Command Palette
Search for a command to run...
اقترحت جامعة أكسفورد/أمازون/ويستليك/تينسنت وآخرون نموذجًا طبيًا متعدد الوسائط ومتعدد المجالات ومتعدد اللغات M³FM، والذي يمكن استخدامه للتشخيص السريري بدون عينة

أعتقد أن العديد من الأصدقاء الذين يحبون أفلام Marvel قد انبهروا بهذا المشهد. في فيلم "الرجل الحديدي 2"، قام كبير الخدم بالذكاء الاصطناعي جارفيس بجمع عينات دم ستارك واستخدم خوارزميات التعلم العميق لتجميع بيانات العينة بسرعة. لقد قام بتحليل محتوى البلاديوم في جسم ستارك بدقة وسرعة، وحتى أنه أعطى اقتراحات عبر المجالات أثناء إصدار تقرير، مثل "العناصر الموجودة لا يمكنها استبدال معدن البلاديوم، ويجب تصنيع عناصر جديدة".ورغم أن هذا الفيديو لا يتجاوز بضع عشرات من الثواني، إلا أنه يوضح تمامًا ميزات الأتمتة والذكاء والميزات القائمة على العمليات في مجال الرعاية الصحية الذكية.
ومع ذلك، في الحياة الواقعية، من أجل تحقيق نفس النتيجة، يحتاج الطاقم الطبي إلى المرور بعمليات معقدة مثل سحب الدم واختباره، وتحليل الصور، ومقارنة البيانات، وإصدار التقارير وتصنيف الأمراض. وهذا من منظور كلي فقط. إذا قمنا بتفكيكها، فإن الوضع سوف يصبح أسوأ. على سبيل المثال، باستخدام الصور الطبية، وهي النوع الأكثر شيوعًا في التشخيص السريري، يمكن للصور الطبية وصف النتائج السريرية وتوفير أساس لمزيد من تشخيص المرض. ومع ذلك، عندما يتعلق الأمر بوصف تقرير عن الصور الطبية باللغة الطبيعية بشكل دقيق وموجز وكامل ومتماسك، يجد العديد من العاملين في المجال الطبي أن هذا الأمر مزعج وممل.تشير الإحصائيات إلى أنه حتى بالنسبة للأطباء ذوي الخبرة، يستغرق الأمر عادةً في المتوسط 5 دقائق أو أكثر لإكمال التقرير.
ولحسن الحظ، ورغم أن الخيال العلمي لم يتمكن بعد من تسليط الضوء على الواقع بالكامل، فقد ظهر بالفعل بريق من الضوء من خلال الشقوق في الظلام. في تقاطع الذكاء الاصطناعي والصحة الطبية، أجرى المزيد والمزيد من الباحثين العلميين أبحاثًا مكثفة وطوروا أساليب لإنشاء التقارير تلقائيًا. تعمل هذه الطرق بشكل تلقائي على إنشاء مسودات التقارير ليقوم الطاقم الطبي بمراجعتها وتعديلها والرجوع إليها. من ناحية، يمكنها حل مهام العمل التي تستغرق وقتًا طويلاً وتتطلب جهدًا كبيرًا للطاقم الطبي بشكل فعال، ومن ناحية أخرى، يمكنها تقليل احتمالية الأخطاء البشرية من خلال الأتمتة.
نشرت مؤخرًا مجلة npj Digital Medicine، وهي مجلة تابعة للمجلة الأكاديمية المشهورة عالميًا Nature Portfolio، دراسة بعنوان "نموذج أساسي طبي متعدد الوسائط ومتعدد المجالات ومتعدد اللغات للتشخيص السريري بدون حقنة".ويشير إلى نموذج أساسي طبي متعدد الوسائط (الصورة والنص)، ومتعدد المجالات (التصوير المقطعي المحوسب والتصوير المقطعي بالأشعة السينية)، ومتعدد اللغات (الصينية والإنجليزية) M³FM (نموذج أساسي طبي متعدد الوسائط ومتعدد المجالات ومتعدد اللغات)، والذي يمكن استخدامه للتشخيص السريري بدون عينة ودعم الإبلاغ عن الأمراض وتصنيفها.وأثبت الباحثون فعالية هذه الطريقة على تسع مجموعات بيانات مرجعية لاثنين من الأمراض المعدية و14 مرضًا غير معدي، متفوقين على الطرق السابقة.
