Command Palette
Search for a command to run...
يقوم Ebook2Audiobook بتحويل الكتب الإلكترونية إلى كتب صوتية بنقرة واحدة؛ أول مجموعة بيانات تحدي اكتشاف الكائنات الصغيرة متعددة النطاقات من CVPR متاحة على الإنترنت

في عصر انفجار المعلومات هذا، أصبحت أعيننا منذ فترة طويلة مشغولة بالتحديق في شاشات الهاتف المحمول في طريقنا إلى العمل، أو النظر إلى مستندات الكمبيوتر أثناء العمل، أو الانغماس في عالم الروايات قبل الذهاب إلى السرير. إذا كان من الممكن تحويل النص إلى صوت دافئ يمكن الاستماع إليه أثناء ممارسة رياضة الجري في الصباح، أو أثناء الطهي، أو أثناء الراحة مع إغلاق العينين، فلن يقتصر اكتساب المعلومات بعد الآن على الرؤية.
Ebook2Audiobook هي أداة مفتوحة المصدر مصممة لتحويل الكتب الإلكترونية (eBooks) إلى كتب صوتية (audiobooks). يستخدم المشروع تكنولوجيا متقدمة لتحويل النص إلى كلام (TTS) لتحويل محتوى النص في الكتب الإلكترونية إلى ملفات صوتية وإنشاء كتب صوتية يمكن الاستماع إليها.
في الوقت الحالي،برنامج تعليمي "تحويل الكتب الإلكترونية إلى كتب صوتية" متوفر الآن على الموقع الرسمي لـ Hyper.ai، يمكن أن يؤدي البدء بنقرة واحدة إلى إعادة إنشاء مكتبة الكتب الإلكترونية الخاصة بك في الموجات الصوتية، تعال وجربها ~
الاستخدام عبر الإنترنت:https://go.hyper.ai/sgLbN
من 3 مارس إلى 7 مارس، تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* اختيار المقالات المجتمعية: 6 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في مارس: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
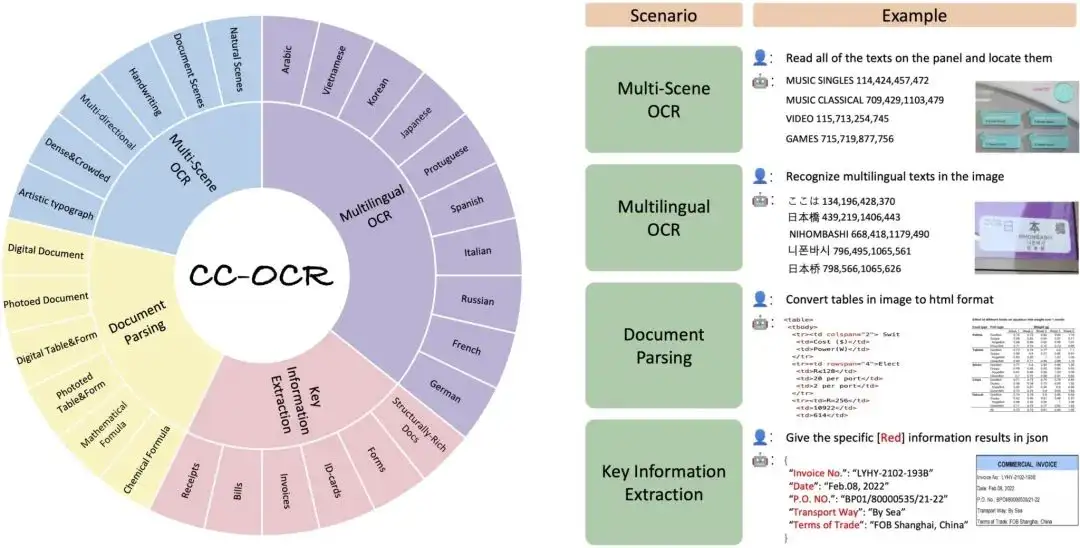
1. مجموعة بيانات التعرف على النصوص CC-OCR
تغطي مجموعة بيانات CC-OCR أربع مهام أساسية: قراءة النصوص متعددة المشاهد، وقراءة النصوص متعددة اللغات، وتحليل المستندات، واستخراج المعلومات الرئيسية، وتحتوي على 39 مجموعة فرعية و7058 صورة موضحة بالكامل. ويساهم إطلاق CC-OCR في سد الفجوة في تقييم النماذج متعددة الوسائط الحالية في الهياكل المعقدة والتحديات البصرية الدقيقة، وهو أمر ذو أهمية كبيرة لتعزيز تقدم النماذج متعددة الوسائط في التطبيقات العملية.
