Command Palette
Search for a command to run...
مهندس الذكاء الاصطناعي في AMD Zhang Ning: تحليل مُجمِّع AMD Triton من وجهات نظر متعددة للمساعدة في بناء نظام بيئي مفتوح المصدر

في الخامس من يوليو، انعقدت الدورة السابعة من صالون "لقاء تقنيات مُجمّعي الذكاء الاصطناعي" الذي استضافته شركة HyperAI في موعدها المحدد. ورغم حرارة الصيف الحارقة، ظلّ حماس الجمهور قويًا. امتلأ المكان بالحضور، حتى أن الكثير منهم وقف للاستماع إلى كل جلسة. تناوب العديد من المحاضرين من AMD وMuxi Integrated Circuits وByteDance وجامعة بكين على إلقاء المحاضرات، مقدمين رؤىً عميقة في هذا المجال وتحليلاتٍ للاتجاهات، بدءًا من مرحلة التجميع وصولًا إلى التطبيق العملي، زاخرةً بالمعلومات العملية!
اتبع حساب WeChat العام "HyperAI Super Neuro" وأجب على الكلمة الرئيسية "0705 AI Compiler" للحصول على عرض تقديمي للمحاضر المعتمد PPT.




باعتبارها لغة برمجة مصممة لتبسيط تطوير نواة وحدة معالجة الرسومات (GPU) عالية الأداء، أصبحت تريتون أداةً أساسيةً في إطار عمل LLM للاستدلال والتدريب، وذلك بتبسيط برمجة الحوسبة المتوازية المعقدة. ميزتها الأساسية هي الموازنة بين كفاءة التطوير وأداء الأجهزة، إذ تتجنب الكشف عن تفاصيل الأجهزة الأساسية، ويمكنها إطلاق العنان لقدرة وحدة معالجة الرسومات (GPU) من خلال تحسين المُجمِّع. وقد أكسبتها هذه الميزة شعبيةً سريعةً في مجتمع المصادر المفتوحة.
بصفتها شركة رائدة في مجال وحدات معالجة الرسومات (GPU)، أخذت AMD زمام المبادرة في دعم لغة Triton والمساهمة في تطوير برمجياتها ذات الصلة لمجتمع المصادر المفتوحة، وذلك لتعزيز توافق نظام Triton بين مختلف الموردين. لا يقتصر هذا التطور على تعزيز النفوذ التقني لشركة AMD في مجال الحوسبة عالية الأداء، بل يوفر أيضًا للمطورين العالميين خيارات برمجة أكثر مرونة لوحدات معالجة الرسومات من خلال نموذج تعاون مفتوح المصدر، لا سيما في سيناريوهات تدريب واستنتاج النماذج الكبيرة، مما يفتح آفاقًا جديدة لتحسين قوة الحوسبة.
في خطاب بعنوان "دعم مجتمع المصدر المفتوح، وتحليل مُجمِّع AMD Triton"، قام Zhang Ning، وهو مهندس ذكاء اصطناعي من AMD، بتفسير التكنولوجيا الأساسية، ودعم البنية التحتية، وإنجازات البناء البيئي لمُجمِّع AMD Triton، مع التركيز على المساهمات التقنية للشركة في مجتمع المصدر المفتوح.إنه يوفر للمطورين منظورًا شاملاً لفهم برمجة وحدة معالجة الرسومات عالية الأداء وتحسين المترجم بشكل عميق.
قامت شركة HyperAI بجمع وتلخيص خطاب البروفيسور تشانغ نينغ دون المساس بالهدف الأصلي. فيما يلي نص الخطاب.
تريتون: برمجة فعالة، وتجميع في الوقت الفعلي، وتكرار مرن
تم اقتراح Triton بواسطة OpenAI وهي لغة برمجة ومُجمِّع مفتوح المصدر مصمم لتبسيط تطوير نوى وحدة معالجة الرسومات عالية الأداء.يُستخدم على نطاق واسع في أطر تدريب التفكير المنطقي السائدة في ماجستير القانون. ومن ميزاته الأساسية:
* يمكن للبرمجة الفعالة تبسيط تطوير Kernel، مما يسمح للمطورين بكتابة كود وحدة معالجة الرسومات بكفاءة دون الحاجة إلى فهم عميق للهندسة المعمارية المعقدة الأساسية لوحدة معالجة الرسومات؛
* التجميع في الوقت الفعلي، ودعم التجميع في الوقت المناسب، يمكن أن يولد بشكل ديناميكي ويحسن كود وحدة معالجة الرسومات للتكيف مع متطلبات الأجهزة والمهام المختلفة؛
* هيكل مساحة التكرار المرن، الذي يعتمد على برنامج الكتلة والخيط القياسي، يعزز مرونة مساحة التكرار، ويسهل التعامل مع العمليات المتفرقة ويحسن موقع البيانات.