تتمتع الدراسة بتشكيلة فاخرة من المؤلفين. وبالإضافة إلى فرق من جامعة أكسفورد وجامعة روتشستر وأمازون ومؤسسات أخرى، يضم الفريق أيضًا الدكتور تشنغ يي فنغ من مختبر الذكاء الاصطناعي الطبي بجامعة ويستليك والدكتور وو شيان، رئيس مركز تيانيان للأبحاث في مختبر تينسنت يوتيوب.

عنوان الورقة:
https://www.nature.com/articles/s41746-024-01339-7
يجمع مشروع المصدر المفتوح "awesome-ai4s" أكثر من 200 تفسير لورقة AI4S ويوفر مجموعات بيانات وأدوات ضخمة:
https://github.com/hyperai/awesome-ai4s
لا يزال فقدان البيانات يمثل نقطة ضعف للطرق الحالية
يشكل التصوير الطبي أساس تقارير التصوير الطبي وتصنيف الأمراض، ويلعب دورًا مهمًا في التشخيص السريري اللاحق. ولذلك، أصبح البحث في طرق الأتمتة ذات الصلة بطبيعة الحال أحد محاور البحث في مجال البحث العلمي. ومع ذلك، وعلى الرغم من نتائج البحوث المثمرة، لا تزال هناك العديد من النواقص من الناحية العملية.ومن بين هذه التحديات، يشكل ندرة البيانات أو حتى الافتقار إليها بالكامل تحدياً رئيسياً.
من ناحية،تتشابه عملية إنشاء تقرير المرض مع مهمة إنشاء اللغة القائمة على الصور، حيث يكون الهدف هو إنشاء نص وصفي لوصف الصورة المدخلة. تعتمد الطرق الأساسية التقليدية في كثير من الأحيان بشكل كبير على كميات كبيرة من بيانات التدريب الطبي عالية الجودة التي يشرحها الأطباء، وهو أمر مكلف ويستغرق وقتًا طويلاً لجمعه، خاصة بالنسبة للأمراض النادرة واللغات غير الإنجليزية.
وعلى وجه التحديد، بالنسبة للأمراض الجديدة أو النادرة، عادة ما تفتقر هذه الأمراض إلى بيانات فعالة كافية للتدريب في المراحل المبكرة. على سبيل المثال، كان فيروس كورونا المستجد الذي بدأ ينتشر في جميع أنحاء العالم في أواخر عام 2019 يحتوي على بيانات محدودة يمكن جمعها في المراحل المبكرة، مما أدى إلى تجاوز وقت تدريب النظام مدة الموجات القليلة الأولى من الوباء بشكل كبير. وفقًا لتقرير "مراقبة اتجاهات صناعة الأمراض النادرة في الصين لعام 2024"، يوجد أكثر من 7000 مرض نادر معروف في العالم. وتشير تقديرات البيانات المحافظة المستندة إلى الأدلة إلى أن معدل انتشار الأمراض النادرة في السكان يتراوح بين 3.5% و5.9% تقريباً، وأن عدد الأشخاص المصابين بالأمراض النادرة في جميع أنحاء العالم يتراوح بين 260 مليون و450 مليون تقريباً. لا شك أن مثل هذا المرض الكبير وغير النمطي يجعل المشاكل المذكورة أعلاه أكثر تحديًا.
علاوة على ذلك، يشمل نظام الرعاية الصحية العالمي مناطق مختلفة، وسكان مختلفين، ولغات مختلفة. بالنسبة للغات الأخرى غير الإنجليزية، عادة ما تكون البيانات المصنفة ذات الصلة نادرة جدًا أو حتى مفقودة تمامًا. لذلك، فإن البيانات المحدودة المصنفة تشكل بلا شك تحديًا كبيرًا لأنظمة التدريب على اللغات غير الإنجليزية التي تستخدم الأساليب الحالية. وفي الوقت نفسه، فإن هذا يجعل أيضًا من الصعب التعامل مع اللغات غير الشائعة باستخدام الأساليب الحالية، مما يؤثر بشكل أكبر على هدف العدالة في مجال الذكاء الاصطناعي ويفشل في تحقيق الاستفادة الكاملة للمجموعات غير الممثلة.
