Command Palette
Search for a command to run...
تُدمج العناصر البدائية على مستوى البلاط مع آليات التفكير الآلي. يُجري مُنشئ مجتمع TileAI تحليلًا مُعمّقًا للتقنية الأساسية ومزايا TileLang.

في الخامس من يوليو، اختُتم بنجاح في بكين المؤتمر السابع لتقنيات مُجمِّعي الذكاء الاصطناعي. شارك خبراء من القطاع في أحدث التطورات والتجارب العملية والتطبيقية، بينما شرح باحثون من الجامعات بالتفصيل مسارات تطبيق التقنيات المبتكرة ومزاياها.
في،ألقى الدكتور وانج لي، مؤسس مجتمع TileAI، خطابًا بعنوان "ربط قابلية البرمجة والأداء في أحمال عمل الذكاء الاصطناعي الحديثة".تم تقديم لغة برمجة المشغل المبتكرة TileLang بطريقة سهلة الفهم، ومشاركة مفاهيم التصميم الأساسية والمزايا التقنية.
يهدف TileLang إلى تحسين كفاءة برمجة نواة الذكاء الاصطناعي، بفصل مساحة الجدولة (بما في ذلك ربط الخيوط، والتخطيط، والتنسوريز، وخط الأنابيب) عن تدفق البيانات، وتغليفها بمجموعة من التعليقات التوضيحية والعناصر الأولية القابلة للتخصيص. يتيح هذا النهج للمستخدمين التركيز على تدفق بيانات النواة نفسه، مع ترك معظم أعمال التحسين الأخرى للمترجم.
وتظهر نتائج التقييم أنيحقق TileLang أداءً رائدًا في الصناعة على العديد من النوى الرئيسية.إنه يوضح بشكل كامل نموذج البرمجة الموحد Block-Thread وقدرات الجدولة الشفافة، والتي يمكن أن توفر الأداء والمرونة المطلوبين لتطوير أنظمة الذكاء الاصطناعي الحديثة.
قامت HyperAI بتجميع وتلخيص الخطاب دون المساس بالقصد الأصلي. فيما يلي نص الخطاب.
اتبع حساب WeChat العام "HyperAI Super Neuro" وأجب على الكلمة الرئيسية "0705 AI Compiler" للحصول على عرض تقديمي للمحاضر المعتمد PPT.
لماذا نحتاج إلى "DSL جديد"؟
يقدم هذا التشارك بشكل أساسي DSL TileLang الجديد لأحمال عمل الذكاء الاصطناعي والذي قام فريقنا بتوفيره مفتوح المصدر على GitHub في يناير 2025.
أولاً، أود أن أتحدث إليكم عن سبب حاجتنا إلى خدمة DSL جديدة؟
من وجهة نظري الشخصية، خلال فترة تدريبي في مايكروسوفت، شاركتُ في مشروع BitBLAS لدراسة الحوسبة متعددة الدقة. في ذلك الوقت، كان المشروع يعتمد بشكل أساسي على تقنية TVM/Tensor IR، وحقق في النهاية نتائج تجريبية ممتازة. ومع ذلك، وجدنا أنه لا يزال يعاني من العديد من المشاكل، مثل صعوبة الصيانة. لكل عملية، مثل حساب طبقة المصفوفة متعددة الدقة، كتبتُ 500 سطر من بدائيات الجدول. على الرغم من كتابته بشكل أنيق،لكنني الوحيد الذي يمكنه فهم رمز الجدولة هذا، ومن الصعب العثور على آخرين للحفاظ عليه أو توسيعه.
بالإضافة إلى ذلك، وجدتُ صعوبةً في وصف المتطلبات أو التحسينات الجديدة بناءً على جدولة IR. على سبيل المثال، أثناء عملي على النواة، كتبتُ ثلاثة مُشغلات جدولة أساسية للمساعدة في تحسين البرنامج، بما في ذلك الانتباه الفوري والانتباه الخطي، إلخ. كان من الصعب وصف هذه المُشغلات بناءً على الجدولة. لذلك، فكرتُ آنذاك أنه إذا استمر المشروع في التوسع، فقد لا يُجدي استخدام TIR نفعًا، وأن هناك حاجةً إلى حلول أخرى.
