Command Palette
Search for a command to run...
تم اختيار فريق معهد هاربين للتكنولوجيا لـ CVPR 2025، واقترح إطار عمل تعليمي متعدد الحالات للتقطير الهرمي HDML لمعالجة صور علم الأمراض ذات الشريحة الكاملة بسرعة.

تحتوي الصور المرضية على معلومات ظاهرية غنية، ويعتبر التشخيص المرضي المبني على الصور المرضية على نطاق واسع "المعيار الذهبي" لتشخيص السرطان. ومن بينها صورة الشريحة الكاملة (WSI)، وهي صورة مرضية رقمية عالية الدقة تستخدم تقنية المسح الرقمي للشريحة الكاملة لتحويل شرائح الأنسجة المرضية إلى صور رقمية تصل إلى مليار بكسل. تتميز بدقة عالية وشاشة بانورامية وحجم بيانات كبير. إنها الطريقة السائدة في التشخيص الطبي والبحث الطبي الحالي.
يعد التعلم متعدد الحالات (MIL) أحد الطرق الرئيسية لتحليل WSI وقد حقق أداءً جيدًا في مهام مثل اكتشاف الورم وتحديد كمية البيئة المحيطة بالأنسجة والتنبؤ بالبقاء على قيد الحياة. ومع ذلك، بما أن WSI تحتوي على كمية هائلة من المعلومات، فإن التفكير باستخدام MIL يواجه تحدي التكلفة العالية. المشكلة الأولى هي مشكلة معالجة البيانات مسبقًا. إن عملية اقتصاص WSI واستخراج الميزات تستغرق وقتًا طويلاً. المشكلة الثانية هي مشكلة التصحيح الزائد. عادةً ما تحتوي WSI على تصحيحات زائدة عن الحاجة، والتي تساهم بشكل أقل في تصنيف مستوى الحقيبة. إن إزالة الأمثلة غير ذات الصلة من خلال درجات الاهتمام هي أبسط طريقة لحل المشكلة المذكورة أعلاه. ومع ذلك، تحتاج خوارزمية MIL الحالية إلى استخراج ميزات جميع الكتل المقطوعة قبل حساب درجات الاهتمام، وهو ما يخلق بلا شك مشكلة "البيضة والدجاجة".
وبناءً على التحليل أعلاه، قام البروفيسور جيانغ جونجون، والأستاذ المساعد جيانغ كوي من معهد هاربين للتكنولوجيا في الصين، والأستاذ تشانغ يونغ بينغ من معهد هاربين للتكنولوجيا (شنتشن)، وآخرون بإظهار حل مبتكر يمكنه تقليل وقت التفكير. واقترح الفريق إطار عمل للتعلم متعدد الحالات للتقطير الهرمي (HDMIL)، والذي يهدف إلى التعرف بسرعة على البقع غير ذات الصلة، وبالتالي تحقيق تصنيف سريع ودقيق. وفقًا للنتائج التجريبية، وبالمقارنة مع الطرق المتقدمة السابقة، يقلل HDMIL وقت الاستدلال بمقدار 28.6% على ثلاث مجموعات بيانات عامة.
وقد نُشرت النتائج ذات الصلة تحت عنوان "التصنيف السريع والدقيق للصور المرضية بالجيجابكسل باستخدام التعلم متعدد الحالات بالتقطير الهرمي" وتم اختيارها لـ CVPR 2025.
أبرز الأبحاث:
* تعمل الطريقة المقترحة على تسريع عملية التفكير مع تحسين أداء التصنيف أيضًا، وتحقيق التوازن بين السرعة والأداء الذي لا تستطيع الطرق التقليدية تحقيقه، كما توفر الإلهام للأبحاث المستقبلية حول التصنيف متعدد الحالات
*أظهرت هذه الطريقة لأول مرة تصنيف كولموغوروف-أرنولد القائم على كثيرات حدود تشيبيشيف وطبقته على علم الأمراض الرقمي، مما أدى إلى تحسين أداء التصنيف بشكل كبير
* تم التحقق من الطريقة المقترحة من خلال عدد كبير من التجارب وحققت نتائج تحقق موثوقة وفعالة على 3 مجموعات بيانات عامة

عنوان الورقة:
https://arxiv.org/abs/2502.21130
مجموعة البيانات: ثلاث مجموعات بيانات عامة رئيسية تؤكد الفعالية
ولضمان فعالية التجربة، قام الباحثون بتقييم فعالية الطريقة المقترحة على ثلاث مجموعات بيانات عامة:
* يتم استخدام مجموعة بيانات Camelyon16 للكشف عن نقائل العقدة الليمفاوية لسرطان الثدي، حيث يتم تقسيم نسبة مجموعة التدريب ومجموعة التحقق وفقًا لمجموعة التدريب الرسمية 9:1، ويتم استخدام مجموعة الاختبار الرسمية للاختبار عبر جميع الطيات
*تم استخدام مجموعة بيانات TCGA-NSCLC لتصنيف سرطان الرئة. تم تقسيم مجموعة البيانات إلى مجموعة التدريب ومجموعة التحقق ومجموعة الاختبار بنسبة 8:1:1.
