Command Palette
Search for a command to run...
ساعد هذا القرار فيفي لي في ترسيخ مكانتها كملكة الذكاء الاصطناعي.

باعتبارها مجموعة البيانات الأكثر كلاسيكية، أدت ImageNet إلى التطور السريع في مجال الرؤية الحاسوبية. فما هي التحديات التي واجهتها هذه المجموعة من البيانات أثناء إنشائها؟ كيف أثر ذلك على تطوير التعلم العميق؟ ما هو الإلهام الذي يمكن أن يجلبه لنا اليوم عندما أصبح التعلم الآلي شائعًا جدًا؟
لقد قال عالم الكمبيوتر الشهير فيفي لي في مناسبات عديدة:الذكاء الاصطناعي سيغير العالم، ولكن من سيغير الذكاء الاصطناعي؟
السبب وراء الدور المهم الذي تلعبه فيفي لي في الصناعة وكل كلمة تقولها يمكن أن تسبب ضجة في الصناعة ليس فقط بسبب نتائج أبحاثها العديدة المهمة. ومن النقاط المهمة جدًا أنها كانت أول من بادر بإنشاء مشروع ImageNet، الذي لعب دورًا مهمًا في الترويج للصناعة بأكملها.
ImageNet: مجموعة البيانات التي غيرت تطور الذكاء الاصطناعي
تعتبر الرؤية الحاسوبية واحدة من أفضل الاتجاهات لتطوير الذكاء الاصطناعي في الوقت الحاضر. ImageNet هي مجموعة بيانات كلاسيكية في هذا المجال. ليس من المبالغة أن نقول أنه بدون تقنية ImageNet، فإن التعرف على الوجه سيكون بمثابة ترف اليوم.
تم تقديم ImageNet بواسطة Fei-Fei Li et al. في ورقة بحثية في مؤتمر CVPR 2009. إن عدد وجودة ImageNet غير مسبوقة.ويحتوي الكتاب على 15 مليون صورة توضيحية تغطي 22 ألف فئة، بهدف تعليم أجهزة الكمبيوتر كيفية التعرف على التنوع في العالم..

في العقد الماضي، تم نشر أوراق تعريفية عن ImageNet. "ImageNet: قاعدة بيانات صور هرمية واسعة النطاق》التأثير كبير. على Google Scholar، الورقة موجودة حاليًاتم الاستشهاد به 11914 مرة.
تتناول ورقة بحثية أخرى تحدي بيانات ImageNet والتقدم البحثي في مجال التعرف على الكائنات. "تحدي التعرف البصري واسع النطاق من ImageNet》كما وصل عدد الاستشهادات إلى رقم مذهل 11056 مرة.

لقد أصبحت ImageNet معيارًا في مجال التعرف على الرؤية الحاسوبية، كما قادت الصناعة إلى عصر مجموعات البيانات عالية الجودة: بعد عام 2010، بدأت شركات كبرى مثل Google وMicrosoft والعديد من معاهد الأبحاث في إطلاق مجموعات بيانات عالية الجودة.
لقد نجحت ImageNet أيضًا في اجتياز اختبار الزمن. في مؤتمر CVPR لعام 2019،تم منحها للمساهمة الأكثر شمولاً في مجال الرؤية الحاسوبية على مدى العقد الماضي——تم منح جائزة Longuet-Higgins للورقة البحثية التي أصدرت ImageNet دون أي تشويق.
قبل عشر سنوات، تنبأت بأهمية البيانات
في عام 2009، كان التفكير السائد في الصناعة لا يزال يدور حول النماذج، التي تنعكس في التعلم الآلي النظري المبرمج يدويًا، واستخدام الأساليب الرياضية لحل المشكلات الشائعة.
لكن فيفي لي فعلت شيئًا "مختلفًا" للغاية، كما قالت لاحقًا في مقابلة،يجب أن يكون البحث طويل الأمد ومؤثرًا. لا تكتفِ بالاتجاهات الحالية، بل التزم بإجراء بحث متين ومؤثر.