فلماذا لا تريتون؟
لقد جربت تريتون أيضًا،لكنني وجدت صعوبة في تخصيص نواة عالية الأداء.على سبيل المثال، عند كتابة مُعامل Dequantize، قد أحتاج إلى التحكم في سلوك كل خيط. ولا تزال كيفية تنفيذ Dequantize لكل خيط على نواة عالية الأداء أمرًا بالغ الدقة.
الطريقة الثانية هي تخزين المخزن المؤقت في نطاق ذاكرة مناسب.على سبيل المثال، في بعض وحدات معالجة الرسومات، يُفضّل تخزين البيانات مؤقتًا في سجلات لتحليلها ثم كتابتها في الذاكرة المشتركة، بينما في وحدات أخرى، يُفضّل كتابتها مباشرةً إلى الذاكرة المشتركة. لكن التحكم في ذلك على تريتون صعب.
أخيرا،أعتقد أن مؤشر تريتون معقد بعض الشيء.على سبيل المثال، إذا كنت بحاجة إلى تخزين Tile مؤقتًا في Local، فأنت بحاجة إلى كتابة الكود الموضح على الجانب الأيسر من الشكل أدناه، ولكن على Tensor IR يمكنك استخدام المؤشرات للفهرسة كما هو موضح على اليمين، وهو ما أعتقد أنه جيد جدًا.
وبناءً على ذلك، وجدت أن خطوط DSL الحالية لا تستطيع تلبية احتياجاتي، لذا أردنا إنشاء خط DSL مبتكر يدعم المزيد من الخوادم الخلفية والمشغلين المخصصين ويحقق أداءً أفضل.لتحقيق أداء أفضل، من الضروري تحسين مساحات التصميم المختلفة مثل البلاط وخطوط الأنابيب.ولتحقيق هذه الغاية، اقترحنا مشروع TileLang.
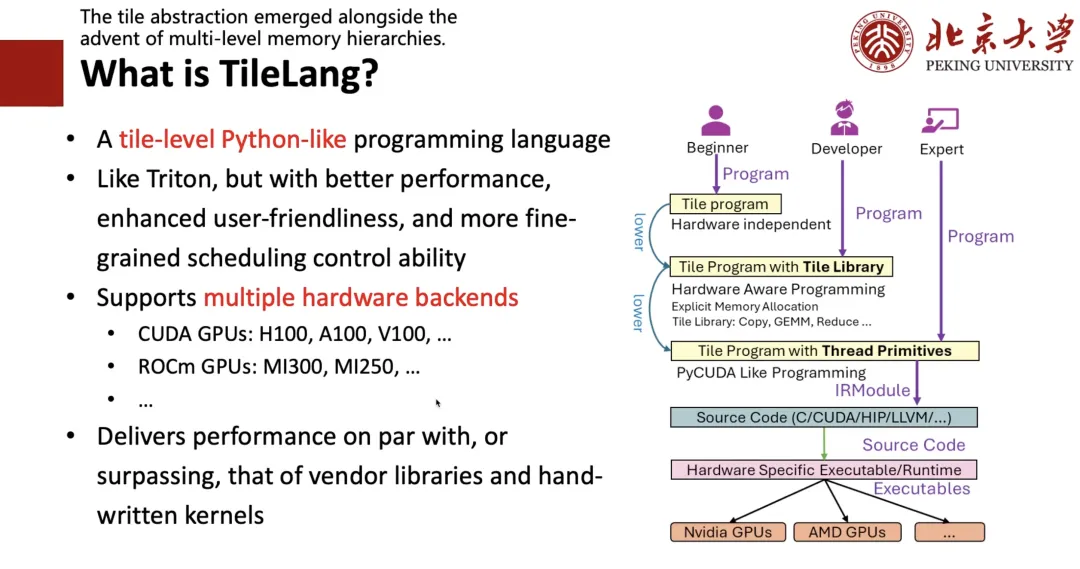
ما هو TileLang؟
لماذا "البلاط"؟
أولاً، وجدنا أن مفهوم "التايل" (Tile) بالغ الأهمية. ما دامت مكونات الجهاز تتضمن ذاكرة التخزين المؤقت (Cache) والسجلات والذاكرة المشتركة، فعند كتابة برامج عالية الأداء، يجب مراعاة استخدام كتل الحوسبة، أي "التايل". ثانياً، بما أن الجميع يميلون إلى كتابة برامج بايثون، فإننا نرغب في تصميم لغة برمجة شبيهة ببايثون، سهلة الكتابة مثل تريتون، وذات أداء أفضل.