الاستخدام المباشر:https://go.hyper.ai/rQT2y
2. مجموعة بيانات محاذاة التفضيلات متعددة الوسائط MM-RLHF
تحتوي مجموعة البيانات هذه على 120,000 زوجًا من بيانات مقارنة التفضيلات الدقيقة والموضحة يدويًا، والتي تغطي ثلاثة مجالات: فهم الصور، وتحليل الفيديو، والأمان المتعدد الوسائط. تتجاوز كمية البيانات الموارد المتاحة بكثير، حيث تغطي أكثر من 100000 حالة مهمة متعددة الوسائط. لقد تم تسجيل كل قطعة من البيانات بعناية وتفسيرها من قبل أكثر من 50 معلقًا، مما يضمن الجودة العالية وتفاصيل البيانات.
الاستخدام المباشر:https://go.hyper.ai/sTfNc
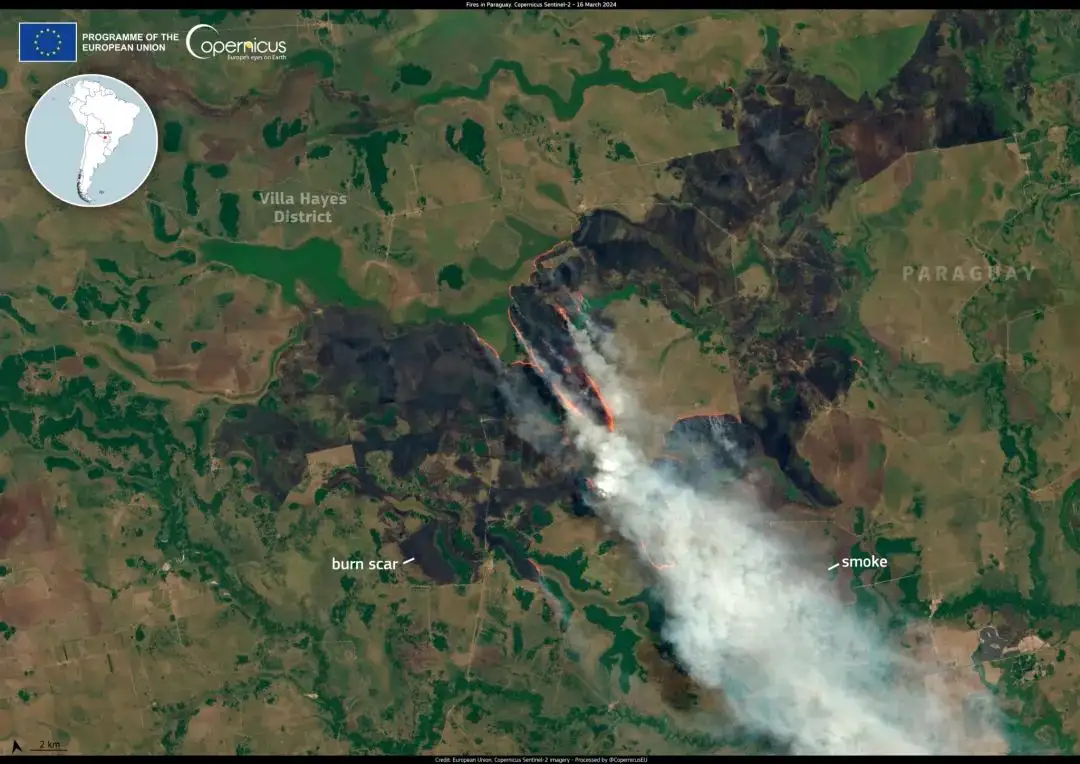
3. مجموعة بيانات فهم الصور عن بُعد للغة البصرية GAIA
GAIA هي مجموعة بيانات عالمية متعددة الوسائط ومتعددة المقاييس للرؤية واللغة لتحليل صور الاستشعار عن بعد، والتي تهدف إلى سد الفجوة بين صور الاستشعار عن بعد وفهم اللغة الطبيعية. تغطي مجموعة البيانات 25 عامًا من بيانات مراقبة الأرض (1998-2024) وتغطي مجموعة متنوعة من المناطق الجغرافية ومهام الأقمار الصناعية ووسائل الاستشعار عن بعد.
