Command Palette
Search for a command to run...
من خلال محاكاة استشارة الطبيب، قام فريق من مستشفى غرب الصين بجامعة سيتشوان بتطوير إطار عمل للحوار متعدد العوامل للمساعدة في تشخيص المرض

إن معدل انتشار الأمراض النادرة منخفض، والمعرفة المهنية ذات الصلة نادرة. بالإضافة إلى ذلك، فإن الأعراض الفردية معقدة ومتغيرة، وبالتالي فإن التشخيص الخاطئ والتأخر في التشخيص يحدثان في كثير من الأحيان. في السنوات الأخيرة، حققت نماذج اللغة الكبيرة (LLMs) مثل GPT-4 أداءً جيدًا في الإجابة على الأسئلة الطبية وتشخيص الأمراض الشائعة، ولكنها لا تزال تواجه تحديات في المهام السريرية المعقدة مثل الأمراض النادرة.من أجل تحسين قدرات التطبيق العملي لطلاب الماجستير في القانون في المجال الطبي، بدأ بعض الباحثين في استكشاف تطبيق أنظمة متعددة الوكلاء (MAS).
الوكيل الذكي هو نظام يمكنه استقبال المدخلات وإجراء عمليات محددة من أجل تحقيق هدف معين. على سبيل المثال، عندما نتواصل مع ChatGPT بشأن حالتنا الطبية، فإننا في الواقع نجري محادثة مع وكيل واحد.في المقابل، يحقق النظام متعدد الوكلاء تشخيصًا أكثر ديناميكية وتفاعلية من خلال الحوار متعدد الوكلاء (MAC). يحاكي هذا النموذج آلية مناقشة الفريق متعدد التخصصات (MDT) في الممارسة السريرية، مما يسمح لعدة وكلاء بمناقشة وتحليل نفس الحالة، وإخراج نتائج التشخيص بعد التوصل إلى إجماع.
في الآونة الأخيرة، شاركت فرق من مستشفى غرب الصين التابع لجامعة سيتشوان، ومركز البيانات الطبية الحيوية غرب الصين، وكلية الطب بجامعة تشجيانغ، وجامعة بكين للبريد والاتصالات، وغيرها.تم تطوير إطار عمل حوار متعدد الوكلاء (MAC) استنادًا إلى GPT-3.5 و GPT-4 على التوالي.يتكون الإطار من وكيل إداري ووكيل مشرف ووكلاء أطباء متعددين، والذين يشاركون بشكل مشترك في تحليل حالات المرضى. أفضل تكوين لنظام MAC هو استخدام GPT-4 كنموذج أساسي ويتكون من 4 وكلاء دكتور ووكيل مشرف واحد.
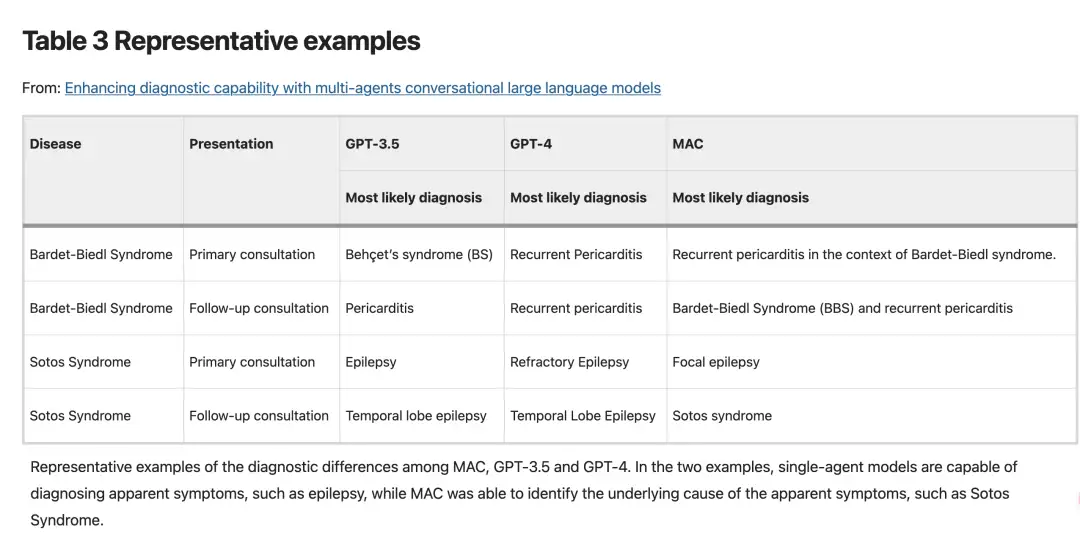
يتوفر تقييم لأداء GPT-3.5 و GPT-4 و MAC في التفكير السريري وتوليد المعرفة الطبية لـ 302 مرض نادر.تفوقت MAC على نموذج الوكيل الفردي في كل من المرحلة الأولية ومرحلة المتابعة.علاوة على ذلك، فإن القدرات التشخيصية لـ MAC تتجاوز الأساليب مثل مطالبات سلسلة الفكر (CoT)، والتحسين الذاتي، والاتساق الذاتي.يمكن إخراج محتوى تشخيصي أكثر ثراءً.على سبيل المثال، يمكن لاختبارات GPT-3.5 وGPT-4 تحديد التهاب التامور والصرع على أساس العرض السريري، ولكن اختبار MAC، من خلال تحليل أكثر تعمقًا للحوار المشترك، يمكن أن يحدد أن التهاب التامور في حالة معينة ناجم عن متلازمة بارديت-بيدل.
