Command Palette
Search for a command to run...
ما وراء GPT-4o! من HTML إلى Markdown، قم بتنظيم صفحات الويب المعقدة بنقرة واحدة؛ لم تعد محادثات الذكاء الاصطناعي باردة، وتعمل محادثات النماذج الكبيرة على ضبط مجموعات البيانات لجعل الاستجابات أكثر سلاسة

في مواجهة محتوى صفحة الويب الذي يحتوي على معلومات زائدة عن الحاجة، كيف يمكننا استخراج المعلومات الأساسية الشاملة بسرعة؟ يوفر لك نموذج Reader-LM حلاً احترافيًا. يمكن لبرنامج Reader-LM معالجة المحتوى الطويل جدًا الذي يصل حجمه إلى 256 كيلو بايت بكفاءة وتحويل HTML إلى تنسيق Markdown واضح بدقة. ويتجاوز أداءه أداء نماذج اللغات الكبيرة مثل GPT-4o، كما أن تصميمه خفيف الوزن يجعله أكثر ملاءمة للسيناريوهات ذات الموارد المحدودة.
في الوقت الحالي،نموذج Reader-LM متاح الآن على موقع hyper.ai. يمكنك تجربة التحويل الفعال من خلال بدء التشغيل بنقرة واحدة. لم يعد عليك أن تقلق بشأن تنظيم معلومات الويب.
من 13 يناير إلى 17 يناير، تم تحديث الموقع الرسمي لـ hyper.ai بسرعة:
* مجموعات البيانات العامة عالية الجودة: 10
* دروس تعليمية عالية الجودة: 9
* اختيار المقالات المجتمعية: 5 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في يناير: 5
قم بزيارة الموقع الرسمي: hyper.ai
مجموعات البيانات العامة المختارة
1. مجموعة بيانات DPO الشبيهة بالإنسان مجموعة بيانات ضبط الحوار النموذجي الكبير
تم تصميم مجموعة البيانات هذه خصيصًا لتحسين طلاقة وتفاعل محادثات نماذج اللغة الكبيرة، بهدف توجيه النموذج لتوليد استجابات أكثر تشابهًا بالإنسان. وتغطي مجموعة البيانات 256 موضوعًا وتحتوي على 10,884 عينة في مجالات مختلفة بما في ذلك التكنولوجيا والحياة اليومية والعلوم والتاريخ والفن.
الاستخدام المباشر:https://go.hyper.ai/zDsGL

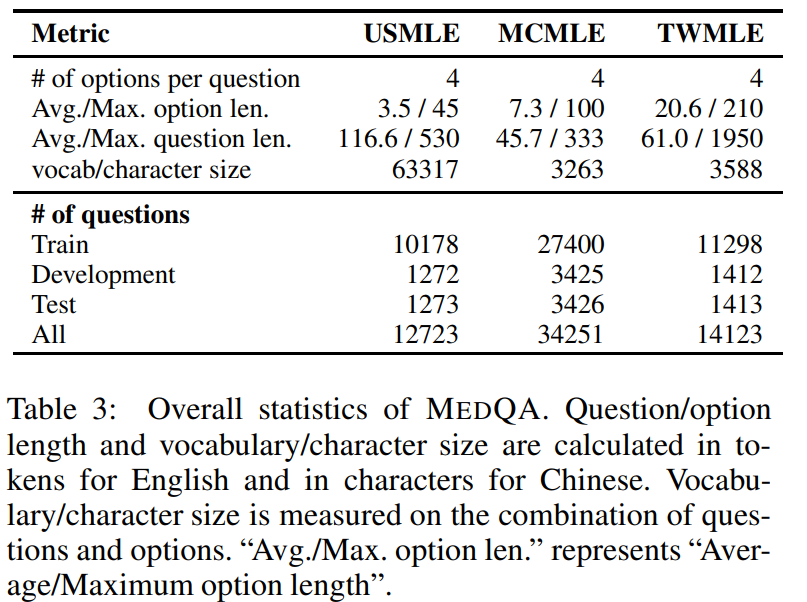
2. مجموعة بيانات الإجابة على أسئلة النصوص الطبية MedQA
تحاكي مجموعة بيانات MedQA أسلوب امتحان الترخيص الطبي في الولايات المتحدة (USMLE) وهي مصممة لتقييم فهم النموذج وتطبيقه للمعرفة الطبية. تم جمع مجموعة البيانات من الفحوصات الطبية المهنية وتغطي اللغة الإنجليزية والصينية المبسطة والصينية التقليدية، وتحتوي على 12723 و34251 و14123 سؤالاً على التوالي.
