Command Palette
Search for a command to run...
نجح فريق جامعة بيردو في تحقيق تمثيل لمسي فعال للبيانات لتعلم الروبوتات من خلال محاكاة الإمساك التفاعلي البشري

يعد اللمس جزءًا لا غنى عنه في رحلة الروبوتات نحو التعلم الذاتي، لأنه يمنح الآلات القدرة على إدراك تفاصيل العالم المادي. ومع ذلك، فإن تدريب أنظمة الإدراك اللمسي التقليدية يعتمد في كثير من الأحيان على جمع كميات هائلة من البيانات، وهو أمر مكلف وغير فعال. مع تزايد وضوح القيود المفروضة على الأساليب المعتمدة على البيانات،أصبحت كيفية تحسين أداء التعلم اللمسي من خلال التمثيل الفعال للبيانات أحد محاور أبحاث الروبوتات الحالية.
في السنوات الأخيرة، ظهرت بسرعة تقنيات مبتكرة تعتمد على التعلم الذاتي، والتمثيل المتناثر، والإدراك عبر الوسائط، مما يوفر أفكارًا جديدة لتبسيط وتحسين التمثيل اللمسي.

إن الاختراقات في هذا المجال لن تمكن الروبوتات من التكيف بسرعة مع المهام المعقدة ذات البيانات المحدودة فحسب، بل ستؤدي أيضًا إلى تحسين قدرتها على التفاعل مع البشر والبيئة بشكل كبير.في هذا التغيير الثوري، تفتح تقنية التمثيل اللمسي الفعالة للبيانات أبوابًا جديدة للإدراك والتعلم لدى الروبوتات.
في 18 ديسمبر، في الحدث الرابع للمشاركة عبر الإنترنت "القادمون الجدد على الحدود" الذي تستضيفه Embodied Touch Community وتنظمه شركة HyperAI،شارك Xu Zhengtong، وهو طالب دكتوراه في السنة الثالثة بجامعة بيردو، نتائج البحث العلمي الرئيسية لـ LeTac-MPC وUniT وطرق البحث التقنية الخاصة بهما مع الجميع تحت عنوان "التمثيل اللمسي الفعال للبيانات لتعلم الروبوت".
قام HyperAI بتجميع وتلخيص المشاركة المتعمقة للدكتور Xu Zhengtong دون انتهاك النية الأصلية.
التحسين التفاضلي هو أداة قوية في تعلم الروبوت
يعد التحسين أداة مهمة وفعالة للغاية في مجال الروبوتات، وقد أظهر العديد من النتائج الممتازة في تخطيط المسار والتفاعل بين الإنسان والحاسوب.قبل مناقشة التحسين،أولاً، علينا أن نقدم مفهومًا: التحسين القابل للتفاضل.ولتوضيح هذا المفهوم، نبدأ بالصياغة العامة لمشاكل التحسين.
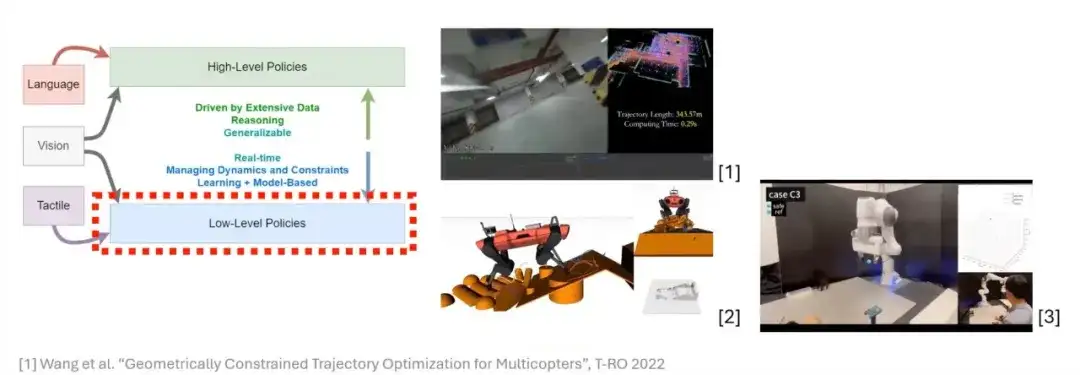
الفكرة الأساسية للتحسين هي إنشاء دالة هدف (دالة التكلفة) لسيناريوهات تطبيق محددة.تحتوي هذه الوظائف الموضوعية عادةً على قدر كبير من المعرفة المسبقة وقد تكون خاضعة لسلسلة من القيود. لذلك، عند صياغة مشاكل التحسين، غالبا ما يكون من الضروري إضافة هذه القيود إلى دالة الهدف.
التالي،سنركز على شكل أساسي من أشكال التحسين - البرمجة التربيعية (QP).وهو أحد أبسط الأشكال في مجال التحسين ولا يزال لديه مجموعة واسعة من السيناريوهات في التطبيقات العملية.

