Command Palette
Search for a command to run...
من الرؤية الحاسوبية إلى الذكاء الاصطناعي الطبي، نشر شيه وييدي من جامعة شنغهاي جياو تونغ عددًا من النتائج، والتي نُشرت في المجلات الفرعية Nature/NeurIPS/CVPR، وما إلى ذلك.

في السنوات الأخيرة، تسارع تطوير الذكاء الاصطناعي للعلوم، الأمر الذي لم يجلب أفكارًا بحثية مبتكرة إلى مجال البحث العلمي فحسب، بل أدى أيضًا إلى توسيع قنوات تنفيذ الذكاء الاصطناعي وتزويده بسيناريوهات تطبيق أكثر تحديًا. وفي هذه العملية، بدأ عدد متزايد من الباحثين في مجال الذكاء الاصطناعي في التركيز على مجالات البحث العلمي التقليدية مثل الطب والمواد وعلم الأحياء، واستكشاف صعوبات البحث والتحديات الصناعية فيها.
كان شيه ويي دي، الأستاذ المشارك الدائم في جامعة شنغهاي جياو تونغ، منخرطًا بشكل عميق في مجال الرؤية الحاسوبية. عاد إلى الصين في عام 2022 وكرس نفسه لأبحاث الذكاء الاصطناعي الطبي.في منتدى COSCon'24 للذكاء الاصطناعي من أجل العلوم الذي شاركت في إنتاجه شركة HyperAI، شارك البروفيسور شي ويدي إنجازات الفريق من وجهات نظر متعددة، بما في ذلك بناء مجموعة بيانات مفتوحة المصدر وتطوير النماذج، تحت عنوان "نحو تطوير نموذج عام للرعاية الصحية".

لقد قامت HyperAI بتنظيم وتلخيص المشاركة المتعمقة دون انتهاك النية الأصلية. وفيما يلي نص لأهم ما جاء في الخطاب:
الذكاء الاصطناعي الطبي هو اتجاه لا مفر منه
يعتبر البحث الطبي ذو أهمية حيوية لأنه يتعلق بحياة وصحة كل شخص. وفي الوقت نفسه، لم يتم حل مشكلة التوزيع غير المتكافئ للموارد الطبية بشكل جذري لفترة طويلة.لذا فإننا نأمل في تعزيز الرعاية الطبية الشاملة ومساعدة الجميع في الحصول على تشخيص وعلاج عالي الجودة.
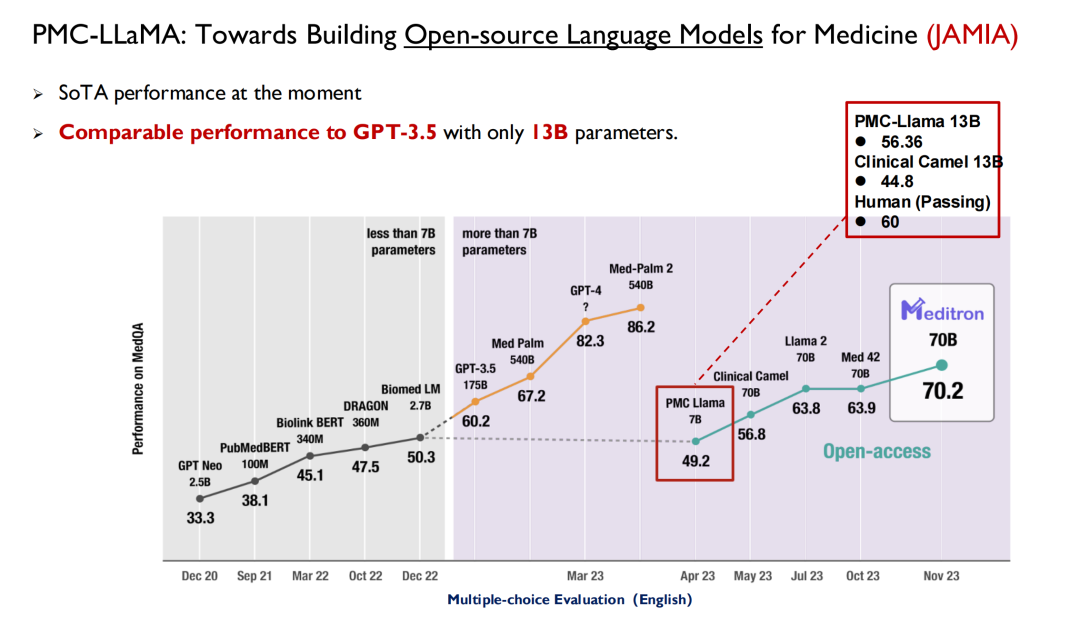
لقد استخدمت ChatGPT والنماذج الكبيرة الأخرى التي تم إصدارها في السنوات الأخيرة الرعاية الصحية كساحة معركة رئيسية لاختبار الأداء. كما هو موضح في الشكل أدناه، في امتحان الترخيص الطبي في الولايات المتحدة، قبل عام 2022، سوف تكون النماذج الكبيرة قادرة على الوصول إلى درجة 50، في حين أن البشر سوف يكونون قادرين على الوصول إلى 70، لذلك لم تجذب الذكاء الاصطناعي الكثير من الاهتمام من قبل الأطباء.
