Command Palette
Search for a command to run...
ولأول مرة، نجح فريق تسينغهوا في توحيد توليد الجزيئات والتنبؤ بالخصائص. وقد اقترح آلية توليد انتشار ذات مرحلتين وتم اختياره لـ ICLR 2025.

تساهم تكنولوجيا الذكاء الاصطناعي في إعادة تشكيل عملية تطوير الأدوية بشكل عميق.ومن بين هذه المهام، تم تطوير التنبؤ بالخصائص الجزيئية وتوليد الجزيئات، باعتبارهما مهمتين أساسيتين، على طول مسارات تقنية مستقلة منذ فترة طويلة.الغرض من التنبؤ بالخصائص الجزيئية هو التنبؤ بالخصائص الكيميائية والبيولوجية المتنوعة للجزيئات بناءً على معلومات البنية الجزيئية وتسريع فحص الأدوية. يهدف التوليد الجزيئي إلى تقدير توزيع البيانات الجزيئية، وربما تعلم التفاعلات الذرية والمعلومات التكوينية، والقدرة على توليد جزيئات كيميائية عقلانية جديدة من الصفر، وتوسيع حدود إمكانيات تصميم الأدوية. وعلى الرغم من إجراء قدر كبير من الأبحاث في هذه المجالات في السنوات الأخيرة، إلا أنها تطورت إلى حد كبير بشكل مستقل.ولم يتم مطلقًا فتح قنوات التعاون بين هاتين الرابطتين الرئيسيتين بشكل فعال.
وفي ضوء ذلك،واقترح فريق جامعة تسينغهوا والأكاديمية الصينية للعلوم نموذج UniGEM، الذي حقق لأول مرة تعزيزًا تعاونيًا لمهمتين استنادًا إلى نموذج الانتشار.وأشار فريق البحث إلى أن التنبؤ بالجيل والخصائص يرتبطان بشكل كبير ويعتمدان على التمثيل الجزيئي الفعال. واقترح الفريق بشكل مبتكر عملية توليد مكونة من مرحلتين، والتي تغلبت على التناقضات في التدريب المشترك التقليدي وفتحت مسارًا جديدًا في مجال توليد الجزيئات والتنبؤ بالخصائص. تم اختيار هذا الإنجاز لـ ICLR 2025 تحت عنوان "UniGEM: نهج موحد للتنبؤ بالجيل وخصائص الجزيئات".

عنوان الورقة:
https://openreview.net/pdf?id=Lb91pXwZMR
مجموعة بيانات الكيمياء الكمومية QM9:
مجموعة بيانات التكوين الجزيئي ثلاثية الأبعاد GEOM-Drugs:
يجمع مشروع المصدر المفتوح "awesome-ai4s" أكثر من 200 تفسير لورقة AI4S ويوفر مجموعات بيانات وأدوات ضخمة:
https://github.com/hyperai/awesome-ai4s
الدافع لتوحيد مهام التوليد والتنبؤ
ويعتقد فريق البحث أن جوهر كل من مهام التوليد والتنبؤ يكمن في تعلم التمثيلات الجزيئية.من ناحية أخرى، تظهر فعالية طرق التدريب المسبق الجزيئي المختلفة أن التنبؤ بالخصائص الجزيئية يعتمد على التمثيل الجزيئي القوي كأساس. من ناحية أخرى، يتطلب إنشاء الجزيئات فهمًا عميقًا للبنية الجزيئية حتى نتمكن من إنشاء تمثيلات جيدة أثناء عملية التوليد.
وتقدم نتائج الأبحاث الأخيرة الدعم لهذا الرأي. على سبيل المثال، أظهر العمل في مجال الرؤية الحاسوبية أن نماذج الانتشار نفسها لديها القدرة على تعلم تمثيلات الصور الفعالة. في المجال الجزيئي، أظهرت الدراسات أن التدريب المسبق التوليدي يمكن أن يعزز مهام التنبؤ بالخصائص الجزيئية، على الرغم من أن هذه الأساليب تتطلب غالبًا ضبطًا دقيقًا إضافيًا لتحقيق الأداء التنبئي الأمثل. وعلاوة على ذلك، على الرغم من أن المتنبئين يمكنهم توجيه عملية توليد الجزيئات من خلال أساليب توجيه المصنف، فإنه لا يزال من غير الواضح ما إذا كان تدريب المتنبئين يمكن أن يحسن أداء التوليد بشكل مباشر.
