Command Palette
Search for a command to run...
شارك بتجربتك في التقديم إلى NeurIPS 2024! يستخدم فريق جامعة تشجيانغ نموذج DePLM للمساعدة في تحسين البروتين، ويوضح المؤلف الأول للورقة البحثية النموذج التجريبي عبر الإنترنت

أكد هاري شوم، العضو الأجنبي في الأكاديمية الوطنية الأمريكية للهندسة، ذات مرة: "إذا كان هناك ما يجب علينا فعله اليوم، فهو الذكاء الاصطناعي في خدمة العلم. من الصعب تخيل وجود أي شيء أكثر أهمية اليوم، ومنح جائزة نوبل هذا العام خير دليل على ذلك".
في الماضي، اعتمد العلماء على تنظيم البيانات يدويًا والفرضيات المبنية على نظريات الموضوع. والآن، بمساعدة الذكاء الاصطناعي، يتم إجراء الأبحاث بشكل مباشر بناءً على بيانات ضخمة. لم يعمل الذكاء الاصطناعي للعلوم على تحسين كفاءة البحث العلمي فحسب، بل غيّر أيضًا نموذج البحث العلمي بأكمله، وهو أمر واضح بشكل خاص في مجال أبحاث البروتين.
في الحلقة الخامسة من Meet AI4S، كان من حسن حظ HyperAI أن تدعو Wang Zeyuan، طالبة الدكتوراه من مختبر محرك المعرفة بجامعة Zhejiang،قدم مقدمة مفصلة لورقة بحثية للفريق المختار لمؤتمر NeurIPS 2024 بعنوان "استخدام عملية إزالة الضوضاء بالانتشار لمساعدة النماذج الكبيرة على تحسين البروتينات" "DePLM: إزالة الضوضاء من نماذج لغة البروتين لتحسين الخصائص".
باعتباره المؤتمر الأهم في مجال الذكاء الاصطناعي، يُعرف مؤتمر NeurIPS بأنه أحد أصعب المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي وأعلى مستوى وأكثرها تأثيرًا. في هذا العام، تلقى المؤتمر ما مجموعه 15,671 ورقة بحثية صالحة، بزيادة قدرها 27% عن العام الماضي، ولكن معدل القبول النهائي بلغ 25.8% فقط. تعتبر الأوراق المختارة ذات قيمة تعليمية كبيرة.في جلسة المشاركة هذه، قدم الدكتور وانج زيوان بالتفصيل مفهوم التصميم والاستنتاجات التجريبية ووضع التشغيل التجريبي والآفاق المستقبلية لنموذج لغة البروتين الخالي من الضوضاء DePLM. كما شاركنا بتجربته في تقديم أوراق بحثية إلى مؤتمرات مرموقة، آملاً أن تكون مفيدة للجميع.
وعلى وجه التحديد، قال الدكتور وانج أنه عندما نقدم أوراقًا بحثية، يمكننا أن نبدأ من اختيار الموضوع، والنقاط المبتكرة، وكتابة الورقة، والتعامل مع المراجعات متعددة التخصصات.
أولاً، فيما يتعلق باختيار الموضوع،يمكنك قراءة مجموعة واسعة من أوراق المؤتمرات المتميزة لفهم اتجاهات البحث الأكثر أهمية التي يهتم بها المجتمع حاليًا. على سبيل المثال، عند إعداد ورقة DePLM، وجد الدكتور وانج أن هندسة البروتين، وخاصة مهام التنبؤ بالبروتين، كانت موضوعًا ساخنًا في مؤتمري ICLR وNeurIPS في العام الماضي.
ثانياً، من حيث الابتكار،ويعتقد أنه من المهم تنمية القدرة على اكتشاف المشاكل. في مجال الذكاء الاصطناعي للعلوم، يجب علينا أولاً أن يكون لدينا فهم عميق للمعرفة في مجال العلوم، ومقارنتها بالمحتوى في مجال الذكاء الاصطناعي لمعرفة المجالات الفارغة التي لم يتم استكشافها بعد بواسطة الذكاء الاصطناعي.
من حيث كتابة المقال،وقال إن الكتابة يجب أن تكون منطقية وواضحة ومفصلة لضمان سهولة فهم المقال. ومن الضروري أيضًا التواصل بشكل أكبر مع المعلمين وزملاء الدراسة لتجنب الوقوع في أنماط التفكير الثابتة الخاصة بالشخص.
أخيرًا، مع الأخذ في الاعتبار أن أوراق الذكاء الاصطناعي للعلوم قد تتم مراجعتها من قبل مراجعين من خلفيتين مختلفتين، أحدهما يركز بشكل أكبر على تكنولوجيا الذكاء الاصطناعي والآخر يركز على تطبيقات العلوم،لذلك، من الضروري توضيح الموقع الأساسي للورقة عند الكتابة.وهذا يعني، سواء كانت هذه الورقة موجهة إلى مجتمع الذكاء الاصطناعي أو مجتمع العلوم، ويتم بناء إطار منطقي وفقًا لذلك لضمان أن يكون المحتوى مرتبطًا ارتباطًا وثيقًا بالموضوع.
في رأيه، لقد تغير الاتجاه الحالي لبحوث النماذج واسعة النطاق. لقد انتقلنا من نهج التقليد البسيط إلى فهم عميق للنماذج واسعة النطاق.في الماضي، كنا نسمح للنماذج الكبيرة بالتكيف مع المهام اللاحقة المتنوعة، ولكننا الآن نهتم أكثر بكيفية جعل المهام اللاحقة تتعاون بشكل أفضل مع مرحلة ما قبل التدريب للنماذج الكبيرة. كلما كان التوافق بين الاثنين أكبر، كان أداء النموذج أفضل.
على سبيل المثال، بالنسبة للتنبؤ بالمناظر الطبيعية التكيفية، فإن طرق الضبط الدقيق البسيطة التقليدية تحقق أداءً ضعيفًا من حيث القدرة على التعميم. نحن بحاجة إلى فهم أعمق للنماذج الكبيرة ونماذج التعلم غير الخاضعة للإشراف لتحديد أوجه القصور فيها وتحسينها. بالإضافة إلى ذلك، يجب علينا أيضًا الانتباه إلى عيوب النماذج الكبيرة نفسها، مثل استكشاف طرق القضاء على تحيز النموذج من أجل تحسين أداء النموذج.
