Command Palette
Search for a command to run...
يمكن أن يصل معدل النجاح إلى 100%. تعاونت شركة تطوير الأدوية Cellarity مع NVIDIA لتحسين الجزيئات المستهدفة استنادًا إلى التعلم التعزيزي

منذ العصور القديمة وحتى يومنا هذا، لم يتوقف البشر عن محاربة الأمراض. قد يؤدي ظهور دواء جديد إلى إنقاذ آلاف الأرواح وحتى إطالة عمر الإنسان بشكل عام.
إذا نظرنا إلى تاريخ أبحاث وتطوير الأدوية الذي يمتد لقرن من الزمان، فسنجد العديد من القصص المثيرة للاهتمام. على سبيل المثال، في أوائل القرن التاسع عشر، قامت مساعدة صيدلي ألمانية تدعى زيلتينا بنقع الأفيون في الماء الساخن ثم استخلصته باستخدام ماء الأمونيا لفصل كومة من المسحوق الأبيض عن الأفيون. لقد أعطيت هذا المسحوق الأبيض للكلب، وسرعان ما أغمي على الكلب بعد تناوله.فأطلق عليه اسم المورفين نسبة إلى إله الأحلام اليوناني مورفيوس.ولذلك، يعتبر المورفين بشكل عام أول مادة فعالة في العالم تم عزلها من نبات، ويعتبر أيضًا نقطة البداية للابتكار الدوائي الحديث.
وبعد ذلك، أتقن الصيادلة تدريجيا تقنية تصنيع الأدوية الكيميائية، وقام الصيدلي الألماني سلمان بتصنيع حمض أسيتيل الساليسيليك، وهو سلف الأسبرين. في بداية القرن العشرين،لقد أدى طلب الشركات على الأدوية الجديدة إلى تطوير تقنية الفحص عالية الإنتاجية، والتي تمكن العلماء من فحص واختبار أعداد كبيرة من المركبات بكفاءة أكبر. في بداية القرن الحادي والعشرين،بدأ الباحثون في استكشاف علاجات دوائية أكثر دقة وفعالية، ومن بينها الأدوية المستهدفة التي أصبحت اتجاهًا بحثيًا ساخنًا.
اليوم، أدى التطور السريع لتكنولوجيا الذكاء الاصطناعي إلى توفير إمكانيات جديدة لاكتشاف الأدوية. يمكن أن تساعد الذكاء الاصطناعي الصيادلة على التحقق من صحة أهداف الأدوية بشكل أسرع وتحسين تصميم بنية الدواء، وحتى توليد جزيئات مباشرة بخصائص فيزيائية أو أنشطة بيولوجية محددة، مما يعمل على تسريع اكتشاف الأدوية بشكل كبير.
وفي هذا السياق،اقترح باحثون من شركة علوم الحياة Cellarity وشركة NVIDIA بشكل مشترك طريقة جديدة لتحسين الجزيئات المستهدفة تعتمد على التعلم التعزيزي الكامن، MOLRL.يجمع النهج بين نموذج توليدي قوي تم تدريبه مسبقًا على مجموعة كبيرة من البيانات الكيميائية مع خوارزمية التعلم التعزيزي (RL) المتطورة لتحسين المساحة المستمرة. ومن خلال تطبيق الطريقة على المهام المتعلقة باكتشاف الأدوية، واستخدام معايير مشتركة والمقارنة بالطرق الحديثة، وجد الباحثون أن MOLRL أظهر أداءً متفوقًا أو تنافسيًا في مجموعة متنوعة من المهام، وخاصة في توليد الجزيئات المستهدفة وتحسين المعلمات المتعددة.
وقد نُشرت النتائج ذات الصلة على موقع ChemRxiv تحت عنوان "التوليد الجزيئي المستهدف باستخدام التعلم التعزيزي الكامن".
