Command Palette
Search for a command to run...
تم تحسين أداء التدريب بشكل ملحوظ. يشرح تشنغ سايز من بايت دانس إطار عمل تريتون الموزع لتحقيق تكامل فعال للاتصالات الموزعة والحوسبة للنماذج الكبيرة.

في عام ٢٠٢٥، سيصل صالون "لقاء مع مُطوّري الذكاء الاصطناعي" الذي تستضيفه شركة HyperAI إلى دورته السابعة. بدعم من شركاء المجتمع والعديد من خبراء الصناعة، أنشأنا قواعد متعددة في بكين وشانغهاي وشنتشن وأماكن أخرى لتوفير منصة تواصل للمطورين والمتحمسين، وكشف أسرار التقنيات الرائدة، ومواجهة ملاحظات المطورين في الخطوط الأمامية، ومشاركة الخبرات العملية في تطبيق التكنولوجيا، والاستماع إلى الأفكار المبتكرة من زوايا متعددة.
اتبع حساب WeChat العام "HyperAI Super Neuro" وأجب على الكلمة الرئيسية "0705 AI Compiler" للحصول على عرض تقديمي للمحاضر المعتمد PPT.




في الخطاب الرئيسي "توزيع تريتون: برمجة بايثون الأصلية للاتصالات عالية الأداء"،تشنغ سايز، عالم أبحاث البذور من بايت دانسيقوم هذا الكتاب بتحليل التقدم المحرز في كفاءة الاتصالات وقابلية التكيف عبر الأنظمة الأساسية لتوزيع Triton في التدريب على النماذج الكبيرة بشكل تفصيلي، بالإضافة إلى كيفية تحقيق التكامل العميق بين الاتصالات والحوسبة من خلال برمجة Python.بعد المشاركة، ازدحمت الساحة بالأسئلة. دارت نقاشات لا حصر لها حول تفاصيل مثل إطار عمل FLUX، ونموذج برمجة Tile، وتحسين AllGather وReduceScatter، وغيرها. ركزت المناقشات على الصعوبات التقنية الأساسية والخبرة العملية، وعززت بشكل فعال الجمع بين النظرية والتطبيق.
قامت شركة هايبر إيه آي بجمع وتلخيص خطاب السيد تشنغ سايز دون المساس بالقصد الأصلي. وفيما يلي نص الخطاب.
التحديات الحقيقية للتدريب الموزع
في سياق التطور السريع للنماذج الكبيرة، يعد التدريب والاستدلال أمرًا بالغ الأهمية.أصبحت الأنظمة الموزعة جزءًا لا غنى عنه.لقد أجرينا أيضًا استكشافًا على مستوى المترجم في هذا الاتجاه وقمنا بجعل المشروع مفتوح المصدر، وأطلقنا عليه اسم Triton-Distributed.
تشمل طرق الربط الحالية الشائعة بين الأجهزة NVLink وPCIe والاتصال الشبكي بين العقد. في الظروف المثالية، يمكن أن يصل عرض النطاق الترددي أحادي الاتجاه لـ H100 عبر NVLink إلى 450 جيجابايت/ثانية، ولكن في معظم التطبيقات المحلية، يُعد H800 هو الأكثر شيوعًا، حيث يبلغ عرض النطاق الترددي أحادي الاتجاه حوالي 200 جيجابايت/ثانية فقط، مما يُقلل بشكل كبير من قدرة الاتصال الإجمالية وتعقيد طوبولوجيا الشبكة.كان التحدي الواضح الذي واجهناه في المشروع هو الاختناق في أداء النظام الناجم عن النطاق الترددي غير الكافي وطوبولوجيا الاتصالات غير المتماثلة.
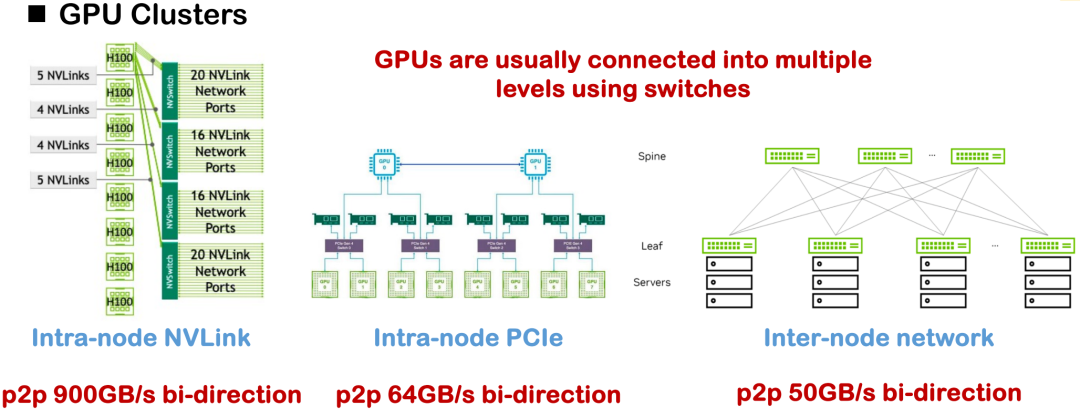
في ضوء ذلك، اعتمدت عمليات التحسين الموزعة المبكرة غالبًا على عدد كبير من مشغلات الاتصالات المُنفَّذة يدويًا، بما في ذلك استراتيجيات مثل توازي الموتر، وتوازي خطوط الأنابيب، وتوازي البيانات، والتي تتطلب جميعها كتابةً دقيقةً لمنطق الاتصال الأساسي. ومن الممارسات الشائعة استدعاء مكتبات الاتصالات مثل NCCL وROCm CCL، إلا أن هذه الحلول غالبًا ما تفتقر إلى التنوع وقابلية النقل، وتتطلب تكاليف تطوير وصيانة عالية.
عند تحليل الاختناقات في النظام الحالي، قمنا بتلخيص ثلاث حقائق رئيسية:
الحقيقة 1: عرض النطاق الترددي للأجهزة محدود، ويصبح زمن انتقال الاتصالات بمثابة عنق زجاجة
الأول هو القيود الناجمة عن ظروف الأجهزة الأساسية. عند استخدام H100 لتدريب نموذج كبير، غالبًا ما يكون تأخير الحوسبة أعلى بكثير من تأخير الاتصال، لذا لا داعي للاهتمام بشكل خاص بالتداخل في جدولة الحوسبة والاتصال. مع ذلك، في بيئة H800 الحالية، يطول تأخير الاتصال بشكل ملحوظ. وقد قيّمنا أنه في بعض السيناريوهات، سيستهلك تأخير الاتصال ما يقرب من نصف وقت التدريب، مما يؤدي إلى انخفاض كبير في إجمالي استخدام مقياس النموذج (MSU). إذا لم يُحسَّن تداخل الاتصال والحوسبة، فسيواجه النظام مشاكل خطيرة في هدر الموارد.
