Command Palette
Search for a command to run...
أصدر فريق جامعة شنغهاي جياوتونغ منصة تصميم هندسة البروتين الشاملة VenusFactory، والتي تغطي أكثر من 40 نموذجًا رئيسيًا ومجموعة بيانات.

مع التطور السريع في الحوسبة بالذكاء الاصطناعي والأساليب المعتمدة على البيانات، يتجه هندسة البروتين نحو مرحلة التصميم بمساعدة الذكاء الاصطناعي. يحتاج الباحثون إلى مجموعات بيانات بروتينية شاملة وعالية الجودة، ونماذج ذكاء اصطناعي بروتينية أكثر قوة وتأثيراً، ومنصات تحليل أكثر كفاءة وموحدة أكثر من أي وقت مضى، وذلك من أجل استخراج المعلومات القيمة بدقة من البيانات البيولوجية الضخمة، وتسريع تصميم وتحسين البروتينات الجديدة، وتعزيز الاختراقات المبتكرة في الطب الحيوي والبيولوجيا الاصطناعية وغيرها من المجالات.
في هذا السياق، يرغب عدد متزايد من ممارسي علوم الحياة في فهم الذكاء الاصطناعي واستخدام تكنولوجيا الذكاء الاصطناعي للمساعدة في تصميم هندسة البروتين. ومع ذلك، فإن كل من حل المصدر المفتوح الذي أعاد ديفيد بيكر تصميمه، وسلسلة ESM من النماذج الكبيرة من Meta، يواجهان العديد من الصعوبات في الاستخدام، مثل المنطق المعقد لإطار عمل الحوسبة الذكاء الاصطناعي، والكمية الكبيرة من التعليمات البرمجية، والحاجة إلى أساس قوي لبرمجة الكمبيوتر. وبعبارة أخرى، لا يزال الباحثون البيولوجيون وحتى ممارسي الكمبيوتر غير ذوي الخبرة يواجهون عتبة عالية إلى حد ما للاستخدام. وفي هذا الصدد، أصبحت التطبيقات منخفضة التكلفة وسهلة الاستخدام تدريجيًا هي الاتجاه السائد في استخدام أدوات المصدر المفتوح الحديثة. يمكن أن تساعد هذه التقنيات الباحثين على التخلص من تكوين النموذج المعقد وتنفيذ التعليمات البرمجية، مما يسمح لعلماء الكمبيوتر وعلماء الأحياء باستدعاء نماذج التعلم العميق أو تدريبها بطريقة أكثر ملاءمة والتركيز على البحث العلمي نفسه.
لتعزيز تطبيق وتطوير الذكاء الاصطناعي في مجال هندسة البروتينات، قامت مجموعة الأبحاث التابعة للبروفيسور هونغ ليانغ في جامعة شنغهاي جياو تونغ في الصين بتطوير VenusFactory، وهي منصة مفتوحة متكاملة مصممة خصيصًا لهندسة البروتينات. يمكن للباحثين تنفيذ استرجاع البيانات المملة، وتدريب النماذج، وتقييم المهام، ونشر النماذج والوظائف الأخرى بسهولة من خلال التفاعل مع الواجهة أو سطر الأوامر. من خلال التصميم الخالي من التعليمات البرمجية والمبني على العملية، تعمل المنصة على تبسيط عمليات هندسة الذكاء الاصطناعي المعقدة في الماضي وتحويلها إلى عمليات خفيفة الوزن في متناول اليد. يمكن للباحثين بدء خدمات الويب محليًا واستدعاء أكثر من 40 نموذجًا متطورًا للتعلم العميق للبروتين بسهولة دون كتابة أكواد معقدة، وبالتالي حماية خصوصية البيانات الخاصة، وخفض عتبة البحث العلمي الذكي بشكل كبير، وتسريع التطبيق المتعمق للذكاء الاصطناعي في مجال علوم الحياة.
الكود والبيانات مفتوحة المصدر على: https://github.com/ai4protein/VenusFactory
تم حاليًا إطلاق "منصة تصميم هندسة البروتين VenusFactory" في قسم البرامج التعليمية بموقع HyperAI. تم إرفاق البرنامج التعليمي التفصيلي للاستخدام في نهاية هذه المقالة. يمكن للقراء المهتمين تجربة المنصة من خلال الرابط أدناه:
VenusFactory: منصة موحدة تكسر الحواجز أمام تطبيقات الذكاء الاصطناعي للبروتين
بيانات البروتين متفرقة للغاية. يتمكن VenusFactory من الوصول مباشرة إلى مصدر البيانات البيولوجية تعتمد أبحاث بروتين الذكاء الاصطناعي بشكل كبير على البيانات البيولوجية واسعة النطاق، ويتم توزيع البيانات الموضحة في قواعد بيانات عامة رئيسية متعددة. غالبًا ما يحتاج العلماء إلى التبديل بين قواعد بيانات متعددة، وتنزيل البيانات يدويًا، وكتابة نصوص برمجية لتحويل التنسيق، مما يؤدي إلى إهدار الوقت والطاقة في أعمال بحثية غير عملية. يتصل VenusFactory مباشرةً بقواعد البيانات العامة الرئيسية، مثل RCSB PDB وUniProt وInterPro وغيرها. يُحسّن التنزيل عالي السرعة متعدد الخيوط كفاءة استرجاع البيانات بشكل كبير:
- الوصول من مكان واحد إلى تسلسل البروتين والبنية ثلاثية الأبعاد والتعليق الوظيفي، ودمج المعلومات البيولوجية بشكل كامل.
- يتجنب تنسيق الإخراج الموحد مشكلات توافق البيانات ويسهل التدريب المباشر للذكاء الاصطناعي.
- تعمل آلية التنزيل متعددة الخيوط على تحسين سرعة الحصول على البيانات بشكل كبير، مما يسمح للعلماء بالتركيز على البحث نفسه.
إن نظام تقييم مهام الذكاء الاصطناعي البروتيني ليس موحدًا. يغطي VenusFactory خمس مهام أساسية. في الوقت الحاضر، يفتقر نظام تقييم نموذج الذكاء الاصطناعي للبروتين إلى بيانات مرجعية جاهزة، ولا تزال معظم الأبحاث تركز على تحسين المهام الفردية. عندما يختار الباحثون حلاً ما، فإنهم غالبًا ما يحتاجون إلى قضاء الكثير من الوقت الإضافي في المقارنات التجريبية. يدمج VenusFactory أكثر من 40 مجموعة بيانات متطورة لتقييم هندسة البروتين، والتي تغطي خمس مهام أساسية:
- التنبؤ بوظيفة البروتين:توقع العلامات الوظيفية للبروتينات لتسهيل اكتشاف إنزيمات وأهداف جديدة.
- التنبؤ بتوطين البروتين تحت الخلوي:التنبؤ بموقع البروتينات في الخلايا للمساعدة في تشخيص المرض.
- تقييم ذوبان البروتين:تحسين كفاءة التجربة الرطبة من خلال الحكم المسبق على الذوبان.
- تحليل آثار الطفرات البروتينية:استكشاف التأثير المحتمل لطفرة الجينات وتطوير الطب الدقيق.
- مهام التنبؤ الأخرى:مثل ربط أيونات المعادن، والتنبؤ بإشارة فرز البروتين، والتنبؤ بدرجة الحرارة المثالية، وما إلى ذلك.
وبمساعدة مجموعات البيانات المرجعية ونتائج التقييم هذه، يستطيع المستخدمون بسهولة مقارنة أداء النماذج المختلفة واختيار الحلول وتحسينها. في الوقت نفسه، يوفر VenusFactory أيضًا وظيفة تنزيل جميع مجموعات البيانات، حتى يتمكن المستخدمون من الحصول على تسلسل البروتين والبنية والعلامة والمعلومات الأخرى المقابلة بنقرة واحدة.
