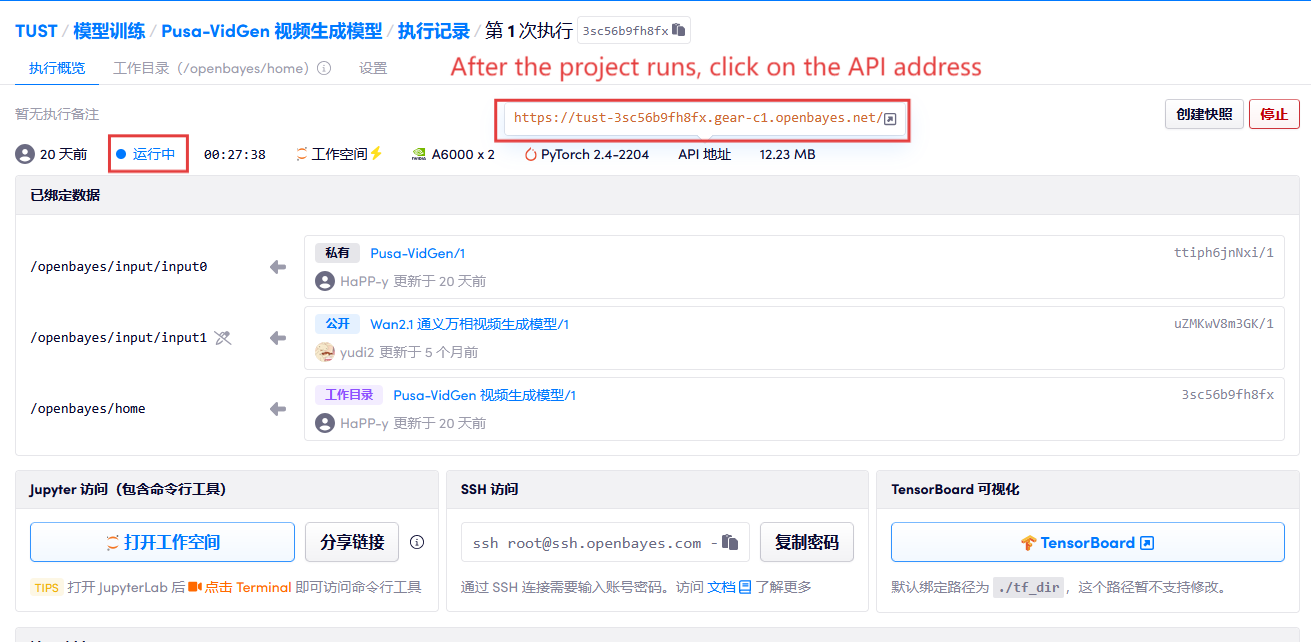
2. خطوات الاستخدام
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 2-3 دقائق وتحديث الصفحة.
2.1 تحويل الصورة إلى فيديو
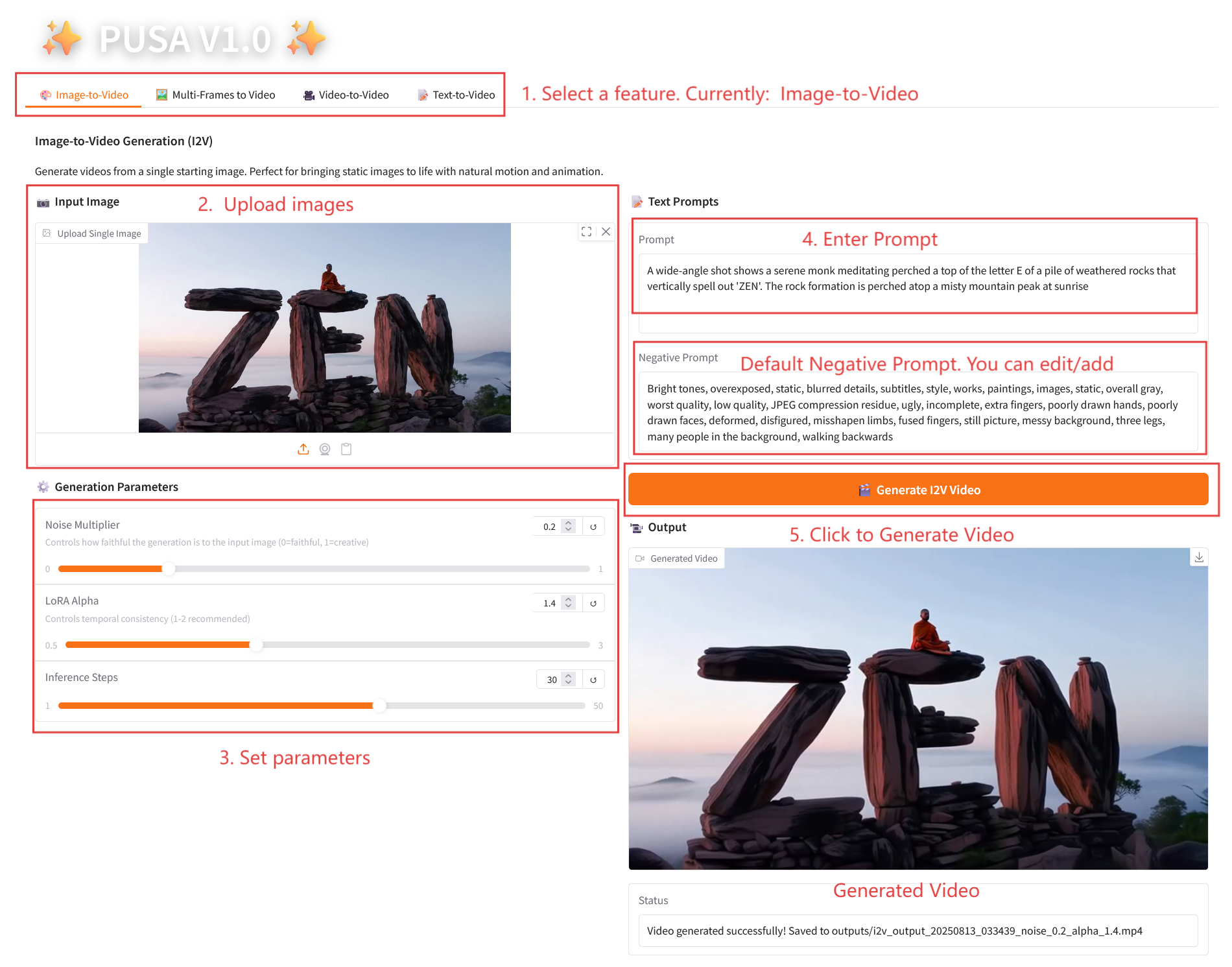
وصف المعلمة
- معلمات التوليد
- مضاعف الضوضاء: قابل للتعديل من 0.0 إلى 1.0، الافتراضي 0.2 (القيم المنخفضة أكثر دقة لصورة الإدخال، والقيم الأعلى أكثر إبداعًا).
- LoRA Alpha: 0.1-5.0 قابل للتعديل، الافتراضي 1.4 (يتحكم في اتساق الأسلوب، إذا كان مرتفعًا جدًا فسوف يصبح متيبسًا، وإذا كان منخفضًا جدًا فسوف يفقد التماسك).