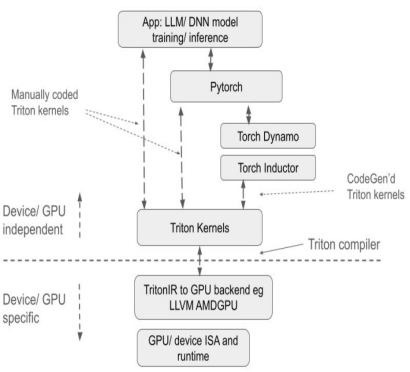
بالمقارنة مع الحلول التقليدية، يتمتع Triton بمزايا كبيرة:
أولاً،كمشروع مفتوح المصدر، يوفر تريتون بيئة برمجة قائمة على بايثون. يمكن للمستخدمين تنفيذ نواة وحدة معالجة الرسومات (GPU Kernel) من خلال تطوير شيفرة تريتون بلغة بايثون دون الاهتمام بتفاصيل بنية وحدة معالجة الرسومات الأساسية، مما يُخفف بشكل كبير من صعوبة التطوير ويُحسّن كفاءة تطوير المنتج بشكل ملحوظ مقارنةً بأساليب برمجة وحدات معالجة الرسومات الأخرى مثل AMD HIP. يستخدم مُجمّع تريتون استراتيجيات تحسين مُتنوعة بناءً على خصائص بنية وحدة معالجة الرسومات لتحويل شيفرة بايثون إلى شيفرة تجميع مُحسّنة لوحدة معالجة الرسومات، وتحقيق التجميع التلقائي لعمليات الموتر عالية المستوى لتعليمات وحدة معالجة الرسومات الأساسية، وضمان كفاءة تشغيل الشيفرة على وحدة معالجة الرسومات.
ثانيًا،يتمتع Triton بتوافق جيد بين مختلف الأجهزة. نظريًا، يمكن تشغيل نفس مجموعة التعليمات البرمجية على مجموعة متنوعة من الأجهزة، بما في ذلك وحدات معالجة الرسومات NVIDIA وAMD، بالإضافة إلى وحدات معالجة الرسومات المحلية التي تدعم Triton. من حيث الأداء والمرونة، يوفر Triton أداءً ومرونة في التحسين أفضل من منصات مثل PyTorch، كما أنه يُخفي تفاصيل تشغيل وحدة معالجة الرسومات الأساسية مقارنةً بـ CUDA، مما يسمح للمطورين بالتركيز بشكل أكبر على تنفيذ الخوارزميات.
مقارنةً بواجهة برمجة تطبيقات PyTorch، تُركز هذه الواجهة بشكل أكبر على التنفيذ الدقيق لعمليات الحوسبة، مما يسمح للمطورين بتحديد أساليب تجزئة كتلة الخيوط بمرونة، وتشغيل قراءة وكتابة البيانات على مستوى الكتلة/البلاط، وتنفيذ بدائيات الحوسبة المتعلقة بالعتاد. وهي مناسبة بشكل خاص لتطوير استراتيجيات تحسين الأداء مثل دمج المشغل وضبط المعلمات.