الاستخدام المباشر:https://go.hyper.ai/cV2ei
3. مجموعة بيانات التعرف على صور الخضروات
تحتوي مجموعة البيانات على صور لستة أنواع من الخضروات: الباذنجان، والفاصوليا، والبامية، والكوسا، والبطاطس، والبصل، مع 800 صورة لكل نوع، بإجمالي 4800 صورة. ويهدف إلى تعزيز قدرات التعلم الآلي والرؤية الحاسوبية في اكتشاف الخضروات وتصنيفها والتعرف عليها.
الاستخدام المباشر:https://go.hyper.ai/mCZr4

4. مجموعة بيانات إشارات المرور في شارع الصين
تتكون مجموعة البيانات من 9,898 صورة لعرض الشوارع. تحتوي كل صورة على إشارة مرور واحدة أو أكثر على الأقل، ويتم تحديد إحداثيات وفئات إشارات المرور. تأتي البيانات من قاعدة بيانات اكتشاف إشارات المرور في الصين.
الاستخدام المباشر:https://go.hyper.ai/9wb5f

5. صور الثعبان المعالجة مسبقًا
تحتوي مجموعة البيانات على خمسة أنواع من الثعابين: ثعبان الماء الشمالي، وثعبان الرباط الشائع، وثعبان ديكر البني، وثعبان الجرذ الأسود، والأفعى الجرسية الغربية. تمت معالجة مجموعة البيانات مسبقًا لزيادة السطوع والتباين، وإزالة الصور يدويًا وتقطيعها لجعل الصور أكثر نظافة وتوحيدًا وقابلية للاستخدام.
الاستخدام المباشر:https://go.hyper.ai/YAgyI

6. إشارات المرور الصينية بيانات صور إشارات المرور الصينية
تحتوي مجموعة البيانات على 5,998 صورة لإشارات المرور من 58 فئة. كل صورة هي عرض مكبر لإشارة مرور واحدة. توفر التعليقات التوضيحية خصائص الصورة (اسم الملف، العرض، الارتفاع) بالإضافة إلى إحداثيات إشارات المرور داخل الصورة والفئات (على سبيل المثال، حد السرعة 5 كم/ساعة).
الاستخدام المباشر:https://go.hyper.ai/Tvvh8

7. مجموعة بيانات تفضيلات إنشاء الصور لتفضيلات الأنماط البشرية
هذه المجموعة من البيانات عبارة عن مجموعة بيانات تم شرحها بواسطة الإنسان لتقييم نماذج توليد النص إلى صورة. ويقوم هذا التطبيق بجمع تقييمات الإجماع البشري لنماذج توليد الصور من خلال عرض صورتين وسؤال المشاركين عن أيهما تبدو أقل غرابة أو غير طبيعية، ويتضمن أكثر من 1.2 مليون صوت إجماع بشري.
الاستخدام المباشر:https://go.hyper.ai/dErEz
8. M²E: مجموعة بيانات الصيغ الرياضية متعددة الأسطر
تحتوي مجموعة البيانات على 99,956 صورة تعبيرية رياضية متعددة السطور وتعليقاتها التوضيحية. يتم التقاط جميع الصور باستخدام هاتف محمول من مشاهد العالم الحقيقي، ويتم التقاط عدة أسطر من صيغ الرياضيات من أوراق اختبار الرياضيات وكتب التمارين لمهمة التعرف على صيغ الرياضيات.
الاستخدام المباشر:https://go.hyper.ai/5BMnN
9. مجموعة بيانات الأبيات الصينية
تحتوي مجموعة البيانات هذه على حوالي 740 ألف مقطع شعري. fixed_couplets_in.txt هو المقطع العلوي و fixed_couplets_out.txt هو المقطع السفلي.