- خطوات الاستدلال: قابلة للتعديل من 1 إلى 50، والافتراضي هو 10 (كلما زاد عدد الخطوات، أصبحت التفاصيل أكثر ثراءً، ولكن الوقت المستغرق يزداد خطيًا).
2.2 إطارات متعددة للفيديو
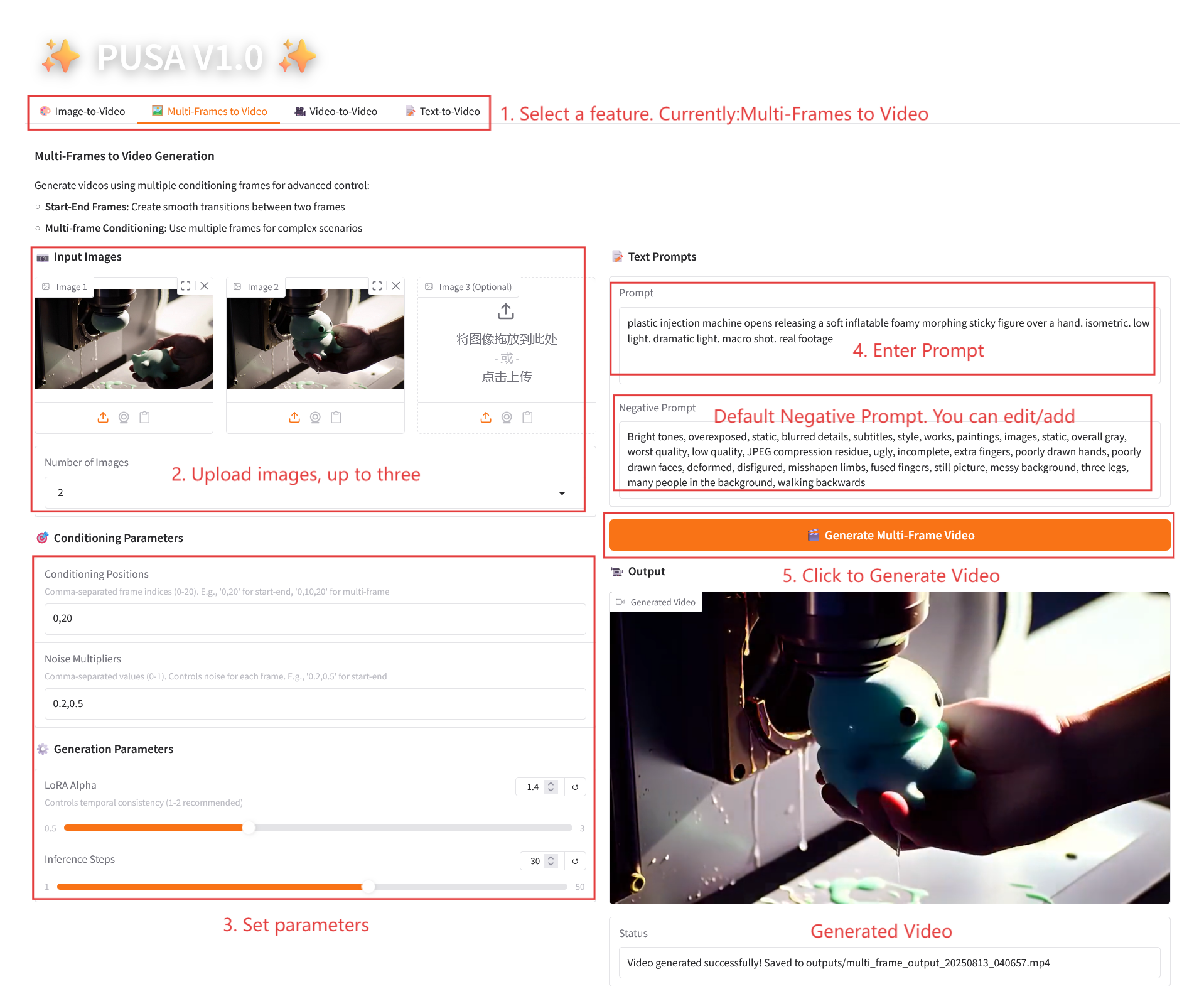
وصف المعلمة
- معلمات التكييف
- مواضع التكييف: مؤشرات الإطارات المنفصلة بفاصلة (على سبيل المثال، "0,20" تحدد نقاط الوقت للإطارات الرئيسية في الفيديو).
- مضاعفات الضوضاء: قيم مفصولة بفواصل من 0.0 إلى 1.0 (على سبيل المثال "0.2،0.5"، والتي تتوافق مع الحرية الإبداعية لكل إطار رئيسي، والقيم المنخفضة أكثر إخلاصًا للإطار، والقيم الأعلى أكثر تنوعًا).
- معلمات التوليد
- LoRA Alpha: 0.1-5.0 قابل للتعديل، الافتراضي 1.4 (يتحكم في اتساق الأسلوب، إذا كان مرتفعًا جدًا فسوف يصبح متيبسًا، وإذا كان منخفضًا جدًا فسوف يفقد التماسك).
- خطوات الاستدلال: قابلة للتعديل من 1 إلى 50، والافتراضي هو 10 (كلما زاد عدد الخطوات، أصبحت التفاصيل أكثر ثراءً، ولكن الوقت المستغرق يزداد خطيًا).