وعلى هذا الأساس نقدم مفهوم "القابل للتفاضل". تعني ما يسمى بالقابلية للتفاضل أنه في الشبكة العصبية، يمكن لمخرجات الطبقة حساب المشتقات الجزئية لمعلماتها الداخلية.تكمن أهمية إدخال البرمجة التربيعية القابلة للتفاضل (QP القابلة للتفاضل) في أنعندما نريد إضافة طبقة تحسين إلى شبكة عصبية، يجب أن نتأكد من أن الطبقة قابلة للتفاضل. بهذه الطريقة فقط يمكن تحديث معلمات طبقة التحسين بشكل طبيعي وتدفقها عبر معلومات التدرج أثناء تدريب الشبكة والاستدلال. لذلك، إذا تمكنا من جعل مشكلة البرمجة التربيعية قابلة للتفاضل، فيمكننا دمجها في الشبكة العصبية وجعلها جزءًا من الشبكة.
علاوة على ذلك، غالبًا ما تعتمد مشكلات التحسين في تعلم الروبوت على المعرفة السابقة في سيناريوهات محددة، مثل تصميم الوظائف والقيود الموضوعية. من خلال صياغة مشكلة تحسين قابلة للتفاضل، يمكننا استغلال هذه المعرفة السابقة بشكل كامل ودمجها في تصميم النموذج بكفاءة. ومع ذلك، في بعض الحالات، قد لا نتمكن من وصف المشكلة بطريقة تعتمد على النموذج (أي أننا لا نستطيع إنشاء تمثيل يعتمد على النموذج). في هذا الصدد،يمكنك محاولة استخدام أساليب تعتمد على البيانات للسماح للنموذج بتعلم قواعد هذه الأجزاء بنفسه. هذه هي الفكرة الأساسية لمشاكل التحسين القابلة للتفاضل.
باختصار، مشكلة البرمجة التربيعية تمتلك خاصية التفاضل، لذا يمكننا تقديمها كجزء من الشبكة العصبية.لا يوفر هذا النهج أدوات جديدة لتصميم الشبكات فحسب، بل يمنح أيضًا المزيد من المرونة والإمكانيات لتصميم النموذج في التعلم الآلي.
LeTac-MPC: بحث في أساليب الإمساك التفاعلي والتحكم في النماذج القائمة على الإشارات اللمسية
نقترح مفهومًا يسمى "التمسك التفاعلي".ومن خلال مراقبة عملية إمساك البشر بالأشياء، وجدنا أن البشر عادة ما يدركون خصائص وحالات الأشياء من خلال أصابعهم ويضبطون حركات أصابعهم بناء على ردود الفعل. على سبيل المثال:
* عندما نمسك البيضة فإننا نعتبرها صلبة ولكنها هشة، لذلك نستخدم القوة المناسبة لتجنب الضرر. مع زيادة ضغط ردود الفعل بالإصبع، فإننا نضعف قبضتنا.
* عند التقاط قطعة من الخبز، وبما أن الخبز طري، سيتم تعديل حركة أصابعك وفقًا لذلك لمنع الضغط عليه وتشويهه.
* عند إمساك زجاجة حليب، إذا قمت برجّ الزجاجة، فإن رجّ الحليب سيغيّر من عزم الجسم. تستشعر الأصابع هذه التغييرات وتضبط قبضتها بشكل ديناميكي لمنع الزجاجة من الانزلاق بسبب القصور الذاتي.

تنفيذ روبوت الإمساك التفاعلي
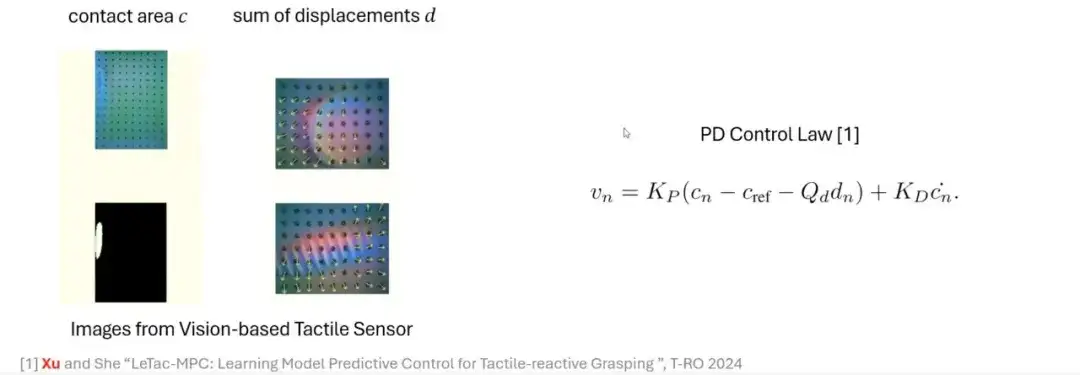
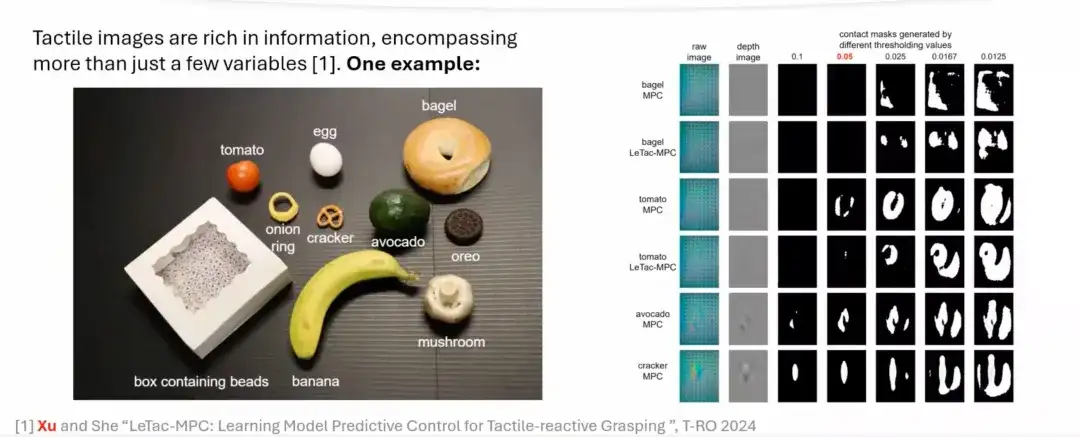
بالاستعانة بعملية الإمساك البشرية، نستكشف كيفية محاكاة هذه العملية من خلال نهج قائم على النموذج.مع أجهزة استشعار اللمس المعتمدة على الرؤية مثل GelSight،يمكننا استخراج الميزات الرئيسية من الصورة الأصلية، وإنشاء صورة عمق أو صورة فرق من خلال معالجة بسيطة، وحساب مساحة الاتصال من خلال عملية تحديد العتبة. يمكن أن تعكس مساحة التلامس مقدار القوة المطبقة. كلما زادت القوة، كلما زادت مساحة التلامس؛ كلما كانت القوة أصغر، كلما كانت مساحة التلامس أصغر.
بالإضافة إلى ذلك، من خلال استخدام تقنية التدفق البصري لتتبع حركة العلامات، يمكن الحصول على كمية مهمة أخرى: الإزاحة.هذه الكمية مرتبطة بالقوة الجانبية. من خلال الجمع بين هذه الإشارات، يمكننا إنشاء طريقة تحكم تعتمد على وحدة تحكم مشتقة تناسبية (PD) لتحقيق القدرة على الإمساك التفاعلي عن طريق اللمس.
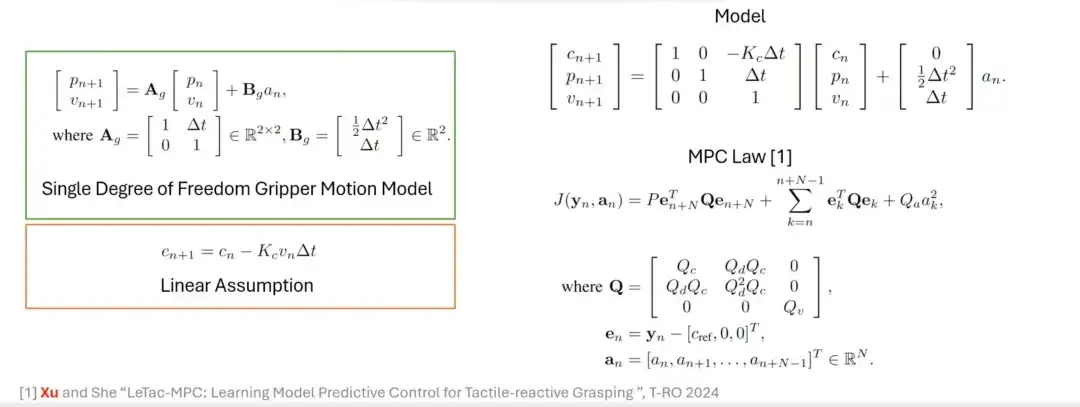
من وحدة التحكم PD إلى وحدة التحكم MPC
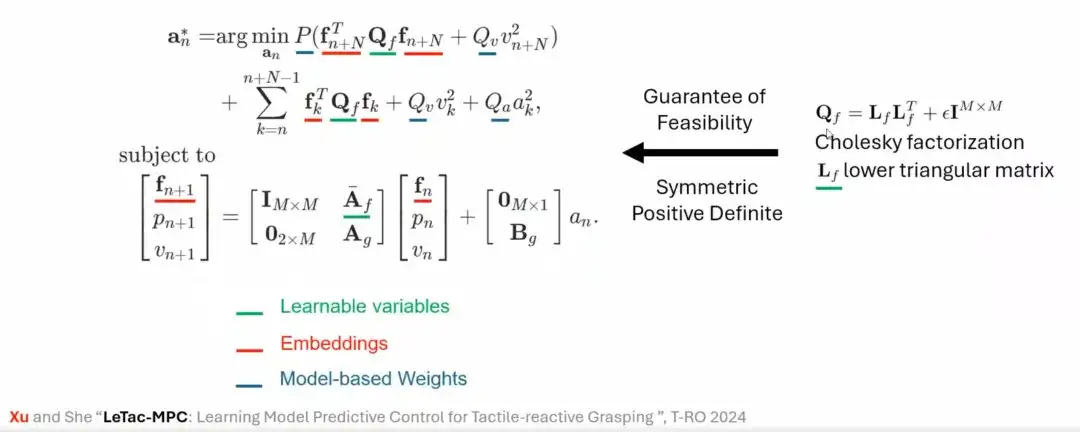
بالإضافة إلى وحدة التحكم PD، قمنا أيضًا بتصميم طريقة إمساك تعتمد على وحدة تحكم تنبؤية للنموذج (MPC). إن هدف التحكم في MPC مشابه لهدف وحدة التحكم PD، ولكن خصائصها تعتمد على افتراض خطي ونموذج Gripper. على سبيل المثال، يتم أولاً تقديم الافتراض الخطي ونموذج حركة القابض بدرجة الحرية الفردية، ثم يتم توحيد الاثنين ونمذجتهما، وأخيراً يتم إنشاء قانون التحكم القائم على MPC.