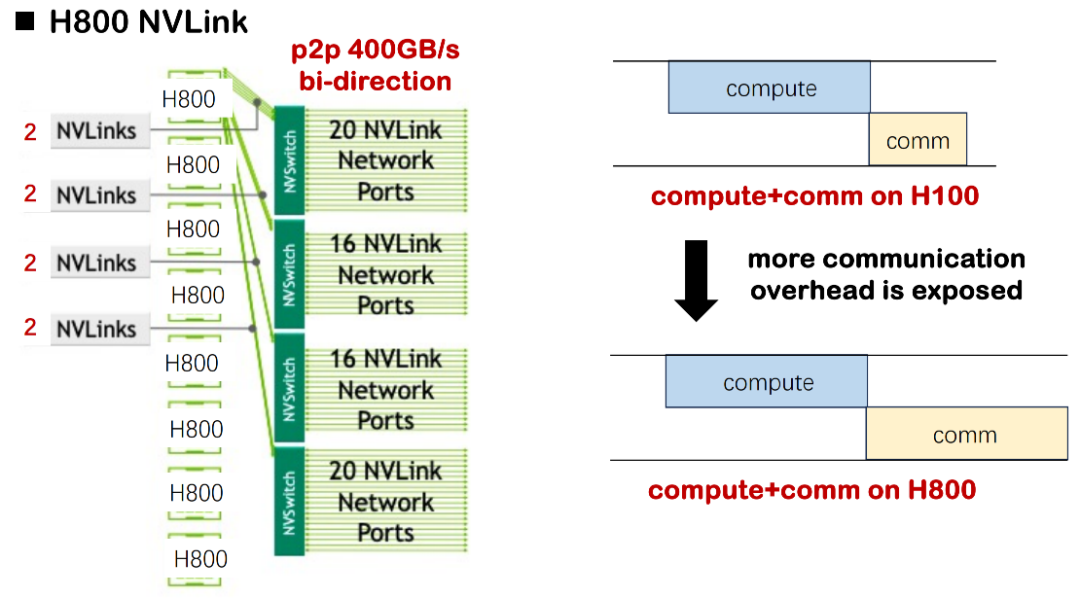
وفي الحالات الصغيرة والمتوسطة الحجم، تكون هذه الخسارة مقبولة؛ ولكن بمجرد توسيع النموذج ليشمل آلاف البطاقات، كما هو الحال في ممارسات التدريب في MegaScale أو DeepSeek، فإن خسارة الموارد المتراكمة ستصل إلى ملايين أو حتى عشرات الملايين من الدولارات، وهو ما يشكل ضغط تكلفة حقيقي للغاية بالنسبة للمؤسسات.
ينطبق الأمر نفسه على سيناريوهات الاستدلال. فقد استخدم النشر المبكر للاستدلال في DeepSeek ما يصل إلى 320 بطاقة. ورغم الضغط والتحسين اللاحقين، لا يزال زمن انتقال البيانات يمثل مشكلة أساسية لا مفر منها في الأنظمة الموزعة. لذلك، أصبحت كيفية جدولة الاتصالات والحوسبة بفعالية على مستوى البرنامج وتحسين الكفاءة العامة مسألةً رئيسيةً يجب مواجهتها بشكل مباشر.
الحقيقة 2: تؤثر تكاليف الاتصال العالية بشكل مباشر على أداء وحدة التحكم الدقيقة
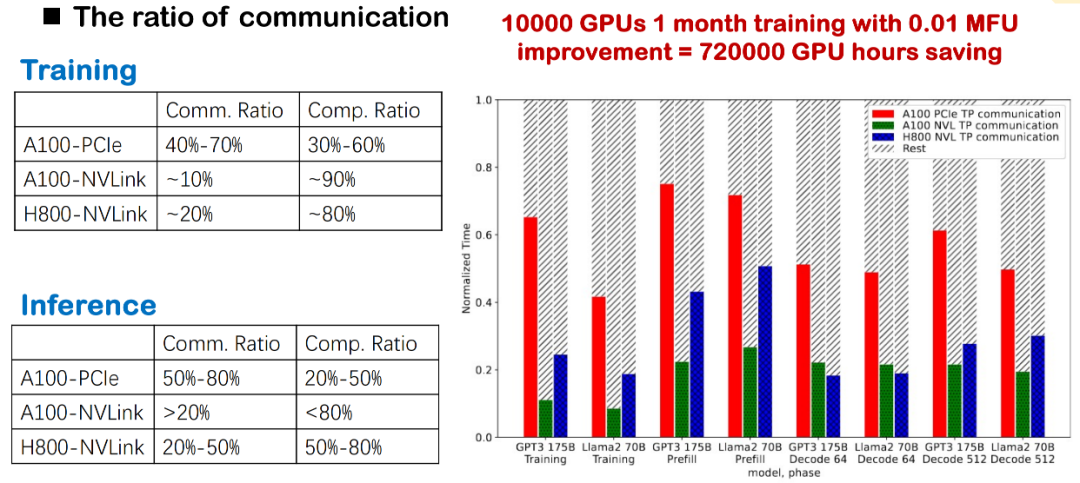
في تدريب النماذج واسعة النطاق الحالية والتفكير المنطقي، تُشكل تكاليف الاتصالات دائمًا عائقًا رئيسيًا. وقد لاحظنا أنه سواءً استخدمت الطبقة الأساسية NVLink أو PCIe أو أجيالًا مختلفة من وحدات معالجة الرسومات (مثل A100 وH800)، فإن نسبة الاتصالات تكون عالية جدًا. وخاصةً في عمليات النشر المحلية الفعلية، نظرًا لقيود النطاق الترددي الواضحة، فإن تأخيرات الاتصالات تُبطئ الكفاءة الإجمالية بشكل مباشر.
بالنسبة لتدريب النماذج الكبيرة، سيُخفّض هذا الاتصال عالي التردد بين البطاقات بشكل كبير من وحدة MFU للنظام. لذلك، يُعدّ تحسين تكلفة الاتصال نقطة تحسين أساسية لتحسين أداء التدريب والاستدلال، وهو أيضًا أحد مجالات تركيزنا الرئيسية.
