Command Palette
Search for a command to run...
تعمل الكاميرا الافتراضية المستقرة على إعادة تعريف إنشاء المحتوى ثلاثي الأبعاد وتفتح أبعادًا جديدة للصور؛ يساعد تطبيق BatteryLife على التنبؤ بعمر البطارية بشكل أكثر دقة

في المنافسة الشرسة لإنشاء المحتوى الرقمي، تقف شركة Stability AI عند مفترق طرق المصير. هذه الشركة، التي أشعلت ثورة في مجال توليد الصور بتقنية Stable Diffusion، وقعت في أزمة بسبب مشاكل في الإدارة العليا. أطلقت شركة Stability AI مؤخرًا نموذج Stable Virtual Camera. أتساءل عما إذا كان بإمكانه كسر الجمود بضربة قوية.
الكاميرا الافتراضية المستقرة هي نموذج انتشار متعدد المشاهد، والذي يجمع بين قدرات التحكم في الكاميرا الافتراضية التقليدية وإبداع الذكاء الاصطناعي التوليدي. تقوم هذه التقنية بتحويل الصور العادية ثنائية الأبعاد إلى مقاطع فيديو ثلاثية الأبعاد ذات عمق ومنظور واقعي، دون الحاجة إلى إعادة بناء المشهد المعقد أو مهارات متخصصة.
بالمقارنة مع نماذج الفيديو ثلاثية الأبعاد التقليدية،لا يتطلب النموذج عددًا كبيرًا من صور الإدخال أو خطوات المعالجة المسبقة المعقدة، مما يجعل إنشاء المحتوى ثلاثي الأبعاد أسهل وأكثر جدوى.وتتمتع هذه التقنية بأداء جيد في معيار Novel View Synthesis (NVS).الأداء يتفوق على بعض النماذج الموجودة.
حاليًا، HyperAI Super Neural متصل بالإنترنت 「تتحول صور الكاميرا الافتراضية الثابتة إلى مقاطع فيديو ثلاثية الأبعاد في ثوانٍ」برنامج تعليمي، تعال وجربه~
الاستخدام عبر الإنترنت:https://go.hyper.ai/N2u9l
من 24 مارس إلى 28 مارس، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* اختيار المقالات المجتمعية: 3 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في أبريل: 10
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات لعب الأدوار CoSER
وتغطي مجموعة البيانات 17,966 شخصية و29,798 حوارًا حقيقيًا. إنه لا يتضمن فقط لمحات عامة عن الشخصيات والحوارات، بل يوفر أيضًا محتوى غنيًا مثل ملخصات الحبكة وتجارب الشخصيات وخلفيات الحوار. بالإضافة إلى ذلك، يغطي محتوى الحوار ثلاثة أبعاد: اللغة والفعل والفكر، مما يجعل أداء الشخصية أكثر ثلاثية الأبعاد.
الاستخدام المباشر:https://go.hyper.ai/1WbXV

2. مجموعة بيانات شرح الاستدلال الرياضي MV-MATH
تحتوي مجموعة بيانات MV-MATH على 2009 مسألة رياضية عالية الجودة، مقسمة إلى ثلاثة أنواع: أسئلة الاختيار من متعدد، وأسئلة ملء الفراغات، وأسئلة متعددة الخطوات. تحتوي مجموعة البيانات على مشاهد بصرية متعددة، وكل سؤال مزود بما يتراوح بين 2 إلى 8 صور. تتشابك هذه الصور مع النصوص لتشكيل مشاهد معقدة متعددة المرئيات، وهي أقرب إلى المشاكل الرياضية في العالم الحقيقي ويمكنها تقييم قدرة النموذج على التفكير في معالجة المعلومات متعددة المرئيات بشكل فعال.
الاستخدام المباشر:https://go.hyper.ai/tRQsA
3. مجموعة بيانات المشاهد متعددة المشاهد WideRange4D
تملأ مجموعة البيانات هذه الفجوة في مجموعات بيانات إعادة بناء رباعية الأبعاد الموجودة في المشاهد الديناميكية المعقدة من خلال تقديم بيانات مشهد رباعي الأبعاد مع نطاق كبير من الحركة المكانية. ويتميز بثراء المشهد وتعقيد الحركة والتنوع البيئي، بما في ذلك مشاهد العالم الحقيقي (مثل شوارع المدينة والطرق الريفية) والمشاهد الافتراضية، التي تغطي الحركات قصيرة المسافة ومتوسطة المسافة وطويلة المسافة، بالإضافة إلى مسارات الحركة المعقدة، بينما تحاكي أيضًا مجموعة متنوعة من الظروف الجوية مثل الأيام المشمسة والأيام الممطرة والعواصف الرملية.
