Command Palette
Search for a command to run...
نموذج لغة طبية عامة مفتوح المصدر يحتوي على 176 مليار معلمة! اقترحت جامعة بكين للتكنولوجيا/جامعة بوليتكنيك في بكين/جامعة الخوانق الثلاثة الصينية شركة MedFound، التي تتمتع بقدرة استدلالية قريبة من قدرة الأطباء الخبراء

كما يقول المثل القديم، "الخطأ من طبيعة البشر"، ولكن في المجال الطبي، فإن خطأ مثل التشخيص الخاطئ يمكن أن يكون له عواقب وخيمة. من ناحية أخرى، بالنسبة للمرضى، فإن أسوأ سيناريو محتمل هو الإنذار الكاذب، وأسوأ سيناريو محتمل هو التأخير في علاج المرض. وفي كلتا الحالتين، سوف يعاني المريض من أضرار نفسية ومادية وحتى في حياته. ومن ناحية أخرى، قد تؤثر الأحكام الخاطئة على صورة الطبيب في إنقاذ الأرواح، وقد تؤثر حتى على مصداقية النظام الطبي بأكمله. ومع ذلك، وعلى عكس التوقعات، لا يزال التشخيص الخاطئ يمثل حادثة متكررة الحدوث سواء في الداخل أو الخارج.
ذكر تشين شياوهونغ، رئيس التحرير السابق لمجلة "التشخيص السريري الخاطئ وسوء المعاملة" وأحد مؤلفي الدراسة الطبية "التشخيص الخاطئ"، في مقابلة أن معدلات التشخيص الخاطئ المذكورة في أحجام العينات في الأدبيات المحلية والأجنبية تتراوح عمومًا حول 20% إلى 40%. بالإضافة إلى ذلك، هناك إحصاءات ذات صلة في كتابه "التشخيص الخاطئ"، على سبيل المثال، يذكر أنه في 200 من بيانات مناقشة علم الأمراض السريرية التي أوردتها العديد من المجلات الطبية المحلية التمثيلية من عام 1973 إلى عام 1980، كان معدل التشخيص الخاطئ يصل إلى 48 %. ويمكن القول إن التشخيص الخاطئ أصبح تقريباً أحد أكبر العوائق أمام تقدم الطب البشري.
من أجل حل مشكلة التشخيص الخاطئ، حاولت الأعمال الطبية في العصور القديمة مثل "السجلات الطبية للجمع بين الطب الصيني والغربي" و"الأخطاء الطبية" و"التصحيحات الطبية" بذل قصارى جهدها لإدراج دروس التشخيص الخاطئ في السجلات الطبية لتحذير الأجيال القادمة؛ في العصر الحديث، وبمساعدة الأساليب الطبية الحديثة مثل الموجات فوق الصوتية B، والتصوير المقطعي المحوسب، والتصوير بالرنين المغناطيسي، أصبحت وسائل التشخيص السريري غنية ومتطورة بشكل متزايد. ومع ذلك، فإن الطب، باعتباره علمًا عمليًا وتخصصًا استكشافيًا، لا يمكنه أبدًا تجنب التشخيص الخاطئ تمامًا. ولذلك، فإن الحد من معدل التشخيص الخاطئ وتحسين دقة تشخيص الأمراض وإمكانية الوصول إليها فقط هو ما يمكننا من تمهيد الطريق لمزيد من تطوير الطب.
إذا أخذنا الذكاء الاصطناعي في مجال العلوم كنموذج جديد، فإنه يوفر أفكارًا جديدة لحل المشكلات المذكورة أعلاه. منذ بضعة أيام،قام فريق متعدد التخصصات من الهندسة الطبية يتكون من البروفيسور وانج جوانجيو من جامعة بكين للبريد والاتصالات، والبروفيسور سونج تشونلي من مستشفى جامعة بكين الثالث، والبروفيسور يانج جيان من جامعة الخوانق الثلاثة الصينية بتقديم والتحقق من MedFound (176B)، نموذج اللغة الطبية الحيوية مع أكبر عدد من المعلمات.لقد قمنا أيضًا بإنشاء MedFound-DX-PA، وهو نموذج لغوي كبير للتشخيص الطبي العام، والذي يتمتع بقدرات معرفية واستدلالية قريبة من قدرات الخبراء ويمكنه تقديم دعم تشخيصي فعال ودقيق عبر السيناريوهات الطبية.