الحقيقة 3: الفجوة بين قابلية البرمجة والأداء
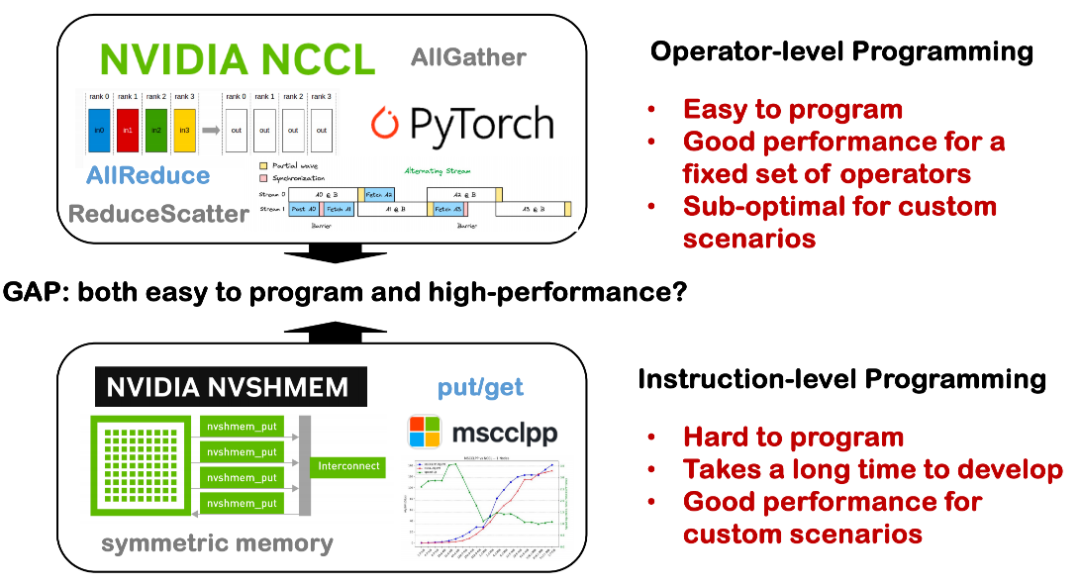
حاليًا، لا تزال هناك فجوة كبيرة بين قابلية البرمجة والأداء في الأنظمة الموزعة. في الماضي، أولينا اهتمامًا أكبر لقدرات تحسين مُجمِّعات البطاقة الواحدة، مثل كيفية تحقيق أداء ممتاز على بطاقة واحدة؛ ولكن عند التوسع إلى جهاز واحد ببطاقات متعددة، أو حتى نظام موزع عبر عُقد، يصبح الوضع أكثر تعقيدًا.
من ناحية، تتضمن الاتصالات الموزعة العديد من التفاصيل التقنية الأساسية، مثل NCCL وMPI والطوبولوجيا، وهي متناثرة في مكتبات مخصصة متنوعة ولها حد استخدام مرتفع. في كثير من الحالات، يحتاج المطورون إلى تنفيذ منطق الاتصال يدويًا، وجدولة الحسابات والمزامنة يدويًا، مما يؤدي إلى تكاليف تطوير عالية ومعدلات خطأ عالية. من ناحية أخرى، إذا وُجدت أدوات يمكنها التعامل تلقائيًا مع جدولة الاتصالات المعقدة وتحسين أداء المشغل في ظل ظروف موزعة، فيمكن أن يساعد ذلك المطورين على خفض حد التطوير بشكل كبير وتحسين توافر الأنظمة الموزعة وقابليتها للصيانة. هذه إحدى المشكلات التي نأمل في حلها في Triton-Distributed.
استنادًا إلى المشكلات العملية الثلاث المذكورة أعلاه، اقترحنا ثلاثة اتجاهات أساسية في Triton-Distributed:
أولاً، تعزيز آلية التداخل بين الاتصالات والحوسبة.في السيناريوهات الموزعة حيث أصبحت تكاليف الاتصالات بارزة بشكل متزايد، نأمل في جدولة نوافذ متوازية للحوسبة والاتصالات قدر الإمكان لتحسين الكفاءة العامة للنظام.
ثانياً، من الضروري التكامل والتكيف بشكل عميق مع أساليب الحوسبة والاتصالات في النماذج الكبيرة.على سبيل المثال، نحاول دمج أنماط الاتصال الشائعة مثل AllReduce وBroadcast في النموذج مع نمط الحوسبة لتقليل الانتظار المتزامن وضغط مسار التنفيذ.
أخيرًا، نعتقد أن هذه التحسينات يجب أن يقوم بها المترجم بدلاً من الاعتماد على المطورين لكتابة تنفيذات CUDA مخصصة للغاية يدويًا.إن جعل تطوير الأنظمة الموزعة أكثر تجريدًا وكفاءة هو الاتجاه الذي نعمل نحوه.
تحليل بنية Triton الموزعة: Python الأصلي للاتصالات عالية الأداء
نأمل في تحقيق التداخل في التدريب الموزع، إلا أن تطبيقه ليس سهلاً. نظرياً، يعني التداخل إجراء عمليات حسابية وتواصلية في آنٍ واحد عبر تدفقات متعددة لإخفاء تأخيرات الاتصال. يكون هذا أسهل في السيناريوهات التي لا يوجد فيها اعتماد بين المشغلين، ولكن في Tensor Parallel (TP) أو Expert Parallel (EP)، يجب إكمال AllGather قبل تنفيذ GEMM. يقع كلاهما في المسار الحرج، والتداخل صعب للغاية.
تتضمن الطرق الشائعة حاليًا ما يلي: أولًا، تقسيم المهمة إلى دفعات صغيرة متعددة، وتحقيق التداخل مع استقلال الدفعات؛ ثانيًا، التقسيم بحبيبات أدق (مثل حبيبات البلاط) ضمن دفعة واحدة، وتحقيق تأثيرات متوازية من خلال دمج النواة. لقد استكشفنا أيضًا هذا النوع من آلية التقسيم والجدولة في Flux. في الوقت نفسه، يُعد وضع الاتصال في تدريب النماذج الكبيرة معقدًا للغاية. على سبيل المثال، يحتاج DeepSeek إلى تخصيص اتصال الكل إلى الكل عند إجراء MoE لمراعاة عرض النطاق الترددي وموازنة الحمل؛ على سبيل المثال، في سيناريوهات الاستدلال والتكميم منخفضة الكمون، يصعب على المكتبات العامة مثل NCCL تلبية متطلبات الأداء، وغالبًا ما تتطلب نوى اتصال مكتوبة بخط اليد، مما يزيد من تكلفة التخصيص.
لذلك نعتقدينبغي أن تتولى طبقة المترجم القدرة على تحسين اندماج الاتصالات والحوسبة للتعامل مع هياكل النماذج المعقدة وبيئات الأجهزة المتنوعة، وتجنب عبء التطوير الناتج عن التنفيذ اليدوي المتكرر.
التجريد البدائي للاتصالات ثنائية الطبقات
في تصميم المترجم الخاص بنا، قمنا بتبني بنية مجردة لبدائيات الاتصال ذات الطبقتين من أجل الأخذ في الاعتبار كل من قدرة التعبير عن التحسين في الطبقة العليا وإمكانية تنفيذ النشر الأساسي.
الطبقة الأولى عبارة عن طبقة بدائية عالية المستوى نسبيًا، وهي تعمل بشكل أساسي على إكمال جدولة الحوسبة على مستوى حبيبات البلاط وتوفر واجهة مجردة للاتصالات.ويستخدم عمليات الدفع/الحصول بين الرتب باعتبارها تجريدات اتصال ويميز كل سلوك اتصال من خلال آلية تحديد العلامة، مما يجعل من الأسهل على المجدول تتبع تدفقات البيانات والتبعيات.