الاستخدام المباشر:https://go.hyper.ai/9KszI
4. مجموعة بيانات اللمس متعددة الوسائط والمستشعرات TacQuad
TacQuad عبارة عن مجموعة بيانات لمسية متعددة الوسائط ومتوافقة ومتعددة المستشعرات تم جمعها من 4 أنواع من أجهزة الاستشعار اللمسية البصرية (GelSight Mini وDIGIT وDuraGel وTac3D). إنه يوفر حلاً أكثر شمولاً للتوحيد القياسي المنخفض لأجهزة الاستشعار اللمسية البصرية من خلال توفير بيانات محاذاة متعددة المستشعرات مع النصوص والصور المرئية. يتيح هذا بشكل صريح للنموذج تعلم السمات اللمسية على المستوى الدلالي والميزات المستقلة عن المستشعر، وبالتالي تشكيل مساحة تمثيل موحدة متعددة المستشعرات من خلال نهج قائم على البيانات.
الاستخدام المباشر:https://go.hyper.ai/uL0Zd

5. مجموعة بيانات فيديو حول الذكاء الاصطناعي الفيزيائي والروبوتات والقيادة الذاتية
هذه المجموعة من البيانات هي مجموعة بيانات الذكاء الاصطناعي المادية التي أصدرتها NVIDIA في مؤتمر GTC25. يحتوي على 15 تيرابايت من البيانات، وأكثر من 320 ألف مسار لتدريب الروبوت، وما يصل إلى 1000 أصل لوصف المشهد العام (OpenUSD)، بما في ذلك مجموعة SimReady، التي تغطي أنواعًا مختلفة من الطرق والبيئات الجغرافية، والبنى التحتية المختلفة، وبيئات الطقس المختلفة.
الاستخدام المباشر:https://go.hyper.ai/LEHa5

6. صور المناظر الطبيعية الجوية - مجموعة بيانات المناظر الطبيعية الجوية
Skyview هي مجموعة بيانات مختارة لتصنيف المناظر الطبيعية الجوية، تحتوي على ما مجموعه 12 ألف صورة، و15 فئة مختلفة، وكل فئة تحتوي على 800 صورة عالية الجودة بدقة 256×256 بكسل. تقوم مجموعة البيانات هذه بدمج الصور من مجموعات البيانات AID وNWPU-Resisc45 المتاحة للجمهور. يهدف هذا التجميع إلى تعزيز البحث والتطوير في مجال الرؤية الحاسوبية، وخاصة في تحليل المناظر الطبيعية الجوية.
الاستخدام المباشر:https://go.hyper.ai/mne9z

7. مجموعة بيانات فيديو حوادث القيادة EMM-AU
تُعد مجموعة البيانات هذه أول مجموعة بيانات مصممة خصيصًا لمهام تفسير حوادث القيادة، وهي توسع مجموعة بيانات MM-AU من خلال الاستفادة من تقنيات إنشاء الفيديو المتقدمة وتحسينه. تحتوي مجموعة البيانات على 2000 مقطع فيديو تفصيلي لمكان الحادث تم إنشاؤه حديثًا، والذي تم إنشاؤه عن طريق ضبط نموذج Open-Sora 1.2 المدرب مسبقًا، بهدف توفير بيانات تدريب أكثر ثراءً وتنوعًا لفهم الحوادث والوقاية منها.
الاستخدام المباشر:https://go.hyper.ai/gy0mb
8. مجموعة بيانات التنبؤ بعمر البطارية BatteryLife
تم إنشاء مجموعة البيانات هذه في الأصل لدعم الأبحاث المتعلقة بالتنبؤ بعمر البطارية. إنه يدمج 16 مجموعة بيانات مختلفة ويوفر أكثر من 90 ألف عينة من 998 بطارية، وكلها تحمل علامات العمر الافتراضي. تُعد مجموعة بيانات BatteryLife أكبر بمقدار 2.4 مرة من أكبر مورد لعمر البطارية السابق، BatteryML.