تطبيقات وقيود وحدات تحكم MPC
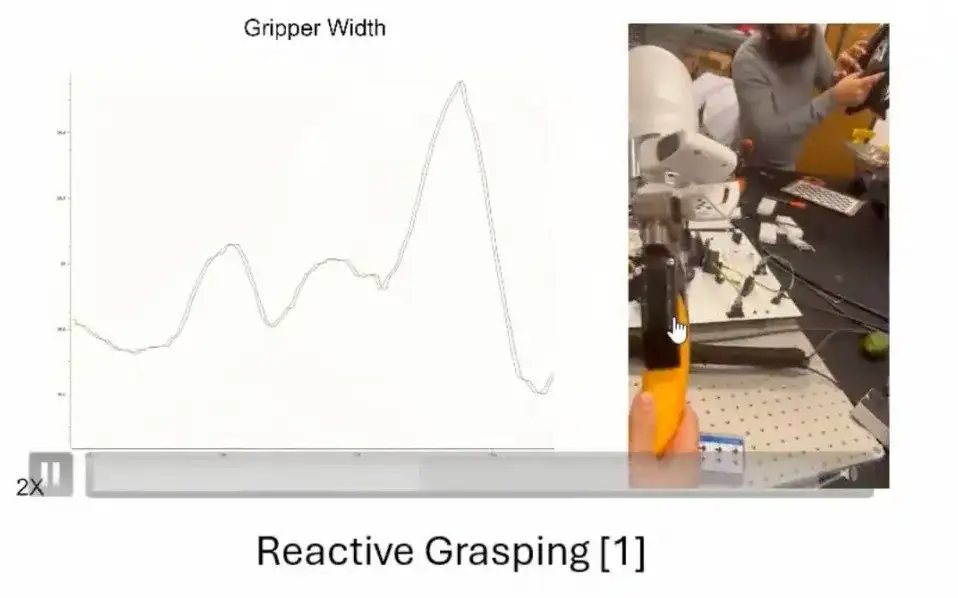
يؤدي نموذج وحدة التحكم MPC أداءً جيدًا في العديد من السيناريوهات.أدرج هنا تطبيقين.التطبيق الأول هو،عند سحب الموز، يمكن للمقبض ضبط القوة وفقًا للتغذية الراجعة الديناميكية للموز لضمان قبضة مستقرة. عندما تتم إزالة القوة الخارجية (مثل قيام شخص ما بترك الموز)، فإن وحدة التحكم ستتقارب تدريجيًا إلى حالة مستقرة.
عنوان الورقة:
https://ieeexplore.ieee.org/document/10684081
أما التطبيق الثاني فهو النتيجة التي اقترحها عضو آخر من مجموعتنا في IROS.وهذا يعني أنه يتم استخدام أداة إمساك متعددة درجات الحرية لتحقيق مهام تشغيل معقدة، كما يتم اعتماد وحدة التحكم MPC التي اقترحناها.
عنوان الورقة:
https://arxiv.org/abs/2408.00610

ومع ذلك، فإن وحدات التحكم القائمة على النموذج لها بعض القيود، ومن الصعب تعميمها على معظم الأشياء اليومية في الحياة الواقعية.ويرجع هذا بشكل أساسي إلى الافتراضات المبسطة في عملية النمذجة، والتي غالبًا ما لا تنطبق على بعض الكائنات الحقيقية. كما هو موضح في الشكل أدناه، بالنسبة للأشياء الناعمة أو الأشياء ذات الأشكال المعقدة، من الصعب استخراج منطقة التلامس بدقة عن طريق ضبط عتبة فقط. ومع ذلك، بالنسبة للأشياء الأكثر صلابة مثل الأفوكادو والبسكويت، فإن إشاراتها اللمسية (الصور اللمسية) تكون أقوى، وبالتالي يمكن استخراج منطقة التلامس بدقة.