على الجانب الآخر،من أجل تصنيف الأمراض بشكل فعال، تستلهم النماذج المتقدمة الحالية في الغالب من نجاح CLIP، مثل BioViL وREFERS وMedKLIP وMRM، والتي تم تطويرها جميعها لفهم البيانات الطبية المتعددة الوسائط بشكل أفضل. في التنفيذ، تستفيد هذه الأساليب من التعلم التبايني وتدريب نماذج CLIP مسبقًا باستخدام البيانات الطبية، ولكن نظرًا لأن معظم النماذج خاصة بأشعة الصدر السينية (CXR)، فإنها تفشل عمومًا في التعامل مع الصور والنصوص الطبية متعددة المجالات ومتعددة اللغات ضمن إطار عمل واحد. وفي الوقت نفسه، فشلت الأعمال السابقة أيضًا في إجراء تقارير عن الأمراض غير المحددة في مجالات مختلفة من اللغة والصور.
* نموذج CLIP هو نموذج تدريب مسبق للغة الصورة المتباينة تم تطويره بواسطة OpenAI - وهي طريقة فعالة للتعلم من الإشراف على اللغة الطبيعية. يتعلم CLIP بشكل أساسي الارتباط بين الصور والنص من خلال التعلم التبايني، ويقوم بتدريب مسبق على أزواج الصور والنصوص واسعة النطاق، حتى يتمكن النموذج من فهم المعلومات وربطها من وسائط مختلفة.
وفي هذا السياق، من الضروري تطوير نموذج قادر على إجراء تشخيص سريري متعدد الوسائط ومتعدد المجالات ومتعدد اللغات باستخدام عينات قليلة أو معدومة.وتتمثل الابتكارات المحددة المقترحة في هذه الدراسة فيما يلي:
* يُعد نموذج M³FM المقترح أول محاولة لإجراء تشخيص سريري متعدد الوسائط ومتعدد المجالات ومتعدد اللغات، حيث تكون البيانات المصنفة للتدريب نادرة أو مفقودة تمامًا؛
* يثبت M³FM فعاليته على 9 مجموعات بيانات، بما في ذلك مجالين من بيانات التصوير الطبي، وهما CXR وCT؛ لغتين مختلفتين، وهما الصينية والإنجليزية؛ مهمتان للتشخيص السريري، وهما الإبلاغ عن المرض وتصنيف المرض؛ وأمراض متعددة، منها 2 أمراض معدية و14 مرضاً غير معدي.
M³FM: وحدتان رئيسيتان، تم التحقق منهما من خلال مجموعات بيانات متعددة
في هذه الدراسة، الفكرة الرئيسية لنموذج M³FM المقترح هي تدريب النموذج مسبقًا على البيانات الطبية العامة عبر الوسائط والمجالات واللغات من أجل تعلم معرفة واسعة ومن ثم الاستفادة من هذه المعرفة لإنجاز المهام اللاحقة دون الحاجة إلى بيانات مصنفة. تتضمن المكونات الرئيسية لإطار عمل M³FM وحدتين رئيسيتين،وهذا يعني MultiMedCLIP وMultiMedLM. كما هو موضح في الشكل التالي:
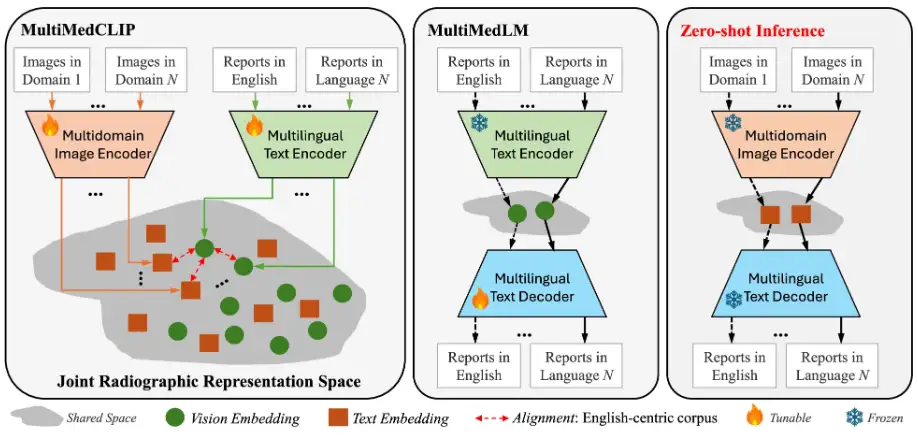
تتمثل العملية في أن MultiMedCLIP يقوم بمحاذاة وربط اللغات والصور المختلفة في مساحة كامنة مشتركة.ثم يقوم MultiMedLM بإعادة بناء النص استنادًا إلى تمثيل النص في المساحة الكامنة المشتركة، وأخيرًا يقوم M³FM بإنشاء تقارير متعددة اللغات استنادًا مباشرة إلى التمثيل المرئي للصور المدخلة من مجالات مختلفة في المساحة الكامنة الموحدة.
