Command Palette
Search for a command to run...
برنامج تعليمي حول كيفية استخدام A6000 مع بطاقة واحدة لبدء AlphaFold3 بنقرة واحدة متاح الآن على الإنترنت! تم إصدار مجموعة بيانات التقاط الحركة بزاوية 360 درجة، بما في ذلك أكثر من 70 ألف مقطع فيديو و50 كائنًا ماديًا

في الأسبوع الماضي، قامت HyperAl بتحديث قاعدة بيانات التبعيات AlphaFold3، لكن العديد من الأصدقاء أبلغوا أن البيانات كانت كبيرة للغاية ويصعب نشرها.
هذا الاسبوع،أطلق الموقع الرسمي لـ hyper.ai العرض التوضيحي "AlphaFold3 Protein Prediction Demo"تم تثبيت وتكوين البيانات والنماذج ذات الصلة، وهي تشغل أقل من 300 ميجا بايت من مساحة التخزين الشخصية، ولا يتطلب الأمر سوى بطاقة A6000 واحدة لنشر AlphaFold3 واستخدامه بسرعة للتنبؤ بالبروتينات.
الاستخدام عبر الإنترنت:https://go.hyper.ai/KHIRR
من 16 ديسمبر إلى 20 ديسمبر، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* اختيار المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات التي لها مواعيد نهائية في يناير: 9
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات اكتشاف الطائرات بدون طيار
تتكون مجموعة البيانات من أكثر من 10 آلاف صورة لطائرات بدون طيار مع مربعات حدودية موضحة حول كل طائرة بدون طيار. توفر المربعات المحددة معلومات تحديد المواقع الدقيقة لاكتشاف الطائرات بدون طيار وتتبعها في مجموعة متنوعة من الخلفيات والبيئات. تعتبر مجموعة البيانات مناسبة لتدريب وتقييم نماذج الرؤية الحاسوبية لمهام اكتشاف الكائنات، وخاصة في التطبيقات مثل المراقبة، واكتشاف الطائرات بدون طيار، والتتبع الذاتي.
الاستخدام المباشر:https://go.hyper.ai/686JV

2. مجموعة بيانات التقاط الحركة 360Motion-Dataset
تحتوي النسخة V1 من مجموعة البيانات هذه على 72 ألف مقطع فيديو تغطي 50 كيانًا مختلفًا، مثل الحيوانات المختلفة، و6 مشاهد من Unreal Engine (UE)، بما في ذلك مشهد صحراوي واحد ومشهدين HDRI. بالإضافة إلى ذلك، تحتوي مجموعة البيانات أيضًا على 121 نموذجًا مختلفًا للمسار، مما يوفر للباحثين أنماط حركة غنية وتغييرات سلوكية.
الاستخدام المباشر:https://go.hyper.ai/rsmeQ

تُستخدم مجموعة البيانات هذه لتصنيف وتجزئة أورام المخ باستخدام نماذج مختلفة. ويحتوي على 7,153 صورة في المجموع، بما في ذلك 1,621 صورة لورم دبقي، و1,775 صورة لورم سحائي، و1,757 صورة للغدة النخامية، و2,000 صورة خالية من الأورام (دماغ سليم).
الاستخدام المباشر:https://go.hyper.ai/zgX7A
4. مجموعة بيانات LAION-SG لفهم الصور عالية الجودة واسعة النطاق
يحتوي LAION-SG على 540,005 زوجًا من رسم بياني للمشهد والصورة مع تعليقات توضيحية للأشياء والسمات والعلاقات، والتي تنقسم إلى مجموعات تدريب وتحقق واختبار. تأتي الصور الموجودة في مجموعة البيانات من مجموعة بيانات LAION-Aesthetics V2 (6.5+)، وتستخدم عملية التعليق التوضيحي GPT-4o للتعليق التوضيحي التلقائي.
الاستخدام المباشر:https://go.hyper.ai/HHT6V

5. مجموعة بيانات سمات الملابس مجموعة بيانات سمات الملابس
تحتوي مجموعة البيانات على 1,856 صورة مع 26 سمة أساسية للملابس، مثل الأكمام الطويلة والياقة والنمط المخطط. تم جمع الملصقات باستخدام Amazon Mechanical Turk.
الاستخدام المباشر:https://go.hyper.ai/7f3ej