في عام 2006، أصبحت فاي فاي لي أستاذة علوم الكمبيوتر في جامعة إلينوي في أوربانا شامبين. ووجدت أن المجتمع بأكمله كان يدرس استراتيجيات أفضل لمواصفات الخوارزمية، لكنه قلل من تقدير دور البيانات.
ومن خلال التحليل الهادئ، رأت عيوب القيام بذلك:إذا تم إنتاج البيانات المستخدمة لأغراض بحثية ولا يمكن أن تعكس العالم الحقيقي، فحتى أفضل الخوارزميات ستكون بلا معنى.
وهذا جعلها مصممة على العمل على البيانات.
منذ عشر سنوات، كانت أجهزة الكمبيوتر تتعرف على الأشياء عن طريق التقاط الميزات ثم إعطاء النتائج. ولكن هذا له العديد من العيوب. على سبيل المثال، غالبًا ما يرتكب النموذج المجرد بواسطة الكمبيوتر أخطاء عندما يتعلق الأمر بنفس الكائن في أوضاع وزوايا متعددة.
المشكلة الأكبر هي وحدة بيانات التدريب. إذا تم تغذية الكمبيوتر بنوع واحد فقط من الصور، فسيتم تدريبه على امتلاك إدراك "نمطي"، وبمجرد حدوث تغيير طفيف، فلن يكون قادرًا على التعرف عليه.
اكتشفت فاي فاي لي بذكاء أن هذه المشكلة ستكون أكبر عقبة في مجال الرؤية الحاسوبية.
ولادة ImagNet: سلسلة من التقلبات والمنعطفات
ولحل هذه المشكلة، عاد تفكير فاي فاي لي إلى الناس. في فهمها،يتمكن الطفل البالغ من العمر ثلاث سنوات من التعرف على الأشياء وتمييزها لأنه رأى عددًا كبيرًا من الأشياء من خلال عينيه وجمع عددًا كبيرًا من الصور.
إذا تم "إدخال" عدد كبير من الصور المصنفة إلى جهاز كمبيوتر، فقد يتمكن الذكاء الاصطناعي من تعلم كيفية التعرف على الصور. إذا قمنا بالتطور وفق هذه الفكرة، فإن المفتاح يكمن في البيانات، ولكن كيف يمكننا إنشاء نظام شامل؟
في هذا الوقت، وورد نت ظهر المشروع في رؤية فيفي لي.
هذا هو الهندسة المعمارية الإنجليزية التي بنيت على أساس تصنيف المفردات. سيتم عرض كل كلمة حسب علاقتها بالكلمات الأخرى. يغطي المشروع بأكمله كلمات لعدد كبير من الأشياء في العالم.
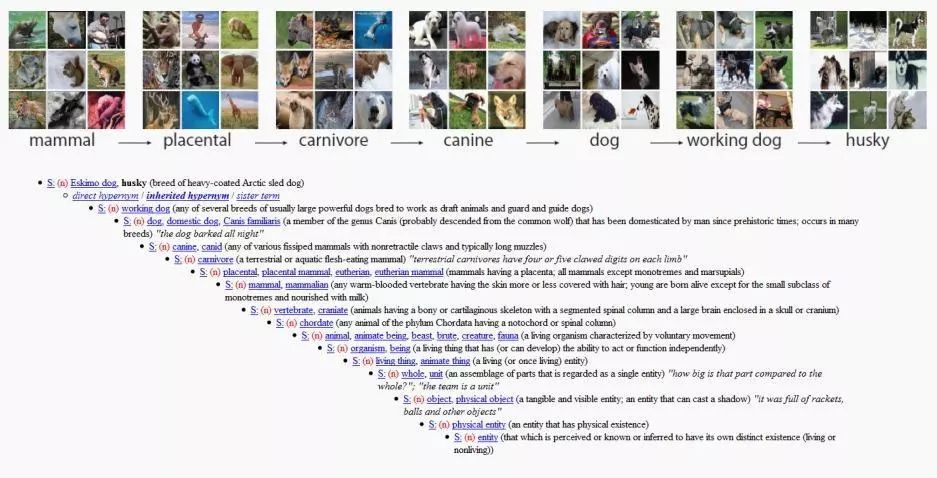
بعد لقاء الباحثة كريستيان فيلباوم في WordNet في عام 2006، توصلت فيفي لي إلى الحل: أرادت تقليد نهج WordNet وبناء مجموعة بيانات كبيرة لتوفير صور توضيحية لكل كلمة.
