Command Palette
Search for a command to run...
أول وثيقة vLLM باللغة الصينية متاحة على الإنترنت! يعمل الإصدار الأحدث على زيادة الإنتاجية بمقدار 2.7 مرة وتقليل زمن الوصول بمقدار 5 مرات، مما يجعل استنتاج نماذج اللغة الكبيرة أسرع!

اليوم، يتوسع تطوير نماذج اللغة الكبيرة (LLMs) من الترقيات التكرارية لمعلمات المقياس إلى التكيف والابتكار في سيناريوهات التطبيق. وفي هذه العملية، يتم الكشف أيضًا عن سلسلة من المشاكل. على سبيل المثال، تكون كفاءة رابط التفكير منخفضة، ويستغرق معالجة المهام المعقدة وقتًا طويلاً، مما يجعل من الصعب تلبية احتياجات السيناريوهات ذات المتطلبات العالية في الوقت الفعلي. من حيث استخدام الموارد، وبسبب الحجم الكبير للنموذج، فإن استهلاك موارد الحوسبة والتخزين ضخم، وهناك درجة معينة من الهدر.
وفي ضوء ذلك،نجح فريق بحثي من جامعة كاليفورنيا، بيركلي (UC Berkeley) في إطلاق نموذج اللغة الافتراضي الكبير (vLLM) مفتوح المصدر في عام 2023.هذا هو الإطار الذي تم تصميمه خصيصا لتسريع عملية التفكير في نماذج اللغة الكبيرة. وقد حظيت باهتمام واسع النطاق في جميع أنحاء العالم لكفاءتها الممتازة في التفكير وقدراتها على تحسين الموارد.
من أجل مساعدة المطورين المحليين على التعرف بسهولة أكبر على تحديثات إصدار vLLM والتطورات المتطورة،أطلقت HyperAI Super Neural Network الآن أول وثيقة vLLM باللغة الصينية.من المعرفة التقنية إلى البرامج التعليمية العملية، ومن الاتجاهات المتطورة إلى التحديثات الرئيسية، يمكن للمبتدئين والخبراء ذوي الخبرة على حد سواء العثور على المحتوى الأساسي الذي يحتاجون إليه.
وثائق vLLM الصينية:
تتبع vLLM: تاريخ المصادر المفتوحة وتطور التكنولوجيا
وُلد النموذج الأولي لـ vLLM في نهاية عام 2022. عندما نشر فريق بحثي في جامعة كاليفورنيا، بيركلي، مشروعًا آليًا للاستدلال المتوازي يُسمى "alpa"، وجدوا أنه يعمل ببطء شديد ويستخدم وحدة معالجة الرسومات بشكل منخفض. يدرك الباحثون تمامًا أن هناك مجالًا كبيرًا للتحسين في التفكير في نماذج اللغة الكبيرة. ومع ذلك، لم يكن هناك نظام مفتوح المصدر في السوق تم تحسينه لاستنتاج نموذج اللغة الكبير، لذلك قرروا إنشاء إطار عمل لاستنتاج نموذج اللغة الكبير بأنفسهم.
بعد عدد لا يحصى من التجارب وعمليات التصحيح، اهتموا بالذاكرة الافتراضية وتقنية التجزئة في نظام التشغيل، وبناءً على ذلك، اقترحوا خوارزمية الاهتمام الرائدة PagedAttention في عام 2023، والتي يمكنها إدارة مفاتيح وقيم الاهتمام بشكل فعال. وعلى هذا الأساس، قام الباحثون ببناء محرك خدمة LLM عالي الإنتاجية vLLM، والذي حقق هدرًا شبه معدوم لذاكرة التخزين المؤقت KV.تم حل مشكلة عنق الزجاجة في إدارة الذاكرة في التفكير في نموذج اللغة الكبير.وبالمقارنة مع محولات Hugging Face Transformers، فإنها تحقق إنتاجية أعلى بمقدار 24 مرة، ولا يتطلب هذا التحسين في الأداء أي تغييرات في بنية النموذج.
والأمر الأكثر جدير بالذكر هو أن vLLM لا يقتصر على الأجهزة. لا يقتصر الأمر على وحدة معالجة الرسوميات Nvidia فحسب، بل يفتح ذراعيه أيضًا للعديد من بنيات الأجهزة الموجودة في السوق، مثل وحدة معالجة الرسوميات AMD ووحدة معالجة الرسوميات Intel وAWS Neuron وGoogle TPU، مما يعزز حقًا التفكير الفعال وتطبيق نماذج اللغة الكبيرة في بيئات الأجهزة المختلفة. اليوم، أصبح برنامج vLLM قادرًا على دعم أكثر من 40 بنية نموذجية وحصل على الدعم والرعاية من أكثر من 20 شركة بما في ذلك Anyscale وAMD وNVIDIA وGoogle Cloud.
