Command Palette
Search for a command to run...
أفضل لاعبي المصدر المفتوح يجتمعون معًا! يفتح QwQ-32B أوضاع لعب متعددة، ويقوم OpenManus ببناء وكلاء الذكاء الاصطناعي بتكلفة منخفضة! يتيح برنامج vLLM v1 إمكانية التفكير النموذجي بكفاءة

وفي خضم موجة الاختراقات المستمرة في مجال الذكاء الاصطناعي، نجح أحدث نموذج لفريق Qwen، QwQ-32B، بمعلماته البالغ عددها 32 مليار معلمة، في تجديد فهم الصناعة للنماذج الكبيرة مفتوحة المصدر مرة أخرى. وأظهر النموذج أداءً ممتازًا في مهام مثل إنشاء التعليمات البرمجية والحوار متعدد الجولات، كما أن قدرته على التفكير قابلة للمقارنة مع الإصدار الكامل من DeepSeek-R1.
منذ وقت ليس ببعيد،تم تصميم بنية vLLM الأساسية خصيصًا لتسريع التفكير في النماذج الكبيرة لتحديث كبير.من خلال تحسين حلقات التنفيذ والجداول الموحدة وذاكرة التخزين المؤقت للبادئات ذات التكلفة الزائدة الصفرية، فإنه يحقق تحسنًا في الأداء يصل إلى 1.7 مرة في الإنتاجية والزمن الكامن، مما يسمح بنشر QwQ-32B بكفاءة على بطاقات الرسومات A6000 ثنائية البطاقة.
في مجال AI Agent، اكتسب OpenManus زخمًا منذ إطلاقه. هذا المشروع مفتوح المصدر، المعروف باسم "بديل مانوس"،ولا يقتصر الأمر على الاستجابة للشكوك الخارجية بشأن النظام البيئي المغلق من خلال إعادة إنتاج التكنولوجيا، بل يوفر للمطورين أيضًا "مفتاحًا رئيسيًا" لبناء كيانات ذكية بتكلفة منخفضة من خلال التصميم المعياري وتكامل سلسلة الأدوات.
في الوقت الحاضر، أطلقت HyperAI برنامجين تعليميين: "استخدام vLLM لنشر QwQ-32B" و"OpenManus + QwQ-32B لتنفيذ AI Agent". تعال وجربها~
نشر QwQ-32B باستخدام vLLM
الاستخدام عبر الإنترنت:https://go.hyper.ai/8nPfC
OpenManus + QwQ-32B ينفذ AI Agent
الاستخدام عبر الإنترنت:https://go.hyper.ai/GIX1H
من 10 مارس إلى 15 مارس، تم تحديث الموقع الرسمي لـ hyper.ai بسرعة:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 4
* اختيار المقالات المجتمعية: 6 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في مارس: 4
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الرياضيات المعززة للتعلم الرياضي الكبير
Big-Math عبارة عن مجموعة بيانات رياضية عالية الجودة وواسعة النطاق مصممة لتطبيق التعلم المعزز (RL) في نماذج اللغة. تحتوي مجموعة البيانات على أكثر من 250 ألف مسألة رياضية عالية الجودة، ولكل منها إجابة يمكن التحقق منها.