على وجه التحديد، MultiMedCLIP هي وحدة لتعلم التمثيلات المشتركة، والتي تقدم مشفرًا بصريًا متعدد المجالات ومشفرًا نصيًا متعدد اللغات، بهدف إنشاء مساحة كامنة مشتركة لمواءمة التمثيلات البصرية والنصية من مجالات التصوير الطبي المختلفة واللغات المختلفة. باستخدام أسلوب التعلم التبايني، استخدم الباحثون فقدان InfoNCE (تقدير تباين ضوضاء المعلومات) وخسارة MSE (خطأ التربيع المتوسط) كأهداف تدريبية لتعظيم التشابه بين أزواج العينات الإيجابية وتقليل التشابه بين أزواج العينات السلبية، وبالتالي تحقيق التوافق بين التمثيلات المرئية في مجالات مختلفة وتمثيلات النصوص بلغات مختلفة، مما يضع أساسًا متينًا للتفكير في اللقطة الصفرية اللاحقة.
MultiMedLM هي وحدة لإنشاء تقارير متعددة اللغات.تم تقديم فك تشفير نص متعدد اللغات، والذي يهدف إلى تعلم كيفية إنشاء التقرير الطبي النهائي استنادًا إلى التمثيلات المستخرجة بواسطة MultiMedCLIP. يتم تدريب هذا الجزء عن طريق إعادة بناء النص المدخل، والذي يمكن أن يكون نصًا صينيًا أو نصًا إنجليزيًا، ويستخدم خسارة توليد اللغة الطبيعية - خسارة XE (الانتروبيا المتقاطعة) كهدف للتدريب. ومن الجدير بالذكر أن تقديم تدريب إعادة البناء يمكن اعتباره تدريبًا غير خاضع للإشراف، والذي يتطلب فقط بيانات نصية عادية غير مصنفة للتدريب. لذلك، ليست هناك حاجة لتدريب بيانات شرح المهمة على المهام اللاحقة. بالإضافة إلى ذلك، ولضمان استقرار تدريب MultiMedLM، قدم فريق البحث أيضًا التسرب العشوائي والضوضاء الغوسية.
تم استخدام مُحسِّن AdamW في التجربة، مع ضبط معدل التعلم على 1e-4 وضبط حجم الدفعة على 32. أُجريت التجارب على PyTorch ووحدة معالجة الرسومات V100، باستخدام تدريب الدقة المختلطة.
من حيث مجموعات البيانات،تم إجراء التدريب المسبق على مجموعات بيانات MIMC-CXR وCOVID-19-CT-CXR، حيث يتكون MIMC-CXR من 377,110 صورة CXR و227,835 تقرير أشعة باللغة الإنجليزية، وهي أكبر مجموعة بيانات تم إصدارها حتى الآن؛ يتضمن فحص COVID-19-CT-CXR 1000 صورة CT/CXR والتقارير الإنجليزية المقابلة. بالإضافة إلى ذلك، استخرج الباحثون نصف النصوص الإنجليزية من مجموعتي البيانات واستخدموا مترجم جوجل لبناء فريق تدريب باللغتين الصينية والإنجليزية. وأظهرت النتائج أن هذه الطريقة قادرة على تحسين نتائج ترجمة النصوص الآلية.
