Command Palette
Search for a command to run...
قام فريق جامعة ويستليك بتوفير SaProt ونماذج لغة البروتين الأخرى مفتوحة المصدر، والتي تغطي التنبؤ بوظيفة البنية/البحث عن المعلومات عبر الوسائط/تصميم تسلسل الأحماض الأمينية، وما إلى ذلك.

في الفترة من 22 إلى 23 مارس 2025، تم عقد "قمة تصميم بروتين الذكاء الاصطناعي" بجامعة شنغهاي جياو تونغ رسميًا.جمعت القمة أكثر من 300 خبير وباحث من جامعات معروفة مثل جامعة تسينغهوا وجامعة بكين وجامعة فودان وجامعة تشجيانغ وجامعة شيامن، بالإضافة إلى أكثر من 200 ممثل من شركات الصناعة الرائدة وموظفي البحث والتطوير الفني، لمناقشة أحدث نتائج الأبحاث والاختراقات التكنولوجية وآفاق التطبيق الصناعي للذكاء الاصطناعي في مجال تصميم البروتين.

خلال القمة،شارك الدكتور يوان فاجي من جامعة ويستليك أحدث التقدم البحثي في نماذج لغة البروتين تحت عنوان "البحث وتطبيق نماذج لغة البروتين" وقدم الإنجازات المهمة للفريق بالتفصيل.بما في ذلك نماذج لغة البروتين SaProt وProTrek وPinal وEvolla وما إلى ذلك. وقد قامت HyperAI بتنظيم وتلخيص المشاركة المتعمقة دون انتهاك النية الأصلية. وفيما يلي نص لأهم ما جاء في الخطاب:
نموذج لغة البروتين جدير بالملاحظة
البروتينات هي جزيئات بيولوجية كبيرة تتكون من 20 حمضًا أمينيًا مرتبطًا على التوالي. إنها تؤدي وظائف أساسية مثل التحفيز والتمثيل الغذائي في الجسم وهي المنفذ الرئيسي للأنشطة الحياتية. يقسم علماء الأحياء عادة بنية البروتينات إلى أربعة مستويات: البنية الأساسية تصف تسلسل الأحماض الأمينية في البروتين، والبنية الثانوية تركز على التكوين المحلي للبروتين، والبنية الثلاثية تمثل التكوين الثلاثي الأبعاد الكلي للبروتين، والبنية الرباعية تنطوي على التفاعل بين جزيئات البروتين المتعددة.في مجال بروتين الذكاء الاصطناعي، يعتمد البحث بشكل أساسي على هذه الهياكل.
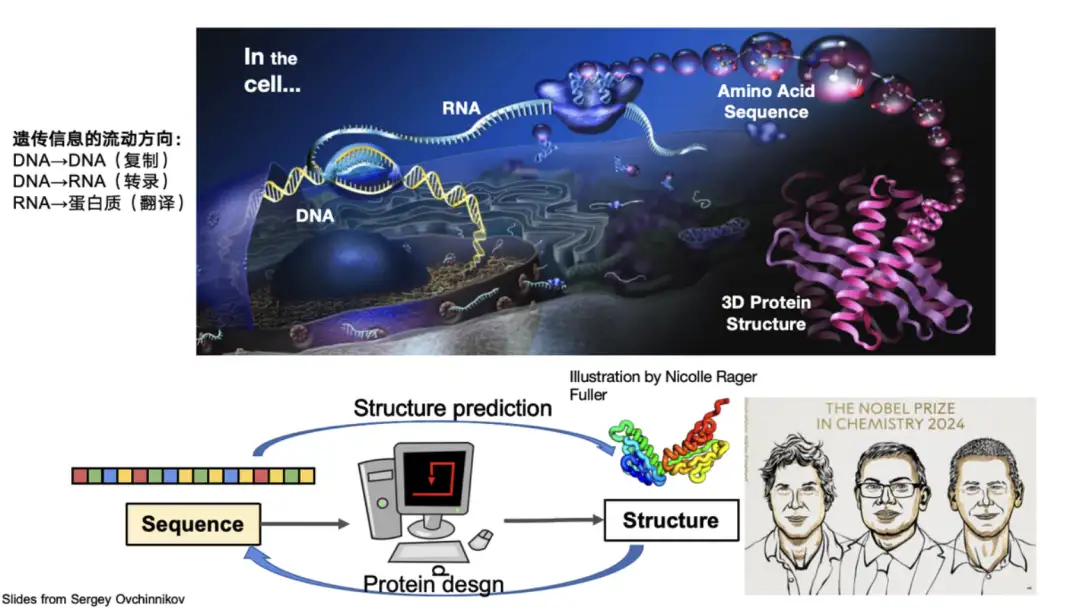
على سبيل المثال، التنبؤ بالبنية الثلاثية الأبعاد لبروتين من خلال تسلسله هو المشكلة الأساسية التي يحلها AlphaFold 2. وقد نجح هذا الاكتشاف في التغلب على مشكلة طي البروتين التي أزعجت المجتمع العلمي لمدة 50 عامًا، وحصل على جائزة نوبل لهذا الاكتشاف. ومن ناحية أخرى، فاز البروفيسور ديفيد بيكر، وهو مساهم مهم في مجال تصميم البروتين، أي تصميم تسلسلات بروتينية جديدة تعتمد على البنية والوظيفة، بجائزة نوبل أيضًا.
تقليديا، يتم تمثيل هياكل البروتين عادة في شكل إحداثيات PDB. في السنوات الأخيرة، استكشف الباحثون طرقًا لتحويل معلومات البنية المكانية المستمرة إلى رموز منفصلة، مثل Foldseek، وProTokens، وFoldToken، وProtSSN، وESM-3، وما إلى ذلك.
*يمكن لـ Foldseek ترميز البنية ثلاثية الأبعاد للبروتين إلى رموز منفصلة أحادية البعد.
ويعتمد نموذج لغة البروتين الخاص بفريقنا على هذه النتائج المنفصلة.
يمكن إرجاع معظم أبحاث الذكاء الاصطناعي والبروتين إلى أبحاث معالجة اللغة الطبيعية، لذا دعونا أولاً نراجع نموذجين لغويين كلاسيكيين في مجال معالجة اللغة الطبيعية (NLP):الأول هو نموذج اللغة أحادي الاتجاه الذي تمثله سلسلة GPT،تعتمد آليتها على تدفق المعلومات من اليسار إلى اليمين، والتنبؤ بالرمز التالي بناءً على البيانات الموجودة على اليسار (أعلاه).الأول هو نموذج اللغة ثنائي الاتجاه الذي يمثله BERT،يتم تدريبه مسبقًا من خلال نموذج اللغة المقنع، والذي يمكنه رؤية المعلومات (السياق) على الجانبين الأيسر والأيمن من الكلمة المطبوخة والتنبؤ بالكلمة المطبوخة.