6. اكتشاف الوجوه المولدة بواسطة الذكاء الاصطناعي - مجموعة بيانات اكتشاف الوجوه
تحتوي مجموعة البيانات على 3203 صورة عالية الجودة لوجوه حقيقية ووجوه اصطناعية تم إنشاؤها بواسطة الذكاء الاصطناعي، بما في ذلك 2202 صورة حقيقية و1001 صورة تم إنشاؤها بواسطة الذكاء الاصطناعي، وهي مصممة لتطبيقات التعلم الآلي والتعلم العميق. ويهدف إلى توفير موارد صور الوجه التي يمكنها التمييز بين الوجوه الحقيقية والوجوه التي تم إنشاؤها بواسطة الذكاء الاصطناعي. إنه مناسب لمهام مثل اكتشاف التزييف العميق، والتحقق من صحة الصورة، وتحليل صور الوجه، ويمكنه دعم الأبحاث والتطبيقات المتطورة.
الاستخدام المباشر:https://go.hyper.ai/SwMXL

7. مجموعة بيانات الاستدلال الرياضي U-MATH
تحتوي مجموعة البيانات على 1.1 ألف مشكلة رياضية غير منشورة على مستوى الكلية مستمدة من مواد تعليمية حقيقية وتغطي ستة مواضيع أساسية في الرياضيات: الرياضيات الابتدائية، والجبر، وحساب التفاضل والتكامل، وحساب التفاضل والتكامل المتعدد المتغيرات، والمتتاليات والمتسلسلات.
الاستخدام المباشر:https://go.hyper.ai/FcNc2
8. مجموعة بيانات الضبط الدقيق المُشرف Open01-SFT
مجموعة بيانات OpenO1-SFT هي مجموعة بيانات تركز على تنشيط قدرة سلسلة الأفكار في نماذج اللغة باستخدام طريقة الضبط الدقيق الخاضع للإشراف (SFT)، بهدف تعزيز قدرة النموذج على توليد تسلسلات منطقية متماسكة. تحتوي على 77,685 سجلاً، والتي لا تغطي اللغة الصينية فحسب، بل أيضًا اللغة الإنجليزية، مما يجعل مجموعة البيانات مفيدة في البيئات متعددة اللغات.
الاستخدام المباشر:https://go.hyper.ai/KlyzY
9. مجموعة بيانات الضبط الدقيق QwQ-LongCoT-130K
مجموعة البيانات QwQ-LongCoT-130K عبارة عن مجموعة بيانات SFT (الضبط الدقيق الخاضع للإشراف) مصممة لتدريب نماذج اللغة الكبيرة (LLMs) مثل O1. تحتوي مجموعة البيانات هذه على حوالي 130 ألف حالة، كل منها عبارة عن استجابة تم إنشاؤها باستخدام نموذج QwQ-32B-Preview.
الاستخدام المباشر:https://go.hyper.ai/kE9aG
10. التعلم الآلي في براءات الاختراع في مجال الرعاية الصحية
تم تجميع مجموعة البيانات من براءات اختراع جوجل باستخدام استعلام البحث "التعلم الآلي والرعاية الصحية" وتتضمن براءات الاختراع الممنوحة في مجالات تتراوح من التصوير الطبي وأدوات التشخيص إلى توصيات العلاج المدفوعة بالذكاء الاصطناعي.
