Command Palette
Search for a command to run...
تم زيادة سرعة الاستدلال بمقدار 1.7 مرة، تم إصدار الإصدار vLLM v1! تم إطلاق أول معيار منطقي متعدد الوسائط خطوة بخطوة VRC-Bench مع أكثر من 4 آلاف خطوة توضيحية

في الشهر الماضي، وعلى خلفية زيادة الطلب على استدلال النماذج الكبيرة، أعلن إطار عمل استدلال النماذج الكبيرة للذكاء الاصطناعي vLLM رسميًا عن إصدار v1.0. بالمقارنة مع الإصدارات السابقة، تم تحسين كفاءة الحوسبة بشكل كبير، وأصبح تصميم واجهة برمجة التطبيقات أكثر استقرارًا، وتم إطلاق العنان لإمكانات الأجهزة بالكامل، وتم زيادة سرعة الاستدلال بمقدار 1.7 مرة! إنه يوفر دعمًا أقوى للنشر الفعال للنماذج التي تحتوي على عشرات المليارات من المعلمات.
في الوقت الحالي،تم إطلاق البرنامج التعليمي التمهيدي لـ vLLM على الموقع الرسمي لـ hyper.ai، والذي سيأخذك من التثبيت إلى التشغيل، حتى تتمكن من إتقان vLLM بسرعة!
دليل البدء في برنامج vLLM:https://go.hyper.ai/qHl62
لمزيد من مستندات ودورات vLLM الصينية، يرجى زيارة → https://vllm.hyper.ai
من 5 فبراير إلى 14 فبراير، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 6
* اختيار المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في فبراير: 3
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات معيار التفكير البصري VRC-Bench
تغطي مجموعة البيانات التحديات في ثمانية مجالات مختلفة، بما في ذلك التفكير البصري، والتفكير الرياضي والمنطقي، والتفكير العلمي، والفهم الثقافي والاجتماعي، وما إلى ذلك. وتحتوي على أكثر من 4 آلاف خطوة تفكير تم التحقق منها يدويًا، والتي يمكنها تقييم دقة وتماسك النموذج المنطقي بشكل شامل في التفكير متعدد الخطوات.
الاستخدام المباشر:https://go.hyper.ai/AV43N

2. مجموعة بيانات Terra متعددة الوسائط المكانية والزمانية
Terra هي مجموعة بيانات مكانية زمنية متعددة الوسائط ذات تغطية عالمية، وتوفر 45 عامًا من البيانات المكانية الزمنية في جميع أنحاء العالم، وتغطي 6.48 مليون نقطة شبكة عالية الدقة، وتهدف إلى تعزيز الأبحاث المستقبلية في مجال استخراج البيانات المكانية الزمنية وتعزيز تحقيق الذكاء المكاني الزمني الأوسع.
الاستخدام المباشر:https://go.hyper.ai/9eev3

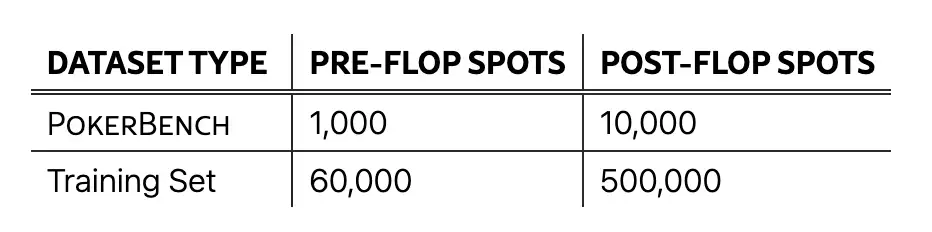
3. مجموعة بيانات تقييم لعبة البوكر PokerBench
تحتوي مجموعة البيانات على 11 ألف مشهد رئيسي، مقسمة إلى 1000 مشهد قبل الدخول في اللعبة و10 آلاف مشهد بعد الدخول في اللعبة، وتغطي مجموعة واسعة من مواقف اللعبة وهي مصممة لتقييم أداء نماذج اللغة الكبيرة (LLMs) في ألعاب البوكر المعقدة والاستراتيجية.
الاستخدام المباشر:https://go.hyper.ai/HK73H
تحتوي مجموعة البيانات هذه على بيانات مناطق الجذب السياحي من 352 مدينة في الصين. يحتوي ملف csv لكل مدينة على 100 موقع. تتضمن البيانات اسم الموقع، وموقع الويب، والعنوان، ومقدمة المعالم السياحية، وساعات العمل، وعنوان URL للصورة، والتقييم، ومدة الزيارة الموصى بها، وموسم الزيارة الموصى به، ومعلومات التذاكر، والنصائح، وغيرها من المعلومات.