الاستخدام المباشر:https://go.hyper.ai/oPxHl
10. مجموعة بيانات الضوضاء الصوتية
تحتوي مجموعة البيانات هذه على 10 فئات مختلفة من الضوضاء ويمكن استخدامها لتصفية الضوضاء وتوليدها والتعرف عليها في تصنيف الصوت والتعرف على الصوت وتوليد الصوت والتعلم الآلي المتعلق بالصوت.
الاستخدام المباشر:https://go.hyper.ai/MXXZy
دروس تعليمية عامة مختارة
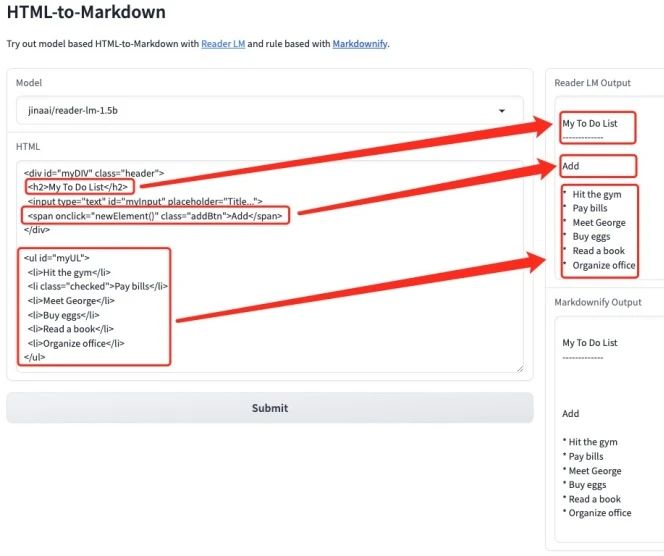
1. Reader-LM: تحويل HTML إلى MarkDown بسرعة وكفاءة
Reader-LM هو نموذج تم تصميمه خصيصًا لتحويل محتوى HTML الخام من الويب إلى تنسيق Markdown واضح ومرتب. إنه يتفوق في التعامل مع النصوص الطويلة والمحتوى متعدد اللغات، ويدعم أطوال السياق حتى 256 كيلو بايت. ويهدف إلى تلبية الحاجة إلى استخراج البيانات بكفاءة واقتصادية من محتوى الويب المزعج.
يوضح هذا البرنامج التعليمي كيفية تحويل HTML إلى Markdown باستخدام reader-lm-1.5b أو reader-lm-0.5b. انقر على الرابط أدناه واتبع البرنامج التعليمي لتجربته.
تشغيل عبر الإنترنت:https://go.hyper.ai/S15IL
2. نشر DeepSeek-V2-Lite-Chat بنقرة واحدة
DeepSeek-V2 هو نموذج لغة مزيج قوي من الخبراء (MoE) وهو اقتصادي في التدريب وفعال في الاستنتاج. يحتوي على 236B معلمة في المجموع، حيث يقوم كل رمز بتنشيط 21B معلمة.
يعد هذا البرنامج التعليمي عرضًا توضيحيًا لنشر DeepSeek-V2-Lite-Chat بنقرة واحدة. كل ما عليك فعله هو استنساخ الحاوية وبدء تشغيلها ونسخ عنوان API الناتج مباشرةً لتجربة استنتاج النموذج.