2.3 فيديو إلى فيديو
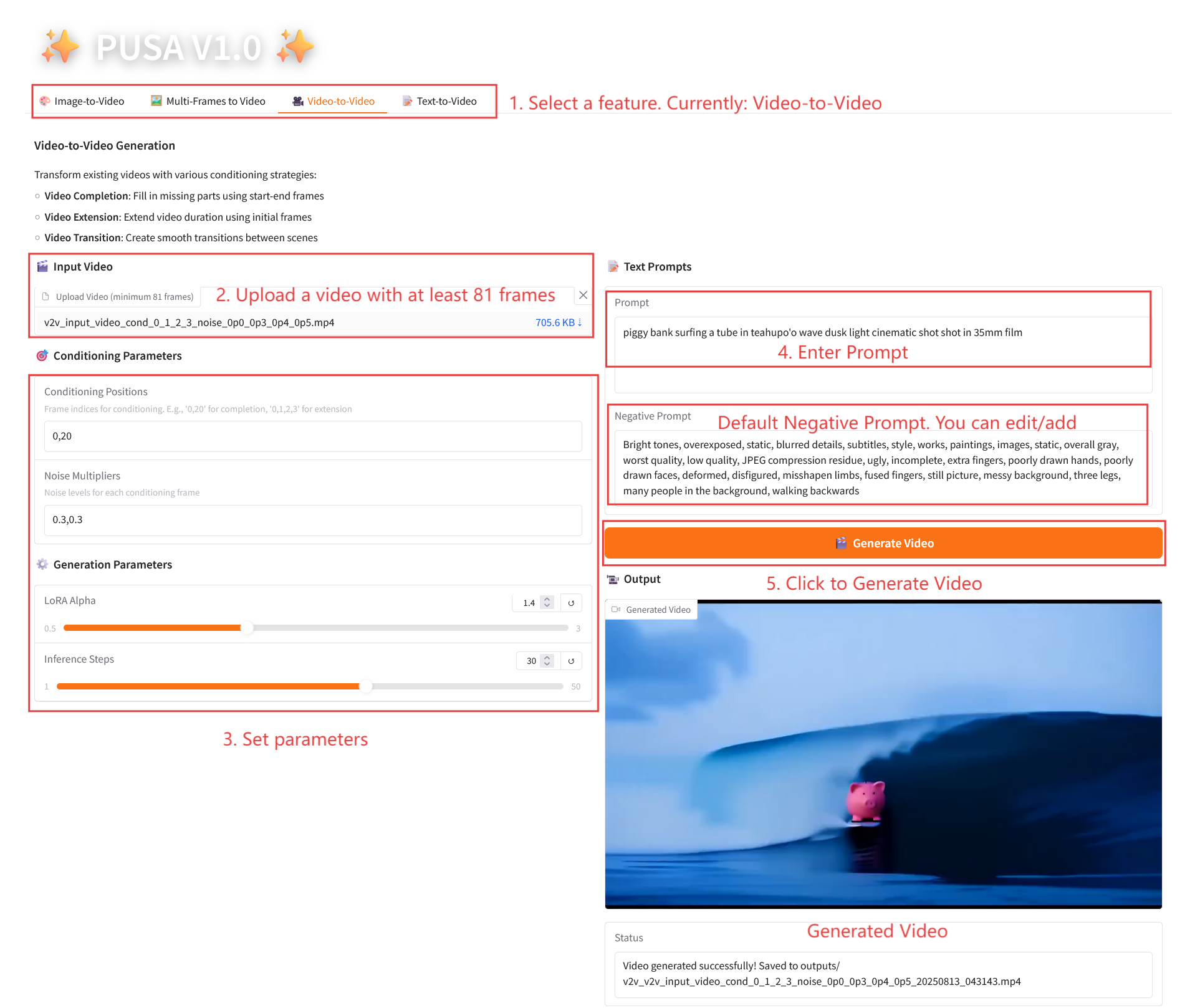
وصف المعلمة
- معلمات التكييف
- مواضع التكييف: مؤشرات الإطارات المنفصلة بفاصلة (على سبيل المثال، "0،1،2،3"، والتي تحدد مواضع الإطارات الرئيسية في الفيديو الأصلي المستخدم لتوليد القيد، مطلوبة).
- مضاعفات الضوضاء: القيم المنفصلة بفاصلة من 0.0 إلى 1.0 (على سبيل المثال "0.0،0.3"، والتي تتوافق مع درجة تأثير كل إطار مشروط، والقيم المنخفضة أقرب إلى الإطار الأصلي، والقيم الأعلى أكثر مرونة).
- معلمات التوليد
- LoRA Alpha: 0.1-5.0 قابل للتعديل، الافتراضي 1.4 (يتحكم في اتساق الأسلوب، إذا كان مرتفعًا جدًا فسوف يصبح متيبسًا، وإذا كان منخفضًا جدًا فسوف يفقد التماسك).
- خطوات الاستدلال: قابلة للتعديل من 1 إلى 50، والافتراضي هو 10 (كلما زاد عدد الخطوات، أصبحت التفاصيل أكثر ثراءً، ولكن الوقت المستغرق يزداد خطيًا).