*باستخدام مجموعة بيانات TCGA-BRCA لتصنيف النوع الفرعي لسرطان الثدي، فإن نسبة مجموعة التدريب ومجموعة التحقق ومجموعة الاختبار هي أيضًا 8:1:1
ومن الجدير بالذكر أن جميع WSIs تمت معالجتها مسبقًا باستخدام الأدوات التي طورتها CLAM، واتبعت التجارب التحقق المتبادل من صحة مونت كارلو بعشرة أضعاف.
هندسة النموذج: تتضمن الهندسة ذات المرحلتين التدريب والاستدلال، وتقدم بشكل مبتكر مصنف كولموغوروف-أرنولد
يتضمن إطار عمل HDMIL الذي اقترحه المعهد جزأين: التدريب والتفكير. في هذا الإطار، هناك عنصران رئيسيان: الأول هو شبكة الحالات المتعددة الديناميكية (DMIN)، والتي تم تصميمها لتصنيف WSI عالية الدقة وتحديد الحالات التي لا تتعلق بتصنيف مستوى الحقيبة؛ الشبكة الأخرى هي شبكة الفحص المسبق للمثيلات خفيفة الوزن (LIPN)، وهي شبكة مصممة خصيصًا لـ WSI منخفضة الدقة.
قبل التدريب، قام الباحثون أولاً بمعالجة بيانات الإدخال وفقًا للإجراء القياسي لـ WSI المرضي. تتكون مجموعة البيانات من أهرامات S WSI مع تسميات الشريحة، كل Xᵢ يحتوي على زوج من WSIs عالية الدقة (20x) ومنخفضة الدقة (1.25x)، والتي يشار إليها بـ Xᵢ،ₕᵣ وXᵢ،ₗᵣ، على التوالي.
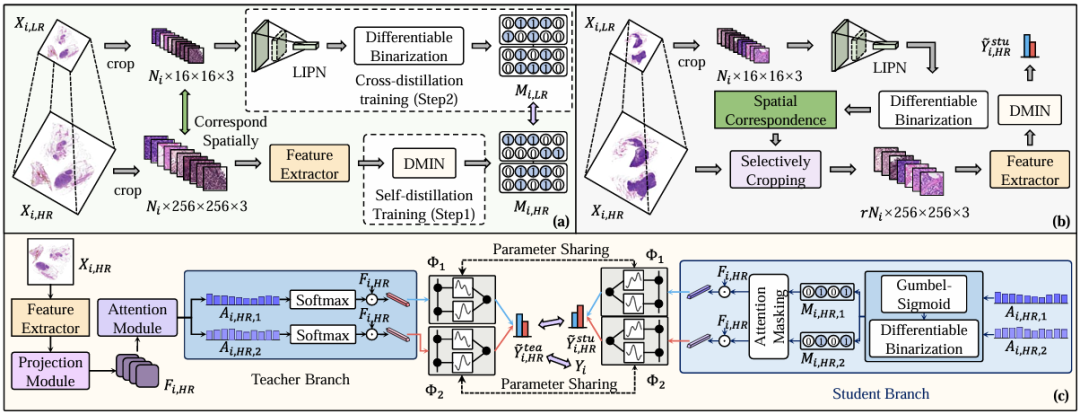
وعلى وجه التحديد، يوضح الشكل (أ) مرحلة التدريب، كما هو موضح في الشكل التالي. اعتمد الباحثون في البداية على استراتيجية تدريب التقطير الذاتي لتدريب DMIN باستخدام WSI عالي الدقة (Xᵢ،ₕᵣ)، مما مكنه من إجراء تصنيف على مستوى الكيس والإشارة إلى المناطق غير ذات الصلة. على الرغم من أن DMIN نجح في تحديد المناطق غير ذات الصلة في WSI، إلا أنه لم يحسن سرعة الاستدلال. نظرًا لأن DIMN يحتاج إلى استخدام ميزات جميع التصحيحات التي تم إنشاؤها بواسطة مستخرج الميزات لتحديد الحالات التي يجب التخلص منها، فإن استخراج الميزات لكل تصحيح هو في الواقع المفتاح لكسر عنق الزجاجة لسرعة استنتاج WSI.