وفي الختام، يعمل برنامج MAC على تحسين القدرة التشخيصية لحاملي شهادات الماجستير في القانون بشكل كبير، ويسد الفجوة بين المعرفة النظرية والممارسة السريرية، ومن المتوقع أن يصبح أداة مساعدة مهمة للأطباء.نُشرت الدراسة، التي تحمل عنوان "تعزيز القدرة التشخيصية باستخدام نماذج لغة كبيرة محادثة متعددة العوامل"، في مجلة npj Digital Medicine، وهي مجلة تابعة لـ Nature.

عنوان الورقة:
https://www.nature.com/articles/s41746-025-01550-0#Tab6
يجمع مشروع المصدر المفتوح "awesome-ai4s" أكثر من 200 تفسير لورقة AI4S ويوفر مجموعات بيانات وأدوات ضخمة:
https://github.com/hyperai/awesome-ai4s
مجموعة البيانات: فحص 302 مرضًا نادرًا
قامت هذه الدراسة بفحص 302 مرضًا نادرًا من قاعدة بيانات Orphanet كأشياء بحثية. قاعدة بيانات Orphanet هي قاعدة بيانات شاملة للأمراض النادرة تم تمويلها بالاشتراك مع المفوضية الأوروبية، وتغطي أكثر من 7000 مرض من 33 نوعًا.
تنزيل مجموعة البيانات الخاصة بـ 302 حالة مرض نادر:
https://go.hyper.ai/EETet
بعد تحديد المرض المستهدف، بحث فريق البحث في قاعدة بيانات Medline عن تقارير الحالات السريرية المنشورة بعد يناير 2022. ومن خلال استخراج البيانات المنظمة من هذه التقارير، جمعنا معلومات مفصلة عن التركيبة السكانية للمريض، والمظاهر السريرية، والتاريخ الطبي، ونتائج الفحص البدني، ونتائج الفحوصات المساعدة المختلفة (بما في ذلك الاختبارات الجينية، والخزعة المرضية، والفحوصات الإشعاعية)، وسجلنا معلومات التشخيص النهائي.
لتقييم قيمة تطبيق نماذج اللغة الكبيرة (LLM) بشكل شامل في الإعدادات السريرية، صمم فريق البحث تجربة محاكاة للتشاور السريري من مرحلتين، حيث تم اختبار كل حالة في إعدادات الاستشارة الأولية والاستشارة المتابعة:
* المرحلة الأولى تحاكي سيناريو الاستشارة الأولية (التشخيص الأولي)،الهدف الرئيسي هو التحقيق في أداء LLM في المرضى الذين يعانون من أعراض لأول مرة ولديهم معلومات سريرية محدودة. تتمثل مهمة طلاب الماجستير في القانون في الوصول إلى التشخيص الأكثر احتمالاً، والعديد من التشخيصات المحتملة، وتشخيصات أخرى.
* المرحلة الثانية تحاكي سيناريو الاستشارة المتابعة (إعادة الفحص).لتقييم القدرة التشخيصية لـ LLM بعد الحصول على معلومات كاملة عن المريض (بما في ذلك نتائج الفحوصات المختلفة). تتمثل مهمة طلاب الماجستير في القانون في الوصول إلى تشخيص واحد محتمل والعديد من التشخيصات المحتملة.
