Command Palette
Search for a command to run...
دعونا نتحدث عن تشفير GAN، بدءًا من تسريب معلومات حجز غرفة فندق Huazhu

بقلم سوبر نيرو
اليوم، هناك شائعات تفيد بأن القراصنة يبيعون علناً "بيانات حجز غرف فندق Huazhu" على شبكة الويب المظلمة. وبناءً على المحتوى الذي أصدره البائع، فإن البيانات تتضمن الفنادق التابعة لشركة Huazhu وبيانات المستخدمين للفنادق التابعة لشركة AccorHotels التي تتعاون معها. عرض الهاكر علنًا بيع 8 بيتكوين (حوالي 56 ألف دولار أمريكي، أي ما يقرب من 380 ألف يوان صيني). وحتى الآن، ردت فنادق هوازو علناً بأنها أبلغت الشرطة بالقضية.
مجموعة فنادق هواتشو (ناسداك: HTHT)، المعروفة سابقًا باسم مجموعة فنادق هانتينج، هي أول مجموعة لإدارة سلسلة فنادق ذات علامة تجارية كاملة في الصين.
تأسست الشركة في عام 2005 وأدرجت في بورصة ناسداك في الولايات المتحدة في مارس 2010. وتدير الشركة حاليًا أكثر من 3000 فندق، تغطي جميع مستويات السوق من الراقية إلى المنخفضة.
ومن بين العلامات التجارية الفندقية التي تستهدف السوق الراقية، جراند ميركيور، وفيو، وجويا؛ وتشمل الفنادق التي تستهدف السوق المتوسطة فندق فور سيزونز، وأورانج كريستال، وأورانج سيليكت، وإيبيس ستايلز؛ يشتمل السوق الشامل على فنادق Ibis وHanting Premium وHanting وHi Inn.
البيانات المباعة على الويب المظلم هذه المرة تتضمن ثلاثة أجزاء:
- تتضمن معلومات التسجيل في الموقع الرسمي لفنادق هوازو ما يلي:
الاسم ورقم الهاتف المحمول وعنوان البريد الإلكتروني ورقم الهوية وكلمة المرور لتسجيل الدخول، بإجمالي 53 جيجابايت، معلومات هوية لنحو 120 مليون شخص؛
- عند تسجيل الوصول إلى فندق Huazhu، تتضمن معلومات تسجيل هوية الضيف ما يلي:
الاسم ورقم الهوية والعنوان المنزلي وتاريخ الميلاد ورقم الهوية الداخلية، بإجمالي 22.3 جيجابايت، معلومات هوية لحوالي 130 مليون شخص؛
- معلومات سجل حجز الغرف في فندق هواتشو، بما في ذلك:
رقم الهوية الداخلية، رقم جمعية الغرفة، الاسم، رقم بطاقة الدفع، رقم الهاتف المحمول، وقت تسجيل الوصول، رقم هوية الفندق، رقم الغرفة، مبلغ الاستهلاك، وما إلى ذلك، بإجمالي 66.2 جيجابايت، حوالي 240 مليون سجل؛
ورغم أن شركة هوازو أعلنت أنها اتصلت بالشرطة، فمن الصعب للغاية تتبع وجمع الأدلة على معاملات الويب المظلم، وكان من المفترض أن تكون البيانات قد تسربت بالفعل، لذا فمن غير المعروف ما هي التدابير التصحيحية التي يمكن اتخاذها.
اختراق البيانات: منطقة رمادية تحت الشمس
في الواقع، هذه ليست المرة الأولى التي يحدث فيها مثل هذا التسريب الواسع النطاق لمعلومات المواطنين.
وفي وقت مبكر من شهر يوليو/تموز من هذا العام، تم الكشف عن حالة كبيرة من تسرب البيانات المشتبه به في الصين. وقد تورطت في العملية 11 شركة، وتم الاستيلاء على 4000 جيجابايت وعشرات المليارات من بيانات معلومات المواطنين.