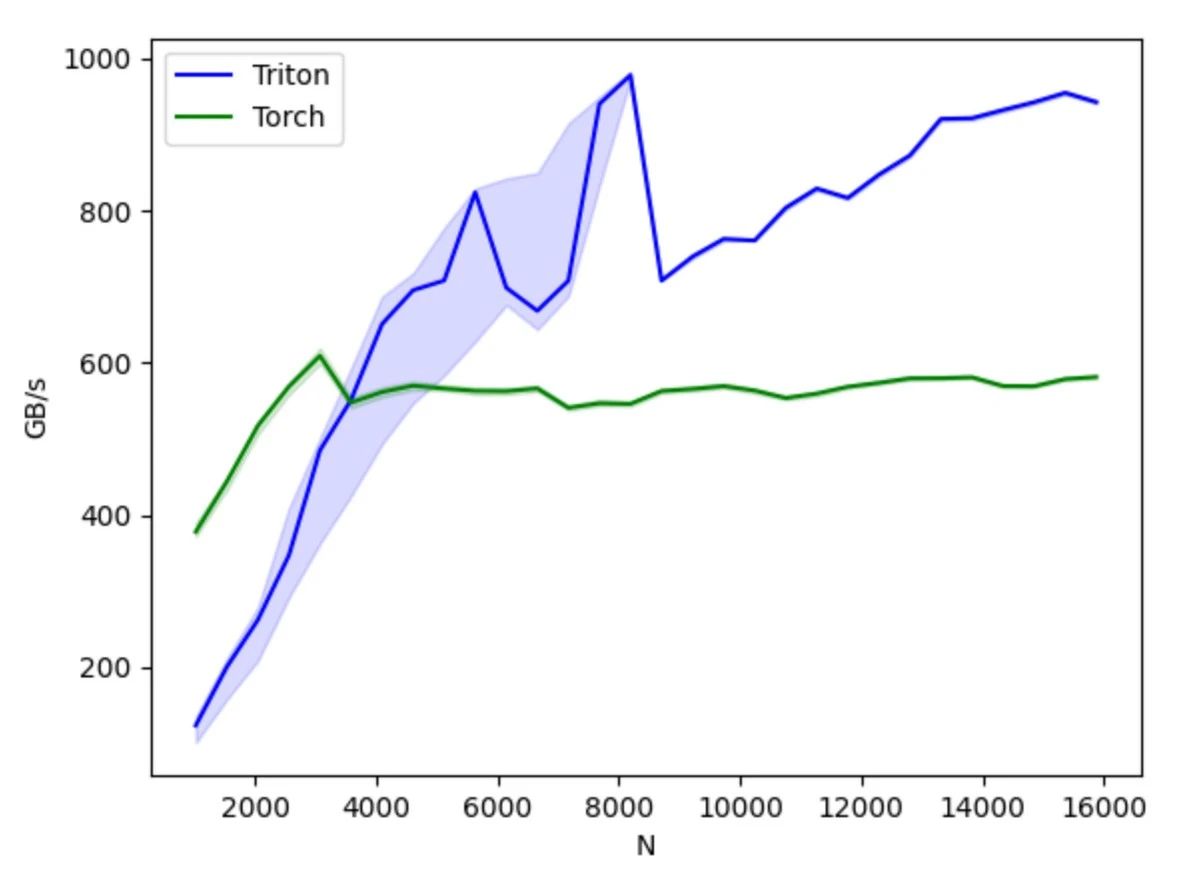
مقارنةً بـ CUDA، يُخفي Triton التحكم في العمليات على مستوى الخيط، ويتيح للمُجمِّع التحكم تلقائيًا في تفاصيل مثل التخزين المُشترك، وتوازي الخيط، والوصول إلى الذاكرة المُدمجة، وتخطيط الموتر، مما يُقلل من صعوبة نموذج البرمجة المتوازية، ويُحسِّن كفاءة تطوير شيفرة وحدة معالجة الرسومات (GPU)، مُحققًا توازنًا فعالًا بين كفاءة التطوير وأداء البرنامج. يُمكن للمطورين التركيز على تصميم وتنفيذ الخوارزمية دون القلق كثيرًا بشأن تفاصيل الأجهزة الأساسية وتقنيات تحسين البرمجة. ما داموا مُلِمّين بمبادئ البرمجة المتوازية البسيطة، يُمكنهم تطوير شيفرة وحدة معالجة الرسومات بسرعة وأداء أفضل.