لا يمكن لتصميم الدراسة المرحلية هذه اختبار قدرة الحكم الأولية لـ LLM في ظل ظروف المعلومات غير المكتملة فحسب، بل يمكنه أيضًا تقييم المنطق الطبي ودقة التشخيص النهائي بشكل منهجي بعد إتقان البيانات السريرية بالكامل، وبالتالي يعكس بشكل شامل إمكانات التطبيق العملي لـ LLM في دعم القرار السريري.

حقق إطار عمل MAC المستند إلى GPT-4 مع 4 Doctor Agents أفضل أداء
وباستخدام الهيكل الذي توفره Autogen، قام فريق البحث بتطوير إطارين للمحادثة متعددة الوكلاء (MAC) يعتمدان على GPT-3.5-turbo وGPT-4 لمحاكاة استشارات الطبيب. كما هو موضح في الشكل أدناه،يقوم وكيل الإدارة بتزويد المريض بمعلومات، ويقوم وكيل المشرف ببدء المحادثة المشتركة والإشراف عليها، ويقوم وكلاء الأطباء الثلاثة بمناقشة حالة المريض معًا.يستمر الحوار حتى يصل الوكلاء إلى إجماع أو يتم الوصول إلى الحد الأقصى المحدد مسبقًا لعدد جولات الحوار (المحدد بـ 13 جولة في هذه الدراسة)، ويتم إخراج نتيجة التشخيص النهائية.
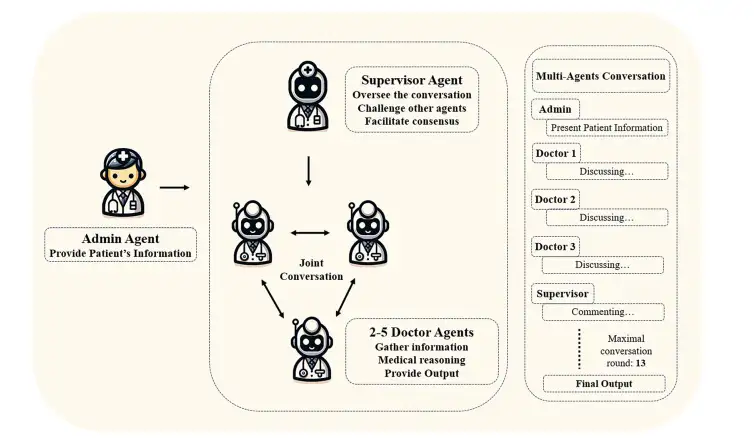
يلعب وكيل الإشراف دور مراقبة الجودة وتحسين العمليات.وتشمل مسؤولياتها: (1) الإشراف على التوصيات والقرارات التي يتخذها وكلاء الأطباء وتقييمها؛ (2) مراجعة خطط التشخيص وعناصر الفحص المقترحة لتحديد النقاط الرئيسية التي قد يتم تفويتها؛ (3) تنسيق المناقشات بين وكلاء الأطباء لتعزيز تحسين خطط التشخيص؛ (4) تشجيع وكلاء الأطباء على التوصل إلى توافق في الآراء بشأن التشخيص النهائي وخطة الفحص؛ (5) إنهاء عملية الحوار في الوقت المناسب بعد التوصل إلى توافق في الآراء.
تشمل مسؤوليات وكلاء الأطباء ما يلي:(1) تقديم الاستدلال التشخيصي والمشورة السريرية على أساس المعرفة الطبية المهنية؛ (2) تقييم آراء الوكلاء الآخرين والتعليق عليها بشكل منهجي وتقديم الحجج والأدلة العلمية والمعقولة؛ (3) دمج وتحسين ردود الفعل من الوكلاء الآخرين لتحسين الناتج التشخيصي بشكل مستمر.
وباستخدام تقارير الحالات السريرية الحقيقية من قاعدة بيانات Medline، قام الباحثون بتقييم المعرفة والقدرات التشخيصية لـ GPT-3.5 وGPT-4 وMAC لـ 302 مرض نادر. بالإضافة إلى ذلك، تمت دراسة تأثير الإعدادات المختلفة على أداء MAC.