وقد نشرت النتائج ذات الصلة في مجلة Nature Medicine تحت عنوان "نموذج لغوي طبي عام لمساعدة تشخيص الأمراض".

عنوان الورقة:
https://www.nature.com/articles/s41591-024-03416-6
قم بمتابعة الحساب الرسمي ورد "MedFound" للحصول على ملف PDF كامل
يجمع مشروع المصدر المفتوح "awesome-ai4s" أكثر من 200 تفسير لورقة AI4S ويوفر مجموعات بيانات وأدوات ضخمة:
https://github.com/hyperai/awesome-ai4s
ما هو الابتكار في MedFound؟
أكبر نموذج لغوي طبي حيوي مفتوح المصدر مع أكبر عدد من المعلمات
وقال فريق البحث إن عدم وجود برامج ماجستير في القانون مصممة بشكل جيد ومتاحة للعامة ومصممة خصيصًا للإعدادات السريرية في العالم الحقيقي هو السبب الرئيسي وراء بقاء برامج الماجستير في القانون في بداياتها في التطبيقات الطبية الحيوية. تم تدريب MedFound مسبقًا استنادًا إلى نموذج اللغة العامة الكبير BLOOM-176B، وهو نموذج لغة طبية عام كبير بمقياس معلمات يبلغ 176 مليار.
من أجل ضمان قدرة النموذج على اكتساب المعرفة الطبية العامة الشاملة، قام فريق البحث ببناء مجموعة بيانات طبية MedCorpus خصيصًا والتي تدمج المعرفة الطبية الضخمة والممارسة السريرية. وهو يتألف من إجمالي 6.3 مليار رمز نصي من 4 مجموعات بيانات، بما في ذلك MedText وPubMed Central Case Report (PMC-CR) وMIMIC-III-Note وMedDX-Note. وتغطي مجموعات البيانات هذه الأدبيات الطبية الصينية والإنجليزية، والكتب المهنية، و8.7 مليون سجل طبي إلكتروني حقيقي، وهي تشكل أساسًا مهمًا لتطبيق النموذج على التشخيص في مختلف التخصصات.
ومن الجدير بالذكر أنه وفقًا لفريق البحث، فإن MedFound أصبح الآن مفتوح المصدر ويمكنه تقديم خدمات نموذجية أساسية كبيرة للباحثين والأطباء والمؤسسات الطبية في جميع أنحاء العالم.
عنوان المشروع:
https://github.com/medfound/medfound?tab=readme-ov-file
إن قدرات التشخيص السريري المبتكرة تجعله "طبيبًا حيًا"
وعلاوة على ذلك، فإن أحد الفروق المهمة بين الآلات والبشر هو أن الأطباء البشر يمكنهم التوصل إلى استنتاجات معقولة حول الحالة الحقيقية للمريض استناداً إلى خبرتهم واحتياطياتهم المعرفية، وبالتالي تقديم علاجات متباينة. وأوضح فريق البحث أن بعض الدراسات الحالية تدمج ببساطة المعرفة السريرية في برنامج الماجستير في القانون لأغراض الأسئلة والأجوبة الطبية أو المحادثات، ولكنها لا تعكس قدرة التفكير التشخيصي السريري.