إن أدوات الحوسبة الخاصة بالذكاء الاصطناعي البروتيني الموجودة لديها حواجز عالية للاستخدام ويصعب على الباحثين الذين ليس لديهم خلفية في الحوسبة استخدامها غالبًا ما يتطلب استخدام نماذج الذكاء الاصطناعي للبروتين الحالية مهارات برمجة قوية ومعرفة التعلم العميق. بالنسبة لمعظم علماء الأحياء، لا يزال التدريب والضبط الدقيق وتطبيق نماذج الذكاء الاصطناعي مهمة ذات عتبة عالية. يدمج VenusFactory أكثر من 40 من نماذج لغة البروتين (PLMs) المتطورة في العالم، والتي تغطي حلول النماذج الكبيرة للذكاء الاصطناعي الشاملة، مثل سلسلة Venus (ProSST، Pro-Prime، PETA، وما إلى ذلك)، وسلسلة ESM (ESM2، ESM1b، وما إلى ذلك)، وسلسلة Ankh (Base، Large) وسلسلة ProtTrans (ProtBert، ProtT5)، وما إلى ذلك.
- نظام بيئي نموذجي مدرب مسبقًا:استدعاء PLM مفتوح المصدر مباشرةً دون الحاجة إلى التدريب من البداية، مما يوفر موارد الحوسبة.
- ضبط الأداء العالي:يدعم الأساليب المتطورة مثل LoRA وSES-Adapter لتكييف النموذج مع المهام البيولوجية المحددة.
- دعم تعدد المهام:سواء كان الأمر يتعلق بالتنبؤ بذوبان البروتين أو التنبؤ بخاصية الطفرة، يمكنك البدء بسهولة.
- وضع سطر الأوامر:مناسب لعلماء الكمبيوتر، حيث يمكنه تعديل المعلمات بمرونة وتحقيق تحسين عميق.
- واجهة ويب بدون أكواد:مناسب لعلماء الأحياء، حيث يمكنك تشغيل مهام الذكاء الاصطناعي بنقرات بسيطة، ولا يتطلب الأمر أي معرفة برمجية!
ولمعالجة هذه التحديات الأساسية، قامت VenusFactory ببناء منصة هندسة بروتينية متكاملة مدعومة بالذكاء الاصطناعي، توفر حلاً كاملاً من جمع البيانات وتقييم المهام إلى ضبط النموذج بدقة، مما يسمح لعلماء الأحياء وعلماء الحوسبة بتطوير أبحاثهم بكفاءة.
المصدر المفتوح وبناء المجتمع لتعزيز الابتكار العلمي
إن مستقبل البحث العلمي يكمن في المشاركة المفتوحة. يستخدم VenusFactory ترخيص Apache 2.0. جميع الأكواد ومجموعات البيانات وأوزان النماذج مفتوحة المصدر تمامًا. يمكن للمستخدمين تنزيل النتائج وتعديلها وتحسينها ومشاركتها بحرية مع الباحثين في جميع أنحاء العالم. يتم استضافة جميع البيانات والنماذج وأكواد الضبط الدقيق على GitHub وHugging Face، مما يضمن للعلماء في جميع أنحاء العالم الوصول بسهولة إلى التجارب وإعادة إنتاجها وبناء مشاريع أبحاث الذكاء الاصطناعي الخاصة بهم استنادًا إلى VenusFactory.
لمساعدة القراء على تجربة VenusFactory، أطلق موقع HyperAI برنامجًا تعليميًا للنشر بنقرة واحدة لـ "منصة تصميم هندسة البروتين VenusFactory". فيما يلي مقدمة مفصلة لاستخدامه↓
رابط البرنامج التعليمي: https://go.hyper.ai/ZqO3h
برنامج تعليمي لتصميم هندسة البروتين من منصة VenusFactory
تشغيل تجريبي
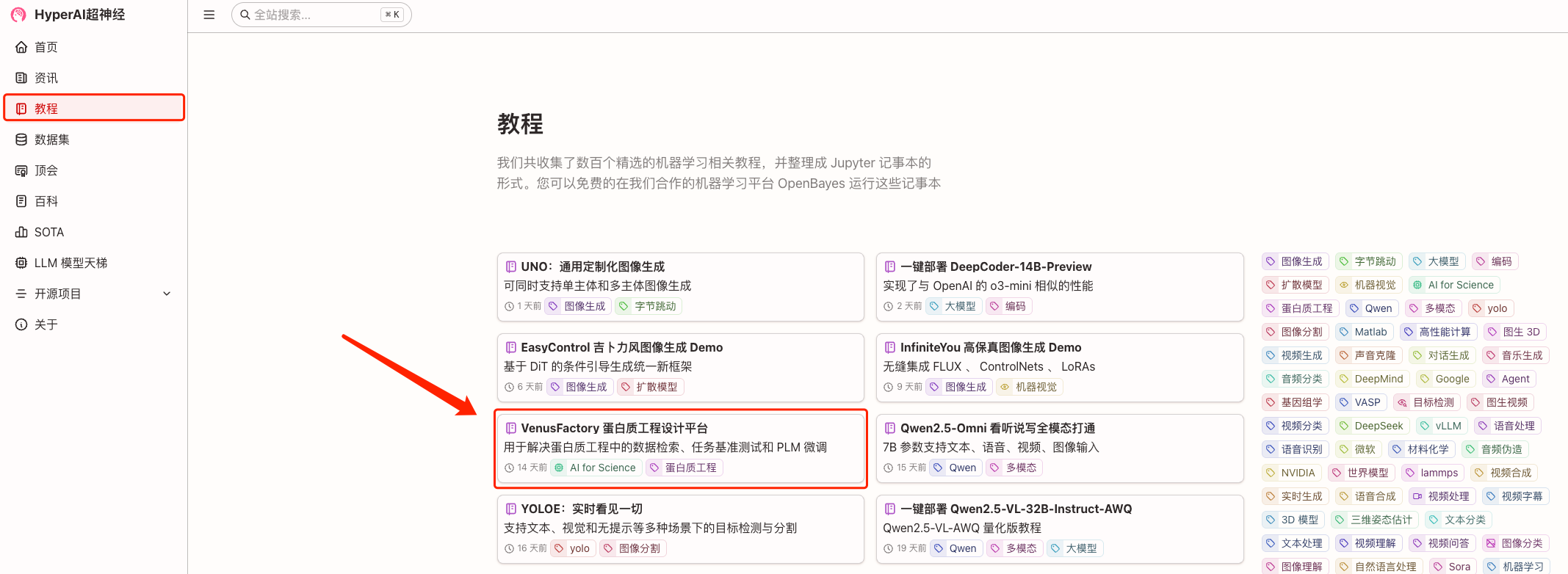
1. قم بتسجيل الدخول إلى hyper.ai، في صفحة البرنامج التعليمي، حدد VenusFactory Protein Engineering Design Platform، ثم انقر فوق تشغيل هذا البرنامج التعليمي عبر الإنترنت.