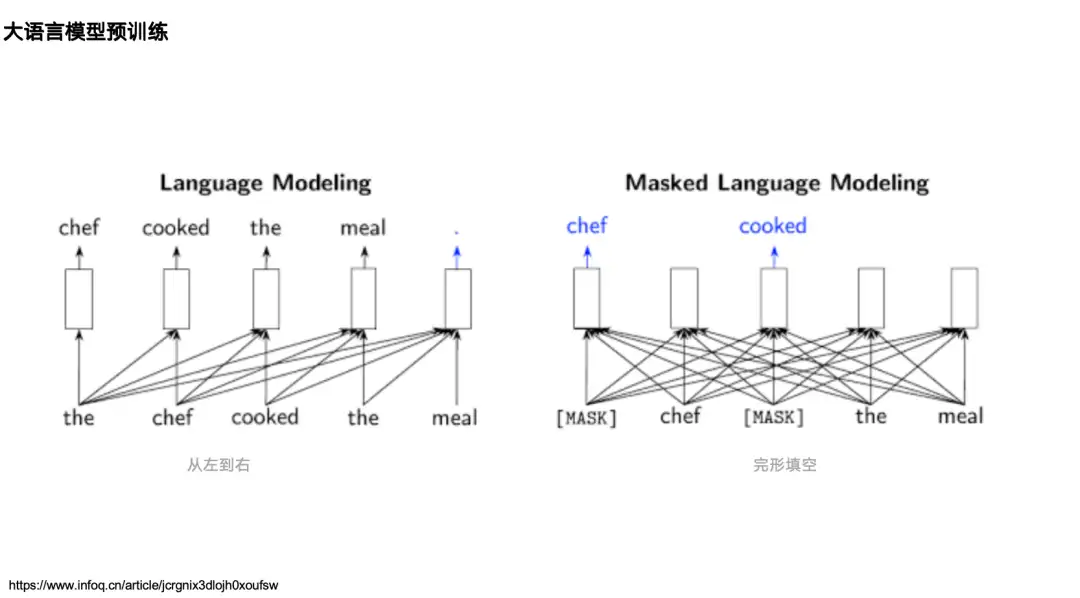
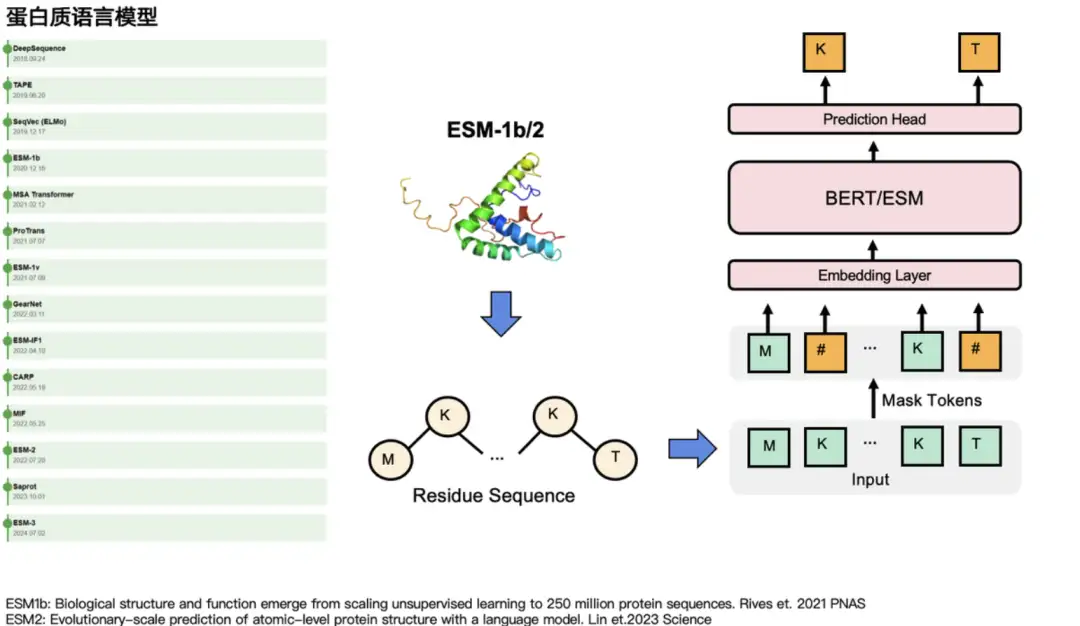
في مجال البروتين، كلا النوعين من النماذج لديهما نماذج لغة البروتين المقابلة لها.على سبيل المثال، فيما يتعلق بـ GPT، هناك ProtGPT2، وProGen، وما إلى ذلك. وفيما يتعلق بـ BERT، هناك نماذج سلسلة ESM: ESM-1b، وESM-2، وESM-3. إنها تقوم بشكل أساسي بإخفاء بعض الأحماض الأمينية والتنبؤ بهويتها الحقيقية. في مهام اللغة الطبيعية، يقومون بإخفاء بعض الكلمات ثم التنبؤ بها. كما هو موضح على الجانب الأيسر من الشكل أدناه، تتضمن نماذج اللغة الأخرى التي لها تأثير كبير نسبيًا في مجتمع البروتين MSA Transformer، وGearNet، وProTrans، وما إلى ذلك.
تم اختيار نموذج لغة البروتين SaProt لـ ICLR 2024، ويدمج المعرفة البنيوية
النتيجة الأولى التي أريد أن أقدمها لكم هي SaProt، وهو نموذج لغة بروتينية يحتوي على مفردات تدرك البنية.تم اختيار هذه الورقة البحثية، بعنوان "SaProt: نمذجة لغة البروتين باستخدام المفردات المدركة للبنية"، لمؤتمر ICLR 2024.
في هذه الورقة، اقترحنا مفهوم المفردات التي تدرك البنية، ودمجنا رموز بقايا الأحماض الأمينية مع رموز البنية، وقمنا بتدريب نموذج لغة البروتين العالمي واسع النطاق SaProt على مجموعة بيانات تحتوي على ما يقرب من 40 مليون تسلسل وبنية بروتينية. لقد تفوق هذا النموذج بشكل شامل على نماذج خط الأساس الناضجة الموجودة في 10 مهام لاحقة مهمة.