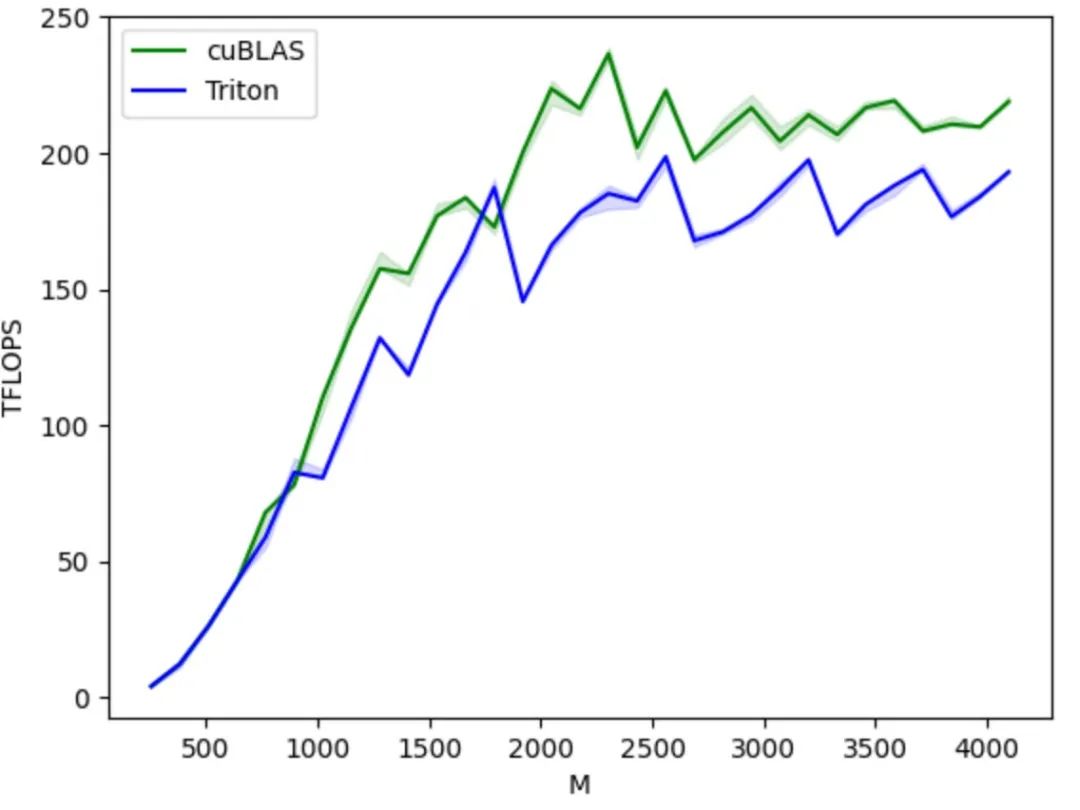
من منظور بيئي، يعتمد نظام Triton على بيئة لغة بايثون، ويستخدم نوع بيانات الموتر المُعرّف من قِبل PyTorch، ويمكن دمج وظائفه بسلاسة في بيئة PyTorch. مقارنةً بنظام CUDA المغلق، يُسهّل شيفرة Triton مفتوحة المصدر ونظامها البيئي المفتوح على مُصنّعي شرائح الذكاء الاصطناعي نقله إلى شرائحهم الخاصة، واستخدام مجتمع المصادر المفتوحة لتحسين سلسلة أدواتهم، مما يُعزز أيضًا التطوير السليم لنظام Triton البيئي.
عملية تجميع AMD Triton
يتكون مُجمِّع Triton من ثلاث وحدات رئيسية: وحدة الواجهة الأمامية، ووحدة المُحسِّن، ووحدة توليد الكود الآلي الخلفية، كما هو موضح في الشكل التالي:
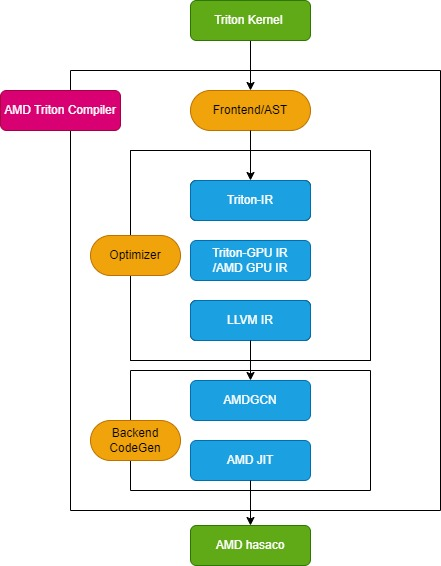
وحدة الواجهة الأمامية
تقوم وحدة الواجهة الأمامية باجتياز شجرة بناء الجملة المجردة (AST) لوظيفة نواة Python Triton لإنشاء التمثيل الوسيط لـ Triton (Triton-IR)، ويتم تحويل وظيفة النواة الخاصة بها إلى Triton-IR.على سبيل المثال، سيتم تحويل دالة نواة add_kernel المُعلَّمة بـ @triton.jit إلى دالة الإدخال المقابلة في هذه الوحدة. تتحقق دالة إدخال مُعلِّم JIT أولاً من قيمة متغير البيئة TRITON_INTERPRET. إذا كانت قيمة المتغير صحيحة، تُستدعى الدالة InterpretedFunction لتشغيل نواة Triton في الوضع المُفسَّر؛ وإذا كانت خاطئة، تُشغَّل الدالة JITFunction لتجميع نواة Triton وتنفيذها على الجهاز الفعلي.