ولتحقيق هذه الغاية، قمنا بتصميم الإطار الموضح على الجانب الأيمن من الشكل التالي:إذا كنت خبيرا،وهذا يعني أنه إذا كنت تعرف CUDA أو الأجهزة بشكل جيد، فيمكنك كتابة التعليمات البرمجية منخفضة المستوى مباشرة؛إذا كنت مطورًا،وهذا يعني أنه إذا كنت تستطيع كتابة تريتون وفهم مفاهيم مثل البلاط والسجل، فيمكنك كتابة برنامج على مستوى البلاط تمامًا مثل كتابة تريتون؛إذا كنت مبتدئًا لا تعرف شيئًا عن الأجهزة ولا تعرف سوى الخوارزميات،يمكنك بعد ذلك كتابة تعبير عالي المستوى مثل كتابة TRL، ثم استخدام الجدولة التلقائية لخفضه إلى الكود المقابل.
كما هو موضح في الشكل أدناه، فإن جدول Dequant على اليسار مكتوب بواسطةي باستخدام TIR، والذي يمكن كتابته بسلاسة وبشكل مكافئ في شكل TileLang على اليمين، مما يحقق التعايش بين المستوى 1 والمستوى 2.

بعد ذلك، سأقدم القضايا التي يجب مراعاتها في تصميم TileLang.
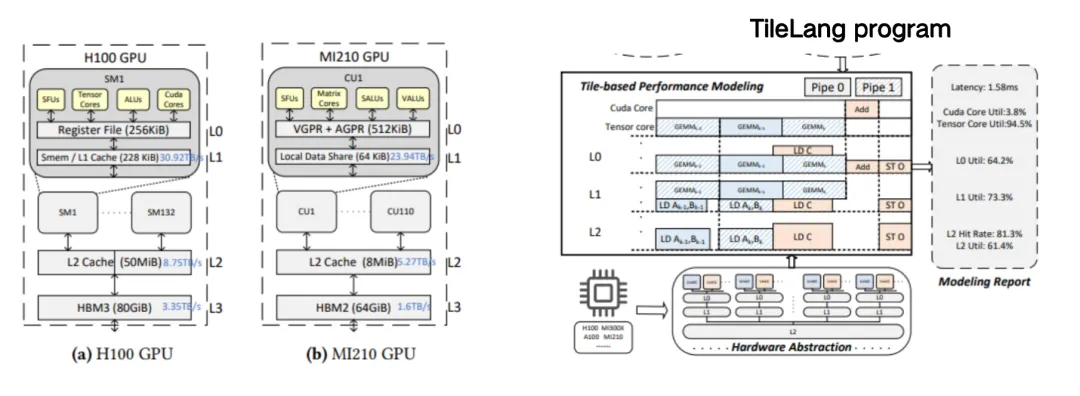
يُظهر الجانب الأيسر من الشكل أدناه تطبيق TileLang لـ DeepSeek MLA، والذي يتكون من حوالي 50 سطرًا من التعليمات البرمجية. في هذه النواة، نرى أن المستخدمين بحاجة إلى إدارة العديد من الأمور، مثل عدد الكتل (كتل الخيوط) المطلوب تحديدها لأداء مهام الحوسبة بالتوازي عند بدء تشغيل نواة وحدة معالجة الرسومات (وظيفة النواة)، وعدد الخيوط التي يجب تخصيصها لكل كتلة. هذا ما نسميه "تكوين البلاط"، أي أن لكل شيفرة برمجية سياقًا. يحتاج المستخدمون إلى التحكم في نطاق الذاكرة الذي يوجد عليه المخزن المؤقت، وتحديد تخطيط الذاكرة المشتركة أو السجلات، والاهتمام بخطوط الأنابيب، وما إلى ذلك. كل هذه تتطلب من المترجم مساعدة المستخدمين في إدارتها.