الاستخدام المباشر:https://go.hyper.ai/uZ5Wh
5. مجموعة بيانات فيديو لعبة GF-Minecraft
تقوم مجموعة البيانات هذه بتجميع 70 ساعة من مقاطع فيديو الألعاب من خلال تنفيذ تسلسلات عمل عشوائية محددة مسبقًا وشرحها. تم تكوين مجموعة البيانات مسبقًا بثلاث مناطق حيوية (الغابات والسهول والصحراء)، وثلاث ظروف جوية (صافي، ممطر، عاصفة رعدية)، و6 فترات زمنية (على سبيل المثال، شروق الشمس، الظهيرة، منتصف الليل)، مما يؤدي إلى إنشاء أكثر من 2 كيلو مقطع فيديو.
الاستخدام المباشر:https://go.hyper.ai/25DAe
6. مجموعة بيانات الضبط الدقيق للثقافة الوطنية التابعة لمركز NCIFD
تُعد مجموعة البيانات هذه مجموعة بيانات لضبط الثقافة الوطنية للنماذج الكبيرة، وتحتوي على 151,159 عنصر بيانات، تغطي سبعة مجالات رئيسية: الهندسة المعمارية، والملابس، والحرف اليدوية، والطعام، وآداب السلوك، واللغة، والعادات.
الاستخدام المباشر:https://go.hyper.ai/Vd6ZP
7. مجموعة بيانات التدريب على الاستدلال الرياضي من AceMath Instruct
هذه المجموعة من البيانات هي مجموعة بيانات أصدرتها NVIDIA في عام 2025 لتدريب نموذج AceMath، بهدف تحسين أداء النموذج في مهام التفكير الرياضي.
الاستخدام المباشر:https://go.hyper.ai/pT5Tr
8. مجموعة بيانات تقييم استدعاءات الوظائف المعقدة ComplexFuncBench
تغطي مجموعة البيانات 1000 عينة من استدعاءات الوظائف المعقدة في 5 سيناريوهات واقعية، بما في ذلك 600 عينة من نطاق واحد، و150 عينة من كل من الفنادق والرحلات الجوية وتأجير السيارات والمعالم السياحية، و400 عينة من نطاقات متعددة. يحتوي نطاق التاكسي على وظيفتين فقط، لذا يتم استخدامه عبر النطاقات فقط.
الاستخدام المباشر:https://go.hyper.ai/v0p4c
9. مجموعة بيانات تخطيط السفر TravelPlanner
تحتوي مجموعة البيانات على 1225 خطة تخطيطية وخطط مرجعية مختارة. تم إعداد مجموعة البيانات في سياق تخطيط السفر وتتطلب من وكيل اللغة إنشاء خطة سفر شاملة بناءً على استعلام معين، بما في ذلك النقل والوجبات اليومية والمعالم السياحية والإقامة.
الاستخدام المباشر:https://go.hyper.ai/22AhZ
10. مجموعة بيانات المركبات غير العضوية لبيانات الذوبان المائي
تحتوي مجموعة البيانات هذه على بيانات تجريبية حول ذوبان مئات المركبات غير العضوية في الماء. تم الحصول على البيانات من مراجع متعددة وهي مناسبة لمجال معلوماتية المواد. يتم التعبير عن جميع بيانات الذوبان بالجرام من المواد المذابة لكل 100 جرام من الماء.
الاستخدام المباشر:https://go.hyper.ai/dqL1y
دروس تعليمية عامة مختارة
1. دليل البدء في برنامج vLLM: دليل خطوة بخطوة للمبتدئين
vLLM هو إطار عمل مصمم خصيصًا لتسريع عملية التفكير في نماذج اللغة الكبيرة. وقد حظيت باهتمام واسع النطاق في جميع أنحاء العالم بسبب كفاءتها الممتازة في التفكير وقدراتها على تحسين الموارد. قام الباحثون ببناء محرك خدمة LLM عالي الإنتاجية vLLM، وحققوا هدرًا شبه معدوم لذاكرة التخزين المؤقت KV، وحلوا مشكلة عنق الزجاجة لإدارة الذاكرة في التفكير في نموذج اللغة الكبير.