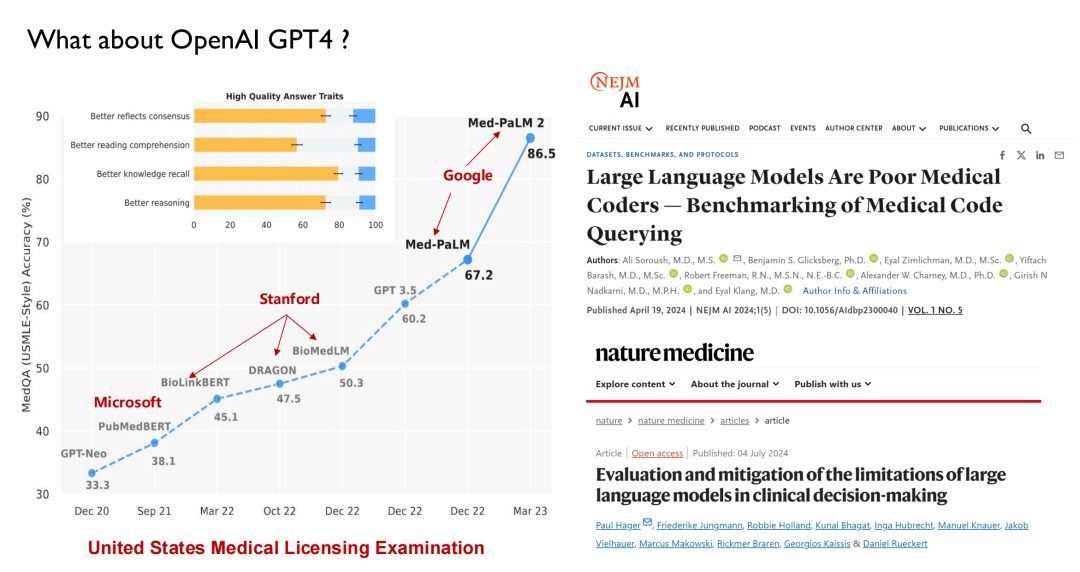
مع إصدار GPT 3.5، وصلت نتيجته إلى 60.2، وهو تحسن كبير. بعد ذلك، قامت جوجل بإصدار Med-PaLM ونسخته المحدثة، حيث وصلت أعلى درجة إلى 86.5. يمكن لـ GPT-4 اليوم الوصول إلى 90 نقطة. لقد أدى هذا الأداء العالي وسرعة التكرار إلى جعل الأطباء يبدأون في الاهتمام بالذكاء الاصطناعي.تقدم العديد من كليات الطب الآن تخصصًا جديدًا: الطب الذكي.
وعلى نحو مماثل، ليس طلاب الطب فقط هم من يحتاجون إلى التعرف على الذكاء الاصطناعي؛يمكن لطلاب الذكاء الاصطناعي أيضًا تعلم المعرفة الطبية في سنتهم الأخيرة.وقد قامت جامعة هارفارد ومؤسسات أخرى بالفعل بإنشاء دورات ذات صلة بتخصصات الذكاء الاصطناعي.
ولكن من ناحية أخرى، تظهر الدراسات في المجلات الأكاديمية مثل مجلة Nature Medicine أنفي الواقع، لا يفهم نموذج اللغة الكبير الطب.على سبيل المثال، لا يفهم النموذج الكبير حاليًا رموز التصنيف الدولي للأمراض (رموز التشخيص في نظام التصنيف الدولي للأمراض)، ومن الصعب عليه تقديم إرشادات طبية في الوقت المناسب بناءً على نتائج فحص المريض مثل الطبيب. ومن الواضح أن النماذج الكبيرة لا تزال تعاني من العديد من القيود في المجال الطبي.أعتقد أنها لن تحل محل الأطباء أبدًا، وما يريد فريقنا فعله هو جعل هذه النماذج تساعد الأطباء بشكل أفضل.
الهدف الأساسي للفريق: بناء نظام ذكاء اصطناعي طبي عام
عدت إلى الصين في عام 2022 وبدأت في إجراء أبحاث حول الذكاء الاصطناعي الطبي، لذا فإن ما سأشاركه اليوم هو بشكل أساسي نتائج الفريق في العامين الماضيين. وتغطي الصناعة الطبية مجموعة واسعة من المجالات، ولا يمكننا القول إن النموذج الذي طورناه عالمي، ولكننا نأمل أن يتمكن من تغطية أكبر عدد ممكن من المهام المهمة.
كما هو موضح في الشكل أدناه،من ناحية الإدخال، نأمل أن ندعم أوضاعًا متعددة.على سبيل المثال، الصور، والصوت، وسجلات صحة المرضى، وما إلى ذلك. بعد إدخالها في نموذج الطب العام متعدد الوسائط، يمكن للأطباء التفاعل معه.يتضمن مخرج النموذج شكلين على الأقل، أحدهما مرئي،يتم تحديد موقع الآفة من خلال التجزئة والكشف.الثاني هو النص (Text)إخراج نتائج التشخيص (التشخيص) أو التقارير (التقرير).
