Command Palette
Search for a command to run...
معاينة البث المباشر | اختراق جديد في تحسين البروتين! تم اختيار نتائج أبحاث جامعة تشجيانغ لـ NeurIPS 2024، وقد أوضح المؤلف الأول للورقة النقاط الفنية البارزة بالتفصيل

سيتم بث الحلقة الخامسة من سلسلة البث المباشر "Meet AI4S" في موعدها المحدد في الساعة 19:00 يوم 10 ديسمبر. يشرف HyperAI بدعوة وانغ زيوان، طالب الدكتوراه من مختبر محرك المعرفة بجامعة تشجيانغ. موضوع مشاركته هذه المرة هو "استخدام عملية إزالة الضوضاء الانتشارية لمساعدة النماذج الكبيرة على تحسين البروتينات".
اقترح البروفيسور تشين هواجون والباحث تشانغ تشيانغ والدكتور وانغ زيوان وآخرون من جامعة تشجيانغ نموذجًا جديدًا للغة البروتين مزيل الضوضاء (DePLM).يمكن النظر إلى المعلومات التطورية التي تم التقاطها بواسطة نموذج لغة البروتين على أنها مزيج من المعلومات ذات الصلة وغير ذات الصلة بالخاصية المستهدفة، حيث تعتبر المعلومات غير ذات الصلة "ضوضاء" ويتم التخلص منها، وبالتالي التنبؤ بالمناظر الطبيعية التكيفية للبروتين ومساعدة تحسين البروتين.
أظهرت الأبحاث أن DePLM يتفوق على الطرق الحالية في التنبؤ بتأثيرات طفرات البروتين ولديه قدرات تعميم قوية للبروتينات الجديدة. تم اختيار هذا الإنجاز لأفضل مؤتمر NeurIPS 2024.
في هذا البث المباشر، سوف يشرح الدكتور وانغ زيوان بالتفصيل الأفكار المبتكرة لهذه الورقة. كما قامت HyperAI بإعداد 10 ساعات من موارد NVIDIA RTX A6000 خصيصًا للجميع. سيحظى الجمهور الذي يشارك في السحب في غرفة البث المباشر بفرصة الحصول عليها مجانًا!
امسح رمز الاستجابة السريعة وأضف "AI4S" للانضمام إلى مجموعة المناقشة⬇️