يوضح لك هذا البرنامج التعليمي خطوة بخطوة كيفية تكوين وتشغيل vLLM، ويوفر دليلاً كاملاً للبدء من التثبيت حتى بدء التشغيل. انقر على الرابط أدناه واتبع البرنامج التعليمي لنشر vLLM.
تشغيل عبر الإنترنت:https://go.hyper.ai/qHl62
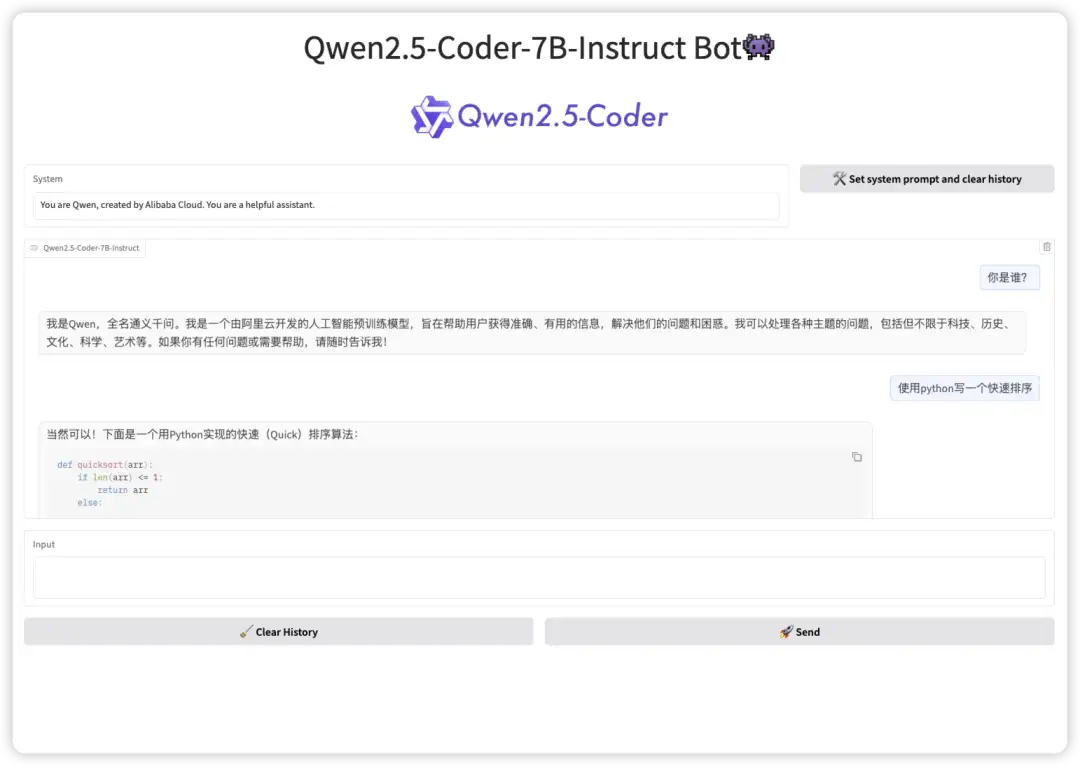
2. نشر Qwen2.5-Coder بنقرة واحدة
Qwen2.5-Coder هو مساعد ذكاء اصطناعي يتمتع بقدرات قوية على توليد التعليمات البرمجية. إنه يدعم إخراج التعليمات البرمجية بمنطق واضح وقواعد نحوية موحدة، ويوفر وظيفة Artifacts لمساعدة المستخدمين على بناء وتنفيذ مشاريع مرئية مختلفة بسرعة. فيما يتعلق بتطوير الألعاب الصغيرة، يمكن لـ Qwen2.5-Coder إنشاء كود اللعبة استنادًا إلى قواعد اللعبة وأسلوب الرسومات ومتطلبات تجربة المستخدم. يمكن للمطورين تخصيصه وتحسينه على هذا الأساس وإطلاق أعمالهم الخاصة في اللعبة بسرعة.