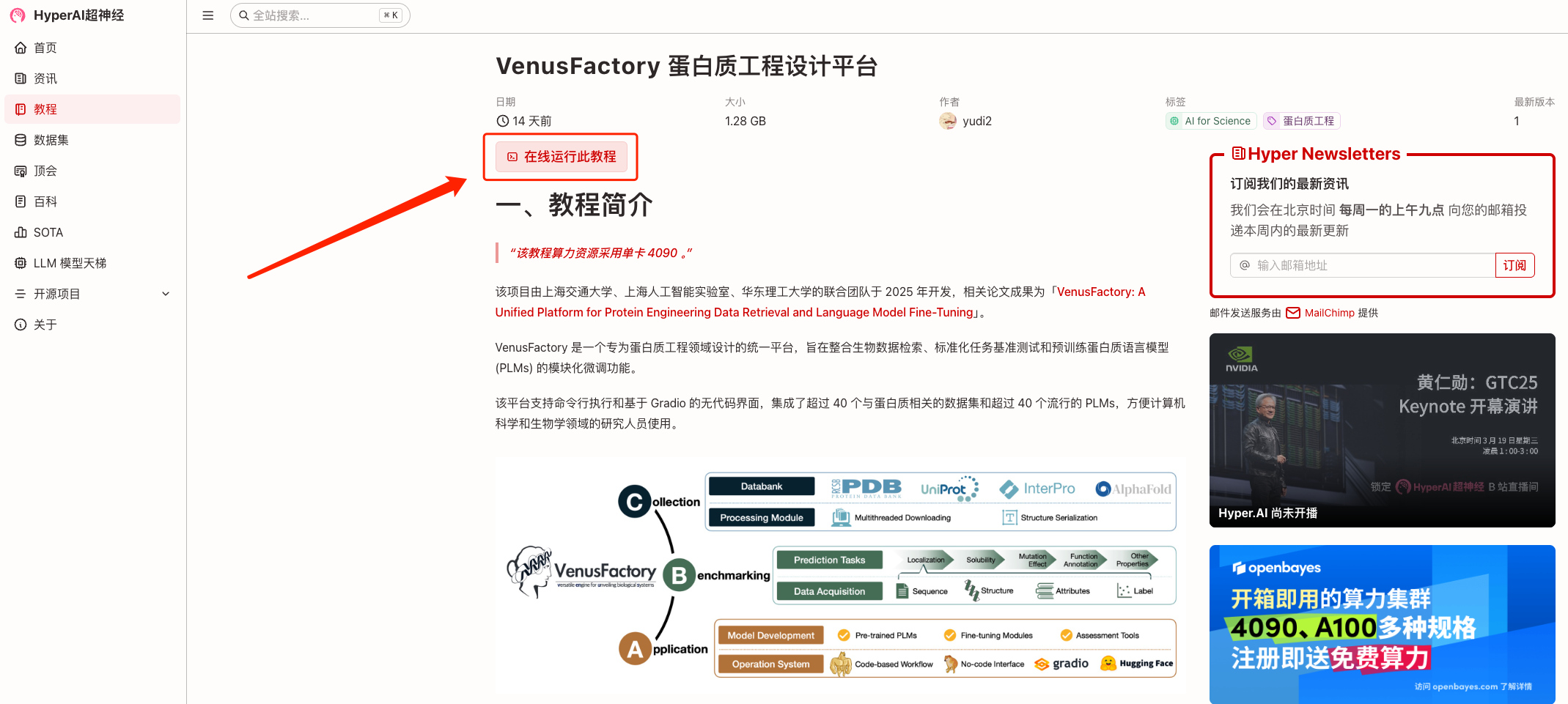
2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
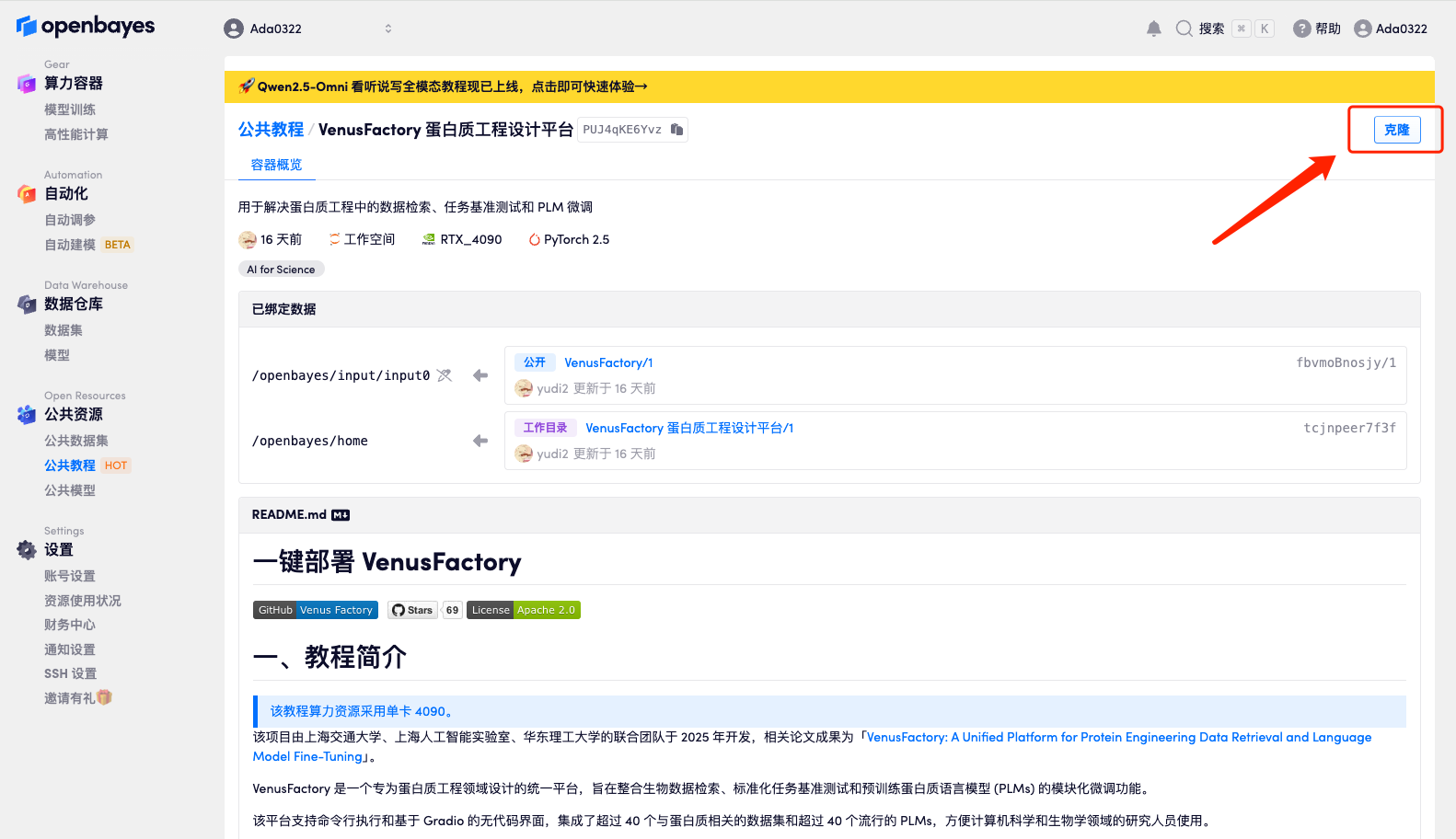
3. حدد صورة NVIDIA GeForce RTX 4090 وPyTorch، ثم انقر فوق متابعة. توفر منصة OpenBayes أربع طرق للدفع. يمكنك اختيار "الدفع حسب الاستخدام" أو "يوميًا/أسبوعيًا/شهريًا" وفقًا لاحتياجاتك. يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على 4 ساعات من RTX 4090 + 5 ساعات من وقت فراغ وحدة المعالجة المركزية!