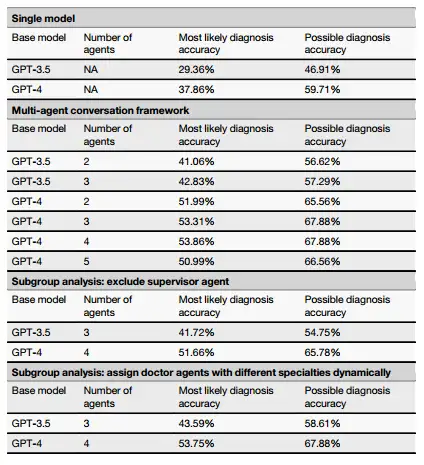
على سبيل المثال، قام فريق البحث بمقارنة الاختلافات في الأداء عندما استخدم إطار عمل MAC GPT-4 وGPT-3.5 كنموذج أساسي.تظهر النتائج أن MAC الذي يستخدم GPT-3.5 أو GPT-4 كنموذج أساسي يعمل بشكل أفضل بكثير من إصداراتهما المستقلة. وبعبارة أخرى، تم تعزيز القدرة التشخيصية لـMAC بشكل كبير مقارنة بنموذج العامل الفردي.علاوة على ذلك، عند استخدامه كنموذج أساسي لـ MAC، فقد ثبت أن GPT-4 يتفوق على GPT-3.5، مما يعني أن النموذج الأساسي الأكثر قوة قد يؤدي إلى أداء أفضل بشكل عام.
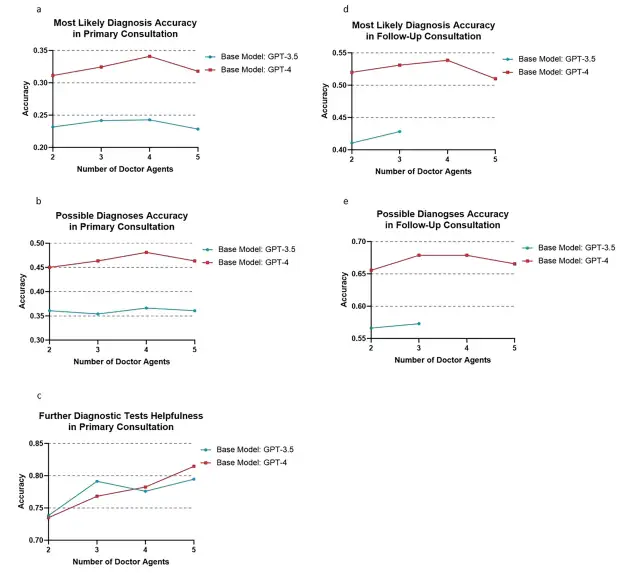
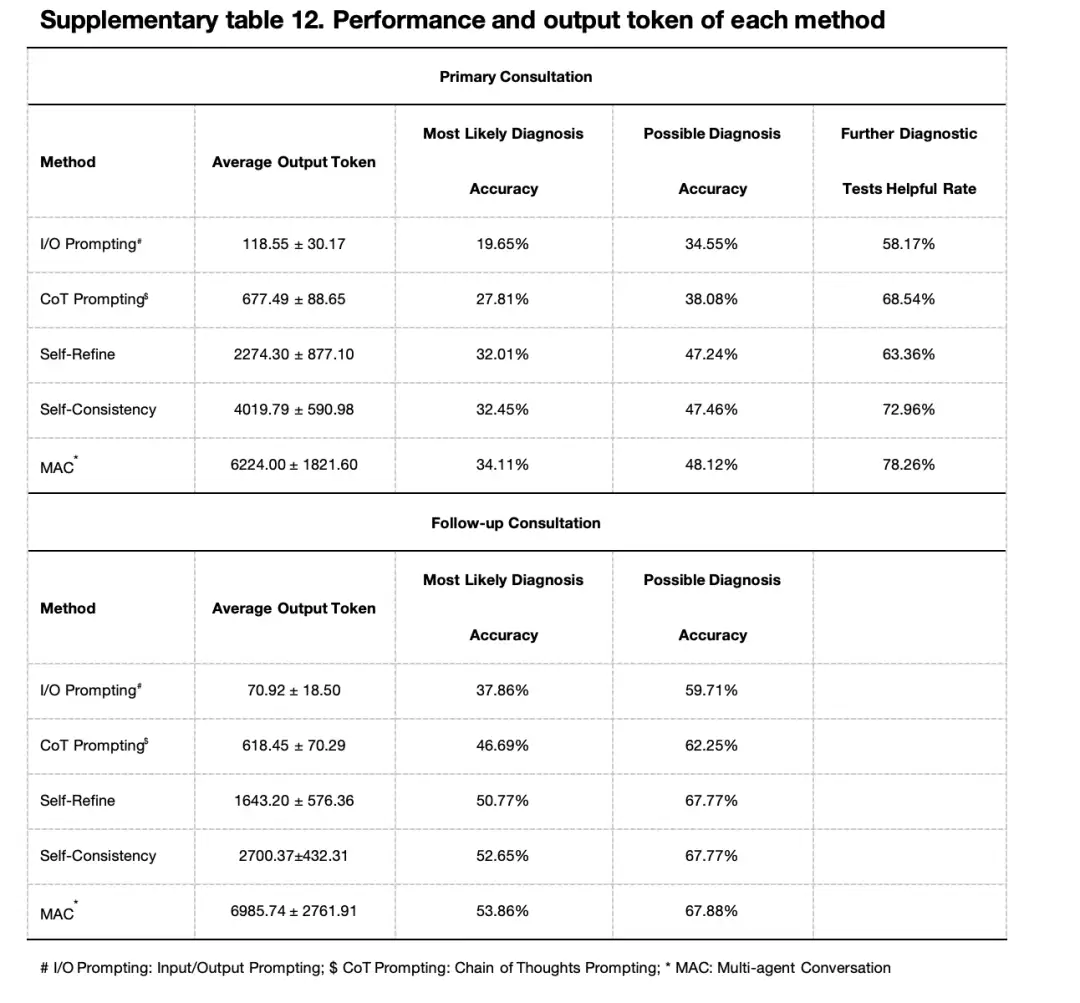
أيضًا،قام الباحثون أيضًا بدراسة تأثير عدد وكلاء الأطباء على أداء إطار العمل متعدد الوكلاء.