Command Palette
Search for a command to run...
واقترح فريق معهد ماساتشوستس للتكنولوجيا نموذج FASTSOLV، وهو أسرع بـ 50 مرة من النموذج الأصلي، للتنبؤ بذوبان الجزيئات الصغيرة في أي درجة حرارة.

في مجالات الكيمياء وعلوم المواد، تُعدّ ذوبانية المواد الصلبة العضوية في مختلف المذيبات خاصية جزيئية أساسية، تؤثر على سلسلة البحث والصناعة بأكملها. في العمليات التركيبية، لا يُساعد التحكم الدقيق في الذوبانية على اختيار المذيب الأمثل وتحسين ظروف التفاعل فحسب، بل يُحسّن أيضًا إنتاجية المنتج ونقائه بشكل ملحوظ، مما يُقلل تكاليف الإنتاج. في العلوم البيئية، تُعدّ الذوبانية معيارًا أساسيًا لتحليل انتقال ومصير الملوثات، مثل مواد البيرفلورو ألكيل والبولي فلورو ألكيل (PFAS)، في التربة والمياه، مما يُوفر أساسًا علميًا للوقاية من التلوث ومكافحته. وفي عمليات مثل التبلور وفصل الأغشية، تُعدّ الذوبانية متغيرًا أساسيًا يُحدد سلوك الطور وكفاءة الفصل.
ومع ذلك، فإن طرق التحديد التجريبية التقليدية لها العديد من القيود: فهي لا تستغرق وقتًا طويلاً وتستهلك موادًا فحسب، بل تتداخل معها بسهولة عوامل مثل شكل البلورات الصلبة العضوية والشوائب، مما يؤدي إلى عدم دقة البيانات. ووفقًا للدراسات، فإن الانحراف المعياري بين المختبرات لسجلات ذوبان الماء (logS) غالبًا ما يتراوح بين 0.5 و0.7 وحدة لوغاريتمية، وفي الحالات القصوى، قد يتجاوز الفرق في نتائج القياس 10 أضعاف. على الرغم من تطبيق أساليب إضافة المجموعات التجريبية، والنماذج الكيميائية الكمومية، وأساليب التعلم الآلي في التنبؤ،ومع ذلك، غالبًا ما تكون هناك مشكلات تتعلق بعدم كفاية التنوع أو صعوبة تحقيق التوازن بين الدقة والكفاءة الحسابية.
ولمعالجة هذه النقطة المؤلمة، قام فريق بحثي من معهد ماساتشوستس للتكنولوجيا بدمج أدوات المعلوماتية الكيميائية مع قاعدة بيانات الذوبان العضوي الجديدة BigSolDB.تم تحسينه على أساس بنية النموذج FASTPROP وCHEMPROP،يمكن للنموذج إدخال جزيئات المواد المذابة وجزيئات المذيبات ومعلمات درجة الحرارة في وقت واحد، وإجراء تدريب الانحدار بشكل مباشر على logS.
في سيناريو استقراء المواد المذابة الصارم، بالمقارنة مع نماذج SOTA الحالية مثل Vermeire،تم تقليل RMSE للنموذج الأمثل بمقدار 2-3 مرات، وتم زيادة سرعة الاستدلال بما يصل إلى 50 مرة.حاليًا، أطلق الفريق على نموذج المشتق FASTPROP اسم FASTSOLV وأصدره كمصدر مفتوح، مما يوفر أداة فعالة وعملية للبحث العلمي والتطبيقات الصناعية ذات الصلة.
وقد نُشرت نتائج البحث ذات الصلة في مجلة Nature Communication تحت عنوان "التنبؤ بالذوبان العضوي القائم على البيانات عند حد عدم اليقين العشوائي".

عنوان الورقة:
https://www.nature.com/articles/s41467-025-62717-7
اتبع الحساب الرسمي ورد "الذوبان العضوي" للحصول على ملف PDF كامل
تصميم نظام بناء وتقييم مجموعة البيانات الموجه بواسطة BigSolDB
المصدر الأساسي للبيانات لهذه الدراسة هو BigSolDB، الذي يجمع بشكل منهجي بيانات ذوبان المواد الصلبة العضوية في مجموعة متنوعة من المذيبات العضوية وفي ظل ظروف درجات حرارة مختلفة قريبة من حد هطول الأمطار، مما يوفر دعمًا رئيسيًا لتدريب نماذج التنبؤ العامة.
