Command Palette
Search for a command to run...
يتضمن البرنامج التعليمي: إنجاز جديد في مجال VLM الطبي! يحقق HealthGPT دقة 99.7% في فهم تقنيات التصوير بالرنين المغناطيسي المعقدة، ويمكن لنموذج واحد التعامل مع مهام توليد متعددة.

يعتمد التشخيص والأبحاث الطبية الحديثة بشكل كبير على تفسير الصور الطبية وإنتاجها. بدءًا من تحديد الآفات بالأشعة السينية ووصولًا إلى تحويل الصور من الرنين المغناطيسي إلى التصوير المقطعي المحوسب، تفرض كل مرحلة متطلبات صارمة على قدرات المعالجة متعددة الوسائط لأنظمة الذكاء الاصطناعي. ومع ذلك، يواجه التطور الحالي لنماذج اللغة البصرية الطبية (LVLMs) عقبتين: من جهة،إن خصوصية البيانات الطبية تؤدي إلى ندرة البيانات الموضحة عالية الجودة على نطاق واسع.عادةً ما يكون حجم مجموعات بيانات التصوير الطبي المتاحة للجمهور واحدًا على عشرة آلاف من مجموعات البيانات العامة، مما يصعب معه بناء نموذج موحد من الصفر. من ناحية أخرى،من الصعب التوفيق بين التناقض الجوهري بين مهام الفهم والتوليد——يتطلب فهم المهام تعميمًا دلاليًا تجريديًا، بينما تتطلب مهام التوليد حفظًا دقيقًا للتفاصيل. غالبًا ما يؤدي التدريب الهجين التقليدي إلى تراجع الأداء بسبب "فقدان شيء ما والتركيز على شيء آخر".
من منظور التطور التكنولوجي، ركزت أجهزة LVLM الطبية المبكرة، مثل Med-Flamingo وLLaVA-Med، بشكل رئيسي على مهام الفهم البصري، محققةً تفسيرًا دلاليًا للصور الطبية من خلال محاذاة النص مع الصورة، لكنها افتقرت إلى قدرات توليد "التصور". أما أجهزة LVLM الموحدة للأغراض العامة، مثل Unified-IO 2 وShow-o، فرغم وظائف توليدها، إلا أنها تُعاني من ضعف الأداء في المهام المهنية نظرًا لعدم كفاية تكييف البيانات الطبية. مُنحت جائزة نوبل في الكيمياء لعام 2024 لإنجازات في مجال التنبؤ ببنية البروتين باستخدام الذكاء الاصطناعي، والتي أكدت بشكل غير مباشر إمكانات الذكاء الاصطناعي في مجال علوم الحياة، وجعلت المجتمع الأكاديمي يُدرك أن بناء أجهزة LVLM طبية بقدرات فهم وتوليد أصبح مفتاحًا لتجاوز العقبات الحالية في تطبيقات الذكاء الاصطناعي الطبي.
في هذا الصدد،اقترحت جامعة تشجيانغ وجامعة العلوم والتكنولوجيا الإلكترونية في الصين نموذج HealthGPT بشكل مشتركمن خلال إطار عمل مبتكر للتكيف مع المعرفة غير المتجانسة،تم بنجاح بناء أول نموذج لغوي بصري واسع النطاق يوحد الفهم والتوليد الطبي المتعدد الوسائط.لقد فتح هذا طريقًا جديدًا لتطوير الذكاء الاصطناعي الطبي، وتم اختيار النتائج ذات الصلة لـ ICML 2025.
عنوان الورقة:
ردًا على التحديين الرئيسيين المتمثلين في محدودية البيانات الطبية والصراع على المهام، اقترح فريق البحث حلاً تقدميًا من ثلاث طبقات:
أولاً، تم تصميم تقنية التكيف غير المتجانسة ذات الرتبة المنخفضة (H-LoRA).من خلال آلية فصل بوابة المهمة، يتم تخزين المعرفة المستفادة والتوليد في "مكونات إضافية" مستقلة، مما يتجنب مشكلة الصراع في تحسين المفصل التقليدي؛
ثانيًا، قم بتطوير إطار الإدراك البصري الهرمي (HVP)،استخدم قدرة استخراج الميزات الهرمية لـ Vision Transformer لتوفير ميزات دلالية مجردة لفهم المهام والاحتفاظ بالميزات المرئية التفصيلية لمهام التوليد، وبالتالي تحقيق تنظيم الميزات "حسب الطلب".
وأخيرًا، تم بناء استراتيجية التعلم المكونة من ثلاث مراحل (TLS).من المحاذاة المتعددة الوسائط إلى دمج المكونات الإضافية غير المتجانسة، ثم إلى ضبط التعليمات البصرية، يتم تزويد النموذج تدريجيًا بقدرات معالجة متعددة الوسائط متخصصة.
