Command Palette
Search for a command to run...
Sa2VA: نحو فهم إدراكي مكثف للصور ومقاطع الفيديو
التاريخ
رابط الورقة البحثية
الترخيص
Apache 2.0
GitHub
1. مقدمة البرنامج التعليمي

تم إطلاق Sa2VA، الذي طُوّر بالتعاون بين فرق بحثية من جامعة كاليفورنيا في ميرسيد، وشركة ByteDance Seed، وجامعة ووهان، وجامعة بكين، في 7 يناير 2025. يُعدّ Sa2VA أول نموذج موحد للفهم الإدراكي العميق للصور والفيديوهات. على عكس نماذج اللغة متعددة الوسائط واسعة النطاق الحالية، والتي تقتصر عادةً على وسائط ومهام محددة، يدعم Sa2VA نطاقًا واسعًا من مهام الصور والفيديوهات، بما في ذلك التجزئة الجبرية والحوار، ويتطلب الحد الأدنى من الضبط الدقيق بتعليمات بسيطة. فيما يلي نتائج الأبحاث ذات الصلة: Sa2VA: دمج SAM2 مع LLaVA لتحقيق فهم أساسي وعميق للصور ومقاطع الفيديو .
يستخدم هذا البرنامج التعليمي الموارد لبطاقة واحدة A6000.
2. أمثلة المشاريع



3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
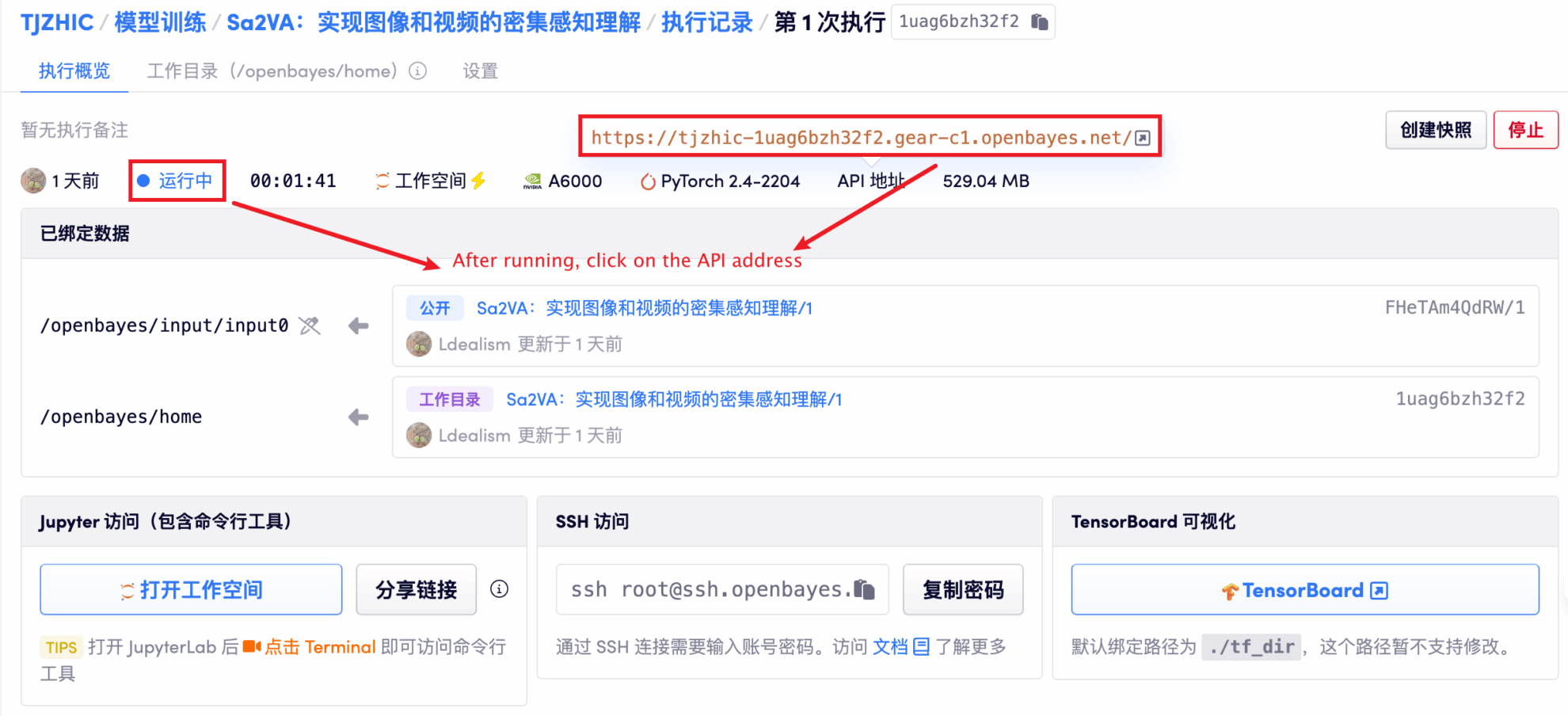
2. بمجرد دخولك إلى صفحة الويب، يمكنك التفاعل مع النموذج
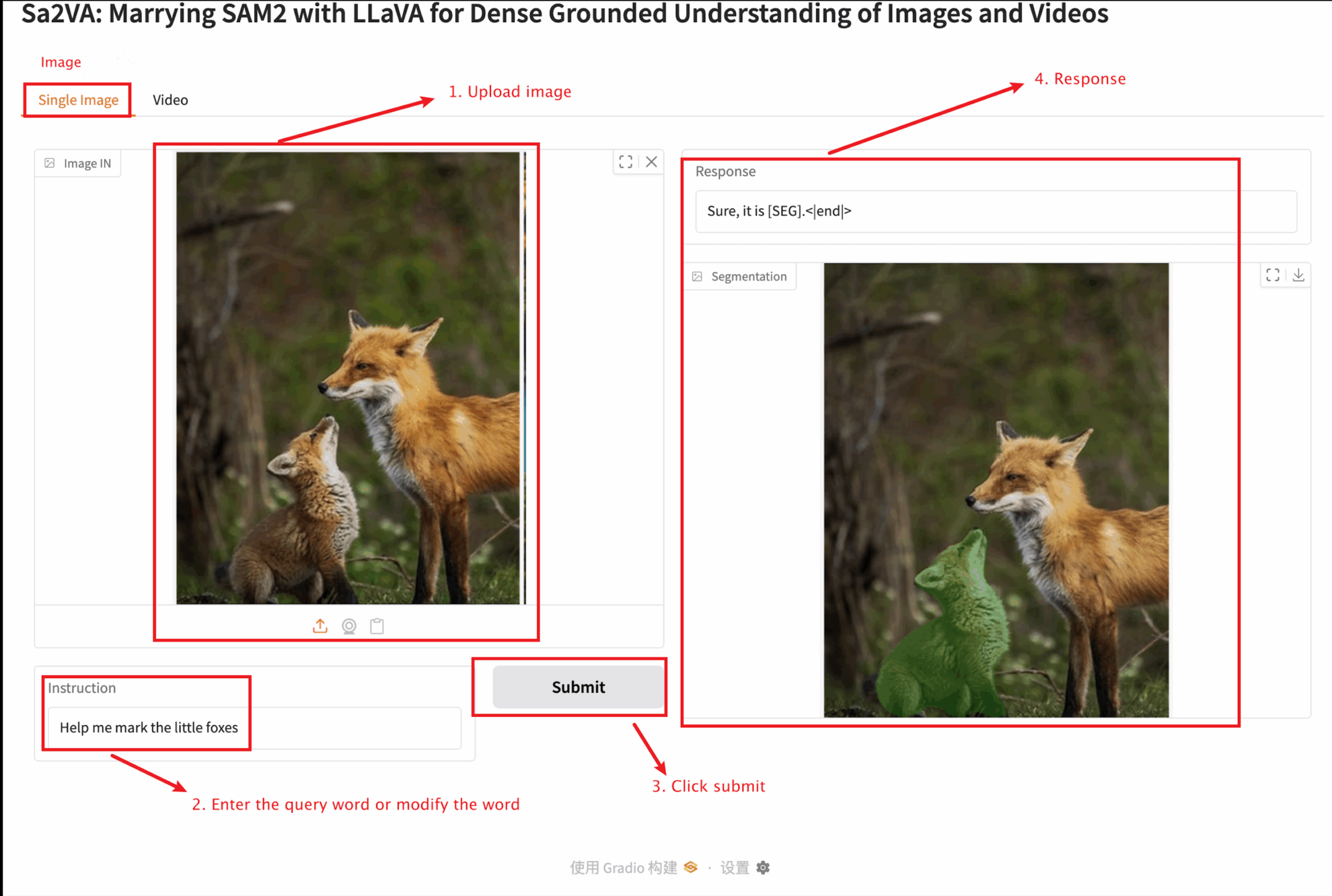
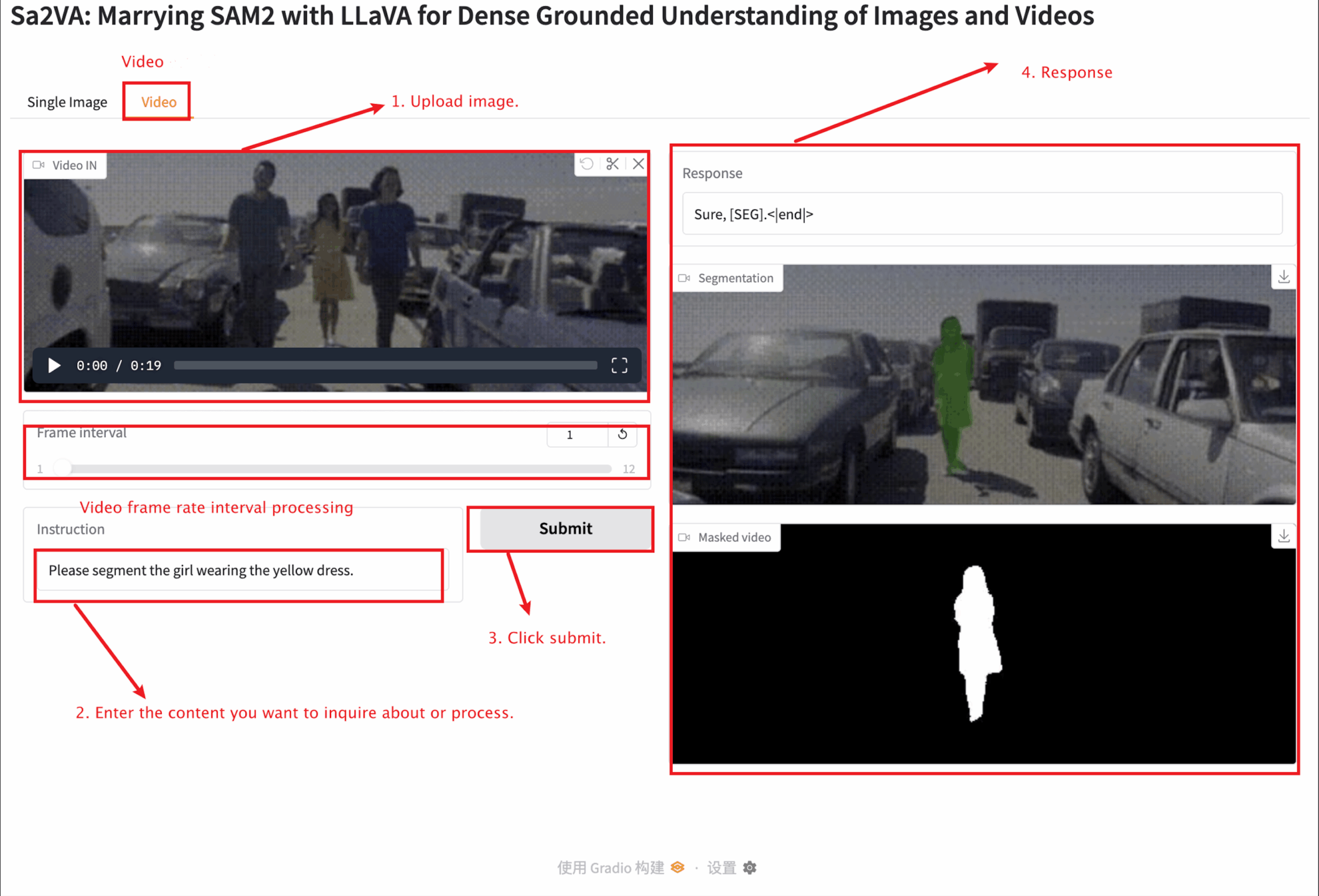
يوفر هذا البرنامج التعليمي اختبارين للوحدة: وحدة صورة واحدة ووحدة فيديو.
يجب ألا يتجاوز حجم الصورة التي تم تحميلها 10 ميجا بايت، ويجب ألا يتجاوز طول الفيديو الذي تم تحميله دقيقة واحدة، ويجب ألا يتجاوز حجم الفيديو 50 ميجا بايت، وإلا فقد يتسبب ذلك في تشغيل النموذج ببطء أو الإبلاغ عن أخطاء.
وصف المعلمة الهامة:
صورة واحدة
فيديو
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

الخامس. معلومات الاستشهاد
شكرًا لمستخدم Github com.zhangjunchang لنشر هذا البرنامج التعليمي، معلومات مرجع المشروع هي كما يلي:
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}نظرة عامة على Notebook
المستوى
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.