عنوان SaProt مفتوح المصدر:
https://github.com/westlake-repl/SaProt
عنوان ورقة SaProt:
https://openreview.net/forum?id=6MRm3G4NiU
لماذا نصنع هذا النموذج؟
في الواقع، تعتمد المعلومات المدخلة لمعظم نماذج لغة البروتين بشكل أساسي على تسلسلات الأحماض الأمينية. بعد الاختراق الذي حققه AlphaFold، تعاون فريق DeepMind مع المعهد الأوروبي للمعلوماتية الحيوية (EMBL-EBI) لإصدار قاعدة بيانات بنية البروتين AlphaFold، التي تخزن 200 مليون بنية بروتينية. فبدأنا نفكر: هل يمكننا دمج المعلومات البنيوية للبروتين في نموذج اللغة لتحسين أدائه؟

نهجنا بسيط للغاية: نستخدم Foldseek لتحويل المعلومات البنيوية للبروتين من شكل إحداثيات إلى رموز منفصلة، وبالتالي بناء مفردات الأحماض الأمينية ومفردات البنيوية، ثم نقوم بدمج هاتين المفردات معًا لتوليد مفردات جديدة، وهي المفردات الواعية للبنية (رمز SA). بهذه الطريقة، يمكن تحويل تسلسل الأحماض الأمينية الأصلي إلى تسلسل جديد للأحماض الأمينية - في هذا التسلسل، تمثل الأحرف الكبيرة رموز الأحماض الأمينية وتمثل الأحرف الصغيرة رموز البنية. ومن ثم، يمكننا الاستمرار في العمل على نموذج اللغة المقنعة. وبناءً على ذلك، قمنا بتدريب نموذج SaProt الذي يحتوي على 650 مليون معلمة باستخدام 64 وحدة معالجة رسومية A100 بإجمالي وقت تدريب يبلغ حوالي 3 أشهر.
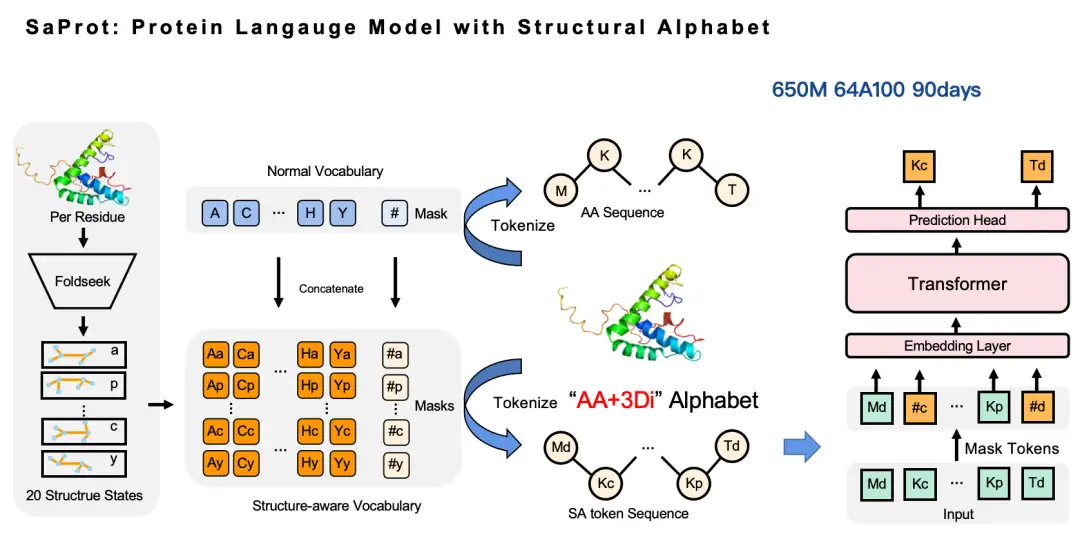
لماذا اخترنا Foldseek لتحويل رموز بنية البروتين؟
استغرق الأمر منا نصف عام لاتخاذ القرار النهائي بشأن تسلسل رمز Foldseek 3Di. من البديهي أن دمج المعلومات البنيوية في نموذج لغة البروتين من شأنه أن يحسن الأداء، ولكن عندما حاولنا ذلك بالفعل، جربنا أساليب مختلفة لكننا فشلنا. على سبيل المثال، استخدمنا طريقة GNN لنمذجة بنية البروتين. نظرًا لأن بنية البروتين هي في الواقع شبكة عصبية بيانية، فإننا نرغب بطبيعة الحال في نمذجة بنية البروتين على شكل رسم بياني، لذلك اعتمدنا طريقة MIF، لكننا وجدنا أن النموذج المدرب لديه قدرة تعميم ضعيفة ولا يمكن تمديده إلى بنية PDB الحقيقية. وبعد إجراء تحليل متعمق، نعتقد أن السبب في ذلك قد يكون أن طريقة النمذجة باستخدام نموذج اللغة المقنعة قد تتسبب في حدوث مشاكل تسرب المعلومات.
ببساطة، فإن بنية البروتين التي يتنبأ بها AlphaFold نفسها تحتوي على تحيزات وأنماط وآثار معينة للتنبؤ بالذكاء الاصطناعي. عندما يتم استخدام هذه البيانات لتدريب نموذج لغوي، يمكن للنموذج التقاط هذه الآثار بسهولة، مما يؤدي إلى أداء النموذج بشكل جيد على بيانات التدريب ولكن لديه قدرة تعميم ضعيفة.
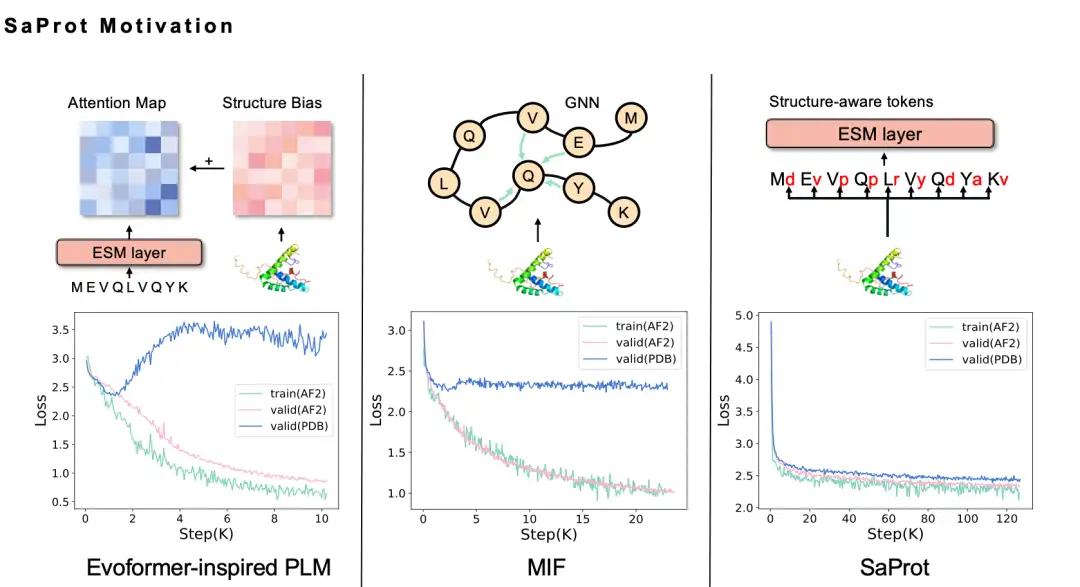
لقد جربنا العديد من التحسينات، بما في ذلك استخدام طريقة Evoformer، ولكن مشكلة تسرب المعلومات ظلت موجودة حتى جربنا Foldseek. وجدنا أن فقدان نموذج SaProt الذي تم الحصول عليه على البيانات الهيكلية التي تنبأ بها AlphaFold قد تم تقليله، كما تم تقليل الخسارة على بيانات بنية PDB الحقيقية بشكل كبير، وهو ما يلبي توقعاتنا.