مجموعة البيانات: الرسم البياني للمعرفة الطبية المتعددة الوسائط من VL-Health
لدعم تدريب HealthGPT،قام فريق البحث ببناء أول مجموعة بيانات شاملة VL-Health لفهم وتوليد الوسائط الطبية المتعددة.تدمج مجموعة البيانات 765000 عينة من مهام الفهم و783000 عينة من مهام التوليد، وتغطي 11 نموذجًا طبيًا (بما في ذلك التصوير المقطعي المحوسب، والتصوير بالرنين المغناطيسي، والأشعة السينية، والتصوير المقطعي البصري، وما إلى ذلك) وسيناريوهات مرضية متعددة (من أمراض الرئة إلى أورام المخ).
عنوان مجموعة البيانات:
https://hyper.ai/cn/datasets/40990
فيما يتعلق بمهام الفهم، يدمج نظام VL-Health مجموعات البيانات المهنية مثل VQA-RAD (أسئلة الأشعة)، وSLAKE (تحسين معرفة التعليقات الدلالية)، وPathVQA (إجابة أسئلة علم الأمراض)، ويكمل بيانات متعددة الوسائط واسعة النطاق مثل LLaVA-Med وPubMedVision لضمان تعلم النموذج لسلسلة القدرات الكاملة، بدءًا من التعرف الأساسي على الصور ووصولًا إلى التفكير المعقد في علم الأمراض. تركز مهام التوليد بشكل رئيسي على أربعة اتجاهات رئيسية: تحويل الوسائط، والدقة الفائقة، وتوليد النصوص والصور، وإعادة بناء الصور.
* التحويل النمطي:بناءً على بيانات CT-MRI المزدوجة لـ SynthRAD2023، يتم تدريب قدرة التحويل بين الوسائط للنموذج؛
* دقة فائقة:استخدام تصوير الدماغ بالرنين المغناطيسي عالي الدقة من مجموعة بيانات IXI لتحسين دقة إعادة بناء تفاصيل الصورة؛
* توليد النص والصورة:صور الأشعة السينية والتقارير المعتمدة على MIMIC-CXR، مما يتيح توليد وصف النص إلى الصورة؛
* إعادة بناء الصورة:تم تكييف مجموعة البيانات LLaVA-558k لتدريب قدرات ترميز وفك تشفير الصور الخاصة بالنموذج.
خلال مرحلة معالجة البيانات، أجرى الفريق معالجة مسبقة موحدة للصور الطبية، بما في ذلك استخراج الشريحة، وتسجيل الصورة، وتحسين البيانات.وتوحيد جميع العينات في صيغة "الأمر والاستجابة"،يسهل التعليم بعد تدريب النموذج.
هندسة النموذج: تصميم السلسلة الكاملة من الإدراك البصري إلى التوليد الانحداري التلقائي
يعتمد HealthGPT على بنية متعددة الطبقات من "المشفر المرئي - جوهر LLM - المكون الإضافي H-LoRA" لتحقيق معالجة فعالة للمعلومات متعددة الوسائط:
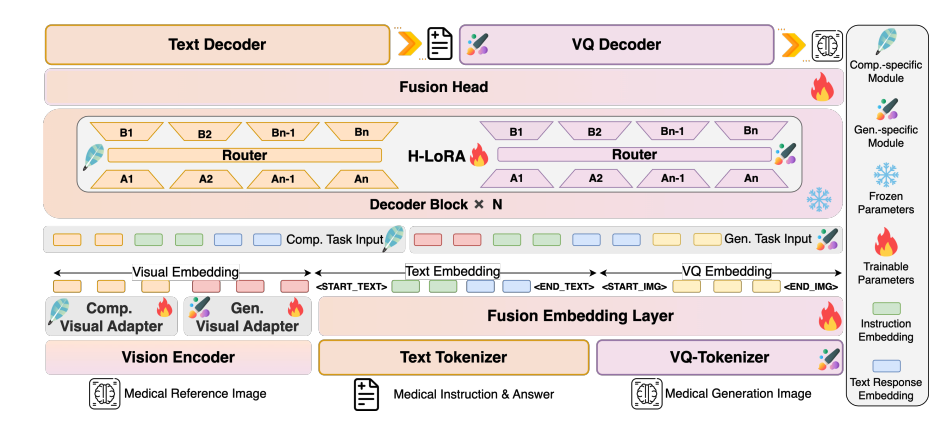
مخطط معماري للنموذج
طبقة الترميز المرئي: استخراج الميزات الهرمية
يُستخدم CLIP-L/14 كمشفّر بصري لاستخراج السمات السطحية (الطبقة الثانية) والعميقة (الطبقة قبل الأخيرة). تُحوّل السمات السطحية إلى سمات حبيبية محددة عبر محوّل MLP ثنائي الطبقات للحفاظ على تفاصيل الصورة؛ بينما يُعالج المحوّل السمات العميقة إلى سمات حبيبية مجردة لالتقاط المفاهيم الدلالية. توفر آلية استخراج السمات ثنائية المسار هذه تمثيلًا بصريًا متكيفًا لمهام الفهم والتوليد اللاحقة.