مقدمة الضيف

شارك الموضوع
استخدام إزالة الضوضاء الانتشارية لمساعدة النماذج الكبيرة على تحسين البروتينات
مقدمة
اقترحت مجموعة البحث الخاصة بنا طريقة تجمع بين نموذج كبير ونموذج إزالة الضوضاء الانتشارية. من خلال الضبط الدقيق باستخدام كمية صغيرة من البيانات التجريبية الرطبة، يتم تحسين دقة النموذج الكبير في مهام التنبؤ بالمناظر الطبيعية التكيفية للبروتين مع الحفاظ على قدرة التعميم الجيدة للنموذج.
الفوائد للجمهور
1. فهم الأساليب ومجموعات البيانات والمؤشرات للتنبؤ بمشهد اللياقة البدنية للبروتين
2. فهم كيفية استخدام نموذج اللغة المعزز لنموذج الانتشار (DePLM) للتنبؤ بالمناظر الطبيعية التكيفية
3. استكشف كيفية الجمع بين المعلومات التطورية والتجارب الرطبة والبيانات الأخرى لتدريب نموذج الذكاء الاصطناعي
مراجعة الورقة
قامت شركة HyperAI في السابق بتفسير ورقة بحثية بعنوان "DePLM: إزالة الضوضاء من نماذج لغة البروتين لتحسين الخصائص" مع الدكتور وانج زيوان كمؤلف أول.
أبرز ما جاء في البحث
* يمكن لـ DePLM تصفية المعلومات غير ذات الصلة بخاصية الهدف بشكل فعال وتحسين تحسين البروتين من خلال تحسين المعلومات التطورية الموجودة في PLM
* لا يتفوق DePLM على النماذج الحديثة في التنبؤ بتأثيرات الطفرات فحسب، بل يُظهر أيضًا قدرات تعميم قوية للبروتينات الجديدة
* تصمم هذه الدراسة عملية تقدمية تعتمد على الفرز في إطار انتشار إزالة الضوضاء، وتوسيع عملية الانتشار إلى مساحة فرز إمكانيات الطفرة، مع تغيير هدف التعلم من تقليل الخطأ العددي إلى تعظيم أهمية الفرز، وتعزيز التعلم المستقل عن مجموعة البيانات وضمان قدرات التعميم القوية للنموذج.
اكتساب مجموعة البيانات
اختارت الدراسة مجموعة بيانات طفرة البروتين ProteinGym، وبعد استبعاد مجموعة بيانات البروتين البري الطويلة للغاية، احتفظت في النهاية بـ 201 مجموعة بيانات فحص الطفرات العميقة (DMS).
يتم استخدام مجموعة البيانات بشكل مباشر:
https://hyper.ai/datasets/32818
الهندسة المعمارية النموذجية
كما هو موضح في الشكل الموجود على اليسار أدناه، يستخدم DePLM احتمالية التطور المستمدة من PLM كمدخل ويولد احتمالية خالية من الضوضاء لسمة معينة للتنبؤ بتأثير الطفرات؛ في الأجزاء الوسطى واليمنى من الشكل أدناه، تستخدم وحدة إزالة الضوضاء مُشفِّر الميزات لإنشاء تمثيل للبروتين، مع مراعاة الهياكل الأولية والثالثية، والتي تُستخدم بعد ذلك لتصفية الضوضاء في الاحتمالية من خلال وحدة إزالة الضوضاء.
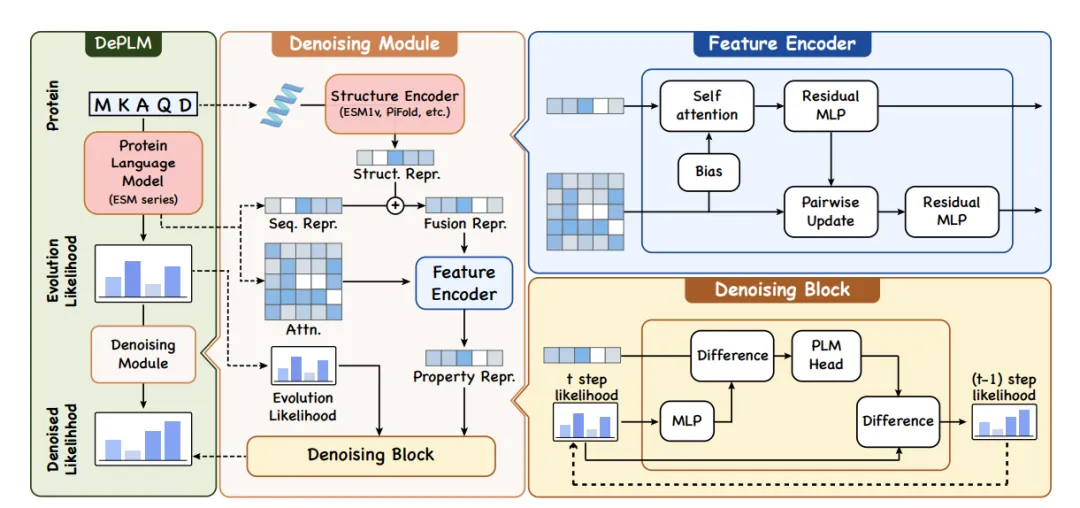
من أجل تحقيق التعلم المستقل عن مجموعة البيانات وضمان قدرة قوية على تعميم النموذج، أجرى الباحثون عملية انتشار في مساحة ترتيب قيم الميزات واستبدلوا الهدف التقليدي المتمثل في تقليل الخطأ العددي بتعظيم أهمية الترتيب.
مختبر محرك المعرفة بجامعة تشجيانغ
يقع مختبر محرك المعرفة على أساس كلية علوم الكمبيوتر والتكنولوجيا، وكلية البرمجيات، وما إلى ذلك في جامعة تشجيانغ.نحن ملتزمون بالبحث الأكاديمي والمصدر المفتوح والابتكار الصناعي والتطبيق في مجالات الرسوم البيانية المعرفية ونماذج اللغة الكبيرة والذكاء الاصطناعي للعلوم. تشمل المشاريع المشتركة مركز البحث والتطوير المشترك بين جامعة تشجيانغ ومجموعة Ant، ومختبر محرك المعرفة المشترك بين جامعة تشجيانغ ومجموعة Alibaba، وما إلى ذلك.
ويقوم الفريق بتجنيد زملاء ما بعد الدكتوراه المتميزين، والأشخاص الذين تبلغ أعمارهم 100 عام، ومهندسي البحث والتطوير، وغيرهم من الباحثين بدوام كامل. مرحبا بالجميع للانضمام~
الصفحة الرئيسية للمختبر على Github:
تعرف على سلسلة AI4S المباشرة
HyperAI (hyper.ai) هو محرك بحث أكبر في الصين في مجال علوم البيانات. يركز على أحدث نتائج الأبحاث العلمية المتعلقة بالذكاء الاصطناعي في العلوم ويتتبع الأوراق الأكاديمية في المجلات العلمية المرموقة مثل Nature وScience في الوقت الفعلي. حتى الآن، تم الانتهاء من تفسير ما يقرب من 200 ورقة بحثية حول الذكاء الاصطناعي للعلوم.
بالإضافة إلى ذلك، فإننا ندير أيضًا مشروع الذكاء الاصطناعي للعلوم مفتوح المصدر الوحيد في الصين، awesome-ai4s.
* عنوان المشروع:
https://github.com/hyperai/awesome-ai4s
من أجل تعزيز نشر AI4S بشكل أكبر، وتقليل حواجز نشر نتائج البحث العلمي للمؤسسات الأكاديمية، ومشاركتها مع مجموعة أوسع من علماء الصناعة وعشاق التكنولوجيا والوحدات الصناعية، خططت HyperAI لعمود الفيديو "Meet AI4S"، بدعوة الباحثين أو الوحدات ذات الصلة الذين يشاركون بعمق في مجال الذكاء الاصطناعي للعلوم لمشاركة نتائج أبحاثهم وطرقهم في شكل مقاطع فيديو، ومناقشة الفرص والتحديات التي تواجه الذكاء الاصطناعي للعلوم في عملية التقدم في البحث العلمي والترويج له وتنفيذه، وذلك لتعزيز نشر الذكاء الاصطناعي للعلوم ونشره.
حتى الآن، نجحنا في عقد 4 جلسات بث مباشر لـ Meet AI4S، والتي تغطي مجالات علوم المعلومات الجغرافية، وعلوم الحياة، وهندسة البروتين.
نرحب بمجموعات البحث والمؤسسات البحثية الفعالة للمشاركة في فعالياتنا المباشرة!امسح رمز الاستجابة السريعة لإضافة "Neural Star" إلى WeChat للحصول على التفاصيل↓