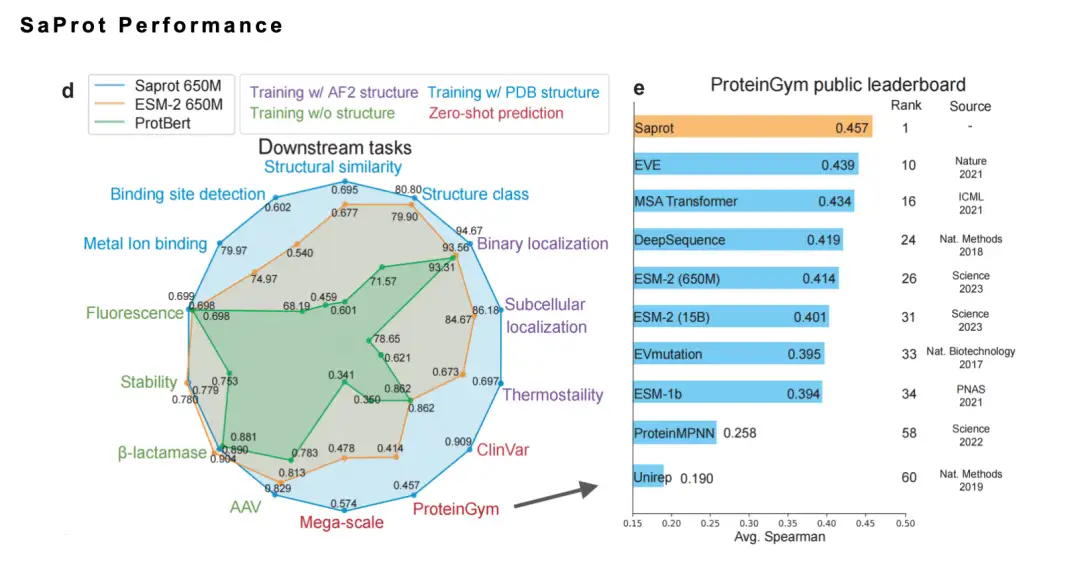
بالإضافة إلى ذلك، يعمل SaProt بشكل جيد على معايير متعددة.وفي العام الماضي، احتلت أيضًا المرتبة الأولى في القائمة الموثوقة ProteinGym. في الوقت نفسه، قمنا أيضًا بجمع نتائج التحقق من التجارب الرطبة التي أجراها المجتمع على SaProt/ColabSaProt على أكثر من 10 بروتينات (مثل تعديلات الطفرة الإنزيمية المختلفة، وتعديل البروتين الفلوري والتنبؤ بالفلورسنت، وما إلى ذلك)، والتي كان أداؤها ممتازًا.
على الرغم من أننا نعتقد أن نموذج SaProt جيد جدًا،ولكن بالنظر إلى أن العديد من علماء الأحياء لم يتلقوا تدريبًا في التعلم العميق،من الصعب جدًا عليهم ضبط نموذج لغة البروتين بشكل مستقل مع حوالي مليار معلمة.لذلك قمنا ببناء منصة واجهة تفاعلية ColabSaprot + SaprotHub.
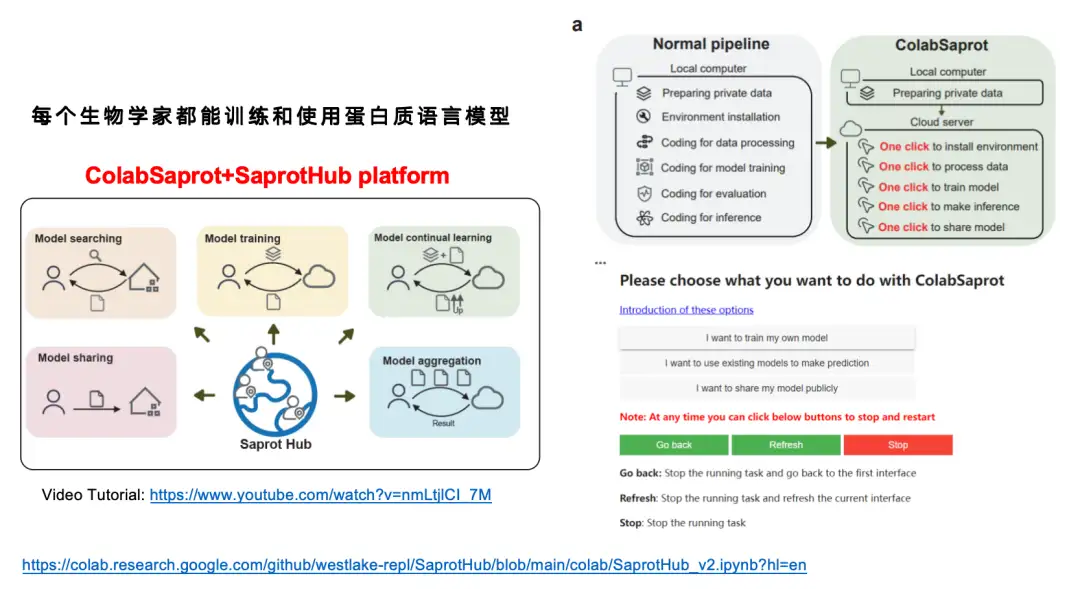
في عملية تدريب النموذج التقليدية (خط الأنابيب العادي)، يحتاج المستخدمون إلى اتباع خطوات متعددة بما في ذلك إعداد البيانات، وتكوين البيئة، وكتابة التعليمات البرمجية، ومعالجة البيانات، وتدريب النموذج، وتقييم النموذج، واستدلال النموذج، وما إلى ذلك. مع ColabSaprot، تم تبسيط العملية برمتها بشكل كبير - يحتاج المستخدمون فقط إلى النقر فوق بضعة أزرار لإكمال تثبيت البيئة، وتدريب النموذج، والتنبؤ، والعمليات الأخرى، مما يقلل بشكل كبير من عتبة الاستخدام.