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=Ada0322_NR0n
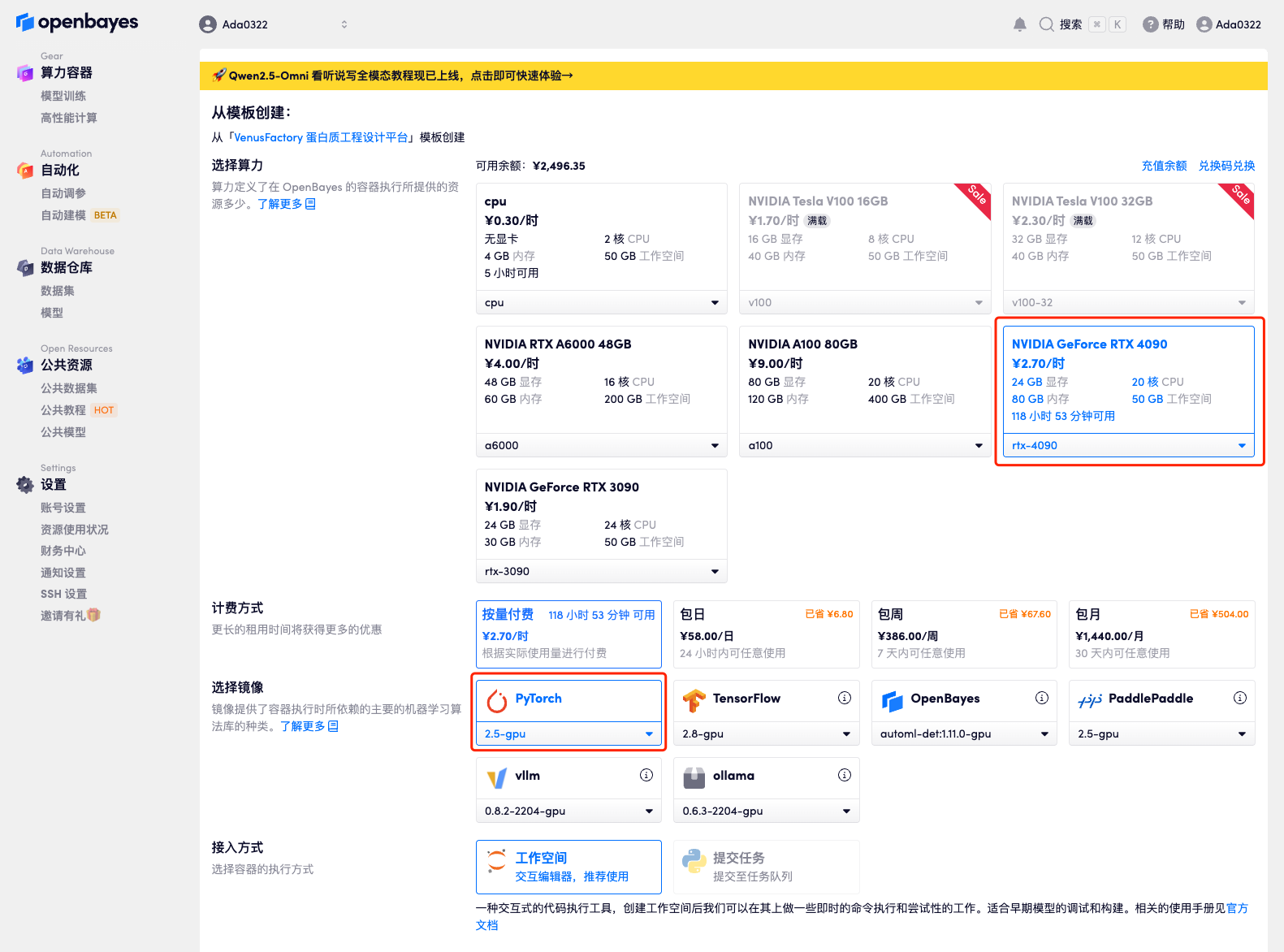
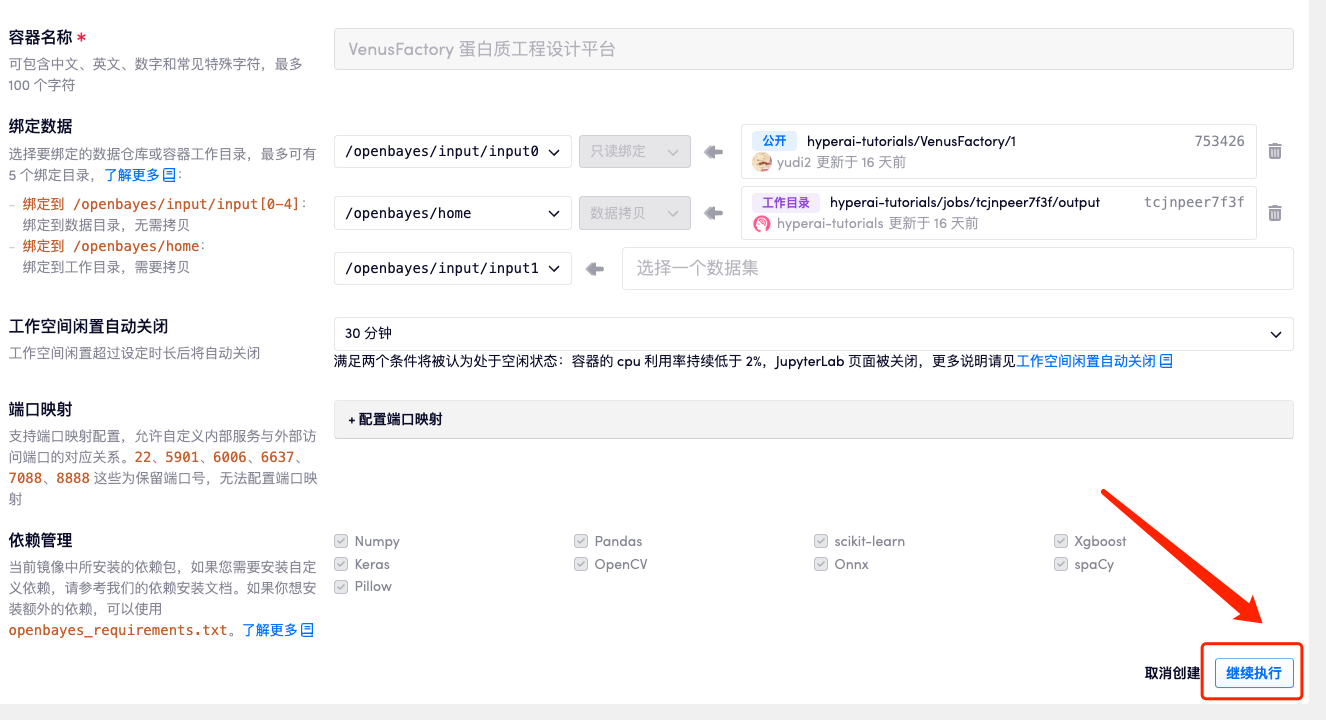
4. انتظر حتى يتم تخصيص الموارد. تستغرق عملية الاستنساخ الأولى حوالي دقيقتين. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق سهم الانتقال بجوار "عنوان API" للانتقال إلى صفحة العرض التوضيحي. نظرًا لأن النموذج كبير الحجم، يستغرق عرض واجهة WebUI حوالي 3 دقائق، وإلا