Command Palette
Search for a command to run...
أولاً! أطلقت أربع جامعات كبرى بشكل مشترك Y-Mol، وهو نموذج لغوي كبير للبحث والتطوير في مجال الأدوية، مع أداء إجمالي يقود LLaMA2

أصبحت نماذج اللغة الكبيرة التي يمثلها ChatGPT وChatGLM وLLaMA أدوات قوية للأشخاص لاستكشاف العالم المجهول. لقد أثبتت هذه النماذج التي تحتوي على مليارات المعلمات قدرات قوية في توليد النص وفهم السياق من خلال التدريب الدقيق لمجموعات النصوص واسعة النطاق. ومع ذلك، فإن معظم هذه النماذج تحقق أداءً جيدًا في المهام العامة، ولكنها تواجه تحديات كبيرة في مجالات محددة معينة، وخاصة تطوير الأدوية.
على عكس مجال معالجة اللغة الطبيعية، يفتقر مجال البحث والتطوير في مجال الأدوية إلى نموذج قياسي موحد، كما أن عملية البحث والتطوير معقدة ومكلفة. بالإضافة إلى ذلك، فهو يشمل تخصصات متعددة مثل الكيمياء الحاسوبية، وعلم الأحياء البنيوي، وعلم المعلومات الحيوية. من الصعب الحصول على البيانات ذات الصلة، وتتطلب بيانات التفاعل بين الكيانات المرتبطة بالمخدرات معرفة متطورة بالمجال ليتم تصنيفها.وتعمل هذه العوامل مجتمعة على الحد من تطبيق نماذج اللغة الكبيرة في أبحاث وتطوير الأدوية.
ردًا على ذلك، اقترحت فرق بحثية من جامعة هونان وجامعة سنترال ساوث وجامعة هونان العادية وجامعة شيانغتان بشكل مشترك نموذجًا لغويًا كبيرًا Y-Mol مسترشدًا بالمعرفة الطبية الحيوية متعددة المقاييس. Y-Mol هو نموذج تسلسلي متراجع ذاتيًا يمكن ضبطه على مجموعات نصية وتعليمات مختلفة، مما يعزز بشكل كبير من أداء النموذج وإمكاناته في تطوير الأدوية. ويعد هذا إنجازًا جديدًا في مجال تطوير الأدوية باستخدام نماذج لغوية كبيرة.
تم نشر الدراسة، التي تحمل عنوان "Y-Mol: نموذج لغوي كبير موجه بالمعرفة الطبية الحيوية متعدد المقاييس لتطوير الأدوية"، كنسخة أولية على arxiv.
أبرز الأبحاث:
* Y-Mol هو أول نموذج لغوي كبير تم إنشاؤه لاكتشاف الأدوية
* تقوم Y-Mol ببناء مجموعة بيانات تعليمات غنية بالمعلومات من خلال دمج المعرفة الطبية الحيوية متعددة المقاييس
* تتميز شركة Y-Mol بالتفوق في التفاعلات الدوائية، والتفاعلات الدوائية المستهدفة، والتنبؤ بالخصائص الجزيئية، وتُظهر قدرات قوية في الفهم والتنوع في مهام تطوير الأدوية المختلفة

عنوان الورقة:
https://doi.org/10.48550/arXiv.2410.11550
اتبع الحساب الرسمي ورد على "نموذج تطوير الدواء" للحصول على ملف PDF كامل
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
استكشاف نوعين من مجموعات البيانات بشكل كامل لبناء مجموعة بيانات طبية حيوية شاملة
من حيث إنشاء مجموعة بيانات ما قبل التدريب لـ Y-Mol، اختارت الدراسة نوعين من مجموعات البيانات:مجموعة نصوص من منشورات PubMed الطبية الحيوية؛ تعليمات خاضعة للإشراف مبنية على رسم بياني للمعرفة الطبية الحيوية، وبيانات استدلالية مستخرجة من نماذج الخبراء.
من أجل استكشاف المعرفة الطبية الحيوية الغنية في المنشورات بشكل عميق،استخرجت الدراسة وعالجت مسبقًا أكثر من 33 مليون منشور تغطي تخصصات متعددة من منصات النشر عبر الإنترنت مثل PubMed.وكما هو موضح في الشكل (أ) أدناه، استخرج الباحثون الملخصات والمقدمات المرئية من هذه المنشورات كبيانات نصية طبية حيوية (نص معاد بناؤه) لضمان جودة وأهمية المجموعة.