عنوان الورقة:
اتبع الحساب الرسمي ورد "تحسين الجزيئات المستهدفة" للحصول على ملف PDF الكامل
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
اختيار المسار: تعديل الجزيئات بشكل مباشر مقابل العمل في الفضاء الكامن
يعد تطوير الأدوية عملية معقدة للغاية - بالإضافة إلى النشاط البيولوجي، يجب أن يتمتع المركب بخصائص أخرى متعددة ليتم اختياره كمرشح سريري. إن هياكل تلك المركبات التي تم تحديدها على أنها ذات نشاط علاجي، والتي يشار إليها غالبًا باسم "المركبات المرشحة"، ليست ثابتة، بل يتم تعديلها على مدى دورة تكرارية طويلة لمعالجة قضايا مثل عدم كفاية الذوبان والنشاط.
في عملية تكرارية، يقوم الصيادلة عادةً بتحويل الجزيئات الأولية لتصميم نظائر بناءً على حدسهم أو من خلال الترقيم من المكتبات القائمة على التفاعل. ومع ذلك، ونظراً للحجم الهائل للمساحة الكيميائية، فإن التصميم يصبح صعباً للغاية حتى بالنسبة لجزيء واحد، مما يتطلب تقييماً شاملاً للمساحة الكيميائية بأكملها. يمكن للطرق الحسابية لتوليد الجزيئات المستهدفة استكشاف الفضاء الكيميائي بكفاءة والتوصية بهياكل لم يتم استكشافها سابقًا للكيميائيين.
في الوقت الحالي، يمكن تقسيم طرق توليد الجزيئات المستهدفة وتحسينها إلى فئتين:الطريقة الأولى هي العمل مباشرة على البنية الجزيئية.لتحديد التعديلات الهيكلية التي تعمل على تحسين خصائص الهدف؛الفئة الثانية من الأساليب تعمل في الفضاء الكامن للنموذج التوليدي.تعديل البنية الجزيئية بطريقة غير مباشرة من خلال تمثيلها الكامن.
الطريقة الأولى: يمكن إجراء تعديلات هيكلية عن طريق إدخال أو حذف الذرات أو الروابط الكيميائية، وقد حققت الصناعة تقدماً كبيراً.
وذكرت التقارير أنه في نوفمبر/تشرين الثاني من العام الماضي، قام فريق بقيادة البروفيسور يونسو بارك من المعهد الكوري المتقدم للعلوم والتكنولوجيا (KAIST) بتطوير تقنية مبتكرة لتحرير الذرة الفردية. تقدم هذه التقنية محفزات ضوئية.تم تحقيق التحرير الذري الفردي لجزيئات الدواء بنجاح في درجة حرارة الغرفة والضغط.تستطيع تقنية "المقص الجزيئي" التي طورها الفريق قطع وتوصيل الهياكل الحلقية المكونة من خمسة أعضاء بدقة، واستبدال ذرات الأكسجين بذرات النيتروجين، وتغيير الخصائص الجزيئية وتحسين فعالية الدواء. وقد نُشرت نتائج البحث ذات الصلة في مجلة Science تحت عنوان "تحويل الفوران إلى بيرول ضوئيًا".

ومع ذلك، ليس من السهل إجراء العمليات الجراحية على الجزيئات حسب الرغبة. من ناحية أخرى، قد تؤدي التعديلات البنيوية إلى انتهاك قواعد الكيمياء وبالتالي تؤدي إلى هياكل جزيئية غير صالحة. من ناحية أخرى، بما أن الهياكل الجزيئية منفصلة بطبيعتها، وأن إضافة أو حذف الروابط الكيميائية ينطوي على عمليات منفصلة، فإن هذا الانفصال سيؤدي إلى تدرجات غير متصلة في عملية التحسين، مما يجعل من الصعب تطبيق الأساليب القائمة على التدرج بشكل فعال.
بالمقارنة مع الطريقة 1،النهج الثاني يحول مهمة التحسين إلى مشكلة تحسين مستمرة، ويستغل المساحة الكامنة في النموذج التوليدي، ويتبنى خوارزميات تحسين المساحة المستمرة مثل الانحدار التدرجي.ومع ذلك، تظل صحة الكيمياء تشكل تحديًا لأنه لا يوجد ما يضمن أن نقطة في الفضاء الكامن تتوافق مع جزيء صالح. ومع ذلك، من خلال استخدام هياكل معمارية جديدة بالإضافة إلى تعديلات التدريب، حققت النماذج التوليدية تقدماً كبيراً في تحسين الفعالية والاستمرارية في المساحة الكامنة.