فسيتم عرض "البوابة سيئة". يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.
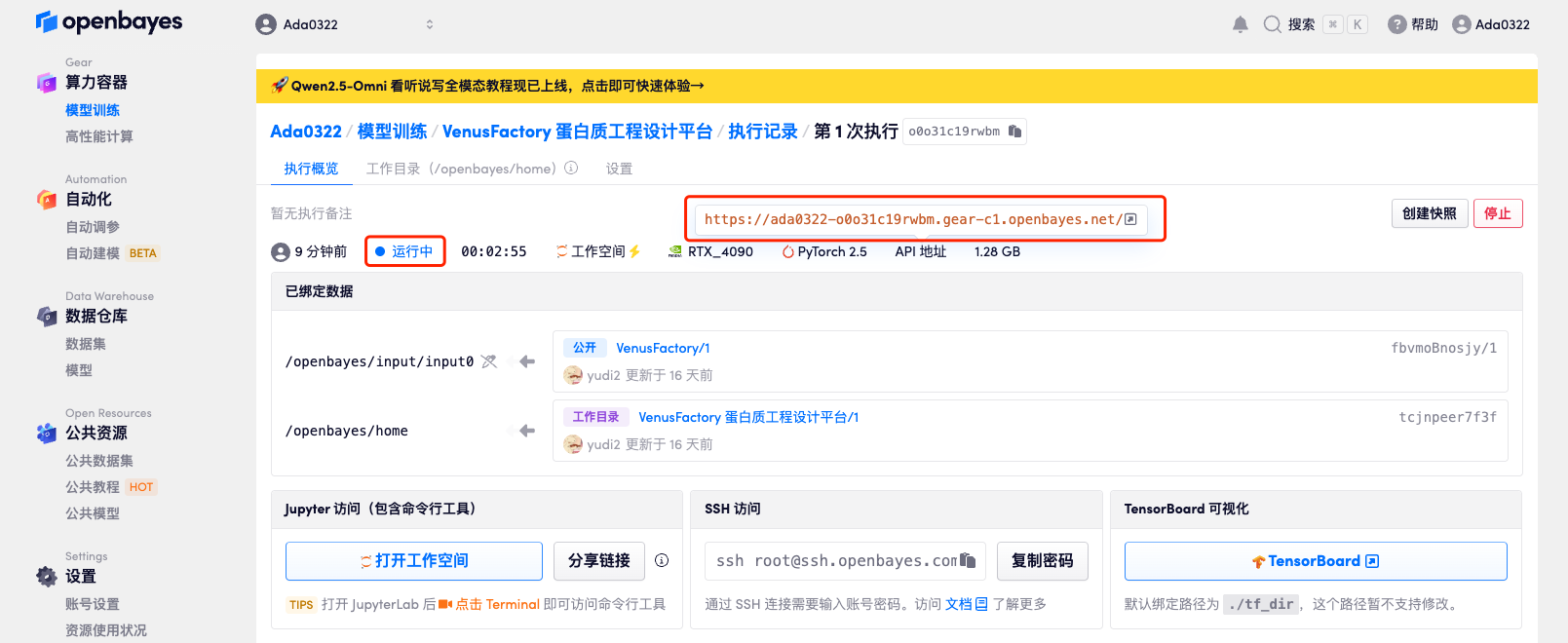
عرض التأثير
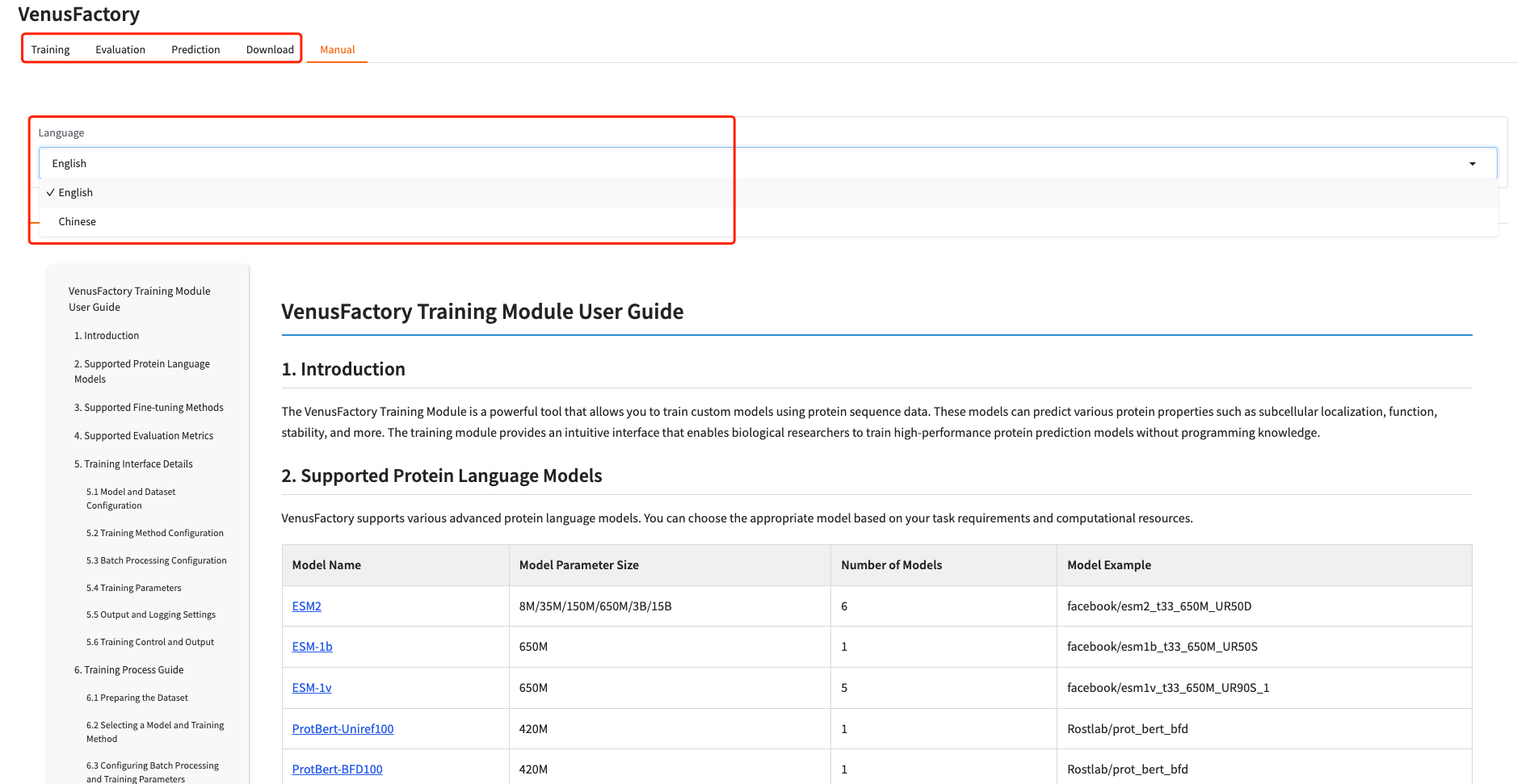
1. يحتوي هذا البرنامج التعليمي على أربع وحدات: التدريب، والتقييم، والتنبؤ، والتنزيل. انقر فوق "يدوي" واختر لغة لرؤية التعليمات التفصيلية لكل وحدة.
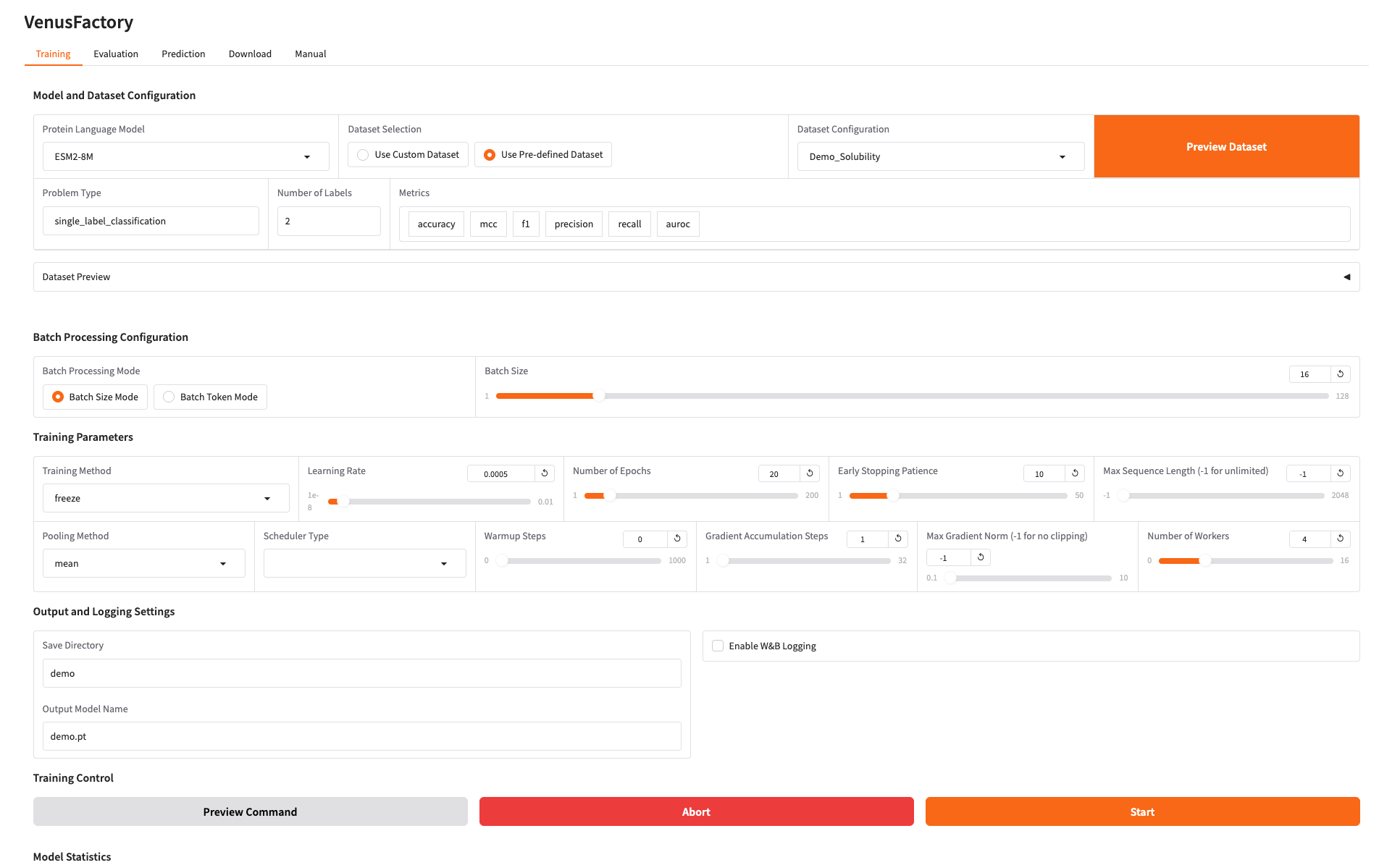
2. وحدة التدريب