تشغيل عبر الإنترنت:https://go.hyper.ai/AD6XU
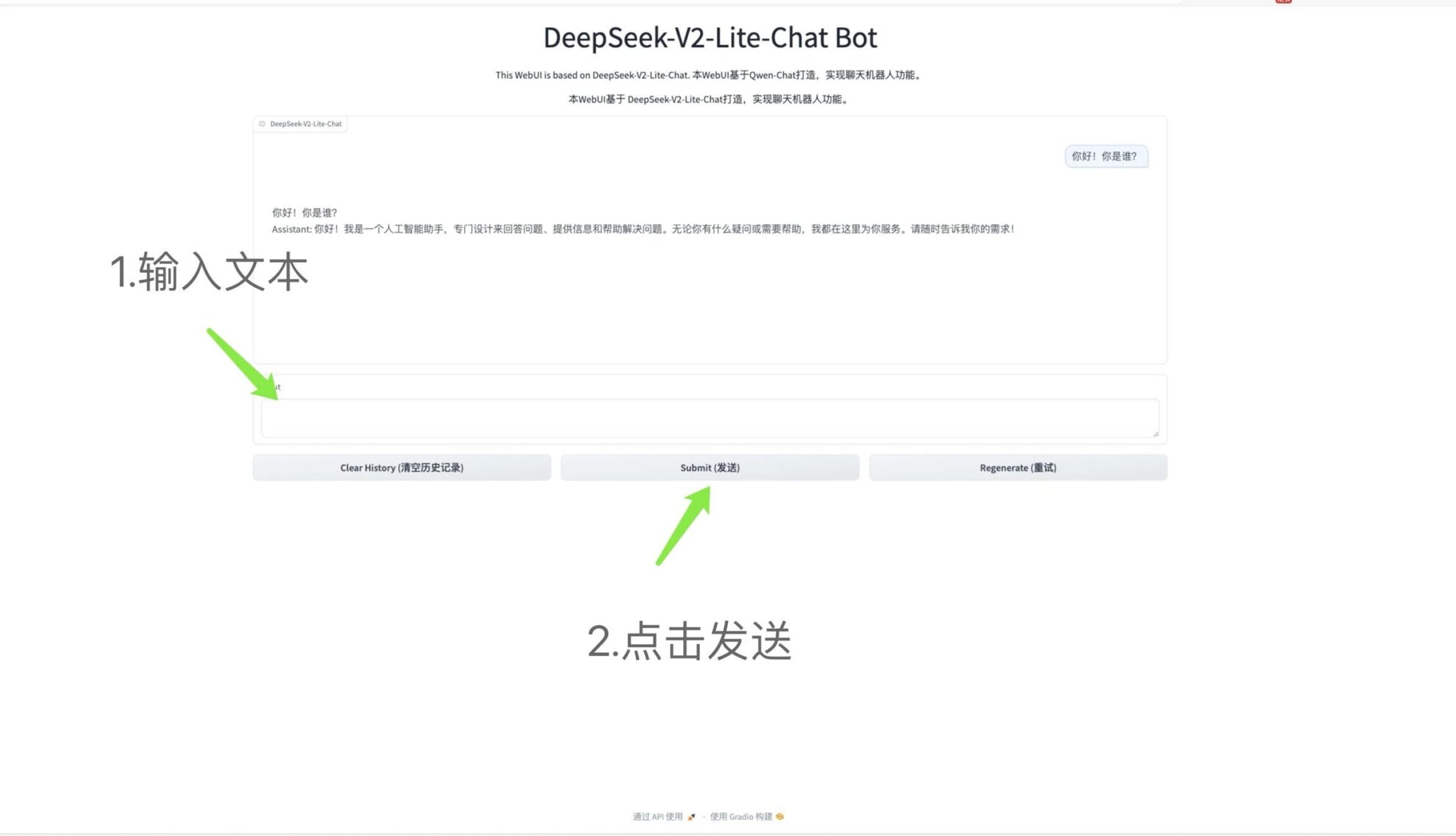
3.نشر ChemVLM-26B بنقرة واحدة
ChemVLM هو نموذج لغوي كبير متعدد الوسائط مفتوح المصدر للكيمياء. يهدف النموذج إلى حل مشكلة عدم التوافق بين فهم الصورة الكيميائية وتحليل النص. من خلال الجمع بين مزايا المحول المرئي (ViT) والإدراك متعدد الطبقات (MLP) ونموذج اللغة الكبير (LLM)، فإنه يحقق التفكير الشامل للصور والنصوص الكيميائية.
اتبع خطوات البرنامج التعليمي وانسخ عنوان API الناتج مباشرةً لاستخدام ChatVLM-26B.