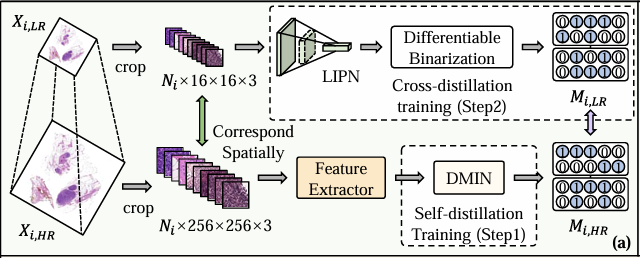
ولذلك، قام الباحثون بعد ذلك بتجميد DMIN واستخدموا القناع الناتج لاستخراج LIPN. كما ذكر أعلاه، LIPN عبارة عن شبكة فحص مسبق للمثيلات خفيفة الوزن مصممة خصيصًا لـ WSI ذات الدقة المنخفضة. يتم تدريبه عن طريق التقطير المتبادل باستخدام WSI منخفض الدقة (Xᵢ،ₗᵣ) ويمكنه التعرف بسرعة على المناطق غير ذات الصلة في WSI منخفض الدقة، وبالتالي الإشارة بشكل غير مباشر إلى البقع غير ذات الصلة في WSI عالي الدقة.
من حيث التنفيذ المحدد، اعتمد الباحثون ResNet-50 المستخدم على نطاق واسع كمستخرج للميزات، وهو نموذج تم تدريبه مسبقًا على ImageNet، واستخدموا نسخة خفيفة الوزن من MobileNetV4 لشبكة الفحص المسبق LIPN. ومن خلال الخطوات المذكورة أعلاه، تمكن الباحثون من التوصل إلى حكم الأهمية الثنائية (أهمية أو عدم أهمية) لكل منطقة بتكلفة حسابية منخفضة للغاية.
يوضح الشكل ج تدريب التقطير الذاتي لـ DMIN على WSI عالي الدقة (Xᵢ،ₕᵣ)، كما هو موضح أدناه. يمكننا أن نرى أن DMIN يتكون من خمس وحدات، بما في ذلك وحدة الإسقاط، ووحدة الاهتمام، وفرع المعلم، وفرع الطالب، ومصنفات CKA.

على وجه التحديد، يتم إدخال جميع الرقع المستخرجة من WSI عالي الدقة (Xᵢ،ₕᵣ) أولاً في مستخرج الميزات المدرب مسبقًا لتوليد مجموعة من ميزات مستوى المثال Iᵢ،ₕᵣ، والتي يتم إدخالها بعد ذلك في وحدة الإسقاط لتقليل الأبعاد للحصول على مجموعة ميزات جديدة Fᵢ،ₕᵣ، والتي يتم إدخالها بعد ذلك في وحدة الاهتمام لحساب درجة الاهتمام غير الطبيعية.
في فرع المعلم، يتم ترجيح Fᵢ,ₕᵣ المختزل خطيًا باستخدام مصفوفة الاهتمام لكل فئة لإنتاج تمثيل على مستوى الحقيبة للتصنيف النهائي. يتم استخدام مجموعة فرعية فقط من الأمثلة ذات درجات الاهتمام الكبيرة في فرع الطالب لحساب تمثيل مستوى الحقيبة، ويفرض الباحثون أيضًا قيودًا لضمان أن يكون تمثيل مستوى الحقيبة متسقًا قدر الإمكان مع التمثيل الذي تم الحصول عليه في فرع المعلم باستخدام جميع الحالات. من خلال هذه الطريقة، يتم تنفيذ وحدة الاهتمام لإيلاء المزيد من الاهتمام للحالات الأكثر أهمية لتصنيف مستوى الحقيبة وتصفية الحالات غير ذات الصلة. في الوقت نفسه، تتبنى عملية التحسين أيضًا خدعة Gumbel لاستخدام الحالات بشكل انتقائي مع درجات الاهتمام الأعلى للتدريب الشامل لتجنب حدوث مشكلات غير قابلة للتفاضل.