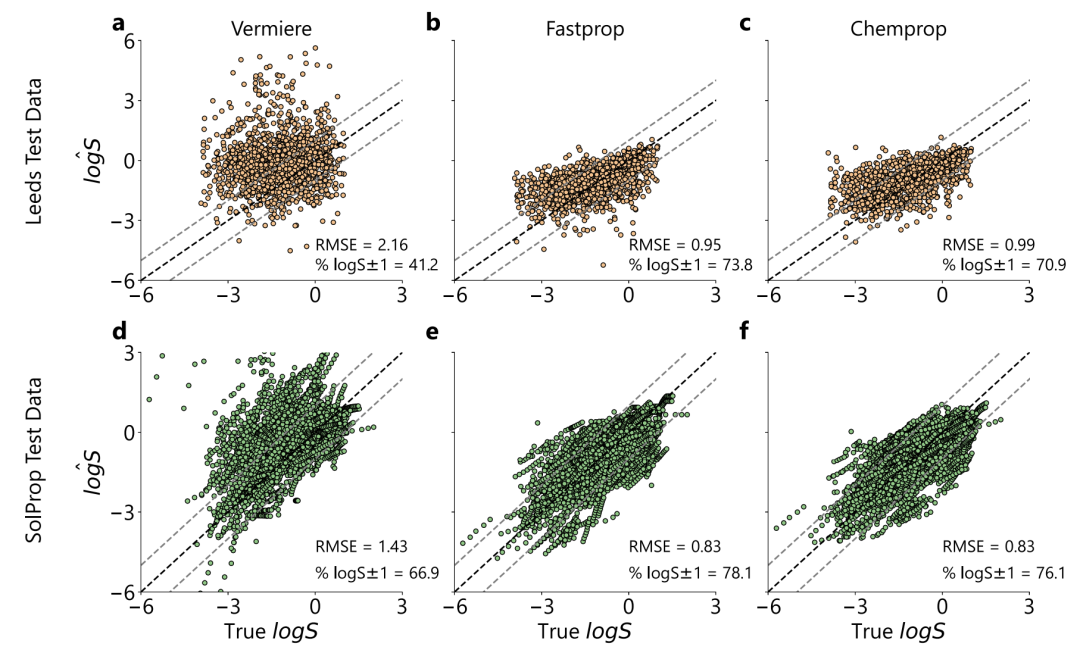
لتحقيق هدف البحث المتمثل في "استقراء مواد مذابة جديدة دون أي معرفة مسبقة"، صمم فريق البحث نظامًا صارمًا للتدريب والتقييم:تم تدريب النموذج على BigSolDB وتم اختباره بشكل مستقل على مجموعتين من البيانات العامة: SolProp و Leeds.لتجنب التقليل من صعوبة الاستقراء، كما هو موضح في الشكل أدناه، قامت هذه الدراسة أولاً بإزالة جميع المواد المذابة في SolProp التي تتداخل مع BigSolDB، وقدمت مجموعة بيانات ليدز مع مساحة كيميائية أوسع كمكمل.