على سبيل المثال، نشر ساينان تشانغ وجيسونج سونج نتيجة في مجلة Nature، حيث طوروا واجهة محادثة تسمى Chat Ella تعتمد على التعلم الانتقالي والضبط الدقيق لـ GPT-2. يمكن للنظام التنبؤ بالأمراض المزمنة بشكل دقيق بناءً على الأعراض التي يصفها المستخدم. لكن في نهاية البحث، أشار الباحثون أيضًا إلى أوجه القصور في الدراسة، مشيرين إلى بعض القيود التي فرضتها النتائج على عملية التفكير، مثل عدم القدرة على تفسير عملية التفكير. عنوان الورقة البحثية هو "نظام الأسئلة والأجوبة القائم على روبوت المحادثة للتشخيص المساعد للأمراض المزمنة بناءً على نموذج لغوي كبير".
عنوان الورقة:
https://www.nature.com/articles/s41598-024-67429-4
لذلك، من أجل تحقيق تشخيص دقيق للمرض، لا يكفي أن يتمتع النموذج الكبير بمعرفة طبية واسعة ومتعددة التخصصات، بل يحتاج أيضًا إلى أن يكون قادرًا على إجراء تفكير معقد.وبناءً على نموذج MedFound، قام فريق البحث بإنشاء MedFound-DX، وهو نموذج لغوي كبير للتشخيص الطبي العام مع قدرات معرفية واستدلالية قريبة من تلك التي يتمتع بها الخبراء، من خلال تحسين التدريب على مرحلتين.كما هو موضح في الشكل التالي:
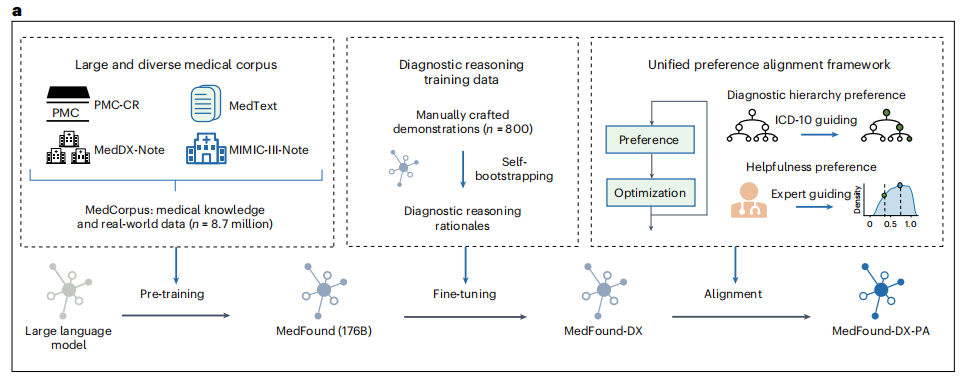
على وجه التحديد، في المرحلة الأولى، استخدم فريق البحث أسلوب سلسلة الفكر (CoT) المبني على استراتيجيات ذاتية التوجيه لتمكين النموذج الكبير من توليد أساس تشخيصي وعملية تفكير تلقائيًا مثل الخبراء الطبيين. ومع ذلك، فإن برامج الماجستير في القانون التوليدية قد تنتج "هلوسة" أو تختلق حقائق كاذبة، وإذا تم اعتماد هذه التشخيصات، فقد تكون العواقب وخيمة.
لذلك، في المرحلة الثانية، قدم فريق البحث أيضًا إطارًا موحدًا لمواءمة التفضيلات لمواءمة LLM مع نظام المعرفة في المجالات المهنية وتفضيلات التشخيص السريري لضمان أن النموذج ليس علميًا ومعقولًا فقط عند إجراء التشخيصات، ولكن أيضًا متوافقًا مع منطق وقيم الخبراء الطبيين في الممارسة السريرية. يدمج الإطار "تفضيل التسلسل الهرمي التشخيصي" و"تفضيل المساعدة"، وكلاهما يستخدم خوارزمية تحسين التفضيل المباشر (DPO) - وهي خوارزمية بسيطة لا تتطلب التعلم التعزيزي. من ناحية، يمكنه توجيه النموذج لتحسين الدقة الدقيقة لتحديد المرض، ومن ناحية أخرى، يمكنه أيضًا تحسين فعالية ومصداقية التفكير النموذجي وتقليل مخاطر المعلومات المضللة وغير الصحيحة.