الاستخدام المباشر:https://go.hyper.ai/8p1M5
دروس تعليمية عامة مختارة
1. عرض توضيحي لتوقع بروتين AlphaFold3
AlphaFold3 هي أداة ذكاء اصطناعي (AI) تم تطويرها في عام 2024 بواسطة Google DeepMind. يستخدم نموذج AlphaFold 3 بنية تعتمد على الانتشار والتي لا يمكنها التنبؤ بهياكل البروتين فحسب، بل يمكنها أيضًا التنبؤ بدقة بهياكل المجمعات بما في ذلك الأحماض النووية والجزيئات الصغيرة والأيونات والبقايا المعدلة.
سوف يقدم هذا البرنامج التعليمي كيفية نشر AlphaFold3 واستخدامه بسرعة للتنبؤ بالبروتينات. كل ما تحتاج إليه هو بطاقة A6000 واحدة لتشغيل التجربة.
تشغيل عبر الإنترنت:https://go.hyper.ai/KHIRR
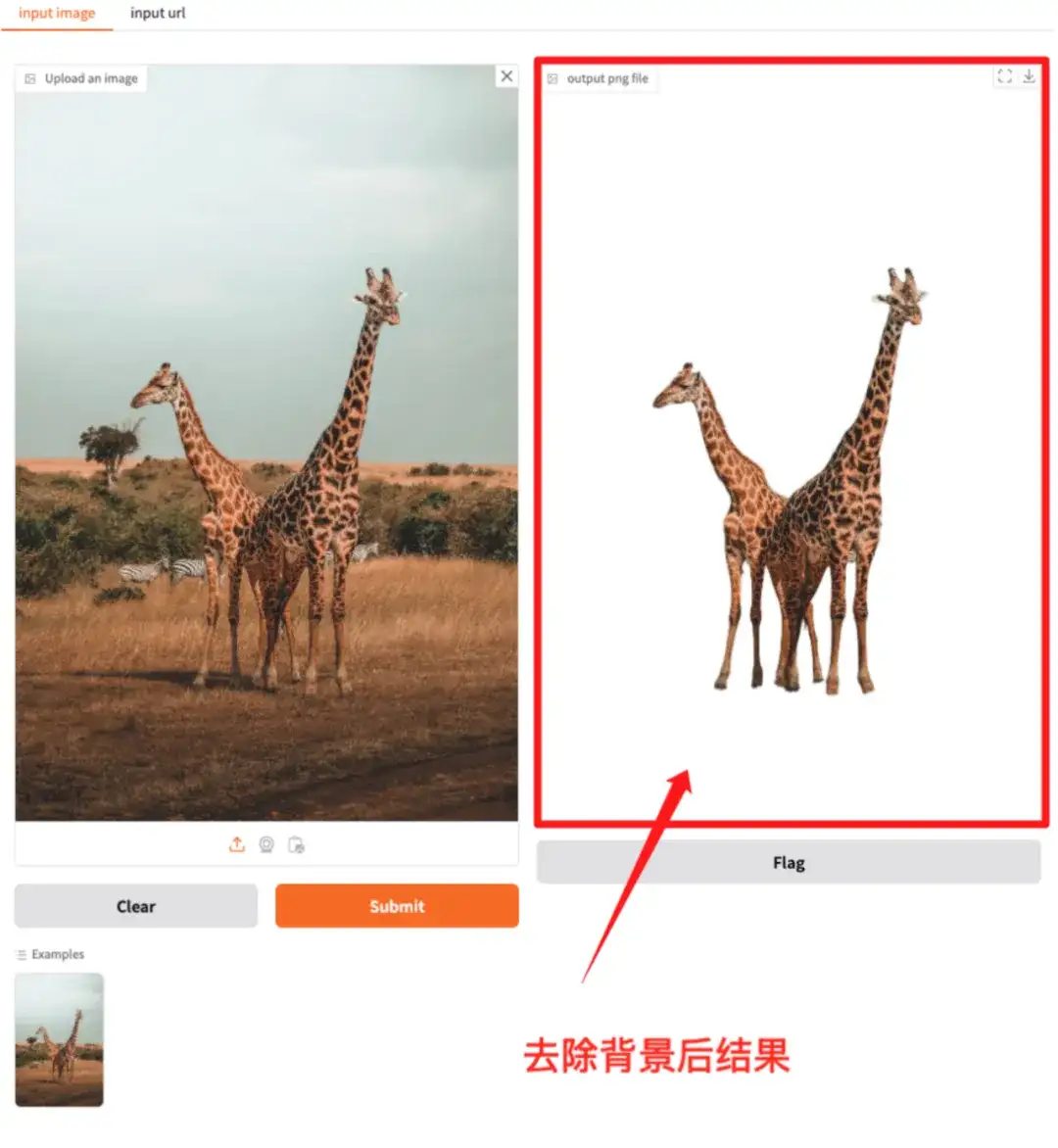
2. RMBG-2.0: نموذج إزالة الخلفية مفتوح المصدر
RMBG-2.0 هو نموذج طرح الخلفية مفتوح المصدر مصمم لفصل المقدمة عن الخلفية بشكل فعال عبر مجموعة متنوعة من الفئات وأنواع الصور.
قام النموذج بتكوين البيئة والتبعيات. بإمكانك إدخال عنوان API لتجربة قص الصورة بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/FF10L
3. DePLM: تحسين البروتينات باستخدام نماذج اللغة الخالية من الضوضاء (عينات صغيرة)
يمكن لنموذج لغة البروتين منزوع الضوضاء (DePLM) معالجة المعلومات التطورية التي تم التقاطها بواسطة نموذج لغة البروتين كمزيج من المعلومات ذات الصلة وغير ذات الصلة بخصائص الهدف المحسنة، حيث تُعتبر المعلومات غير ذات الصلة "ضوضاء" ويتم التخلص منها، وبالتالي تحسين دقة النموذج في التنبؤ بالمناظر الطبيعية التكيفية للبروتين والمساعدة في تحديد التسلسل الأمثل وظيفيًا للتحسين.
يتناول هذا البرنامج التعليمي تدريب واستنتاج نموذج لغة البروتين لإزالة الضوضاء (DePLM) الذي أصدرته جامعة تشجيانغ. لقد تم اختيار النتائج ذات الصلة لـ "NeurIPS 24". قامت المنصة بتكوين البيئة ومجموعة البيانات المطلوبة. يمكنك إجراء التدريب والاستدلال من خلال تنفيذ الأوامر الواردة في البرنامج التعليمي بشكل مباشر.
تشغيل عبر الإنترنت:https://go.hyper.ai/ktd87
لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