ماجستير القانون الأساسي: قاعدة المعرفة العامة
بناءً على Phi-3-mini وPhi-4، تم بناء نموذجين بمعلمات مختلفة: HealthGPT-M3 (حجم معلمات النموذج 3.8 مليار) وHealthGPT-L14 (حجم معلمات النموذج 14 مليار). لا يقتصر دور LLM على فهم النصوص وتوليدها فحسب، بل يُعالج أيضًا تسلسلات الرموز المرئية بشكل موحد من خلال آلية انحدار ذاتي - إخراج استجابات نصية لمهام الفهم وإخراج تسلسلات فهرس VQGAN لمهام التوليد، ثم إعادة بناء الصور من خلال مُفكك تشفير VQGAN.
مكون H-LoRA الإضافي: محول خاص بالمهمة
أدخل ملحق H-LoRA في كل وحدة تحويل من برنامج ماجستير إدارة الأعمال، بما في ذلك نوعان من الوحدات الفرعية: الفهم والتوليد. تحتوي كل وحدة فرعية على خبراء متعددين في LoRA، ويتم تفعيل المعرفة بشكل انتقائي من خلال التوجيه الديناميكي لأنواع المهام وإدخال الحالات المخفية. يُدمج الملحق مع الأوزان المجمدة لبرنامج ماجستير إدارة الأعمال لتشكيل نمط تفكير هجين يجمع بين "المعرفة العامة والخبرة في المهام".
الاستنتاج التجريبي: HealthGPT متقدم بشكل كبير في مهام الفهم البصري الطبي والتوليد
فهم المهمة: الريادة في القدرات المهنية
في مهمة فهم الرؤية الطبية، يتفوق HealthGPT بشكل ملحوظ على النماذج الحالية. بمقارنة HealthGPT مع نماذج طبية عامة ومحددة أخرى (مثل Med-Flamingo، وLLA-VA-Med، وHuatuoGPT-Vision، وBLIP-2، وغيرها)، تُظهر النتائج أنيؤدي HealthGPT أداءً جيدًا في مهام الفهم البصري الطبي، ويتفوق بشكل كبير على النماذج الطبية العامة والمحددة الأخرى.
في مجموعة بيانات VQA-RAD، حقق HealthGPT-L14 دقةً بلغت 77.7%، وهو تحسنٌ قدره 29.1% مقارنةً بـ LLaVA-Med؛ وفي اختبار OmniMedVQA المعياري، بلغ متوسط نتيجته 74.4%، وحقق أفضل النتائج في 6 من أصل 7 مهام فرعية، بما في ذلك التصوير المقطعي المحوسب (CT)، والتصوير بالرنين المغناطيسي (MRI)، والتصوير المقطعي البصري (OCT). وبشكلٍ خاص، بلغت دقته في فهم أساليب التصوير بالرنين المغناطيسي المعقدة 99.7%، مما يُظهر فهمه العميق للصور الطبية شديدة الصعوبة.
مهام التوليد: اختراقات في تحويل الوسائط والدقة الفائقة
أظهرت تجربة المهمة التوليدية أن HealthGPT يُظهر أداءً جيدًا في تحويل الصور الطبية وتحسينها. في مهمة تحويل نمط التصوير المقطعي المحوسب إلى التصوير بالرنين المغناطيسي، وصل مؤشر SSIM لجهاز HealthGPT-M3 إلى 79.38 (تصوير الدماغ المقطعي المحوسب إلى التصوير بالرنين المغناطيسي)، وهو أعلى بمقدار 11.6% من الطريقة التقليدية Pix2Pix. كما أن دقة التحويل في المناطق المعقدة مثل الحوض ممتازة. في مهمة الدقة الفائقة، وصل مؤشر SSIM إلى 78.19 ونسبة الإشارة إلى الضوضاء (PSNR) إلى 32.76، متجاوزًا بذلك نماذج SRGAN وDASR وغيرها من النماذج المتخصصة في استعادة التفاصيل، وخاصةً في إعادة بناء هياكل الدماغ بدقة.