في العام التالي، أثناء العمل في جامعة برينستون، أطلقت فاي فاي لي شبكة إيماج نت المشروع، وبدأت في تشكيل فريق لإكمال هذا العمل الضخم. أهدافهم هي:احصل على ما يكفي من الصور الموضحة لإنشاء نظام صور كامل وضخم.
لكن المهمة كانت ضخمة للغاية لدرجة أنهم أرادوا في البداية توظيف طلاب جامعيين للبحث عن الصور الموجودة على الإنترنت وتصفيتها ووضع علامات عليها وإضافتها إلى مجموعة البيانات.
لكن سرعان ما أدركت فاي فاي لي أن هذه الطريقة لجمع الصور كانت بطيئة للغاية. وفقًا لتقدير تقريبي، إذا استمر الشخص في وضع العلامات دون توقف أو تناول الطعام أو الشراب، فسوف يستغرق الأمر عقودًا من الزمن.
وبمحض الصدفة، اكتشفت فاي فاي لي نقطة تحول أخرى. لقد اكتشفوا ذلك من خلال شخص قام بتقديمه.Amazon Mechanical Turk هي طريقة تمويل جماعي عبر الإنترنت.على هذه المنصة، يمكن لأصحاب العمل توظيف العديد من الأشخاص عبر الإنترنت لإكمال بعض العلامات البسيطة.
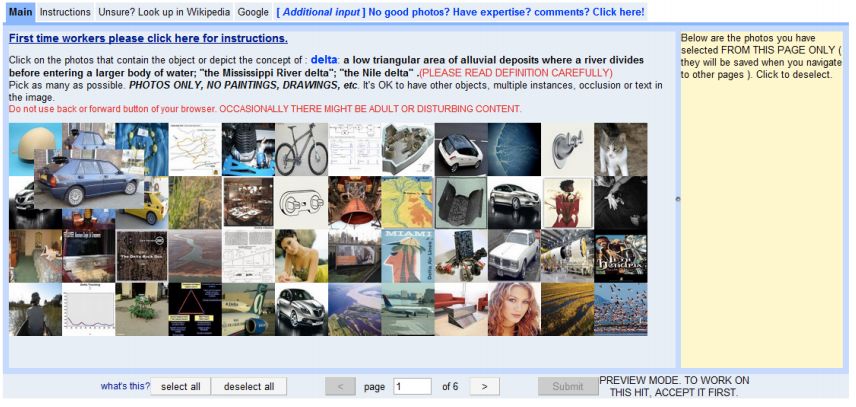
في نهاية المطاف، من خلال استخدام خدمة التمويل الجماعي من أمازون،49000 شخص من 167 دولة أمضوا عامين ونصفًاحان الوقت لإكمال هذا المشروع الضخم.
وعلى الرغم من مواجهة العديد من التحديات مثل نقص الدعم، وعدم كفاية التمويل، ونقص القوى العاملة، إلا أن ImageNet ولدت بفضل إصرارها.
باعتبارها شيئًا جديدًا، لم يتم أخذ ImageNet على محمل الجد في البداية. في مؤتمر CVPR لعام 2009، تم استخدام ورقة ImageNet فقط كملصق بحثي وتم نشرها في مكان غير واضح.
وقد انعكس هذا الوضع تمامًا مع مسابقة التحدي المستمدة من ImageNet.
مسابقة ILSVRC: دع ImageNet تصبح ناجحة
بعد مرور عام على إصدار ImageNet، بفضل جهود Fei-Fei Li وآخرين، تم إطلاق تحدي التعرف البصري واسع النطاق من ImageNet (ILSVRC).