ثلاث مزايا رئيسية لوحدة التحكم LeTac-MPC
ولحل هذه المشكلة، نستخدم الأساليب الرياضية (مثل تحليل العوامل Cholesky) لضمان إمكانية حل مشكلة التحسين، وبالتالي استقرار عملية تدريب وحدة التحكم، وأخيرًا اقترحنا LeTac-MPC.
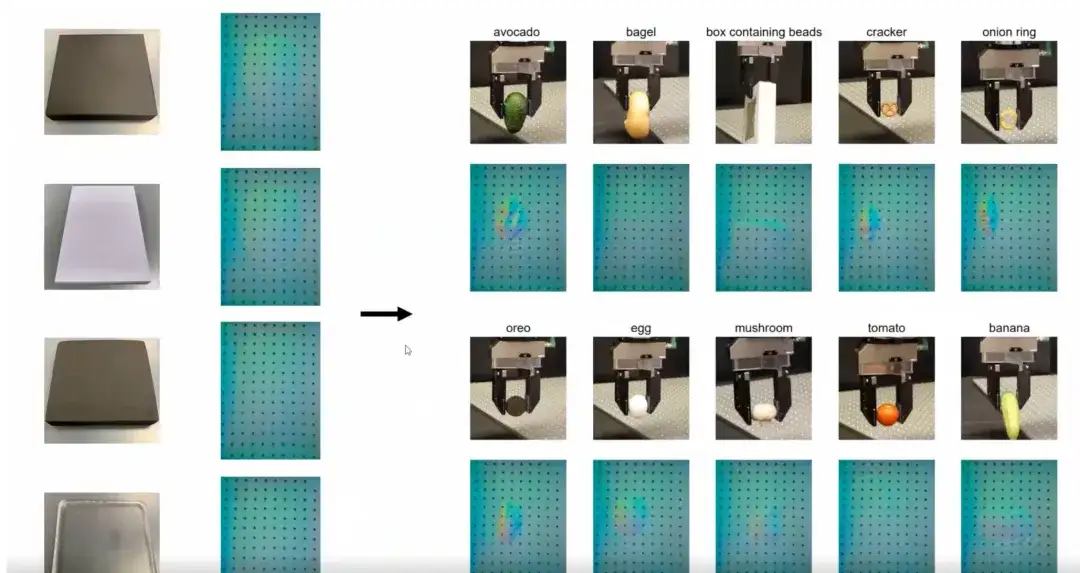
يوضح الشكل أدناه نتائج التدريب الأكثر بديهية. لقد قمنا بالتدريب على مجموعة بيانات تحتوي فقط على 4 كائنات ذات صلابة مختلفة. تتمتع هذه الأشياء بصلابة مختلفة. على الرغم من بيانات التدريب المحدودة، فإننا ندرب وحدات تحكم تعمم على الأشياء اليومية ذات الأحجام والأشكال والمواد والقوام المختلفة.إن قدرة التعميم هذه المبنية على تدريب عينة صغيرة تشكل ميزة رئيسية لوحدة التحكم.
ثانيًا، نقوم بتدريب المتحكم ليكون قويًا في مواجهة التداخل مع الكائن الذي تم الإمساك به.يمكن تعديل طريقة الإمساك وقوتها في الوقت الفعلي بحيث لا يسقط الجسم الممسك بسبب التدخل الخارجي.
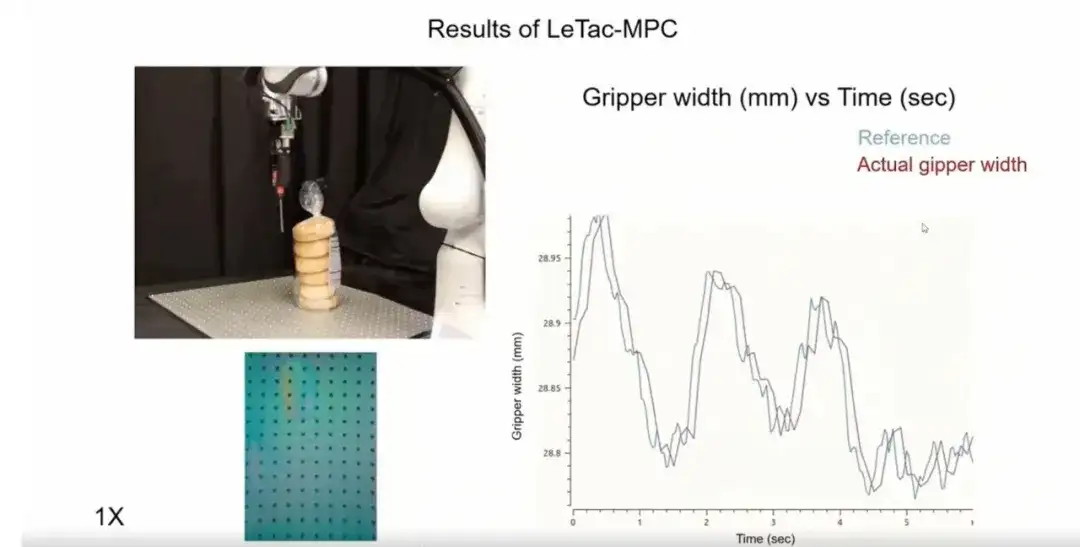
ثالثًا، المتحكم الذي ندربه سريع الاستجابة.كما هو موضح في الشكل أدناه، في السيناريوهات ذات الحركة الشديدة أو تغييرات القصور الذاتي (مثل صندوق مليء بالحطام)، يمكن لوحدة التحكم الاستجابة بسرعة للتغيرات الديناميكية للكائن.