ومن الجدير بالذكر أنيمكن لـ HealthGPT التعامل مع مهام إنشاء متعددة في نموذج واحد.تتطلب الطرق التقليدية تدريب نماذج مستقلة لكل مهمة فرعية، وهو ما يسلط الضوء على ميزة الكفاءة التي يوفرها الإطار الموحد.
التحقق من صحة الطريقة: قيمة H-LoRA والاستراتيجية المكونة من ثلاث مراحل
وأكدت تجارب الاستئصال ضرورة التكنولوجيا الأساسية: بعد إزالة H-LoRA، انخفض متوسط أداء مهام الفهم والتوليد بمقدار 18.7%؛ وعندما تم اعتماد التدريب الهجين بدلاً من استراتيجية المراحل الثلاث، تسبب تعارض المهام في تدهور الأداء بمقدار 23.4%.
تُظهر المقارنة بين H-LoRA وMoELoRA أنه عند استخدام أربعة خبراء، يبلغ زمن تدريب H-LoRA 67% فقط مقارنةً بـ MoELoRA، ولكن الأداء يتحسن بمقدار 5.2%، مما يُثبت ميزته المزدوجة في كفاءة الحوسبة وأداء المهام. كما تم التحقق من دور الإدراك البصري الطبقي.يتم تحسين سرعة التقارب بواسطة 40% عند استخدام الميزات المجردة في مهمة الفهم، ويتم تحسين دقة الصورة بواسطة 25% عند استخدام ميزات محددة في مهمة التوليد.
الإمكانات للتطبيق السريري: جسر من البحث إلى الممارسة
في تجربة التقييم البشري، قام خمسة أطباء سريريين بتقييم الإجابات على 1000 سؤال مفتوح بشكل أعمى.بلغت نسبة إجابات HealthGPT-L14 التي تم اختيارها باعتبارها "أفضل الإجابات" 65.7%،يتجاوز بكثير LLaVA-Med (34.08%) وHuatuoGPT-Vision (21.94%).