الاستخدام المباشر:https://go.hyper.ai/0PzfZ
9. مجموعة بيانات عينة صغيرة لطفرة بروتين VenusMutHub
VenusMutHub هي أول مجموعة بيانات صغيرة من الطفرات البروتينية لسيناريوهات التطبيق الحقيقية. قام فريق البحث بتجميع 905 مجموعات بيانات تجريبية صغيرة الحجم بعناية لسيناريوهات التطبيق الحقيقية، والتي تغطي 527 بروتينًا (منها 98% بروتينات تحتوي على 5-200 طفرة)، وتغطي مجموعة متنوعة من بيانات القياس الوظيفية مثل الاستقرار والنشاط وتقارب الارتباط والانتقائية. تم الحصول على جميع البيانات باستخدام القياسات الكيميائية الحيوية المباشرة بدلاً من قراءات الفلورسنت البديلة، مما يضمن دقة التقييم.
الاستخدام المباشر:https://go.hyper.ai/8y20R
10. الطيور مقابل الطائرات بدون طيار: مجموعة بيانات تصنيف صور الطيور والطائرات بدون طيار
تحتوي مجموعة البيانات هذه على مجموعة متنوعة من الصور من موقع Pexel، والتي تمثل الطيور والطائرات بدون طيار أثناء الحركة. يتم التقاط الصور من إطارات الفيديو، وتجزئتها، وتضخيمها، ومعالجتها مسبقًا لمحاكاة الظروف البيئية المختلفة، وبالتالي تعزيز عملية تدريب النموذج.
الاستخدام المباشر:https://go.hyper.ai/RdN4d
دروس تعليمية عامة مختارة
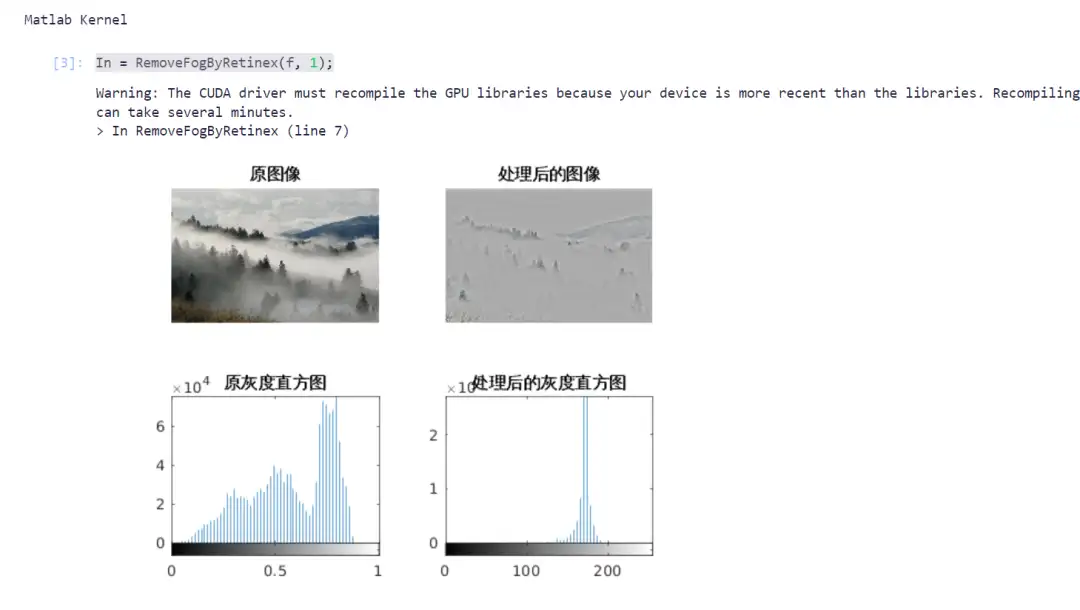
1. إزالة الضبابية من الصورة باستخدام MATLAB
في مجال الرؤية الحاسوبية، يعد إزالة الضبابية من الصور مهمة معالجة مسبقة مهمة، خاصة في القيادة الذاتية وتحليل الصور عن بعد وأنظمة المراقبة. يمكن أن يؤدي إزالة الضباب إلى تحسين جودة الصورة بشكل فعال وجعل الهدف أكثر وضوحًا.
يستخدم هذا المشروع خوارزمية Retinex لإزالة الضبابية من الصور ويجمعها مع تسريع وحدة معالجة الرسوميات لتحسين الكفاءة الحسابية. أدخل الكود المناسب وفقًا للبرنامج التعليمي لإكمال عملية إزالة الضبابية من الصورة.