البيانات المتعلقة بهذه القضية خاصة للغاية. تتضمن بيانات عنوان URL للإنترنت المعنية بالقضية أكثر من 40 عنصرًا من المعلومات مثل أرقام الهواتف المحمولة وأكواد محطة الإنترنت الأساسية، والتي تسجل سلوك الإنترنت المحدد لمستخدمي الهواتف المحمولة. ويمكن لبعض البيانات أن تدخل مباشرة إلى الصفحة الرئيسية للحسابات الشخصية للمواطنين.
ولكن الأمر الأكثر إثارة للدهشة هو أن من يشترون هذه البيانات ليسوا مجرد منظمات احتيال أو جهات إقراض مالي عبر الإنترنت وما إلى ذلك كما نعتقد. تعد العديد من شركات الإنترنت المحلية والأجنبية الكبيرة، بما في ذلك جوجل وهواوي، من عملاء الإيرادات المهمين للشركة، مما يعني أن جميعها لديها إمكانية الوصول إلى مختلف البيانات الخاصة للمواطنين.
بالنسبة لمهندسي البحث والتطوير في أي شركة ذكاء اصطناعي في العالم، فإن القدرة على الحصول على كمية كبيرة من البيانات الحقيقية مفيدة جدًا لتطوير نماذج الذكاء الاصطناعي. وسيكون الأمر أفضل إذا كانت البيانات ذات نقاء عالي.
يمكنهم معالجة البيانات بسهولة أكبر ومقارنة النماذج وتقييمها بكفاءة أكبر، وبالتالي التوصل إلى حلول صحيحة للمشاكل في الحياة الواقعية.
ومع ذلك، وبسبب مشكلات سرية البيانات، فإن البيانات التي يمكن لهذه الشركات العملاقة مشاركتها محدودة للغاية. لذلك، أصبح من الشائع في الصناعة أن تقوم الشركات الكبيرة بشراء البيانات.
ليس فقط في الصين، ولكن المستخدمين في جميع أنحاء العالم ليس لديهم فهم واضح بشكل خاص لخصوصية وسرية البيانات. عند استخدام منتجات الإنترنت المختلفة، يجب عليك اختيار "نعم" في "اتفاقية المستخدم".
الشركات الكبرى تشتري البيانات، ثم ماذا؟
لقد أنفقت الشركات الكبرى الكثير من الأموال لشراء البيانات، لذا فمن الطبيعي أن تقوم باستخدام هذه البيانات بكفاءة.
يقومون بشراء البيانات، وجمع البيانات باستخدام منتجاتهم الخاصة، وتطوير أساليب تشفير أكثر أمانًا لحماية بياناتهم.

صحيح أن الضعيف سيبقى ضعيفًا دائمًا، والقوي سيبقى قويًا دائمًا
باعتبارنا مهندسين، دعونا نتحدث عن العديد من طرق تشفير البيانات المستخدمة بشكل شائع وكيفية فهم خصائصها ومبادئها.
آلية حماية غير كافية بطبيعتها للبيانات مجهولة المصدر
في الوقت الحالي، يتم تحقيق آلية سرية مشاركة البيانات الأكثر استخدامًا من خلال إخفاء هوية مجموعة البيانات، ولكن في معظم الحالات، لا يزال هذا ليس حلاً جيدًا.
إن إخفاء هوية البيانات قد يحافظ على السرية إلى حد ما عن طريق إخفاء بعض البيانات الحساسة، لكنه لا يستطيع منع خبراء البيانات من استخلاص الاستنتاجات. وفي التطبيق الفعلي، يمكن استنتاج البيانات الحساسة المخفية من خلال الاستنتاج العكسي للمعلومات ذات الصلة.
وفي وقت سابق، نشر باحث ألماني بحثًا بعنوان قم ببناء NSA الخاص بكتتحدث ورقة البحث عن كيفية عكس إخفاء هوية البيانات والعثور على المعلومات الأصلية.