في الوقت الحالي،هايبر ايه اي هايبر ايه ايأصبح البرنامج التعليمي "HealthGPT: AI Medical Assistant" متاحًا الآن في قسم البرامج التعليمية.ما عليك سوى تحميل صور طبية لبدء محادثة استشارية تُضاهي محادثة الأطباء المحترفين. انضم إلينا وجرّبها!
رابط البرنامج التعليمي:
تشغيل تجريبي
1. بعد الدخول إلى الصفحة الرئيسية لـ hyper.ai، حدد صفحة "البرامج التعليمية"، وحدد "HealthGPT: AI Medical Assistant"، وانقر فوق "تشغيل هذا البرنامج التعليمي عبر الإنترنت".

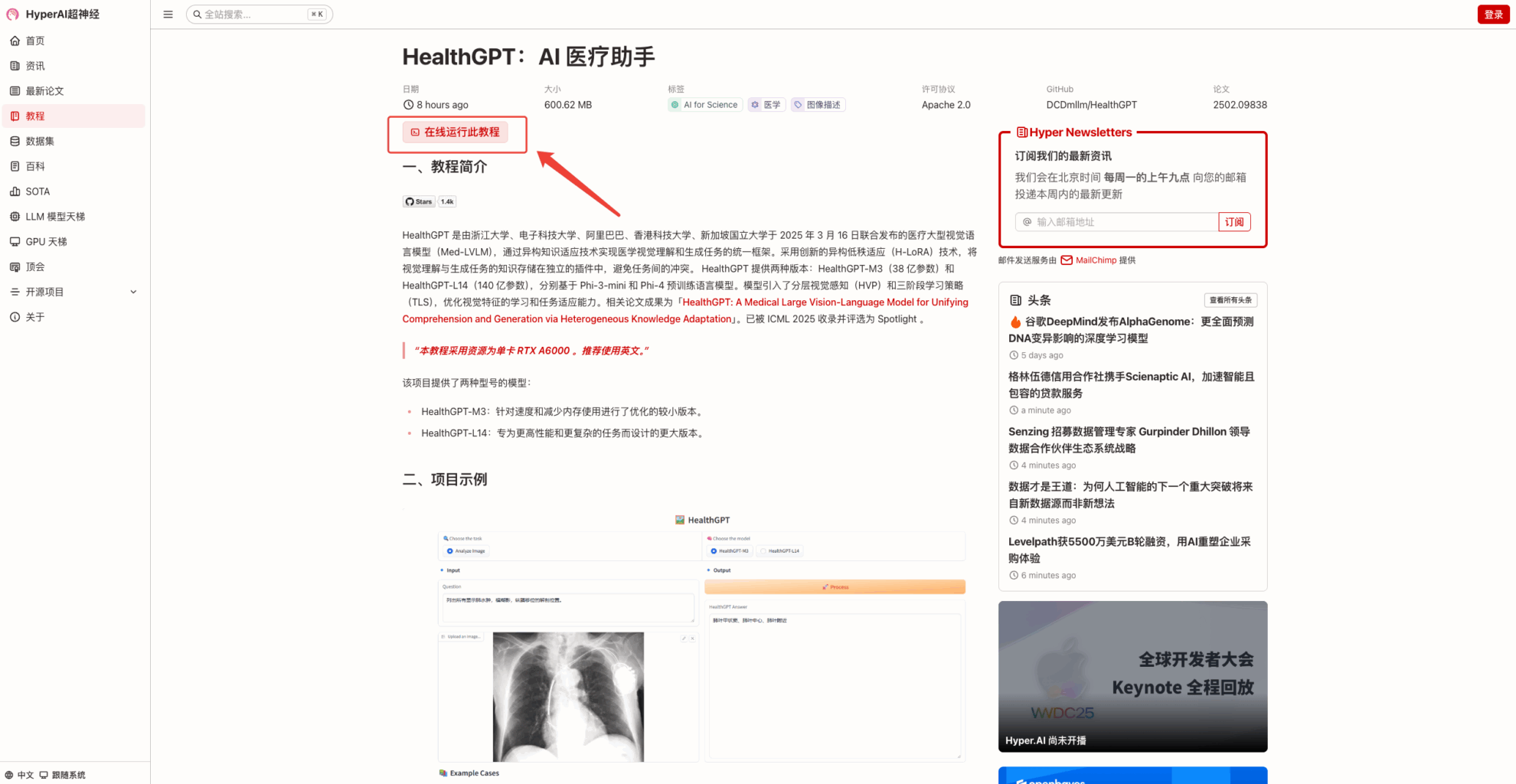
2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
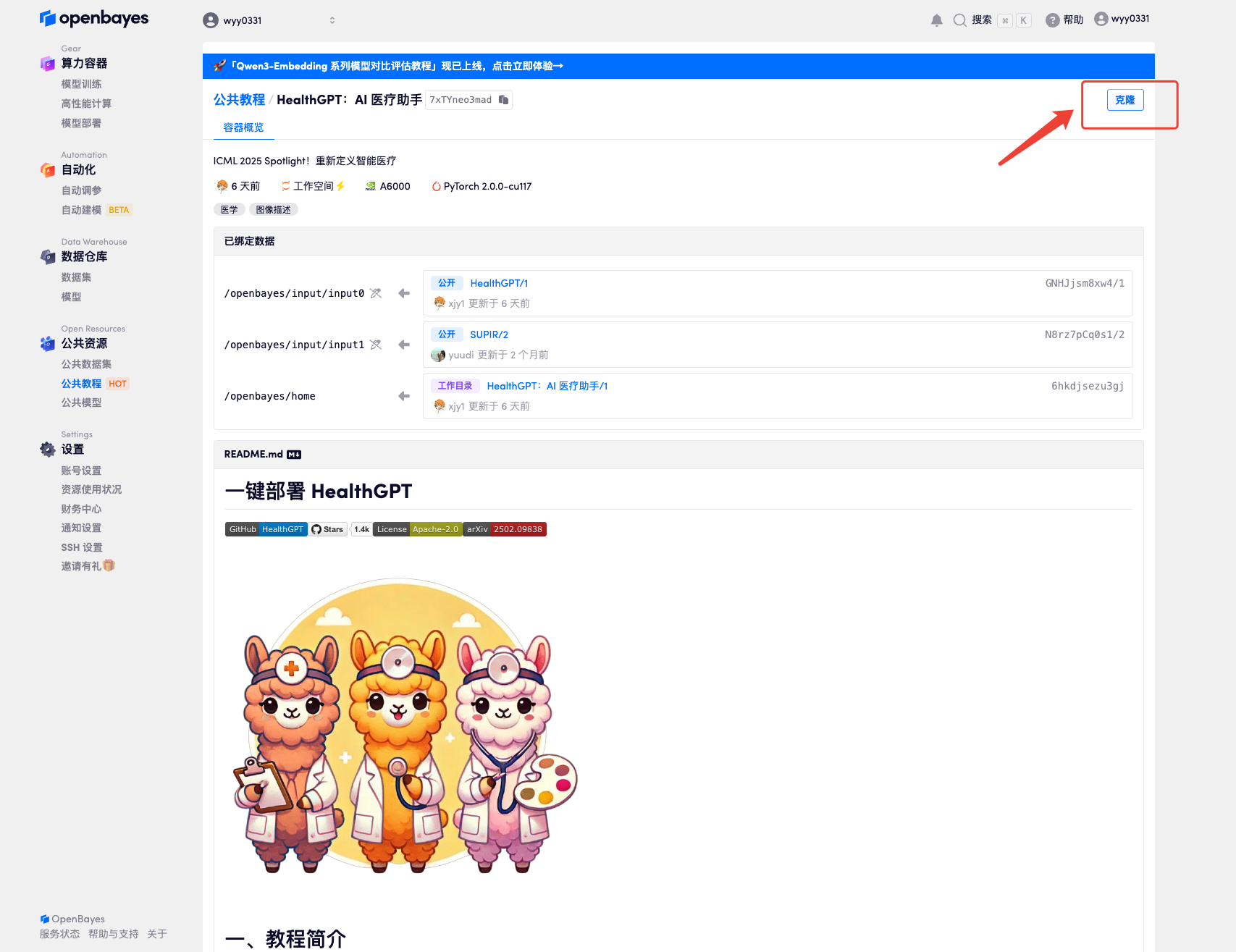
٣. اختر صورتي "NVIDIA RTX A6000" و"PyTorch". توفر منصة OpenBayes أربع طرق دفع. يمكنك اختيار "الدفع الفوري" أو "يومي/أسبوعي/شهري" حسب