ولتحقيق هذه الغاية، نقسم مساحة التحسين إلى فئتين:الأول هو الاستدلال.وهذا يعني أن المترجم يساعد المستخدم بشكل مباشر على التوصل إلى حل أفضل؛واحد هو الموصى به،أي اختيار الخطة عن طريق التوصية.
بعد النظر في جميع مساحات التحسين،لقد قمنا بضغط تنفيذ FlashMLA عالي الأداء والذي كان يتكون في الأصل من أكثر من 500 كتلة تعليمات برمجية في 50 سطرًا فقط من تعليمات TileLang البرمجية، مع الاحتفاظ بأداء 95%.
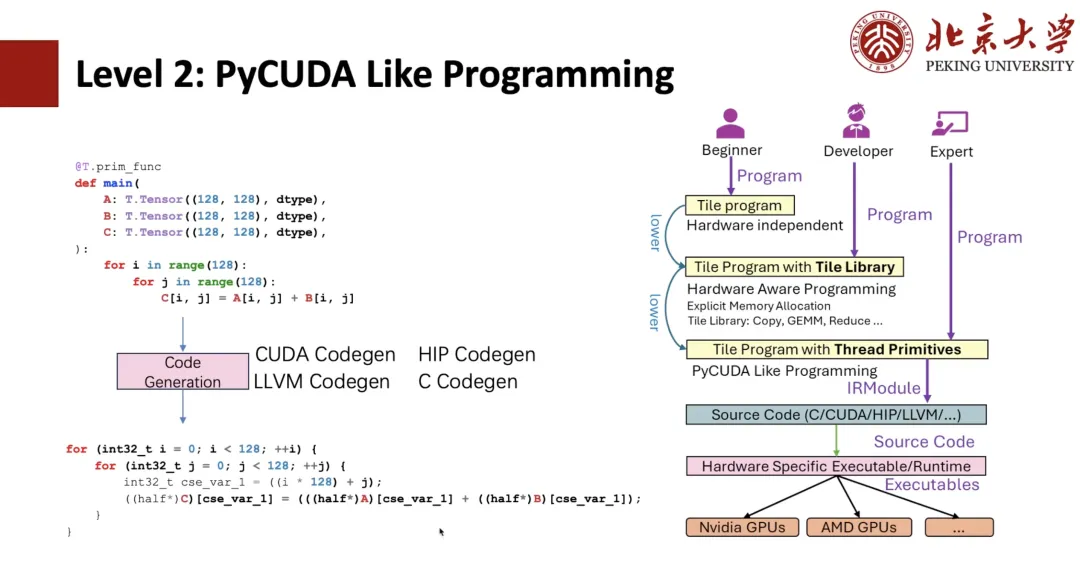
بعد ذلك، سأقدم لك TileLang من الأسفل.
كما هو موضح في الشكل أدناه، سيتمكن الطلاب المطلعون على TIR من معرفة أن هذا تعبير TIR. بعد ذلك، يمكننا برمجة PyCUDA بناءً على TIR. على سبيل المثال، إذا كتبنا حلقتين سلبيتين في بايثون، يمكننا تحويلهما إلى تعبيرات CUDA من خلال TIR Codegen.
باستخدام بدائيات الخيوط، مثل التوجيه، يُمكننا تطبيق توجيه CUDA، ثم ربط الخيوط. جميع البرامج المذكورة أعلاه كانت موجودة في TIR، ويمكن للمستخدمين كتابة برامج مشابهة لـ CUDA، ولكن كتابتها باستخدام بايثون أكثر تعقيدًا.