الاستخدام المباشر:https://go.hyper.ai/JHgSb
4. مجموعة بيانات الاستدلال الرياضي OpenR1-Math-220k
OpenR1-Math-220k عبارة عن مجموعة بيانات تفكير رياضي واسعة النطاق تحتوي على 220,000 مشكلة رياضية عالية الجودة وآثار التفكير الخاصة بها، والتي تم استخلاصها من 800,000 أثر تفكير تم إنشاؤه بواسطة DeepSeek R1.
الاستخدام المباشر:https://go.hyper.ai/VkUMt
5. مجموعة بيانات معيارية للأحكام القانونية الصينية JuDGE
JuDGE عبارة عن مجموعة بيانات مرجعية لإنشاء المستندات القانونية مصممة للنظام القانوني الصيني. تهدف مجموعة البيانات هذه إلى تحسين أداء نماذج إنشاء المستندات القانونية من خلال بيانات توضيحية عالية الجودة، وخاصة في التفكير القانوني وكتابة المستندات. فهو مناسب لمختلف سيناريوهات التطبيق مثل الأنظمة القانونية الذكية، والتوليد التلقائي للوثائق القانونية، وأنظمة الأسئلة والأجوبة القانونية.
الاستخدام المباشر:https://go.hyper.ai/Fygtg
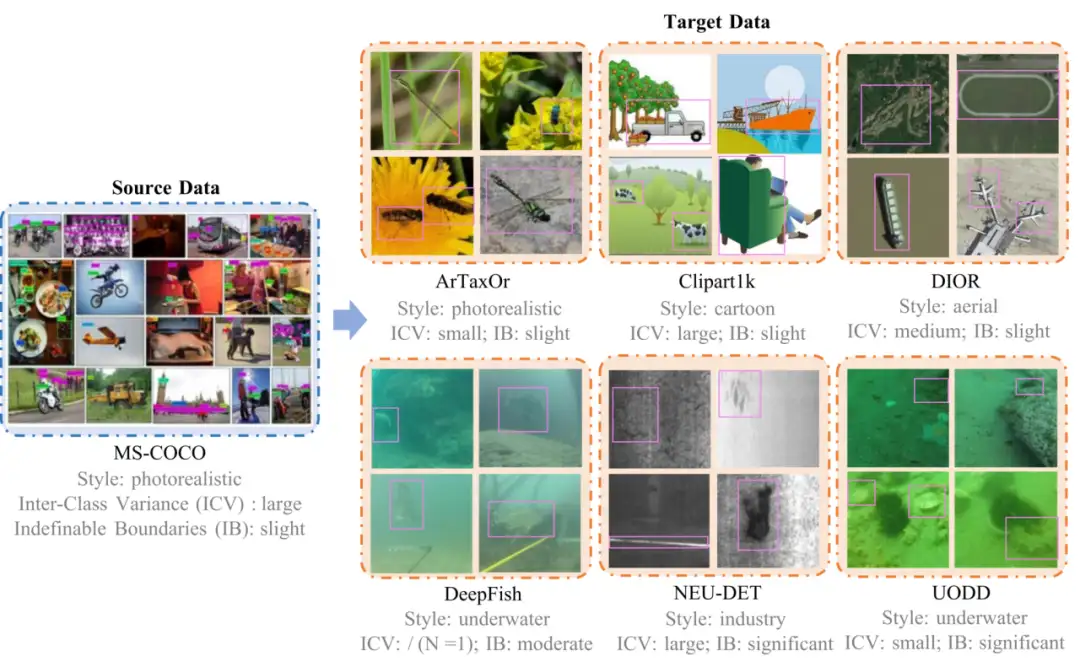
6. مجموعة بيانات الكشف عن الكائنات ذات العينات الصغيرة NTIRE2025 CDFSOD
تُستخدم مجموعة البيانات هذه بواسطة أول تحدٍ لاكتشاف الكائنات ذات العينات الصغيرة عبر النطاقات NTIRE 2025، والذي يتضمن مجموعة البيانات المصدر COCO ومجموعات بيانات التحقق المتعددة مثل ArTaxOr و Clipart1k و DIOR و DeepFish و NEU-DET و UODD وما إلى ذلك. تتمثل مشكلة البحث الأساسية لهذه المجموعة من البيانات في كيفية إجراء اكتشاف الهدف في سيناريوهات عبر النطاقات باستخدام صور هدف موضحة محدودة للغاية فقط.