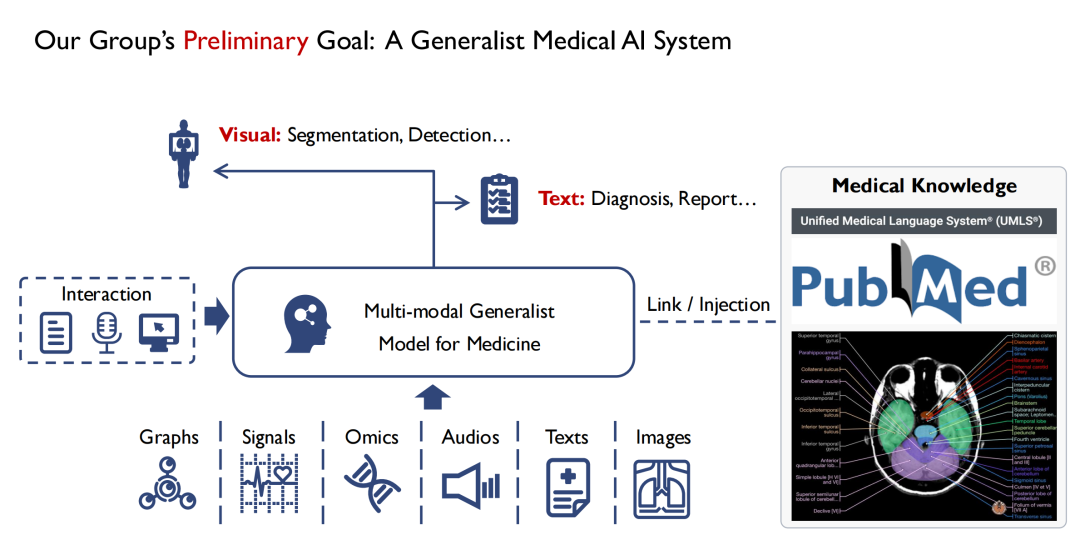
أنا متخصص في رؤية الكمبيوتر. من خلال ملاحظاتي، فإن الفرق الكبير بين الرؤية والطب هو أن معظم المعرفة في الطب، وخاصة الطب المبني على الأدلة، يتم تلخيصها من الخبرة الإنسانية. إذا استطاع المبتدئ أن يستنفذ جميع الكتب الطبية، فإنه يستطيع على الأقل أن يصبح خبيراً طبياً من الناحية النظرية. لذلك،خلال عملية تدريب النموذج، نأمل أيضًا أن نحقن فيه كل المعرفة الطبية.لأن إذا كان النموذج يفتقر إلى المعرفة الطبية الأساسية، فسيكون من الصعب اكتساب ثقة الأطباء والمرضى.
لذا، باختصار،الهدف الأساسي لفريقنا هو بناء نموذج طبي عالمي متعدد الوسائط وحقن أكبر قدر ممكن من المعرفة الطبية فيه.
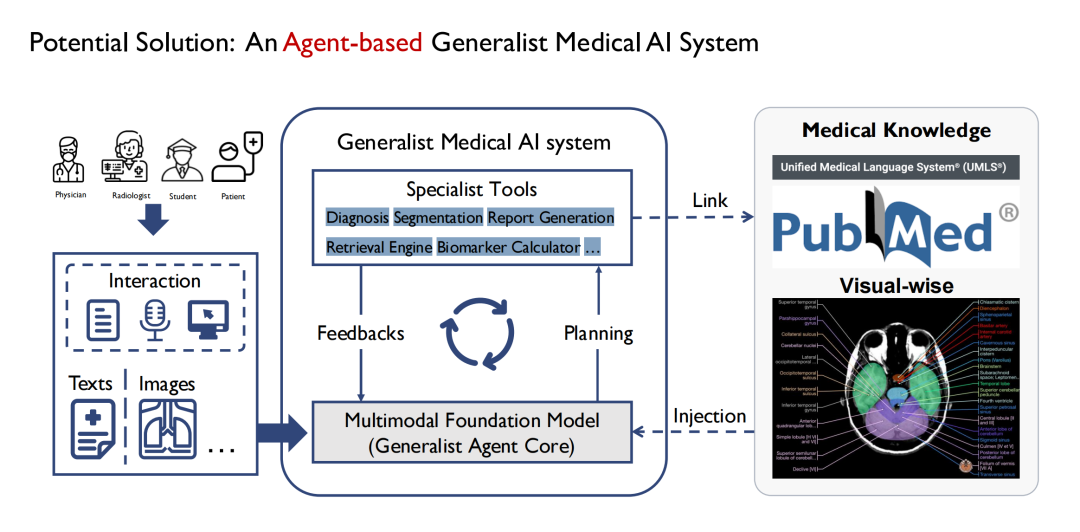
في البداية، بدأنا في تحديد النماذج العامة، وتدريجيًا اكتشفنا أنه من غير الواقعي بناء نموذج طبي قادر على كل شيء مثل GPT-4. نظرًا لوجود العديد من الأقسام في المستشفى ولكل قسم مهام مختلفة، فمن الصعب أن يغطي النموذج العام جميع المهام.لذلك اخترنا تنفيذه من خلال الوكيل.كما هو موضح في الشكل أدناه، يتكون النموذج العام في المنتصف من نماذج فرعية متعددة، وكل نموذج فرعي هو في الأساس وكيل، ويتم بناء النموذج العام في النهاية في شكل وكيل متعدد.
تتمثل مزاياها في أن الوكلاء المختلفين يمكنهم قبول مدخلات مختلفة، وبالتالي فإن نهاية الإدخال في النموذج يمكن أن تكون أكثر تعقيدًا وتنوعًا؛ يمكن أيضًا للوكلاء المتعددين تشكيل سلسلة تفكير في عملية التعامل مع المهام المختلفة خطوة بخطوة؛ كما أن نهاية الإخراج أكثر ثراءً، على سبيل المثال، يمكن لوكيل واحد إكمال تقسيم أنواع متعددة من الصور الطبية مثل التصوير المقطعي المحوسب والتصوير بالرنين المغناطيسي؛ وفي الوقت نفسه، فإنه يتمتع أيضًا بقدرة أفضل على التوسع.
