Command Palette
Search for a command to run...
إن تعليم الذكاء الاصطناعي لعب الورق والألعاب لا يقتصر على هزيمة البشر فحسب

أعلنت شركة DeepMind أمس أن الذكاء الاصطناعي الخاص بها، AlphaStar، سيكون متاحًا على الخادم الأوروبي، حيث سيتنافس بشكل مجهول مع لاعبين بشريين في سلم StarCraft 2. اليوم، سيطرت الأخبار مرة أخرى على الأخبار حول هزيمة Pluribus، وهو مقامر الذكاء الاصطناعي الذي طورته شركة فيسبوك وجامعة كارنيجي ميلون، لأفضل اللاعبين البشريين في لعبة Texas Hold'em المكونة من ستة لاعبين. يتحسن أداء الذكاء الاصطناعي بشكل متزايد في مسابقات الألعاب، ولكننا ندرب الذكاء الاصطناعي باستمرار للتغلب على البشر في الألعاب. ما هو الهدف النهائي والأهمية؟
بالأمس فقط، أعلنت شركة DeepMind عن الذكاء الاصطناعي الخاص بها سيتوفر AlphaStar قريبًا على الخادم الأوروبي وسيتنافس بشكل مجهول ضد لاعبين بشريين في سلم StarCraft 2.اليوم، قامت فيسبوك وجامعة كارنيجي ميلون بتطوير مشترك إله المقامرة بالذكاء الاصطناعي ، هزيمة أفضل اللاعبين البشريين في بطولة تكساس هولدم المكونة من ستة لاعبين.
لماذا يهتم الذكاء الاصطناعي دائمًا بألعاب الطاولة، ولماذا يعمل الفريق الذي يقف وراءه بجهد كبير للفوز بالألعاب ومسابقات الطاولة؟
لنبدأ بلعبة الإستراتيجية الأكثر تعقيدًا "StarCraft 2"
تم إطلاق لعبة StarCraft بواسطة Blizzard Entertainment في عام 1998، وتم إصدار الجزء الثاني منها StarCraft 2 في عام 2010. وتعتبرلعبة الإستراتيجية الأكثر صعوبة وتحديًا في الوقت الفعليفي حين أن العديد من الألعاب تم غزوها بواسطة الذكاء الاصطناعي، إلا أن هذا النوع من الألعاب يعتبر صعبًا نسبيًا بالنسبة للذكاء الاصطناعي لإتقانه.