كما هو موضح في الشكل أدناه، يتكون ColabSaprot بشكل أساسي من ثلاثة أجزاء: وحدة التدريب ووحدة التنبؤ ووحدة المشاركة.

* في وحدة التدريب، يحتاج المستخدمون فقط إلى وصف المهمة على اليسار وتحميل البيانات، ثم النقر فوق التدريب. سيقوم النظام تلقائيًا باختيار المعلمات الفائقة المثلى (مثل حجم الدفعة، وما إلى ذلك).
* في وحدة التنبؤ، يمكن للمستخدمين تحميل النماذج التي تم تدريبهم عليها مسبقًا بشكل مباشر وإجراء التنبؤات. يمكنك أيضًا إدخال النماذج التي تمت مشاركتها بواسطة باحثين آخرين بشكل مباشر لإجراء التنبؤات.
* توفر وحدة المشاركة طريقة لحماية خصوصية البيانات أثناء مشاركة النتائج. إن البيانات من العديد من المختبرات ذات قيمة كبيرة، وقد يحتاج بعض الباحثين إلى استخدام هذه البيانات لإجراء أبحاث متابعة، ولكنهم ما زالوا يرغبون في مشاركة النماذج الموجودة. في ColabSaprot، يمكن للمستخدمين مشاركة النموذج نفسه فقط. وبما أن النموذج هو في الأساس صندوق أسود، فلا يستطيع الآخرون الحصول على البيانات الأصلية.
عند مشاركة النماذج، ونظرًا لأن نماذج اللغة عادةً ما تكون كبيرة الحجم، فمن غير الممكن تقريبًا مشاركة نموذج يحتوي على مليار معلمة عبر الإنترنت بشكل مباشر.ولذلك، اعتمدنا آلية محول ناضجة.لا يحتاج المستخدمون إلا إلى مشاركة عدد صغير جدًا من المعلمات - عادةً 1% فقط أو 1/1000 من معلمات النموذج الأصلي. يمكن لأي شخص مشاركة المحولات مع بعضهم البعض وتحميل محولات الأشخاص الآخرين لإجراء تعديلات دقيقة أو تنبؤات بناءً عليها. إذا كان التحسن جيدًا، فيمكن مشاركة المحولات الجديدة مرة أخرى، وبالتالي تشكيل آلية فعالة للتعاون المجتمعي وتحسين كفاءة البحث بشكل كبير.
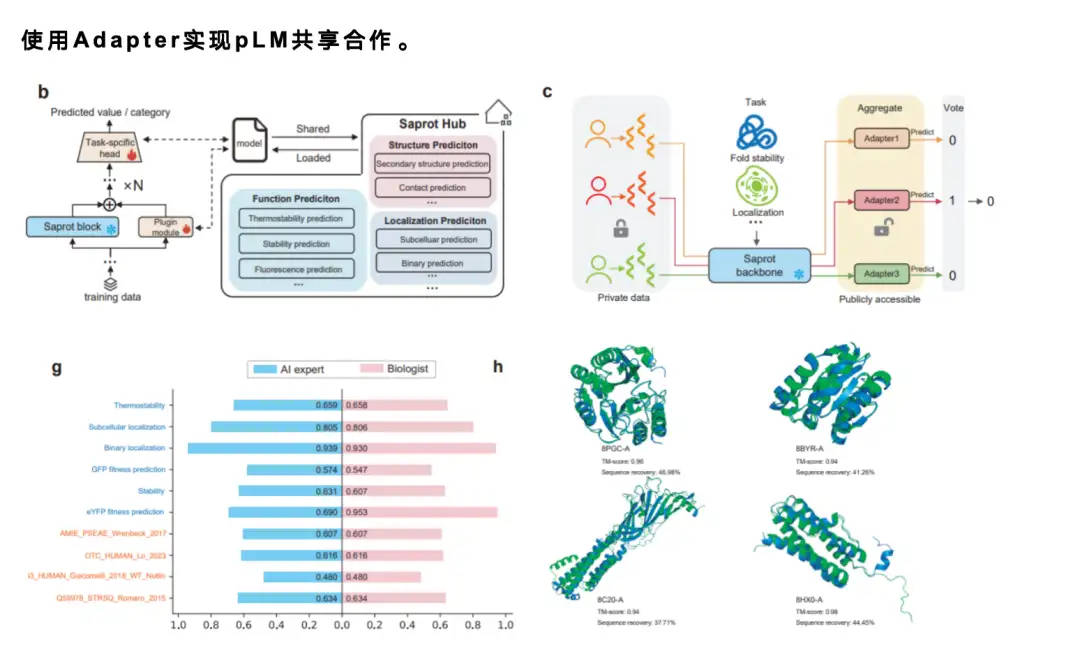
بالإضافة إلى ذلك، أجرينا أيضًا دراسة للمستخدمين.لقد قمنا بدعوة 12 طالبًا ليس لديهم أي خلفية في التعلم الآلي أو معرفة بالبرمجة لتجربة منصة ColabSaprot. لقد قدمنا لهم البيانات وأخبرناهم بالمهام التي يجب القيام بها، وطلبنا منهم استخدام ColabSaprot لتدريب النموذج والتنبؤ به. وأخيرًا، من خلال مقارنة نتائجهم بأداء خبراء الذكاء الاصطناعي، وجدنا أن هؤلاء المستخدمين غير الخبراء تمكنوا من الوصول إلى مستوى قريب من مستوى الخبراء الذين يستخدمون ColabSaprot.
بالإضافة إلى ذلك، من أجل تعزيز تبادل نماذج لغة البروتين،لقد قمنا أيضًا بتأسيس مجتمع يسمى OPMC،وشارك فيه علماء معروفون من الداخل والخارج في هذا المجال، مما شجع الجميع على تبادل النماذج وتعزيز التعاون والتواصل.
عنوان OPMC:

نموذج ProTrek: ابحث عن التوافق بين تسلسل البروتين وبنيته ووظيفته
العمل الثاني الذي أريد أن أقدمه هو نموذج لغة البروتين ProTrek.
في البحث البيولوجي، يواجه العديد من العلماء هذه الحاجة: لديهم جينوم يحتوي على العديد من البروتينات ولكنهم لا يعرفون وظائفها المحددة.