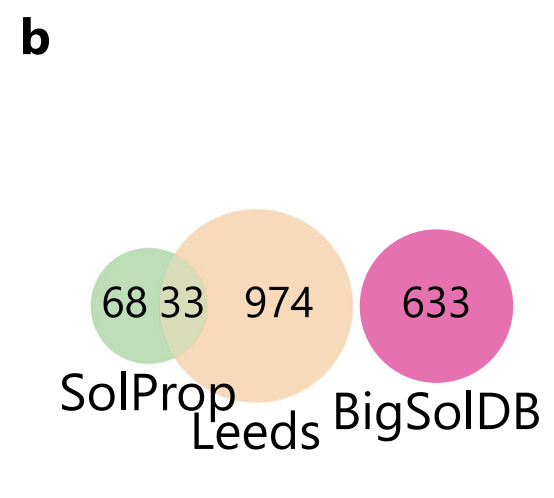
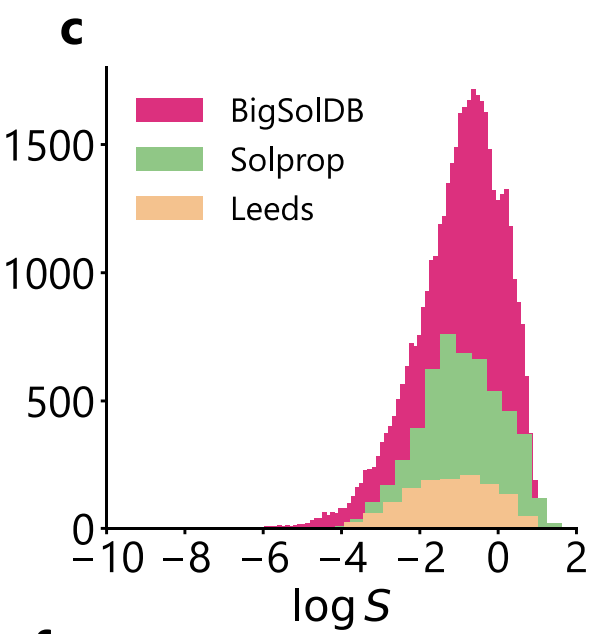
بالمقارنة مع SolProp،يوفر ليدز تنوعًا أعلى للمذاب ولكنه يغطي فقط ظروف درجة حرارة الغرفة.هذا لا يسمح فقط باختبار قدرة النموذج على التكيف مع المساحات الكيميائية الجديدة، بل يوفر أيضًا حدًا أعلى لعدم اليقين نظرًا لعدم وجود تقليل ضمني للضوضاء من "متوسط درجات الحرارة المتعددة". والجدير بالذكر، كما هو موضح في الشكل أدناه، أن توزيعات logS لمجموعات البيانات الثلاث متسقة للغاية، حيث تتركز جميعها بالقرب من -1 وتُظهر ذيلًا طويلًا عند الطرف ذي الذوبانية المنخفضة، مما يضمن قابلية المقارنة التوزيعية لمقارنات الأداء عبر مجموعات البيانات.
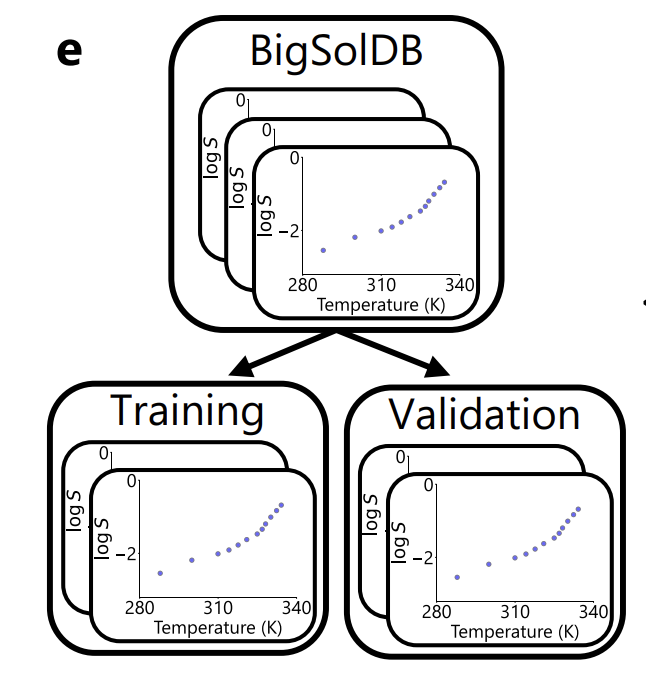
من حيث تقسيم البيانات، كما هو موضح في الشكل أدناه، يستخدم الباحثون المذاب بشكل صارم كوحدة: يتم استخدام 95% من المذاب للتدريب، ويتم استخدام 5% للتحقق واختيار النموذج،لن تظهر جميع قياسات نفس المذاب في مذيبات ودرجات حرارة مختلفة في مجموعات فرعية مختلفة في نفس الوقت.وهذا يتجنب تسرب المعلومات بشكل فعال.