من أجل جعل العملية أسهل للمستخدمين،تم اقتراح طريقة كتابة مكتبة البلاط المستوى 1.على سبيل المثال، نُنشئ سياق نواة يحتوي على 128 خيطًا، ثم نُغلّف عملية النسخ بـ "T.Parallel". بعد استنتاج المُجمّع، يُمكنه استنتاج الصيغة عالية الأداء الموضحة، وأخيرًا توليد الكود إلى شيفرة CUDA. لمزيد من الإتقان، يُمكنك كتابة "T.copy" مباشرةً وتوسيع عملية النسخ مباشرةً إلى تعبير "T.Parallel".
لا يقتصر دور T.Parallel على النسخ فحسب، بل يُمكّن أيضًا من تنفيذ حسابات معقدة، بالإضافة إلى إمكانية تطبيق المتجهات وربط الخيوط تلقائيًا. حاليًا، بالإضافة إلى النسخ، نوفر أيضًا مجموعة من مكتبات Tile Libraries مثل Reduce وFill وClear وغيرها. بناءً على مكتبة Tile Libraries، يُمكنك كتابة مُعامل جيد مثل Triton.
لذا،المفهوم الأساسي الذي يدعم "T.Parallel" هو تخطيط الذاكرة.
في TileLang، ندعم فهرسة المصفوفات متعددة الأبعاد باستخدام واجهات عالية المستوى، مثل A[i, k]. يُحوّل هذا الفهرس عالي المستوى في النهاية إلى عنوان ذاكرة فعلي عبر سلسلة من طبقات التجريد البرمجية والعتادية. ولنمذجة عملية تحويل الفهرس هذه،لقد قدمنا التخطيط لوصف كيفية تنظيم البيانات وتعيينها في الذاكرة.
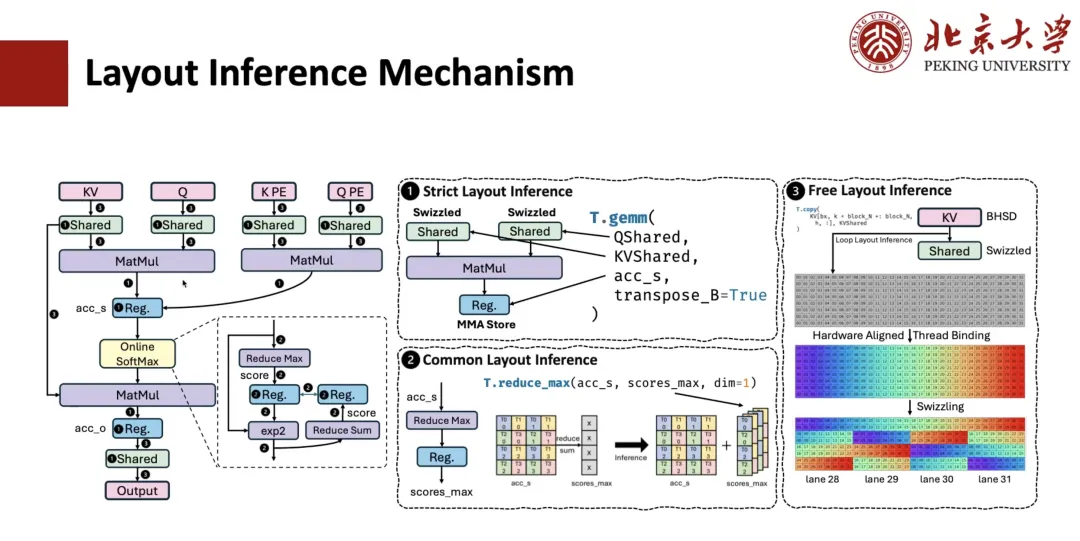
كيف يُنفَّذ اشتقاق التخطيط لحسابات MLA؟ عادةً، تتضمن هذه العملية ثلاث خطوات.
الخطوة الأولى هي الاستدلال على التخطيط الصارم.على سبيل المثال، تخضع عمليات مثل ضرب المصفوفات لقيود صارمة على تخطيط البيانات، ويجب أن تتبع التخطيط المحدد، وبالتالي يُحدد تخطيط السجلات المتصلة بها أيضًا. إذا كانت الذاكرة المشتركة متضمنة، وعلمنا أن هذا المشغل بحاجة إلى إجراء عملية انسكاب، فسيتم تحديد تخطيط الذاكرة المقابل أيضًا.