الاستخدام المباشر:https://go.hyper.ai/qtlbQ
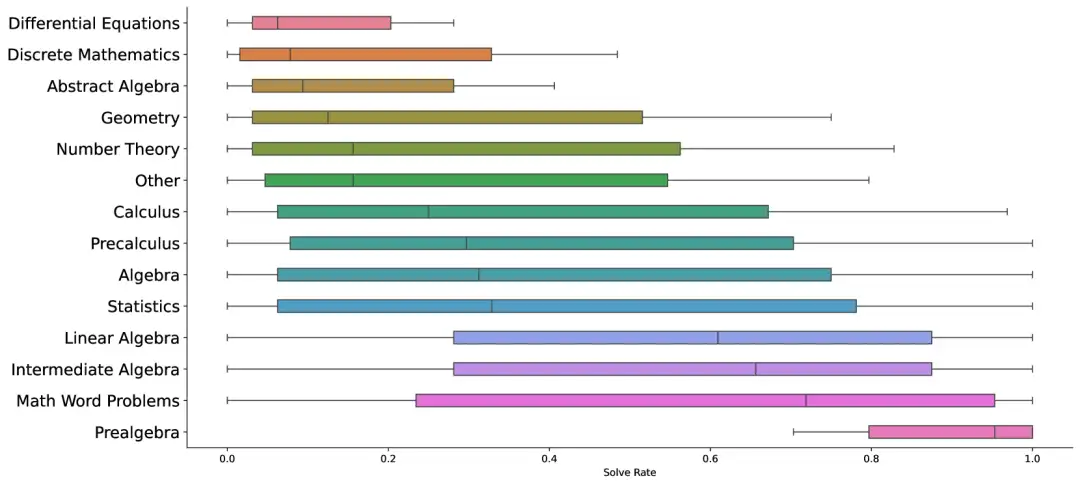
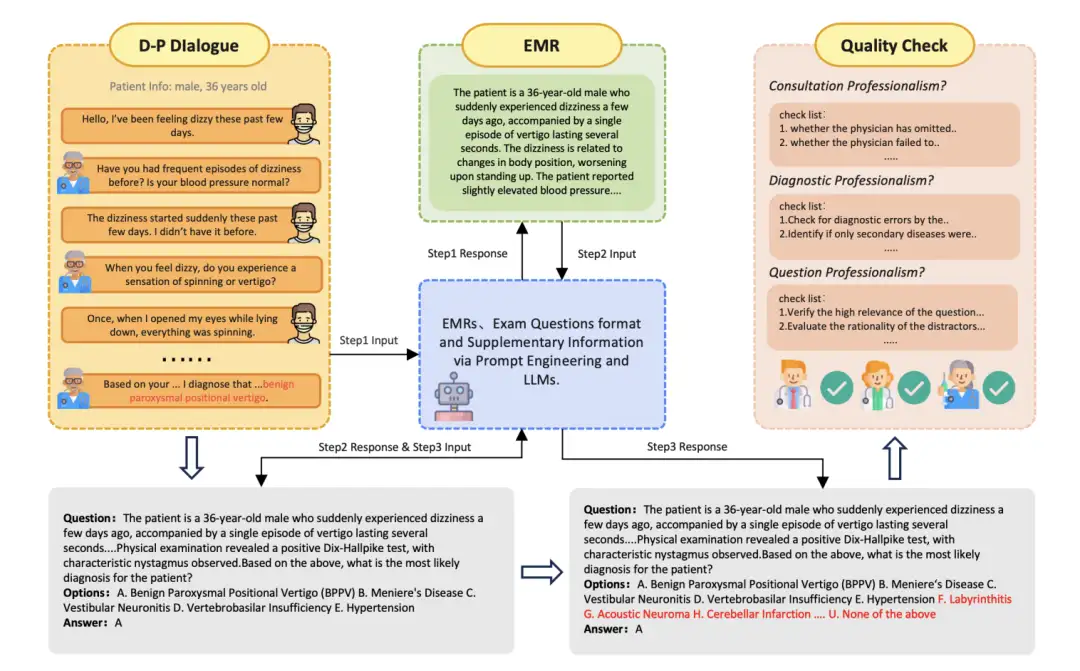
2. مجموعة بيانات JMED الطبية الصينية الحقيقية
مجموعة بيانات JMED هي مجموعة بيانات جديدة تعتمد على توزيع البيانات الطبية في العالم الحقيقي. يتم الحصول على مجموعة البيانات من محادثات مجهولة بين الطبيب والمريض في مستشفى JD Health على الإنترنت ويتم تصفيتها للاحتفاظ بالاستشارات التي تتبع سير عمل تشخيصي موحد.