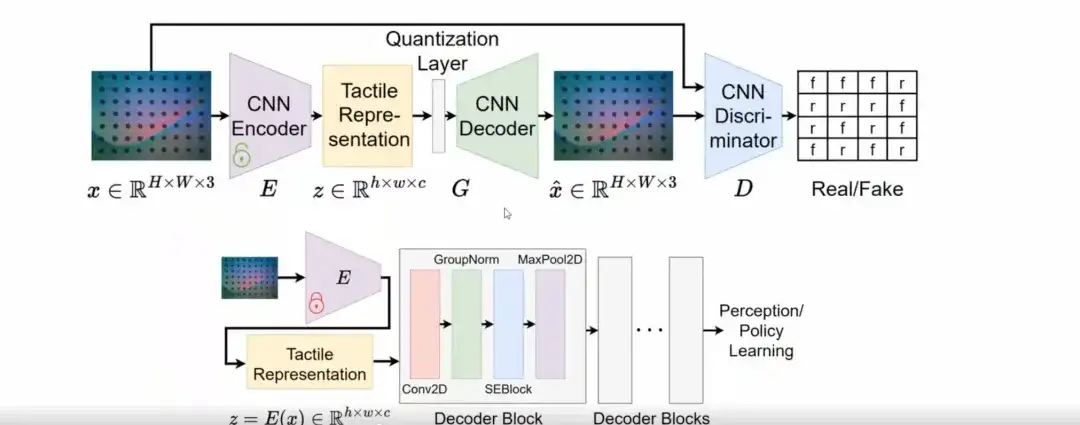
UniT: تمثيل لمسيّ موحّد لتعلّم الروبوتات
وفي البحث المذكور توصلنا إلى قدرة المتحكم على التعميم. هل يمكننا تعلم تمثيل لمسي موحد باستخدام كائن بسيط واحد؟
كما هو موضح في الشكل أدناه، يمكن أن يكون الكائن البسيط الواحد كائنًا هندسيًا بسيطًا مثل كرة صغيرة أو مفتاح ربط (مثل مفتاح ألين). وبما أن الصور اللمسية لهذه الأشياء بسيطة نسبيًا، فإن طريقتنا أيضًا بسيطة نسبيًا.

على وجه التحديد، بدلاً من تصميم بنية شبكة جديدة تمامًا، وجدنا أن VQGAN يمكنه تعلم التمثيلات اللمسية بشكل فعال مع قدرات التعميم.
في مرحلة التدريب، نعتمد نموذج VQGAN لتعلم التمثيلات اللمسية. في مرحلة الاستدلال، يتم فك تشفير المساحة الكامنة لـ VQGAN من خلال طبقة ملتوية بسيطة للاتصال بالمهام اللاحقة مثل الإدراك أو تعلم السياسات.
عنوان الورقة:
https://arxiv.org/abs/2408.06481
تجربة إعادة الإعمار
للتحقق من فعالية التمثيل، أجرينا تجارب إعادة بناء على Allen Key وSmall Ball.
التجربة الأولى هي تجربة ألين كي.كما هو موضح في الشكل أدناه، على الرغم من أن بيانات التدريب تأتي فقط من مفتاح ألين، فما زال بإمكاننا إعادة بناء الصورة الأصلية للكائن غير المرئي من خلال الفضاء الكامن، مما يدل على أن الفضاء الكامن يحتوي على معظم المعلومات المفيدة للصورة الأصلية. عند المقارنة مع MAE، نجد أنه من الصعب على MAE إعادة بناء الصورة الأصلية بدقة، مما يشير إلى أن MAE قد يعاني من فقدان المعلومات أثناء عملية فك التشفير.

التجربة الثانية هي تجربة الكرة الصغيرة.كما هو موضح في الشكل أدناه، على الرغم من أن بيانات التدريب تأتي فقط من Small Ball وأن تأثير إعادة البناء ليس جيدًا مثل Allen Key، إلا أن النموذج لا يزال قادرًا على إعادة بناء الإشارة الأصلية للأشياء المعقدة إلى حد ما.