في البحث الذي أجراه Cellarity و NVIDIA، اقترح الباحثون MOLRL لتحسين المساحة الكامنة للنموذج التوليدي المدرب مسبقًا باستخدام طريقة تحسين السياسة القريبة (PPO).
MOLRL، وهي طريقة تحسين جزيئية مستهدفة تعتمد على التعلم التعزيزي الكامن
كيف يعمل إطار عمل MOLRL؟
يتكون إطار عمل MOLRL من جزأين: نموذج توليد المساحة الكامنة ووكيل التعلم المعزز (RL).
النموذج التوليدي هو نموذج ترميز وفك تشفير مدرب مسبقًا حيث تقوم مساحته الكامنة بترميز المساحة الكيميائية التي يعمل عليها وكيل التعلم التوليدي. يتم تدريب وكيل RL باستخدام طريقة PPO،للتنقل في الفضاء الكامن؛ توفر وظيفة المكافأة ردود الفعل للوكيل،ساعدهم على تعلم كيفية التنقل في الفضاء،تحديد الجزيئات ذات الخصائص المرغوبة.
كما هو موضح أدناه: يتم إزعاج التمثيل الكامن "z" للجزيء المدخل بواسطة الفعل "a" المستخرج من مخرجات شبكة السياسة. يتم فك تشفير المتجه الكامن المضطرب "z′" إلى جزيئات وتسجيله بواسطة دالة المكافأة. يتم جمع الحالة "z"، والإجراء "a"، والمكافأة "R" واستخدامها لتحديث شبكة السياسة.
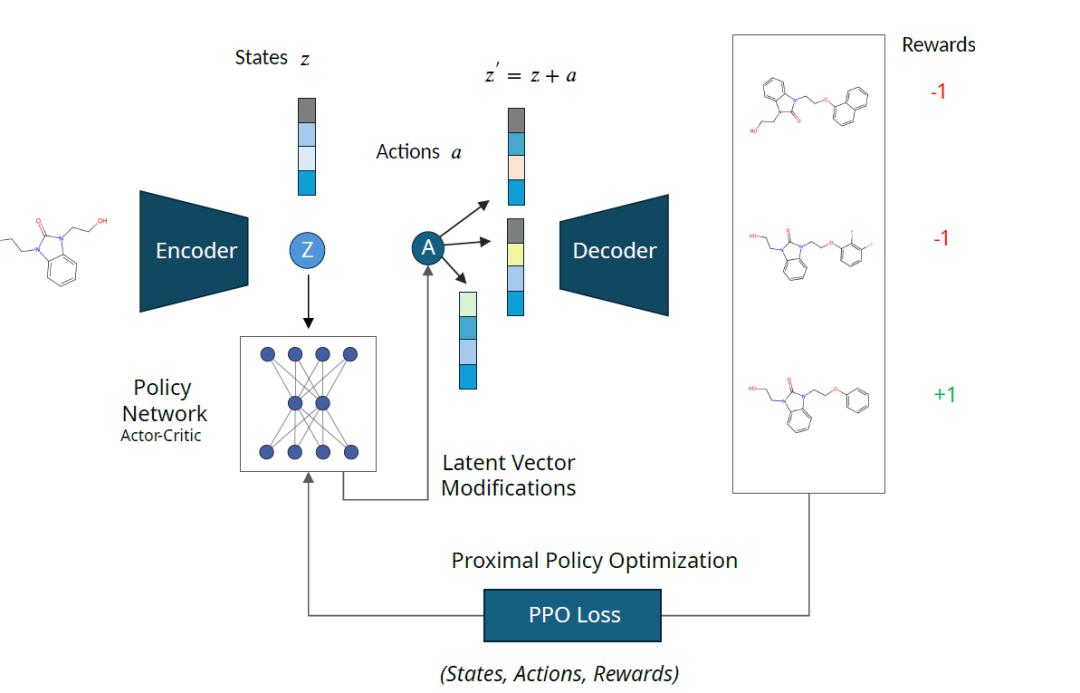
الإطار لا يعتمد على بنية المشفر وفك التشفير، ومع ذلك فإن خصائص المساحة الكامنة ستؤثر بشكل كبير على أداء التحسين. لذلك، قام الباحثون بتقييم أداء MOLRL على بنيتين مختلفتين للمشفر-الفك، وهما المشفر التلقائي المتغير (VAE) والمشفر التلقائي المدرب على أساس التعلم الآلي للمعلومات المتبادلة (MolMIM).