ProTrek هو نموذج لغوي ثلاثي الأنماط للتعلم المتباين للتسلسل والبنية والوظيفة.بفضل واجهة البحث باللغة الطبيعية، يستطيع المستخدمون استكشاف مساحة البروتين الواسعة في ثوانٍ والبحث عن العلاقات بين جميع التركيبات الزوجية للتسلسل والبنية والوظيفة لتسع مهام مختلفة. بمعنى آخر، باستخدام ProTrek، يحتاج المستخدمون فقط إلى إدخال تسلسل البروتين والنقر فوق الزر للعثور بسرعة على المعلومات المتعلقة بوظيفة البروتين وبنيته. وبالمثل، يمكنك أيضًا العثور على معلومات التسلسل والبنية بناءً على الوظيفة، والعثور على معلومات التسلسل والوظيفة بناءً على البنية، وما إلى ذلك. بالإضافة إلى ذلك، فهو يدعم أيضًا عمليات البحث عن فئات التسلسل-التسلسل والبنية-البنية.
عنوان استخدام ProTrek:
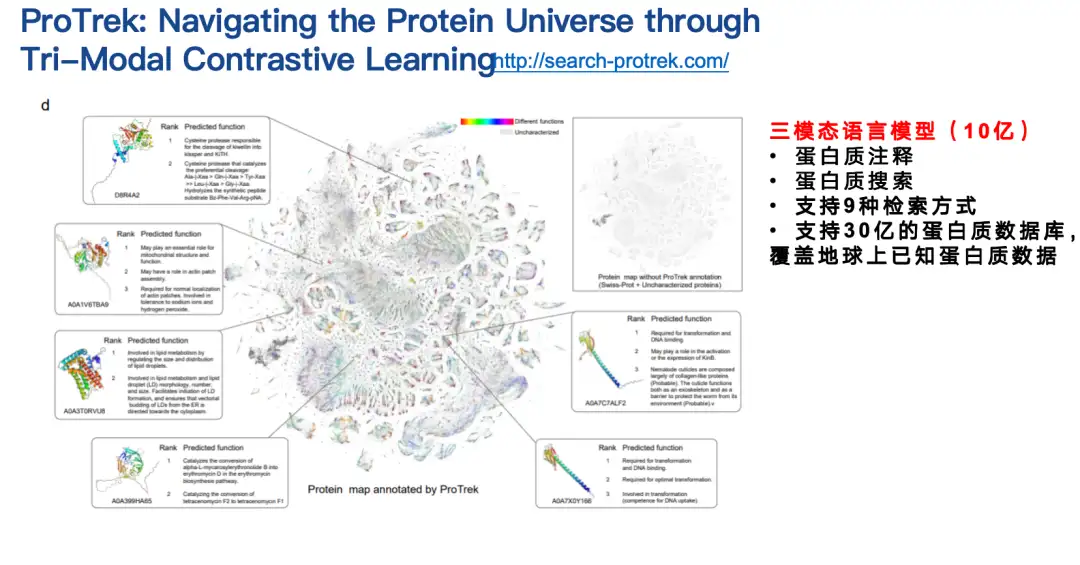
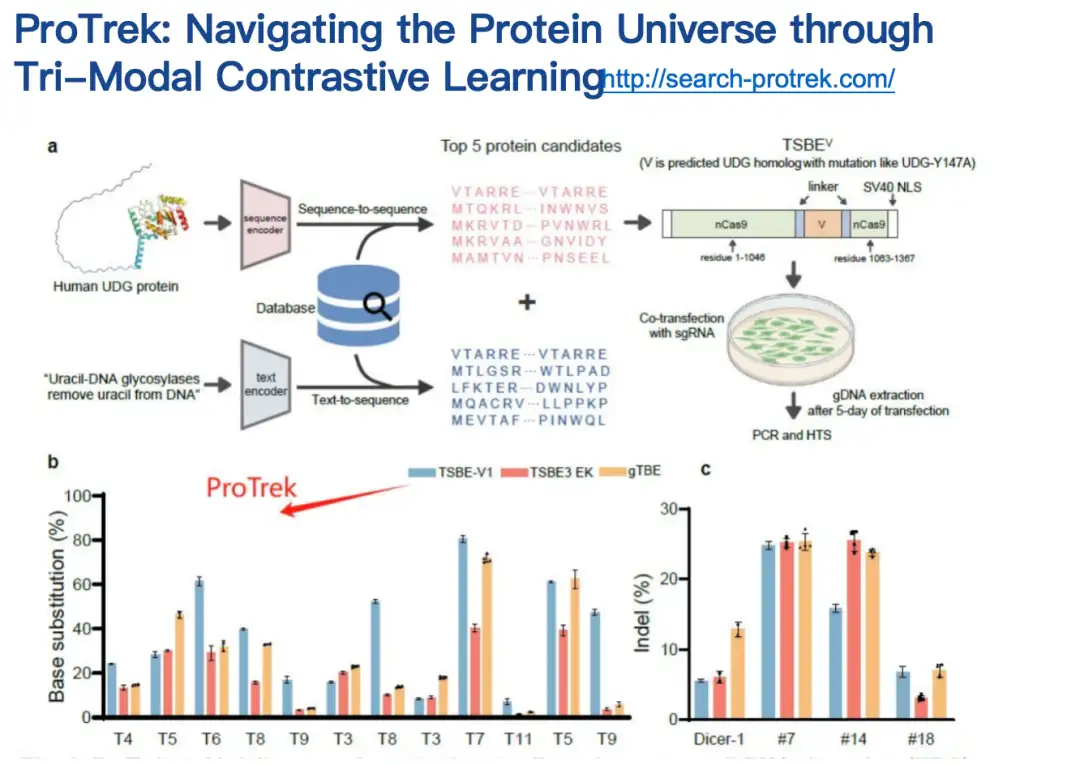
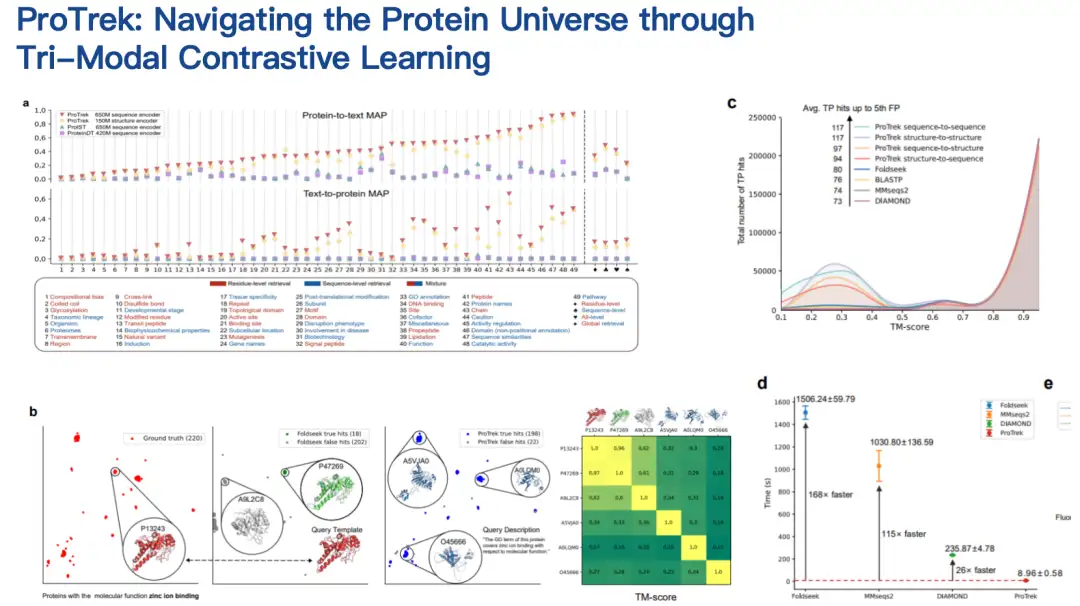
قام زملاؤنا بتقييم نموذج ProTrek في الاختبارات الجافة والرطبة.وبالمقارنة بالطرق ذات الصلة الموجودة، حقق ProTrek تحسينات كبيرة في الأداء. بالإضافة إلى ذلك، استخدمنا أيضًا ProTrek لإنشاء كمية كبيرة من البيانات لتدريب نموذجنا التوليدي، والذي حقق أيضًا أداءً جيدًا.