الطبقة الثانية أقرب إلى التنفيذ الأساسي وتستخدم نظامًا بدائيًا مشابهًا لمعيار الذاكرة المشتركة المفتوحة (OpenSHMEM).تُستخدم هذه الطبقة بشكل أساسي لتعيين مكتبات الاتصالات الموجودة أو واجهات الأجهزة الخلفية لتنفيذ سلوكيات الاتصال الحقيقية.
أيضًا،في سيناريو الرتب المتعددة، نحتاج أيضًا إلى تقديم آليات التحكم في الحواجز والإشارات للمزامنة بين الرتب.على سبيل المثال، عندما تحتاج إلى إخطار الرتب الأخرى بأن بياناتك قد تمت كتابتها، أو عندما تنتظر أن تكون بيانات رتبة معينة جاهزة، فإن هذا النوع من إشارة المزامنة أمر بالغ الأهمية.

هندسة المترجم والنمذجة الدلالية
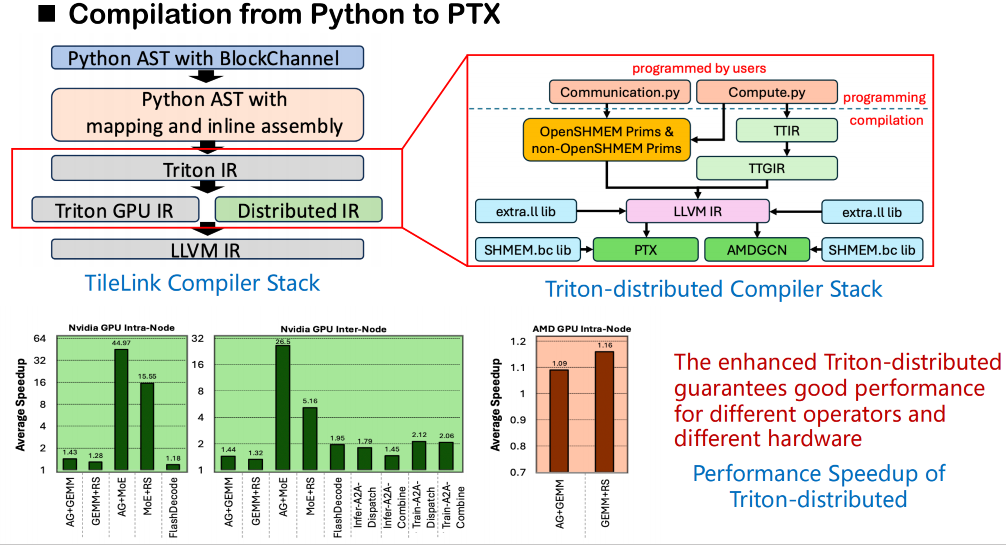
فيما يتعلق بمجموعة التجميع، لا تزال عمليتنا الشاملة تعتمد على إطار عمل تجميع تريتون الأصلي. بدءًا من الكود المصدري، سيُحوّل تريتون كود المستخدم إلى شجرة بناء جملة مجردة (AST)، ثم يُترجمه إلى تريتون آي آر. في نظام تريتون الموزع الذي بنيناه،تم توسيع نطاق Triton IR الأصلي وتمت إضافة طبقة IR جديدة للدلالات الموزعة.يُقدّم هذا النموذج الموزع نمذجةً دلاليةً لعمليات المزامنة، مثل الانتظار والإشعار، لوصف تبعيات الاتصال بين الرتب. وفي الوقت نفسه، نُصمّم مجموعةً من الواجهات الدلالية لـ OpenSHMEM لدعم مكالمات الاتصال منخفضة المستوى.
في مرحلة توليد الشيفرة الفعلية، يمكن ربط هذه الدلالات باستدعاءات خارجية لمكتبة الاتصال الأساسية. نربط هذه الاستدعاءات مباشرةً بإصدار الكود البتّي للمكتبة (وليس الكود المصدري) الذي توفره OpenSHMEM عبر الطبقة الوسطى LLVM لتحقيق اتصال فعال عبر الذاكرة المشتركة بين الرتب. تتجاوز هذه الطريقة القيد المتمثل في عدم دعم Triton للوصول المباشر إلى المكتبة الخارجية من الكود المصدري، مما يسمح للاستدعاءات المتعلقة بالذاكرة المشتركة بإكمال تحليل الرموز والربط بسلاسة أثناء التجميع.
آلية رسم الخرائط بين البدائيات عالية المستوى والتنفيذ منخفض المستوى
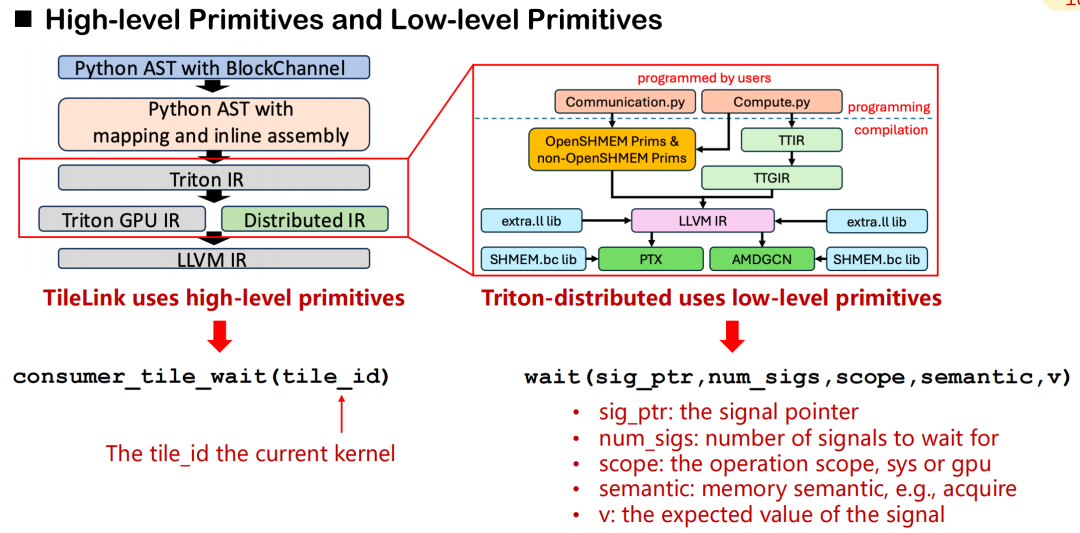
في Triton-distributed، قمنا بتصميم نظام من عناصر الاتصال البدائية التي تغطي التجريد عالي المستوى والتحكم منخفض المستوى.على سبيل المثال، باستخدام consumer_tile_wait، يكفي المطورون إعلان مُعرّف المربع الذي ينتظرونه، وسيستنتج النظام تلقائيًا الترتيب والإزاحة المحددين لهدف الاتصال بناءً على دلالات المُشغّل الحالية (مثل AllGather) لإكمال منطق المزامنة. تُخفي العناصر الأولية عالية المستوى تفاصيل مصادر البيانات المُحددة ونقل الإشارات، مما يُحسّن كفاءة التطوير.