لذلك، فإن الأبحاث الحالية لم توضح بعد العلاقة بين مهام التوليد ومهام التنبؤ بشكل كامل.وهذا يثير سؤالا رئيسيا: هل يمكننا بناء نموذج موحد يحقق تعزيزا تآزريا لمهام التوليد والتنبؤ؟
تحليل أسباب فشل الطرق التقليدية
الطريقة المباشرة للجمع بين هاتين المهمتين هي استخدام إطار عمل التعلم متعدد المهام التقليدي، حيث يعمل النموذج على تحسين كل من خسارة التوليد وخسارة التنبؤ. ومع ذلك، أظهرت التجارب التي أجراها فريق البحث أن هذا النهج أدى إلى تقليل أداء مهام التوليد ومهام التنبؤ بالخصائص بشكل كبير (انخفض استقرار التوليد بمقدار 6%، وزاد خطأ التنبؤ بأكثر من مرة). حتى بعد تجميد أوزان النموذج التوليدي وإضافة رأس منفصل لمهمة التنبؤ بالخصائص للحفاظ على أداء التوليد، لم يلاحظ الباحثون أي تحسن في أداء التنبؤ بالخصائص مقارنة بالتدريب من الصفر.
ويعزو الباحثون النتائج الضعيفة للطرق التقليدية إلى التناقض الكامن بين مهام التوليد والتنبؤ.أثناء عملية توليد الانتشار، يحتاج الهيكل الجزيئي إلى الخضوع لإعادة بناء تدريجية من الضوضاء غير المنتظمة إلى الهيكل الدقيق. ومع ذلك، في مهام التنبؤ، لا يمكن تعريف الخصائص الجزيئية ذات المعنى إلا بعد تحديد البنية الجزيئية بشكل أساسي. لذلك، فإن مجرد اعتماد نهج بسيط لتحسين المهام المتعددة سيؤدي إلى تكوينات جزيئية شديدة الفوضى مرتبطة بشكل غير صحيح بعلامات الخصائص في مرحلة الانتشار المبكرة، مما سيكون له تأثير سلبي على تكوين الجزيئات والتنبؤ بالخصائص.
ولتوضيح هذه النقطة بشكل أكبر، أجرى الباحثون تحليلًا نظريًا للمعلومات المتبادلة بين التمثيلات الوسيطة داخل شبكة إزالة الضوضاء والجزيئات المستهدفة أثناء تدريب الانتشار.علاوة على ذلك، ثبت نظريًا أن نموذج الانتشار يعمل ضمناً على تعظيم الحد الأدنى للمعلومات المتبادلة بين التمثيل الوسيط والجزيء المستهدف، مما يشير إلى قدرة تمثيل نموذج الانتشار على التعلم. ومع ذلك، فإن المعلومات المتبادلة بين التمثيل الوسيط والجزيء المستهدف تظهر اتجاهًا تنازليًا رتيبًا وتقترب من الصفر في خطوات زمنية أكبر، مما يعني أن التمثيل الوسيط في المرحلة غير المنظمة لا يمكنه دعم التنبؤ الفعال. لذلك، تشير كل من الحدس والنظرية إلى أن مهام التوليد والتنبؤ لا يمكن أن تتم مواءمتها إلا في خطوات زمنية أصغر، عندما تظل الجزيئات منظمة نسبيًا.
آلية توليد الانتشار ثنائية المرحلتين
وبناء على التحليل أعلاه،واقترح فريق البحث طريقة توليد جديدة من مرحلتين تهدف إلى توحيد التنبؤ وتوليد الخصائص الجزيئية، كما هو موضح في الشكل أدناه.