يمكن لهذا المشروع إنشاء واجهة تفاعلية أمامية من خلال واجهة Gradio. لقد تم نشر النماذج والتبعيات ذات الصلة. يمكنك إدخال التعليمات إلى النموذج وإنشاء الكود المطلوب بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/JVOTN
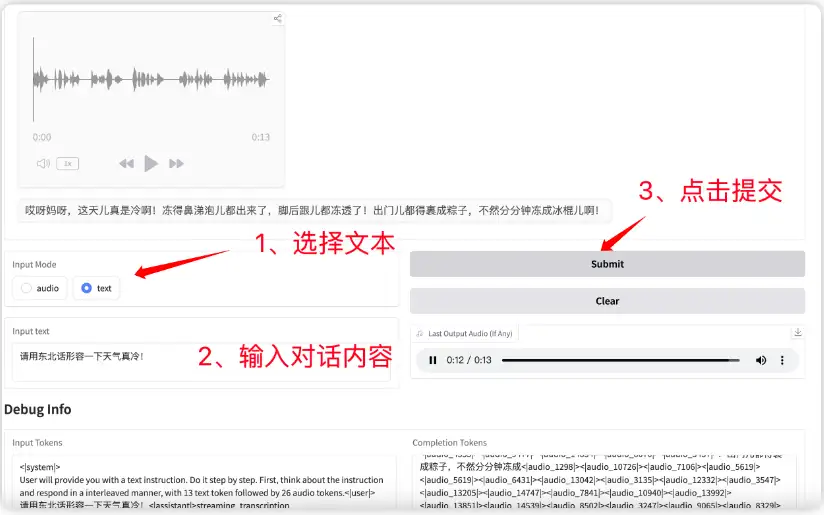
3. نموذج المحادثة الصوتية الشاملة باللغتين الصينية والإنجليزية GLM-4-Voice
GLM-4-Voice هو نموذج كلام متكامل يمكنه فهم وتوليد الكلام الصيني والإنجليزي بشكل مباشر، وإجراء محادثات صوتية في الوقت الفعلي، واتباع تعليمات المستخدم لتغيير سمات الكلام مثل العاطفة والتجويد وسرعة التحدث واللهجة.
انتقل إلى الموقع الرسمي لاستنساخ الحاوية وبدء تشغيلها، ثم انسخ عنوان API مباشرةً، ويمكنك التواصل مع النموذج.
تشغيل عبر الإنترنت:https://go.hyper.ai/s4MId
4. Linly-Dubbing تنزيل الفيديو بنقرة واحدة + الترجمة + الدبلجة + الترجمة التوضيحية
Linly-Dubbing هي أداة دبلجة وترجمة فيديو متعددة اللغات ذكية يمكنها ترجمة محتوى الفيديو تلقائيًا إلى لغات متعددة وإنشاء ترجمات.