وأخيرًا، لتعزيز قدرات مصنف MIL، اقترح الباحثون استخدام شبكة كولموغوروف-أرنولد لتعلم وظائف التنشيط غير الخطية بدلاً من استخدام وظائف التنشيط الثابتة في المصنف. ومن خلال تصميم دالة خسارة هجينة، نجح الباحثون في تحقيق ثلاثة أهداف تدريبية لـ DMIN. الأول هو أن فرع المعلم يمكنه تصنيف Xᵢ،ₕᵣ بشكل صحيح؛ الثاني هو أن نتائج التصنيف لاستخدام بعض الحالات في فرع الطالب يمكن أن تكون متوافقة مع نتائج التصنيف لاستخدام جميع الحالات في فرع المعلم؛ والثالث هو أن تكون نسبة الحالات المختارة قابلة للتحكم.
يوضح الشكل (ب) مرحلة التفكير، كما هو موضح أدناه. يمكن تقسيم العملية المحددة إلى ثلاث خطوات: الخطوة الأولى هي اقتصاص جميع الرقع في WSI منخفضة الدقة (Xᵢ،ₗᵣ)، بإجمالي Nᵢ؛ الخطوة الثانية هي إدخال هذه الرقع في LIPN لتحديد المناطق ذات الصلة بالتصنيف وتوليد Mᵢ,ₗᵣ؛ الخطوة الثالثة هي اقتصاص الرقع المقابلة بشكل انتقائي في Xᵢ،ₕᵣ بناءً على Mᵢ،ₗᵣ، ثم إدخال الرقع المتبقية في مستخرج الميزات وDMIN، وأخيرًا حسابها بشكل منفصل من خلال فروع الطلاب عبر الفئات لتوليد نتائج التصنيف النهائية.
نتائج البحث: لا يزال HDMIL "المبسط" يتفوق على الطرق المتقدمة الموجودة
استنادًا إلى مجموعات البيانات الثلاث Camelyon16 وTCGA-NSCLC وTCGA-BRCA، قارن الباحثون أداء تصنيف HDMIL مع 11 طريقة MIL، بما في ذلك Max-pooling وMean-Pooling وABMIL وCLAMSB وCLAMMB وDSMIL وTransMIL وDTFDAFS وDTFDMAS وS4MIL وMambaMIL.
ومن الجدير بالذكر أن الباحثين قاموا باختبار تكوينات مختلفة من HDMIL، وهي HDMIL† وHDMIL. والأمر السابق يعني أن DMIN فقط هو المستخدم للاستدلال دون الحاجة إلى فحص مسبق من خلال LIPN. وتظهر النتائج المحددة في الشكل أدناه:
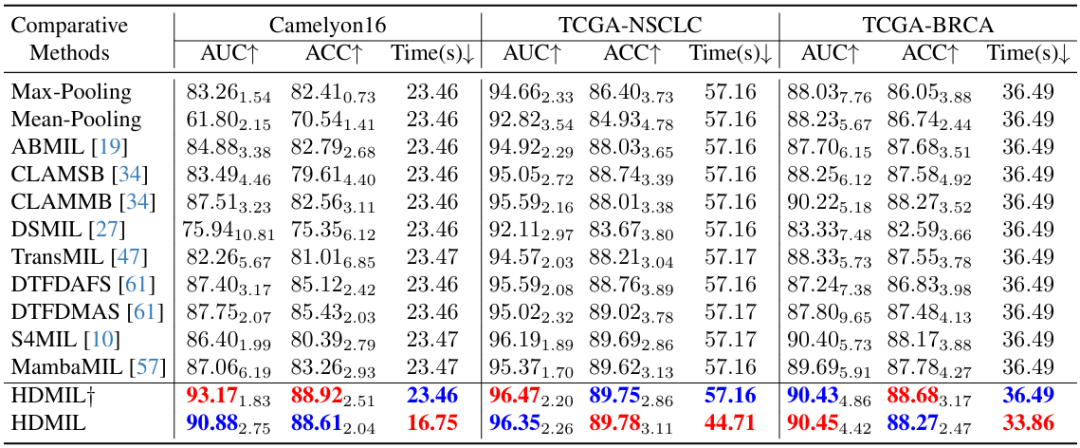
يمكن ملاحظة أن كلاً من HDMIL† وHDMIL لديهما نتائج اختبار أفضل باستمرار على مجموعات البيانات الثلاث مقارنة بالطرق الحالية. على سبيل المثال، في مجموعة بيانات Camelyon16، حقق HDMIL AUC يبلغ 90.88% ودقة تبلغ 88.61%، وهي أعلى بمقدار 3.13% و3.18% من أفضل طريقة سابقة على التوالي.