خلال مرحلة التقييم، تضمنت مجموعات البيانات المستخدمة IU-Xray، وCOVID-19 CT، وCOV-CTR، ومجموعة بيانات السل في شنتشن، وCOVID-CXR، وNIH ChestX-ray، وCheXpert، وRSNA Pneumonia، وSIIM-ACR Emphysema، مما يتيح تقييمًا شاملاً لأداء النموذج.
* IU-Xray:وشملت الدراسة 7,470 صورة أشعة سينية على الصدر و3,955 تقرير أشعة باللغة الإنجليزية. يتم تقسيم مجموعة البيانات بشكل عشوائي إلى 80% – 10% – 10% للتدريب والتحقق والاختبار.
* كوفيد-19 CT:ويحتوي على 1,104 صورة مقطعية و368 تقرير أشعة صيني. وبالمثل، يتم تقسيم مجموعة البيانات عشوائيًا إلى 80% – 10% – 10% للتدريب والتحقق والاختبار.
*COV-CTR:يحتوي على 726 صورة مقطعية لفيروس كورونا المستجد (كوفيد-19)، مرتبطة بتقارير باللغتين الصينية والإنجليزية.
* مجموعة بيانات مرض السل في شنتشن:يحتوي على 662 صورة CXR، ومجموعات التدريب والتحقق والاختبار مقسمة إلى 7:1:2.
* كوفيد-CXR:تحتوي مجموعة البيانات على أكثر من 900 صورة CXR، وهي مقسمة عشوائيًا إلى 80% – 10% – 10% للتدريب والتحقق والاختبار.
* أشعة الصدر NIH:يحتوي على 112,120 صورة أشعة سينية مقطعية، كل صورة مُسمّاة بوقوع 14 مرضًا إشعاعيًا شائعًا، ونسبة مجموعات التدريب والتحقق والاختبار هي 7:1:2.
* تشي إكسبيرت:يحتوي على أكثر من 220،000 صورة تشخيصية للقلب. بعد المعالجة المسبقة، حصلنا على 218,414 صورة في مجموعة التدريب، و5,000 صورة في مجموعة التحقق، و234 صورة في مجموعة الاختبار.
* الالتهاب الرئوي RSNA:يتكون من حوالي 30 ألف صورة أشعة، مع نسب التدريب والتحقق ومجموعات الاختبار 85% – 5% – 10%.
* انتفاخ الرئة SIIM-ACR:ويحتوي على 12047 صورة CXR، مع نسبة مجموعات التدريب والتحقق والاختبار 70% – 15% – 15%.
تظهر التجارب أن M³FM يتمتع بأداء متفوق، متجاوزًا الطرق المتقدمة السابقة.كما هو موضح في الشكل أدناه. كما هو موضح في نتائج الإبلاغ عن الأمراض، فإن الطرق السابقة غير قادرة على التعامل مع مهمة الإبلاغ عن الأمراض في وضع اللقطة الصفرية، في حين أن M³FM قادر على إجراء تقارير عن الأمراض متعددة اللغات ومتعددة المجالات في وقت واحد في إطار واحد. في إعداد اللقطات القليلة، عند تدريبه باستخدام بيانات 10% المصبوبة، يحقق M³FM نتائج متطورة، حتى أنه يتفوق على نهج الإشراف الكامل R2Gen في توليد تقرير CT-to-Chinese من خلال درجات CIDEr الخاصة بـ 1.5% وROUGE-L الخاصة بـ 1.2%.يوضح هذا أن M³FM يمكنه إنشاء تقارير متعددة اللغات دقيقة وصحيحة حتى عندما تكون البيانات المصنفة نادرة، وبالتالي سيكون مفيدًا بشكل خاص للأمراض النادرة أو الناشئة.