الاستخدام المباشر:https://go.hyper.ai/FjZsa
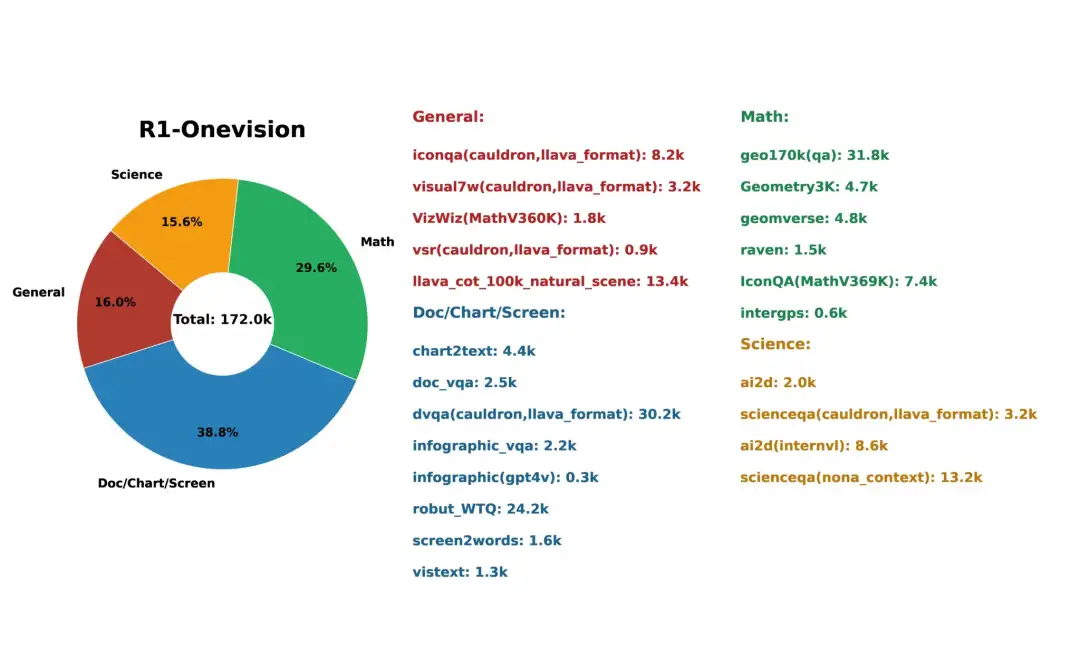
3. مجموعة بيانات الاستدلال متعدد الوسائط R1-Onevision
تم تصميم مجموعة بيانات R1-Onevision لتزويد النماذج بقدرات تفكير متعددة الوسائط متقدمة. ويعمل على سد الفجوة بين الفهم البصري والنصي من خلال مهام التفكير الغنية والواعية للسياق في مجالات متعددة مثل المشاهد الطبيعية والعلوم والمشكلات الرياضية والمحتوى القائم على التعرف الضوئي على الحروف والرسوم البيانية المعقدة.
الاستخدام المباشر:https://go.hyper.ai/jLbSI
4. مجموعة بيانات الاستدلال الطبيعي
مجموعة بيانات NaturalReasoning هي مجموعة بيانات استدلالية واسعة النطاق وعالية الجودة تحتوي على 2.8 مليون سؤال صعب تغطي مجالات متعددة مثل مجالات العلوم والتكنولوجيا والهندسة والرياضيات (مثل الفيزياء وعلوم الكمبيوتر) والاقتصاد والعلوم الاجتماعية وما إلى ذلك. تهدف مجموعة البيانات إلى توليد أسئلة استدلالية متنوعة وصعبة وإجاباتها المرجعية من خلال الاستفادة من مجموعات البيانات المدربة مسبقًا ونماذج اللغة الكبيرة (LLMs) دون الحاجة إلى تعليقات بشرية إضافية.