الخطوة الثانية هي استنتاج التخطيط المشترك.على سبيل المثال، بالنسبة للتعبيرات المرتبطة بالتخطيط المحدد في الخطوة السابقة، يجب تحديد تخطيطها أيضًا. على سبيل المثال، لنفترض أن لدينا عملية تقليل من accum_s إلى scope_max، حيث يُحدد تخطيط نظام إدارة الجودة (QMS) من خلال طبقة المصفوفة، فيمكننا استنتاج تخطيط scope_max بناءً عليه. من خلال هذا المستوى من التفكير العام، يمكن تحديد تخطيط معظم التعبيرات الوسيطة.
الخطوة الثالثة هي الاستدلال الحر على التخطيط.هذا يعني أنه يتم استنتاج التخطيط الحر المتبقي. ولأنه غير مقيد بشدة، عادةً ما تُعتمد بعض استراتيجيات استنتاج التخطيط المتوافقة مع الأجهزة لاستنتاج حل التخطيط الأمثل بناءً على وضع الوصول ونطاق الذاكرة.
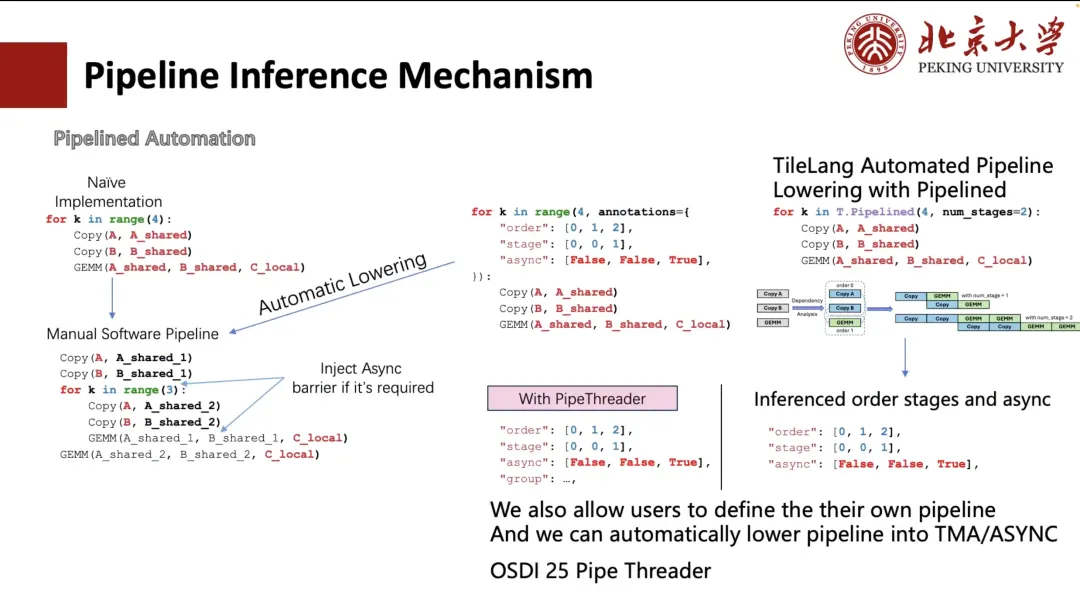
يوضح ما يلي كيفية قيام Pipeline بإجراء الاشتقاق.
بشكل عام، يُمكن توسيع خط الأنابيب يدويًا، ولكن طريقة الكتابة هذه مُرهقة وغير سهلة الاستخدام. لذلك، استكشفت TVM تبسيط العملية من خلال التعليقات التوضيحية. يحتاج المستخدمون فقط إلى تحديد ترتيب التنفيذ ومرحلة جدولة الحلقة.يمكن لـ TVM تحويل الحلقة تلقائيًا إلى هيكل يعادل الفك اليدوي (كما هو موضح في الزاوية اليسرى السفلية من الشكل أدناه).