تشغيل عبر الإنترنت:https://go.hyper.ai/NRBXG
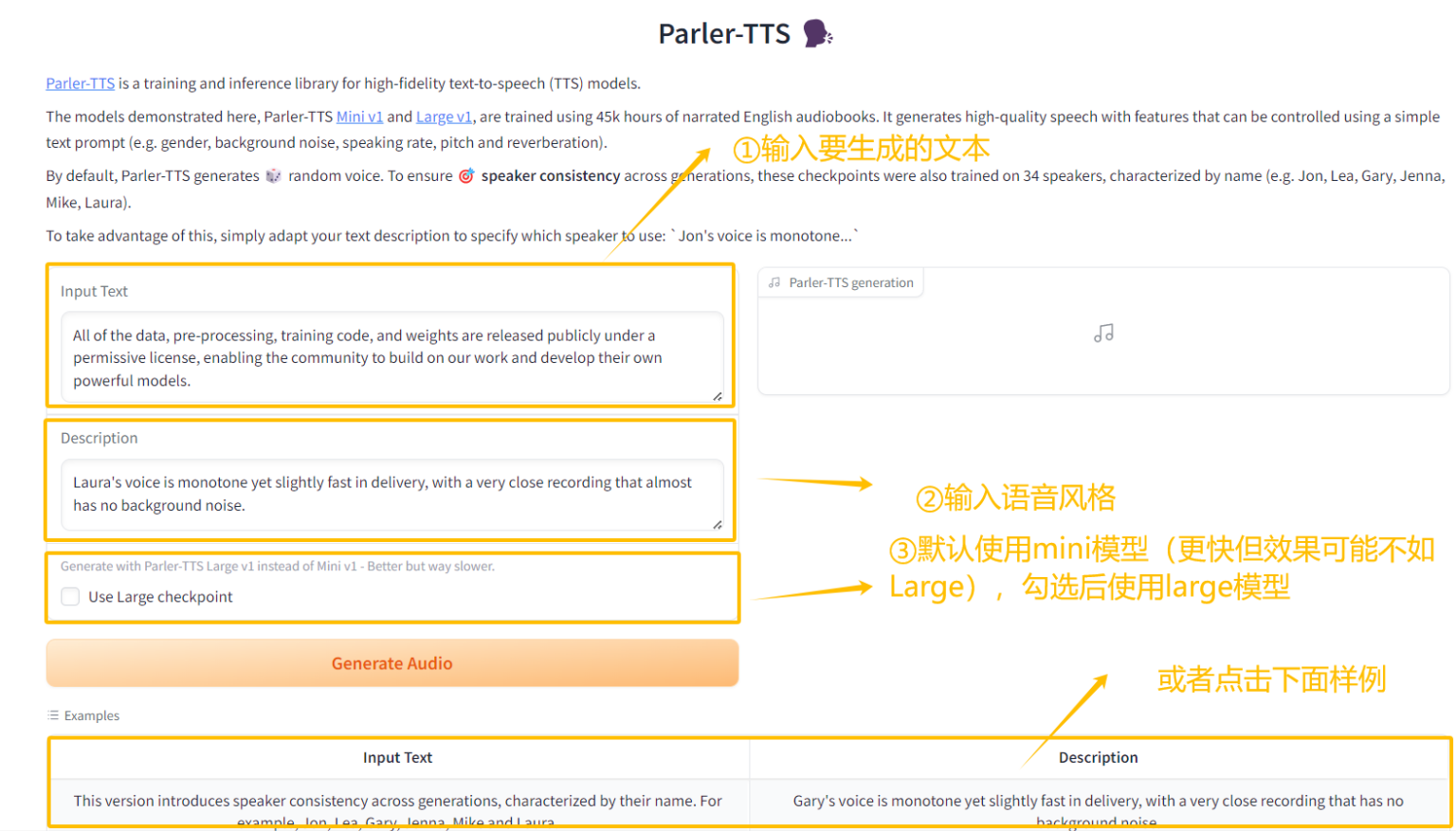
4. نشر Parler-TTS بنقرة واحدة
Parler-TTS هو نموذج تحويل النص إلى كلام (TTS) خفيف الوزن والذي يمكنه إنشاء كلام طبيعي عالي الجودة بأسلوب متحدث معين. يتمتع بدرجة عالية من الحرية والابتكار، ويمكنه التحكم في جنس المتحدث، وجرسه، ونبرته، ومشهده (داخليًا، وخارجيًا، وعلى الطريق، وفي قاعة حفلات موسيقية، وما إلى ذلك) من خلال Prompt.