ومن الجدير بالذكر أنه في عملية الضبط والتعديل الدقيق لهذا الجزء، قام فريق البحث أيضًا ببناء مجموعة بيانات خاصة تسمى MedDX-FT، والتي تحتوي على عروض توضيحية لعمليات التفكير التي كتبها الأطباء يدويًا بناءً على السجلات الطبية الحقيقية للتدريب والضبط الدقيق. تتكون مجموعة البيانات من مجموعة أساسية تعتمد على العروض التوضيحية اليدوية و109,364 ملاحظة من السجلات الصحية الإلكترونية.
تظهر نتائج العرض المذهلة إمكانيات تطبيقها المحتملة
خلال مرحلة التقييم، قام فريق البحث أيضًا ببناء مجموعة بيانات MedDX-Bench، والتي تتضمن ثلاث مجموعات بيانات سريرية: MedDX-Test وMedDX-OOD وMedDX-Rare.
* يتم استخدام مجموعة بيانات MedDX-Test لتقييم الأداء التشخيصي لـ MedFound-DX-PA في مجالات مختلفة وتحتوي على 11662 سجلاً طبيًا بنفس توزيع مجموعة بيانات التدريب.
* MedDX-OOD وMedDX-Rare عبارة عن مجموعات تحقق خارجية، تحتوي الأولى على 23,917 سجلاً للأمراض الشائعة، وتحتوي الثانية على 20,257 سجلاً لـ 2,105 أمراض نادرة، والتي لها توزيع طويل الذيل.
تتكون تجربة التقييم بشكل أساسي من ثلاث مراحل، وهي التقييم داخل التوزيع (ID)، والتقييم خارج التوزيع (OOD)، وتقييم توزيع الأمراض الطويلة الأمد. تتضمن كائنات المقارنة برامج الماجستير في القانون مفتوحة المصدر ومغلقة المصدر مثل MEDITRON-70B وClinical Camel-70B وLlama 3-70B وGPT-4o.
وتظهر النتائج أن أداءها أفضل من أداء برامج الماجستير في القانون الرائدة الأخرى.على سبيل المثال، في الأداء التشخيصي للأمراض الشائعة، يبلغ متوسط دقة Top-3 لـMedFound-DX-PA 84.2% (تحت إعداد ID)، وبالمقارنة، تبلغ دقة التشخيص لـ GPT-4o 62% فقط؛ في الأداء التشخيصي للأمراض النادرة، يبلغ متوسط دقة MedFound-DX-PA في المراكز الثلاثة الأولى في 8 تخصصات 80.7%، ويحتل GPT-4o المرتبة الثانية بمتوسط 59.1%.
ومن الجدير بالذكر أنه في المقارنة بين MedFound-DX-PA وأطباء الغدد الصماء وأطباء الرئة، كانت معدلات دقة التشخيص 74.7% و72.6% على التوالي، وهو أعلى بكثير من معدلات الأطباء ذوي سنوات الخبرة المنخفضة والمتوسطة، ومقارنتها بمعدلات الأطباء ذوي سنوات الخبرة الأعلى. ومن حيث التشخيص المساعد، فإنه يمكن أن يساعد الأطباء في هذين القسمين على تحسين دقة التشخيص بمقدار 11.9% و4.4% على التوالي. الشكل أدناه هو حالة تشخيص نموذجية بديهية.
كما هو موضح في الشكل أدناه، كان التشخيص الأولي للطبيب هو التهاب الشعب الهوائية الحاد. سلط نموذج MedFound الضوء على تاريخ المريض فيما يتعلق بالتهاب الشعب الهوائية المتكرر. وبناء على توجيهات النموذج، قام الطبيب بتعديل التشخيص إلى تفاقم حاد لالتهاب الشعب الهوائية المزمن.