بالإضافة إلى ذلك، لا تلتقط المساحة الكامنة المعلومات الهندسية اللمسية فحسب (مثل الشكل وتكوين الاتصال)، بل تحتوي أيضًا ضمناً على معلومات حركة العلامات. على سبيل المثال، من خلال تتبع علامات الصورة الأصلية والصورة المعاد بناؤها، وجدنا أن أداءهما في تتبع العلامات متشابه للغاية.

المهام والمعايير النهائية
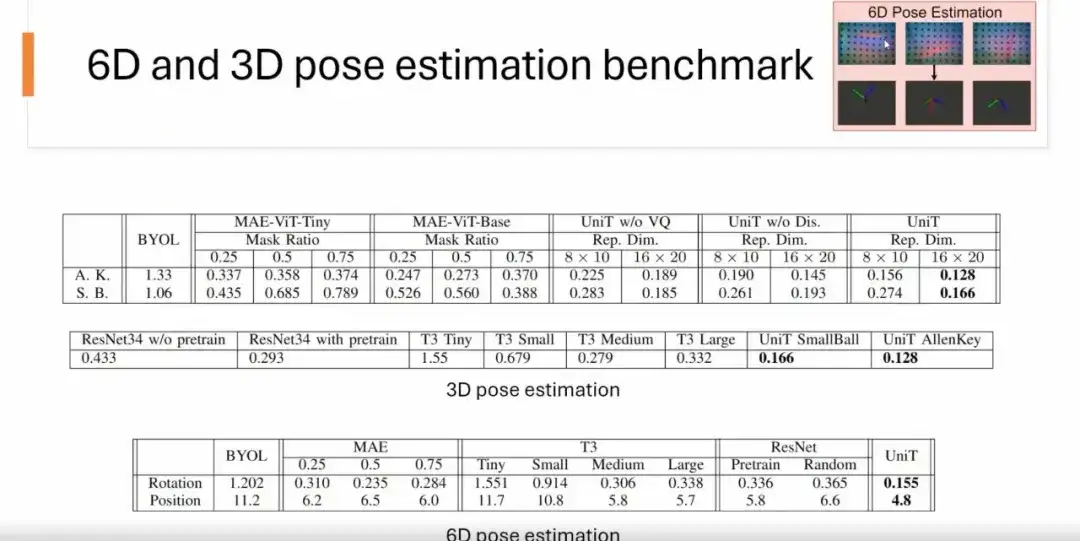
لقد قمنا باختبار قدرات التمثيل لطريقة UniT على معايير متعددة، بما في ذلك تقدير الوضع 6D، وتقدير الوضع 3D، ومعايير التصنيف.
لتقدير وضعية 6D،نقوم بإدخال صورة خام ملموسة (مثل صورة ملموسة لمقبس USB) للتنبؤ بموقعه ودورانه. تظهر النتائج أنه بالمقارنة مع طرق MAE وBYOL وResNet وT3، فإن نموذج UniT يتفوق على الطرق الأخرى في الدقة.
لتقدير الوضع ثلاثي الأبعاد،نحن فقط نتوقع الوضع الدوراني للكائن. كما هو موضح في الشكل أدناه، فإن أداء UniT أفضل من الطرق الأخرى.
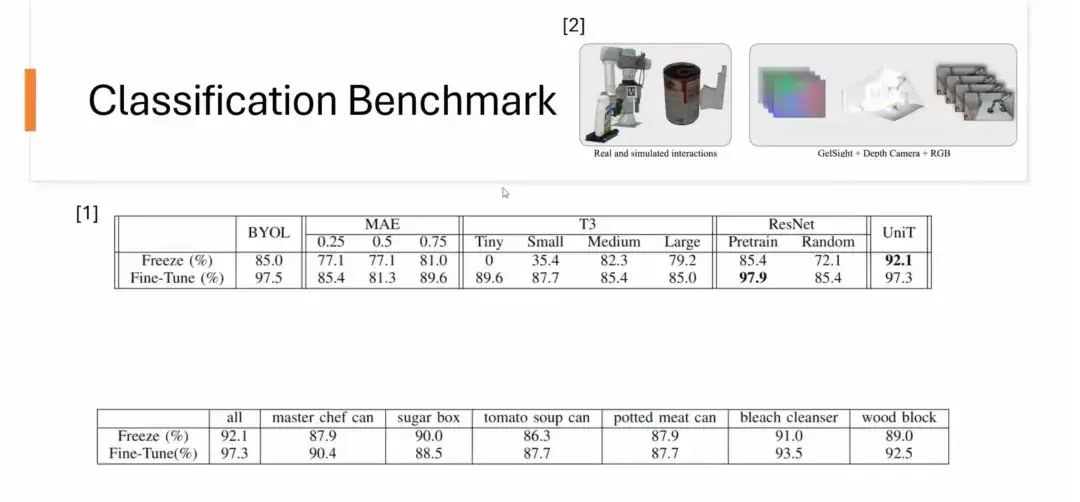
ثانياً، قمنا أيضاً بعمل معيار تصنيفي.تأتي مجموعة البيانات من YCBSight-Sim التابع لجامعة CMU. على الرغم من أن مجموعة البيانات صغيرة، إلا أن UniT تظهر أداءً جيدًا في مهام التصنيف. وعلى وجه الخصوص، بعد تعلم التمثيل اللمسي لكائن واحد، فإنه يمكن بشكل طبيعي تعميم مهام تصنيف الكائنات غير المرئية الأخرى. على سبيل المثال، يمكن تطبيق التمثيل الذي تم تدريبه فقط على رئيس الطهاة بنجاح على تصنيف 6 أشياء مختلفة مع الحصول على نتائج ممتازة. تتفوق بعض التمثيلات المدربة على كائن واحد على تلك التي تم تدريبها على عدد كبير من الكائنات.