يمكن لهذا المشروع إنشاء واجهة تفاعلية أمامية من خلال واجهة Gradio. تم نشر النماذج والتبعيات ذات الصلة، ويمكن إنشاء ملفات الصوت المائية بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/pk6lF
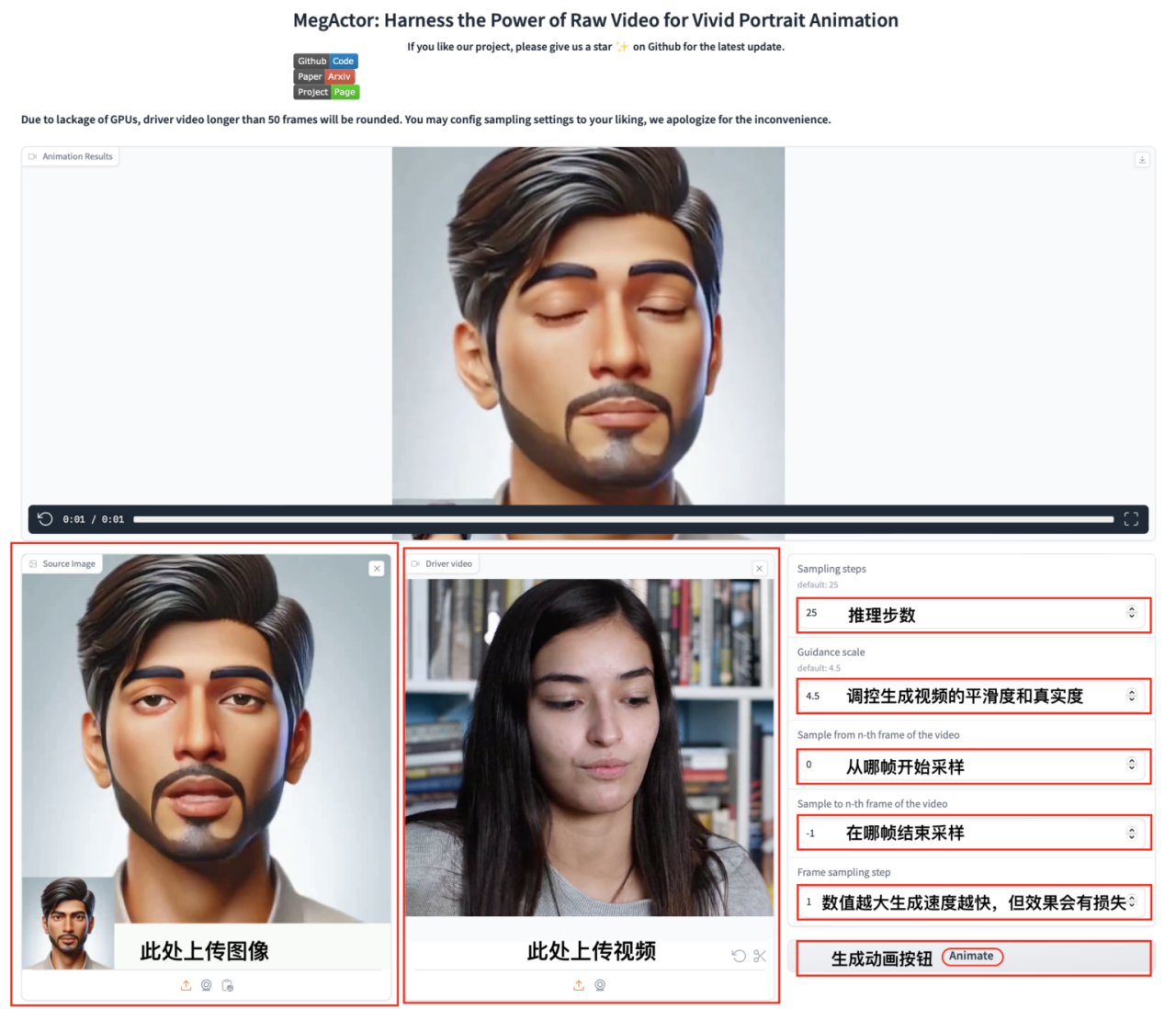
5. عرض توضيحي لمولد الرسوم المتحركة للصور الشخصية من MegActor
MegActor هو برنامج رسوم متحركة للصور الشخصية يستخدم الفيديو الخام كمحرك لتوليد مقاطع فيديو واقعية وحيوية لرؤوس المتحدثين.