الاستخدام المباشر:https://go.hyper.ai/Mb6Cd
5. مجموعة بيانات مجموعة نواة AI-CUDA-Engineer-Archive
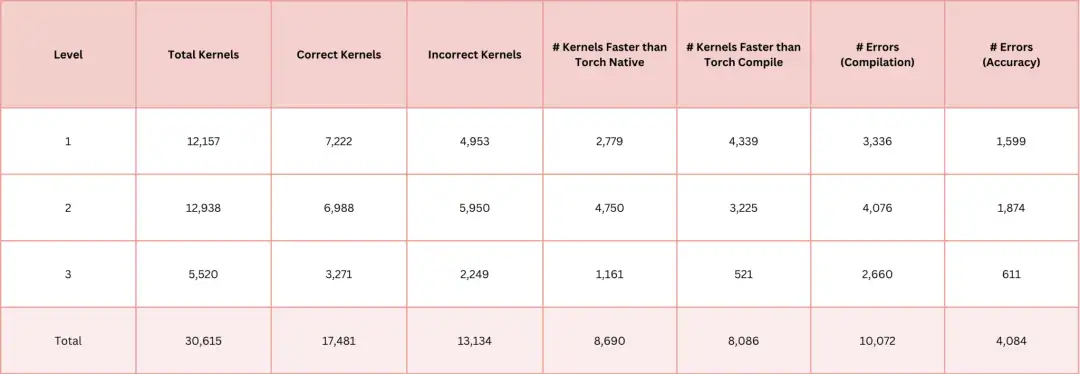
مجموعة بيانات AI-CUDA-Engineer-Archive عبارة عن مجموعة من نوى CUDA التي تم إنشاؤها بواسطة الذكاء الاصطناعي، والتي تهدف إلى تسهيل التدريب اللاحق للنماذج مفتوحة المصدر وتطوير وحدات وظيفة CUDA أفضل. تحتوي مجموعة البيانات على أكثر من 30000 نواة CUDA، والتي تم إنشاؤها جميعًا بواسطة مهندسي CUDA المعتمدين على الذكاء الاصطناعي، وقد تم التحقق من صحة أكثر من 17000 نواة منها، وحوالي 50% من النوى تتفوق على وقت التشغيل الأصلي لـ PyTorch.
الاستخدام المباشر:https://go.hyper.ai/3lPrI
6. مجموعة بيانات الكيمياء الكمومية QM9
مجموعة بيانات QM9 عبارة عن مجموعة بيانات كيمياء كمية مستخدمة على نطاق واسع، وتحتوي على نتائج حسابات كيمياء كمية لنحو 134 ألف جزيء عضوي صغير. تتكون هذه الجزيئات من عناصر الكربون والهيدروجين والنيتروجين والأكسجين والفلور، ويبلغ وزنها الجزيئي لا يزيد عن 900 دالتون.
الاستخدام المباشر:https://go.hyper.ai/PZdz7
7. مجموعة بيانات التكوين الجزيئي ثلاثية الأبعاد GEOM-Drugs
مجموعة بيانات GEOM-Drugs عبارة عن مجموعة بيانات كبيرة للتكوين الجزيئي ثلاثي الأبعاد تحتوي على 430,000 جزيء، يحتوي كل منها على 44 ذرة في المتوسط. بعد معالجة البيانات، يمكن أن يحتوي كل جزيء على ما يصل إلى 181 ذرة. في التجربة، جمع الباحثون 30 من أدنى مستويات الطاقة لكل جزيء وطلبوا من كل طريقة أساسية إنشاء مواضع ثلاثية الأبعاد وأنواع الذرات المكونة لهذه الجزيئات.
الاستخدام المباشر:https://go.hyper.ai/5B3U8
8. مجموعة بيانات الكهانة الصينية في فنغ شوي
تحتوي مجموعة البيانات على 207 سؤالاً حول فنغ شوي، وبازي، وما إلى ذلك، وكل سؤال لديه إجابة فريدة مقابلة.
الاستخدام المباشر:https://go.hyper.ai/31k1P
9. مجموعة بيانات معايير تقييم مجالات التخصص SuperGPQA
SuperGPQA عبارة عن مجموعة بيانات معيارية لتقييم أداء أنظمة الإجابة على الأسئلة المتقدمة. يركز على مجالات معالجة اللغة الطبيعية وتقييم التعلم الآلي، ويهدف إلى اختبار قدرة التفكير ومستوى المعرفة للنموذج من خلال أسئلة معقدة متعددة التخصصات. تغطي مجموعة البيانات 285 مجالًا دراسيًا على مستوى الدراسات العليا مع أنواع مختلفة من الأسئلة، بما في ذلك علم الأحياء والفيزياء والكيمياء وغيرها من المجالات العلمية.