لاحظنا على تويتر أنلقد بدأ العديد من المستخدمين في استخدام ProTrek للتنافس.لقد تلقينا أيضًا الكثير من التعليقات الإيجابية، والتي أثبتت بشكل أكبر جدوى النموذج.
نموذج بينال: تصميم تسلسلات بروتينية جديدة بمجرد إدخال النص
ومن أعمالنا الأخرى مشروع Pinal، وهو نموذج لتصميم البروتينات استنادًا إلى الأوصاف النصية.
عادةً ما يحتاج تصميم البروتين التقليدي إلى مراعاة عوامل معقدة، مثل معلومات قالب وظيفة الطاقة البيوفيزيائية. ما نريد استكشافه هو، بما أن نماذج اللغة الكبيرة تعمل بشكل جيد في العديد من المهام، فهل من الممكن تصميم نموذج لغة بروتينية يعتمد على النص؟ في هذا النموذج، نحتاج فقط إلى وصف معلومات البروتين لتصميم تسلسل الأحماض الأمينية الخاصة به؟
عنوان استخدام بينال:
http://www.denovo-pinal.com/
عنوان الورقة:
https://www.biorxiv.org/content/10.1101/2024.08.01.606258v1
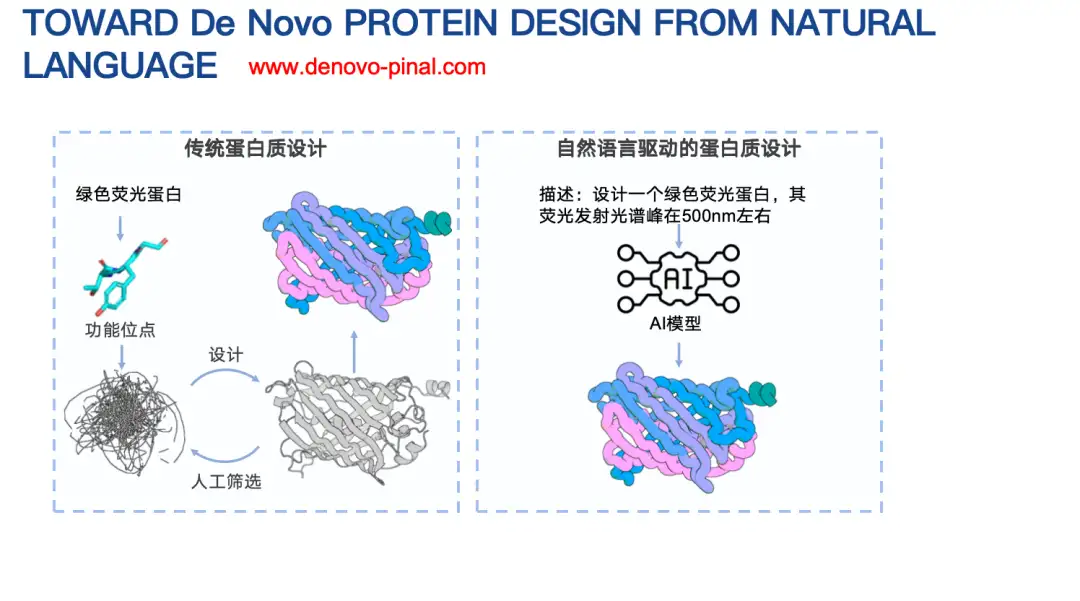
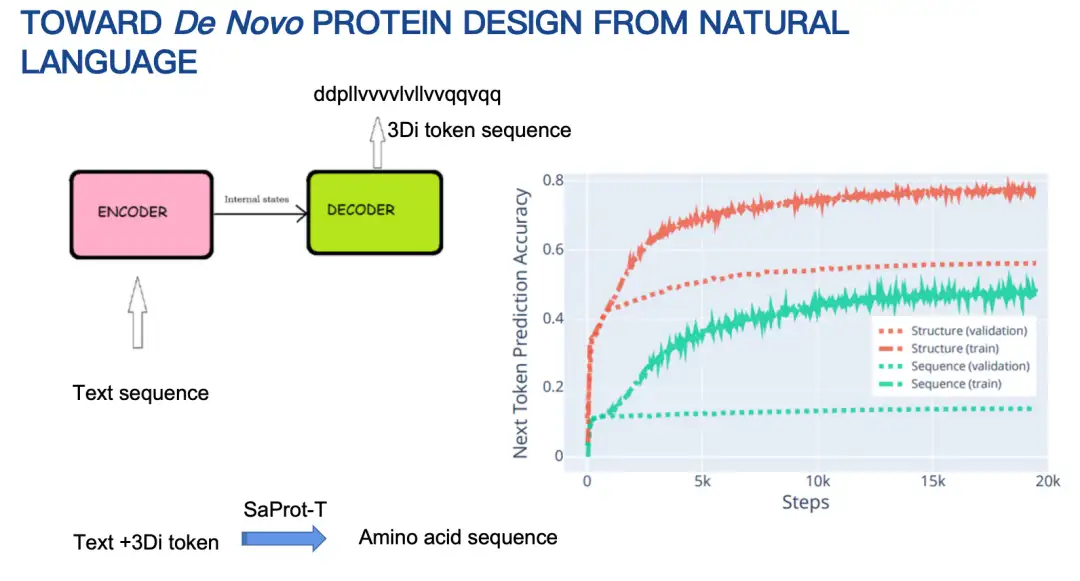
دعوني أقدم لكم بشكل مختصر المبادئ الأساسية لـPinal (16 مليار معلمة).في البداية، كانت فكرتنا هي استخدام بنية تشفير وفك تشفير تقوم بإدخال النص وإخراج تسلسل الأحماض الأمينية. ومع ذلك، بعد المحاولة لفترة طويلة، لم تكن النتائج مثالية. السبب الرئيسي هو أن مساحة تسلسل الأحماض الأمينية كبيرة جدًا، مما يجعل التنبؤات صعبة.