في يونيو 2023، تم إصدار الكود مفتوح المصدر لـ vLLM رسميًا. في عام واحد فقط، تجاوز عدد نجوم vLLM على Github 21.8 ألفًا.حتى الآن، وصل عدد نجوم المشروع إلى 31 ألف نجمة.
في سبتمبر من نفس العام، نشر فريق البحث ورقة بحثية بعنوان "إدارة الذاكرة الفعالة لخدمة نموذج اللغة الكبير باستخدام PagedAttention"، والتي توضح التفاصيل الفنية ومزايا vLLM بشكل أكبر. ولم يتوقف الفريق عن أبحاثه على vLLM ولا يزال يقوم بإجراء ترقيات متكررة في مجالات مثل التوافق وسهولة الاستخدام. على سبيل المثال، من حيث تكيف الأجهزة، بالإضافة إلى وحدة معالجة الرسوميات Nvidia، كيف يمكن لـ vLLM أن يعمل على المزيد من الأجهزة؟ على سبيل المثال، في البحث العلمي، كيفية تحسين كفاءة النظام وسرعة الاستدلال بشكل أكبر. تنعكس هذه أيضًا في تحديثات إصدار vLLM.
عنوان الورقة:
https://dl.acm.org/doi/10.1145/3600006.3613165
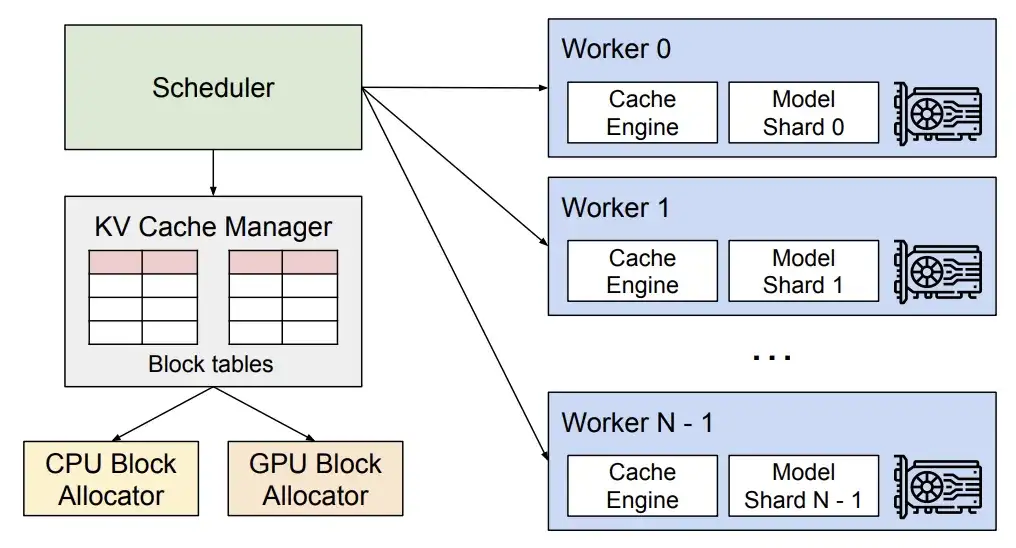
تحديث vLLM v0.6.4
إنتاجية أعلى بمقدار 2.7 مرة وزمن وصول أقل بمقدار 5 مرات
في الشهر الماضي فقط، تم تحديث vLLM إلى الإصدار 0.6.4، والذي حقق تقدماً مهماً في تحسين الأداء ودعم النموذج والمعالجة متعددة الوسائط.
من حيث الأداء، يقدم الإصدار الجديد جدولة متعددة الخطوات ومعالجة إخراج غير متزامنة.تم تحسين استخدام وحدة معالجة الرسوميات وزيادة كفاءة المعالجة، وبالتالي تحسين الإنتاجية الإجمالية.