في المقابل، توفر البدائيات منخفضة المستوى إمكانيات تحكم أكثر دقة. يحتاج المطورون إلى تحديد مؤشرات الإشارة، والنطاقات (وحدة معالجة الرسومات أو النظام)، ودلالات الذاكرة (الاستحواذ، الإصدار، إلخ)، والقيم المتوقعة يدويًا. على الرغم من أن هذه الآلية أكثر تعقيدًا، إلا أنها مناسبة للسيناريوهات ذات المتطلبات العالية جدًا لزمن انتقال الاتصالات ودقة الجدولة.
يمكن تقسيم البدائيات عالية المستوى تقريبًا إلى فئتين: التحكم في الإشارة والتحكم في البيانات. في دلالات التحكم في الإشارة،نحن نعرف بشكل أساسي ثلاثة أنواع من الأدوار: المنتج والمستهلك والنظير.يتم تحقيق المزامنة من خلال إشارات القراءة والكتابة، وهو ما يشبه آلية المصافحة في الاتصالات الموزعة. لنقل البيانات، يوفر توزيع تريتون عمليتين أساسيتين: الدفع والسحب، وهما إرسال البيانات بشكل نشط إلى البطاقة البعيدة أو سحبها من البطاقة البعيدة إلى البطاقة المحلية.
تتبع جميع عناصر الاتصال منخفضة المستوى معيار OpenSHMEM، وتدعم حاليًا NVSHMEM وROCSHMEM. توجد علاقة تعيين واضحة بين العناصر عالية المستوى ومنخفضة المستوى، والمُجمِّع مسؤول عن تحويل الواجهات الموجزة تلقائيًا إلى تعليمات مزامنة وإرسال منخفضة المستوى. من خلال هذه الآلية،لا يحتفظ Triton الموزع بإمكانيات الأداء العالية لجدولة الاتصالات فحسب، بل يقلل أيضًا بشكل كبير من تعقيد البرمجة الموزعة.
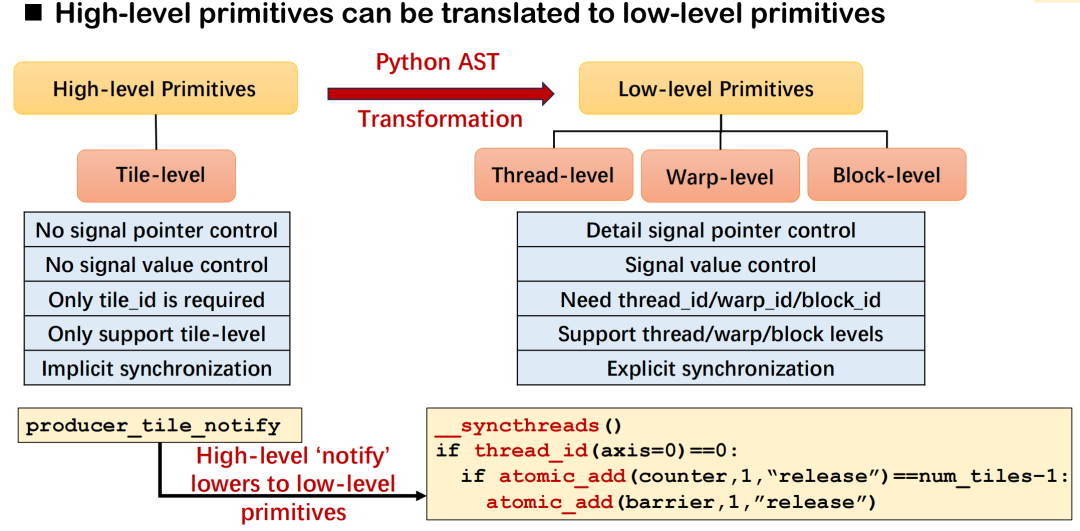
في نظام تريتون الموزع، يهدف تصميم أساسيات الاتصالات عالية المستوى (مثل الإشعار والانتظار) إلى وصف متطلبات المزامنة بين البطاقات بدلالات موجزة، ويكون المُجمِّع مسؤولاً عن ترجمتها إلى منطق التنفيذ الأساسي المُناسب. لنأخذ الإشعار كمثال، حيث يُشكل الإشعار والانتظار زوجًا من دلالات المزامنة: يُستخدم الأول لإرسال الإشعارات، ويُستخدم الثاني لانتظار اكتمال إعداد البيانات. يحتاج المطورون فقط إلى تحديد مُعرِّف المربع، ويمكن للنظام استنتاج التفاصيل الأساسية تلقائيًا، مثل أهداف الاتصال وإزاحات الإشارة، بناءً على نوع المُشغِّل وطوبولوجيا الاتصال.
يختلف التنفيذ الأساسي المحدد باختلاف بيئة النشر. على سبيل المثال، في سيناريو يحتوي على 8 وحدات معالجة رسومية، يمكن تحقيق هذا النوع من المزامنة من خلال _syncthreads() وatomic_dd ضمن سلسلة؛ أما في النشر عبر الأجهزة، فيعتمد على عناصر بدائية مثل signal_up التي يوفرها NVSHMEM أو ROCSHMEM لإكمال العمليات المكافئة. تُشكل هذه الآليات معًا علاقة التعيين بين الدلالات عالية المستوى والعناصر البدائية منخفضة المستوى، وتتميز بتنوع وقابلية توسع جيدة.
لنأخذ مثالاً على سيناريو اتصال GEMM ReduceScatter: لنفترض وجود أربع وحدات معالجة رسومية في النظام، وأن الموقع المستهدف لكل شريحة مُحدد بمعلومات تعريفية محسوبة مسبقًا (مثل تخصيص الشريحة ورقم الحاجز لكل رتبة). كل ما يحتاجه المطورون هو إضافة عبارة إشعار في نواة GEMM المكتوبة بلغة Triton، وتستخدم نواة ReduceScatter أمر الانتظار لتلقي البيانات بشكل متزامن.
يمكن التعبير عن العملية بأكملها باستخدام بايثون، كما أنها تدعم وضع بدء التشغيل ثنائي المسار في نواة النظام، مع منطق اتصال واضح وجدولة سهلة. لا تُحسّن هذه الآلية من سهولة التعبير عن برمجة الاتصالات بين البطاقات فحسب، بل تُقلل أيضًا بشكل كبير من تعقيد التنفيذ الأساسي، مما يوفر دعمًا قويًا للقدرات الأساسية لتدريب واستدلال فعالين للنماذج الموزعة الكبيرة.