ولذلك، قمنا بتعديل استراتيجيتنا لتصميم بنية البروتين أولاً ثم تصميم تسلسل الأحماض الأمينية بناءً على البنية والإشارات النصية. يتم تمثيل بنية البروتين هنا أيضًا من خلال التشفير المنفصل. وتظهر النتائج أن طريقة التصميم الممزوجة بالهيكل تؤدي أداءً أفضل بكثير من طريقة التنبؤ المباشر بتسلسل الأحماض الأمينية من حيث دقة التنبؤ بالرمز التالي، كما هو موضح في الشكل أدناه.
لقد تلقينا مؤخرًا التحقق من مختبر Pinal من شركائنا.قام بينال بتصميم 6 تسلسلات بروتينية، 3 منها تم التعبير عنها وتم التحقق من أن تسلسلين لهما نشاط تحفيزي إنزيمي مماثل. ومن الجدير بالذكر أنه في هذا العمل لم نركز على تصميم بروتين أفضل من النوع البري. هدفنا الرئيسي هو التحقق ما إذا كان البروتين المصمم على أساس النص لديه وظيفة البروتين المقابلة.
نموذج إيفولا: فك شفرة اللغة الجزيئية للبروتينات
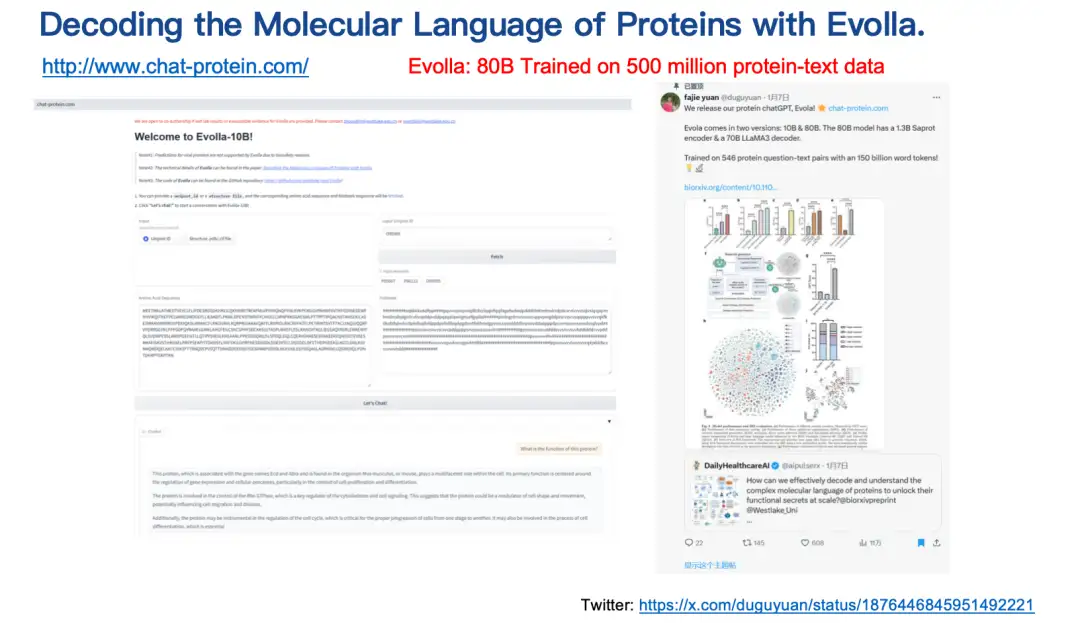
النتيجة الأخيرة التي تم تقديمها هي نموذج Evolla.هذا نموذج لتوليد لغة بروتينية يحتوي على 80 مليار معلمة، وهو أحد أكبر النماذج البيولوجية مفتوحة المصدر، مصمم لفك شفرة اللغة الجزيئية للبروتينات.
من خلال دمج تسلسل البروتين وبنيته ومعلومات استعلام المستخدم،يوفر Evolla رؤى دقيقة حول وظيفة البروتين.كل ما يحتاجه المستخدمون هو إدخال تسلسل وبنية البروتين، ثم طرح الأسئلة، مثل تقديم الوظيفة الأساسية أو النشاط التحفيزي للبروتين، والنقر ببساطة على زر، وسوف يقوم Evolla بإنشاء وصف مفصل يتكون من حوالي 200-500 كلمة.
عنوان استخدام Evolla:
http://www.chat-protein.com/
عنوان ورقة Evolla:
https://www.biorxiv.org/content/10.1101/2025.01.05.630192v2

ومن الجدير بالذكر أن بيانات التدريب وقوة الحوسبة المطلوبة لمشروع Evolla هائلة. لقد أمضى اثنان من طلاب الدكتوراه لدينا ما يقرب من عام في جمع ومعالجة بيانات التدريب. وفي النهاية، تمكنا من توليد أكثر من 500 مليون زوج من النصوص البروتينية عالية الجودة من خلال البيانات الاصطناعية، والتي تغطي مئات المليارات من رموز الكلمات. النموذج دقيق جدًا في التنبؤ بوظائف الإنزيم.ولكن هناك حتما بعض مشاكل الوهم.
عن الفريق
يشارك الدكتور يوان فاجي من جامعة ويستليك بشكل أساسي في البحث العلمي التطبيقي المتعلق بالتعلم الآلي التقليدي والموضوعات متعددة التخصصات، ويركز على استكشاف نماذج الذكاء الاصطناعي الكبيرة وعلم الأحياء الحسابي. لقد نشر أكثر من 40 ورقة أكاديمية في مؤتمرات ومجلات مرموقة في مجال التعلم الآلي والذكاء الاصطناعي (مثل NeurIPS، ICLR، SIGIR، WWW، TPAMI، Molecular Cell، إلخ). للحصول على معلومات مفصلة حول أعضاء الفريق والمساهمين في المشروع، يرجى الرجوع إلى الورقة.
لقد قامت مجموعة البحث بإجراء أبحاث طويلة الأمد في مجالات التعلم الآلي والذكاء الاصطناعي + المعلوماتية الحيوية. نرحب بكم لتقديم طلبات التوظيف لطلاب الدكتوراه، ومساعدي الباحثين، وزملاء ما بعد الدكتوراه، ومناصب الباحثين في مجموعة البحث. يرحب بالطلاب بزيارة المختبر للتدريب. يمكن للأطراف المهتمة إرسال سيرتهم الذاتية إلى [email protected].