من أجل الفوز، يجب على اللاعبين موازنة العوامل المتعددة والتعامل معها بعناية، ووضع خطط واستراتيجيات استجابة في الوقت المناسب. على عكس ألعاب الشطرنج التي تعتمد فقط على الاستراتيجية، يحتاج الذكاء الاصطناعي إلى مواجهة تحديات متعددة حتى يتمكن من اللعب بشكل جيد في هذه اللعبة، بما في ذلك التعامل مع المعلومات غير الكاملة، ووضع خطط طويلة الأجل، وتعلم الاستراتيجيات في الوقت المناسب، وما إلى ذلك.
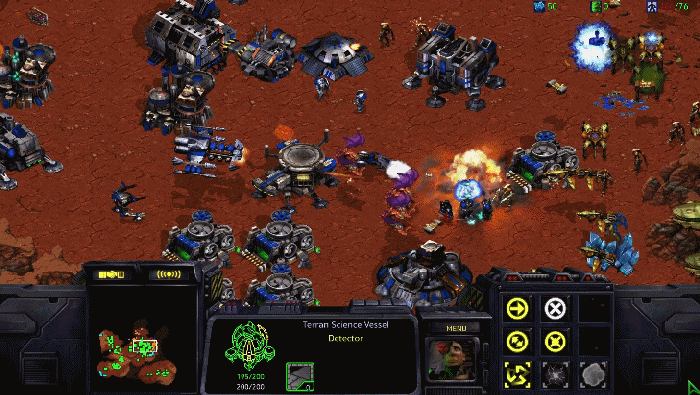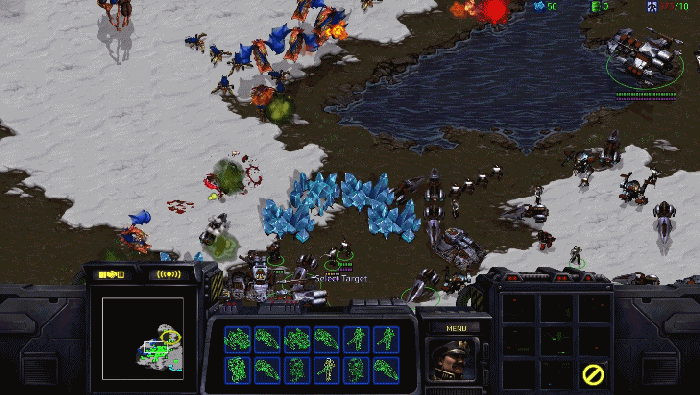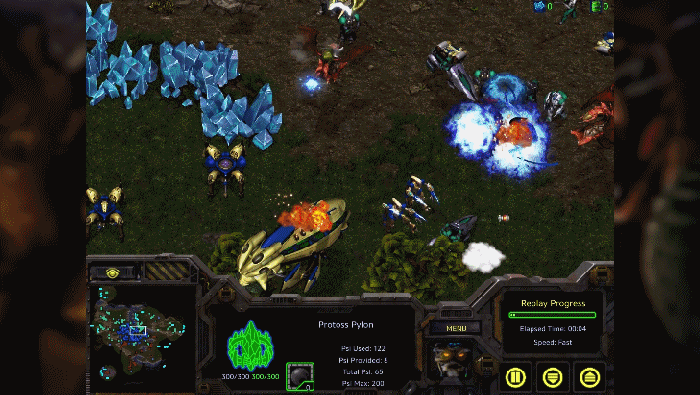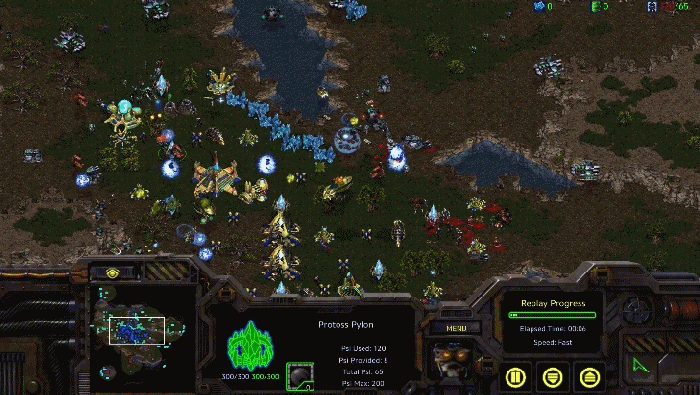
لكن في شهر ديسمبر/كانون الأول الماضي، تغير هذا الوضع بشكل جذري. في 11 لعبة StarCraft 2 بين البشر وAlphaStar، حققت الذكاء الاصطناعي فوزًا ساحقًا بنتيجة 10:1.في هذه المرحلة، تركت الذكاء الاصطناعي بصمة قوية على لعبة StarCraft.
يتم تحديد سلوك AlphaStar بواسطةالشبكات العصبية العميقةتتلقى الشبكة العصبية بيانات الإدخال من واجهة اللعبة (قائمة الوحدات وسماتها) وتخرج سلسلة من التعليمات التي تشكل الإجراءات داخل اللعبة.
بناءً على معلومات غير كاملة، تستغرق الألعاب عادةً ما يصل إلى ساعة وتتطلب آلاف الحركات. يتم استخدام كل إطار من StarCraft كخطوة إدخال،تتنبأ الشبكة العصبية بتسلسل الإجراءات المتوقع لبقية كل إطار ثم تتخذ الإجراء الأفضل.

وأوضح DeepMind أن نجاح AlphaStar في اللعبة كان في الواقع نتيجة لقرارات استراتيجية ممتازة على المستويين الكلي والجزئي، وليس بسبب معدل النقر المتفوق أو وقت رد الفعل الأسرع.
يمكن أن تساعد هذه التقنية أيضًا في مواجهة العديد من التحديات الأخرى في أبحاث التعلم الآلي، بما في ذلك نمذجة التسلسلات طويلة الأمد ومساحات الإخراج الكبيرة، مثل الترجمة ونمذجة اللغة والتمثيل المرئي.
لقد سيطر الذكاء الاصطناعي على ألعاب الطاولة
- في عام 1997، هزم برنامج الكمبيوتر "ديب بلو" أفضل لاعب شطرنج في العالم في ذلك الوقت، مسجلاً بذلك المرة الأولى التي يهزم فيها الذكاء الاصطناعي اللاعبين البشريين.
- في مايو 2017، هزم برنامج AlphaGo المتنامي Ke Jie، أفضل لاعب Go في العالم في ذلك الوقت، بنتيجة 3:0. وبعد خمسة أشهر فقط، أعلنت شركة DeepMind عن إصدار جديد من الخوارزمية: ألفاجو زيروتمكن من التغلب على AlphaGo بنتيجة 100 إلى 0؛
- في نهاية عام 2018، استخدم معهد أوبر لأبحاث الذكاء الاصطناعي خوارزميات التعلم المعزز انطلق واستكشف،يخرج انتقام مونتيزوماتجاوزت النتيجة 2 مليون، مع متوسط نتيجة يزيد عن 400000، وتُعرف بأنها أقوى خوارزمية تصفية في تاريخ ألعاب أتاري؛
- OpenAI Five أولاً، نعتمد على 5 شبكات عصبية. OpenAI Five هزيمة فريق من لاعبي Dota 2 الهواة. في أبريل 2019، هزموا فريق OG بطل العالم بنتيجة 2:0 في بطولة Dota2 International Invitational.