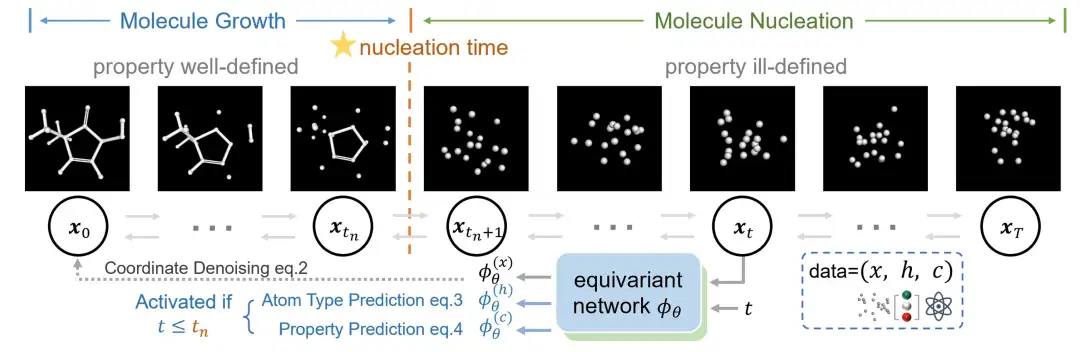
يقسم الباحثون عملية توليد الجزيئات إلى مرحلتين، أي "مرحلة النواة الجزيئية" و"مرحلة النمو الجزيئي"،هذا التقسيم مستوحى من عملية تكوين البلورات في الفيزياء.
خلال مرحلة التكوين النووي الجزيئي، يشكل الجزيء هيكله من حالة غير منظمة تمامًا، ثم ينمو الجزيء الكامل بناءً على هذا الهيكل. يتم الفصل بين هاتين المرحلتين من خلال "وقت النواة". وقد قدم الباحثون طريقة جديدة لتوليد الجزيئات لوصف هاتين المرحلتين. ومن بينها، قبل "زمن التكوّن النووي"، يقوم نموذج الانتشار بتوليد إحداثيات جزيئية تدريجيًا؛ بعد التكوين النووي، يستمر النموذج في ضبط إحداثيات الجزيئات مع تحسين خصائص وخسائر التنبؤ بنوع الذرة.
على عكس النماذج التوليدية التقليدية التي تقوم عادةً بإجراء انتشار مشترك لأنواع الذرات والإحداثيات، تركز هذه الطريقة المبتكرة فقط على انتشار الإحداثيات وتتعامل مع أنواع الذرات كمهمة تنبؤ منفصلة.لأن الباحثين لاحظوا أن أنواع الذرات يمكن في كثير من الأحيان استنتاجها من إحداثيات الجزيئات المتكونة. على وجه التحديد، قبل التبلور، تهدف عملية الانتشار إلى إعادة بناء الإحداثيات؛ بعد التكوين النووي، فإنه يدمج خسائر التنبؤ بأنواع الذرات وخصائصها في إطار تعليمي موحد.
استراتيجية تدريب UniGEM
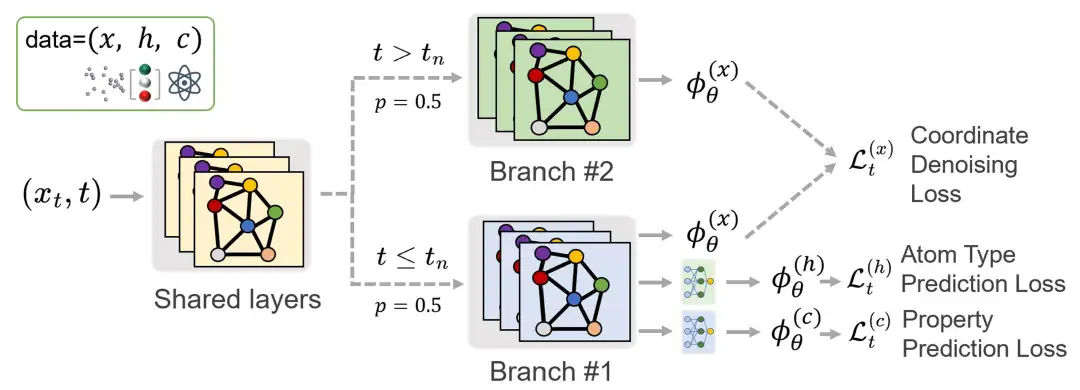
من أجل تسهيل المقارنة مع طريقة الانتشار المشترك التقليدية، اعتمد الباحثون نموذج الانتشار المتغير E (3) (EDM) باستخدام EGNN كهيكل هيكلي للشبكة. ومن بينها، تشكل مرحلة النمو حوالي 1% فقط من عملية التدريب بأكملها. إذا اتبعنا إجراء التدريب الانتشاري القياسي وقمنا بأخذ عينات من خطوات الوقت بشكل موحد، فإن عدد التكرارات لمهمة التنبؤ سيمثل فقط 1% من إجمالي عملية التدريب، مما سيقلل بشكل كبير من أداء النموذج في هذه المهمة.لذلك، ولضمان التدريب الكافي لمهمة التنبؤ، قام الباحثون بأخذ عينات زائدة من الخطوات الزمنية أثناء مرحلة النمو.