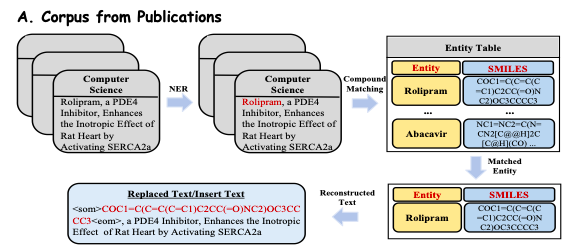
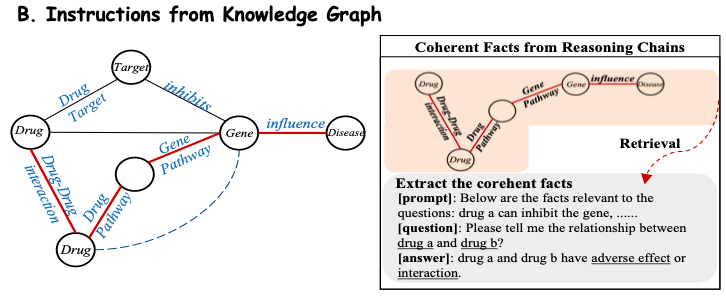
من أجل استخراج المعرفة المجالية بكفاءة من قاعدة المعرفة الطبية الحيوية، تقوم هذه الدراسة بتحويل الحقائق الموجودة في قاعدة المعرفة إلى مطالبات باللغة الطبيعية.وكما هو موضح في الشكل ب أدناه، تفترض هذه الدراسة أن كل سلسلة استدلال في الرسم البياني الفرعي لها دلالات علاقاتية واضحة، وبالتالي يتم استخراج كل مسار متماسك وتحويله إلى وصف باللغة الطبيعية باستخدام قالب مصمم بعناية كسياق سريع. ثم تقوم الدراسة بدمج هذه السياقات المبنية مع الأسئلة المقابلة وإدخالها في Y-Mol لإخراج إجابات خاضعة للإشراف.
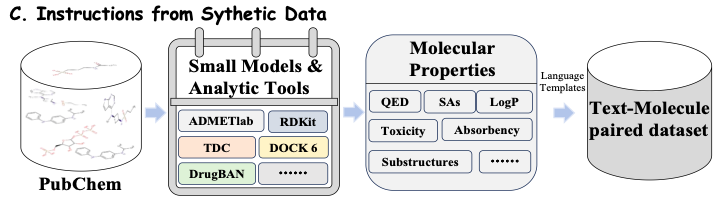
بالإضافة إلى ذلك، من أجل الحصول على تعليمات واسعة النطاق تعتمد على سمات الدواء ومعرفة المجال، استخدمت هذه الدراسة بيانات تركيبية متخصصة من نماذج صغيرة موجودة لبناء التعليمات وصقل طيف معرفة الدواء في Y-Mol.وفي نهاية المطاف، جمعت الدراسة 11.2 مليون إدخالاً من مجموعة نصوص و2.3 مليون تعليمات مصممة بعناية.
كما هو موضح في الشكل ج أدناه، بالنسبة لجزيء دواء معين، من أجل استخراج خصائص جزيئية أكثر شمولاً، جمعت هذه الدراسة سلسلة من الأدوات الجزيئية المتقدمة والنماذج الحسابية، مثل ADMETlab وRDKit وTDC وDrugBAN. تستخرج هذه الأدوات والنماذج معلومات جزيئية ذات خصائص مختلفة من مجموعات البيانات المتاحة للجمهور، بما في ذلك QED، وSAs، وLogP، والسمية، والامتصاص، والبنى الفرعية. وبهذه الطريقة، يمكن للبحث أن يدمج بشكل مستمر أحدث النماذج والأدوات واستخدام بياناتها التنبؤية لتدريب النماذج، بحيث يمكن لشركة Y-Mol أن تتطور في الوقت الفعلي وتحافظ على مكانتها الرائدة في مجال تطوير الأدوية.