تُعرف مسابقة ILSVRC أيضًا باسم مسابقة ImageNet، والتي تُقام سنويًا منذ عام 2010. في هذه المسابقة، يستخدم المشاركون مجموعة بيانات ImageNet كمعيار لتقييم أدائهم في اكتشاف الكائنات واسعة النطاق وتصنيف الصور.
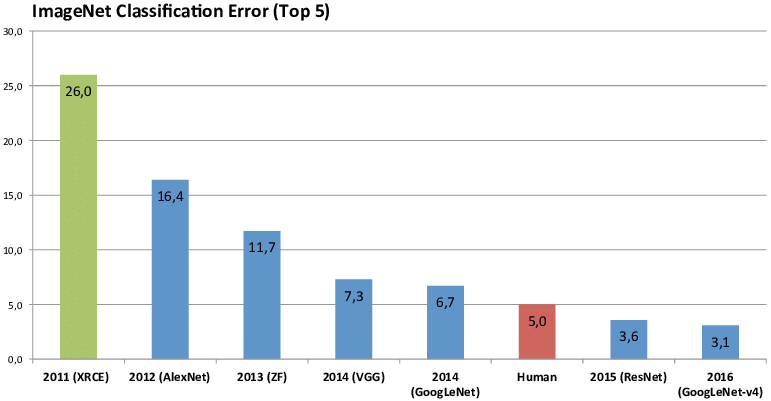
وسرعان ما أصبح الحدث بمثابة أولمبياد لمسابقات خوارزميات الفحص. وقد استخدمتها المؤسسات الكبرى كأرض تدريب لاختبار إيجابيات وسلبيات خوارزمياتها الخاصة. وفجأة، ظهرت العديد من الاختراقات والإنجازات.
لكن أهم ما يميز مسابقة ImageNet هو أنها شجعت على ظهور الشبكات العصبية والتعلم العميق.
قاد هينتون فريقه للمشاركة في مسابقة ImageNet لعام 2012. في ذلك العام، كانت طريقة التعلم العميق التي استخدمها فريق هينتون متقدمة كثيرًا عن جميع الطرق الأخرى في مسابقة التعرف على الصور. نموذج بنية الشبكة العصبية التلافيفية العميقة الذي قدموه تمكنت Alexnet من تحسين الأداء بمقدار 10.8 %، وهو أعلى بمقدار 41% من المركز الثاني.

ما هو مفهوم هذا؟ في ذلك الوقت، كان من الممكن اعتبار تحسن أداء 1% "مساهمة رئيسية"، وكانت الشبكة العصبية، وهي الطريقة التي كانت خاملة لأكثر من عشر سنوات، قد تجاوزت في الواقع 10 نقاط مئوية، مما تسبب على الفور في زلزال هائل.

قبل ذلك، لم يتم تدريب الشبكات العصبية العميقة على الإطلاق باستخدام بيانات بهذا الحجم. بعد AlexNet، تم إثبات القدرات الممتازة للشبكات العصبية العميقة بشكل كامل بمساعدة ImagNet.
بعد مرور عامين، استخدمت جميع الفرق المشاركة في تحدي ImageNet التعلم العميق.
انتهت المسابقة، واستمر البحث
في عام 2017، بعد ثماني سنوات، حققت تحدي ImagNet مهمتها: أصبحت معدلات أخطاء التعرف لدى أجهزة الكمبيوتر أقل من تلك لدى البشر. لم يعد التعرف على الصورة الناضجة يشكل تحديًا، وأشارت الرحلة الجديدة إلى فهم الصورة، لذا وصلت المنافسة إلى خاتمة ناجحة.
بفضل ImageNet والتحدي،ارتفعت دقة الكمبيوتر في تصنيف الأشياء من 71.8% إلى 97.3%.، متجاوزًا المستوى البشري بكثير.