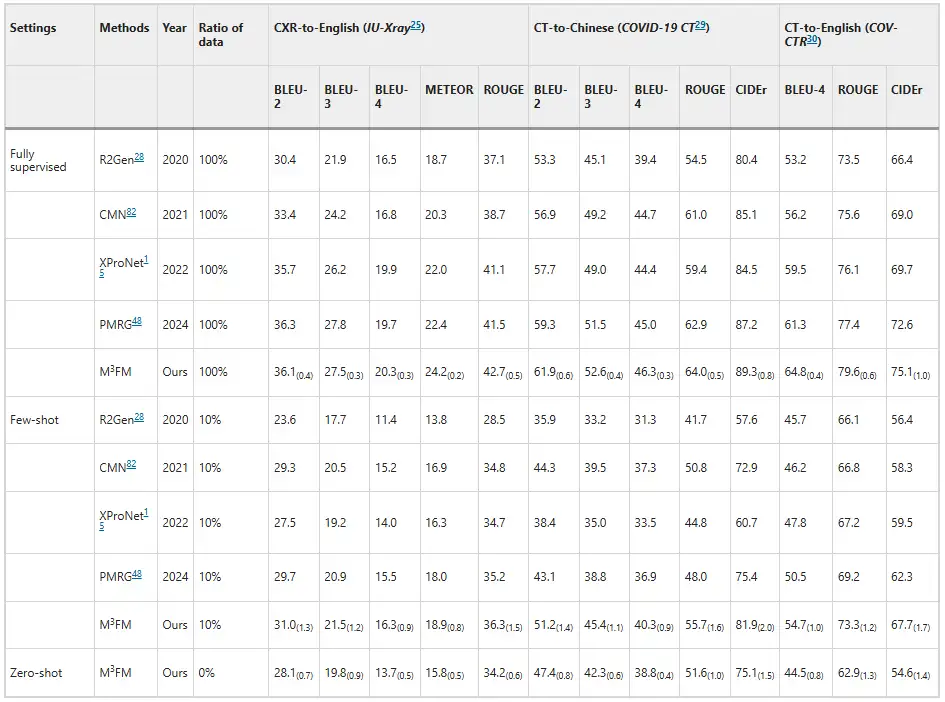
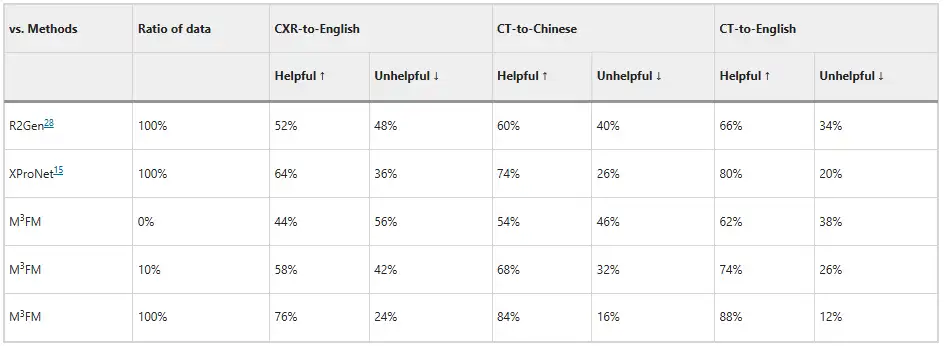
بالإضافة إلى ذلك، قام الباحثون بدعوة اثنين من الأطباء لتقييم النموذج، وتظهر النتائج في الشكل أدناه. بدون أي تدريب للبيانات المصنفة، يمكن لـ M³FM إنشاء تقارير مثالية متعددة اللغات ومتعددة المجالات؛ عندما يتم استخدام 10% فقط من البيانات المسمىة للتدريب، يمكن أن يكون M³FM أعلى بمقدار 6% و8% و8% من الطريقة الخاضعة للإشراف الكامل R2Gen في مهام CXR-to-English وCT-to-Chinese وCT-to-English على التوالي؛ عند استخدام بيانات التدريب الكاملة، يمكن لـ M³FM تحسين R2Gen بما يزيد عن 20% في ثلاث مهام، وبمقدار 12% و10% و8% أعلى من XProNet على التوالي.يوضح هذا إمكانات M³FM في تحرير الأطباء من مهمة كتابة التقارير التي تستغرق وقتًا طويلاً وتتطلب جهدًا كبيرًا.