نموذج مفتوح المصدر وقابل للاختبار
أود اليوم أن أشارككم ورقة بحثية نشرناها في NeurIPS 2024، والتي تستكشف كيفية استخدام نموذج إزالة الضوضاء الانتشارية للمساعدة في تحسين نماذج اللغة الكبيرة للبروتينات.في هذه الورقة، نقترح نموذج لغة البروتين الخالي من الضوضاء (DePLM)ويتمثل جوهر هذا النهج في النظر إلى المعلومات التطورية التي يلتقطها نموذج لغة البروتين باعتبارها مزيجًا من المعلومات ذات الصلة وغير ذات الصلة بالخصائص المستهدفة، حيث تُعتبر المعلومات غير ذات الصلة "ضوضاء" ويتم التخلص منها. وجدنا أن إجراء إزالة الضوضاء القائم على الترتيب المقترح يمكن أن يحسن بشكل كبير أداء تحسين البروتين مع الحفاظ على قدرات التعميم القوية.
حاليًا، أصبح DePLM مفتوح المصدر. بسبب بيئة التكوين المعقدة للنموذج،لقد أطلقنا "DePLM: تحسين البروتينات باستخدام نماذج اللغة الخالية من الضوضاء (عينات صغيرة)" في قسم البرامج التعليمية على الموقع الرسمي لـ HyperAI.من أجل مساعدتك على فهم عملنا وإعادة إنتاجه بشكل أفضل، سأشرح لك كيفية عمل النموذج من عدة جوانب، بما في ذلك كيفية تشغيل نموذج DePLM، وما هي ملفات التكوين المرتبطة به، وكيفية ضبط خطوات انتشار النموذج، وكيفية تشغيل نموذج DePLM بمجموعة البيانات الخاصة بك.
عنوان المصدر المفتوح لـ DePLM:
https://github.com/HICAI-ZJU/DePLM
عنوان البرنامج التعليمي DePLM:
الخلفية: تعظيم استخدام المعلومات التطورية وتقليل إدخال إشارات تحيز البيانات
هدف البحث في هذه المقالة هو البروتين، وهو جزيء بيولوجي كبير يتكون من 20 حمض أميني على التوالي. ويقوم بوظائف مثل التحفيز والتمثيل الغذائي وتكرار الحمض النووي في الجسم، كما أنه المنفذ الرئيسي للأنشطة الحياتية. يقوم علماء الأحياء عادة بتقسيم بنيته إلى 4 مستويات. يصف المستوى الأول كيفية تكوين البروتينات؛ المستوى الثاني يصف البنية المحلية للبروتينات، مثل حلزونات ألفا وطيات بيتا الشائعة؛ المستوى الثالث يصف البنية الشاملة ثلاثية الأبعاد للبروتينات؛ والمستوى الرابع يتناول التفاعلات بين البروتينات.
في الوقت الحالي، يمكن إرجاع معظم أبحاث الذكاء الاصطناعي والبروتين إلى أبحاث معالجة اللغة الطبيعية نظرًا لوجود أوجه تشابه بين الاثنين. على سبيل المثال، يمكننا مقارنة البنية الرباعية للبروتين بالحروف والكلمات والجمل والفقرات في اللغة الطبيعية. عندما يحدث خطأ في أحد الحروف في الجملة، تفقد الجملة معناها. وبالمثل، فإن الطفرة في الأحماض الأمينية للبروتين قد تتسبب في عدم قدرة البروتين على تكوين بنية مستقرة وبالتالي فقدان وظيفته.
كما هو موضح في الشكل أدناه، في الورقة البحثية "تصميم البروتين القابل للتحكم باستخدام نماذج اللغة"، قام الباحثون بمطابقة اللغة الطبيعية مع البروتينات. وقد تم الاعتراف بهذا النهج على نطاق واسع من قبل الباحثين. منذ عام 2020، أظهرت أبحاث البروتين نموًا هائلاً.
الورق الأصلي:
https://www.nature.com/articles/s42256-022-00499-z
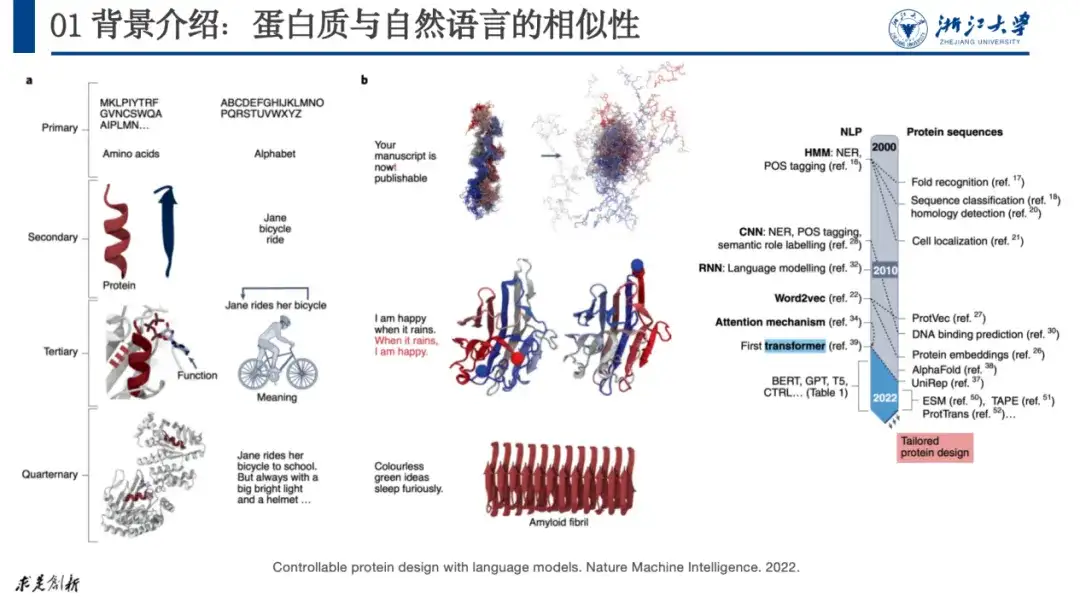
الموضوع الذي نناقشه هذه المرة هو تحسين الذكاء الاصطناعي + البروتين، أي إذا كان لدينا بروتين لا يعمل كما هو متوقع، فكيف يمكننا تعديل تسلسل الأحماض الأمينية الخاص به لتلبية الوظيفة المتوقعة.