ومع ذلك، لاحظ الباحثون أن الإفراط في أخذ العينات قد يؤدي إلى اختلال التوازن في التدريب عبر مجموعة من الخطوات الزمنية، مما يؤثر بدوره على جودة عملية التوليد. ولحل هذه المشكلة، تم اقتراح بنية شبكة متعددة الفروع. تتقاسم الشبكة المعلمات في الطبقات الضحلة، ولكنها تنقسم إلى فرعين في الطبقات العميقة، كل منهما بمجموعة مستقلة من المعلمات.يتم تنشيط هذه الفروع في مراحل مختلفة من التدريب: يركز أحد الفروع على مرحلة النواة، ويتعامل فرع آخر مع مرحلة النمو،كما هو موضح في الشكل أدناه. يضمن هذا التصميم إمكانية تدريب مهمة التنبؤ ومهمة التوليد بشكل فعال دون التأثير على بعضهما البعض.
عملية التفكير في UniGEM
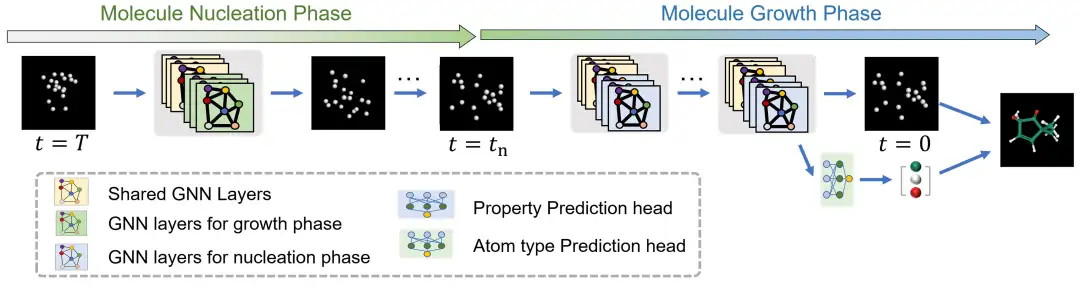
في UniGEM،يتم إجراء التوليد الجزيئي عن طريق إعادة بناء الإحداثيات الذرية من خلال عملية الانتشار الخلفي ومن ثم التنبؤ بنوع الذرة بناءً على الإحداثيات المولدة.كما هو موضح في الصورة. بالنسبة للتنبؤ بالخاصية، يتم تثبيت خطوة وقت إدخال الشبكة على الصفر ويتم استخدام رأس التنبؤ بالخاصية. ومن الجدير بالذكر أن هذا النهج لا يفرض تكلفة حسابية إضافية لكل من مهمة التوليد ومهمة التنبؤ، كما أن إجمالي وقت الاستدلال هو نفس الوقت الأساسي.