وأظهرت النتائج التجريبية المبنية على نموذج GPT-4 أنه من حيث دقة التشخيص الأكثر احتمالا، فقد وصلت إلى ذروة 34.11% مع 4 عوامل، في حين انخفضت قليلا إلى 31.79% مع 5 عوامل. وقد لوحظ نمط مماثل في دقة التشخيص المحتمل، حيث بلغت دقة العوامل 2 و3 و4 و5 51.99% و53.31% و53.86% و50.99% على التوالي. وفي التجربة التي تعتمد على نموذج GPT-3.5، أظهر وكلاء الأطباء الأربعة أيضًا أفضل أداء. ومع ذلك، بشكل عام، فإن أداء 3 وكلاء لا يختلف كثيرا عن أداء 4 وكلاء.
علاوة على ذلك، في سيناريو محاكاة التشاور الأولي الذي يتضمن أربعة وكلاء الأطباء،حقق إطار عمل MAC القائم على GPT-4 أداءً أفضل في العديد من المؤشرات الرئيسية: وصلت دقة التشخيص الأكثر احتمالاً إلى 34.11% (GPT-3.5 هو 24.28%)، ووصلت دقة التشخيص المحتمل إلى 48.12% (GPT-3.5 هو 36.64%)، ووصلت فائدة اختبارات التشخيص الإضافية إلى 78.26% (GPT-3.5 هو 77.37%). ومن حيث الأداء التشخيصي في الاستشارات المتابعة، حقق إطار عمل MAC القائم على GPT-4 بمشاركة 4 وكلاء أطباء أيضًا أفضل أداء.