لكن الأمر لا يزال معقدًا ومُزعجًا للمستخدمين. لذلك، في TileLang، نُقلصه إلى "num_stage". يحتاج المستخدمون فقط إلى تحديد قيمة "num_stage"، ليتمكن النظام تلقائيًا من تحليل التبعيات في الحساب والجدولة وتقسيمها وفقًا لذلك. في الواقع، على وحدة معالجة الرسومات (GPU) أو معظم الأجهزة الأخرى، لا يُمكن تحقيق التنفيذ غير المتزامن الحقيقي إلا من خلال Copy وGEMM، وخاصةً عملية النسخ، التي تدعم النقل غير المتزامن من خلال آليات مثل ASYNC أو TMA.
لذلك،في الجدولة، سوف نقوم بفصل عملية النسخ إلى مرحلة منفصلة.ويتم تلقائيًا تحديد تقسيم المراحل المناسب لخط الأنابيب بأكمله. وبالطبع، يمكن للمستخدمين أيضًا تحديد طريقة الجدولة يدويًا، مثل الترتيبين المخصصين الموضحين في الشكل على اليسار.
بالإضافة إلى ذلك، ندعم أيضًا الاستدلال التلقائي على التخطيط وتحسين الجدولة بناءً على ميزات الأجهزة (مثل وحدات TMA على A100 وH100). هذا الجزء من العمل مأخوذ من مشروعنا Pipe Threader الذي سيُنشر في مؤتمر OSDI 25 هذا العام.
بعد ذلك، سأشارك معكم استنتاج التعليمات.
على سبيل المثال، عند ضرب المصفوفات، هناك العديد من تعليمات الأجهزة التي يمكن استدعاؤها لـ "T.GEMM". على سبيل المثال، في ظل دقة INT8، قد يكون من الممكن استخدام تعليمات DP4A، أو استخدام تطبيق INT8 المبني على TensorCore. يدعم كل تعليمة أشكالًا متعددة، لذا فإن اختيار تكوين البلاط الأمثل من بين هذه التطبيقات يُعدّ مسألة أساسية.
ولتحقيق هذه الغاية، يوفر TileLang طريقتين للاستخدام:
الأول هو أن TileLang يسمح للمستخدمين بكتابة ASM عن طريق استدعاء PTX.لكن عيب هذه الطريقة هو ضخامة مساحة التجميع - فإذا أردتَ التوافق مع جميع أنظمة PTX، فستحتاج إلى كتابة الكثير من الأكواد البرمجية، بالإضافة إلى إدارة التخطيط. مع ذلك، هذه الطريقة مجانية تمامًا، وأنا شخصيًا أحبها كثيرًا.
ولكننا الآن نستخدم الطريقة الثانية.وهذا يعني أن "T.GEMM" يتبعه مكتبة بلاط مثل CUTE/CK-TILE.يوفر واجهة مكتبة على مستوى البلاط تُستخدم عادةً لضرب المصفوفات، ولكن عيبه هو استغراق وقت طويل جدًا في التجميع بسبب توسيع القالب. على RTX 4090، قد يستغرق تجميع Flash Attention 10 ثوانٍ، منها أكثر من 90% يُقضى على توسيع القالب. ومن المشاكل الأخرى أنه منفصل تمامًا عن واجهة Python الأمامية.
لذلك نحن نعتقد،مكتبة البلاط هي الاتجاه الذي سوف نركز عليه في المستقبل.وهذا يعني أنه من خلال بناء الجملة الأصلي لـ Tile، يتم دعم مكتبات مختلفة على مستوى Tile مثل "T.GEMM" و"T.GEMMSP".
آفاق العمل المستقبلية
وأخيرًا، أود أن أعرض عليكم بعضًا من أعمال فريقنا المستقبلية.
الأول هو Tile Sight، والذي تم تصميمه خصيصًا لتسريع تحسين أداء النوى المعقدة واسعة النطاق (مثل FlashAttention وFlashMLA) في نماذج اللغة الكبيرة.هذا إطار عمل ضبط تلقائي خفيف الوزن يهدف إلى إنشاء وتقييم تكوينات Tile الفعالة (أي استراتيجيات البلاط أو تلميحات الجدولة) للعديد من الواجهات الخلفية مثل وحدات معالجة الرسومات ووحدات المعالجة المركزية والمعجلات، مما يساعد المطورين على العثور بسرعة على استراتيجيات الجدولة ذات الأداء المتفوق وتقليل وقت الضبط اليدوي.