يعد وكيل التعلم المعزز (RL) مسؤولاً عن التنقل في المساحة الكامنة لتحديد الجزيئات ذات الخصائص الجزيئية المرغوبة. استخدم الباحثون PPO، أو Proximal Policy Optimization، لتدريب وكيل التعلم التعزيز.ترشد خوارزمية PPO العميل للعثور على المسار الأمثل في المساحة الكامنة من خلال تحسين السياسة لتحقيق أقصى قدر من المكافأة التراكمية طويلة الأجل.تشكل وظيفة المكافأة جوهر إطار عمل MOLRL، الذي يوفر ردود فعل للعامل بناءً على خصائص الهدف للجزيء (مثل تشابه الدواء، وإمكانية الوصول الاصطناعي، وربط الهدف، وما إلى ذلك).
كيف يعمل إطار عمل MOLRL؟
لتقييم أداء إطار عمل MOLRL، قام الباحثون بتصميم مهمة تحسين متعددة الأهداف وقارنوها بطرق التحسين الحديثة الحالية.
على وجه التحديد، قام الباحثون بتطبيق MOLRL لتوليد جزيئات نشطة بيولوجيًا تستهدف هدفين مع تحسين كل من تشابه الدواء (QED) وإمكانية الوصول الاصطناعي (SA). كانت الأهداف البيولوجية المختارة عبارة عن كينازين مرتبطين بمرض الزهايمر - GSK3β و JNK3. وبناءً على استراتيجية التقييم التي وضعها جين وآخرون، سجل الباحثون أفضل 5000 جزيء بأعلى قيم المكافأة التي تم إنشاؤها أثناء عملية التحسين وحسبوا المؤشرات الثلاثة التالية: معدل النجاح؛ بدعة؛ والتنوع.
يوضح الجدول التالي أداء MOLRL المدرب في الفضاء الكامن VAE-CYC وMOLRL المدرب في فضاء MolMIM، بالإضافة إلى مقارنة أداء طرق التحسين الجزيئي الحديثة الحالية المذكورة في الأدبيات.
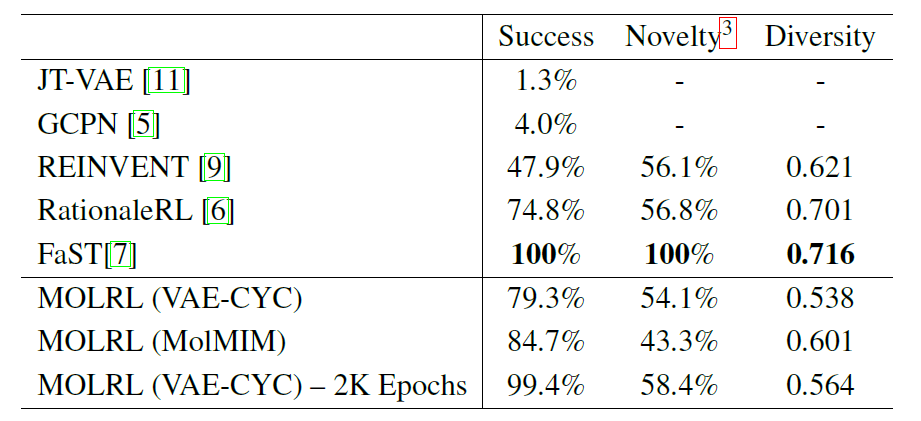
كما هو موضح في الجدول، يقوم FaST ببناء الرسوم البيانية الجزيئية من خلال الجمع بين الأجزاء الجزيئية باستخدام التعلم التعزيزي (RL).ويظهر معدل نجاح أعلى بين جميع الطرق المقارنة. تتمتع طريقتا FaST و RationaleRL بمزايا التنوع والابتكار، وتستغل كلتا الطريقتين المعرفة السابقة. يبدأ كل من REINVENT وMOLRL من جزيئات عشوائية قد تكون بعيدة عن نطاق تدريب مصنف التعلم الآلي.لا يزال MOLRL يحقق حداثة مماثلة لـ RationaleRL ويحقق أعلى معدل نجاح.