حصل الباحث على إمكانية الوصول المجاني إلى معلومات حول تصفح الإنترنت لمدة شهر كامل من حوالي 3 ملايين ألماني من خلال شركة وهمية. تتم إخفاء هوية هذه المعلومات، على سبيل المثال باستخدام سلسلة من الأحرف العشوائية. 4vdp0qoi2kjaqgbلاستبدال الاسم الحقيقي للمستخدم.
نجح الباحث في استنتاج الاسم الحقيقي للمستخدم على الموقع من خلال سجل التصفح التاريخي للمستخدم والمعلومات الأخرى ذات الصلة. ومن الواضح أن إخفاء هوية البيانات لا يمكنه ضمان السرية التامة.
يستضيف مؤتمر Chaos Communication نادي Chaos Computer Club الألماني، وهو أكبر منظمة تحالف للقراصنة في أوروبا. يدرس بشكل أساسي قضايا أمن الكمبيوتر والشبكات، بهدف تعزيز أمن الكمبيوتر والشبكات.
وهكذا، وُلِد التشفير المتماثل
وهذا يعد أحد الإنجازات الرائدة في مجال التشفير. لا يمكن لفك التشفير سوى معرفة النتيجة النهائية ولكن لا يمكنه الحصول على المعلومات المحددة لكل نص مشفر.
يمكن أن يعمل التشفير المتجانس على تحسين أمان المعلومات بشكل فعال وقد يصبح تقنية رئيسية في مجال الذكاء الاصطناعي في المستقبل، ولكن في الوقت الحالي، فإن سيناريوهات تطبيقه محدودة.
ببساطة، التشفير المتجانس يعني أنه يمكنك استخدام بياناتي وفقًا لاحتياجاتك، ولكن لا يمكنك رؤية ما هي البيانات على وجه التحديد.

على الرغم من فعالية طريقة التشفير هذه، إلا أن تكلفتها الحسابية مرتفعة للغاية.
يمكن لتقنية التشفير المتجانس الأساسية تحويل 1 ميجا بايت من البيانات إلى 16 جيجابايت، وهو أمر مكلف للغاية في سيناريوهات الذكاء الاصطناعي. علاوة على ذلك، فإن تقنية التشفير المتجانس (مثل معظم خوارزميات التشفير) عادة ما تكون غير قابلة للتفاضل، مما يجعلها غير مناسبة إلى حد ما لخوارزميات الذكاء الاصطناعي السائدة مثل الانحدار التدرجي العشوائي (SGD).
في الوقت الحاضر، لا تزال تقنية التشفير المتجانس في الأساس على المستوى المفاهيمي ومن الصعب وضعها في التطبيق العملي، ولكن هناك أمل في المستقبل.
تعرف على المزيد حول تقنية تشفير GAN
نشرت جوجل ورقة بحثية في عام 2016 بعنوان "تعلم حماية الاتصالات باستخدام التشفير العصبي العدائي"تقدم هذه المقالة بالتفصيل تقنية تشفير تعتمد على GAN، والتي يمكنها حل مشكلة حماية البيانات بشكل فعال في عملية مشاركة البيانات.
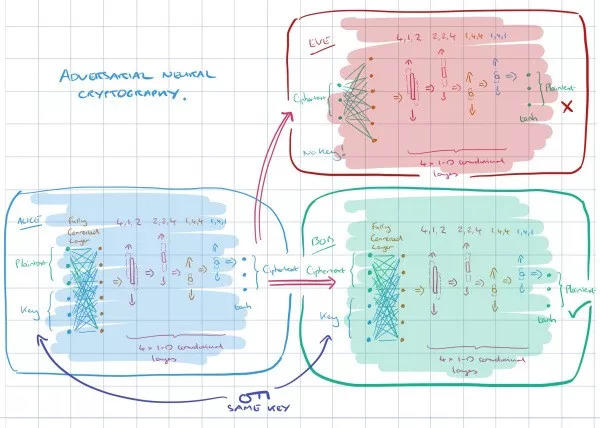
هذه تقنية تشفير تعتمد على الشبكات العصبية، والتي عادة ما يعتبر استخدامها للتشفير صعبًا لأنها تواجه صعوبة في إجراء عمليات XOR.