احتياجاتك. انقر على "متابعة". يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على ٤ ساعات من RTX 4090 + ٥ ساعات من وقت فراغ المعالج!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=Ada0322_NR0n
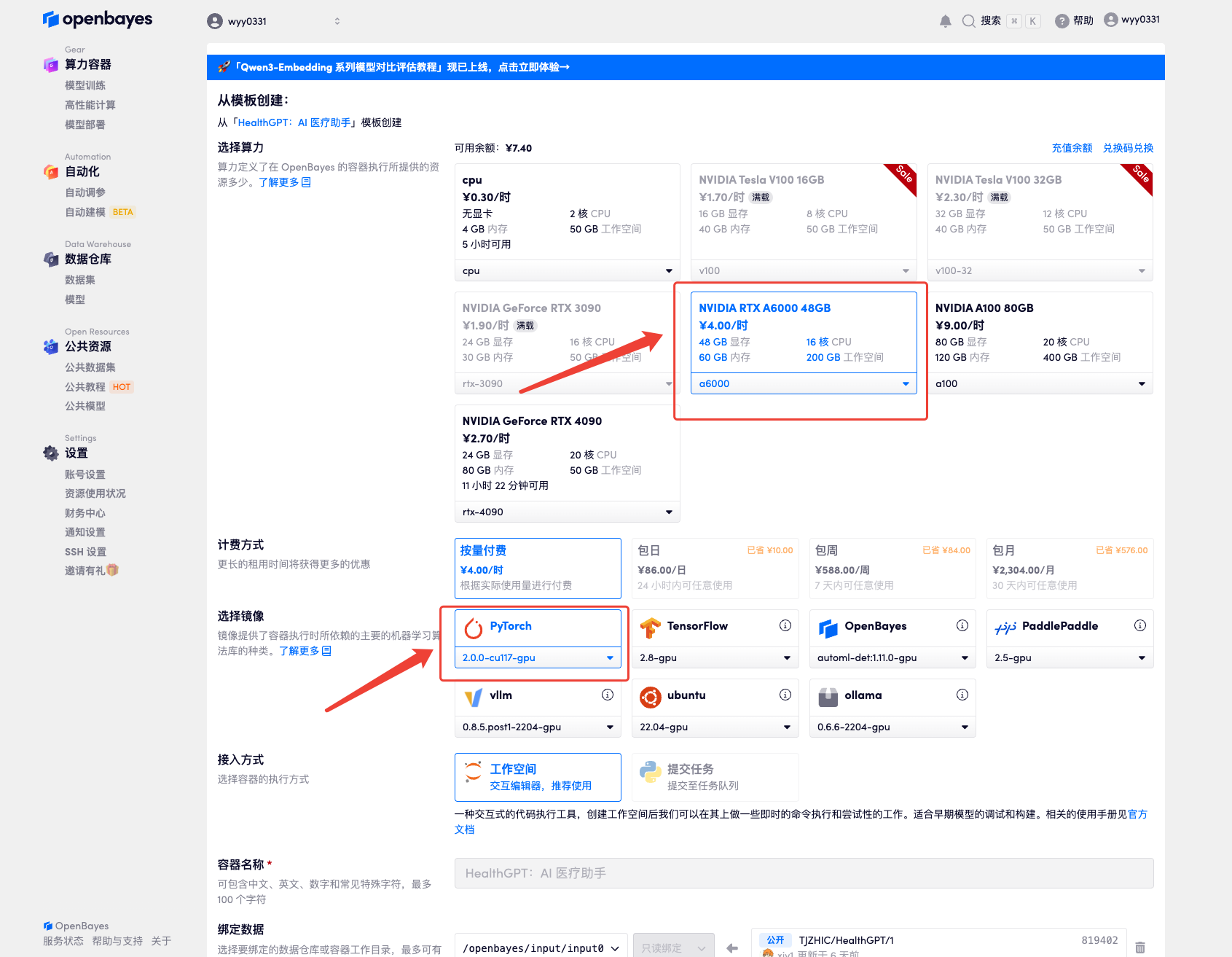
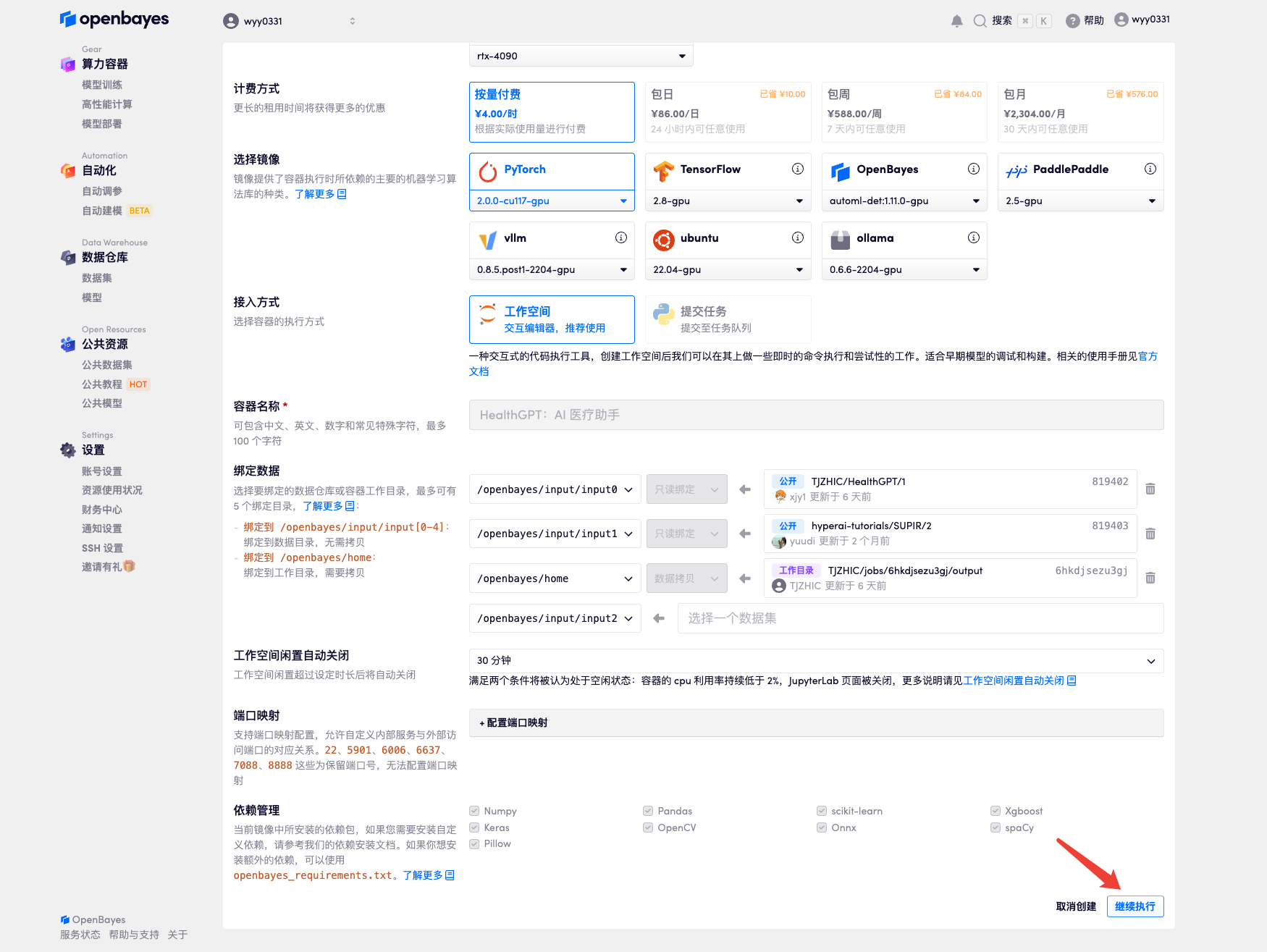
4. انتظر حتى يتم تخصيص الموارد. تستغرق عملية الاستنساخ الأولى حوالي دقيقتين. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق سهم الانتقال بجوار "عنوان API" للانتقال إلى صفحة العرض التوضيحي. نظرًا لأن النموذج كبير الحجم، يستغرق عرض واجهة WebUI حوالي 3 دقائق، وإلا فسيتم عرض "البوابة سيئة". يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.