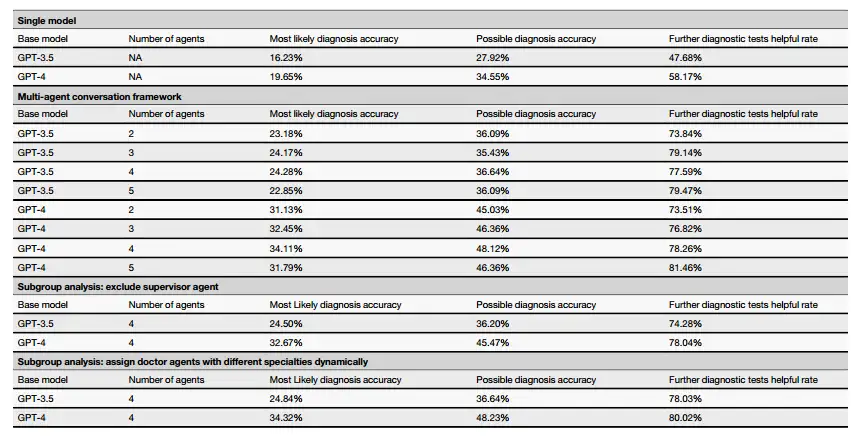
قام الباحثون أيضًا بتقييم التأثير المحتمل لإزالة وكيل المشرف على الأداء العام لـ MAC. تظهر النتائج أنه عند إزالة وكيل المشرف، في سيناريو الاستشارة الأولية الذي تم محاكاته باستخدام 4 وكلاء طبيب،كانت بيانات إطار عمل MAC المستند إلى GPT-4 من حيث دقة التشخيص الأكثر احتمالاً ودقة التشخيص الممكنة ومدى فائدة الاختبارات التشخيصية الإضافية 32.67% و45.47% و78.04% على التوالي، وهي كلها أقل مما كانت عليه عندما لم تتم إزالتها.في سيناريو الاستشارة المتابعة، كان إطار عمل MAC مع إزالة وكيل المشرف أقل دقة في التشخيص المحتمل ودقة التشخيص المحتملة مقارنةً بحالة عدم إزالته.يوضح هذا أن وكيل المشرف يحسن فعالية الإطار.
الاستنتاج التجريبي: يمكن لـ MAC تحديد السبب الجذري للمرض بشكل مباشر ولديه قدرات تشخيصية أقوى
قام فريق البحث بتقييم أداء أطر GPT-3.5 و GPT-4 و MAC في توليد المعرفة حول الأمراض النادرة، بما في ذلك تعريف المرض، وعلم الأوبئة، والخصائص السريرية، وعلم الأسباب، وطرق التشخيص، والتشخيص التفريقي، والتشخيص قبل الولادة، والاستشارة الوراثية، وإدارة العلاج والتشخيص. وتظهر النتائج أن هذه النماذج تحقق أداء جيدا في جميع أبعاد التقييم، حيث تجاوزت الدرجات 4 نقاط لكل مؤشر، كما هو موضح في الشكل أدناه. أيضًا،وقد أظهروا مستويات عالية من دقة المحتوى (المحتوى غير المناسب/غير الصحيح)، واكتمال المعلومات (الإغفالات)، والسلامة (احتمالية وحجم الضرر المحتمل)، والموضوعية (التحيز).
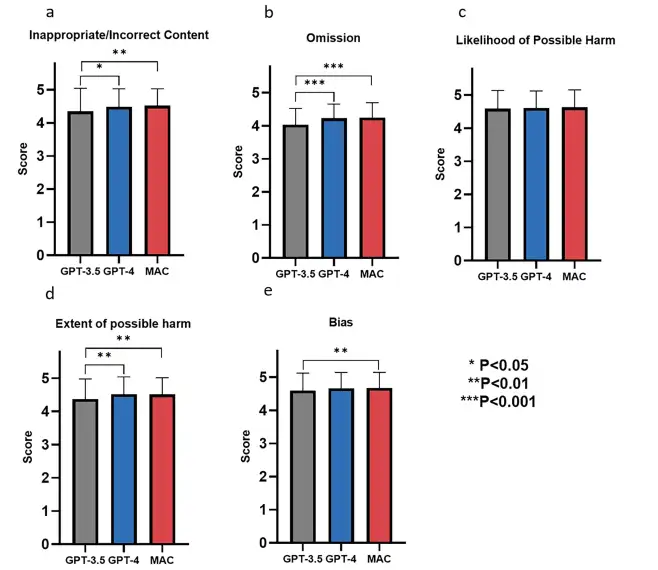
وفي تشخيص حالات مرضية محددة، كما هو موضح في الشكل أدناه، وجد الباحثون أن GPT-3.5 وGPT-4 كانا قادرين على تشخيص الأمراض بناءً على أعراض واضحة، مثل تحديد التهاب التامور والصرع من خلال المظاهر السريرية، إلا أنهما لم يكونا كافيين في استكشاف الأسباب الجذرية للمرض.في المقابل، يوفر إطار MAC تحليلًا أكثر عمقًا من خلال الحوار المشترك، والذي يمكن أن يحدد أن التهاب التامور في حالة معينة ناجم عن متلازمة بارديت-بيدل.