نقطة الدخول لتجميع النواة هي دالة تجميع تريتون، التي تُستدعى مع معلومات الجهاز المستهدف وخيار التجميع. تُنشئ هذه العملية مدير ذاكرة التخزين المؤقت للنواة، وتبدأ مسار التجميع، وتُملأ بيانات تعريف النواة. بالإضافة إلى ذلك، تُحمّل لهجات خاصة بالواجهة الخلفية، مثل TritonAMDGPUDialect لمنصات AMD، ووحدات LLVM الخاصة بالواجهة الخلفية التي تُعالج تجميع LLVM-IR. إذا كانت جميع الاستعدادات جاهزة، تُستدعى دالة ast_to_ttir لإنشاء ملف Triton-IR للنواة.
وحدة المُحسِّن
تنقسم وحدة التحسين إلى 3 أجزاء أساسية: تحسين Triton-IR، وتحسين Triton-GPU IR، وتحسين LLVM-IR.
* تحسين Triton-IR
على منصات AMD، يُعرَّف خط أنابيب تحسين Triton-IR بواسطة دالة make_ttir. في هذه المرحلة، تكون عمليات التحسين مستقلة عن الأجهزة، وتشمل التضمين الداخلي، وإزالة التعبيرات الفرعية الشائعة، والتطبيع، وإزالة الكود الميت، ونقل الكود الثابت للحلقة، وفك الحلقة.
* تحسين الأشعة تحت الحمراء لـ Triton-GPU
على منصة AMD، تُعرّف دالة make_ttgir عملية تحسين Triton-IR لتحسين أداء وحدة معالجة الرسومات. واستنادًا إلى خصائص وحدات معالجة الرسومات AMD وخبرة التحسين، طوّرنا أيضًا عملية تحسين محددة، كما هو موضح في الشكل التالي:
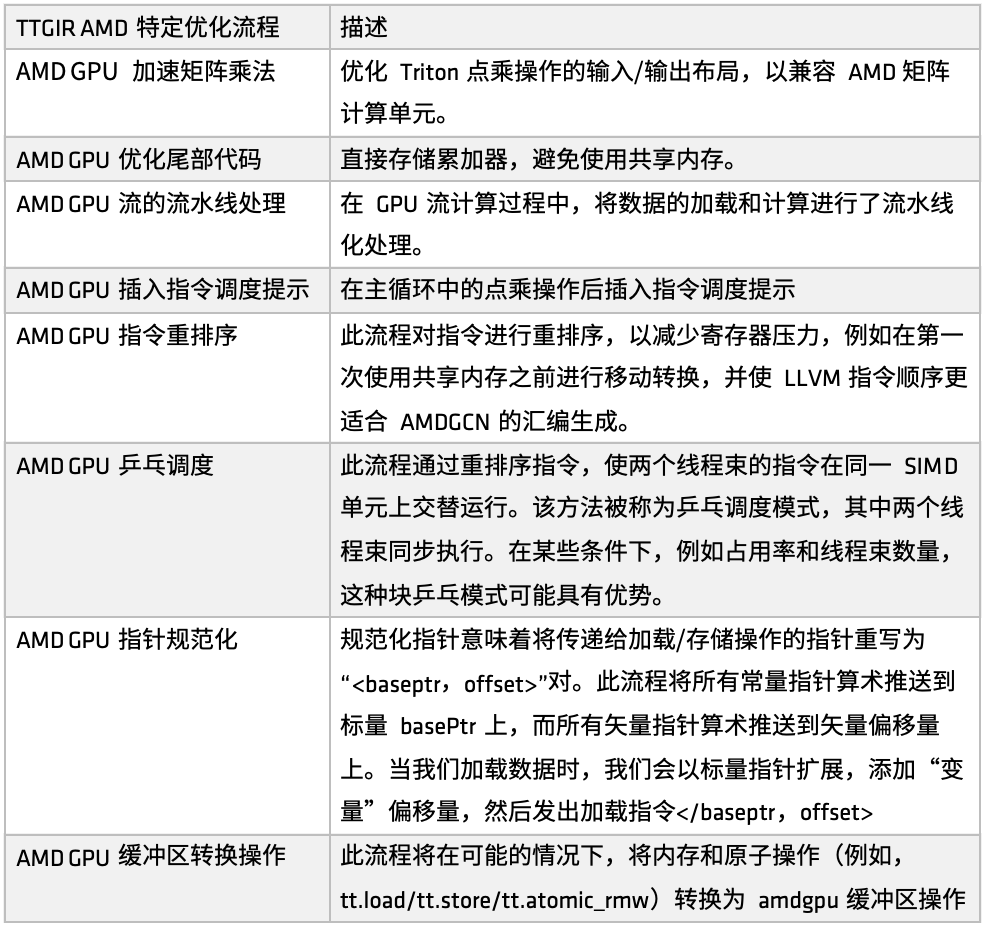
أولاً، مضاعفة المصفوفة المتسارعة لوحدات معالجة الرسومات AMD،يركز التحسين على تخطيط الإدخال/الإخراج لعملية ضرب النقاط في تريتون، مما يجعله أكثر توافقًا مع وحدة الحوسبة المصفوفية من AMD (مثل ماتريكس). يتضمن هذا التحسين معالجة مطابقة مكثفة لبنية CDNA، وهو جزء كبير نسبيًا من عملية التنفيذ بأكملها. إذا كنت ترغب في تحسين الكود المُولّد بواسطة تريتون على منصة AMD بشكل عميق، فإن هذا الجزء من التنفيذ يستحق التركيز عليه.