تشغيل عبر الإنترنت:https://go.hyper.ai/wu1fE
2. تقوم الكاميرا الافتراضية المستقرة بتحويل الصور إلى مقاطع فيديو ثلاثية الأبعاد في ثوانٍ
الكاميرا الافتراضية المستقرة (Seva باختصار) هي نموذج انتشار عام أطلقته شركة Stability AI في مارس 2025. تتمكن Seva من إنشاء وجهات نظر جديدة للمشهد مع الأخذ في الاعتبار أي عدد من وجهات النظر المدخلة وكاميرات الهدف. يتغلب تصميمه على قيود الطرق الحالية في إنشاء عينات ذات اختلافات كبيرة في وجهة النظر أو عينات سلسة زمنياً، في حين لا يعتمد على تكوين مهمة محددة.
الميزة البارزة لهذا النموذج هي أنه يمكنه الحفاظ على توليد عينات متسقة للغاية دون الحاجة إلى تعلم تمثيل ثلاثي الأبعاد إضافي، وبالتالي تبسيط عملية تركيب المنظور في التطبيقات العملية. بالإضافة إلى ذلك، يمكن لـSeva إنشاء مقاطع فيديو عالية الجودة تصل مدتها إلى نصف دقيقة وتكرارها بسلاسة. تظهر اختبارات المقارنة الشاملة أن Seva يتفوق على الطرق الحالية على مجموعات البيانات والإعدادات المختلفة.
لقد تم نشر النماذج والتبعيات ذات الصلة بهذا المشروع. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/N2u9l

أطلق فريق Sesame نموذج توليد الكلام CSM (نموذج الكلام المحادثي) الذي يمكنه إخراج كلام سلس وطبيعي وعاطفي بناءً على إدخال النص والصوت. وبالمقارنة بنماذج توليد الكلام بالذكاء الاصطناعي التقليدية، يتمتع CSM بقدرات فهم عاطفية أقوى، وإيقاع محادثة أكثر طبيعية، وتفاعل في الوقت الفعلي بدون تأخير تقريبًا، ولا يوجد إحساس بالطائرات بدون طيار.
تشغيل عبر الإنترنت:https://go.hyper.ai/bxOoN
مقالات المجتمع
تستطيع خوارزمية التعلم العميق AcneDGNet التي طورها فريق مستشفى جامعة بكين الدولي تحديد آفات حب الشباب بدقة وتحديد شدتها تلقائيًا، بدقة تشخيصية تضاهي دقة كبار أطباء الجلد. إنه يوفر دعمًا قويًا للاستشارات عبر الإنترنت والعلاج الطبي غير المتصل بالإنترنت، مما يساعد على إدارة حب الشباب بشكل أكثر كفاءة. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/qAjYK
اقترح فريق بحثي من جامعة كامبريدج طريقة تسمى AlphaFold-Metainference. تستخدم هذه الطريقة الارتباط بين خريطة خطأ المحاذاة التي يتنبأ بها AlphaFold ومصفوفة تغيير المسافة في محاكاة الديناميكيات الجزيئية لبناء مجموعة هيكلية من البروتينات غير المنظمة والبروتينات التي تحتوي على مناطق غير منظمة، مما يوفر أفكارًا جديدة للتنبؤ بهياكل البروتين غير المنظمة بناءً على أساليب التعلم العميق، وتوسيع نطاق تطبيق AlphaFold بشكل أكبر. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/6Bbhc
أظهرت الدراسات أنه بعد ساعات طويلة من العمل مع الصور الطبية، يمكن أن يؤدي التعب البصري لدى المحترفين إلى حدوث أخطاء حدودية تصل إلى 12%. ولحل هذه المشكلة، تعاونت NVIDIA مؤخرًا مع فرق بحثية أخرى لاقتراح نموذج تقسيم الصور الطبية متعدد الوسائط VISTA3D. كان هذا النموذج رائداً في طريقة استخراج الميزات الفائقة ثلاثية الأبعاد، وحقق تحسينًا تعاونيًا للتجزئة التلقائية ثلاثية الأبعاد والتجزئة التفاعلية من خلال بنية موحدة. وفي اختبار معياري شامل شمل 23 مجموعة بيانات، تم تحسين دقة التجزئة بمقدار 5.2% مقارنة بنموذج الخبير الأمثل الحالي. وقد تم نشر النتائج ذات الصلة كنسخة أولية على arXiv. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/D19LU
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