قام الباحثون بمقارنة MAC مع إشارات الإدخال/الإخراج (I/O)، وإشارات سلسلة الأفكار (CoTs)، والتحسين الذاتي، وطرق الاتساق الذاتي. كما هو موضح في الشكل أدناه،في كل من الاستشارات الأولية والمتابعة، كان أداء MAC هو الأفضل من حيث التشخيص الأكثر احتمالا، والتشخيص المحتمل، وفعالية الاختبارات التشخيصية الإضافية.
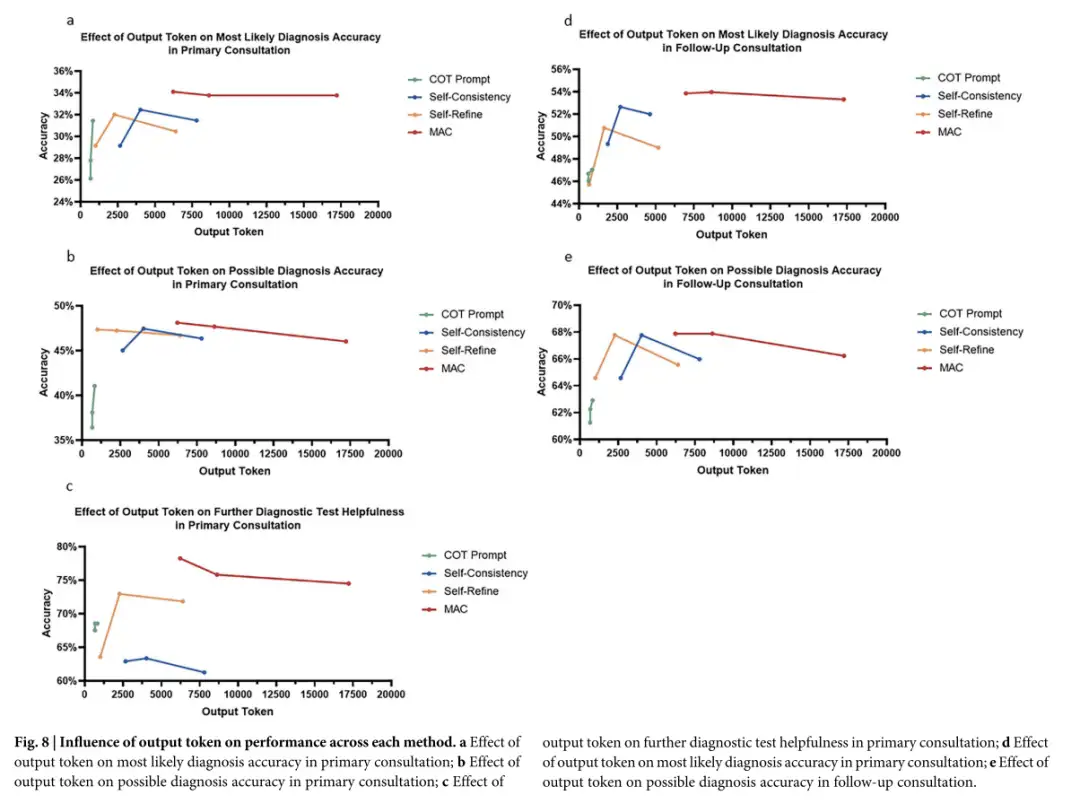
بالإضافة إلى ذلك، يقوم MAC بإخراج المزيد من الرموز. إن زيادة الإنتاج لا تساعد فقط في استكشاف مسارات التفكير المختلفة، بل تجعل من الممكن أيضًا التفكير في المخرجات السابقة وتصحيحها، مما قد يزيد من عمق التحليل ويحسن القدرة على تحديد الأسباب الجذرية للأمراض المهملة. ومع ذلك، تظهر الأبحاث أيضًا أنعلى الرغم من أن زيادة عدد مكالمات LLM وبالتالي توليد المزيد من الرموز يمكن أن يؤدي إلى تحسين أداء MAC، إلا أن حجم هذا التحسين يقتصر على نوع المهمة وطريقة التحسين المستخدمة.