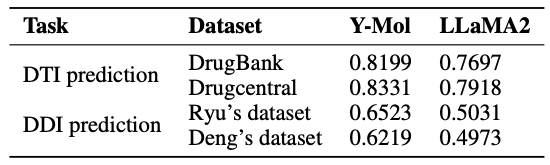
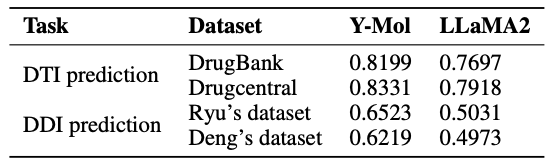
وأخيرًا، وكما هو موضح في الشكل أدناه، تُظهر الدراسة توزيع بيانات Y-Mol لمهام مختلفة أثناء مرحلة ما قبل التدريب ومرحلة الضبط الدقيق الخاضع للإشراف. من حيث تقييم القدرة على الاستدلال، من أجل اختبار أداء Y-Mol بشكل شامل في التنبؤ بتفاعل الدواء مع الهدف (DTI) والتنبؤ بتفاعل الدواء مع الدواء (DDI)،وقد اختار فريق البحث مجموعات البيانات المرجعية المعترف بها على نطاق واسع DrugBank و DrugCentral للتنبؤ بمؤشر DTI.
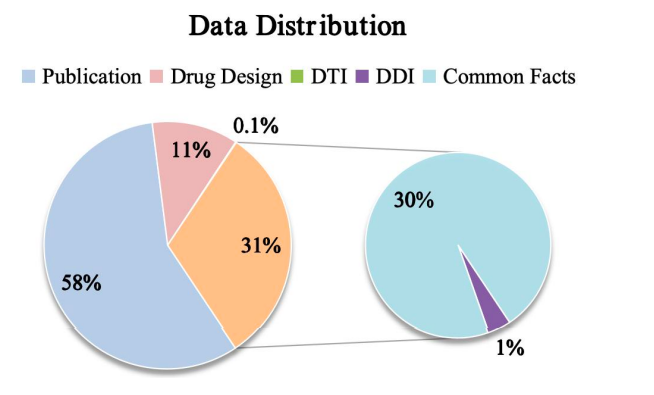
وفي الوقت نفسه، من أجل تقييم أداء التنبؤ بـ DDI، استخدم الباحثون مجموعة البيانات التي قدمها ريو ودينج.تم اختيار طرق التقييم هذه بعناية لضمان إمكانية اختبار Y-Mol بشكل عادل وشامل وفقًا لمعايير الصناعة في مجال تطوير الأدوية لإثبات فعاليته.
مجموعة بيانات ريو: https://doi.org/10.1073/pnas.1803294115
مجموعة بيانات دينج: https://doi.org/10.1093/bioinformatics/btaa501
Y-Mol: يعتمد على LLaMA2-7b، مخصص لتطوير الأدوية
اختارت هذه الدراسة LLaMA2-7b كنموذج لغوي كبير أساسي لبناء إطار متقدم للتدريب والاستدلال خصيصًا لتطوير الأدوية - Y-Mol. كما هو موضح في الشكل أدناه،تم تقسيم تطوير Y-Mol إلى مرحلتين رئيسيتين:
أولاً،تم تدريب Y-Mol مسبقًا على مجموعة واسعة النطاق من المنشورات الطبية الحيوية وضبط LLaMA2 من خلال التدريب المسبق الخاضع للإشراف الذاتي، مما يتيح لـ Y-Mol الحصول على فهم أساسي لخلفية المعرفة المتعلقة بتطوير الأدوية.ثم،يتم الإشراف على LLaMA2 وضبطه بشكل أكبر باستخدام المعرفة المتعلقة بالأدوية والبيانات الاصطناعية المتخصصة. تقوم هذه العملية بإدخال كمية كبيرة من المعلومات المتعلقة بالدواء في Y-Mol، مما يعزز فهم النموذج لآليات التفاعل في عملية تطوير الدواء.