انقر فوق وحدة التدريب، وحدد النموذج الذي تريد تدريبه في نموذج لغة البروتين، وقم بتكوين بيانات التدريب في تكوين مجموعة البيانات
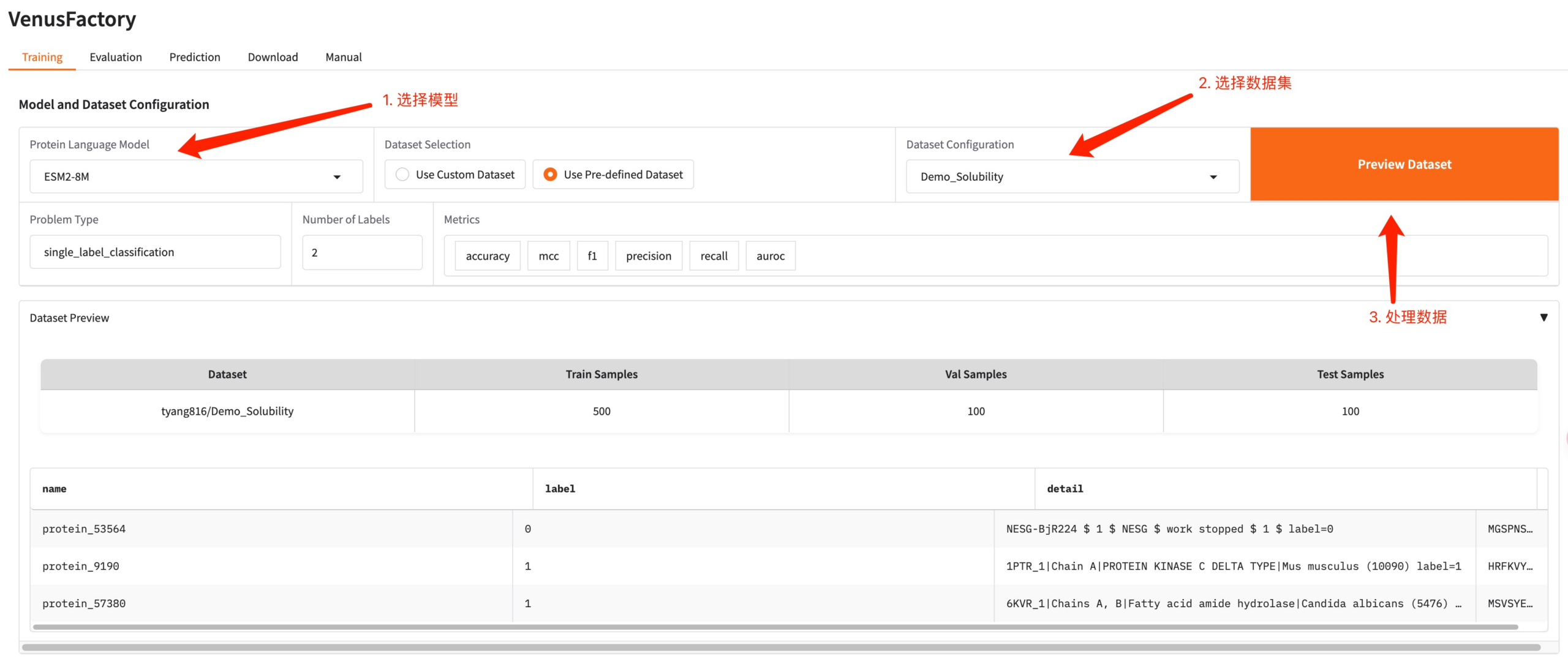
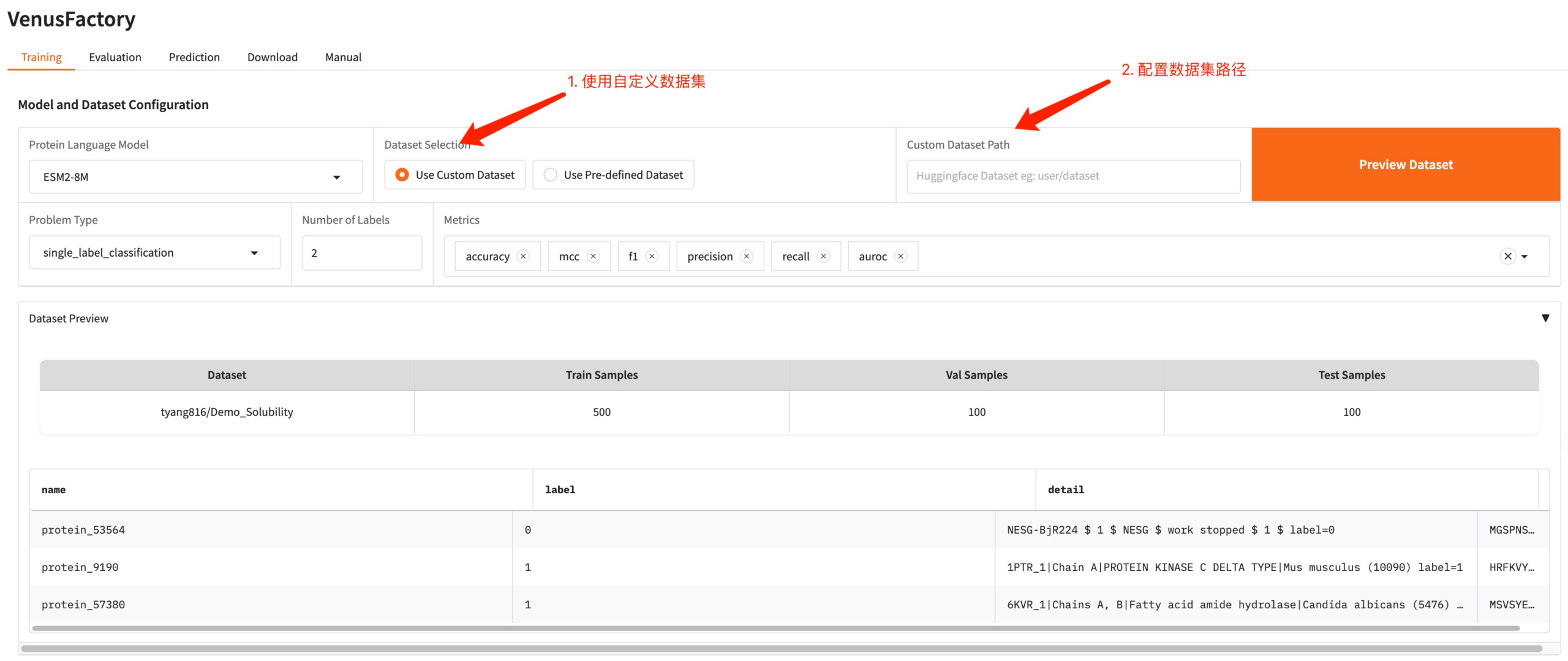
إذا كنت بحاجة إلى استخدام مجموعة البيانات الخاصة بك، فيمكنك استخدام تكوين استخدام مجموعة البيانات المخصصة وكل ما عليك فعله هو ملء مسار مجموعة البيانات (راجع وثائق الاستخدام اليدوي للحصول على التفاصيل).
قم بتعيين مسار حفظ نموذج التدريب وانقر فوق "ابدأ" لبدء التدريب.