بالإضافة إلى ذلك، استخدمت الدراسة مجموعة أدوات ASTARTES لتقسيم مجموعة التحقق بشكل عشوائي إلى "تجارب كاملة" في بيانات التدريب، وإعادة التحقق من حدود التقسيم من كل من أبعاد المذاب والأبعاد التجريبية في التقييم النهائي لضمان استقلالية ودقة التقييم.
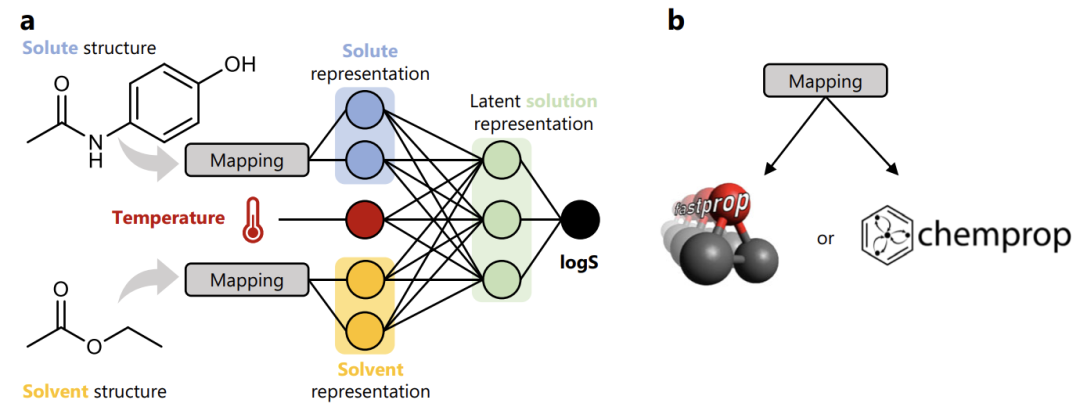
بناء نموذج FASTSOLV مدفوعًا بـ BigSolDB
بالاعتماد على مجموعة بيانات BigSolDB، كما هو موضح في الشكل أدناه، قامت هذه الدراسة بتخصيص نموذجي الهندسة المعمارية الكلاسيكيين FASTPROP وCHEMPROP وبناء عملية نمذجة التعلم الآلي الواضحة.
أولاً،قم برسم خريطة للهياكل الجزيئية للمواد المذابة (مثل الباراسيتامول) والمذيبات (مثل أسيتات الإيثيل) في متجهات التمثيل المقابلة؛ثم،يتم دمج هذين المتجهين التمثيليين الجزيئيين مع معلمة درجة حرارة المحلول لتشكيل تمثيل كامل للحل.أخير،تم إدخال التمثيل في شبكة عصبية متصلة بالكامل وتم إجراء تدريب الانحدار مع logS (لوغاريتم الذوبان) كهدف.
ومن خلال هذا التحويل، تمكن النموذج الذي تم تطويره أخيرًا من تحقيق تنبؤ موحد بذوبان الجزيئات الصغيرة في مذيبات عضوية متعددة + سيناريوهات درجات حرارة مختلفة، وهو ما يكسر اعتماد النموذج التقليدي على مذيبات محددة أو نطاقات درجات حرارة.
ولتحسين قوة ومتانة النموذج وموثوقيته التنبؤية بشكل أكبر، لم يعتمد فريق البحث على مخرجات نموذج واحد.بدلاً من ذلك، يتم تدريب نموذج FASTPROP تحت أربعة ظروف تهيئة عشوائية مختلفة، ويتم الحصول على نموذج FASTSOLV النهائي من خلال الجمع بين استراتيجية التكامل.وتستند جميع التحليلات الرئيسية اللاحقة، مثل مقارنات الأداء والتحقق من الحالات، إلى هذا النموذج المتكامل، مما يقلل بشكل فعال من خطر التقلب العشوائي لنموذج واحد.