التحليل الفني vLLM
* يسمح الجدول متعدد الخطوات لـ vLLM بإكمال الجدولة وإعداد الإدخال لخطوات متعددة في وقت واحد، بحيث يمكن لوحدة معالجة الرسومات معالجة خطوات متعددة بشكل مستمر دون الحاجة إلى انتظار تعليمات وحدة المعالجة المركزية لكل خطوة، وبالتالي توزيع عبء عمل وحدة المعالجة المركزية وتقليل وقت الخمول لوحدة معالجة الرسومات.
* تسمح معالجة الإخراج غير المتزامنة بإجراء معالجة الإخراج بالتوازي مع تنفيذ النموذج. على وجه التحديد، لم يعد vLLM يعالج الإخراج على الفور، بل يؤخر المعالجة بدلاً من ذلك، ويعالج إخراج الخطوة n أثناء تنفيذ الخطوة n+1. ورغم أن هذا قد يؤدي إلى خطوة إضافية واحدة لكل طلب، فإن التحسن الكبير في استخدام وحدة معالجة الرسوميات يعوض عن هذه التكلفة.
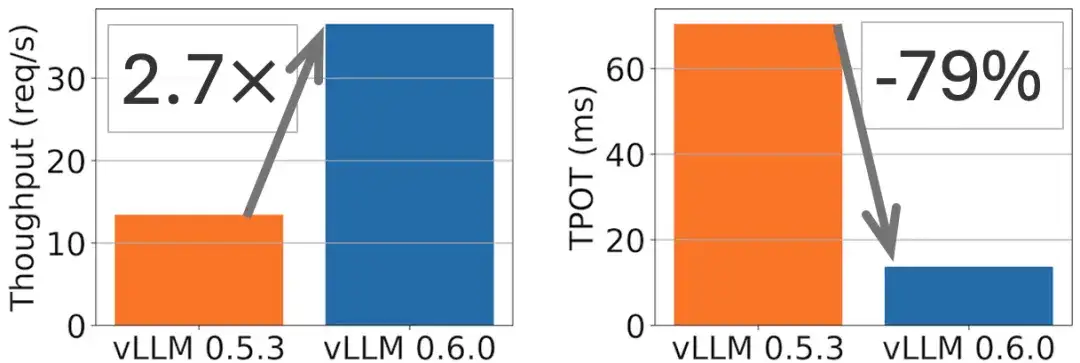
على سبيل المثال، يمكن تحقيق تحسين في الإنتاجية بمقدار 2.7x وخفض في وقت إخراج الرمز (TPOT) بمقدار 5x على طراز Llama 8B، كما هو موضح في الشكل التالي.
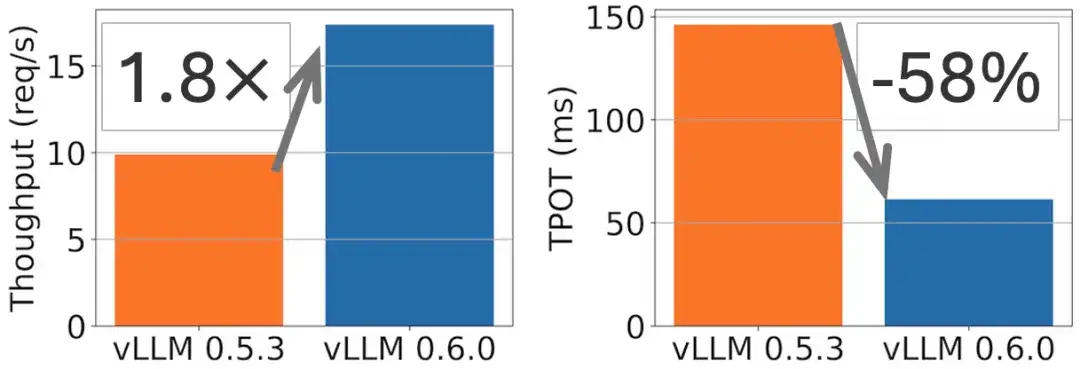
في طراز Llama 70B، تم تحقيق تحسن في الإنتاجية بمقدار 1.8 ضعفًا وخفض TPOT بمقدار 2 ضعفًا، كما هو موضح في الشكل التالي.
من حيث دعم النموذج، قام vLLM مؤخرًا بتضمين تعديلات لنماذج اللغة الكبيرة المتطورة مثل Exaone وGranite وPhi-3.5-MoE. في المجال المتعدد الوسائط، تمت إضافة وظيفة إدخال الصور المتعددة (يتم استخدام نموذج Phi-3-vision كمثال في الوثائق الرسمية)، بالإضافة إلى القدرة على معالجة كتل صوتية متعددة من Ultravox، مما يؤدي إلى توسيع نطاق تطبيق vLLM في المهام المتعددة الوسائط.