تحسين التداخل متعدد الأبعاد: من آلية الجدولة إلى الوعي الطوبولوجي
على الرغم من أن نظام Triton الموزع يوفر واجهة اتصال بدائية عالية المستوى وموجزة نسبيًا، إلا أنه لا تزال هناك بعض العوائق التقنية في عملية كتابة وتحسين النواة. لاحظنا أنه على الرغم من قدرة التصميم البدائي على التعبير بشكل جيد، إلا أن عدد المستخدمين القادرين على تطبيقه بمرونة وتحسينه بعمق لا يزال محدودًا. في جوهره، لا يزال تحسين الاتصال مهمة تعتمد بشكل كبير على الخبرة الهندسية وفهم الجدولة، ولا يزال حاليًا يتطلب التحكم اليدوي من المطورين. ولحل هذه المشكلة، قمنا بتلخيص بعض مسارات التحسين الرئيسية. فيما يلي استراتيجيات التنفيذ النموذجية في نظام Triton الموزع.
الدفع مقابل السحب: اتجاه تدفق البيانات والتحكم في عدد الحواجز
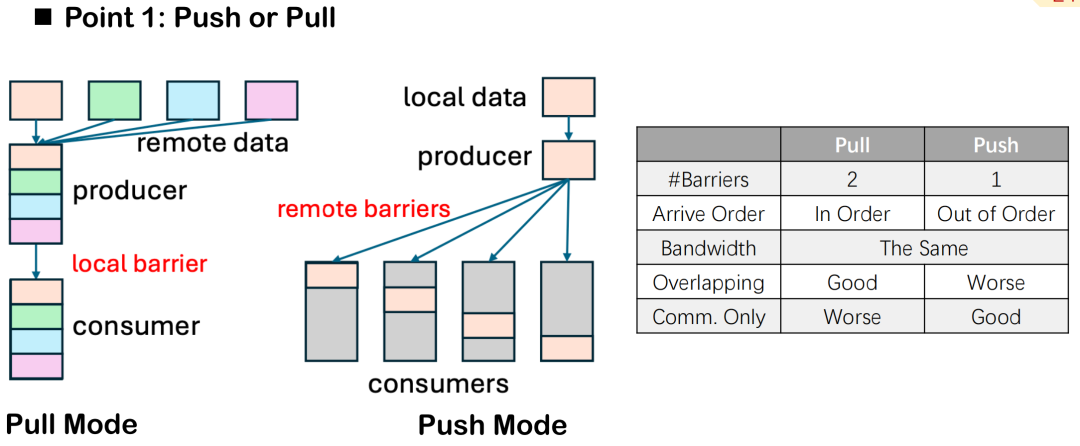
في تحسين التداخل بين الاتصالات والحوسبة،يوفر Triton-distributed طريقتين لنقل البيانات: الدفع والسحب.على الرغم من أن الاختلاف الدلالي بينهما يقتصر فقط على اتجاه "الإرسال النشط" و"السحب السلبي"، إلا أنه في التنفيذ الموزع الفعلي، توجد اختلافات واضحة في أدائهما وقدراتهما على التحكم في الجدولة.
على سبيل المثال، يتطلب وضع السحب عادةً حاجزين: أحدهما لضمان جاهزية البيانات المحلية قبل سحبها من قِبل الطرف الآخر، والآخر لحماية البيانات من التعديل بواسطة المهمة المحلية طوال دورة الاتصال، مما يمنع تضارب البيانات أو تعارضات القراءة والكتابة. في وضع الدفع، يلزم ضبط حاجز واحد فقط بعد كتابة البيانات إلى الطرف البعيد لمزامنة جميع الأجهزة، مما يُبسط التحكم العام.
ومع ذلك، فإن وضع السحب له مزاياه أيضًا. فهو يسمح للعقد المحلية بالتحكم النشط في ترتيب سحب البيانات، مما يُحسّن من دقة جدولة توقيت الاتصال وتداخل الحوسبة. عندما نرغب في تعظيم تأثير التداخل وتحقيق التوازي بين الاتصال والحوسبة، يوفر وضع السحب مرونة أكبر.
بشكل عام، إذا كان الهدف الرئيسي هو تحسين التداخل، فمن المستحسن استخدام وضع السحب؛ في بعض مهام الاتصال البحتة، مثل نواة AllGather أو ReduceScatter المنفصلة، يكون وضع الدفع أكثر شيوعًا بسبب بساطته وتكاليفه المنخفضة.
الجدولة المتغيرة: تعديل الترتيب ديناميكيًا استنادًا إلى موقع البيانات
لا يعتمد تداخل الاتصال والحوسبة على اختيار البدائيات فحسب، بل يعتمد أيضًا على استراتيجية الجدولة. من بينها، Swizzling، وهي طريقة لتحسين الجدولة تعتمد على الوعي الطوبولوجي، وتهدف إلى تقليل خمول التنفيذ أثناء الحوسبة بين البطاقات. من منظور توزيعي، يمكن اعتبار كل بطاقة معالجة رسومية وحدة تنفيذ مستقلة. بما أن كل بطاقة تحتوي في البداية على شظايا بيانات مختلفة، فإذا بدأت جميع البطاقات الحوسبة من نفس مؤشر الشريحة، فسيتعين على بعض الرتب انتظار جاهزية البيانات، مما يؤدي إلى فترات خمول طويلة في مرحلة التنفيذ، مما يقلل من كفاءة الحوسبة الإجمالية.
الفكرة الأساسية لـ Swizzling هي:يتم تعديل إزاحة الحساب الأولية بشكل ديناميكي استنادًا إلى موقع البيانات المحلية الموجودة على كل بطاقة.على سبيل المثال، في سيناريو AllGather، يمكن لكل بطاقة تحديد أولوية معالجة بياناتها الخاصة وبدء عمليات السحب من المربعات البعيدة في الوقت نفسه، مما يحقق جدولة متزامنة للاتصالات والحسابات. إذا بدأت جميع البطاقات المعالجة من المربع 0، فإن المرتبة 0 فقط هي التي يمكنها بدء الحساب فورًا، وستواجه الرتب المتبقية تأخيرات متسلسلة بسبب انتظار البيانات.
في الحالات الأكثر تعقيدًا، مثل سيناريو ReduceScatter بين الأجهزة، يجب تصميم استراتيجية Swizzling بالتزامن مع طوبولوجيا الشبكة. لنأخذ عقدتين كمثال، تتمثل إحدى طرق الجدولة المعقولة في: إعطاء الأولوية لحساب البيانات المطلوبة من العقدة الأخرى، وتفعيل الاتصال بين الأجهزة من نقطة إلى نقطة في أقرب وقت ممكن؛ وأثناء عملية الإرسال، حساب البيانات المطلوبة من العقدة المحلية بالتوازي لتعظيم تأثير التداخل بين الاتصالات والحوسبة.