الاستخدام المباشر:https://go.hyper.ai/oP1pb
10. olmOCR-mix-0225 مجموعة بيانات مستندات PDF واسعة النطاق
olmOCR-mix-0225 عبارة عن مجموعة بيانات مستندات PDF عالية الجودة وواسعة النطاق مصممة لتدريب نماذج التعرف الضوئي على الحروف (OCR) وتحسينها. تحتوي مجموعة البيانات على حوالي 250 ألف صفحة من محتوى PDF، تغطي أنواعًا مختلفة مثل الأوراق الأكاديمية والمستندات القانونية والأدلة. لا تحتوي مجموعة البيانات على محتوى نصي فحسب، بل تستخرج أيضًا معلومات إحداثيات العناصر البارزة (مثل كتل النص والصور) في كل صفحة. يتم حقن هذه المعلومات بشكل ديناميكي في موجه النموذج، مما يقلل بشكل كبير من هلوسات النموذج.
الاستخدام المباشر:https://go.hyper.ai/dXNkk
دروس تعليمية عامة مختارة
1. نشر QwQ-32B-AWQ بنقرة واحدة
QwQ-32B هو نموذج الاستدلال لسلسلة Qwen. وبالمقارنة مع نماذج ضبط التعليمات التقليدية، يتمتع QwQ بقدرات التفكير والاستدلال، ويمكنه تحقيق تحسينات كبيرة في الأداء في المهام اللاحقة، وخاصة المشكلات الصعبة. وهو قابل للمقارنة مع نماذج الاستدلال المتقدمة مثل DeepSeek-R1 و o1-mini.
لقد تم نشر النماذج والتبعيات ذات الصلة بهذا المشروع. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/Q8HmJ

vLLM هو إطار عمل مفتوح المصدر مصمم للنشر الفعال لنماذج اللغة الكبيرة. تعمل تقنيتها الأساسية على تقليل عتبة الأجهزة اللازمة لاستدلال النموذج بشكل كبير من خلال تحسين إدارة الذاكرة وكفاءة الحوسبة. يستخدم هذا البرنامج التعليمي vLLM لنشر نموذج QwQ-32B لتقليل تكاليف النشر بشكل أكبر وتلبية احتياجات السيناريوهات الأكثر تفاعلية.
لقد تم نشر النماذج والتبعيات ذات الصلة بهذا المشروع. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/8nPfC
3.OpenManus + QwQ-32B ينفذ وكيل الذكاء الاصطناعي
OpenManus هو مشروع مفتوح المصدر أطلقه فريق MetaGPT. ويهدف إلى تكرار الوظائف الأساسية لـ Manus وتزويد المستخدمين بحل وكيل ذكي يمكن نشره محليًا دون رمز دعوة.
انتقل إلى الموقع الرسمي لاستنساخ الحاوية وبدء تشغيلها، وأدخل مساحة العمل، وأدخل الأوامر المقابلة لتجربة النموذج.