الاستخدام المباشر:https://go.hyper.ai/kGZhW
7. مجموعة بيانات الكشف عن كائنات خدش القط بتنسيق YOLO
هذه المجموعة من البيانات عبارة عن مجموعة بيانات بتنسيق YOLO للكشف عن القطط التي تخدش الأشياء. يحتوي على حوالي 1500 صورة مع الخلفيات. تحتوي كل صورة على ملف تسمية .txt متوافق مع YOLO، والذي يمكن استخدامه لتدريب نماذج اكتشاف الكائنات لتحديد ما إذا كانت القطة تخدش شيئًا ما.
الاستخدام المباشر:https://go.hyper.ai/wkzNJ

8. بيانات التقطير الصينية DeepSeek R1 110k استنادًا إلى مجموعة بيانات التقطير DeepSeek-R1
هذه المجموعة من البيانات عبارة عن مجموعة بيانات R1 كاملة المصدر ومقطرة ومفتوحة المصدر. لا تحتوي مجموعة البيانات على بيانات رياضية فحسب، بل تحتوي أيضًا على كمية كبيرة من البيانات العامة، بإجمالي يصل إلى 110 كيلو بايت.
الاستخدام المباشر:https://go.hyper.ai/5zvRt
9. مجموعة بيانات اكتشاف إيماءات اليد
تم إنشاء مجموعة البيانات هذه خصيصًا لأنظمة التحكم بالإيماءات الخاصة بالتلفزيون الذكي وتحتوي على حوالي 500 عينة فيديو قصيرة تم جمعها بشكل مستقل. يستمر كل مقطع فيديو لمدة تتراوح من ثانيتين إلى ثلاث ثوانٍ، ويسجل بالكامل العملية الديناميكية من الحركة الأولية للإيماءة إلى العرض الكامل. تتضمن هذه الإيماءات الإبهام لأعلى، والإبهام لأسفل، والتمرير لليسار، والتمرير لليمين، والتوقف، وتعمل كعينات تدريبية منفصلة لنموذج التعرف على الإيماءات. تم إكمال العينات بشكل تعاوني من قبل المشاركين من مختلف الأعمار (18-65 سنة)، والجنسين، وألوان البشرة، وتغطي مجموعة متنوعة من المواقف التفاعلية مثل الوقوف والجلوس، من أجل التقاط الاختلافات في عادات التشغيل التي قد تحدث بين المستخدمين الحقيقيين.
الاستخدام المباشر:https://go.hyper.ai/nMdjB

10. مجموعة بيانات صور التغذية الراجعة البشرية الغنية
تم تصميم مجموعة البيانات هذه لتوفير ملاحظات غنية لتدريب وتقييم نماذج إنشاء النص إلى صورة وتحتوي على 15 ألف صورة. إنه يجمع 1.5 مليون تعليق قدمها أكثر من 150 ألف شخص، وتغطي التعليقات مثل تقييمات الصور، والتناسق الدلالي، واقتراحات التصحيح.