حاليًا، لا يزال المبرمج يتحكم في هذا النوع من تحسين الجدولة لتجنب تضحية المُجمِّع بمسارات الأداء الرئيسية في التحسين العام. كما نُدرك أن فهم تفاصيل مثل Swizzling يُعدّ شرطًا أساسيًا للمطورين. في المستقبل، نأمل في توفير المزيد من الحالات العملية وأكواد القوالب لمساعدة المطورين على إتقان نموذج تطوير المشغل الموزع بشكل أسرع، وبناء نظام برمجة موزع مفتوح وفعال تدريجيًا باستخدام Triton.

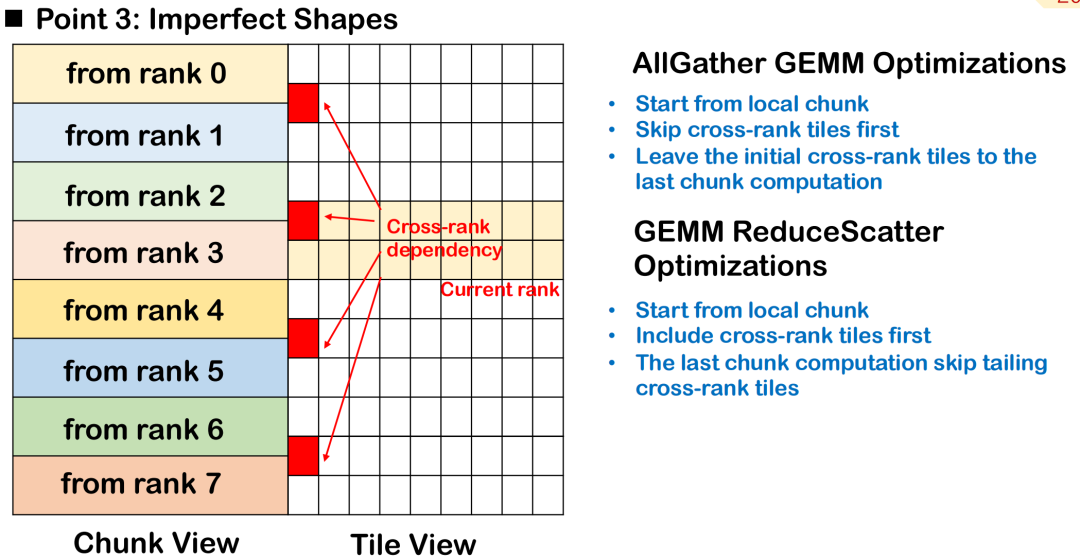
جدولة الكتل غير الكاملة: معالجة الأولويات عبر مربعات الرتبة
في سيناريوهات التدريب والاستدلال الفعلية ذات النماذج الكبيرة، غالبًا ما يكون شكل إدخال المشغل غير منتظم، خاصةً عندما لا يكون طول الرمز ثابتًا، ويصعب الحفاظ على كتل البلاط مرتبة وموحدة.سيؤدي هذا التوزيع غير الكامل إلى امتداد بعض المربعات إلى عدة مراتب، أي أن بيانات نفس المربع يتم توزيعها على أجهزة متعددة، مما يزيد من تعقيد الجدولة والمزامنة.
لنأخذ AllGather GEMM كمثال، لنفترض أن شريحةً تحتوي على بيانات محلية وبعيدة. إذا بدأت العملية الحسابية من هذه الشريحة، فيجب انتظار إرسال البيانات البعيدة أولاً، مما سيؤدي إلى ظهور فقاعات بيانات إضافية ويؤثر على التوازي الكلي للعملية الحسابية. النهج الأفضل هو تجاوز شريحة الرتب المتقاطعة هذه، وإعطاء الأولوية لمعالجة البيانات المتوفرة محليًا بالكامل، وجدولة الشريحة بحيث تنتظر تنفيذ الإدخال البعيد أخيرًا، وذلك لتحقيق أقصى قدر من التداخل بين الاتصال والحساب.
في سيناريو ReduceScatter، يجب عكس ترتيب الجدولة. نظرًا لضرورة إرسال نتائج حسابات الشرائح المتقاطعة إلى الطرف البعيد في أسرع وقت ممكن، فإن أفضل استراتيجية هي إعطاء الأولوية للشرائح التي تعتمد عليها العقد البعيدة، وذلك لإتمام نقل البيانات بين الأجهزة في أسرع وقت ممكن وتقليل الاعتماد على الطرف البعيد.
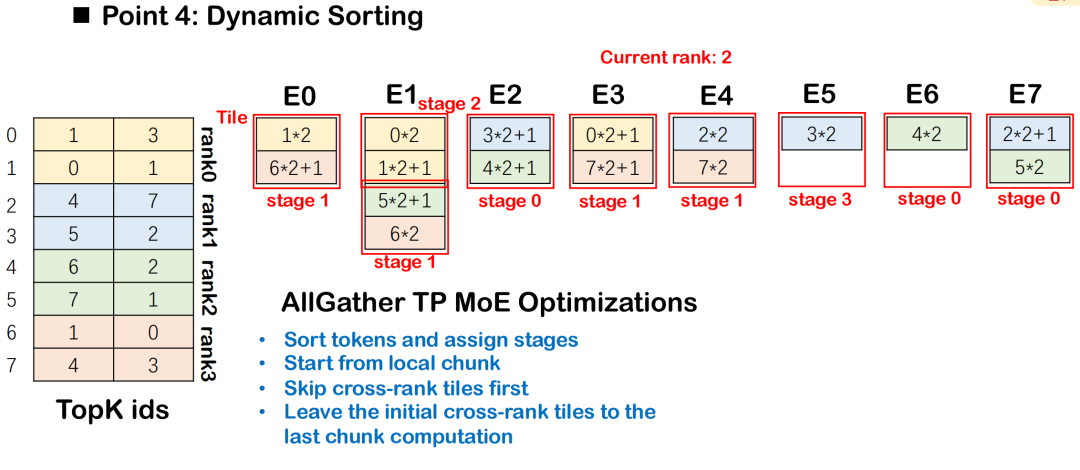
استراتيجية الفرز الديناميكي في وزارة التربية والتعليم
في نموذج MoE (مزيج الخبراء)، يجب توزيع الرموز على خبراء متعددين بناءً على نتائج التوجيه، مصحوبةً عادةً باتصالات شاملة وحسابات GEMM للمجموعة. لتحسين كفاءة التداخل بين الاتصالات والحوسبة، يُقدّم نظام Triton-distributed نظام الفرز الديناميكي، الذي يُجدول مهام الحوسبة على مراحل وفقًا لشدة اعتمادها على بيانات الاتصالات، مع إعطاء الأولوية للمهام الأقل اعتمادًا على البيانات.
يضمن هذا الترتيب أن حساب كل مرحلة يمكن أن يبدأ بأقل قدر ممكن من حجب الاتصالات، وبالتالي تحقيق تداخل أفضل بين الكل إلى الكل والمجموعة GEMM.يبدأ الجدول الشامل من المربع الذي يحتوي على أقل قدر من التبعيات للبيانات ويتوسع تدريجيًا إلى المربعات التي تحتوي على التبعيات المعقدة، مما يعمل على تعظيم التزامن في التنفيذ.