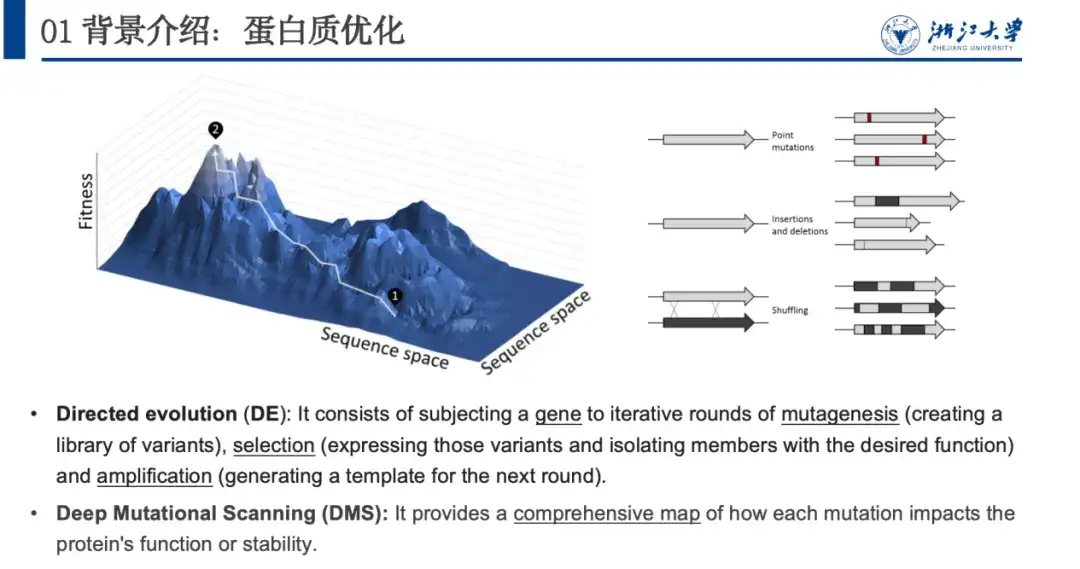
في الطبيعة، تعمل البروتينات على تحسين نفسها بشكل مستمر من خلال تغييرات عشوائية، بما في ذلك إدخالات النقاط، أو الحذف، أو الطفرات النقطية. ومن خلال تقليد هذه العملية، اقترح علماء الأحياء التطور الموجه والمسح الطفري العميق لتحسين البروتينات. المشكلة مع هاتين الطريقتين هي أنهما تستهلكان الكثير من الموارد التجريبية. لذلك،نحن نستخدم الأساليب الحسابية لنمذجة العلاقة بين البروتينات وملاءمة خصائصها، أي التنبؤ بمشهد اللياقة البدنية، وهو أمر بالغ الأهمية لتحسين البروتين.
من أجل نمذجة هذه المشكلة، نستخدم عادةً مجموعات البيانات ومقاييس التقييم وطرق الحساب.كما هو موضح في الشكل أدناه، تحتوي مجموعة بيانات تحسين البروتين عادةً على تسلسل من النوع البري xwt، وأزواج طفرات متعددة μi، وقيمة اللياقة البدنية المتوقعة yi بعد الطفرة. تعتمد نماذج التقييم بشكل أساسي على معامل ارتباط سبيرمان. لا يركز هذا المؤشر على القيمة المتوقعة المحددة، بل على ترتيب تغييرات قيمة اللياقة البدنية الناجمة عن الطفرات. كلما اقتربت قيمة ترتيب الطفرة الفعلية R(Y) من درجة اللياقة البدنية المتوقعة، كان تدريب النموذج أفضل.
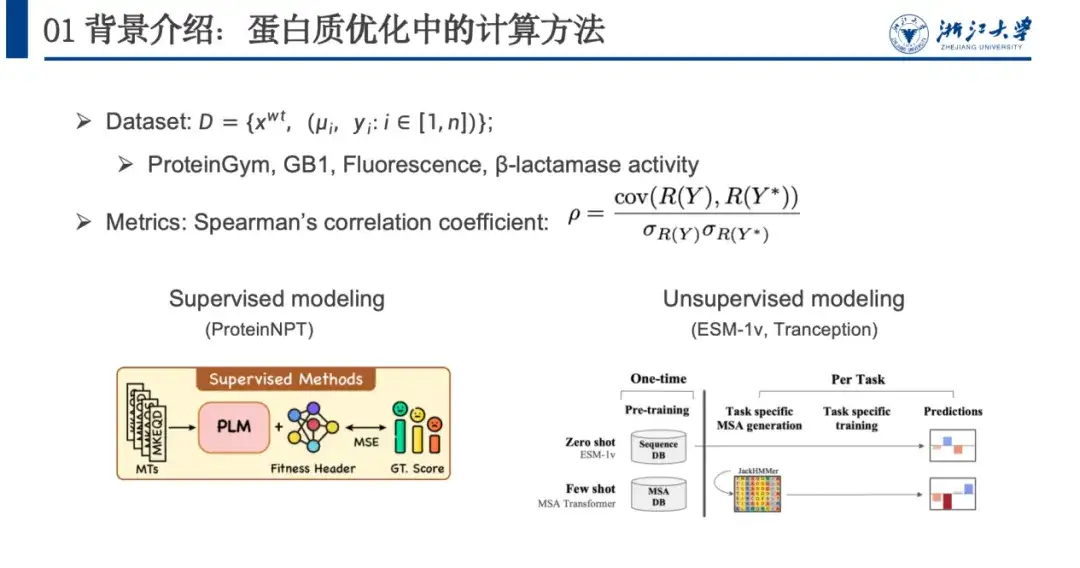
يمكن تقسيم الأساليب الحسابية تقريبًا إلى نمذجة خاضعة للإشراف ونمذجة غير خاضعة للإشراف. يعتمد التعلم الخاضع للإشراف على البيانات المصنفة ويقوم بتدريب النموذج من خلال تحسين دالة الخسارة لتحسين القدرة التنبؤية لللياقة البدنية. لا يتطلب التعلم غير الخاضع للإشراف بيانات مُسمّاة، بل يقوم بدلاً من ذلك بالتعلم الذاتي الإشراف على مجموعة بيانات بروتينية واسعة النطاق لا علاقة لها باللياقة البدنية. يحتاج النموذج إلى التدريب مرة واحدة فقط ويمكن تعميمه على مهام التنبؤ بالبروتين المختلفة.