في الوقت نفسه، ولقياس أداء النموذج الجديد بموضوعية، قدمت الدراسة نموذج SOTA المعروف حاليًا على نطاق واسع، وهو نموذج Vermeire، كمعيار للمقارنة. يُدرَّب هذا النموذج من خلال أربعة نماذج فرعية كيميائية حرارية مستقلة، ثم يُخرِج نتائج الذوبانية من خلال دمج الدورة الديناميكية الحرارية. يتميز هذا النموذج بموازنة تنوع المذيبات والاعتماد على درجة الحرارة. ومع ذلك، وجدت الدراسة أن مجموعة بيانات SolProp المستخدمة في الاختبار تحتوي على قدر كبير من تداخل بنية المذاب مع مجموعة التدريب الخاصة بها. قد يؤدي هذا "التداخل في البيانات" إلى المبالغة في تقدير الأداء المُستَقرَأ. لضمان الإنصاف والدقة في المقارنة، أعادت هذه الدراسة إنتاج إعدادات التدريب والاختبار الأصلية لنموذج Vermeire بدقة، وأجرت تجارب تحكم على هذا الأساس لضمان أن يكون فرق الأداء ناتجًا فقط عن النموذج نفسه وليس عن ظروف الاختبار.
تحديث استقراء الذوبان العضوي SOTA بدقة أكبر بمقدار 2-3 مرات وسرعة أكبر بمقدار 50 مرة
أجرت هذه الدراسة اختبارًا متعدد الأبعاد وتحققًا من أداء النموذج. في سيناريو الاستيفاء، حقق نموذج FASTPROP المُحسَّن قيمة RMSE = 0.22، P₁ = 94%، وحقق نموذج CHEMPROP قيمة RMSE = 0.28، P₁ = 90%.اقترب الأداء من سقف الضوضاء للبيانات التجريبية، مما يؤكد القيمة الداعمة لـ BigSolDB.
في اختبار استقراء المذاب الجديد، كما هو موضح في الشكل أدناه، كان أداء نموذج فيرمير ضعيفًا في مجموعة بيانات ليدز بسبب المبالغة المنهجية في التقدير (RMSE=2.16، P₁=34%)، بينما انخفض RMSE لـ FASTPROP وCHEMPROP إلى 0.95 و0.99 على التوالي، وتجاوز P₁ قيمة 69%. أما في مجموعة بيانات SolProp، فقد كان أداء نموذجنا أفضل أيضًا (RMSE=0.83، P₁=80%).وتبلغ سرعة الاستدلال لـ FASTPROP حوالي 50 ضعف سرعة نموذج Vermeire.يدعم تحليل قابلية تفسير SHAP.
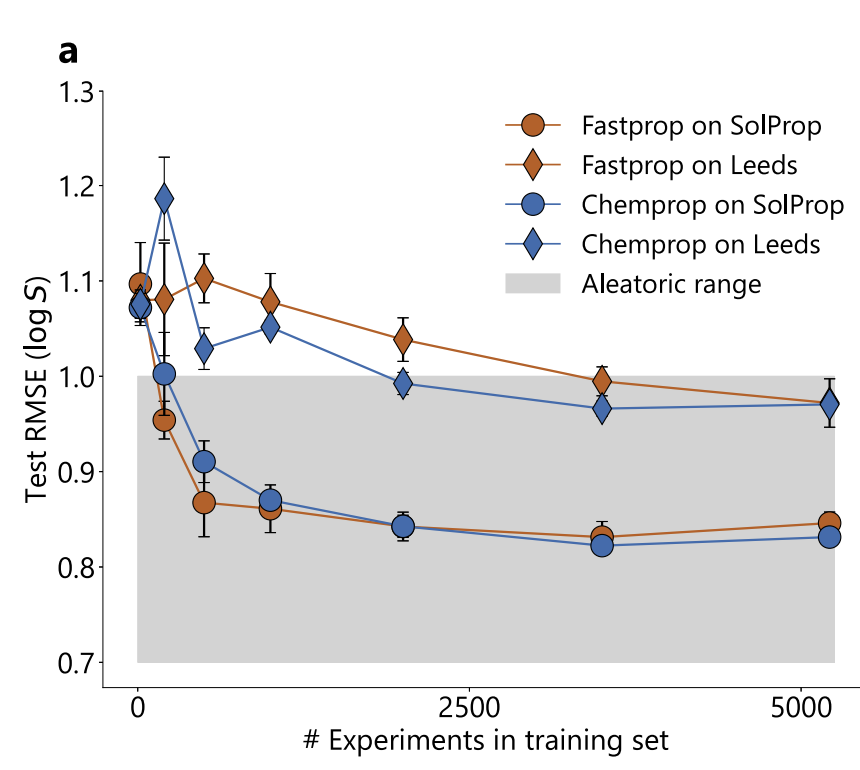
يظهر الشكل أدناه تجربة حجم بيانات التدريب. على الرغم من اختلاف تمثيلات FASTPROP وCHEMPROP الجزيئية، إلا أن أداءهما يتقارب إلى حدود متشابهة: تتطلب مجموعة اختبار SolProp حوالي 500 تجربة (حوالي 5000 نقطة بيانات) للوصول إلى نقطة الثبات، بينما تتطلب CHEMPROP حوالي 2000 تجربة (حوالي 20000 نقطة بيانات) على مجموعة اختبار ليدز.