انقر على الرابط أدناه لبدء رحلتك الإبداعية على الفور وتحقيق الدبلجة والترجمة الذكية متعددة اللغات لمقاطع الفيديو.
تشغيل عبر الإنترنت:https://go.hyper.ai/xEAzn
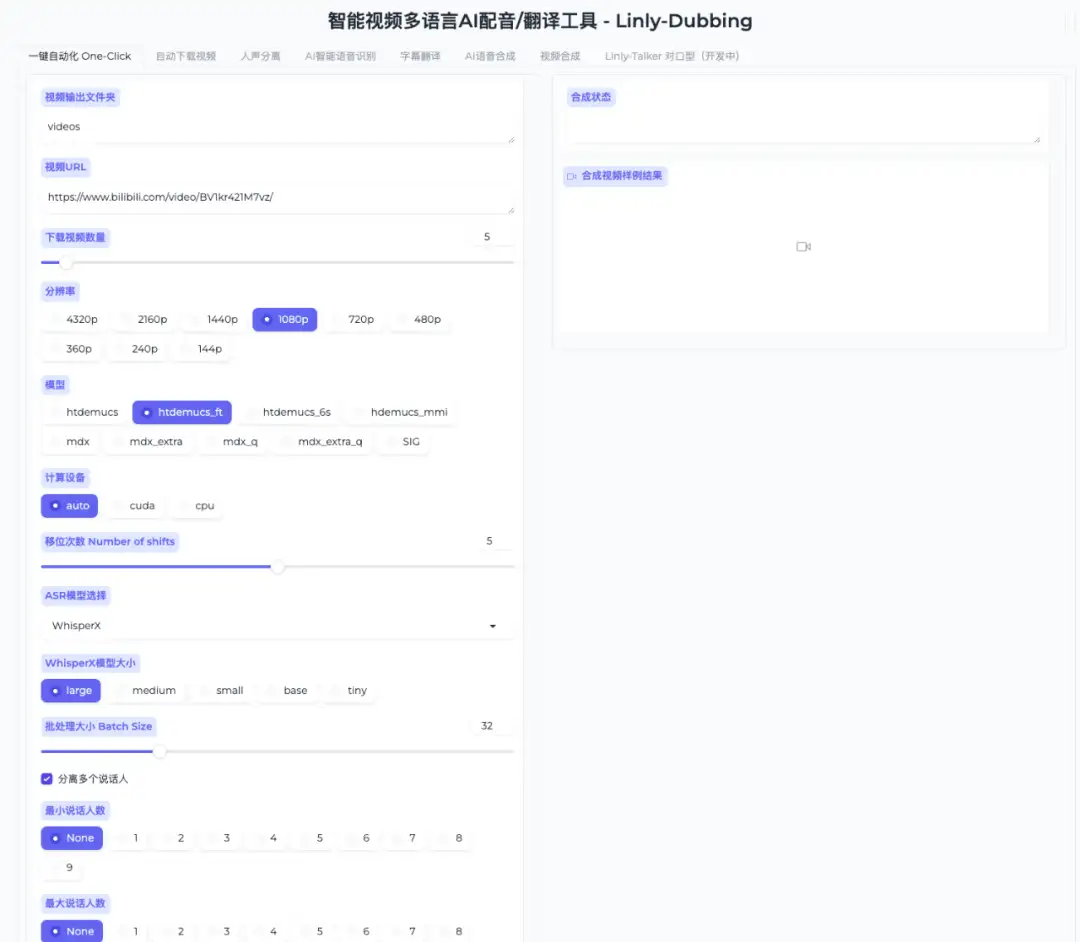
5. DrawingSpinUp: رسم شخصيات ثنائية الأبعاد → رسوم متحركة ثلاثية الأبعاد
DrawingSpinUp هي تقنية مبتكرة لإنشاء رسوم متحركة ثلاثية الأبعاد تعمل على تحويل رسومات الشخصيات المسطحة إلى رسوم متحركة ديناميكية ذات تأثيرات ثلاثية الأبعاد، مع الحفاظ بعناية على أسلوب وخصائص العمل الفني الأصلي.
اتبع خطوات البرنامج التعليمي لإنشاء رسوم متحركة ثلاثية الأبعاد واقعية ومفصلة.
تشغيل عبر الإنترنت:https://go.hyper.ai/H9fV1
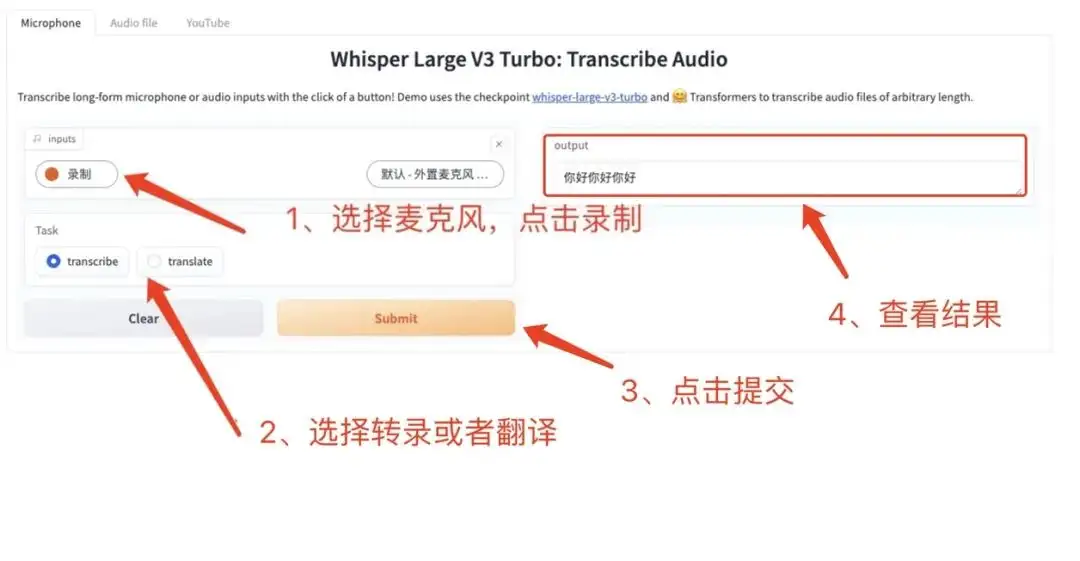
6. عرض توضيحي لتقنية التعرف على الكلام والترجمة Whisper-large-v3-turbo
Whisper هو نموذج التعرف على الكلام للأغراض العامة. يتم تدريبه على مجموعة كبيرة ومتنوعة من البيانات الصوتية ويمكنه تنفيذ مهام متعددة مثل التعرف على الكلام متعدد اللغات وترجمة الكلام.