ثانياً، في مرحلة معالجة الذيل،تتمثل استراتيجية التحسين في تخزين المجمع بشكل مباشر، وبالتالي تجنب استخدام الذاكرة المشتركة، وتقليل ضغط الوصول إلى الذاكرة المشتركة، وتحسين الكفاءة الشاملة.
بعد ذلك، في عملية الحوسبة المتدفقة لوحدة معالجة الرسوميات، تم تقديم معالجة خط الأنابيب للتحميل والحوسبة.أي أنه أثناء تنفيذ المهمة السابقة، تُستدعى الذاكرة المقابلة لتحميل البيانات، مما يُشكّل نمطًا للتنفيذ المتوازي للتحميل والحوسبة. وقد حققت هذه الآلية نتائج جيدة في العديد من سيناريوهات الاستخدام. واستنادًا إلى تحسين خط الأنابيب، تُقدّم أيضًا تلميحات لجدولة التعليمات لتوجيه تدفق التعليمات بعد اكتمال وحدة الحوسبة أو التشغيل عن بُعد، مما يُحسّن كفاءة الاستجابة على مستوى التعليمات.
وبعد ذلك، قامت AMD بتنفيذ مجموعات متعددة من إعادة ترتيب التعليمات لأغراض مختلفة.بما في ذلك: تخفيف ضغط السجل، وتجنب تخصيص الموارد الزائدة والإصدار، وتحسين الاتصال بين عملية التحميل والحساب، وما إلى ذلك. يتم دمج جزء واحد من إعادة الترتيب بشكل وثيق مع آلية خط الأنابيب، ويركز الجزء الآخر على تعديل ترتيب تعليمات LLVM IR لخدمة قواعد توليد تجميع AMDGCN بشكل أفضل.
بالإضافة إلى تلميحات إعادة ترتيب التعليمات والجدولة،لقد قدمنا أيضًا استراتيجية أخرى لتحسين الجدولة - جدولة تنس الطاولة.من خلال آلية الجدولة الدائرية، يتم تنفيذ تشوهين للخيوط بالتناوب على نفس وحدة SIMD لتجنب الخمول والانتظار، وبالتالي تحسين استخدام موارد الحوسبة.