وفي الوقت نفسه، عندما تكون مجموعة البيانات كبيرة بما يكفي، يعمل HDML على تحسين السرعة دون التأثير على أداء التصنيف. على سبيل المثال، يحتوي كل من TCGA-NSCLC وTCGA-BRCA على حوالي 1000 WSI، ولكن الفجوة في أداء الاختبار بين HDML† وHDML ليست كبيرة، مما يثبت أن HDML قد حقق توازنًا ممتازًا بين سرعة الاستدلال وأداء التصنيف.
بالإضافة إلى ذلك، فإن HDMIL† على قدم المساواة مع الطرق الأخرى الموجودة في وقت المعالجة، في حين يتفوق HDMIL بشكل كبير على جميع الطرق لأنه يحتاج إلى معالجة نفس عدد التصحيحات عالية الدقة مثل الطرق الأخرى. يقلل HDMIL من الوقت المستغرق في معالجة البيانات من خلال LIPN، وبالتالي يقلل بشكل كبير من الوقت المستغرق في الاستدلال مقارنة بالطرق الأخرى على مجموعات البيانات الثلاث، مما يحقق زيادات في السرعة بمقدار 28.6%، و21.8%، و7.2% على التوالي.
ومن أجل تحليل تأثير كل مكون، أجرى الباحثون تجربة استئصال لتوضيح تأثير كل وحدة في HDML على نتائج التصنيف بشكل أكبر، كما هو موضح في الشكل أدناه. تظهر نتائج البحث أن استبدال المصنف التقليدي القائم على الطبقة الخطية بالمصنف المقترح CKA ودمج التقطير الذاتي في تدريب DMIN يحسن بشكل كبير من أداء التصنيف.

بشكل عام فإن اقتراح HDMIL هو بلا شك فكرة ومحاولة جديدة. وقد تم إثبات جدوى فكرتها من خلال عدد كبير من التجارب. إنه يوفر طريقة جديدة لتحليل الصور المرضية، وخاصة WSI، باستخدام طريقة MIL، ويسرع التطوير القوي لعلم الأمراض الرقمي.
علم الأمراض الرقمي يزدهر مع الذكاء الاصطناعي
في السنوات الأخيرة، أدى التطور القوي لعلم الأمراض الرقمي إلى جولة جديدة من التقدم في الطب وعلم الأحياء، وخاصة لعب دور مهم في مكافحة السرطان، أحد أعظم أعداء البشرية. ومن الجدير بالذكر أن مقترح HDMIL ليس المحاولة الأولى لفريق معهد هاربين للتكنولوجيا في هذا المجال.
في العام الماضي، تضمن مؤتمر CVPR 2024 دراسة بعنوان "التلوين المناعي الكيميائي الافتراضي للصور النسيجية بمساعدة التعلم الخاضع للإشراف الضعيف". ذكرت المقالة طريقة تعلم ضعيفة الإشراف تسمى confusion-GAN لصبغ المناعة الكيميائية الافتراضية (IHC)، والتي يمكنها تحويل صور H&E إلى صور IHC، مما يحل التكلفة الباهظة والمكلفة للطرق التقليدية في صبغ IHC.

عنوان الورقة: https://openaccess.thecvf.com/content/CVPR2024/papers/Li_Virtual_Immunohistochemistry_Staining_for_Histological_Images_Assisted_by_Weakly-supervised_Learning_CVPR_2024_paper.pdf
بالإضافة إلى نفس المؤلفين الذين قاموا بالبحث المذكور أعلاه، شارك في تأليف هذه المقالة أيضًا البروفيسور جيانغ جونجون والبروفيسور تشانغ يونغ بينغ، مما يؤكد بشكل أكبر الزراعة العميقة والتراكم في هذا المجال لدى معهد هاربين للتكنولوجيا.