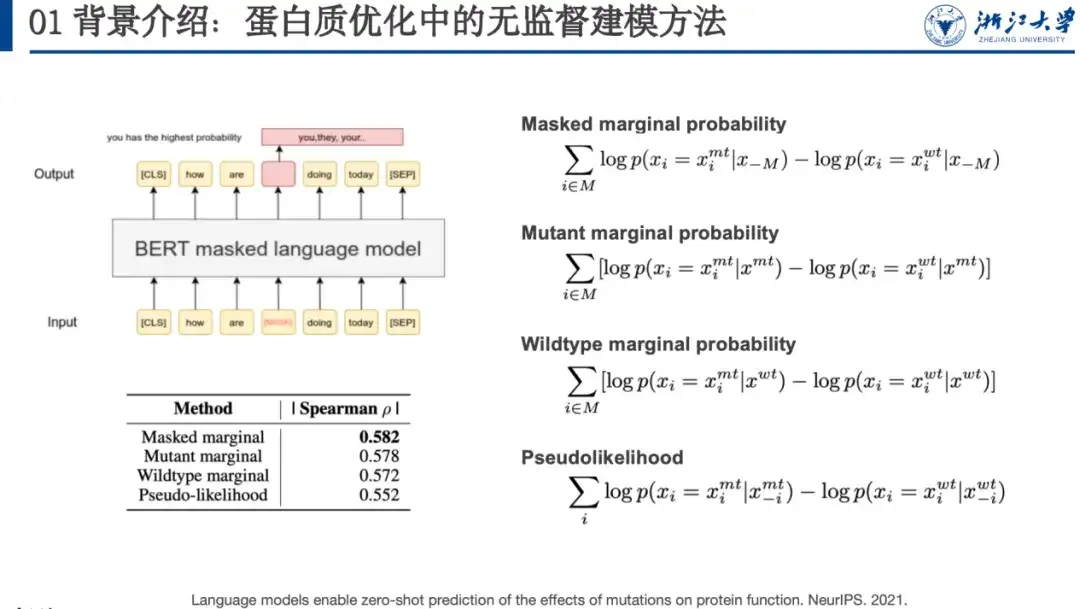
على سبيل المثال، نمذجة اللغة المقنعة هي طريقة تعلم غير خاضعة للإشراف. عند تدريب النموذج، نحتاج إلى تزويد النموذج بتسلسل ملوث. يمكننا إخفاء كلمة (مثل الكلمة الموجودة في المربع الأحمر في الشكل أدناه) أو تغييرها عشوائيًا إلى كلمة أخرى والسماح لنموذج اللغة باستعادتها، أي استعادة التسلسل الأصلي. وفي ورقة بحثية في مؤتمر NeurIPS 2021، وجد الباحثون أن احتمال حدوث طفرة بروتينية تتنبأ بها مثل هذه النماذج يرتبط بمشهد اللياقة البدنية. ولتحقيق هذه الغاية، قاموا بتصميم أربع صيغ لتسجيل الطفرات، كما هو موضح على الجانب الأيمن من الشكل أدناه.
الورق الأصلي:
https://proceedings.neurips.cc/paper/2021/file/f51338d736f95dd42427296047067694-Paper.pdf
باختصار، تعمل الطرق الخاضعة للإشراف بشكل جيد ولكنها تتمتع بقدرات تعميم محدودة، في حين تعمل الطرق غير الخاضعة للإشراف بشكل أسوأ قليلاً ولكنها تتمتع بقدرات تعميم قوية.من أجل الجمع بين مزايا كل منهما، كما هو موضح في الشكل أدناه، استعرنا استراتيجية التدريب المسبق + الضبط الدقيق من مجال معالجة اللغة الطبيعية. بعد بعض المحاولات، وجدنا أنه على الرغم من أن هذه الطريقة تعمل بشكل جيد، إلا أن قدرتها على التعميم كانت ضعيفة، على غرار التعلم الخاضع للإشراف. لقد قمنا بعد ذلك بتحليل سبب امتلاك الأساليب غير الخاضعة للإشراف لقدرات تعميم ممتازة وافترضنا أن هذه القدرة على التعميم تأتي من المعلومات التطورية (EI). ويرجع ذلك إلى أن الكائنات الحية قادرة على تحسين البروتينات من خلال التطور الطبيعي، كما أن مثل هذه الطفرات التطورية سوف تظل موجودة أيضًا. لذلك، فإننا نعتبر أن الارتباط بين احتمالية الطفرة ومناظر اللياقة البدنية مرتبط بشكل إيجابي.

ومع ذلك، عندما نحاول ضبط النموذج، فإننا في الواقع نستخدم المعلومات المضمنة ولا نستغل المعلومات التطورية بشكل كامل. بالإضافة إلى ذلك، هناك تحيز للمعلومات غير ذات الصلة في البيانات التجريبية الرطبة. نحن نعتقد أن المعلومات التطورية تحتوي على معلومات شاملة في اتجاهات مختلفة، مثل الاستقرار والنشاط والتعبير والارتباط وما إلى ذلك. عندما نقوم بتحسين استقرار البروتينات، فإن تطور النشاط والتعبير والارتباط يصبح معلومات غير ذات صلة. إذا أمكن إزالة قيمة احتمالية هذه المعلومات غير المثيرة للاهتمام، فمن الممكن تحسين أداء النموذج. نظرًا لأن العملية برمتها تتم في فضاء الاحتمالية، فلن يؤثر ذلك على قدرة النموذج على التعميم.لذلك، نحن بحاجة إلى تعظيم استخدام المعلومات التطورية أثناء الضبط الدقيق مع تقليل إشارة التحيز التي يتم إدخالها إلى مجموعة البيانات.
إطار عمل خوارزمية DePLM: نموذج إزالة الضوضاء استنادًا إلى مساحة الفرز
وبناءً على ذلك، اقترحنا نموذج DePLM، الذي تتلخص فكرته الأساسية في اعتبار المعلومات التطورية التي يلتقطها نموذج لغة البروتين بمثابة اندماج للإشارات المثيرة للاهتمام وغير المثيرة للاهتمام. ويعتبر الأخير بمثابة "ضوضاء" في مهمة تحسين السمات المستهدفة ويجب التخلص منها. تعمل DePLM على إزالة الضوضاء من المعلومات التطورية من خلال إجراء عملية انتشار في مساحة ترتيب قيم السمات، وبالتالي تعزيز قدرة النموذج على التعميم والتنبؤ بتأثيرات الطفرة.