بالإضافة إلى ذلك، قامت AMD بإجراء تحسينات في تطبيع المؤشر وتحويلات تشغيل المخزن المؤقت.الهدف الرئيسي من هذا التحسين هو ربط التعليمات بشكل فعال بتطبيقات الأعمال المحددة وتحقيق تنفيذ تعليمات ذرية أكثر كفاءة.
تُحوّل عمليات التحسين هذه أولاً Triton-IR إلى Triton-GPU IR. في هذه العملية، تُدمج معلومات التخطيط في IR. خذ الشكل التالي كمثال، حيث يُمثَّل الموتر بصيغة تخطيط مُحظور #.

إذا حاولنا تجربة مثال آخر لضرب مصفوفة Triton، فإن تدفق التحسين أعلاه يقدم إمكانية الوصول إلى الذاكرة المشتركة لتحسين الأداء، وهو حل تحسين شائع لضرب المصفوفة، مع استخدام تخطيط amd_mfma المصمم لمسرع AMD MFMA.
أخيرا،في عملية التحقق التجريبي، استخدمتُ طبقة مصفوفة ضرب المصفوفات الأكثر تعقيدًا كمثال. أثناء عملية تأكيد تعيين سجل الأغراض العامة (GPR)، أُدرج عدد كبير من التعليمات المتعلقة بالعتاد، مثل MFMA، والنقل، واستدعاءات الذاكرة المشتركة، وغيرها. من خلال تقليل تضاربات البيانات، وتطبيق عمليات التبديل، والجمع بين إعادة ترتيب التعليمات واستراتيجيات معالجة خط الأنابيب، ستُضاف جميع هذه التحسينات تلقائيًا أثناء عملية تحويل Triton IR لتحقيق مرونة أكبر في العتاد وتحسين الأداء.

* تحسين LLVM-IR
في منصات AMD، تُعرّف دالة make_llir عملية التحسين. تتضمن هذه الدالة جزأين: تحسين مستوى IR وتهيئة مُجمّع AMD GPU LLVM. لتحسين مستوى IR، تتضمن عملية التحسين الخاصة بوحدة معالجة الرسومات AMD تحسينات متعلقة بـ LDS/الذاكرة المشتركة، وتحسينات عامة على مستوى LLVM-IR، كما هو موضح في الشكل التالي:
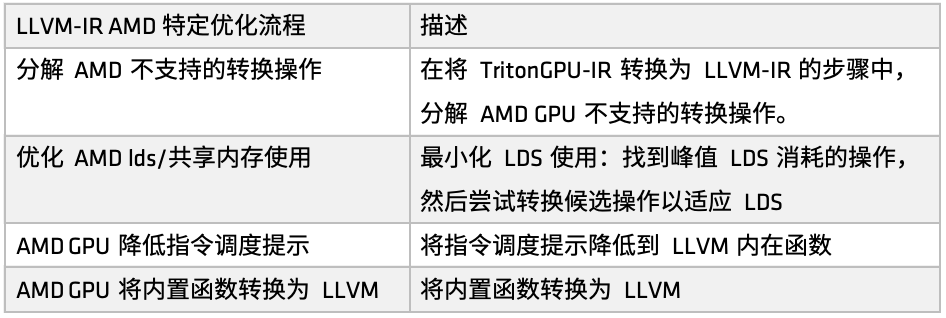
أولاً،تحليل بعض عمليات التحويل التي لا تدعمها AMD. على سبيل المثال، عند تحويل Triton GPU IR إلى LLVM-IR، إذا صادفنا مسارات تحويل غير مدعومة حاليًا، فسنحلل هذه العمليات إلى عمليات فرعية أساسية لضمان إتمام عملية التحويل بسلاسة.
عند تكوين مُجمِّع AMD GPU LLVM، قم أولاً بتهيئة مكتبة LLVM المستهدفة والسياق، ثم قم بتعيين معلمات التجميع على وحدة LLVM، ثم قم بتعيين اتفاقية الاستدعاء لنواة AMD GPU HIP، وقم بتكوين بعض خصائص LLVM-IR مثل amdgpu-flat-work-group-size، وamdgpu-waves-per-eu، وdenormal-fp-math-f32، وأخيرًا قم بتشغيل تحسينات LLVM وقم بتعيين مستوى التحسين إلى OPTIMIZE_O3.