عرض التأثير
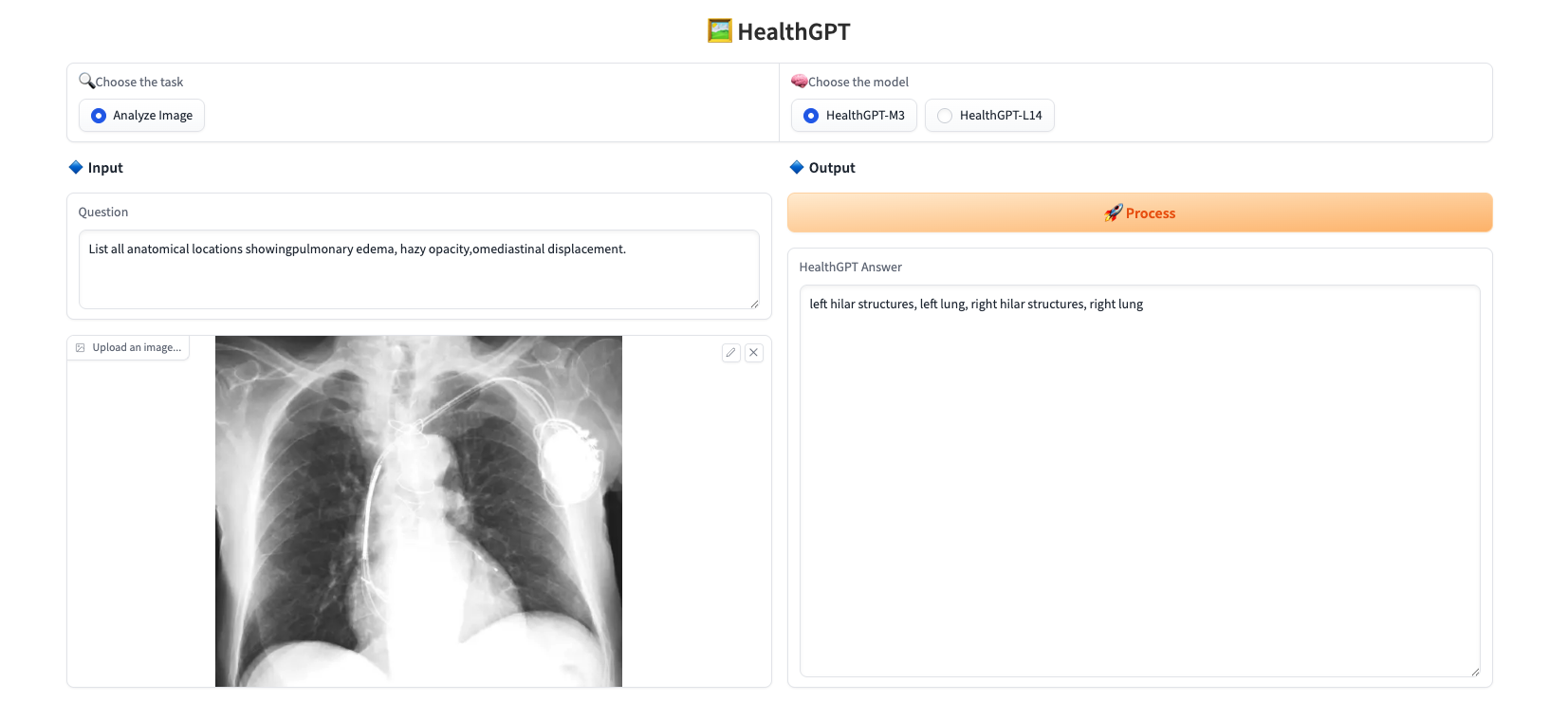
حمّل صورة، أدخل السؤال الذي تريد طرحه في "السؤال"، ثم اختر النموذج من "اختيار النموذج"، وانقر على "معالجة" للإجابة عليه فورًا. يوفر هذا المشروع نموذجين:
* HealthGPT-M3: إصدار أصغر حجمًا تم تحسينه للسرعة وتقليل استخدام الذاكرة.
* HealthGPT-L14: إصدار أكبر مصمم لتحقيق أداء أعلى ومهام أكثر تعقيدًا.
يظهر مثال الاستجابة أدناه:
ما سبق هو البرنامج التعليمي المُوصى به من قِبل HyperAI. ندعو القراء المهتمين لتجربته ⬇️
رابط البرنامج التعليمي:








