Command Palette
Search for a command to run...
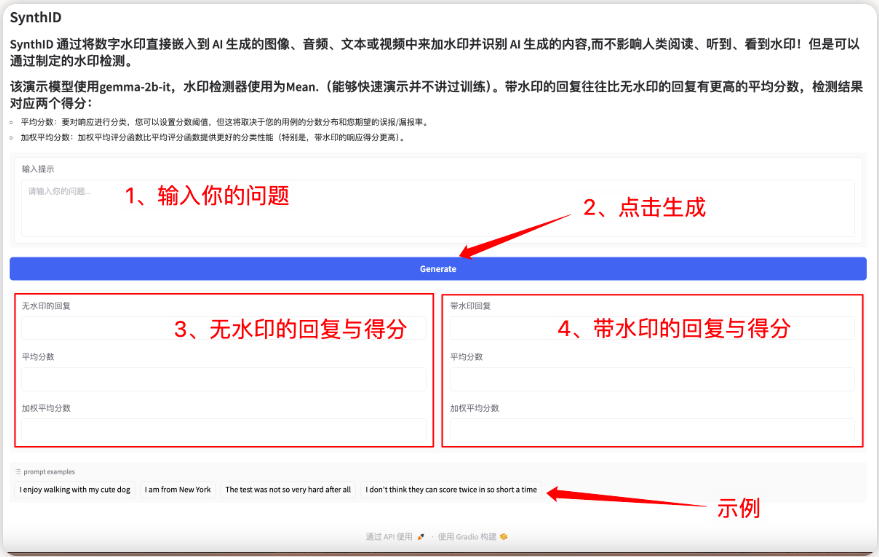
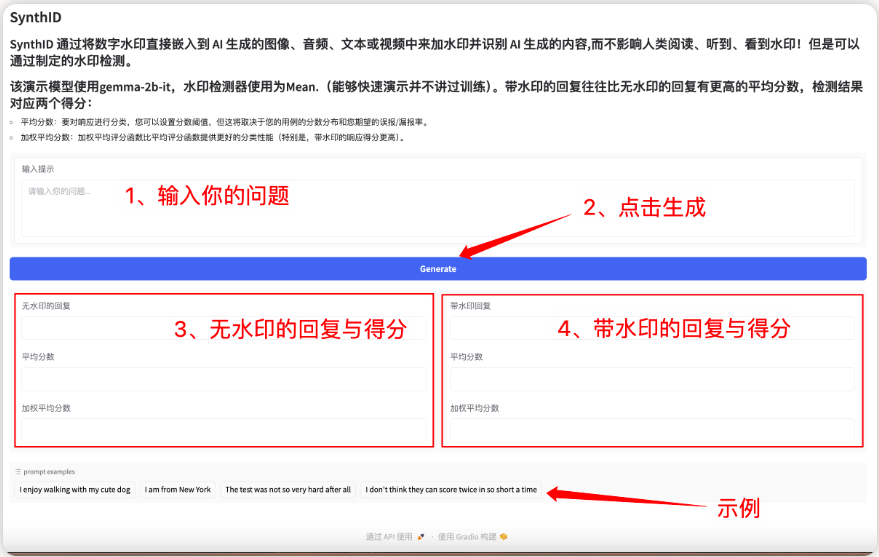
كن أول من يختبر العلامة المائية غير المرئية لـ SynthID! جعل المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي أكثر قابلية للتحكم؛ أصبحت مجموعة بيانات الترجمة الصوتية واسعة النطاق متاحة الآن على الإنترنت، وتحتوي على 6 ملايين ملف صوتي

في عصر أصبح فيه المحتوى الذي يتم إنشاؤه بواسطة الذكاء الاصطناعي شائعًا بشكل متزايد، أصبحت كيفية التمييز بسرعة بين ما إذا كان المحتوى يتم إنشاؤه يدويًا أو تم إنشاؤه بواسطة الذكاء الاصطناعي موضوعًا ساخنًا. ولا يقتصر هذا الأمر على مصداقية الأخبار وحماية حقوق النشر فحسب، بل يرتبط أيضًا ارتباطًا وثيقًا بأمن الشبكة.
أطلقت Google DeepMind مؤخرًا تقنية SynthID-Text، التي يمكنها تضمين العلامات المائية دون فقدان الجودة دون التأثير على جودة النص من خلال تحسين درجة احتمالية الرمز في عملية إنشاء النص، وتتمتع بكفاءة اكتشاف عالية للغاية. وبالمقارنة بالتقنيات التقليدية، فإنه يحقق دقة تصنيف أعلى بتكلفة زمن انتقال أقل، مما يوفر حلاً مبتكرًا للإشراف على محتوى الذكاء الاصطناعي.
أطلق الموقع الرسمي لـ hyper.ai الآن برنامجًا تعليميًا حول كيفية استخدام SynthID-Text. يمكنك استنساخه وبدء تشغيله بنقرة واحدة لإضافة العلامات المائية الرقمية إلى جيل الذكاء الاصطناعي:
رابط البدء بنقرة واحدة:
من 18 نوفمبر إلى 22 نوفمبر، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* اختيار المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات ذات المواعيد النهائية من نوفمبر إلى ديسمبر: 3
قم بزيارة الموقع الرسمي: hyper.ai
مجموعات البيانات العامة المختارة
1. مجموعة بيانات استخراج علاقات الكيانات والكائنات متعددة الوسائط
تحتوي مجموعة البيانات على 21 نوعًا مختلفًا من العلاقات وتغطي أكثر من 20000 حقيقة علاقة متعددة الوسائط، والتي تم شرحها على 3559 زوجًا من التعليقات النصية والصور المقابلة.
الاستخدام المباشر:https://go.hyper.ai/LlfTx

2. مجموعة بيانات أمراض ثمار الجوافة
تحتوي مجموعة البيانات على 473 صورة لفاكهة الجوافة المُسمّاة، والتي خضعت لخطوات معالجة مسبقة مثل إخفاء العيوب ومعادلة الهيستوجرام التكيفي المحدود التباين (CLAHE)، مما أدى إلى زيادة عدد الصور إلى 3784. يتم معالجة كل صورة مسبقًا إلى تنسيق RGB متسق يبلغ 512 × 512 بكسل.
الاستخدام المباشر:https://go.hyper.ai/RRLEd

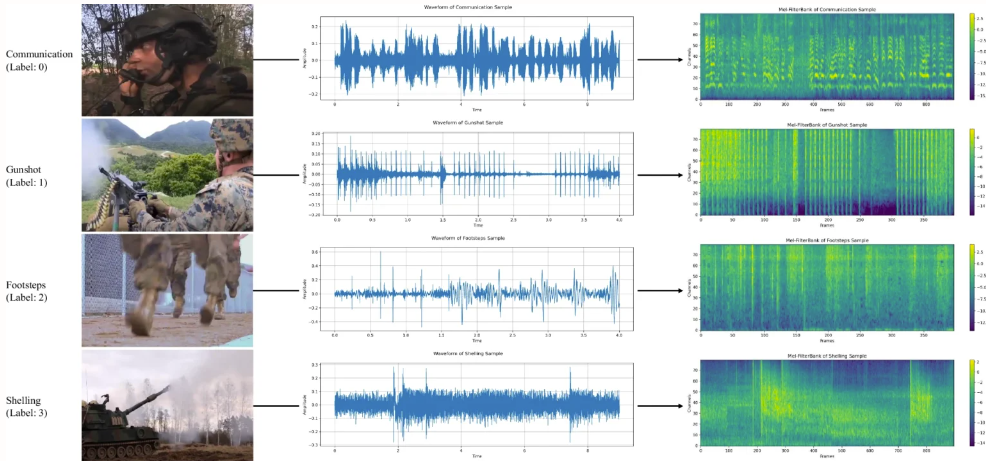
3. مجموعة بيانات الصوت العسكرية MAD
تم تصميم مجموعة بيانات MAD لدعم تدريب وتقييم أنظمة تصنيف الصوت، وخاصة في مهام تصنيف الصوت المتعلقة بالأنشطة العسكرية، مثل إطلاق النار أو نيران المدفعية أو الانفجارات. تم استخراج مجموعة البيانات من مقاطع فيديو عسكرية متعددة وتحتوي على 8075 عينة صوتية مقسمة إلى 7 فئات، بإجمالي حوالي 12 ساعة من الصوت.
الاستخدام المباشر:https://go.hyper.ai/kxqH3
4. مجموعة بيانات تفضيلات الاستدلال متعدد الوسائط MMPR
تحتوي مجموعة بيانات MMPR على 750,000 عينة بدون إجابات صحيحة واضحة و2.5 مليون عينة بإجابات صحيحة واضحة. وتغطي العينات مجالات متعددة مثل VQA والعلوم والرسومات والرياضيات والتعرف الضوئي على الحروف والمستندات لضمان التنوع. تهدف مجموعة البيانات إلى تحسين أداء النماذج في مهام التفكير المتعدد الوسائط مع تجنب التأثيرات السلبية المحتملة أثناء التدريب.
الاستخدام المباشر:https://go.hyper.ai/bbHH0

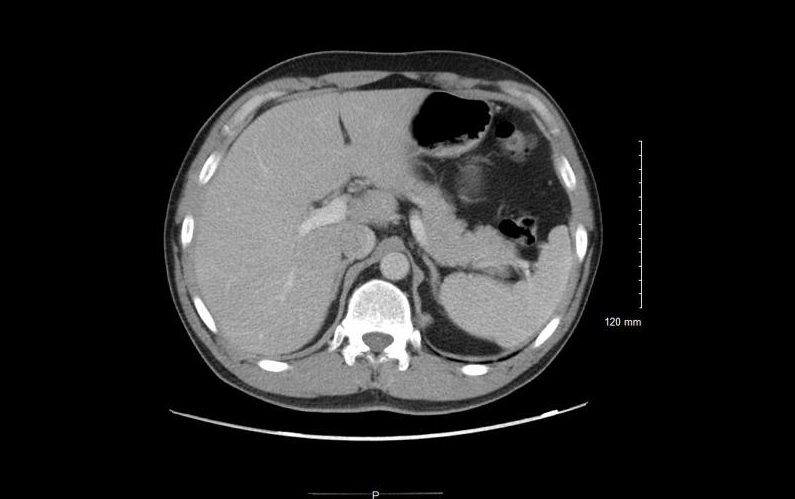
5.مجموعة بيانات صور الأشعة الطبية متعددة الوسائط ROCOv2
تجمع مجموعة بيانات ROCOv2 الصور الإشعاعية مع المفاهيم والأوصاف الطبية ذات الصلة، وتحتوي على أكثر من 70000 صورة إشعاعية، تغطي مجموعة متنوعة من الأنماط السريرية والمناطق التشريحية والاتجاهات (للأشعة السينية)، وكل صورة لها وصف مفهوم طبي مطابق.
الاستخدام المباشر:https://go.hyper.ai/XgqCa
6. مجموعة بيانات الفهرس الجغرافي PDFM
مجموعة بيانات PDFM Geo-Index عبارة عن بيانات حقيقية تُستخدم لتقييم التضمينات القائمة على ديناميكيات السكان. ويحتوي على معلومات موجزة غنية عن السلوك البشري تم التقاطها من الخرائط وملخصات اتجاهات البحث والعوامل البيئية مثل الطقس وجودة الهواء.
الاستخدام المباشر:https://go.hyper.ai/jpzY1
7. مجموعة بيانات ضبط تعليمات الصور المتعددة Mantis-Instruct
مجموعة البيانات عبارة عن مجموعة بيانات متعددة الوسائط متداخلة بين النصوص والصور تركز على ضبط التعليمات متعددة الصور، وتتكون من 14 مجموعة فرعية تحتوي على 721 ألف مثال لتدريب عائلة نموذج Mantis. تغطي مجموعة البيانات مجموعة متنوعة من مهارات الصور المتعددة، بما في ذلك المرجع المشترك، والاستدلال، والمقارنة، والفهم الزمني.
الاستخدام المباشر:https://go.hyper.ai/dOtuR
8. مجموعة بيانات سير العمل العلمي لـ MASSW
تحتوي مجموعة بيانات MASSW على أكثر من 152 ألف منشور تمت مراجعته من قبل النظراء من 17 مؤتمرًا رائدًا في علوم الكمبيوتر، والتي تغطي السنوات الخمسين الماضية. تعرف مجموعة البيانات خمسة جوانب رئيسية لسير العمل العلمي: السياق، والأفكار الرئيسية، والأساليب، والنتائج، والتأثير المقصود. وقد تم استخدام هذه الجوانب لاستخراج المعلومات وتنظيمها من كل منشور، وبالتالي توليد ملخص منظم.
الاستخدام المباشر:https://go.hyper.ai/2pUy8
9. مجموعة بيانات الترجمة الصوتية AudioSetCaps
تحتوي مجموعة بيانات التعليقات الصوتية AudioSetCaps على أكثر من 6.11 مليون ملف صوتي مدته 10 ثوانٍ. يأتي كل ملف صوتي مصحوبًا بعنوان وصفي وثلاثة أزواج من الأسئلة والأجوبة كبيانات وصفية لإنشاء العنوان النهائي.
الاستخدام المباشر:https://go.hyper.ai/3QCQP
10. مجموعة بيانات الطب الصيني التقليدي - مجموعة بيانات تشخيص الطب الصيني التقليدي SFT
تحتوي مجموعة البيانات هذه على ما يقرب من 1 جيجابايت من المحتوى عالي الجودة بما في ذلك الحالات السريرية في مختلف مجالات الطب الصيني التقليدي والكتب الشهيرة والموسوعات الطبية والقواميس. تتكون مجموعة البيانات بشكل أساسي من بيانات داخلية من مصادر غير شبكية. 99% مكتوب باللغة الصينية المبسطة بجودة ممتازة وكثافة معلومات كبيرة، مما يجعله مناسبًا لأغراض التدريب المسبق أو التدريب المسبق المستمر.
الاستخدام المباشر:https://go.hyper.ai/zb7Uf
دروس تعليمية عامة مختارة
1. أداة إنشاء العلامة المائية النصية SynthID-Text AI
النموذج هو تقنية وضع العلامات المائية لتحديد والتحقق من النصوص التي تم إنشاؤها بواسطة نماذج اللغة الكبيرة (LLMs)، والتي يمكنها الحفاظ على جودة النص وتحقيق دقة اكتشاف عالية مع تقليل تكاليف زمن الوصول. ويتمثل جوهرها في تضمين علامات مائية غير محسوسة تقريبًا عن طريق تعديل درجة احتمالية الرمز قليلاً في عملية التوليد دون المساس بجودة النص وتجربة المستخدم، وبالتالي تحقيق دقة اكتشاف عالية.
يمكن لهذا المشروع إنشاء واجهة تفاعلية أمامية من خلال واجهة Gradio. تم نشر النماذج والتبعيات ذات الصلة، ويمكن إنشاء نص العلامة المائية من خلال البدء بنقرة واحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/lQ1UK
2. إيفو: التنبؤ بالتسلسل وتوليده من المستوى الجزيئي إلى مستوى الجينوم
Evo هو نموذج مبني على أساس بيولوجي يعمم عبر اللغات الأساسية لعلم الأحياء: DNA و RNA والبروتينات. النموذج قادر على تنفيذ مهام التنبؤ والتصميمات التوليدية، وتغطية التنبؤ بالتسلسل وتوليده على نطاقات تتراوح من الجزيئات إلى الجينومات بأكملها.
انقر على الرابط أدناه واتبع البرنامج التعليمي للتنبؤ بتسلسلات على مستوى الجينوم.
تشغيل عبر الإنترنت:https://go.hyper.ai/LgFWm
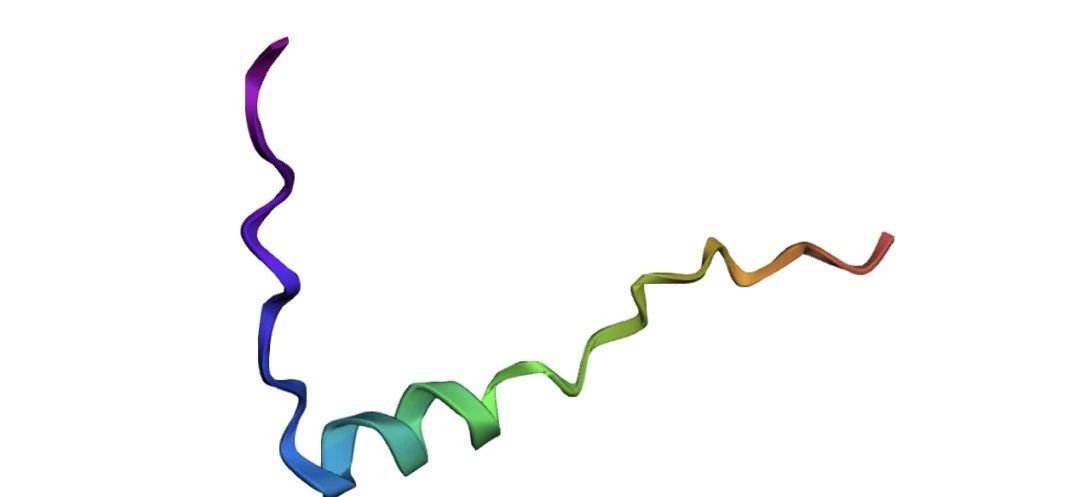
3. برنامج VASP التعليمي: 1-1. حساب DFT لذرات الأكسجين المعزولة
VASP عبارة عن حزمة برمجية لإجراء حسابات البنية الإلكترونية ومحاكاة ميكانيكا الكم والديناميكا الجزيئية. وهو أحد البرامج التجارية الأكثر شعبية لمحاكاة المواد وأبحاث علوم المواد الحسابية. إن دقتها العالية ووظائفها القوية تجعلها أداة مهمة للباحثين للتنبؤ بخصائص المواد وتصميمها. يتم استخدامه على نطاق واسع في الفيزياء الصلبة، وعلوم المواد، والكيمياء، والديناميكيات الجزيئية وغيرها من المجالات.
هذا البرنامج التعليمي هو الجزء الأول من البرنامج التعليمي الرسمي لـ VASP: حسابات DFT لذرات الأكسجين المعزولة. انقر على الرابط أدناه واتبع البرنامج التعليمي لبدء حسابات DFT عالية الأداء من الصفر.
تشغيل عبر الإنترنت:https://go.hyper.ai/pa2NX
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

مقالات المجتمع
يلعب الطي العكسي الجزيئي دورًا رئيسيًا في تصميم الأدوية والمواد، ولكن الأبحاث السابقة نادرًا ما ركزت على الطي العكسي للجزيئات العامة. ردًا على ذلك، اقترح فريق من مركز أبحاث الصناعات المستقبلية بجامعة ويستليك نموذجًا موحدًا، UniIF، للطي العكسي لجميع الجزيئات. وتظهر النتائج التجريبية أن UniIF قد حقق أداءً متطورًا في مهام متعددة مثل تصميم البروتين وتصميم الحمض النووي الريبي وتصميم المواد. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/efhze
في التطبيق متعدد التخصصات لتكنولوجيا الذكاء الاصطناعي، أصبحت كيفية الجمع بين المتغيرات المنفصلة والمستمرة لتحسين جودة إنتاج المواد البلورية مشكلة أساسية في مجال إنتاج المواد البلورية. ولمعالجة هذه المشكلة، أصدر مختبر Meta FAIR نموذج توليد المواد FlowLLM. تم تحسين كفاءة هذا النموذج في توليد مواد مستقرة بما يزيد عن 300% مقارنة بالنماذج السابقة، كما تم تحسين كفاءة توليد مواد SUN بما يقرب من 50%. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/KJzjz
في الآونة الأخيرة، نجحت جامعة شنغهاي جياو تونغ ومختبر الذكاء الاصطناعي في شنغهاي في تطوير نموذج لغة بروتينية مدرب مسبقًا مع قدرات الوعي بالبنية - ProSST. تم تدريب النموذج مسبقًا على مجموعة بيانات كبيرة مكونة من 18.8 مليون بنية بروتينية ويمكنه دمج معلومات بنية البروتين وتسلسل الأحماض الأمينية بشكل فعال، متفوقًا بشكل كبير على النماذج الحالية في مهام التعلم الخاضع للإشراف. هذه المقالة عبارة عن تفسير مفصل ومشاركة للورقة.
شاهد التقرير الكامل:https://go.hyper.ai/qi5ei
وقد اقترح مختبر الذكاء الاصطناعي في شنغهاي ومؤسسات بحثية علمية أخرى معيار GMAI-MMBench، الذي يغطي 284 مجموعة بيانات للمهام النهائية في جميع أنحاء العالم، بما في ذلك 38 نموذجًا للتصوير الطبي، و18 مهمة ذات صلة سريرية، و18 قسمًا، و4 حبيبات إدراكية في شكل أسئلة وأجوبة مرئية. إنه المرجع الطبي العام الأكثر شمولاً حتى الآن. بالإضافة إلى ذلك، تلخص هذه المقالة أيضًا مجموعات البيانات الطبية الأخرى لك، بما في ذلك روابط الاستخدام بنقرة واحدة.
شاهد التقرير الكامل:https://go.hyper.ai/csr2M
مقالات موسوعية شعبية
1. وظيفة السيني
2. القاعدة النووية
3. الشبكات العصبية الاصطناعية
4. زيادة البيانات
5. الشبكة العصبية الكمومية
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
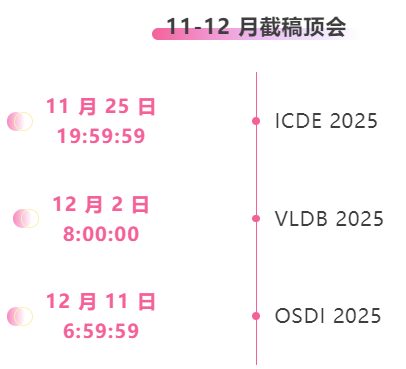
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1300 مجموعة بيانات عامة
* يتضمن أكثر من 400 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 200 حالة بحثية من AI4Science
* دعم البحث عن أكثر من 500 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:
وأخيرًا، أوصي ببرنامج "حوافز المبدعين". يمكن للأصدقاء المهتمين مسح رمز الاستجابة السريعة للمشاركة!