الاستخدام المباشر:https://go.hyper.ai/GhD9w

دروس تعليمية عامة مختارة
لفترة طويلة، كان تعزيز بنية الشبكة لإطار عمل YOLO موضوعًا أساسيًا في مجال الرؤية الحاسوبية. على الرغم من تفوق آلية الانتباه في قدرات النمذجة، فإن التحسينات المستندة إلى CNN لا تزال سائدة لأن النماذج المستندة إلى الانتباه يصعب مطابقتها في السرعة. ومع ذلك، أدى تقديم YOLOv12 إلى تغيير هذا الوضع. إنه ليس فقط قابلاً للمقارنة مع الأطر المستندة إلى CNN من حيث السرعة، ولكنه أيضًا يستفيد بشكل كامل من مزايا الأداء لآلية الانتباه، ليصبح معيارًا جديدًا لاكتشاف الكائنات في الوقت الفعلي.
لقد تم نشر النماذج والتبعيات ذات الصلة بهذا المشروع. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب.
تشغيل عبر الإنترنت:https://go.hyper.ai/Wy1So

2. تحويل الكتاب الإلكتروني إلى كتاب صوتي
Ebook2Audiobook هي أداة مفتوحة المصدر مصممة لتحويل الكتب الإلكترونية (eBooks) إلى كتب صوتية (audiobooks). يستخدم المشروع تقنية تحويل النص إلى كلام المتقدمة (TTS) لتحويل محتوى النص في الكتب الإلكترونية إلى كلام تلقائيًا وإنشاء كتب صوتية يمكن للمستخدمين الاستماع إليها. يدعم Ebook2Audiobook تنسيقات متعددة للكتب الإلكترونية، مثل EPUB وPDF وMOBI وما إلى ذلك، ويمكنه الحفاظ على بنية الفصل والبيانات الوصفية، مما يجعل الكتب الصوتية المولدة أسهل في التنقل والفهم.
انتقل إلى الموقع الرسمي لاستنساخ الحاوية وبدء تشغيلها، ثم انسخ عنوان API مباشرة، ثم ابدأ تشغيل النموذج.
تشغيل عبر الإنترنت:https://go.hyper.ai/sgLbN
مقالات المجتمع
واقترح فريق من جامعة غرب أستراليا ومؤسسات أخرى استخدام إطار عمل آلي يعتمد على التعلم العميق. استخدمت الدراسة 200 صورة مقطعية للجمجمة من مستشفى في إندونيسيا لتدريب واختبار ثلاثة تكوينات شبكية تعتمد على التعلم العميق. كان إطار التعلم العميق الأكثر دقة قادرًا على الجمع بين ميزات الجنس والجمجمة للحكم، بدقة تصنيف 97%، وهي أعلى بكثير من 82% للمراقبين البشريين. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/0rfjM
اقترح باحثون من مختبر GIS الرئيسي في مقاطعة تشجيانغ نموذج التعلم العميق CatGWR استنادًا إلى آلية الانتباه. يقدم النموذج آلية انتباه لدمج المسافة المكانية والتشابه السياقي بين العينات لتقدير عدم الثبات المكاني بشكل أكثر دقة. وهذا يوفر آفاقًا جديدة للنمذجة الجغرافية المكانية، وخاصة عند التعامل مع الظواهر الجغرافية المعقدة، ويمكنه التقاط التباين المكاني والتأثيرات السياقية بشكل أفضل. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/irDAo
قامت HyperAI بتجميع مجموعات بيانات الاستدلال الأكثر شيوعًا بعناية، والتي تغطي مجالات متعددة مثل الرياضيات والبرمجة والعلوم والألغاز وما إلى ذلك. بالنسبة للممارسين والباحثين الذين يرغبون في تحسين قدرات الاستدلال للنماذج الكبيرة بشكل كبير، فإن مجموعات البيانات هذه تُعد بلا شك نقطة انطلاق ممتازة. هذه المقالة هي عنوان تنزيل مجموعة البيانات.