النسخة الكاملة الأولى من وثائق vLLM الصينية متاحة على الإنترنت
ليس هناك شك في أن vLLM، باعتباره ابتكارًا تكنولوجيًا مهمًا في مجال النماذج الكبيرة، يمثل اتجاه التطوير الحالي للتفكير الفعال. من أجل تمكين المطورين المحليين من فهم المبادئ التقنية المتقدمة وراءها بشكل أكثر ملاءمة ودقة، سيتم إدخال vLLM في تطوير النماذج الكبيرة المحلية، وبالتالي تعزيز تطوير هذا المجال. نجح متطوعو مجتمع HyperAI في إكمال أول وثيقة vLLM باللغة الصينية من خلال التعاون المفتوح والمراجعة المزدوجة للترجمة والمراجعة.تم إطلاقه الآن بالكامل على hyper.ai.
وثائق vLLM الصينية:
توفر لك هذه الوثيقة:
* المفاهيم الأساسية من الصفر
* دليل سريع لبدء الاستنساخ بنقرة واحدة
* قاعدة المعرفة vLLM المحدثة في الوقت المناسب
* بيئة مجتمعية صينية ودية ومنفتحة
بناء جسور مفتوحة المصدر:
رحلة بناء مجتمع TVM وTriton وvLLM معًا
في عام 2022، أطلقت HyperAI أول وثائق Apache TVM الصينية في الصين (تم إطلاق الموقع الرسمي لقناة TVM الصينية! "كتاب مرجعي" شامل لنشر نموذج التعلم الآلي موجود هنا)مع التطور السريع للرقائق المحلية، فإننا نوفر لمهندسي التجميع المحليين البنية الأساسية اللازمة لفهم وتعلم TVM.وفي الوقت نفسه، تعاونا أيضًا مع الدكتور Feng Siyuan من شركة Apache TVM PMC وآخرين لتشكيل مجتمع TVM الصيني الأكثر نشاطًا في الصين.من خلال الأنشطة عبر الإنترنت وخارجها، نجحنا في جذب مشاركة ودعم مصنعي الرقائق المحليين الرئيسيين، الذين يشملون أكثر من ألف مطور للرقائق ومهندس تجميع.

عنوان توثيق TVM باللغة الصينية:
في أكتوبر 2024، أطلقنا موقع Triton الصيني (أول وثيقة صينية كاملة باللغة تريتون متاحة على الإنترنت! افتتاح عصر جديد من تسريع استنتاجات وحدة معالجة الرسومات)، مما يؤدي إلى توسيع الحدود التقنية ونطاق المحتوى لمجتمع مُجمِّعي الذكاء الاصطناعي.
عنوان توثيق تريتون الصيني:
في رحلتنا لبناء مجتمع مُجمِّعي الذكاء الاصطناعي، كنا نستمع إلى صوت الجميع ونراقب اتجاهات الصناعة. إن إطلاق وثائق vLLM الصينية يأتي لأننا لاحظنا أنه مع التطور السريع للنماذج الكبيرة، يتزايد اهتمام الناس والطلب على استخدام vLLM. ونأمل أن نوفر منصة للتعلم والتواصل والتعاون بين المطورين، ونعمل بشكل مشترك على تعزيز نشر وتطوير التقنيات المتطورة في السياق الصيني.
يعد تحديث وصيانة مستندات TVM و Triton و vLLM الصينية العمل الأساسي بالنسبة لنا لبناء المجتمع الصيني. في المستقبل، نتطلع إلى انضمام المزيد من الشركاء إلينا لبناء مجتمع مفتوح المصدر للذكاء الاصطناعي أكثر انفتاحًا وتنوعًا وشاملاً!
عرض وثائق vLLM الصينية الكاملة:
على GitHub vLLM الصينية:
https://github.com/hyperai/vllm-cn
ستعقد شركة HyperAI هذا الشهر اجتماعًا للتبادل الفني غير المتصل بالإنترنت يسمى Meet AI Compiler في شنغهاي. يرجى مسح رمز الاستجابة السريعة والتعليق على "AI Compiler" للانضمام إلى مجموعة الحدث والحصول على معلومات ذات صلة بالحدث في أقرب وقت ممكن.

مراجع:
1.https://blog.vllm.ai/2024/09/05/perf-update.html