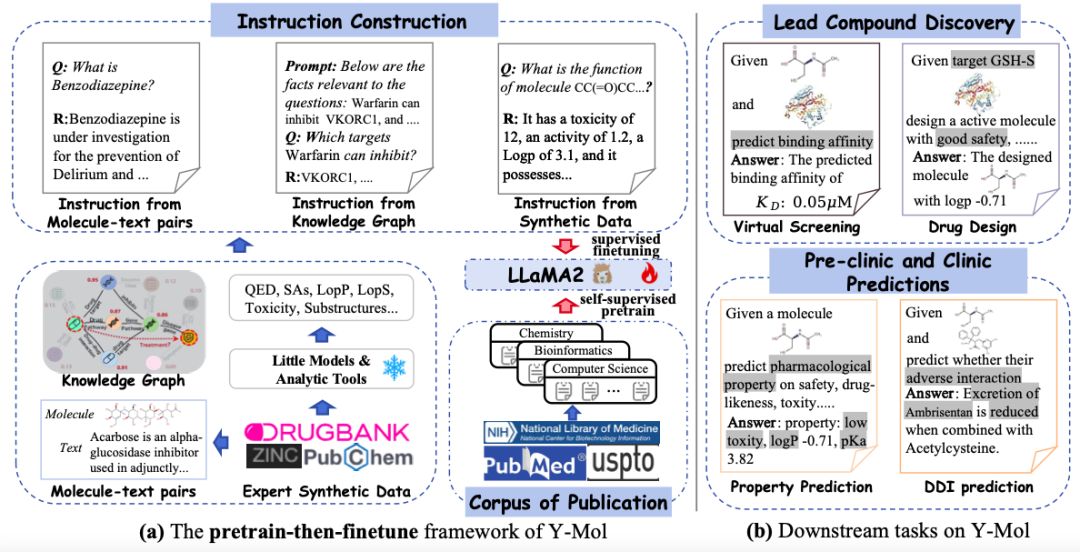
صممت الدراسة بعناية مجموعة متنوعة من التعليمات وضبطت Y-Mol. تضمنت هذه التعليمات تعليمات من أزواج النصوص الجزيئية والأوصاف المستخرجة من قواعد بيانات الأدوية. تقدم هذه الأوصاف خصائص الأدوية وبنيتها ووظيفتها باللغة الطبيعية وتحتوي على معلومات دلالية غنية، مما يساعد على تعزيز الاتساق بين البشر ونماذج اللغة الكبيرة في إدراك كيانات الأدوية.
كما هو موضح في الشكل أدناه، تستخدم هذه الدراسة التعليمات المولدة كمدخلات للتعلم الخاضع للإشراف وتغذيتها في Y-Mol. على وجه التحديد، يتم إدخال سياقات الأسئلة المصممة في Y-Mol، ويتم استخدام هذه الإجابات المصممة للإشراف على المخرجات التي يولدها النموذج.
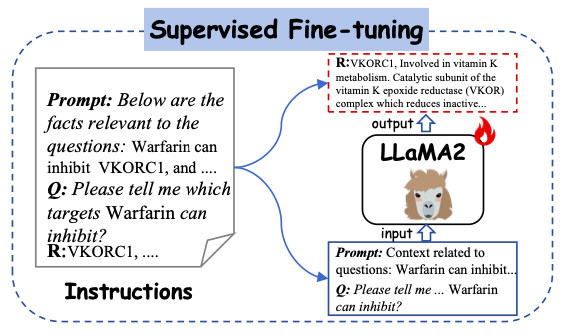
بعد ضبط Y-Mol بعناية استنادًا إلى هذه التعليمات المولدة، قام الباحثون بتطبيقه على مجموعة من المهام اللاحقة، والتي تغطي روابط متعددة من اكتشاف المركب الرئيسي إلى التنبؤات السريرية وما قبل السريرية. ومن خلال طريقة الضبط الدقيق الخاضعة للإشراف هذه، يمكن لشركة Y-Mol فهم ومعالجة المشكلات المعقدة في تطوير الأدوية بشكل أكثر دقة، مما يوفر أداة قوية لتطوير الأدوية بمساعدة الكمبيوتر.