تم تقدير حد عدم اليقين العشوائي التجريبي من 34 مجموعة من البيانات متعددة المصادر في ظل نفس الظروف في BigSolDB، وهو RMSE = 0.75 وحدة لوغاريتمية، في حين أن RMSE للنموذجين على SolProp هو 0.83، وهو قريب من هذا الحد؛ وبالمقارنة مع النماذج الكبيرة مثل MolFormer وChemBERTa-2، فإن النموذجين يعملان بشكل أفضل.يثبت أن عنق الزجاجة في الأداء يأتي من البيانات التجريبية وليس من قدرة النموذج على التعبير.
اختبار متوسط أداء النموذج عند حدود تعسفية
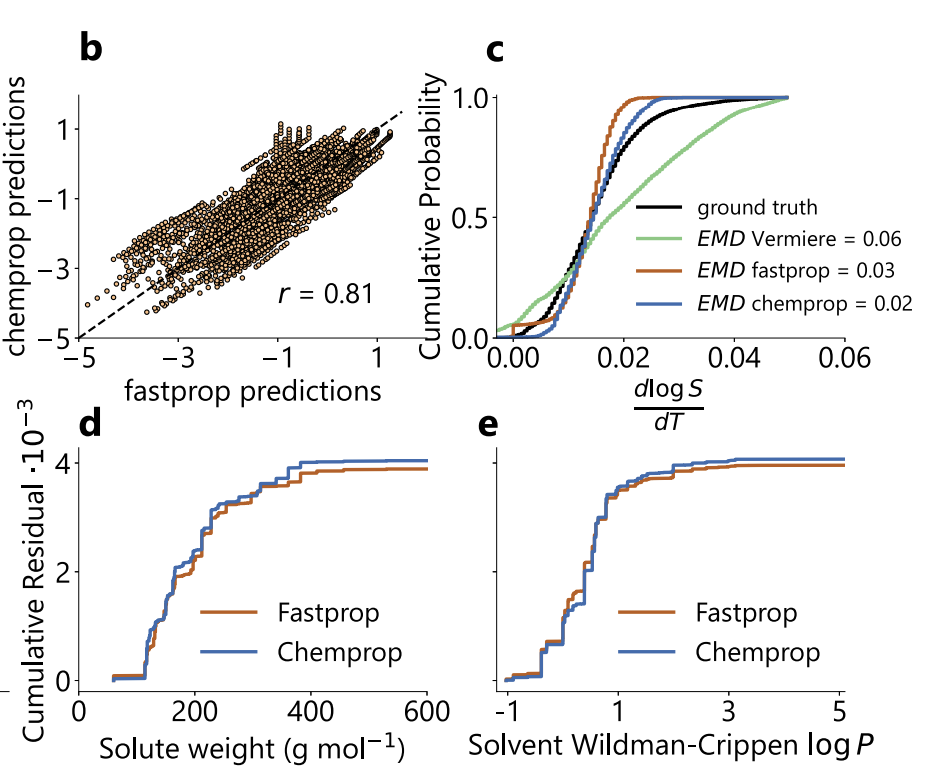
بالإضافة إلى ذلك، وكما هو موضح في الشكل أدناه، يمتلك النموذجان تنبؤات مترابطة للغاية على مجموعة اختبار SolProp (معامل ارتباط بيرسون = 0.81)، كما أن توزيعات تدرج درجة الحرارة المتوقعة متسقة للغاية (EMD = 0.03/0.02). الخطأ المنهجي أقل بكثير من خطأ نموذج فيرمير (EMD = 0.06).