يعد هذا البرنامج التعليمي بمثابة برنامج تعليمي للنشر بنقرة واحدة لـ whisper-large-v3-turbo. إنه أسرع بـ 8 مرات من whisper-large-v3 مع عدم فقدان الجودة تقريبًا. تم تثبيت البيئة والتبعيات ذات الصلة، ويمكنك تجربة ذلك عن طريق استنساخه وبدء تشغيله بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/3P9nk
مقالات المجتمع
شركة Generate: Biomedicines للأدوية الحيوية القائمة على الذكاء الاصطناعي، بمنصتها البيولوجية القابلة للبرمجة الفريدة، لا تدمج الذكاء الاصطناعي في هندسة البروتين فحسب، بل تساعد العلماء أيضًا على تصميم حلول أكثر كفاءة للأهداف التي يصعب علاجها تقليديًا. أعلنت شركة Generate مؤخرًا أنها حصلت على استثمار استراتيجي من Samsung Science & Life Science Fund. والأهمية وراء هذا واضحة بذاتها. هذه المقالة عبارة عن تقرير مفصل عن الشركة، اضغط لقراءته بسرعة.
عرض ملخص الحدث:https://go.hyper.ai/fVtKK
في السنوات الأخيرة، تم تطبيق الذكاء الاصطناعي تدريجيا وبشكل أعمق في مجال أبحاث الأدب الصيني القديم. في يونيو 2024، اقترحت جامعة أنيانغ العادية، بالتعاون مع جامعة هواتشونغ للعلوم والتكنولوجيا، وجامعة جنوب الصين للتكنولوجيا، وغيرها، نموذج انتشار مشروط مُحسَّن لفك تشفير عظام الوحي. ولم يتم اختيار النتائج لـ ACL 2024 فحسب، بل فازت أيضًا بجائزة أفضل ورقة بحثية بنجاح. ويظهر هذا أن الذكاء الاصطناعي يعمل على تسريع كفاءة عمل الباحثين. المزيد من التفاصيل حول كيفية تفسير الذكاء الاصطناعي لعظام أوراكل هي كما يلي.
شاهد التقرير الكامل:https://go.hyper.ai/xzw4c
لا يمكن فصل التطور السريع للذكاء الاصطناعي الطبي عن دعم مجموعات البيانات عالية الجودة. من تشخيص الأمراض إلى تطوير الأدوية إلى الطب الشخصي، تلعب مجموعات البيانات دورًا لا غنى عنه في تعزيز تطبيق الرؤية الآلية والنماذج الكبيرة وما إلى ذلك في المجال الطبي. تنظم هذه المقالة 10 مجموعات بيانات في المجال الطبي، وتغطي الطب الصيني شينونغ، وكتب الطب الصيني القديم، والمنطق الطبي، والأسئلة والأجوبة الطبية، وما إلى ذلك. يمكنك النقر للتنزيل مباشرة.
شاهد التقرير الكامل:https://go.hyper.ai/NHlJ0
أدى التطور السريع للذكاء الاصطناعي إلى توفير إمكانيات جديدة لاكتشاف الأدوية. في الآونة الأخيرة، اقترح باحثون من شركة علوم الحياة Cellarity وNVIDIA طريقة مشتركة جديدة لتحسين الجزيئات المستهدفة تعتمد على التعلم التعزيزي الكامن، MOLRL، والتي أظهرت أداءً متفوقًا في المهام المتعلقة باكتشاف الأدوية، وخاصة في توليد الجزيئات المستهدفة وتحسين المعلمات المتعددة. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/YBhnM
في الحلقة السادسة من سلسلة البث المباشر "Meet AI4S"، شارك البروفيسور Zheng Wei، أستاذ في كلية الإحصاء وعلوم البيانات بجامعة نانكاي، مع الجميع حدود AlphaFold واتجاهات التحسين المستقبلية، بالإضافة إلى الخوارزميات ومواضيع البحث التي تستحق الاستكشاف في المجتمع الأكاديمي. انظر أدناه لمزيد من التفاصيل.
شاهد التقرير الكامل:https://go.hyper.ai/YgCip
مقالات موسوعية شعبية
1. دمج الفرز المتبادل RRF
2. معلمات النموذج
3. نظرية كولموغوروف-أرنولد للتمثيل
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