تسريع الاتصالات القائمة على الأجهزة
يدعم Triton الموزع أيضًا تحسين الاتصالات بالاشتراك مع إمكانيات الأجهزة المحددة.عند استخدام بنية NVSwitch، يُمكن استخدام مُسرّع SHARP المُدمج فيها لإجراء حسابات اتصالات منخفضة الكمون. تُنجز هذه الوحدة عمليات مثل البث والتخفيض الكامل في شريحة التبديل، مما يُسرّع تجميع البيانات في مسار الإرسال، مما يُقلل من زمن الوصول واستهلاك النطاق الترددي. تم دمج التعليمات ذات الصلة في نظام Triton المُوزّع، ويمكن للمستخدمين الذين لديهم عتاد مُناسب استدعاؤها مُباشرةً لبناء نواة اتصالات أكثر كفاءة.
تحسين تجميع AOT: تقليل تكلفة زمن الوصول إلى الاستدلال
يُقدّم نظام Triton الموزع آلية AOT (التنفيذ المسبق)، المُحسّنة خصيصًا لتلبية المتطلبات شديدة الحساسية لزمن الوصول في سيناريوهات الاستدلال. يستخدم Triton أسلوب التجميع JIT (التجميع الفوري) افتراضيًا، مما يُسبب تكلفة تجميع وذاكرة تخزين مؤقت كبيرة عند تنفيذ الوظيفة لأول مرة.
تتيح آلية AOT للمستخدمين تجميع الدوال مسبقًا إلى بايت كود قبل تشغيلها، وتحميلها وتنفيذها مباشرةً أثناء مرحلة الاستدلال، متجنبين عملية تجميع JIT، مما يُقلل بفعالية من التأخير الناتج عن التجميع والتخزين المؤقت. بناءً على ذلك، وسّع Triton-distributed آلية AOT، ويدعم الآن تجميع AOT ونشره في بيئات موزعة، مما يُحسّن أداء الاستدلال الموزع بشكل أكبر.
قياس الأداء وإعادة إنتاج الحالة
أجرينا اختبارًا شاملاً لأداء Triton-distributed في سيناريوهات متعددة المنصات ومتعددة المهام، تغطي NVIDIA H800، ووحدة معالجة الرسومات AMD، ووحدة معالجة الرسومات المكونة من 8 بطاقات، ومجموعات متعددة الأجهزة، وقارنا حلول التنفيذ الموزعة السائدة مثل PyTorch وFlux.
على 8 بطاقات GPU،يحقق توزيع Triton تسريعًا كبيرًا مقارنةً بتنفيذ PyTorch في مهام AG GEMM وGEMM RS.مقارنةً بحل Flux المُحسّن يدويًا، يُحقق هذا الحل أداءً أفضل بفضل تحسينات متعددة، مثل جدولة Swizzling، وتفريغ الاتصالات، وتجميع AOT. في الوقت نفسه، مقارنةً بدمج PyTorch وRCCL على منصة AMD، على الرغم من انخفاض التسارع الإجمالي قليلاً، إلا أنه يُحقق تحسينًا ملحوظًا. تكمن القيود الرئيسية في ضعف قدرة الحوسبة لأجهزة الاختبار وبنية البنية غير المُبدّلة.
في مهمة AllReduce،تتمتع Triton-distributed بسرعات كبيرة مقارنة بـ NCCL في تكوينات الأجهزة التي اختبرناها لمجموعة متنوعة من أحجام الرسائل من الصغيرة إلى الكبيرة، مع متوسط تسريع يبلغ حوالي 1.6 مرة.في سيناريو الانتباه، اختبرنا بشكل رئيسي عملية الانتباه من نوع collect-KV. بالمقارنة مع التنفيذ الأصلي لـ PyTorch Touch، يمكن تحسين أداء Triton الموزع على 8 بطاقات معالجة رسومية بنحو 5 مرات؛ وهو أيضًا أفضل من تنفيذ Ring Attention مفتوح المصدر، حيث بلغ التحسن حوالي ضعفين.
الاختبار عبر الآلات:إن AG GEMM أسرع بـ 1.3 مرة وGEMM RS أسرع بـ 1.4 مرة، وهو أقل قليلاً من Flux، ولكنه يتمتع بمزايا أكثر في مرونة الشكل وقابلية التوسع.اختبرنا أيضًا فك تشفير رمز واحد في سيناريوهات استدلال عالية السرعة. تم التحكم في زمن الوصول خلال ٢٠-٣٠ ميكروثانية في سياق رمز واحد، وهو متوافق مع NVLink وPCIe.
بالإضافة إلى ذلك، قمنا بإعادة إنتاج منطق الجدولة الموزعة في DeepEP، مع مواءمة استراتيجيات التوجيه الشامل وتوزيع السياقات بشكل رئيسي. في السيناريوهات التي تحتوي على أقل من 64 بطاقة، يكون أداء توزيع Triton مماثلاً لأداء DeepEP، مع تحسن طفيف في بعض التكوينات.
أخيرًا، نوفر أيضًا عرضًا تجريبيًا للتعبئة المسبقة وفك التشفير يعتمد على Qwen-32B، والذي يدعم النشر والتشغيل على 8 بطاقات معالجة رسومية. يُظهر الاختبار الفعلي إمكانية تحقيق تأثير تسريع الاستدلال بنحو 1.2 مرة.
بناء نظام بيئي مفتوح للتجميع الموزع
نحن نواجه حاليًا تحدي السيناريوهات المتداخلة المخصصة، والتي اعتمدنا بشكل أساسي على التحسين اليدوي لحلها في الماضي، وهو ما يتطلب عمالة مكثفة ومكلف.لقد اقترحنا إطار عمل Triton الموزع وجعلناه مفتوح المصدر.على الرغم من أنه يتم تنفيذه على أساس Triton، بغض النظر عن المترجم أو مكتبة الاتصالات الأساسية التي تستخدمها كل شركة، فإنه يمكن دمجه لإنشاء نظام بيئي مفتوح موزع.
لا يزال هذا المجال شاغرًا نسبيًا في الصين، بل وحتى في العالم. نأمل أن نستغل قوة مجتمعنا لجذب المزيد من المطورين للمشاركة، سواءً في تصميم قواعد اللغة، أو تحسين الأداء، أو دعم أنواع أخرى من الأجهزة، لنساهم معًا في تعزيز التقدم التكنولوجي. أخيرًا، حققنا أداءً جيدًا، وجميع الأمثلة ذات الصلة مفتوحة المصدر. نرحب بطرح قضايا التواصل بنشاط، ونتطلع إلى انضمام المزيد من الشركاء إلينا لبناء مستقبل أفضل!