مقالات المجتمع
أعلنت شركة Enveda، وهي شركة ناشئة في مجال الذكاء الاصطناعي في الولايات المتحدة، مؤخرًا أنها أكملت تمويلًا بقيمة 130 مليون دولار أمريكي من الفئة C، ليصل إجمالي مبلغ التمويل إلى 360 مليون دولار أمريكي. بالإضافة إلى ذلك، في نهاية أكتوبر/تشرين الأول من هذا العام، حصل ENV-294، أول مرشح دواء تم اكتشافه باستخدام منصة Enveda، على موافقة IND من إدارة الغذاء والدواء الأمريكية ودخل مرحلة التجارب السريرية للمرحلة الأولى. تعتبر هذه المقالة تقريرا مفصلا عن المؤسسة.
شاهد التقرير الكامل:https://go.hyper.ai/rMk2U
بسبب الموقع الجغرافي الخاص لهضبة تشينغهاي-التبت، فإن بيانات تدفق الحرارة السطحية في بعض المناطق الوعرة نادرة للغاية. ولحل هذه المشكلة، اقترحت كلية علوم الأرض بجامعة تشجيانغ نموذج الانحدار المرجح للشبكة العصبية الجغرافية مع إمكانية تفسير محسنة، والذي يوفر إطارًا بحثيًا جديدًا ودعمًا فنيًا لفهم شامل لتوزيع تدفق الحرارة والآلية الجيوديناميكية لهضبة تشينغهاي-التبت. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/vqQDi
في البث المباشر الخامس لـ Meet AI4S، شارك وانج زيوان، طالب الدكتوراه في مختبر محرك المعرفة بجامعة تشجيانغ، إنجازًا تم اختياره لـ NeurlPS 2024 وأظهر عرضًا توضيحيًا. كما قدم أيضًا تجربته في الخضوع. فهو مليء بالمعلومات العملية، لذا اضغط لمشاهدته بسرعة.
شاهد التقرير الكامل:https://go.hyper.ai/PLyBo
أصدرت شركة DeepMind وGoogle Research التابعة لشركة Google عددًا من النتائج في مجال التنبؤ بالطقس، مع الأخذ في الاعتبار التوقعات قصيرة ومتوسطة وطويلة الأجل، ودمج الأساليب التقليدية مع الذكاء الاصطناعي، وبناء "محارب سداسي" تدريجيًا للتنبؤ بالطقس.
شاهد التقرير الكامل:https://go.hyper.ai/Cvzkc
مقالات موسوعية شعبية
1. دمج الفرز المتبادل RRF
2. نمذجة اللغة المقنعة (MLM)
3. القاعدة النووية
4. نظرية كولموغوروف-أرنولد للتمثيل
5. زيادة البيانات
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:

تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!