باختصار، نجحت هذه الدراسة في تطوير إطار حوار متعدد العوامل (MAC) لتشخيص المرض، والذي يمكن أن يوفر اقتراحات تشخيصية قيمة ويوصي بمزيد من التشخيص في مراحل مختلفة من الاستشارة السريرية، وهو قابل للتطبيق على جميع أنواع الأمراض النادرة. بالإضافة إلى ذلك، بالمقارنة مع الأساليب الحالية مثل سلسلة الفكر (CoT)، والتحسين الذاتي والاتساق الذاتي،لا يتمتع MAC بدقة تشخيصية أعلى فحسب، بل يولد أيضًا محتوى تشخيصيًا أكثر ثراءً وشاملاً.يعمل هذا الإطار على تحسين قدرات التشخيص السريري للنماذج اللغوية الكبيرة بشكل كبير.
تتمتع أنظمة الوكلاء المتعددين بإمكانيات كبيرة للتطبيق في المجال الطبي
وفي السنوات الأخيرة، أظهرت أنظمة الوكلاء المتعددين تقدماً واعداً في مجال اتخاذ القرارات الطبية والتشخيص. وقد ظهرت العديد من الأطر المهمة واعتمدت استراتيجيات مختلفة لاستخدام نماذج اللغة الكبيرة لأداء المهام السريرية. على سبيل المثال، اقترحت جامعة شنغهاي جياو تونغ مشروع MedAgents، وهو إطار عمل للتعاون متعدد التخصصات في المجال الطبي. يتيح هذا الإطار للوكلاء المعتمدين على LLM إجراء جولات متعددة من المناقشات التعاونية في بيئة لعب الأدوار، مما يعزز بشكل كبير أداء LLM في الإجابة على الأسئلة الطبية بدون عينة. نُشر البحث على arXiv تحت عنوان "MedAgents: نماذج اللغة الكبيرة كمتعاونين في التفكير الطبي بدون حقن".
عنوان الورقة:
https://arxiv.org/abs/2311.10537
يختلف عن MedAgents والمنصات الأخرى التي تركز على الأسئلة والأجوبة الطبية،يركز إطار عمل MAC على المهام التشخيصية، مما يدفع العديد من الوكلاء إلى التحليل والمناقشة التفاعلية وتقديم اقتراحات تشخيصية مفتوحة في نفس السياق السريري.من حيث تصميم بنية الوكيل الذكي، يحتوي MAC على وكلاء Doctor متعددين ووكيل مشرف، بينما تعتمد الأطر الأخرى إعدادات مختلفة، مثل إنشاء وكلاء منفصلين للأسئلة والأجوبة. وتختلف الأطر أيضًا في كيفية التوصل إلى الإجماع. على سبيل المثال، يقوم MedAgents بشكل مستمر بتحسين إجاباتهم من خلال المراجعات التكرارية حتى يصل جميع الخبراء إلى إجماع، بينما يتم تحديد MAC بواسطة وكيل المشرف عندما يصل وكلاء الطبيب إلى إجماع كافٍ.
وعلى الرغم من أن هذه الأنظمة متعددة العوامل لها خصائصها الخاصة في التكوين والأهداف، إلا أنها تتمتع بإمكانات كبيرة للتطبيق في المجال الطبي، ولا يزال هناك حاجة إلى مزيد من البحث في المستقبل لاستكشاف دورها الفعلي في البيئات السريرية وتحسينه بشكل كامل.
يركز فريق البحث في إطار الحوار متعدد الوكلاء المذكور أعلاه على الاستكشاف المتطور في تقاطع الذكاء الاصطناعي التوليدي والطب السريري.ويحتوي المركز على موارد غنية بالبيانات السريرية ومرافق أجهزة الكمبيوتر المتقدمة، وقد نُشرت نتائج أبحاثه في مجلات أكاديمية دولية رفيعة المستوى.
ويلتزم الفريق بالتطبيق العملي لتكنولوجيا الذكاء الاصطناعي وتحويل نموذج التشخيص والعلاج الطبي السريري والنظام البيئي بشكل حقيقي. ونحن ندعو المؤسسات الأكاديمية والشركات بصدق إلى تنفيذ التعاون في المشروع. نرحب بطلبة الدراسات العليا المتميزين المهتمين بهذا المجال للتقديم. وفي الوقت نفسه، نقوم بتجنيد مساعدي الأبحاث العلمية المتحمسين للانضمام إلى الفريق. يمكن للأطراف المهتمة الاتصال بـ [email protected].