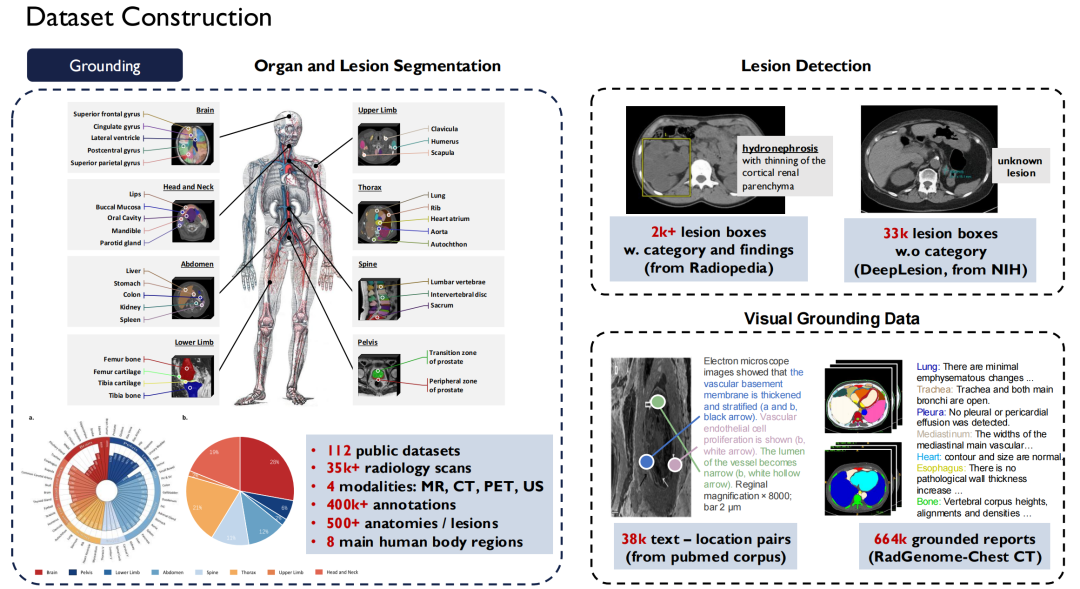
المساهمة في تقديم مجموعات بيانات مفتوحة المصدر عالية الجودة
مع التركيز على الهدف الكبير المتمثل في بناء نموذج طبي عالمي متعدد الوسائط، سأقدم الآن إنجازات الفريق من جوانب متعددة، بما في ذلك مجموعات البيانات مفتوحة المصدر، ونماذج اللغة الكبيرة، ووكلاء تشخيص الأمراض، وما إلى ذلك.
الأول هو مساهمتنا في مجموعات البيانات مفتوحة المصدر.
لا يوجد نقص في مجموعات البيانات في المجال الطبي، ولكن البيانات عالية الجودة المتاحة علنًا نادرة نسبيًا بسبب مشكلات الخصوصية من خلال التصميم. وباعتبارنا فريقًا أكاديميًا، نأمل أن نساهم في توفير المزيد من البيانات مفتوحة المصدر عالية الجودة للصناعة.وبعد عودتي إلى الصين، بدأت في بناء مجموعة بيانات طبية واسعة النطاق.
من حيث النصوص، قمنا بجمع أكثر من 30 ألف كتاب طبي، تحتوي على 4 مليارات رمز؛ تم فحص جميع الأدبيات الطبية في PubMed Central (PMC)، بما في ذلك 4.8 مليون ورقة بحثية و75 مليار رمز؛ وجمع الكتب الطبية بثماني لغات منها الصينية والإنجليزية والروسية واليابانية على الإنترنت وحولها إلى نصوص.
أيضًا،لقد قمنا أيضًا ببناء تعليمات فائقة في المجال الطبي.مع الأخذ في الاعتبار تنوع المهام، تم إدراج 124 مهمة طبية، تشمل 13.5 مليون عينة.

من الأسهل الحصول على بيانات النص، ولكن من الصعب الحصول على الرؤية واللغة (أزواج الصورة والنص). لقد قمنا بفحص حوالي 200 ألف حالة من موقع Radiopaedia، وجمعنا الصور وتعليقاتها التوضيحية من الأوراق، وأكثر من 30 ألف مجلد من تقارير الأشعة الأساسية.
حاليًا، معظم بياناتنا مفتوحة المصدر.
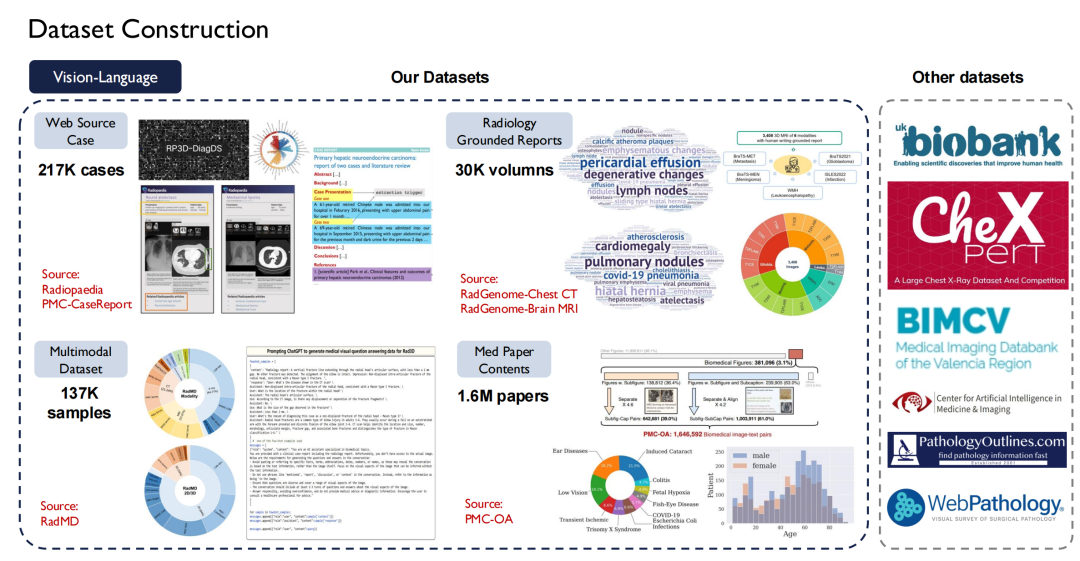
ويُظهر الجانب الأيمن من الشكل أعلاه مجموعات بيانات عامة أخرى، مثل UK Biobank، التي دفعنا مقابلها لشراء بيانات عن ما يقرب من 100 ألف مريض في المملكة المتحدة لمدة 10 سنوات؛ بالإضافة إلى ذلك، يوفر كتاب Pathology Outlines معرفة شاملة بعلم الأمراض.
من حيث بيانات التأريض،هذه هي بيانات التجزئة والكشف التي ذكرتها للتو.لقد قمنا بتوحيد ما يقرب من 120 مجموعة بيانات عامة لصور الأشعة المتاحة في السوق في معيار واحد، مما أدى إلى إنتاج أكثر من 35000 صورة مسح إشعاعي ثنائية الأبعاد / ثلاثية الأبعاد.ويغطي هذا الكتاب أربع وسائل: التصوير بالرنين المغناطيسي، والتصوير المقطعي المحوسب، والتصوير المقطعي بالإصدار البوزيتروني، والتصوير بالموجات فوق الصوتية، مع 400 ألف تعليق تفصيلي دقيق، وتغطي هذه البيانات 500 عضو في الجسم.وفي الوقت نفسه، قمنا بتوسيع وصف الآفات وجعلنا كل هذه المجموعات من البيانات مفتوحة المصدر.
التكرار المستمر لإنشاء نموذج طبي احترافي
نموذج اللغة
يمكن فقط لمجموعات البيانات مفتوحة المصدر عالية الجودة أن تساعد الطلاب والباحثين في إجراء تدريب نموذجي أفضل. وبعد ذلك سأقدم إنجازات الفريق على النموذج.
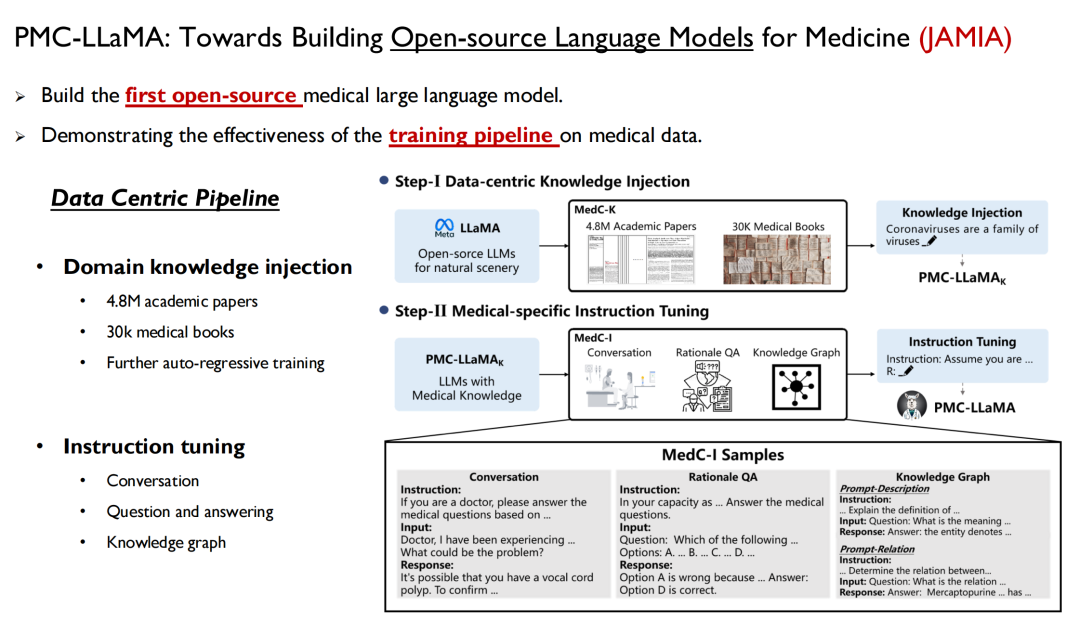
الأول هو نموذج اللغة، وهو وسيلة لحقن المعرفة الإنسانية بسرعة في النموذج. في أبريل/نيسان الماضي، أطلقنا نموذجًا يسمى PMC-LLaMA، وتم نشر البحث ذي الصلة في JAMIA تحت عنوان "نحو بناء نماذج لغوية مفتوحة المصدر للطب".
عنوان الورقة:
https://academic.oup.com/jamia/article/31/9/1833/7645318
هذا هو أول نموذج لغوي مفتوح المصدر قمنا بتطويره في المجال الطبي. لقد قمنا بتدريب جميع البيانات الطبية وبيانات الورق المذكورة أعلاه في النموذج، وقمنا بإجراء تدريب انحداري ذاتي، ثم قمنا بضبط التعليمات لتحويل البيانات إلى أزواج من الأسئلة والأجوبة.
ذكر باحثو جامعة ييل في ورقتهم البحثية: PMC-LLaMA هو أقدم نموذج طبي مفتوح المصدر في هذا المجال.وقد استخدمه العديد من الباحثين لاحقًا كخط أساس، ولكن في رأيي، لا تزال هناك فجوة بين PMC-LLaMA والنماذج المغلقة المصدر، لذلك سنستمر في تكرار هذا النموذج وترقيته في المستقبل.
وبعد ذلك، نشرنا ورقة بحثية أخرى في مجلة Nature Communications: "نحو بناء نماذج لغوية متعددة اللغات للطب".تم إطلاق نموذج طبي متعدد اللغات، يغطي ست لغات بما في ذلك الإنجليزية والصينية واليابانية والفرنسية والروسية والإسبانية، وتم تدريبه باستخدام 25 مليار رمز مرتبط بالمجال الطبي. ونظرًا لعدم وجود مجموعة اختبار موحدة متعددة اللغات، فقد قمنا أيضًا ببناء معيار ذي صلة ليقوم الجميع باختباره.
وفي الممارسة العملية، وجدنا أنه مع ترقية النموذج الأساسي وإدخال المعرفة الطبية إليه، سيتم أيضًا تحسين أداء النموذج الطبي الكبير الناتج.
معظم المهام المذكورة أعلاه هي "أسئلة اختيار من متعدد"، ولكننا جميعًا نعلم أنه من المستحيل على الأطباء الإجابة فقط على أسئلة الاختيار من متعدد في عملهم الفعلي، لذلك نأمل أن يتم تضمين نموذج اللغة الكبير في سير عمل الطبيب في شكل نص حر. وفي ضوء ذلك،في بحثنا الجديد، سنركز بشكل أكبر على المهام السريرية، وجمع مجموعات البيانات ذات الصلة، وتحسين قابلية التوسع السريري للنموذج.
ولا تزال الورقة ذات الصلة قيد المراجعة.
نموذج اللغة البصرية
وعلى نحو مماثل، كنا أحد أوائل الفرق التي أجرت أبحاثًا حول نماذج اللغة البصرية في المجال الطبي. وبناء على البيانات المذكورة أعلاه،لقد قمنا ببناء 3 مجموعات بيانات مفتوحة المصدر:
* تم جمع 1.6 مليون زوج من التعليقات التوضيحية للصور على نطاق واسع من PubMed Central وإنشاء مجموعة بيانات PMC-OA؛
* تم إنشاء 227000 زوجًا من الأسئلة والأجوبة البصرية الطبية من PMC-OA لتشكيل PMC-VQA؛
* تم إنشاء مجموعة بيانات Rad3D من خلال جمع 53000 حالة و48000 زوجًا من التعليقات التوضيحية المتعددة للصور من أنواع Radiopaedia.
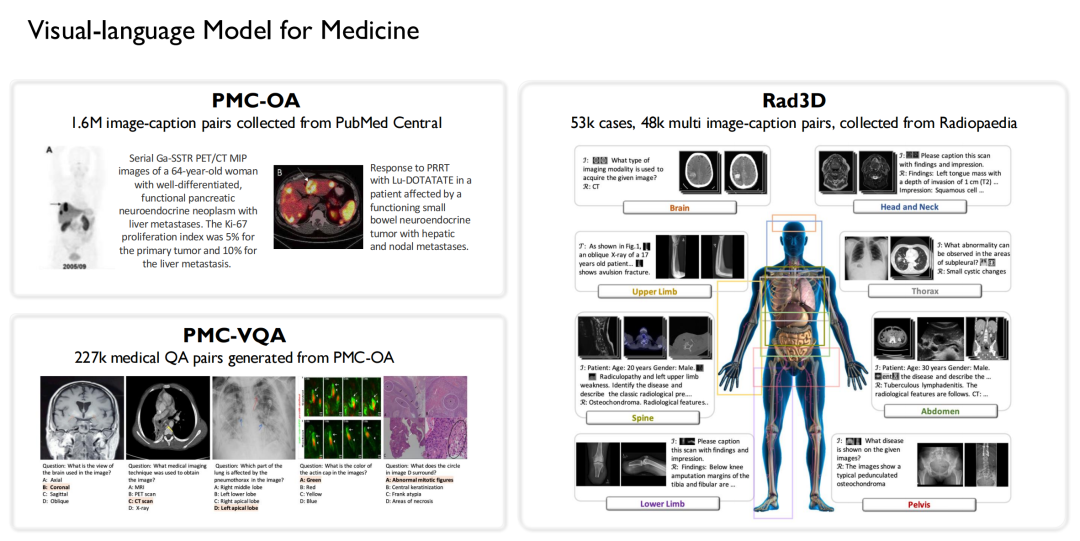
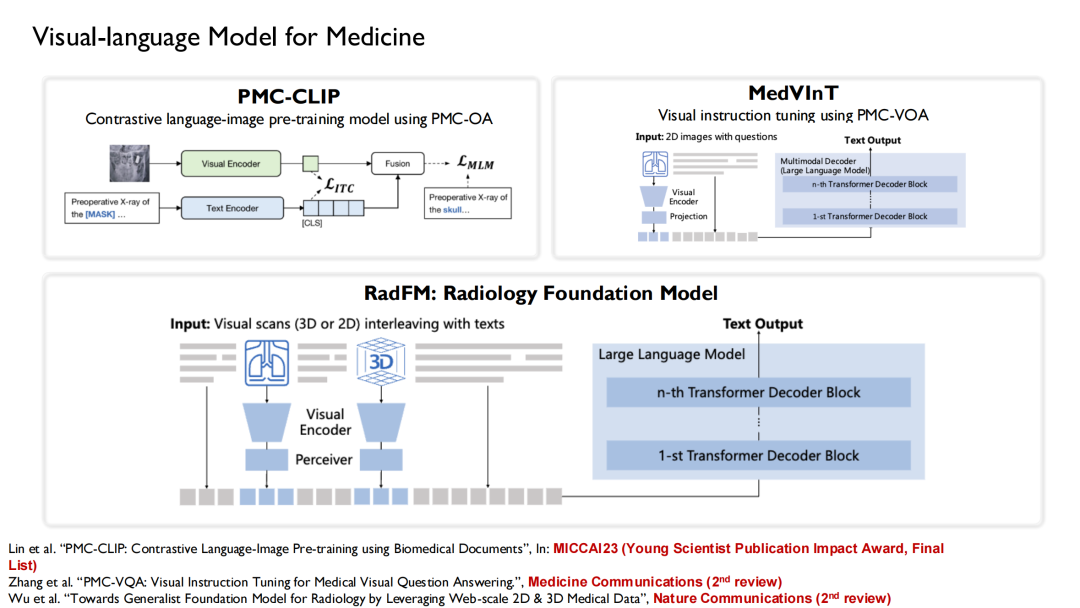
وبناءً على مجموعات البيانات هذه، قمنا بدمج نماذج اللغة التي تم تدريبها.تم تدريب ثلاثة إصدارات من نماذج الرؤية واللغة: PMC-CLIP، وMedVInT، وRadFM.
PMC-CLIP هي نتيجة نشرناها في MICCAI 2023، المؤتمر الأبرز في مجال التصوير بالذكاء الاصطناعي الطبي.وأخيراً تم اختياره ضمن القائمة النهائية لجائزة تأثير النشر للعلماء الشباب.يتم منح الجائزة لثلاثة إلى سبعة أوراق بحثية فائزة يتم اختيارها من الأوراق المنشورة خلال السنوات الخمس الماضية.
لقد أصبح نموذج RadFM (نموذج مؤسسة الأشعة) الآن شائعًا جدًا، ويستخدمه العديد من الباحثين كخط أساس. أثناء عملية التدريب،نقوم بإدخال تداخل النص والصورة في النموذج، والذي يمكنه توليد إجابات مباشرة بناءً على الأسئلة.
تعزيز المعرفة الخاصة بالمجال وتحسين أداء النموذج
يحتاج ما يسمى بالتعلم التمثيلي المعزز بالمعرفة (التعلم التمثيلي المعزز بالمعرفة) إلى حل مشكلة كيفية حقن المعرفة الطبية في النموذج. لقد أجرينا أيضًا سلسلة من الأبحاث حول هذا التحدي.
أولاً، علينا أن نحل مشكلة من أين تأتي "المعرفة".من ناحية أخرى، فهي المعرفة الطبية العامة.تم الحصول على أكبر رسم بياني للمعرفة في المجال الطبي من الإنترنت، بالإضافة إلى الأوراق والكتب ذات الصلة التي تبيعها UMLS؛ومن ناحية أخرى، هناك المعرفة الخاصة بمجال معين.على سبيل المثال، تقارير الحالة، والصور الإشعاعية، والموجات فوق الصوتية، وما إلى ذلك؛ بالإضافة إلى المعرفة التشريحية، يمكن الحصول عليها كلها من بعض المواقع الإلكترونية. وبطبيعة الحال، ينبغي إيلاء اهتمام خاص لقضايا حقوق الطبع والنشر هنا، حيث لا يمكن استخدام المحتوى الموجود على بعض المواقع الإلكترونية.

بعد الحصول على هذه "المعرفة"، يمكننا رسم بياني للمعرفة.وهذا يقيم العلاقات بين المرض والمرض، والدواء والدواء، والبروتين والبروتين، ويقدم أوصافًا تفصيلية.
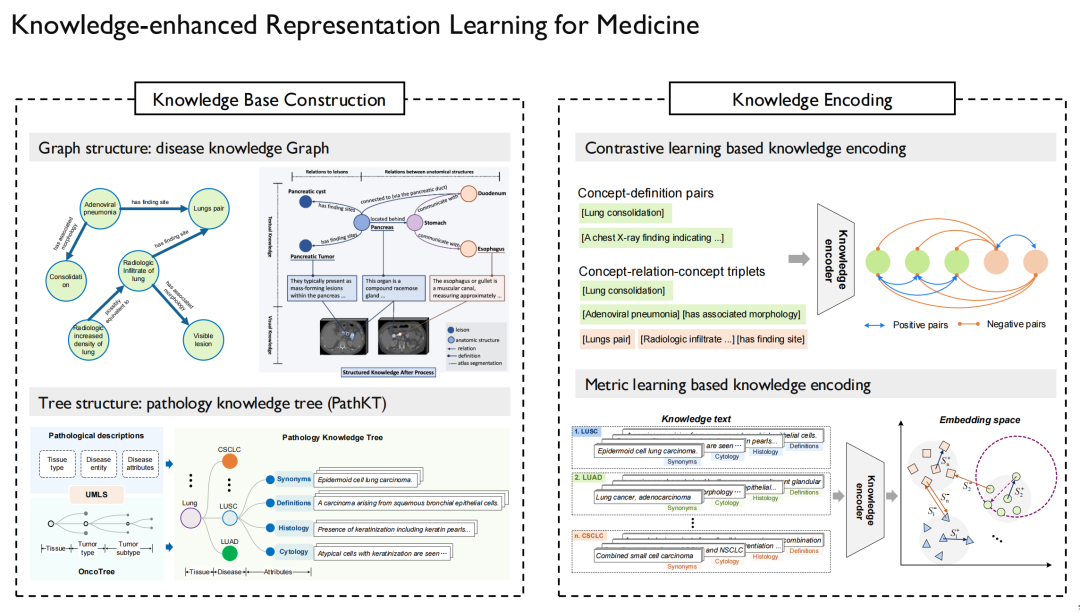
على الجانب الأيسر من الصورة أعلاه يوجد مخطط المعرفة المرضية وشجرة المعرفة التي بنيناها.يتم استخدامه بشكل أساسي لتشخيص السرطان، لأن السرطان قد يحدث في أعضاء مختلفة من جسم الإنسان وينقسم إلى أنواع فرعية مختلفة، والتي تكون مناسبة لتحويلها إلى شكل هيكلي على شكل شجرة. وبالمثل، بالإضافة إلى علم الأمراض المتعدد الوسائط، أجرينا أيضًا أبحاثًا ذات صلة حول الأشعة المتعددة الوسائط والأشعة السينية المتعددة الوسائط.
والخطوة التالية هي حقن هذه المعرفة في نموذج اللغة حتى يتمكن النموذج من تذكر العلاقة بين الرسم البياني والنقط الموجودة في الرسم البياني.بمجرد تدريب نموذج اللغة، لن يحتاج النموذج المرئي إلا إلى التوافق مع نموذج اللغة.