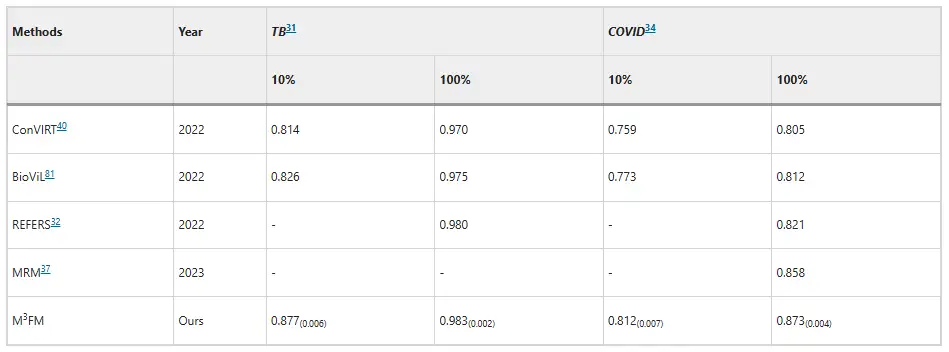
من حيث تصنيف المرض، أظهر M³FM تفوقًا في تشخيص الأمراض المعدية.في مجموعة بيانات مرض السل في شنتشن ومجموعة بيانات كوفيد-CXR، عند استخدام 10% من بيانات التدريب، كانت درجات AUC لـ M³FM أعلى بمقدار 5.1% و3.9% من أفضل النتائج الموجودة، على التوالي. عندما تم استخدام بيانات التدريب بالكامل، حقق M³FM أفضل النتائج في مرضين معديين. وفيما يتعلق بالأمراض غير المعدية، جاءت مجموعة البيانات من NIH ChestX-ray، وحققت M³FM نتائج مماثلة مع طريقة الإشراف الكامل Model Genesis مع 1% فقط من ملصقات التدريب. في 10%، تفوقت M³FM على الطرق الأساسية MRM وREFERS في تشخيص أمراض متعددة، مما أكد أيضًا فعالية وقدرة M³FM على التعميم في تشخيص المرض.
الذكاء الاصطناعي يقود الرعاية الصحية الذكية، وفريق تشنغ يي فنغ يتولى زمام المبادرة
في السابق، ركزت العديد من المختبرات على هذه القضية، وكانت النماذج التي اقترحتها تتميز بتركيزات ومزايا مختلفة.
على سبيل المثال، فيما يتعلق بالإنشاء التلقائي للتقارير، نشرت كلية علوم وتكنولوجيا المعلومات بجامعة داليان البحرية ورقة بحثية بعنوان "DACG: نموذج التوجيه المزدوج للانتباه والسياق لإنشاء تقارير الأشعة" في المنتدى المهني لتحليل الصور الطبية في مجال تحليل الصور الطبية والبيولوجية. اقترحت الورقة نموذجًا مزدوجًا للانتباه والتوجيه السياقي (DACG) لتوليد تقارير الأشعة تلقائيًا، والذي يمكن أن يخفف من تحيز البيانات المرئية والنصية ويعزز توليد النصوص الطويلة.
عنوان الورقة:
https://www.sciencedirect.com/science/article/abs/pii/S1361841524003025
هناك أيضًا نماذج مصممة للغات متعددة. على سبيل المثال، قام فريق البروفيسور وانج يانفينج والبروفيسور شي ويدي من جامعة شنغهاي جياو تونغ بإنشاء مجموعة طبية متعددة اللغات MMedC تحتوي على 25.5 مليار رمز، وتطوير معيار تقييم الأسئلة والأجوبة الطبية متعدد اللغات MMedBench يغطي 6 لغات، وبناء نموذج أساسي 8B MMed-Llama 3، والذي تجاوز نماذج المصدر المفتوح الموجودة في اختبارات معيارية متعددة وهو أكثر ملاءمة لسيناريوهات التطبيقات الطبية. وقد نُشرت نتائج البحث ذات الصلة في مجلة Nature Communications تحت عنوان "نحو بناء نموذج لغوي متعدد اللغات للطب".