تشغيل عبر الإنترنت:https://go.hyper.ai/GIX1H
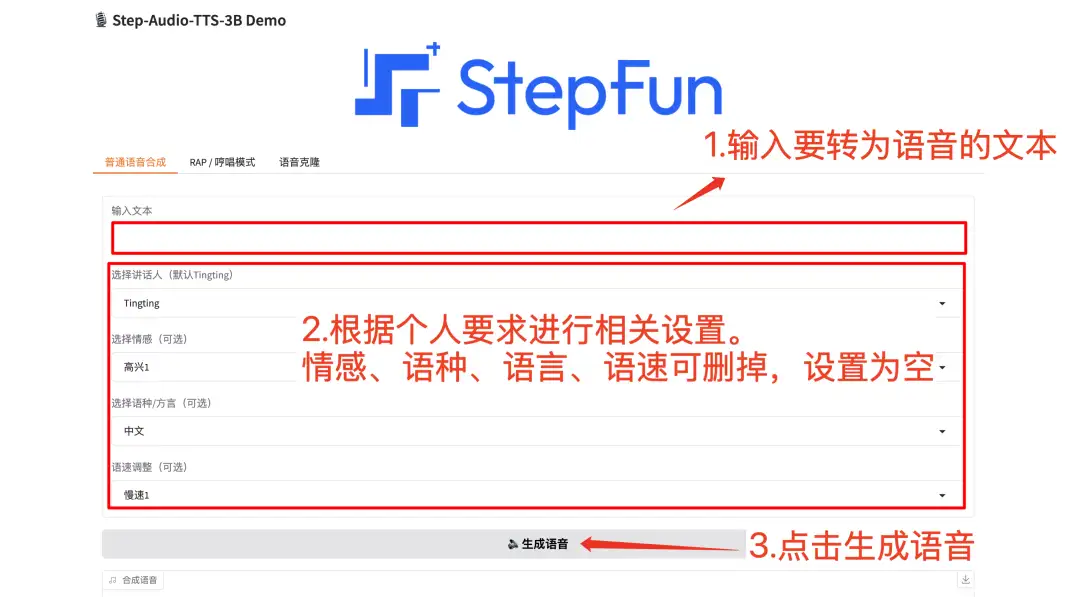
4. نموذج توليد الكلام اللهجي على مستوى الإنتاج Step-Audio-TTS-3B
Step-Audio هو أول نظام حوار صوتي مفتوح المصدر على مستوى المنتج في الصناعة والذي يدمج فهم الكلام والتحكم في التوليد. تم إطلاقه مفتوح المصدر بواسطة فريق Stepfun-AI في عام 2025. وهو يدعم إنشاء لغات متعددة (مثل الصينية والإنجليزية واليابانية)، والعواطف الصوتية (مثل السعادة والحزن)، واللهجات (مثل لهجة الكانتونية والسيتشوان). يمكنه التحكم في سرعة الكلام والنمط الإيقاعي، ويدعم RAP والهمهمة، وما إلى ذلك.
انتقل إلى الموقع الرسمي لاستنساخ الحاوية وبدء تشغيلها، وانسخ عنوان API مباشرةً، ويمكنك إجراء توليف كلامي متعدد الوظائف.
تشغيل عبر الإنترنت:https://go.hyper.ai/WiyVK
مقالات المجتمع
واقترح فريق من جامعة غرب أستراليا ومؤسسات أخرى استخدام إطار عمل آلي يعتمد على التعلم العميق. استخدمت الدراسة 200 صورة مقطعية للجمجمة من مستشفى في إندونيسيا لتدريب واختبار ثلاثة تكوينات شبكية تعتمد على التعلم العميق. كان إطار التعلم العميق الأكثر دقة قادرًا على الجمع بين ميزات الجنس والجمجمة للحكم، بدقة تصنيف 97%، وهي أعلى بكثير من 82% للمراقبين البشريين. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/0rfjM
اقترح باحثون من مختبر GIS الرئيسي في مقاطعة تشجيانغ نموذج التعلم العميق CatGWR استنادًا إلى آلية الانتباه. يقدم النموذج آلية انتباه لدمج المسافة المكانية والتشابه السياقي بين العينات لتقدير عدم الثبات المكاني بشكل أكثر دقة. وهذا يوفر آفاقًا جديدة للنمذجة الجغرافية المكانية، وخاصة عند التعامل مع الظواهر الجغرافية المعقدة، ويمكنه التقاط التباين المكاني والتأثيرات السياقية بشكل أفضل. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/irDAo
قامت HyperAI بتجميع مجموعات بيانات الاستدلال الأكثر شيوعًا بعناية، والتي تغطي مجالات متعددة مثل الرياضيات والبرمجة والعلوم والألغاز وما إلى ذلك. بالنسبة للممارسين والباحثين الذين يرغبون في تحسين قدرات الاستدلال للنماذج الكبيرة بشكل كبير، فإن مجموعات البيانات هذه تُعد بلا شك نقطة انطلاق ممتازة. هذه المقالة هي عنوان تنزيل مجموعة البيانات.