ولكن اتضح أن الشبكات العصبية يمكنها أن تتعلم كيفية الحفاظ على سرية البيانات من الشبكات العصبية الأخرى: فهي تستطيع اكتشاف جميع طرق التشفير وفك التشفير دون الحاجة إلى إنشاء خوارزميات للتشفير أو فك التشفير.
كيف يحمي تشفير GAN البيانات
تتضمن تقنية تشفير GAN ثلاثة جوانب، والتي يمكننا توضيحها باستخدام Alice وBob وEve. عادةً ما يكون أليس وبوب طرفي اتصال آمن، وتقوم إيف بمراقبة اتصالهما وتحاول العثور على معلومات البيانات الأصلية بطريقة عكسية.
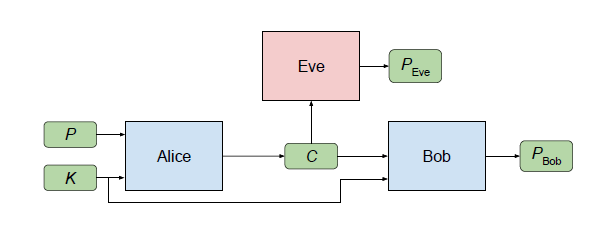
ترسل أليس إلى بوب رسالة سرية P، أدخلتها أليس. عندما تقوم أليس بمعالجة هذا الإدخال، فإنها تنتج إخراجًا C ("P" تعني "نص عادي" و"C" تعني "نص مشفر").
يتلقى كل من بوب وإيف C ويحاولان استرداد P من C (نشير إلى هذه الحسابات بواسطة PBob وPEve، على التوالي).
بوب لديه ميزة على إيف: وهو وأليس يتقاسمان مفتاحًا سريًا K.
الهدف من Eve بسيط: إعادة بناء P بشكل دقيق (بعبارة أخرى، تقليل الخطأ بين P وPEve).
يريد أليس وبوب التواصل بوضوح (لتقليل الخطأ بين P وPبوب)، ولكنهما يريدان أيضًا إخفاء تواصلهما عن إيف.
من خلال تقنية GAN، يتم تدريب أليس وبوب معًا، وينقلان المعلومات بنجاح أثناء التعلم على تجنب مراقبة إيف. لا تستخدم العملية بأكملها أي خوارزمية محددة مسبقًا. بموجب مبدأ GAN، تم تدريب أليس وبوب على التغلب على أفضل حواء، بدلاً من حواء ثابتة.
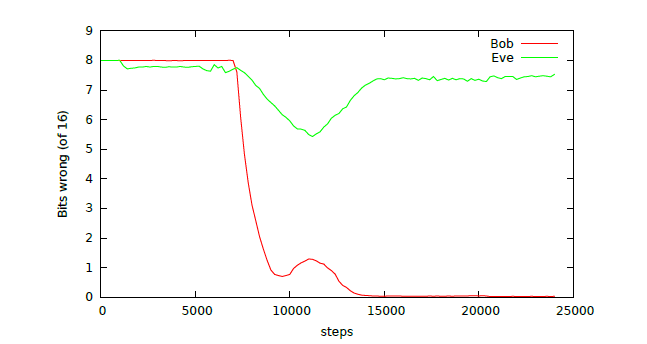
كما هو موضح في الشكل أدناه، بعد حوالي 8000 خطوة تدريبية، يمكن لكل من بوب وإيف البدء في إعادة بناء الرسالة الأصلية. بعد حوالي 10000 خطوة تدريبية، يبدو أن شبكات أليس وبوب تكتشف إيف وتبدأ في التدخل معها، مما يتسبب في ارتفاع معدل خطأ إيف. وهذا يعني أن بوب قادر على التعلم من سلوك إيف وحماية الاتصالات، وتحقيق إعادة بناء دقيقة للرسالة مع تجنب الهجمات.