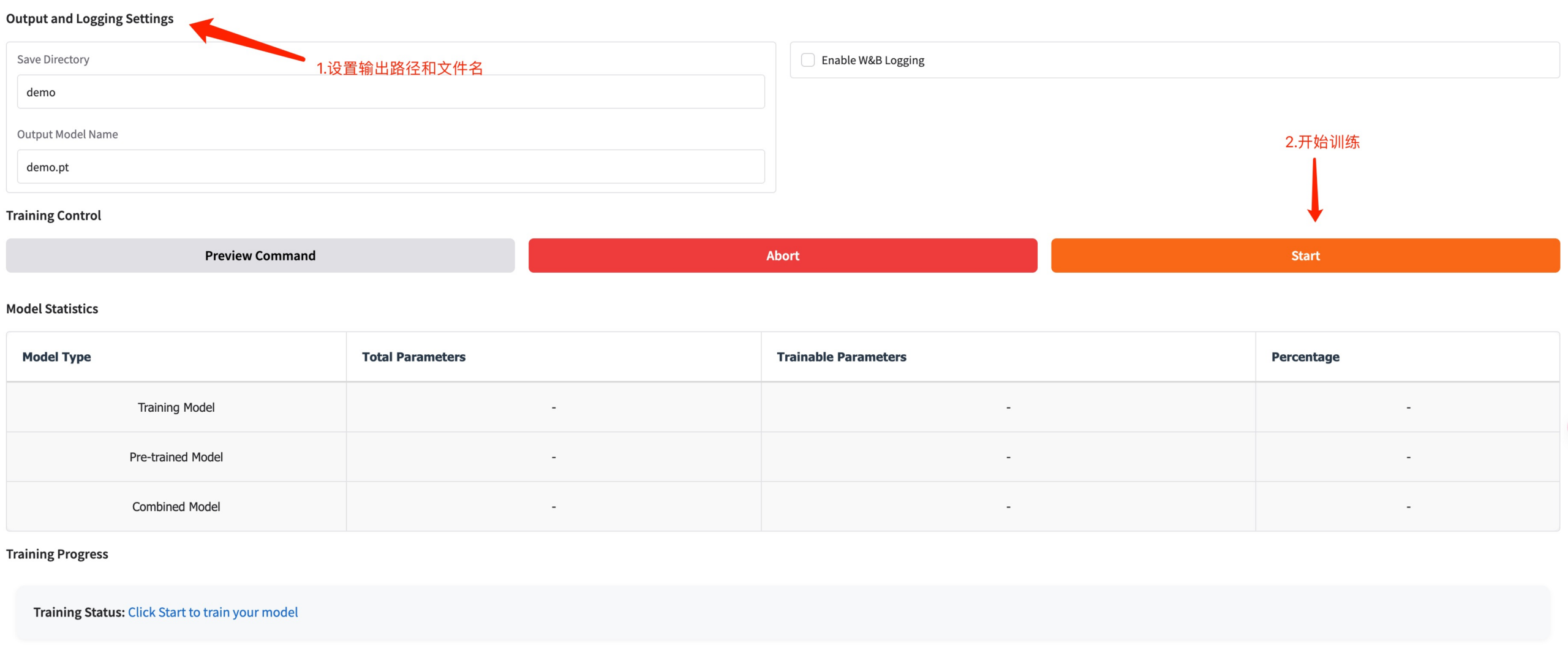
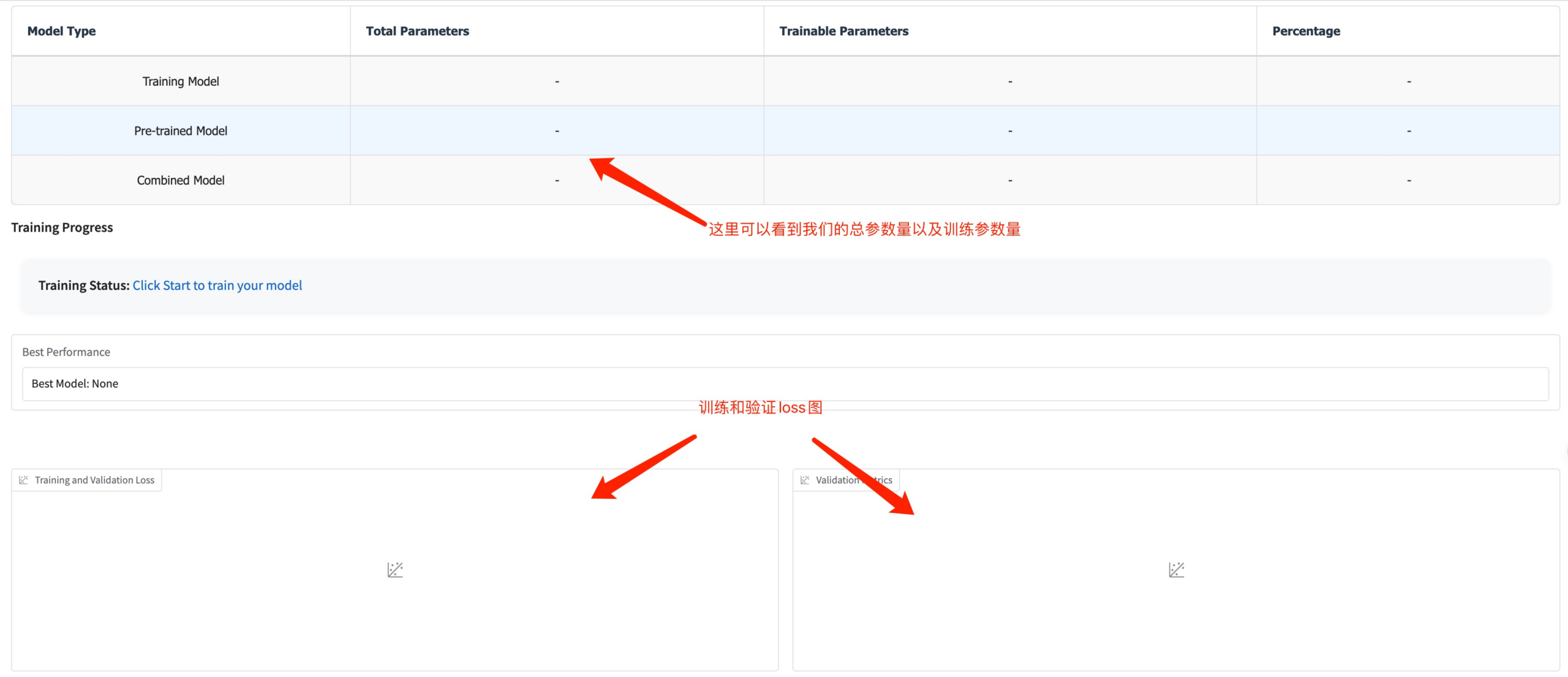
في هذه المرحلة يمكنك رؤية معلمات التدريب ومنحنى الخسارة
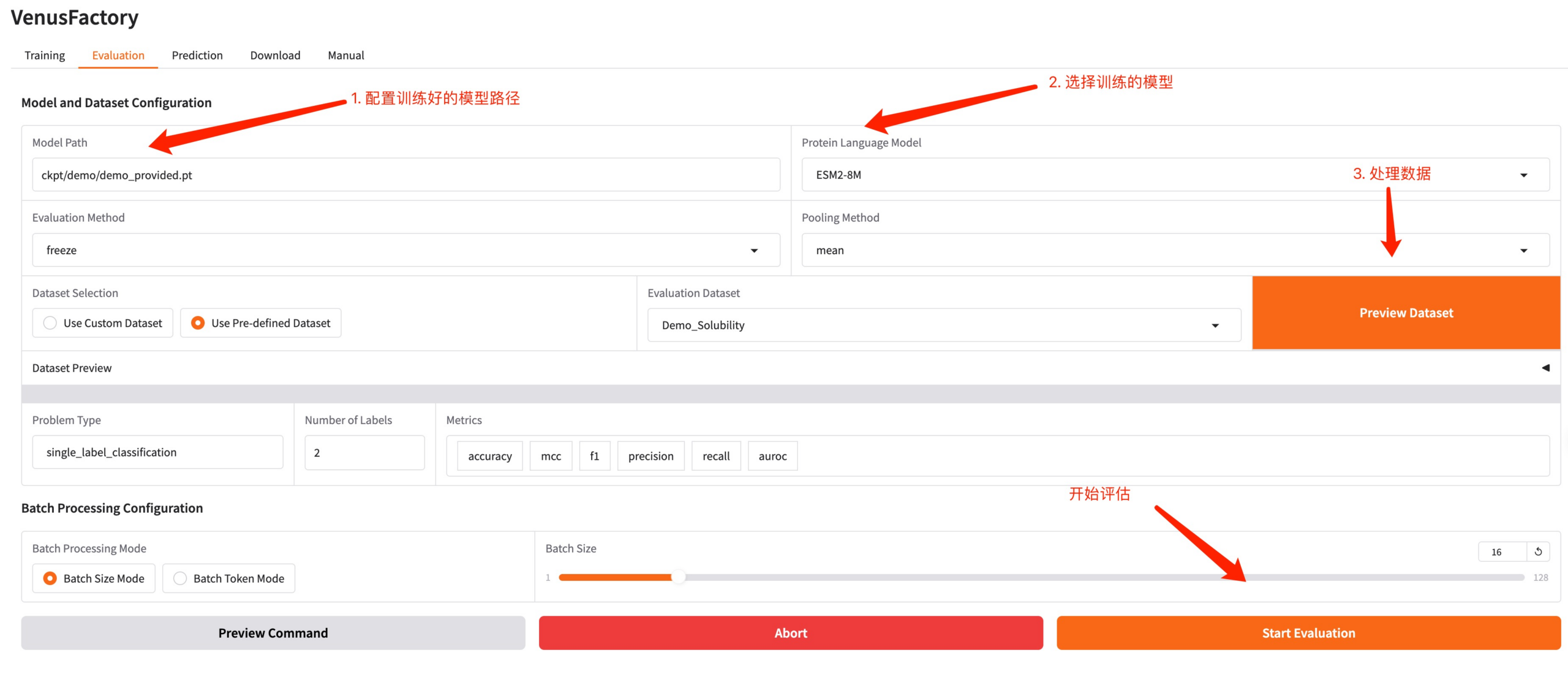
3. وحدة التقييم
انقر فوق وحدة التقييم، وقم بتكوين مسار النموذج الناتج عن التدريب والنموذج المدرب، ومعالجة البيانات، وضبط المعلمات الفائقة، وبدء التقييم.