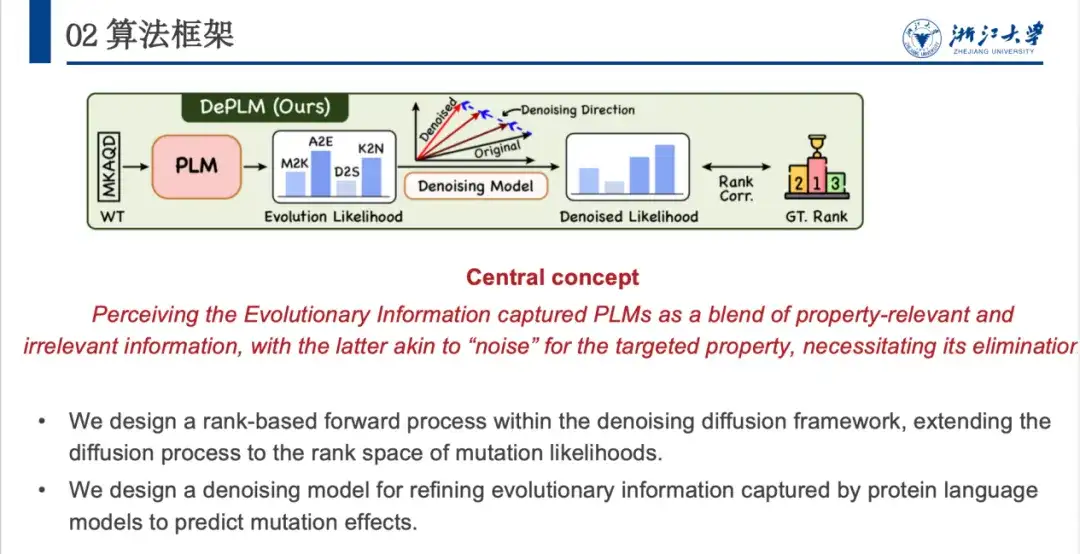
بالنظر إلى تسلسل الأحماض الأمينية في البروتين، يتنبأ النموذج باحتمالية تحور كل موضع إلى أحماض أمينية مختلفة، ثم يقوم الاحتمال التطوري بعد ذلك بتوليد احتمالية الخاصية المطلوبة من خلال وحدة إزالة النويدات. خاصة،يتكون DePLM بشكل أساسي من جزأين: عملية الانتشار الأمامي وعملية إزالة الضوضاء الخلفية المكتسبة.في العملية الأمامية، يتم إضافة كمية صغيرة من الضوضاء تدريجيًا إلى الوضع الحقيقي، وفي عملية إزالة الضوضاء العكسية، يتم التعلم لإزالة الضوضاء المتراكمة تدريجيًا واستعادة الوضع الحقيقي.
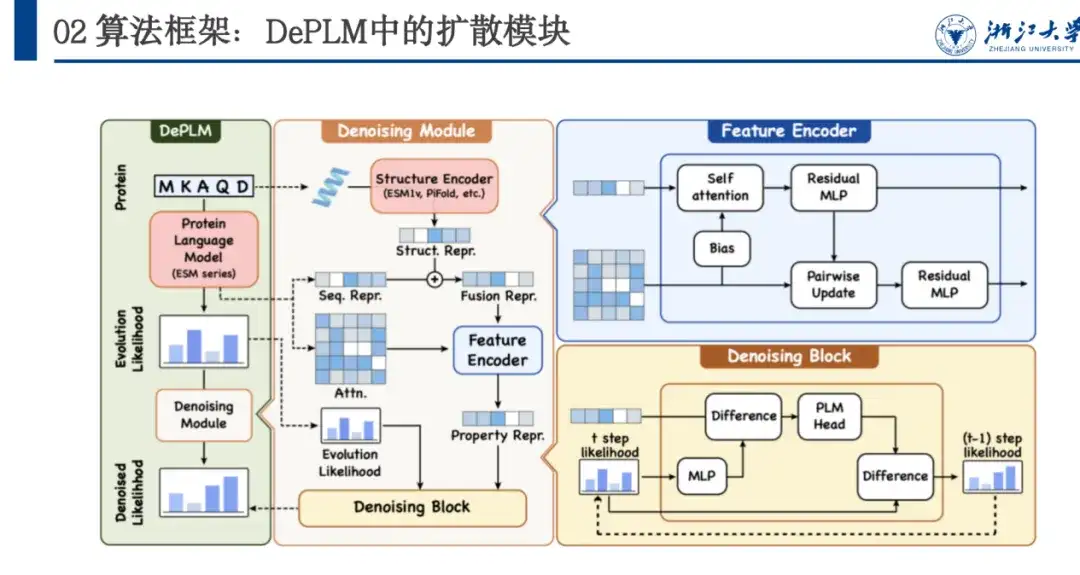
كما هو موضح في الشكل أدناه، يعتمد DePLM على سلسلة ESM ويتبنى بنية المحول. تعتمد وحدة إزالة الضوضاء على تدريب عملية الانتشار، وتشتمل بنية الشبكة على Feature Encoder وDenosing Block. يقوم Feature Encoder باستخراج ميزات التسلسل من نموذج لغة البروتين واستخراج الميزات الهيكلية من خلال نموذج ESM 1v. يتم استخدام هاتين الميزتين كنقطتي تثبيت، ويتم استخدام جولات متعددة من تكرارات كتلة إزالة الضوضاء لإزالة الضوضاء تدريجيًا والحصول على احتمالية إزالة الضوضاء.
في الماضي، كانت طرق إزالة الضوضاء تستخدم في الغالب في مجال توليد الصور، وخاصة في نماذج الانتشار. كما هو موضح في الشكل أدناه، يتم تحويل الصورة الأصلية x0 إلى مساحة ضوضاء (xT) قريبة من التوزيع الغاوسي من خلال عملية إزالة الضوضاء المحددة، ثم يتعلم النموذج عملية إزالة الضوضاء العكسية.