لقد قارنا نتائجنا مع نتائج مايكروسوفت وستانفورد، وأظهرت النتائج أنالنموذج الذي يحتوي على معرفة المجال المضافة لديه أداء أعلى بكثير من النماذج الأخرى التي لا تحتوي على معرفة المجال.
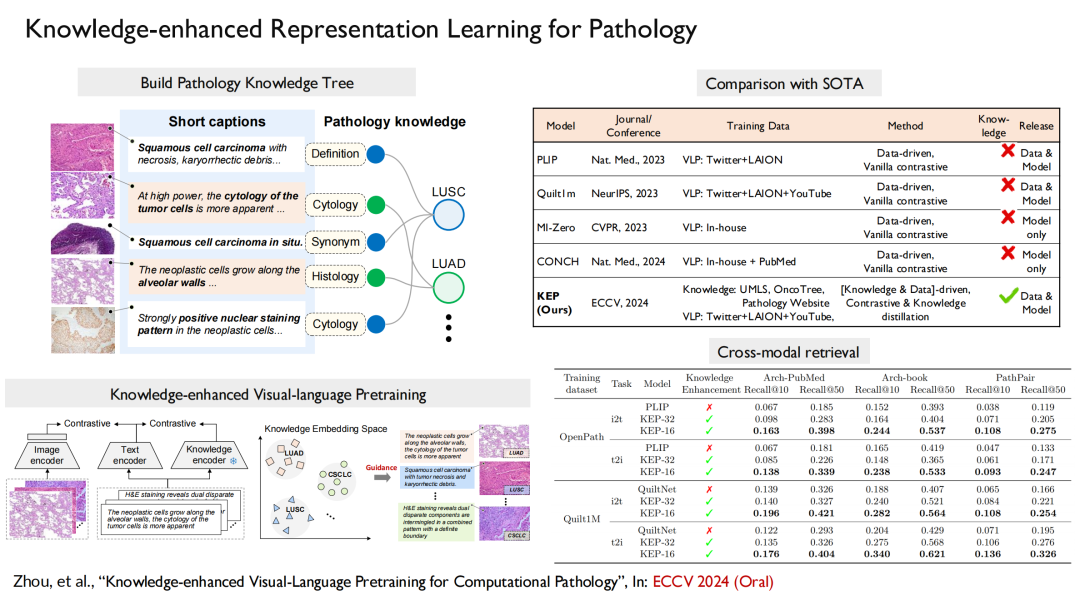
في مجال علم الأمراض، تم اختيار ورقتنا البحثية "التدريب المسبق لللغة البصرية المعزز بالمعرفة لعلم الأمراض الحسابي" لأفضل مؤتمر للتعلم الآلي ECCV 2024 (شفوي). في هذا العمل، قمنا ببناء شجرة المعرفة وحقنها في تدريب النموذج، ثم قمنا بمحاذاة الرؤية واللغة.
علاوة على ذلك، استخدمنا نفس الطريقة لبناء نموذج تصوير شعاعي متعدد الوسائط، ونشرت النتائج في مجلة Nature Communications تحت عنوان "تشخيص الأمراض طويلة المدى على نطاق واسع باستخدام صور الأشعة".يمكن للنموذج إخراج الأعراض المقابلة بشكل مباشر استنادًا إلى الصور الإشعاعية للمريض.
في ملخص،نفذ عملنا عملية كاملة - أولاً، قمنا ببناء أكبر مجموعة بيانات مفتوحة المصدر للصور الإشعاعية، والتي تحتوي على 200000 صورة، و41000 صورة للمريض، وتغطي 930 مرضًا، وما إلى ذلك؛ ثانياً، قمنا ببناء نموذج متعدد الوسائط ومتعدد اللغات لتعزيز المعرفة في مجالات محددة؛ وأخيرًا، قمنا ببناء معيار مماثل.
نبذة عن البروفيسور شيه ويدي
وهو أستاذ مشارك دائم في جامعة شنغهاي جياو تونغ، وحاصل على جائزة برنامج المواهب الشابة رفيعة المستوى الوطنية (الخارجية)، وبرنامج المواهب الرفيعة المستوى في الخارج في شنغهاي، وبرنامج نجمة شنغهاي الصباحية. وهو أيضًا القائد الشاب للمشروع الرئيسي لوزارة العلوم والتكنولوجيا "الابتكار في العلوم والتكنولوجيا 2030 - الجيل الجديد من الذكاء الاصطناعي"، وقائد المشروع في مؤسسة العلوم الطبيعية الوطنية في الصين.
حصل على درجة الدكتوراه. من مجموعة الهندسة البصرية (VGG) في جامعة أكسفورد، حيث درس تحت إشراف البروفيسور أندرو زيسرمان والبروفيسورة أليسون نوبل. وهو أحد أوائل الحاصلين على منحة Google-DeepMind الكاملة، ومنحة China-Oxford، وجائزة التميز في قسم الهندسة بجامعة أكسفورد.
مجالات بحثه الرئيسية هي الرؤية الحاسوبية والذكاء الاصطناعي الطبي. لقد نشر أكثر من 60 ورقة بحثية، بما في ذلك CVPR، ICCV، NeurIPS، ICML، IJCV، Nature Communications، وغيرها، مع أكثر من 12500 استشهاد على Google Scholar. فاز بجائزة أفضل ورقة بحثية، وجائزة أفضل ملصق، وجائزة أفضل ورقة بحثية في مؤتمرات وندوات دولية مرموقة عدة مرات، كما أنه أحد المتأهلين للنهائيات في جائزة MICCAI Young Scientist Publication Impact Award. وهو مراجع خاص لمجلة Nature Medicine ومجلة Nature Communications، ورئيس مجال مؤتمرات CVPR وNeurIPS وECCV، المؤتمرات الرائدة في مجال الرؤية الحاسوبية والذكاء الاصطناعي.
* الصفحة الشخصية :