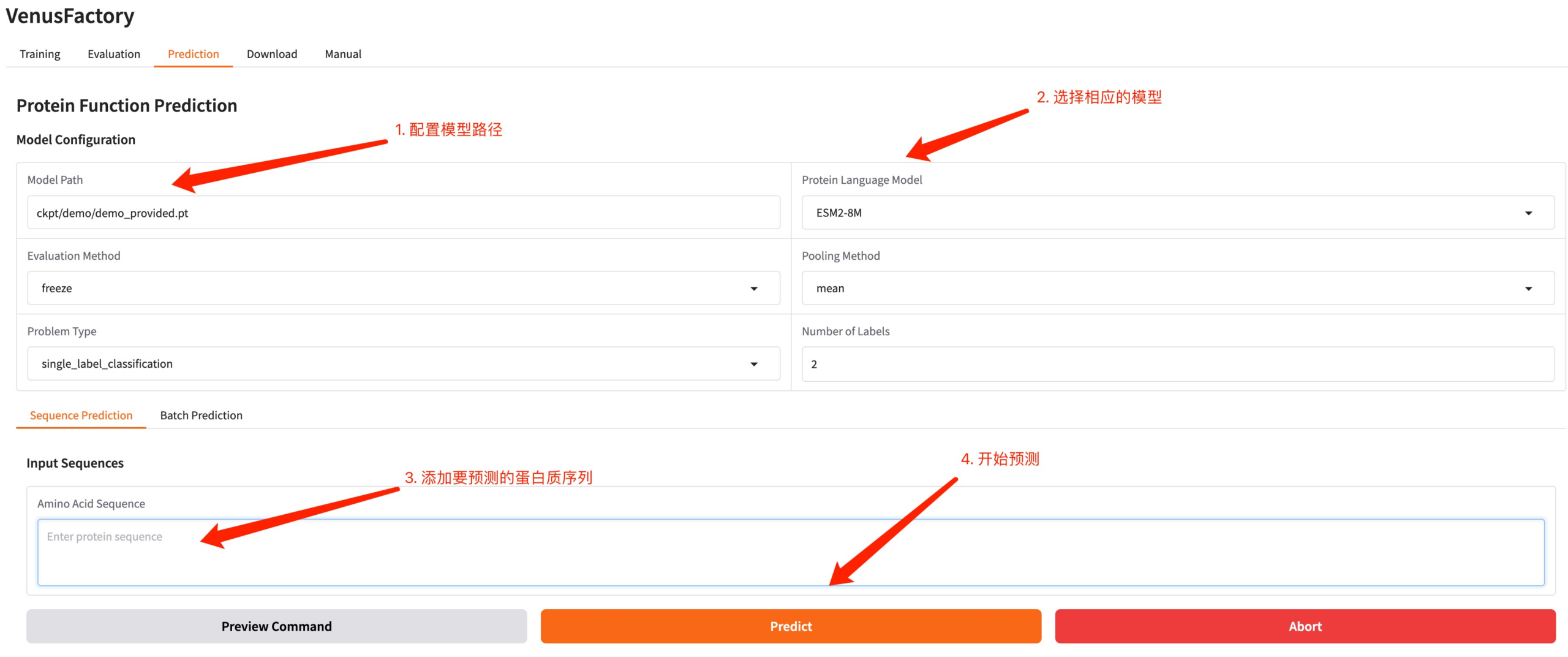
4. وحدة التنبؤ
انقر فوق وحدة التنبؤ، وقم بتكوين مسار النموذج الذي تم إنشاؤه بواسطة التدريب والنموذج المدرب، وأدخل تسلسل البروتين الذي تريد التنبؤ به، وانقر فوق التنبؤ لإجراء تنبؤ.
مثال على تسلسل البروتين: MKTWFGHVLQ
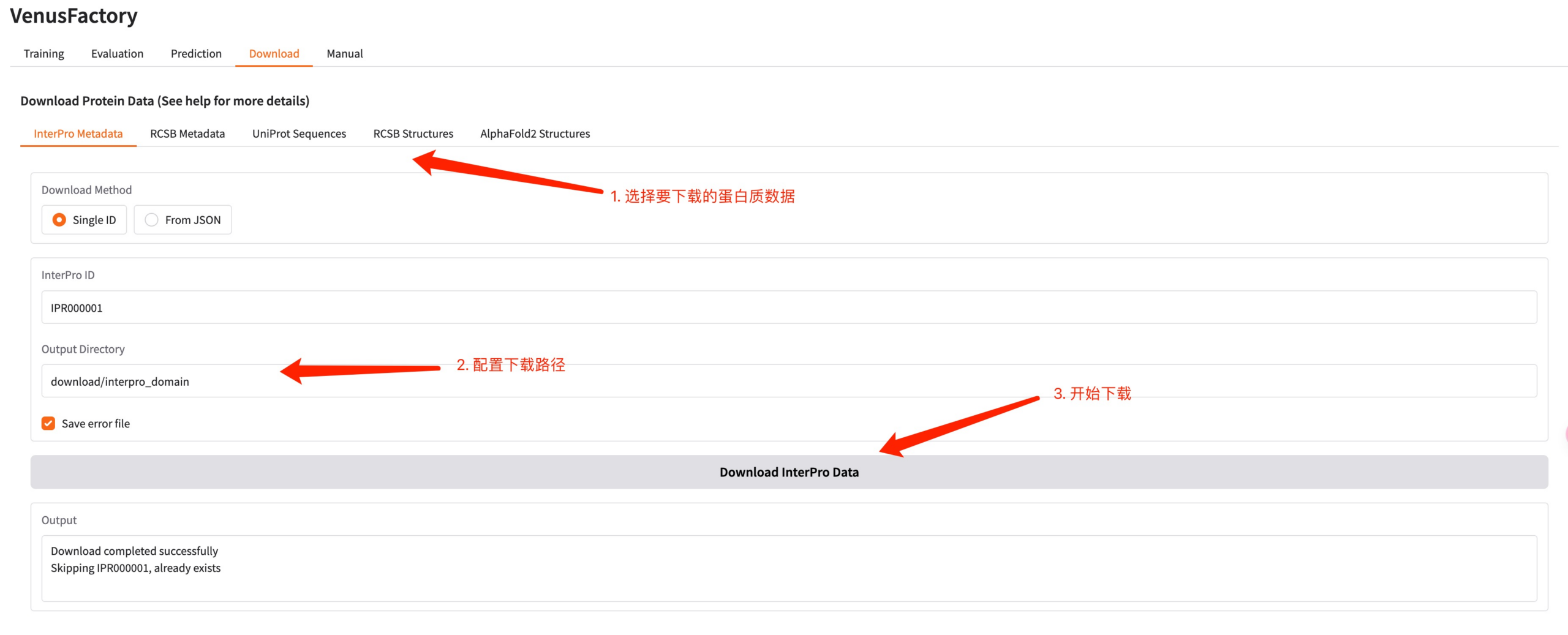
5. تنزيل الوحدة
انقر فوق وحدة التنزيل لتنزيل بيانات البروتين في هذه الواجهة.
ما ورد أعلاه هو برنامج تعليمي مفصل حول كيفية استخدام "منصة تصميم هندسة البروتين VenusFactory". الجميع مدعوون للحضور وتجربتها!