2.4 تحويل النص إلى فيديو
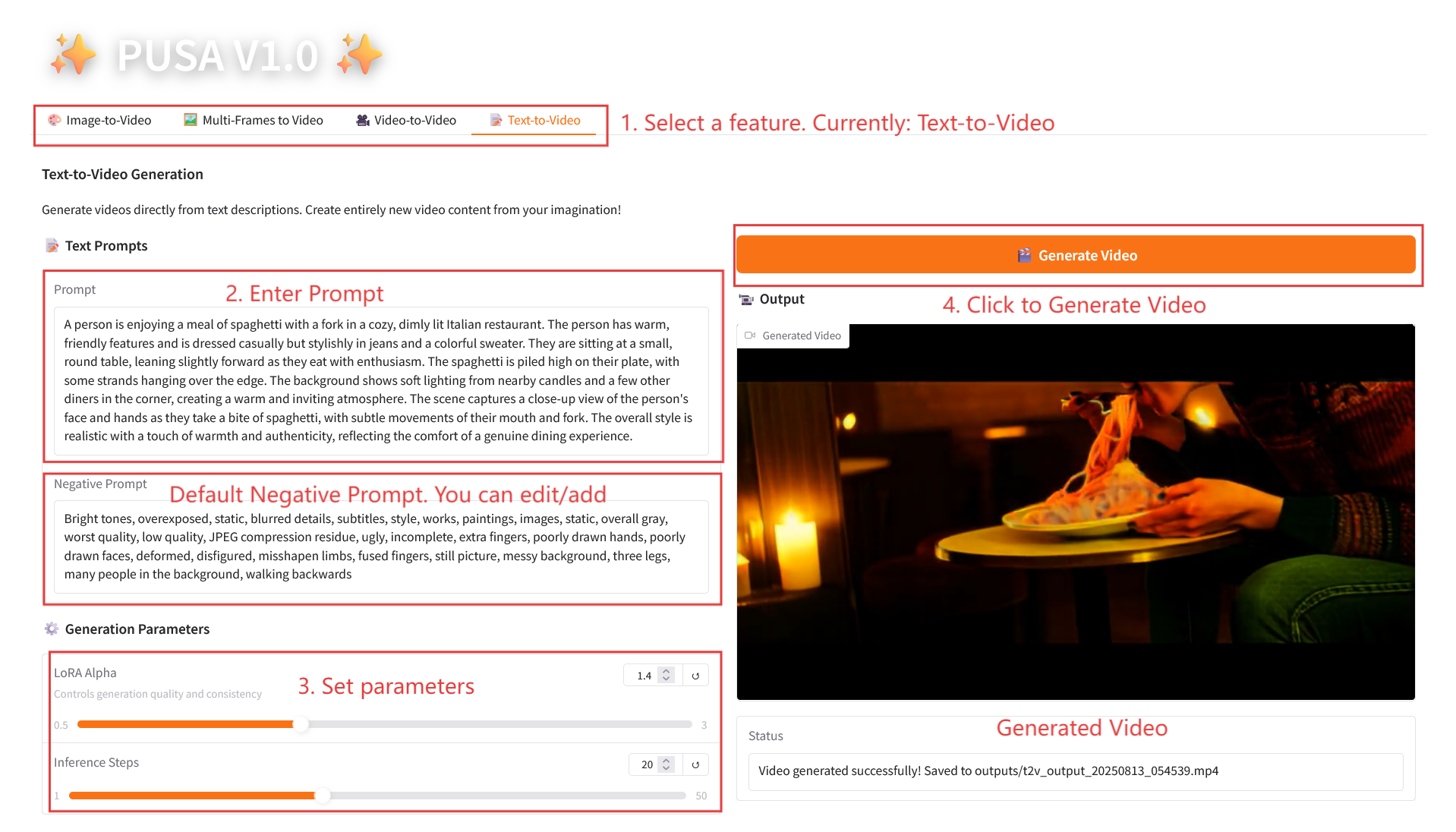
وصف المعلمة
- معلمات التوليد
- LoRA Alpha: 0.1-5.0 قابل للتعديل، الافتراضي 1.4 (يتحكم في اتساق الأسلوب، إذا كان مرتفعًا جدًا فسوف يصبح متيبسًا، وإذا كان منخفضًا جدًا فسوف يفقد التماسك).
- خطوات الاستدلال: قابلة للتعديل من 1 إلى 50، والافتراضي هو 10 (كلما زاد عدد الخطوات، أصبحت التفاصيل أكثر ثراءً، ولكن الوقت المستغرق يزداد خطيًا).
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}نظرة عامة على Notebook
المستوى
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.