وبالعودة إلى تطبيقات الذكاء الاصطناعي، يمكن استخدام تقنية تشفير GAN لتبادل المعلومات بين الشركات والشبكات العصبية دون الحفاظ على مستوى عالٍ من الخصوصية. إنه حل عملي لحماية البيانات لتطبيقات الذكاء الاصطناعي.
لأن النموذج يمكنه أن يتعلم كيفية حماية المعلومات بشكل انتقائي، وترك بعض عناصر مجموعة البيانات غير مشفرة، ولكن منع أي شكل من أشكال الاستدلال من العثور على هذه البيانات الحساسة، وبالتالي التحايل بشكل فعال على أوجه القصور في إخفاء هوية البيانات.
قام فريق Google بتكييف بنية تشفير GAN في نموذج حيث لا يزال أليس وبوب يتشاركان مفتاحًا، ولكن أليس هنا تتلقى A وB وC وتولد D-public من النص المشفر.
يمكن لكل من بوب وإيف الوصول إلى مخرجات أليس D-public. يستخدم بوب هذه الأدوات لتوليد تقدير محسّن لـ D، ويسمح لإيف بالعمل بشكل عكسي لاستعادة C من هذا التقريب. الهدف هو إثبات أن التدريب العكسي يسمح بتقريب D دون الكشف عن C، وأن هذا التقريب يمكن دمجه مع معلومات مشفرة ومفتاح لإرباك Eve بشكل أفضل.
وللتحقق من قدرة النظام على إخفاء المعلومات بشكل صحيح، أنشأ الباحثون أداة تقييم أطلقوا عليها اسم "Blind Eve". إنه يعرف C، لكنه لا يعرف D-public والمفتاح، وهو ما تعرفه Eve.
إذا كان خطأ إعادة بناء حواء مساويًا لخطأ إعادة بناء حواء العمياء، فهذا يعني أن حواء لم تستخرج المعلومات الصالحة بنجاح. بعد بضع جلسات، لم تعد إيف تتمتع بأي ميزة على إيف العمياء. يوضح هذا أن Eve لا تستطيع إعادة بناء أي معلومات حول C بمجرد معرفة توزيع قيم C.
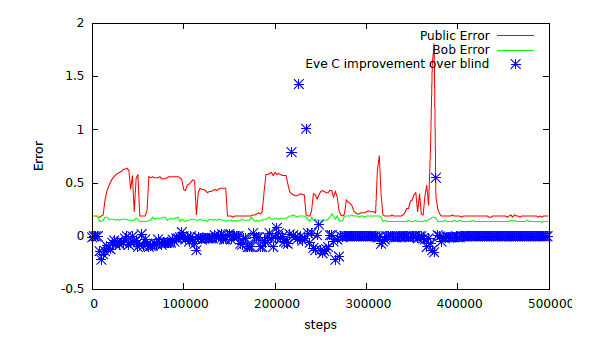
في الوقت الحاضر، تعد تقنية تشفير GAN تقنية جديدة نسبيًا في تطبيقات الذكاء الاصطناعي السائدة. ولكن من الناحية النظرية، قد تسمح تقنية تشفير GAN للشركات بمشاركة مجموعات البيانات مع علماء البيانات دون الكشف عن البيانات الحساسة الموجودة بداخلها.
وعلى المدى الطويل، إذا كنت تريد كسب ثقة المستخدم وتقليل الأزمات القانونية، فإن تقنية التشفير تأتي في المرتبة الثانية. الأمر الأكثر أهمية بالنسبة لشركات الإنترنت هو احترام خصوصية المستخدم واستخدامها بشكل معقول.