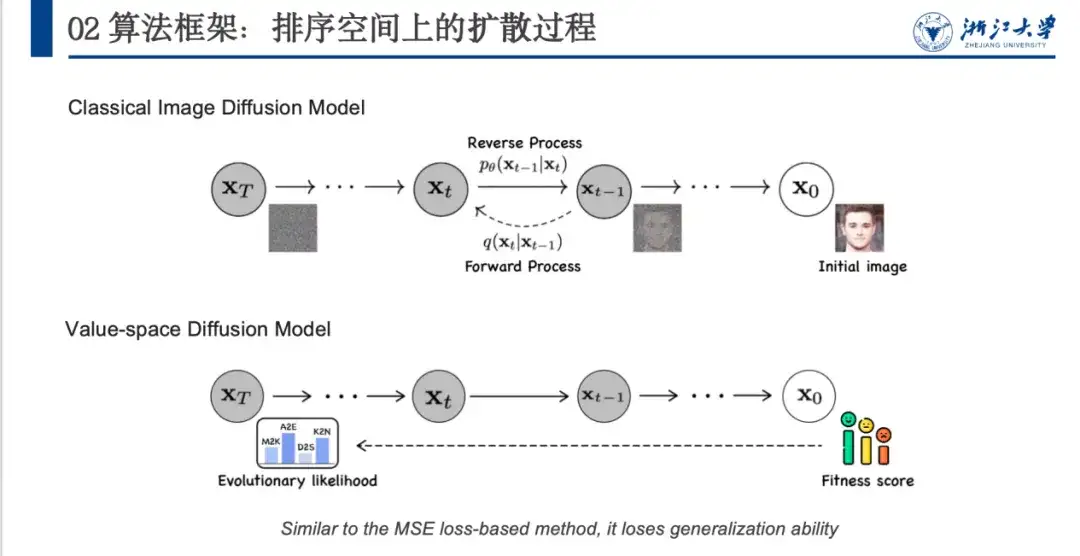
ومع ذلك، هناك بعض المشاكل في تطبيق نماذج إزالة الضوضاء من الصور بشكل مباشر على مجال البروتين. كما هو موضح في الشكل أعلاه، يمكن لنموذج إزالة الضوضاء من الصورة إضافة ضوضاء عشوائية لتشكيل مساحة ضوضاء غير قابلة للفصل (من x0 إلى xT). ومع ذلك، فإن البروتينات لها درجة لياقة واحتمالية تطورية، والحالات الأولية والنهائية ثابتة. لذلك، يجب أن يتم تصميم عملية إضافة الضوضاء بعناية. ثانياً، سوف يتوافق النموذج مع درجة اللياقة البدنية، مما يؤدي إلى أداء جيد ولكن قدرة تعميم ضعيفة.
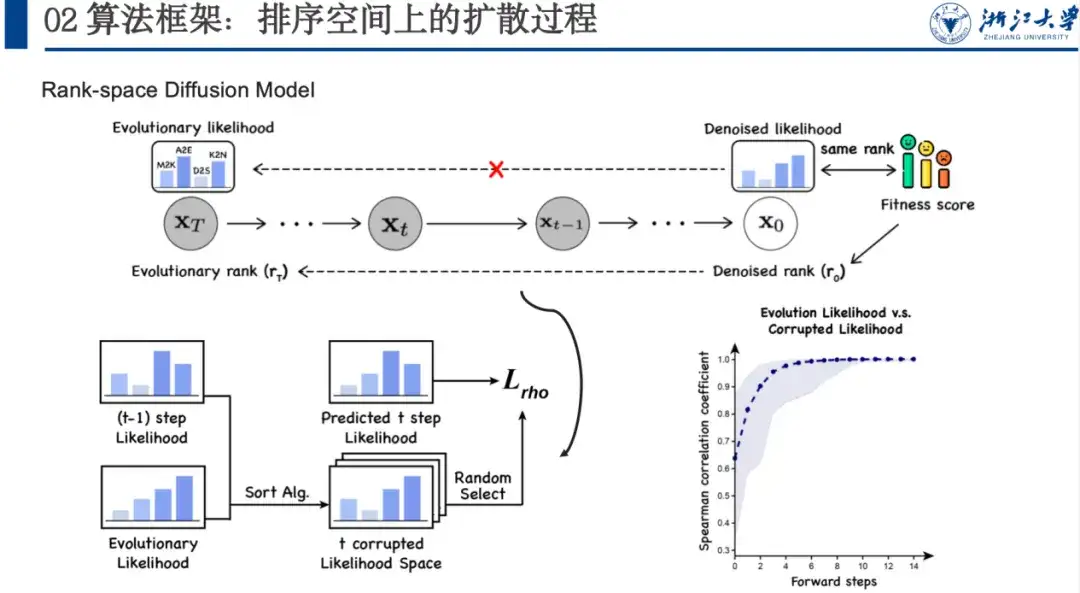
لذلك نقترح نموذجًا لإزالة الضوضاء يعتمد على مساحة الترتيب، مع التركيز على تعظيم أهمية الترتيب.وذلك لأننا نريد إزالة الضوضاء من الاحتمالية التطورية لمساحة الملكية محل الاهتمام. رغم أننا لا نعرف الوضع المحدد لهذه المساحة، إلا أننا نعلم أن تصنيفها يتوافق مع تصنيف اللياقة البدنية.
نضيف الضوضاء إلى هذه المساحة ونترك النموذج يتعلم عددًا كبيرًا من مجموعات البيانات، ويتعلم تدريجيًا كيف يجب أن يبدو الاحتمال المنقوص، بدلاً من محاذاة درجة اللياقة البدنية بشكل مباشر. في هذه العملية الصاخبة الأمامية، نستخدم خوارزمية فرز لجعل كل خطوة من خطوات الفرز أقرب إلى الحالة النهائية وتحتوي على العشوائية. وسوف يتعلم النموذج أيضًا فكرة الفرز العكسي خطوة بخطوة. على وجه التحديد، كما هو موضح في الشكل أدناه، إذا كان لدينا xt-1، فيمكننا تغذية xt-1 وxT إلى خوارزمية الفرز والسماح لها بالفرز عدة مرات. بعد الحصول على مساحة الفرز للخطوة t، يمكننا أخذ عينات عشوائية من متغيرات الفرز للخطوة t منها، والسماح للنموذج بالتنبؤ باحتمالية الخطوة t+1 إلى الخطوة t، وحساب خسارة سبيرمان. نظرًا لأننا لا نحتاج إلى إضافة العديد من الخطوات مثل إزالة الضوضاء من الصورة، فيمكن عادةً إكمال عملية الفرز في 5 إلى 6 خطوات، مما يحسن الكفاءة أيضًا.