اتبع خطوات البرنامج التعليمي، ما عليك سوى استنساخ المشغل وفتح عنوان API لتوليد مقاطع فيديو اصطناعية حية استنادًا إلى محتوى الفيديو الأصلي.
تشغيل عبر الإنترنت:https://go.hyper.ai/wkCPo
6. عرض توضيحي لفهم فيديو Flash-VStream
Flash-VStream هو نموذج لغة فيديو يحاكي آليات الذاكرة البشرية. إنه قادر على معالجة تدفقات الفيديو الطويلة للغاية في الوقت الفعلي والرد على استفسارات المستخدم في نفس الوقت.
يعد هذا البرنامج التعليمي عرضًا توضيحيًا لكيفية تشغيل Flash-VStream بنقرة واحدة. تم تثبيت البيئة والتبعيات ذات الصلة. يمكنك تجربته عن طريق استنساخه وبدء تشغيله بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/M3pBO
7. يُنشئ PhotoMaker V2 صورًا شخصية مخصصة في ثوانٍ - عرض توضيحي
PhotoMaker هو نموذج رسومي فعال مخصص للصور الشخصية تم تطويره مفتوح المصدر بواسطة فريق Tencent في عام 2024. يمكنه إنشاء صور فنية مخصصة بسرعة استنادًا إلى صور شخصية. بالإضافة إلى إنشاء صور شخصية للأشخاص، فإنه يمكنه أيضًا تغيير عمر وجنس الأشخاص ودمج خصائص الأشخاص المختلفين لإنشاء معلومات شخصية جديدة.
يعد هذا البرنامج التعليمي الإصدار 2.0 من PhotoMaker، والذي قام بتحسين الاتساق والقدرة على التحكم في الأحرف بشكل كبير مقارنةً بالإصدار V1.
تشغيل عبر الإنترنت:https://go.hyper.ai/VcewN

8. عرض تجريبي لمولد الفيديو الهزلي StoryDiffusion
StoryDiffusion هي أداة ذكاء اصطناعي تركز على إنشاء الصور ومقاطع الفيديو طويلة المدى. تستخدم هذه التقنية آلية الاهتمام الذاتي المتسقة لضمان استمرارية وتناسق محتوى الصور والفيديو، مع الحفاظ على تناسق الأسلوب سواء في إنشاء القصص المصورة أو الشخصيات الكرتونية أو إنشاء مقاطع فيديو طويلة.
يعد هذا البرنامج التعليمي الإصدار الأحدث من حزمة التشغيل بنقرة واحدة لـ StoryDiffusion. يمكنك تجربة StoryDiffusion من خلال الاستنساخ بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/HPu2p

9. محاكي ديناميكيات جزيئية سهل الاستخدام LAMMPS: التحكم في درجة حرارة npt لتقدير نقطة انصهار FCC Cu
يمكن استخدام LAMMPS لنمذجة مجموعة متنوعة من المواد، بما في ذلك المواد ذات الحالة الصلبة (المعادن، وأشباه الموصلات)، والجزيئات الحيوية، والبوليمرات، وما إلى ذلك، ويمكن أن توفر مجموعة متنوعة من نماذج تفاعل الجسيمات لمواد مختلفة.
يعد هذا البرنامج التعليمي بمثابة برنامج تعليمي تمهيدي لـ LAMMPS: تقدير نقطة انصهار FCC Cu باستخدام التحكم في درجة الحرارة npt. يمكنك تشغيله باستخدام إصدار وحدة المعالجة المركزية من LAMMPS لتجربة محاكاة الديناميكيات الجزيئية.