- ثم، مؤخرًا، تم إنشاء لعبة Texas Hold'em Poker God AI، بالتعاون بين Facebook وCMU، بلسرإيبوسفي لعبة مكونة من ستة لاعبين، يمكن أن يؤدي هزيمة أفضل لاعبي تكساس هولدم البشريين إلى تحقيق ربح متوسط يبلغ حواليألف دولار.
استغرق الفريق أقل من أسبوع لتدريب الذكاء الاصطناعي للعبة البوكر Texas Hold'em.

لقد طور البشر العديد من الذكاء الاصطناعي الذي هزم لاعبين بشريين كبار في العديد من ألعاب الرياضات الإلكترونية المعقدة، مما جعل البشر يرتجفون خوفًا.
لكن هل تلعب الذكاء الاصطناعي الألعاب من أجل المتعة فقط؟أولاً هزيمة البشرية، ثم خدمة الإنسانية
ومن أجل تعليم الخوارزميات كيفية لعب لعبة "جو" والرياضات الإلكترونية والبوكر، بذلت شركات الذكاء الاصطناعي الكثير من الجهود، ويمكن القول إن موقفها جاد للغاية.
حتى أن شركة OpenAI طورت صالة الألعاب الرياضية والكون منصة مفتوحة المصدر تتيح للجميع استخدام هذه المنصة لتعليم أجهزة الكمبيوتر كيفية لعب الألعاب. يتم استخدام Gym لتشغيل الألعاب الصغيرة مثل Atari و Flappy Bird و Snake، بينما يتم استخدام Universe لتشغيل الألعاب ثلاثية الأبعاد الكبيرة مثل GTA5 وسباقات السيارات.

هل ينفقون كميات هائلة من الطاقة والموارد المالية لمجرد ممارسة الألعاب من أجل الترفيه؟ أم أن قدرة الذكاء الاصطناعي على هزيمة البشر تمنحهم شعورًا كبيرًا بالإنجاز؟ لا، بالنسبة لباحثي الذكاء الاصطناعي، الألعاب هي مجرد طريقة، وليست هدفًا.
بيئة اللعبة:إنه مسرع للتنمية الشاملة للذكاء الاصطناعي
تعتبر الألعاب منصة اختبار مثالية للذكاء الاصطناعي.تحتوي الألعاب على بيانات سهلة المعالجة، وقواعد ثابتة، ومجموعة متنوعة من الاستراتيجيات الافتراضية. تعتبر الألعاب عبارة عن سيناريوهات محاكاة، مما يجعلها مكانًا مثاليًا للبحث والتطوير في مجال الذكاء الاصطناعي.
وقال جوليان توجيليوس، الأستاذ المشارك في مركز دراسات الألعاب بجامعة نيويورك: "لم نشهد الكثير من الأشياء التي يتم تدريبها من خلال الألعاب ثم نقلها إلى العالم الحقيقي". "ولكننا رأينا أساليب تم اختراعها للعب الألعاب تنتقل إلى العالم الحقيقي."
الذكاء الاصطناعي في اللعبة: أفضل معلم وخصم للاعبين البشر
من ناحية أخرى، يمكن للذكاء الاصطناعي أن يساعد في اكتشاف بعض الاستراتيجيات الأكثر مثالية وتحسين المهارات التنافسية للاعبين البشر. يعتقد كي جيه أن المباراة مع ألفا جو فتحت عقله وحسّنت مهاراته في لعبة جو.
ومن ناحية أخرى، فإن تدخل الذكاء الاصطناعي سوف يخلق خصمًا أكثر ذكاءً في العديد من الألعاب. لا يمكن للذكاء الاصطناعي المعدل أن يصبح مدربًا للاعبين البشريين فحسب، بل يمكنه أيضًا التكيف مع مستويات اللاعبين المختلفين للعب ضدهم.
ويمكنه أيضًا منع اللاعبين البشر في ألعاب اليوم من الغضب على بعضهم البعض. إذا كان هناك ذكاء اصطناعي بوذي في الجهة المقابلة لك، فسوف يحافظ بالتأكيد على بيئة لعب أكثر تحضراً. اللعبة هي مجرد البداية: هناك الكثير للقيام به
قال ديميس هاسابيس، الرئيس التنفيذي لشركة DeepMind: "هدف DeepMind ليس الفوز باللعبة فحسب، بل أيضًا الاستمتاع بها والاستلهام منها".

لكنني شخصيًا أستمتع بلعب الألعاب، وقد طورتُ ألعابًا حاسوبية. لكنها تُعدّ أيضًا منصات اختبار، حيث نحاول كتابة خوارزميات واختبارها.وفي نهاية المطاف، نأمل أن نتمكن من تطبيق تقنيتنا لحل المشاكل الحقيقية في العالم."
في المستقبل، لن يكون AlphaGo وAlphaStar مجرد أسماء للاعبين الذكاء الاصطناعي الذين يتحكمون في الأبطال في اللعبة، ولن يقتصر DeepMind على حل مشكلات اللعبة. وسوف يصبحون أبطال الذكاء الاصطناعي للمجتمع البشري.
-- زيادة--