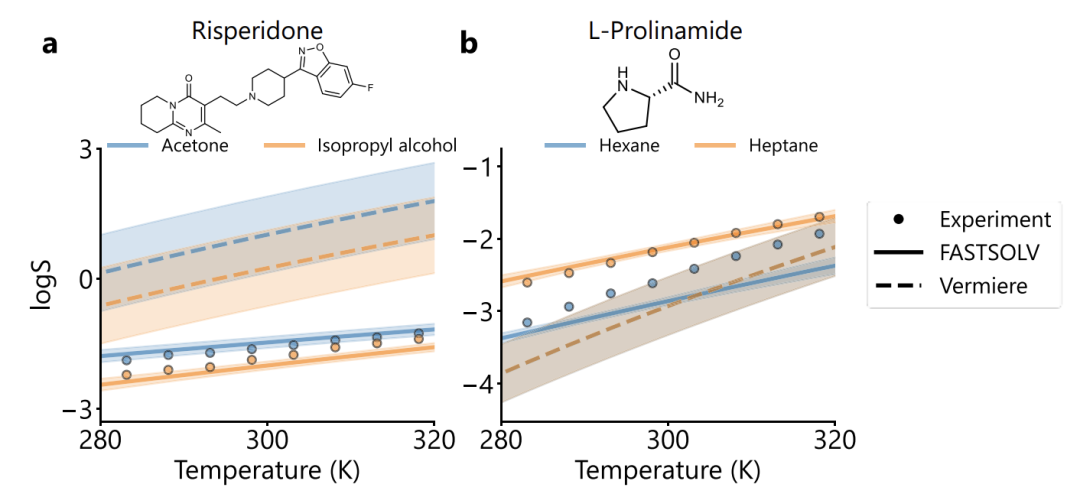
ووجدت الدراسة أيضًا أنه في التحقق النموذجي للمذاب، كما هو موضح في الشكل أدناه، يتمتع FASTSOLV بميزة كبيرة في التنبؤ بالريسبيريدون (RMSE = 0.16 مقابل Vermeire 1.64) و L-proline (RMSE = 0.25 مقابل Vermeire 2.33).لا يمكنه فقط تحديد ترتيب ودرجة حرارة ذوبان المذيبات بشكل صحيح، بل يمكنه أيضًا التمييز بين الهكسان والهبتان، اللذين لهما هياكل مماثلة.أظهر تحليل وضع الفشل أن خطأ التنبؤ بالأنثراكينونات كان مرتفعًا، ولكن في مجموعة فرعية من 85 مشتقًا من الأنثراكينون/الأنثراكينون، كان متوسط خطأ التربيع الجذري الإجمالي للنموذج 0.52، ويمكن تصنيف ذوبان المذيبات بشكل مستقر، مما يشير إلى أن التوصيف الجزيئي كان معقولاً.
في ملخص،وبالمقارنة مع نموذج Vermeire، فإن FASTSOLV يقلل من RMSE بمقدار 2-3 مرات ويسرع الاستدلال بما يصل إلى 50 مرة.تجمع هذه الطريقة بين سهولة التفسير والإمكانات الهندسية، مما يُمثل أداءً متطورًا في ظل ظروف استقراء صارمة. وتشير الدراسة أيضًا إلى أن إضافة بيانات تدريب إضافية لن تتجاوز حدود الأداء، وستركز الأبحاث المستقبلية على بناء مجموعة بيانات عالية الدقة للمذيبات العضوية.