بناءً على النموذج المخصص المذكور أعلاه، يُسهّل على المستخدمين كتابة نواة معقدة، مثل MLA. يُرشد النموذج المخصص المستخدمين إلى وضع كل ذاكرة تخزين مؤقتة على الذاكرة المشتركة المقابلة.
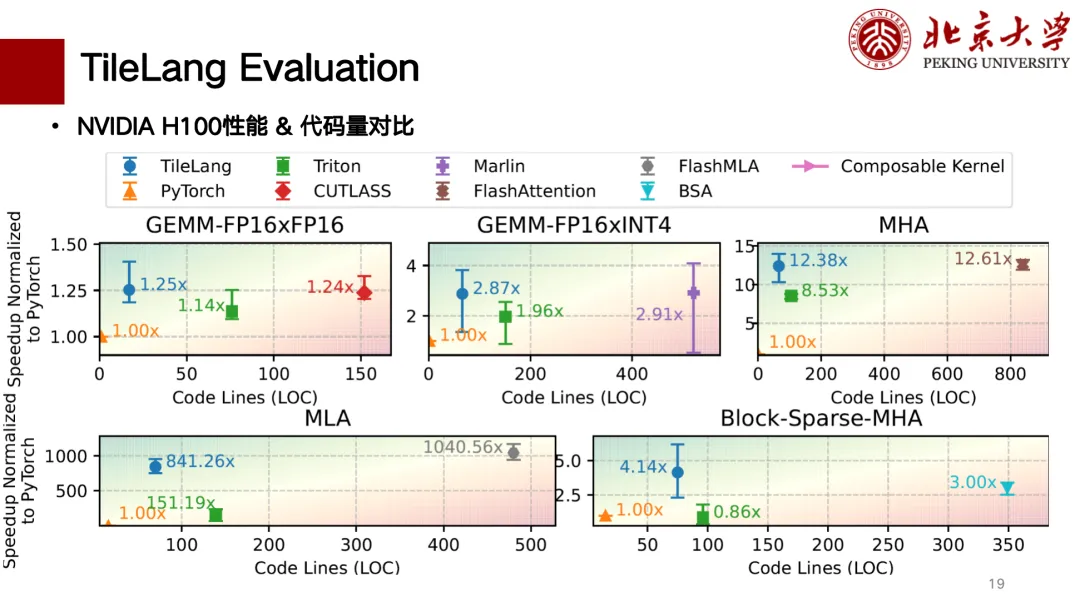
فيما يلي تقييم جزئي لأداء TileLang. لقد أكملنا بشكل رئيسي دعم بطاقات H وبطاقات A. يوضح الشكل أدناه مخططًا لمقارنة الارتباط بين عدد أسطر التعليمات البرمجية والأداء. يظهر الأداء أفضل في الزاوية العلوية اليسرى. من بين هذه الأسطر، في عملية ضرب المصفوفات، يمكن لـ TileLang تحقيق أداء مماثل لـ CUTLASS. بالإضافة إلى ذلك، يمكن لعوامل مثل MLA وFlash Attention وBlock Sparse وغيرها تحقيق أداء مماثل لـ CUTLASS، كما أن عدد أسطر التعليمات البرمجية صغير نسبيًا، كما أن كتابته سهلة نسبيًا.
في بيئة TileLang، يستخدمها بعض المستخدمين بالفعل. على سبيل المثال، طُوِّر مُشغِّل التكميم الأساسي لنموذج BitNet كبير الحجم منخفض الدقة من مايكروسوفت استنادًا إلى TileLang، كما يعتمد BitBLAS من مايكروسوفت بالكامل على TileLang. وفيما يتعلق بدعم الشرائح المحلية، فقد قدمنا أيضًا بعض الدعم لمعالجات Suanneng TPU وAscend NPU.