إن استخدام المعرفة السابقة كنقطة بداية يمكن أن يكون له مزايا معينة، ولكنه قد يحد أيضًا من الحداثة وقدرة الخوارزمية على اكتشاف هياكل عظمية جديدة. وعلاوة على ذلك، فإن قابلية تطبيق مثل هذه الأساليب تكون محدودة عندما لا تتوفر أي معرفة مسبقة، كما هو الحال عند دراسة الأهداف غير المستكشفة.
بالإضافة إلى مهام التحسين متعددة الأهداف، فإن النهج الشائع في اكتشاف الأدوية هو تحديد سقالة كيميائية معروفة بالارتباط بهدف معين أو فئة من الأهداف واستخدام ذلك كنقطة بداية لتصميم المواد الكيميائية وتحسينها. لذلك، تؤكد الورقة البحثية أيضًا قدرة MOLRL على تحسين خصائص الأهداف المتعددة مع الحفاظ على الهيكل الجزيئي المحدد. كما هو موضح في الجدول التالي،عند تحسين الجزيئات التي تحتوي على العمود الفقري للأمينوبيريميدين، حقق MOLRL معدل نجاح بلغ 100%.
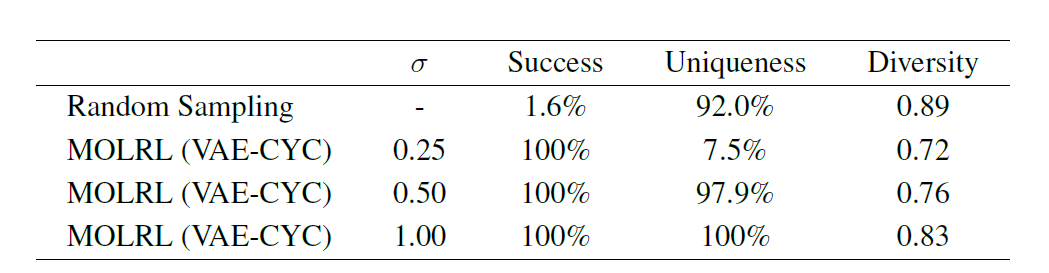
باختصار، يظهر MOLRL أداءً متفوقًا أو تنافسيًا في مجموعة متنوعة من المهام مقارنة بالطرق الحالية.وخاصة في توليد الجزيئات المستهدفة وتحسين المعلمات المتعددة.
الذكاء الاصطناعي هو خطوة أساسية في تحسين كفاءة اكتشاف الأدوية
كم من الموارد نحتاج لتطوير دواء جديد؟ لدى صناعة الأدوية قاعدة شهيرة تسمى "القاعدة العشرية المزدوجة"، والتي تنص على أن الأمر يستغرق 10 سنوات ومليار دولار لاكتشاف دواء جديد وطرحه في السوق. وفقًا لأحدث تقرير أصدرته شركة ديلويت، إذا تم أخذ تكلفة التجارب السريرية الفاشلة في الاعتبار، فإن متوسط التكلفة التي تتحملها شركات الأدوية الكبرى في العالم لجلب دواء جديد إلى السوق بنجاح هووقد ارتفعت من 1.188 مليار دولار أميركي في عام 2010 إلى 2.284 مليار دولار أميركي في عام 2022.