"مجموعة البيانات + الذكاء الاصطناعي" تقود تقدمًا عالميًا في التنبؤ بالخصائص الجزيئية
في موجة اليوم من الابتكار المتبادل في الكيمياء والطب وعلوم المواد، أصبحت تكنولوجيا التنبؤ بالخصائص الجزيئية، التي تركز على "مجموعات البيانات واسعة النطاق + نماذج التعلم الآلي المتقدمة"، أداة رئيسية لمعالجة نقاط الضعف في الصناعة مثل التجارب التي تستغرق وقتًا طويلاً، وتكاليف البحث والتطوير المرتفعة، وصعوبة التنبؤ بالأداء.
في الأوساط الأكاديمية، تستجيب فرق بحثية حول العالم لاختراقات FASTSOLV وBigSolDB بإطلاق سلسلة من الدراسات المبتكرة للتنبؤ بالذوبان. على سبيل المثال، اقترح باحثون في جامعة ليدز بالمملكة المتحدة نموذجًا للعلاقة السببية بين البنية والخصائص، يجمع بين الذكاء الاصطناعي والآليات الفيزيائية والكيميائية.إن التنبؤ بالذوبانية في نظام المذيبات العضوية والماء دقيق تقريبًا مثل الخطأ التجريبي.كما أنها تتمتع بقدرة متميزة على التفسير وتعتبر إنجازًا مهمًا في مجال نمذجة الذوبان.
في غضون ذلك، أحرز فريق بحثي في معهد ماساتشوستس للتكنولوجيا (MIT) تقدمًا ملحوظًا في اكتشاف المضادات الحيوية باستخدام الشبكة العصبية البيانية Chemprop. وحددوا نشاط المضادات الحيوية وأنماط السمية الخلوية البشرية لـ 39,312 مركبًا، واستخدموا مجموعات الشبكات العصبية البيانية للتنبؤ بنشاط المضادات الحيوية وسمية الخلايا لـ 12,076,365 مركبًا لاكتشاف مضادات حيوية جديدة. ومن خلال فحص مجموعة من المركبات الأولية وتقييم نشاطها المثبط للنمو ضد سلالة المكورات العنقودية الذهبية الحساسة للميثيسيلين RN4220،تم الحصول على 512 مركبًا فعالًا.يتم بعد ذلك تدريب الشبكة العصبية البيانية لأداء تنبؤات التصنيف الثنائي.
في صناعة الأدوية، تبرز ابتكاراتٌ بارزةٌ أيضًا. لطالما ركّزت صناعة الأدوية على تقنيات تقييم الذوبان عالية الإنتاجية ومنخفضة التكلفة. على سبيل المثال، تستطيع أداة Aspen Solubility Modeler من AspenTech التنبؤ بالذوبان في مئات من تركيبات المذيبات بناءً على بيانات مُقاسة في عدد قليل من المذيبات. تُحسّن هذه الأداة بشكل كبير كفاءةَ وموثوقيةَ اتخاذ القرارات في فحص البلورات وتطوير العمليات في شركاتٍ كبرى مثل GSK وAstraZeneca.
بالإضافة إلى ذلك، تستفيد بعض الشركات من نماذج مماثلة قائمة على البيانات في مجال البحث والتطوير في مجال المواد. فمن خلال تحليل كميات كبيرة من بيانات البنية الجزيئية والأداء، تتنبأ هذه الشركات بخصائص المواد الجديدة، مما يُختصر دورات البحث والتطوير، ويُخفض تكاليفه. وفي قطاع الصناعات الكيميائية، تستخدم بعض الشركات نماذج للتنبؤ بآثار التفاعلات الكيميائية في ظل ظروف مذيبات ودرجات حرارة مختلفة، مما يُحسّن عمليات الإنتاج ويرفع كفاءته وجودة المنتج. وهذه كلها أمثلة على شركات تُطبّق نماذج ومفاهيم بيانات من البحث الأكاديمي على ابتكارات الإنتاج الفعلية.
روابط مرجعية:
2.https://www.manufacturingchemist.com/news/article_page/Solubility_modelling/57726
احصل على أوراق بحثية عالية الجودة ومقالات تفسيرية متعمقة في مجال AI4S من عام 2023 إلى عام 2024 بنقرة واحدة⬇️