وثائق مرجعية لتكوين الخاصية:
https://llvm.org/docs/AMDGPUUsage.html
وحدة توليد كود الآلة الخلفية
وحدة توليد كود الآلة الخلفية مسؤولة بشكل رئيسي عن تحويل الكود الوسيط إلى ملف ثنائي يعمل على الأجهزة. تنقسم هذه المرحلة بشكل رئيسي إلى خطوتين: توليد كود تجميع AMDGCN، وبناء ملف AMD hsaco ELF النهائي.
أولاً، استدعِ دالة translateLLVMIRToASM لتوليد شيفرة تجميع AMD في مرحلة make_amdgcn. تُكمل هذه العملية عملية الربط بين الشيفرة الوسيطة ومجموعة تعليمات البنية المستهدفة، مما يُمهّد الطريق لتوليد الملفات الثنائية لاحقًا. بعد ذلك، يستخدم المُجمّع دالة assemble_amdgcn ووحدة ربط ROCm لتوليد ملف ثنائي AMD hsaco ELF (تنسيق قابل للتنفيذ والربط) في مرحلة make_hsaco. هذا الملف هو الملف الثنائي النهائي الذي يُمكن تشغيله مباشرةً على وحدة معالجة الرسومات AMD، ويحتوي على تعليمات وبيانات تعريفية كاملة من جانب الجهاز.
من خلال هاتين الخطوتين، يقوم المترجم بتحويل التمثيل المتوسط عالي المستوى بكفاءة إلى كود قابل للتنفيذ على وحدة معالجة الرسومات (GPU) منخفض المستوى، مما يضمن إمكانية تشغيل البرنامج بسلاسة على وحدات معالجة الرسومات (GPU) مثل سلسلة AMD Instinct والاستفادة الكاملة من أداء الأجهزة الأساسية.
سحابة مطوري وحدة معالجة الرسومات AMD
افتتحت AMD رسميًا منصة السحابة الخاصة بوحدة معالجة الرسومات عالية الأداء، AMD Developer Cloud، للمطورين العالميين ومجتمعات المصدر المفتوح.ويهدف إلى تمكين كل مطور من الوصول دون عوائق إلى موارد الحوسبة ذات المستوى العالمي، والوصول بسهولة إلى موارد وحدة معالجة الرسومات AMD Instinct MI series، والبدء بسرعة في مهام الذكاء الاصطناعي والحوسبة عالية الأداء.
في AMD Developer Cloud، يمكن للمطورين اختيار موارد الحوسبة بمرونة استنادًا إلى احتياجاتهم:
* صغير: وحدة معالجة رسومية واحدة من سلسلة MI (ذاكرة فيديو 192 جيجابايت)
* كبير: 8 وحدات معالجة رسومية من سلسلة MI (ذاكرة VRAM سعة 1536 جيجابايت)
تُقلل المنصة من متطلبات التهيئة، ويمكن للمستخدمين بدء تشغيل Jupyter Notebook السحابي فورًا دون الحاجة إلى تثبيت معقد. يُمكن إتمام التهيئة بسهولة باستخدام حساب GitHub أو بريد إلكتروني. بالإضافة إلى ذلك، تُوفر AMD Developer Cloud حاويات Docker مُهيأة مسبقًا مع أطر عمل برمجية رئيسية مُدمجة للذكاء الاصطناعي، مما يُقلل من وقت إعداد البيئة مع الحفاظ على درجة عالية من المرونة، مما يُتيح للمطورين تخصيص الكود وفقًا لاحتياجات المشروع المُحددة.
نرحب بالمطورين لتجربة AMD Developer Cloud شخصيًا، وتشغيل برمجتهم، والتحقق من أفكارهم هنا. ستوفر لكم المنصة دعمًا قويًا ومرنًا لقدرة الحوسبة، مما يُسرّع الابتكار والتنفيذ.
رابط AMD Developer Cloud:
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
احصل على PPT:اتبع حساب WeChat العام "HyperAI Super Neuro" وأجب على الكلمة الرئيسية "0705 AI Compiler" للحصول على عرض تقديمي للمحاضر المعتمد PPT.