كما هو موضح في الشكل أدناه، قام الطبيب في البداية بتشخيص المريض بقصور الغدة الدرقية دون السريري. أشار نموذج MedFound إلى احتمال وجود مرض الغدة الدرقية المناعي الذاتي الكامن، وقام الطبيب بمراجعة النتيجة إلى التهاب الغدة الدرقية المناعي الذاتي.

ومن الواضح أن MedFound لا يمتلك القدرة على تحسين كفاءة التشخيص ودقته فحسب، بل لديه القدرة أيضًا على أن يصبح مساعدًا تشخيصيًا للعاملين في المجال السريري.ويوفر هذا دعماً قوياً للتطوير المستقبلي للتشخيص والعلاج السريري الذكي والطب الشخصي.
تستمر AI4S في إحراز التقدم، وقد وصل عصر التنفيذ
فريق وانغ قوانغيو يواصل التقدم
وفي هذا الجهد التعاوني، بذل كل فريق قصارى جهده واستخدم خبراته للمساهمة في تحقيق هذا الإنجاز. ومن الجدير بالذكر أن البروفيسور وانغ قوانغيو من جامعة بكين للبريد والاتصالات هو أحد المؤلفين المراسلين لهذه الدراسة.
في الواقع، هذه ليست المرة الأولى التي يدمج فيها فريق البروفيسور وانغ قوانغيو الذكاء الاصطناعي مع الطب الحيوي.وباعتباره أول فائز بجائزة استكشاف العلوم بعد التسعينيات، اكتسب وانغ قوانغيو شهرة طويلة ونشر سلسلة من الإنجازات الأكاديمية الرائدة على المستوى الدولي.نُشرت أعماله في مجلات أكاديمية دولية مرموقة مثل Cell وNature Medicine وNature Biomedical Engineering.

على سبيل المثال، في عام 2020، نشر البروفيسور وانغ قوانغيو، بصفته المؤلف المراسل الأول، دراسة بعنوان "نظام الذكاء الاصطناعي القابل للتطبيق سريريًا للتشخيص الدقيق وتوقع الالتهاب الرئوي الناتج عن كوفيد-19 باستخدام التصوير المقطعي المحوسب" في المجلة الدولية الرائدة Cell. ركزت الدراسة على الالتهاب الرئوي الناجم عن كوفيد-19 الذي كان منتشرًا في ذلك الوقت، واستخدمت ما مجموعه أكثر من 530 ألف صورة مقطعية محوسبة لبناء نموذج تشخيصي للذكاء الاصطناعي يعتمد على تقسيم الآفة، مع معدل دقة تشخيصية يصل إلى 92.49%.
عنوان الورقة:
https://www.cell.com/pb-assets/products/coronavirus/CELL_CELL-D-20-00656.pdf

في عام 2023، نشر فريق وانغ قوانغيو مرة أخرى ورقتين بحثيتين في مجلة Nature Medicine. اقترحت إحدى الأوراق البحثية، بعنوان "تحليل التفاعل بين البروتينات المدعوم بالتعلم العميق للتنبؤ بعدوى فيروس SARS-CoV-2 وتطور المتغيرات"، إطار عمل للذكاء الاصطناعي يسمى UniBild، والذي يمكنه التنبؤ بشكل فعال وقابل للتطوير بتأثير متغيرات بروتين سبايك في فيروس SARS-CoV-2 على البشر.
عنوان الورقة:
https://www.nature.com/articles/s41591-023-02483-5

وتقترح ورقة بحثية أخرى بعنوان "التحكم الأمثل في نسبة السكر في الدم لدى مرضى السكري من النوع الثاني باستخدام التعلم التعزيزي: تجربة إثبات المفهوم"، إطار عمل للتعلم التعزيزي يعتمد على النموذج RL-DITR، بما في ذلك نموذج للمريض يتتبع حالة السكر في الدم الفردية ونموذج سياسة للتخطيط متعدد الخطوات للرعاية طويلة الأمد، والذي يمكن أن يساعد الأطباء والمرضى في تحديد خطط علاج الأنسولين الديناميكية والمرنة.