شاهد التقرير الكامل:https://go.hyper.ai/XGIi8
وقد اقترحت جامعة تشجيانغ وآخرون تقنية تسمى محاذاة بولتزمان، والتي تنقل المعرفة من نموذج الطي العكسي المدرب مسبقًا إلى التنبؤ بالطاقة الحرة الملزمة. وقد تم تنفيذ هذه الطريقة على مستوى متفوق وتم تضمينها في ICLR 2025، وهو المؤتمر الأكاديمي الدولي الأبرز في مجال الذكاء الاصطناعي. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/MsUDj
قامت شركة NVIDIA، بالتعاون مع معهد ماساتشوستس للتكنولوجيا وشركات أخرى، بتطوير نوع جديد من مولدات العمود الفقري للبروتين المتدفق على نطاق واسع، Proteina. تحتوي شركة Proteina على خمسة أضعاف عدد معلمات نموذج RFdiffusion، كما قامت بتوسيع بيانات التدريب الخاصة بها إلى 21 مليون بنية بروتينية اصطناعية. وقد حققت أداء SOTA في تصميم العمود الفقري للبروتين الجديد وأنشأت بروتينات متنوعة وقابلة للتصميم بطول غير مسبوق يصل إلى 800 بقايا. وقد تم اختيار نتائجها لـ ICLR 2025 الشفوي. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/n4fWv
لقد تابع لي جون وتشو هونغ يي وليو تشينغفينج وقادة الصناعة الآخرون نبض العصر عن كثب وطرحوا بنشاط مقترحات واقتراحات في العديد من المجالات الرئيسية مثل المركبات ذات الطاقة الجديدة، والهلوسة النموذجية الكبيرة، والرعاية الطبية بالذكاء الاصطناعي، وتغيير الوجه بالذكاء الاصطناعي، والتعليم بالذكاء الاصطناعي. انظر أدناه لمزيد من التفاصيل.
شاهد التقرير الكامل:https://go.hyper.ai/EazuY
مقالات موسوعية شعبية
1. فقدان الانتشار
2. الاهتمام السببي
3. نظرية كولموغوروف-أرنولد للتمثيل
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
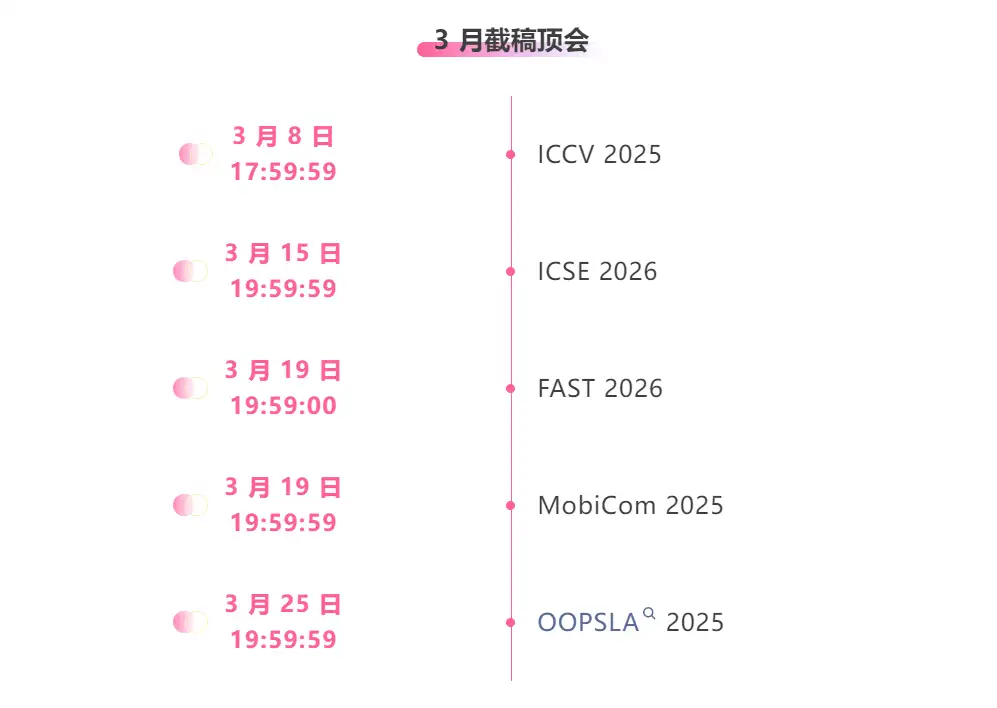
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