انقريفحصتقرير مفصل: اختبار المعيار في المجال الطبي يتجاوز Llama 3 ويقترب من GPT-4. أصدر فريق جامعة شنغهاي جياوتونغ نموذجًا طبيًا متعدد اللغات يغطي 6 لغات
وبالمقارنة، فإن الأداء المتميز لـ M³FM في تعدد الوسائط والمجالات واللغات وغيرها من الجوانب سيجلب بلا شك حيوية جديدة لتقاطع الذكاء الاصطناعي والرعاية الصحية.وبالطبع، عندما نتحدث عن هذا البحث، لا بد أن نذكر الدكتور تشنغ يي فنغ، أحد مؤلفي هذه المقالة.
وفي الواقع، يمكن القول إن هذه الورقة هي نتيجة تم إنتاجها حديثًا، ويمكن أيضًا اعتبارها علامة على بداية جديدة للدكتور تشنغ يي فنغ. في 29 يوليو 2024، انضم زميل IEEE وزميل AIMBE وعالم الذكاء الاصطناعي الطبي Zheng Yefeng إلى جامعة ويستليك بدوام كامل، وتم تعيينه أستاذاً في كلية الهندسة، وأسس مختبر الذكاء الاصطناعي الطبي. تشمل اتجاهات البحث في المختبر تحليل الصور الطبية، وفهم اللغة الطبيعية الطبية، وعلم المعلومات الحيوية، وما إلى ذلك. وتعد هذه المقالة واحدة من الإنجازات المهمة في السنة الأولى للمختبر.
بالإضافة إلى هذا الإنجاز، نشر المختبر أيضًا العديد من الأوراق في مجال الصحة الطبية، مثل الدراسة التي تحمل عنوان "إطلاق العنان لإمكانات البيانات ضعيفة التصنيف: إطار عمل تعليمي مشترك لكشف الشذوذ وتوليد التقارير"، والتي تقدم إطار عمل تعاوني لكشف الشذوذ وتوليد التقارير (CoE-DG) يستخدم البيانات ذات التصنيف الكامل والضعيف لتعزيز التطوير المتبادل لمهمتي كشف الشذوذ في تصوير الصدر بالأشعة السينية وتوليد التقارير. تم نشر هذا البحث في مجلة IEEE Transactions on Medical Imaging.
بالطبع، يمتلك المختبر أيضًا نتائج بحثية حول نماذج اللغة الكبيرة الشائعة حاليًا، مثل الدراسة المعنونة "تخفيف هلوسات نماذج اللغة الكبيرة في استخراج المعلومات الطبية عبر فك التشفير التبايني"، والتي نُشرت في مجلة EMNLP 2024. تقدم هذه الورقة البحثية حلاً لظاهرة تعرض طلاب الماجستير في القانون لـ"الهلوسة" في الحالات الطبية، وتقترح "فك تشفير تبايني بديل" (ALCD). يمكن أن تقلل هذه الطريقة بشكل كبير من حدوث الأخطاء عن طريق فصل قدرات التعرف والتصنيف للنموذج وضبط أوزان الاثنين بشكل ديناميكي أثناء عملية التنبؤ. وتؤدي هذه التقنية أداءً جيدًا في العديد من المهام الطبية.
ربما لا تزال هذه الإنجازات اليوم في المختبرات أو لديها الزخم اللازم لتطبيقها، ولكن في النهاية، سوف يقود الذكاء الاصطناعي مجال الرعاية الصحية نحو الذكاء والذكاء والأتمتة. كما قال الدكتور تشنغ يي فنغ: "الذكاء الاصطناعي الطبي مجال يتطور بسرعة. أتوقع أنه خلال 10-15 عامًا، سيتمكن الذكاء الاصطناعي من تحقيق دقة تشخيص الأطباء وعلاجهم، ويمكن استخدامه على نطاق واسع".
مراجع:
1.https://www.nature.com/articles/s41746-024-01339-7
2.https://mp.weixin.qq.com/s/pMNXAvzgGRpPwqVtCWjXbA
3.https://mp.weixin.qq.com/s/6hw6EJY6slAIRbGGN9XY9g