عنوان الورقة:
https://www.nature.com/articles/s41591-023-02552-9
كما قال وانغ قوانغيو: "لدينا توقعات بهذا الشأن. أما أنا، فأتمنى تطوير أساليب ذكاء اصطناعي أكثر قوة واستخدامها لحل العديد من المشكلات الطبية الحيوية المهمة، مثل التغلب على الأوبئة المفاجئة أو السرطان".
يتسارع دمج الذكاء الاصطناعي والطب الحيوي
في الواقع، كان دمج الذكاء الاصطناعي والطب الحيوي منذ فترة طويلة محور اهتمام المختبرات الكبرى. ونظراً لخصوصية المجال الطبي، فإن الذكاء الاصطناعي لديه فرص أكبر للعب دور في هذا المجال، وهناك المزيد من الفرق على استعداد للخوض بشكل أعمق في هذا المجال.
على سبيل المثال، في عام 2024، قام فريق من جامعة هونج كونج الصينية أيضًا بتطوير نظام استشارة طبيب افتراضي متعدد الجولات يعتمد على LLM، يسمى DrHouse، والذي يمكنه تحسين دقة وموثوقية التشخيص بمساعدة الأجهزة الذكية، وفي الوقت نفسه، من خلال قاعدة المعرفة الطبية المحدثة باستمرار وخوارزميات التشخيص المتقدمة، فإنه يتمتع بعمر وظيفي طويل للغاية ويوفر تقييمات طبية ذكية وموثوقة. عنوان الورقة البحثية ذات الصلة هو "دكتور هاوس: نظام تشخيصي مدعوم ببرنامج الماجستير في القانون من خلال تسخير نتائج بيانات الاستشعار والمعرفة المتخصصة".
عنوان الورقة:
https://arxiv.org/abs/2405.12541
بالإضافة إلى ذلك، أصدر فريق وانغ يانفينج وشي ويدي من جامعة شنغهاي جياوتونغ أيضًا نتائج ذات صلة في عام 2024. وذكرت الدراسة أن الفريق بنى مجموعة طبية متعددة اللغات - MMedC، تحتوي على ما يقرب من 25.5 مليار رمز وتغطي 6 لغات رئيسية. وفي الوقت نفسه، اقترحت أيضًا معيارًا للأسئلة الطبية متعددة الاختيارات متعددة اللغات - MMedBench. يحتوي النموذج النهائي الذي طوره فريق البحث، MMed-Llama 3، على 8 مليارات معلمة فقط، لكن أداءه مماثل لأداء GPT-4 على MMedBench ومعايير اللغة الإنجليزية.
ومن الواضح أن عاصفة دمج الذكاء الاصطناعي والطب الحيوي قد اشتدت. بفضل قوتها الحاسوبية القوية وخوارزمياتها الجديدة وقدرتها على استيعاب كميات هائلة من البيانات بسهولة أكبر، تعمل الذكاء الاصطناعي على جعل البحث العلمي التقليدي أكثر كفاءة وذكاءً. والأمر الأكثر إثارة للاهتمام هو أن هذه النتائج المتقدمة تدريجيا سوف تجعل التطبيق يصل إلى الأرض بشكل أسرع في نهاية المطاف. يبدو أن العصر الذي يصبح فيه التنفيذ هو الملك قد وصل بهدوء.
مراجع:
1.https://mp.weixin.qq.com/s/9mhp6luTzQeNhqpEKw9CWQ
2.https://mp.weixin.qq.com/s/WlamJ7N9YKrOJljvEvE9cA
3.https://mp.weixin.qq.com/s/r-S9qkVU645K-ZdaLGYhBA
4.https://mp.weixin.qq.com/s/BfByFCWC9VN6iABnPq1iDw