شاهد التقرير الكامل:https://go.hyper.ai/XGIi8
وقد اقترحت جامعة تشجيانغ وآخرون تقنية تسمى محاذاة بولتزمان، والتي تنقل المعرفة من نموذج الطي العكسي المدرب مسبقًا إلى التنبؤ بالطاقة الحرة الملزمة. وقد تم تنفيذ هذه الطريقة على مستوى متفوق وتم تضمينها في ICLR 2025، وهو المؤتمر الأكاديمي الدولي الأبرز في مجال الذكاء الاصطناعي. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/MsUDj
قامت شركة NVIDIA، بالتعاون مع معهد ماساتشوستس للتكنولوجيا وشركات أخرى، بتطوير نوع جديد من مولدات العمود الفقري للبروتين المتدفق على نطاق واسع، Proteina. تحتوي شركة Proteina على خمسة أضعاف عدد معلمات نموذج RFdiffusion، كما قامت بتوسيع بيانات التدريب الخاصة بها إلى 21 مليون بنية بروتينية اصطناعية. وقد حققت أداء SOTA في تصميم العمود الفقري للبروتين الجديد وأنشأت بروتينات متنوعة وقابلة للتصميم بطول غير مسبوق يصل إلى 800 بقايا. وقد تم اختيار نتائجها لـ ICLR 2025 الشفوي. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/n4fWv
لقد تابع لي جون وتشو هونغ يي وليو تشينغفينج وقادة الصناعة الآخرون نبض العصر عن كثب وطرحوا بنشاط مقترحات واقتراحات في العديد من المجالات الرئيسية مثل المركبات ذات الطاقة الجديدة، والهلوسة النموذجية الكبيرة، والرعاية الطبية بالذكاء الاصطناعي، وتغيير الوجه بالذكاء الاصطناعي، والتعليم بالذكاء الاصطناعي. انظر أدناه لمزيد من التفاصيل.
شاهد التقرير الكامل:https://go.hyper.ai/EazuY
مقالات موسوعية شعبية
1. دال-إي
2. دمج الفرز المتبادل RRF
3. جبهة باريتو
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
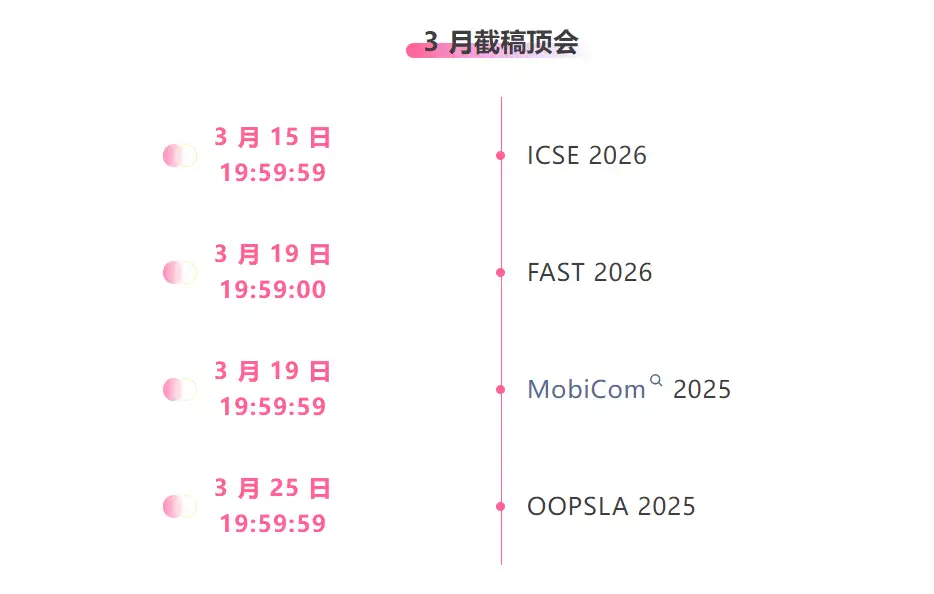
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