الاستنتاج التجريبي: يتمتع DePLM بأداء متفوق وقدرة قوية على التعميم
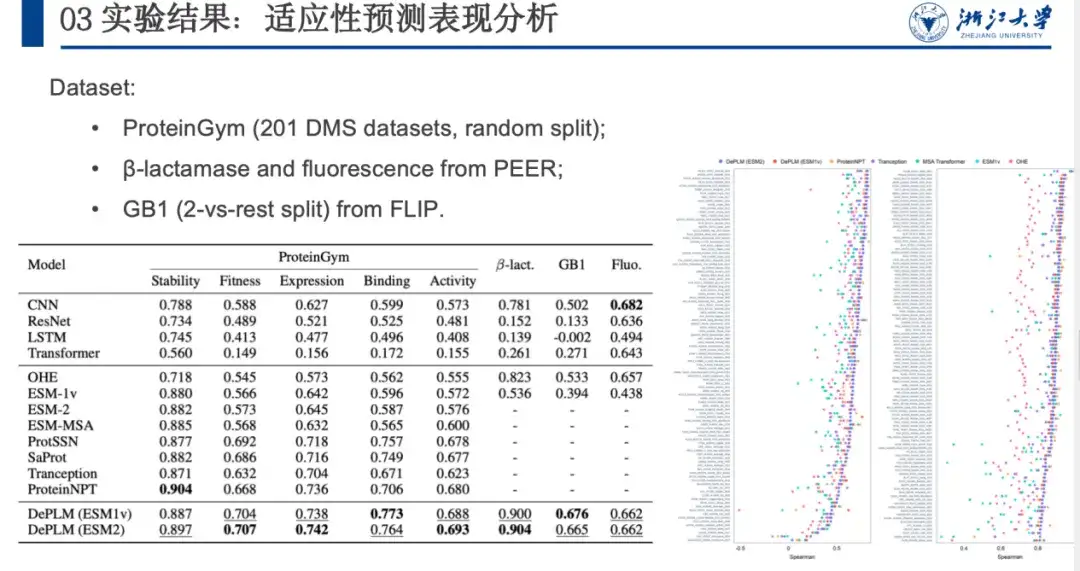
لتقييم أداء DePLM في مهام هندسة البروتين، قمنا بمقارنته بمشفرات تسلسل البروتين المدربة من الصفر، والنماذج ذاتية الإشراف، وما إلى ذلك على مجموعات البيانات ProteinGym، وβ-lactamase، وGB1، وFluorescence. وتظهر النتائج في الشكل أدناه. يتفوق DePLM على النموذج الأساسي.وجدنا أن المعلومات التطورية عالية الجودة يمكن أن تعمل على تحسين نتائج الضبط الدقيق بشكل كبير، مما يوضح فعالية إجراء التدريب على إزالة الضوضاء الذي اقترحناه ويؤكد ميزة دمج المعلومات التطورية مع البيانات التجريبية في مهام هندسة البروتين.
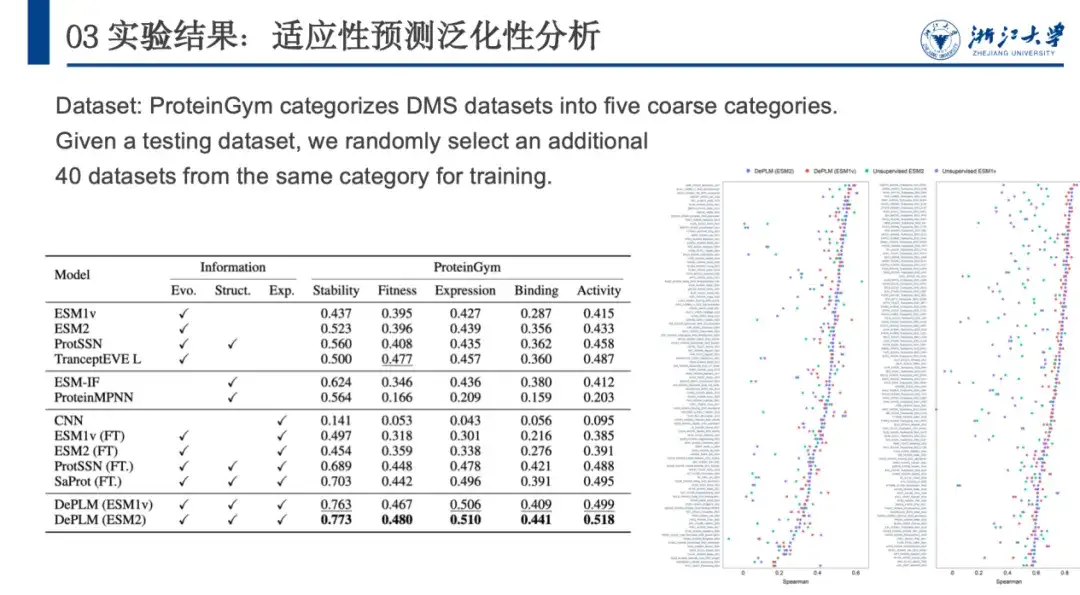
بعد ذلك، لتقييم قدرة DePLM على التعميم بشكل أكبر، قامت ProteinGym بتصنيف مجموعة بيانات DMS إلى خمس فئات وفقًا لخصائص البروتين التي قاموا بقياسها، وهي الاستقرار واللياقة البدنية والتعبير والارتباط والنشاط. نقوم بمقارنتها مع نماذج أخرى ذاتية الإشراف، ونماذج تعتمد على البنية، ونماذج أساسية خاضعة للإشراف. وتظهر النتائج في الشكل أدناه. يتفوق DePLM على جميع النماذج الأساسية.يوضح هذا أن النماذج التي تعتمد فقط على المعلومات التطورية غير المفلترة غير كافية، لأنها غالبًا ما تعمل على تخفيف سمات الهدف بسبب تحسين أهداف متعددة في وقت واحد. من خلال القضاء على تأثير العوامل غير ذات الصلة، يعمل DePLM على تحسين الأداء بشكل كبير.