بالنسبة لمهمة التوليد الجزيئي، قام الباحثون أيضًا بتحليل الاختلافات في أخطاء التوليد بين UniGEM وطرق التوليد المشتركة التقليدية.أولاً، لوحظ أن خطأ فقدان التنبؤ بنوع الذرة في UniGEM أصغر من فقدان توليد الضوضاء لنوع الذرة في التوليد المشترك. ثانياً، أثناء عملية التوليد المشترك، سوف يتأثر توليد الإحداثيات بتذبذب نتائج التنبؤ بنوع الذرة، مما سيؤدي إلى زيادة الأخطاء. وأخيرًا، تؤدي طريقة التوليد المشترك أيضًا إلى إدخال أخطاء توزيع أولية أكبر وأخطاء تقديرية. تشرح هذه العوامل مجتمعة كيف يحقق UniGEM نتائج جيل متفوقة.
النتائج التجريبية: تفوق النموذج الأساسي في كل من مهام توليد الجزيئات والتنبؤ بالخصائص
التوليد الجزيئي: UniGEM يتفوق على النماذج المعيارية
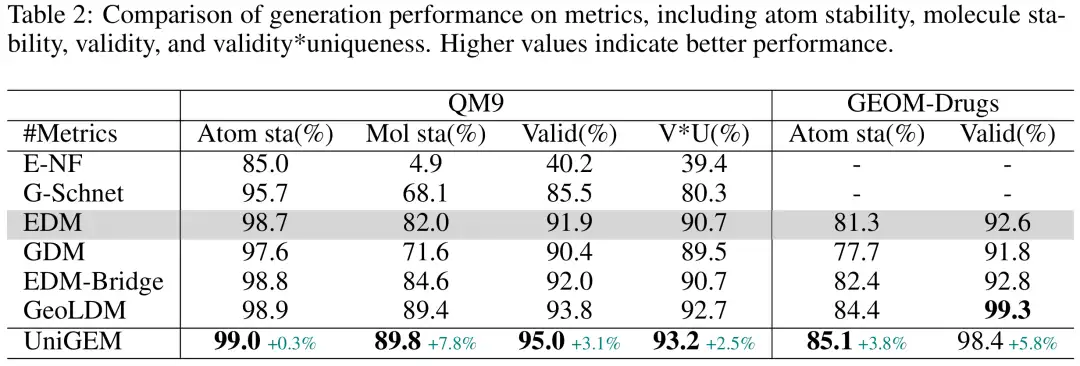
قام الباحثون أولاً بمقارنة UniGEM المستند إلى EDM مع متغيرات EDM الموجودة في مجموعات البيانات QM9 وGEOM-Drugs. وقد تفوقت UniGEM على النموذج الأساسي في جميع مؤشرات التقييم تقريبا، كما هو موضح في الشكل أدناه. ومن الجدير بالذكر أنه بالمقارنة مع متغيرات EDM الأخرى،يعد UniGEM أبسط بشكل كبير لأنه لا يعتمد على المعرفة المسبقة ولا يتطلب تدريبًا إضافيًا للمشفر التلقائي، ومع ذلك فإنه يتفوق على EDM-Bridge وGeoLDM، مما يسلط الضوء على مزايا UniGEM.
ولإثبات مرونة UniGEM في التكيف مع خوارزميات التوليد المختلفة، طبق الباحثون UniGEM على شبكات التدفق البايزية (BFNs)، متجاوزين GeoBFN، التي أنتجت بشكل مشترك إحداثيات وأنواع ذرات، على مجموعة بيانات QM9، محققين نتائج SOTA.
بالإضافة إلى ذلك، قام الباحثون باختبار أداء UniGEM في مهام التوليد المشروط، وتجنب الحاجة إلى إعادة تدريب نموذج التوليد المشروط باستخدام وحدة التنبؤ بالخصائص الخاصة بالنموذج كدليل أثناء عملية أخذ العينات.