إن الخطوة الأساسية في اكتشاف الدواء هي العثور على مجموعة من الجزيئات المرشحة للدراسة الحسابية أو التوليف والوصف، وهي مهمة صعبة لأن المساحة الكيميائية للجزيئات المحتملة ضخمة وتتطلب تكاليف عالية للغاية للتجربة والخطأ. واليوم، أصبح بإمكان الذكاء الاصطناعي والتعلم الآلي تحسين كفاءة هذه الخطوة بشكل فعال.
31 أكتوبر 2023تعاونت معاهد نوفارتيس للأبحاث الطبية الحيوية ومركز أبحاث مايكروسوفت للذكاء العلمي من أجلنُشرت ورقة بحثية بعنوان "استخراج حدس الكيمياء الطبية من خلال التعلم الآلي للتفضيلات" في مجلة Nature Communications.
طلب الباحثون من 35 كيميائيًا طبيًا اختيار الجزيء المفضل لديهم من بين 5000 زوج من الجزيئات، واستخدموا ردودهم لتشكيل لعبة تصنيف لتدريب نموذج التعلم الآلي، ثم طلبوا من النموذج تسجيل الجزيئات. إن هذه النتيجة لا تتأثر إلى حد كبير بالخصائص الأخرى التي كانت تميز هذا المجال في السابق، لأنها تأتي من سنوات من المعرفة المتراكمة داخل الصناعة.
يمكن للنموذج إعادة إنتاج المعرفة الجماعية التي تراكمت لدى الكيميائيين المحترفين في عملهم جزئيًا، والتي غالبًا ما يطلق عليها "الحدس الكيميائي"، مما يجعل تطوير الأدوية في المستقبل أكثر كفاءة.
في مارس 2024، نشرت شركة Insilico Medicine، وهي شركة رائدة في مجال الأدوية القائمة على الذكاء الاصطناعي، ورقة بحثية علمية في مجلة Nature Biotechnology، توضح بالتفصيل استخدام منصة الذكاء الاصطناعي لاكتشاف TNIK المستهدف الجديد لعلاج IPF، والعملية اللاحقة لاستخدام منصة الكيمياء التوليدية لتصميم جزيء ISM001-055.
ISM001-055 هو مثبط جزيئي صغير هو الأول من نوعه في العالم.استهداف TNIK (كيناز التفاعل بين Traf2/NCK) لعلاج التليف الرئوي مجهول السبب (IPF). قالت شركة Insilicon Valley Silicon أن الذكاء الاصطناعي التوليدي يمكنه تحسين كفاءة البحث والتطوير بشكل كبير، وخفض تكاليف البحث والتطوير، وزيادة معدل نجاح البحث والتطوير في المراحل المبكرة من البحث والتطوير. إذا أخذنا الجزيئات المضادة للتليف الرئوي مجهول السبب كمثال، بدءًا من اكتشاف الهدف المبكر وحتى تحديد المركبات المرشحة قبل السريرية،استغرق الأمر 18 شهرًا فقط واستثمر 2.6 مليون دولار في البحث والتطوير.
وأظهر تقرير بحثي صادر عن شركة فورتشن بيزنس إنسايت أن حجم السوق العالمية للذكاء الاصطناعي في اكتشاف الأدوية سيبلغ 3 مليارات دولار أمريكي في عام 2022، ومن المتوقع أن ينمو من 3.54 مليار دولار أمريكي في عام 2023 إلى 7.94 مليار دولار أمريكي في عام 2030، بمعدل نمو سنوي مركب قدره 12.21٪. في المستقبل، تتمتع تقنية الذكاء الاصطناعي بإمكانيات كبيرة لإحداث تغييرات في صناعة الأدوية.
مراجع:
1.https://mp.weixin.qq.com/s/OL7TJQcUE-ubhUDyc7GBzQ
2.https://www.thepaper.cn/newsDetail_forward_29097303
3.https://news.bioon.com/article/6127e7234091.html
4.https://bydrug.pharmcube.com/news/detail/49720140c1e9d57ac3c7cfe20ef7f8be
5.https://mp.weixin.qq.com/s/UGAXWMhPlSg2hFnI5ghr1w