تشغيل عبر الإنترنت:https://go.hyper.ai/qQSqr
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

مقالات المجتمع
تعرف على AI Compiler مراجعة الصالون التقني السادس هنا. أظهر أربعة من كبار خبراء التجميع من Horizon Robotics وZhiyuan وByteDance وLingchuan Technology للجميع أحدث نتائج الأبحاث التي أجرتها فرقهم. وفي الوقت نفسه، قاموا أيضًا بدمج حالات تطبيقية عملية غنية لشرح عملية التطبيق وتأثيرات هذه النتائج في حل المشكلات العملية بطريقة سهلة الفهم.
عرض ملخص الحدث:https://go.hyper.ai/KDzY3
أجرت شركة HyperAI مقابلة معمقة مع البروفيسور شيه ويدي، الأستاذ المشارك الدائم في جامعة شنغهاي جياو تونغ. وبناءً على تجربته الشخصية، شارك معنا تجربته في التحول من الرؤية الحاسوبية إلى الذكاء الاصطناعي للرعاية الصحية، كما أجرى تحليلًا معمقًا لاتجاهات التطوير المستقبلية للصناعة. وهذا تقرير مفصل عن المقابلة.
شاهد التقرير الكامل:https://go.hyper.ai/LqpqE
3. مستشعر لمسي يعتمد على فيلم مغناطيسي مرن
يعد الإدراك اللمسي أحد القدرات المهمة للروبوتات الذكية والتفاعل بين الإنسان والحاسوب، ولكن كيفية تحقيق الإدراك اللمسي عالي الدقة والاستجابة السريعة لا يزال يواجه العديد من التحديات. شارك الدكتور يان يوكان من المركز الوطني الفرنسي للبحوث العلمية مع الجميع تصميم وتطبيق أجهزة استشعار لمسية تعتمد على أفلام مغناطيسية مرنة، وقدم كيفية استخدام مجموعة هالباخ المغناطيسية المتعامدة لتحقيق الفصل الذاتي للقوى ثلاثية الأبعاد. تعتبر هذه المقالة تقريرا مفصلا عما تمت مشاركته.
شاهد التقرير الكامل:https://go.hyper.ai/Y5uA0
يمكن أن يكشف دمج الصور الطبية المتعددة الوسائط عن الكثير من المعلومات القيمة ويساعد الأطباء على إجراء تشخيصات أكثر احترافية للأمراض، ولكن التحدي الرئيسي الذي يواجهنا حاليًا هو أن الميزات المستخدمة في الدمج والميزات المستخدمة في المحاذاة غير متوافقة. اقترحت جامعة كونمينغ للعلوم والتكنولوجيا وجامعة المحيط الصينية بشكل مشترك طريقة محاذاة الميزات ثنائية الاتجاه خطوة بخطوة BSAFusion، والتي يمكنها تحقيق محاذاة الصور الطبية متعددة الوسائط والاندماج. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/sTySj
إن نقص الموارد الطبية يمثل مشكلة طويلة الأمد تؤثر على النظام الطبي العالمي. ولتحقيق هذه الغاية، اقترحت فرق بحثية من أربع جامعات كبرى مشروع KG4Diagnosis. هذا إطار عمل هرمي متعدد الوكلاء جديد يمكن استخدامه لأتمتة بناء وتشخيص وعلاج وتفسير الرسوم البيانية للمعرفة الطبية، مما يساعد على تشخيص 362 مرضًا شائعًا في مجالات طبية متعددة مثل السمنة. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/0CPhV
مقالات موسوعية شعبية
1. فقدان الانتشار
2. الاهتمام السببي
3. نظرية كولموغوروف-أرنولد للتمثيل
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. التعلم التبايني
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
الموعد النهائي لشهر يناير للمؤتمر الأعلى

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1700 مجموعة بيانات عامة
* يتضمن أكثر من 500 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* يدعم البحث عن أكثر من 600 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:
وأخيرًا، أوصي ببرنامج "حوافز المبدعين". يمكن للأصدقاء المهتمين مسح رمز الاستجابة السريعة للمشاركة!