التنبؤ بالخصائص الجزيئية: UniGEM يتفوق على معظم طرق التدريب المسبق
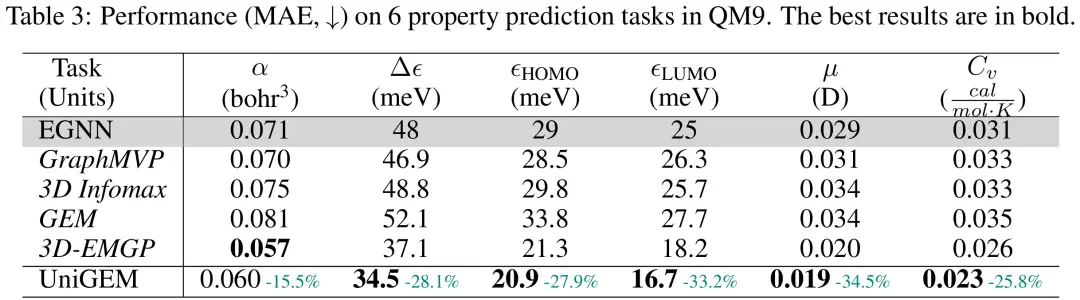
قام الباحثون بتقييم أداء التنبؤ بخصائص UniGEM على مجموعة بيانات QM9، باستخدام متوسط الخطأ المطلق (MAE) في مجموعة الاختبار كمقياس للتقييم. كما هو موضح في الشكل،يتفوق UniGEM بشكل كبير على EGNN المدرب من الصفر، مما يدل على فعالية النمذجة الموحدة.من المثير للدهشة أن UniGEM لا يزال يتفوق على معظم طرق التدريب المسبق المتطورة هذه على الرغم من الاستفادة من مجموعات بيانات التدريب المسبق الإضافية واسعة النطاق. ويسلط هذا الضوء على ميزة نموذجه الموحد للإنشاء والتنبؤ، والذي يمكنه استغلال قوة التعلم التمثيلي الجزيئي بشكل فعال أثناء عملية الإنشاء دون الحاجة إلى بيانات إضافية وخطوات تدريب مسبقة.
خاتمة
يوحد نموذج UniGEM مهام توليد الجزيئات والتنبؤ بالخصائص ويحسن أداء كليهما بشكل كبير. يتم دعم الأداء المعزز لـ UniGEM من خلال التحليل النظري القوي والدراسات التجريبية الشاملة. ونحن نعتقد أن عملية التوليد المبتكرة المكونة من مرحلتين والنموذج المقابل لها توفر نموذجًا جديدًا لتطوير أطر التوليد الجزيئي وقد تلهم تطوير أطر توليد جزيئي أكثر تقدمًا، وبالتالي الاستفادة من التوليد الجزيئي في مجالات تطبيق أكثر تحديدًا.
يتم إجراء هذا البحث بواسطة مختبر ATOM. لدى الفريق المزيد من نتائج الأبحاث في مجالات التدريب المسبق الجزيئي، وتوليد الجزيئات، وتوقع بنية البروتين، والفحص الافتراضي، وما إلى ذلك، لذا يرجى الانتباه!
مرحباً بكم في الصفحة الرئيسية لمختبر ATOM:
https://atomlab.yanyanlan.com/
عن المؤلف:
* لان يانيان أستاذة في معهد الصناعات الذكية (AIR) بجامعة تسينغهوا. تشمل اهتماماتها البحثية AI4Science، والتعلم الآلي، ومعالجة اللغة الطبيعية.
* شيكون فينج هو طالب دكتوراه في معهد الصناعات الذكية (AIR) بجامعة تسينغهوا. تشمل اهتماماته البحثية التعلم التمثيلي، والنماذج التوليدية، وAI4Science.
* يويان ني هو مرشح لنيل درجة الدكتوراه في أكاديمية الرياضيات وعلوم الأنظمة (AMSS) التابعة للأكاديمية الصينية للعلوم. تشمل اهتماماتها البحثية النماذج التوليدية، والتعلم التمثيلي، وAI4Science، ونظرية التعلم العميق.
المؤلفان الرئيسيان لهذه الورقة البحثية، الدكتور شيكون فينج والدكتور يويان ني، يبحثان حاليًا عن فرص عمل. يمكن للأصدقاء المهتمين التواصل معهم.
* البريد الإلكتروني لفنغ شيكون: [email protected]
* عنوان البريد الإلكتروني لني يويان: [email protected]