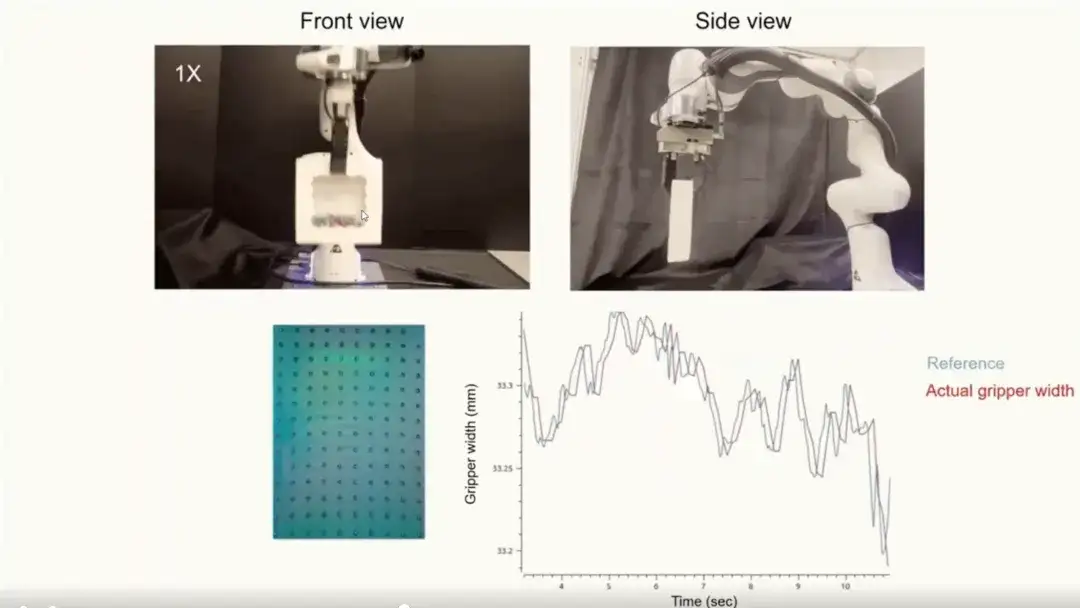
تجربة تعلم الاستراتيجية
لقد قمنا أيضًا بتطبيق التمثيل الملموس على تجارب تعلم السياسة.التحقق من أدائه في المهام المعقدة. استخدمت التجربة بيانات مفتاح ألين للتدريب وقامت بتقييم المهام الثلاث التالية:
* إدخال مفتاح ألين (انظر اليسار): مهمة إدخال دقيقة تتطلب دقة عالية للغاية.
* الإمساك بالرقائق (انظر الصورة): التعامل مع مهام الإمساك الدقيقة للأشياء الهشة.
تعليق أرجل الدجاج (انظر إلى اليمين): مهمة تتطلب استخدام ذراعين وتتضمن الإمساك والتحكم الديناميكي على المدى الطويل.

لقد قمنا بمقارنة ثلاثة أساليب مختلفة:الأساليب الثلاثة هي: الرؤية فقط (الاعتماد فقط على الإشارات البصرية)، والرؤية اللمسية من الصفر (تدريب مشترك على الرؤية واللمس)، والرؤية اللمسية مع UniT (استخدام التمثيلات اللمسية المستخرجة بواسطة UniT لتعلم الاستراتيجية). كما هو موضح في الشكل أدناه، فإن أسلوب تعلم السياسات باستخدام تمثيل UniT يحقق أفضل أداء في جميع المهام.

وفي المستقبل، سوف تساعد HyperAI أيضًا مجتمع اللمس المتجسد على مواصلة عقد أنشطة المشاركة عبر الإنترنت، ودعوة الخبراء والعلماء من الداخل والخارج لمشاركة النتائج والرؤى المتطورة. ابقوا متابعين!