عند النظر إلى عملية إنشاء ImageNet، نجد أنها لم تكن مهمة شائعة في ذلك الوقت. ومع ذلك، فإن هذا العمل "المضاد للاتجاه"، بسبب إصرار فيفي لي وآخرين، عزز في نهاية المطاف التقدم التاريخي للذكاء الاصطناعي. وفي الوقت نفسه، ترك Fei-Fei Li أيضًا البصمة الأكثر أهمية في مجال الرؤية الحاسوبية بفضل ImageNet.
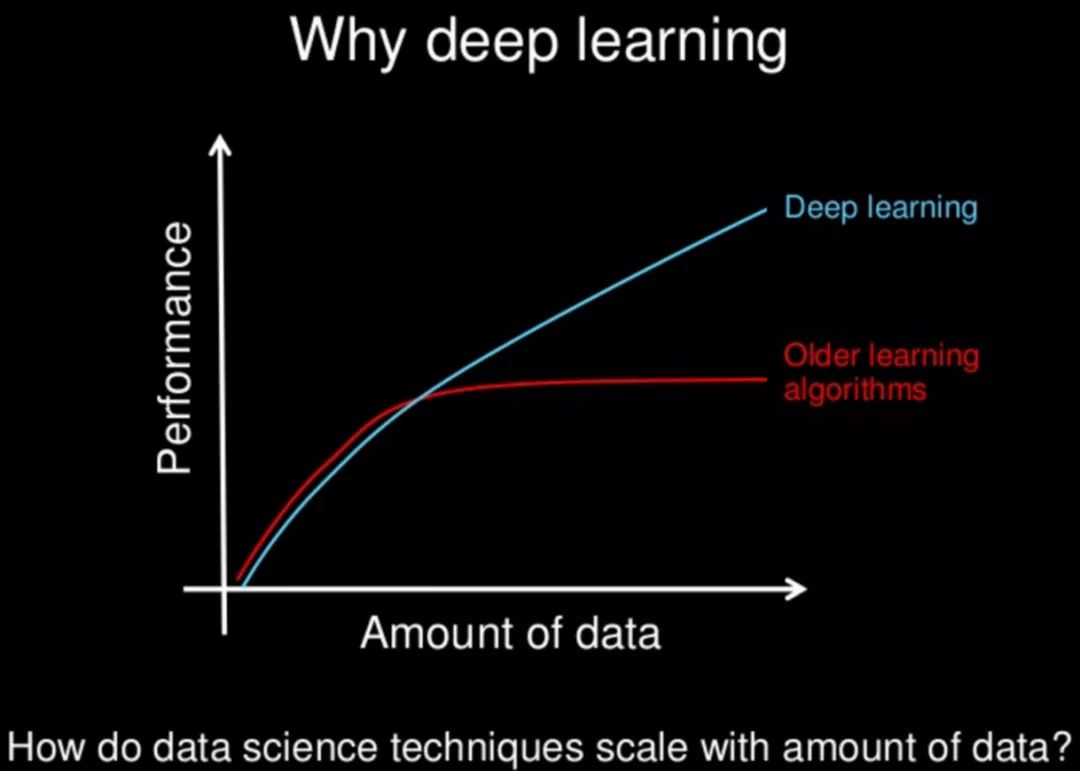
إذا تم تشبيه البيانات بـ "وقود الصواريخ" للتعلم الآلي، فإن ImageNet هي بلا شك أول وأكبر برميل من هذا الوقود.
كما قال فريق فيفي لي،"لا يتعين عليك القيام بالشيء الأكثر شهرة، ولكن عليك أن تفعل شيئًا تؤمن به وسيكون له تأثير."

مراجع:
1. البيانات التي غيّرت أبحاث الذكاء الاصطناعي - وربما العالم
2. كيف نُعلّم أجهزة الكمبيوتر فهم الصور
4. لم يكن هناك سوى اختراق واحد في مجال الذكاء الاصطناعي
5. منشورات ImageNet والاستشهادات
6. تحدي التعرف البصري على نطاق واسع
-- زيادة--