لمزيد من تحليل أداء التعميم وتحديد أهمية تصفية المعلومات غير ذات الصلة بالسمات، قمنا بإجراء التحقق المتبادل للتدريب والاختبار بين السمات. كما هو موضح في الشكل أدناه، في معظم الحالات، عندما يتم تدريب النموذج على السمة A واختباره على السمة B، يكون أداءه أقل مما هو عليه عندما يتم تدريبه واختباره على نفس السمة (أي A).وهذا يوضح أن اتجاهات التحسين للخصائص المختلفة ليست متسقة وأن هناك تداخل متبادل، مما يؤكد فرضيتنا الأولية.
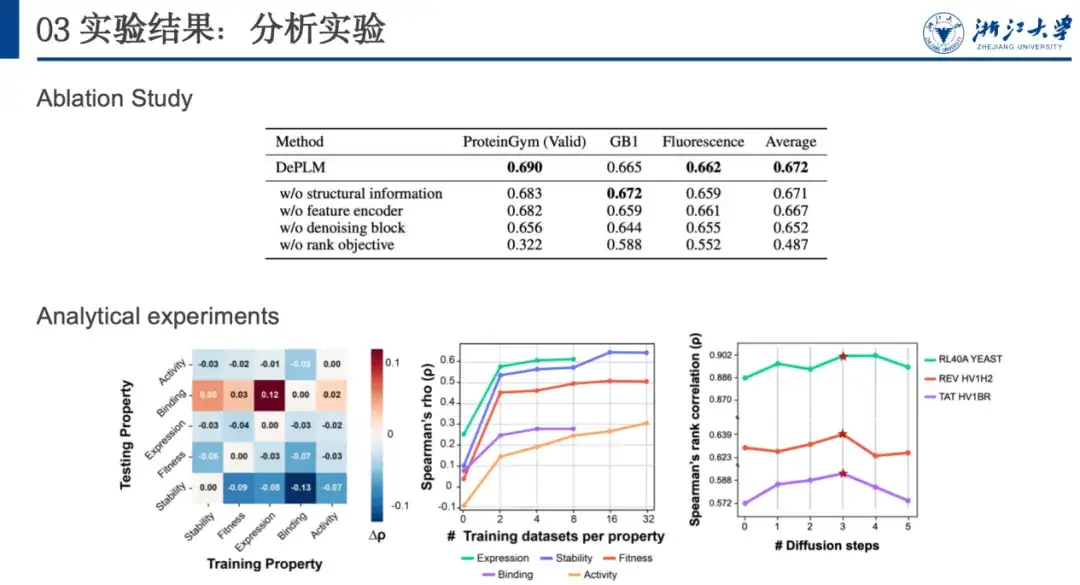
بالإضافة إلى ذلك، وجدنا أن أداء النموذج قد تحسن من خلال التدريب على مجموعات البيانات الخاصة بالخصائص الأخرى والاختبار على مجموعة البيانات الملزمة. قد يعزى ذلك إلى حجم البيانات المحدود وانخفاض جودة البيانات لمجموعة البيانات الملزمة، مما يؤدي إلى عدم قدرتها الكافية على التعميم. هذا يلهمناعند تحسين البروتينات بخصائص جديدة، إذا كان هناك عدد أقل من مجموعات البيانات المتعلقة بهذه الخاصية، فيمكن للمرء أن يفكر في استخدام البيانات ذات الخصائص ذات الصلة لإزالة الضوضاء والتدريب للحصول على قدرات تعميم أفضل.
مواصلة تعميق مجال البروتين
ضيف هذا البث المباشر هو وانغ زيوان، طالب دكتوراه في مختبر محرك المعرفة بجامعة تشجيانغ. يلتزم فريقه، بقيادة البروفيسور تشين هواجون والباحث تشانغ تشيانغ وآخرين، بالبحث الأكاديمي في مجالات الرسوم البيانية المعرفية ونماذج اللغة الكبيرة والذكاء الاصطناعي للعلوم وما إلى ذلك، ونشر العديد من الأوراق في مؤتمرات الذكاء الاصطناعي الكبرى مثل NeurIPS و ICML و ICLR و AAAI و IJCAI.
الصفحة الشخصية لـ Zhang Qiang:
https://person.zju.edu.cn/H124023
وفي مجال البروتينات، لم يقترح الفريق نماذج متقدمة مثل DePLM لتحسين البروتينات فحسب، بل عمل أيضًا على سد الفجوة بين التسلسلات البيولوجية واللغة البشرية.ولتحقيق هذه الغاية، اقترحوا نموذج InstructProtein.استخدام تعليمات المعرفة لمواءمة لغة البروتين واللغة البشرية، واستكشاف قدرات التوليد ثنائية الاتجاه بين لغة البروتين واللغة البشرية، ودمج التسلسلات البيولوجية في نماذج لغوية كبيرة، وجسر الفجوة بين اللغتين بشكل فعال. تثبت التجارب التي أجريت على عدد كبير من مهام توليد النصوص البروتينية ثنائية الاتجاه أن برنامج InstructProtein يتفوق على برامج LLM الحديثة الموجودة.
انقر لرؤية المزيد من التفاصيل: تم اختياره للمؤتمر الرئيسي ACL2024 | InstructProtein: مواءمة لغة البروتين مع اللغة البشرية باستخدام تعليمات المعرفة
بالإضافة إلى ذلك، اقترح الفريق أيضًا طريقة تصميم تسلسل البروتين متعدد الأغراض PROPEND استنادًا إلى إطار "التدريب المسبق والتحفيز".من خلال التوجيهات إلى الهياكل العظمية والمخططات وعلامات الوظائف ومجموعاتها، يمكن التحكم مباشرة في مجموعة متنوعة من الخصائص، وتتمتع هذه الطريقة بنطاق واسع من التطبيق العملي والدقة. ومن بين التسلسلات الخمسة التي تم اختبارها في التجارب المختبرية، وصل معدل الاسترداد الوظيفي الأقصى لـ PROPEND إلى 105.2%، متجاوزًا بشكل كبير معدل 50.8% لخط الأنابيب ذي التصميم الكلاسيكي.
الورق الأصلي:
https://www.biorxiv.org/content/10.1101/2024.11.17.624051v1
في الوقت الحاضر، تم إتاحة العديد من النتائج التي أصدرها الفريق مفتوحة المصدر. ويقومون أيضًا بتجنيد زملاء ما بعد الدكتوراه المتميزين، و100 شخص، ومهندسي البحث والتطوير، وغيرهم من الباحثين بدوام كامل على المدى الطويل. الجميع مدعوون للانضمام~
الصفحة الرئيسية للمختبر على Github:
http://github.com/zjunlp