وبطبيعة الحال، باعتبارهما المؤلفين المراسلين للمقالة، فإن البروفيسور جيانغ جونجون والبروفيسور تشانغ يونغ بينغ يستحقان أيضًا ذكرًا خاصًا. يشغل البروفيسور جيانغ جونجون حاليًا منصب أستاذ دائم ومشرف على الدكتوراه في كلية علوم الكمبيوتر في معهد هاربين للتكنولوجيا، ونائب عميد كلية الذكاء الاصطناعي، ونائب مدير مركز أبحاث الواجهة الذكية والتفاعل بين الإنسان والحاسوب. تم اختياره لبرنامج المواهب الوطنية للشباب وهو أيضًا القائد الأكاديمي لـ "استوديو العلماء الشباب" في معهد هاربين للتكنولوجيا. تتضمن اتجاهات بحثه معالجة الصور، ورؤية الكمبيوتر، والتعلم العميق (يركز البحث على النماذج الكبيرة ومعالجة الصور، والأنظمة غير المأهولة المستقلة متعددة الوسائط، والذكاء الاصطناعي التوليدي، وما إلى ذلك) وغيرها من المجالات.
يشغل البروفيسور تشانغ يونغ بينغ حاليًا منصب أستاذ ومشرف دكتوراه في كلية علوم الكمبيوتر في معهد هاربين للتكنولوجيا. تشمل مجالات بحثه الرئيسية الرؤية الحاسوبية، ومعالجة الصور الطبية الحيوية، والتصوير الحاسوبي. بالإضافة إلى ذلك، يشغل البروفيسور تشانغ يونغ بينغ أيضًا مناصب متعددة. وهو عضو في العديد من الجمعيات المحلية والأجنبية المعروفة، بما في ذلك جمعية الكمبيوتر الصينية، وجمعية الذكاء الاصطناعي الصينية، ومعهد مهندسي الكهرباء والإلكترونيات، وجمعية مهندسي البرمجيات في الصين، وجمعية مهندسي البرمجيات في الولايات المتحدة الأمريكية، وجمعية مهندسي البرمجيات في الولايات المتحدة الأمريكية، وغيرها. وقد نشر أكثر من 100 ورقة بحثية في مؤتمرات الذكاء الاصطناعي الدولية المرموقة، وحصل على أكثر من 50 براءة اختراع. حاليا، يركز البحث الرئيسي للأستاذ الدكتور تشانغ يونغ بينغ على استكشاف تطبيق الذكاء الاصطناعي والرؤية الحاسوبية في مجالات الطب الحيوي والصحة الطبية.
بالإضافة إلى معهد هاربين للتكنولوجيا، يتزايد عدد الجامعات والمختبرات التي تولي اهتمامًا لمجال علم الأمراض الرقمي وتساهم بجهودها الخاصة. على سبيل المثال، نشر فريق من جامعة آيندهوفن للتكنولوجيا في هولندا دراسة بعنوان "إطار عمل التعلم المتعدد الحالات المدرك مكانيًا لعلم الأمراض الرقمي"، والذي اقترح نموذجًا يسمى Global ABMIL (GABMIL). هذا النموذج هو نسخة محسنة من نموذج ABMIL التقليدي. يمكنه دمج المعلومات المكانية في متجه التضمين من خلال وحدة خلط المعلومات المكانية، ثم استخدام شبكة ABMIL للتنبؤ بعلامة الشريحة، وتجنب طريقة MIL التقليدية التي غالبًا ما تتجاهل عاملًا رئيسيًا في التشخيص المرضي - معلومات التفاعل المكاني بين كتل الصور.
عنوان الورقة: https://arxiv.org/abs/2504.17379
باختصار، إن دمج الذكاء الاصطناعي والطب التقليدي أمر لا رجعة فيه، ويمكن لأي شخص الاستفادة منه. لا يمكن إنكار أن هؤلاء "المستكشفين" الملتزمين بالريادة في مجال العلوم هم الذين يمنحوننا الفرصة للاستمتاع بتطبيقات التكامل المتبادل بين الذكاء الاصطناعي والطب. وبطبيعة الحال، مع الزراعة العميقة طويلة الأمد، هناك سبب للاعتقاد بأن فريق معهد هاربين للتكنولوجيا سيواصل ترسيخ جذوره هنا، وبالتالي تسريع تطوير المجال بأكمله.