نتائج البحث: يتمتع Y-Mol بأفضل أداء للتنبؤ
ومن أجل التحقق الكامل من فعالية Y-Mol في مجال البحث والتطوير الدوائي، صممت الدراسة بعناية سلسلة من المهام تغطي مراحل مختلفة مثل اكتشاف المركب الرئيسي والبحث ما قبل السريري والتنبؤات السريرية.وعلى وجه التحديد، فإن المهام الرئيسية المختلفة هي كما يلي: (1) الفحص الافتراضي وتصميم الدواء لاكتشاف المركب الرئيسي؛ (2) التنبؤ بالخصائص الفيزيائية والكيميائية للمركبات الرصاصية المكتشفة في المرحلة ما قبل السريرية؛ (3) التنبؤ بالأحداث الضارة المحتملة للأدوية في المرحلة السريرية.
في الفحص الافتراضي،يعد تحديد أزواج التفاعل غير المعروفة بين الدواء والهدف أمرًا بالغ الأهمية. كما هو موضح في الجدول أدناه، بالمقارنة مع LLaMA2، تم تحسين درجات AUC لـ Y-Mol على مجموعات بيانات DrugBank وDrugCentral بمقدار 5.02% و4.13% على التوالي. يشير هذا إلى أن Y-Mol يعمل بشكل جيد في التنبؤ بـ DTI لمصادر البيانات متعددة المقاييس، مما يدل على أدائه المتفوق في الفحص الافتراضي.
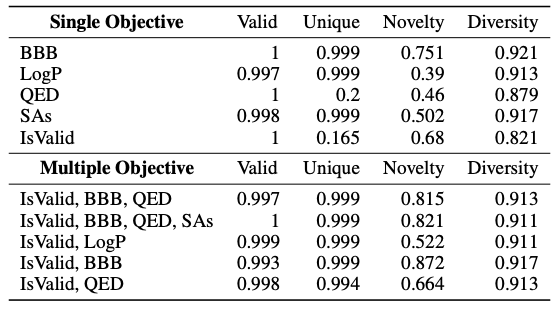
في تصميم الأدوية،ومن أجل التحقق من أداء Y-Mol في اكتشاف مركبات الرصاص الجديدة، صممت الدراسة أيضًا مهمة لإنتاج مركبات فعالة في ظل ظروف محددة. وهذا يعني أنه بالنظر إلى حالة الهدف والاستعلام الوصفي، فإنه يقوم بتقييم ما إذا كان Y-Mol قادرًا على توليد جزيئات تسلسل SMILES المقابلة بدقة من معلومات السياق.
كما هو موضح في الجدول أدناه، قدمت هذه الدراسة مؤشرات قياسية مثل الصالحية والفريدة والحداثة والتنوع للتنبؤ بأهداف فردية مختلفة مثل BBB وLogP. وأظهرت النتائج أن أداء Y-Mol بشكل عام كان أفضل. وبالمقارنة، فإن قدرة التكيف المجالية لنموذج LLaMA2-7b فقط كانت ضعيفة الأداء ولم تتمكن من توليد جزيئات فعالة. وفي الوقت نفسه، اختبرت الدراسة أيضًا أداء تصميم الدواء لـ Y-Mol في ظل أهداف متعددة. وأظهرت النتائج أن Y-Mol أظهر أداءً جيدًا أيضًا في هذه الحالة.
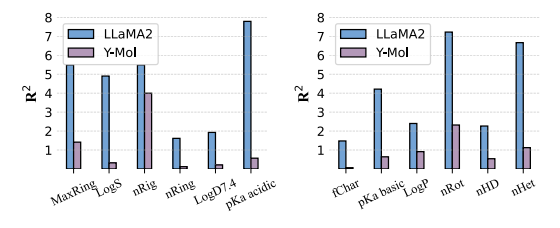
في التنبؤ بالخصائص الجزيئية،كما هو موضح في الشكل أدناه، يظهر Y-Mol درجات R² أقل من LLaMA2 في جميع المهام، مما يشير إلى أن Y-Mol لديه قدرة تعميم أقوى في التنبؤ بالخصائص الفيزيائية والكيميائية.
خلال المرحلة السريرية لتطوير الدواء، يعد التنبؤ بالتفاعلات المحتملة بين الأدوية أمرًا أساسيًا لضمان الاستخدام الآمن للدواء.كما هو موضح في الشكل أدناه، يعمل Y-Mol بشكل جيد في مهمة تحديد التفاعلات الدوائية المحتملة (DDIs).
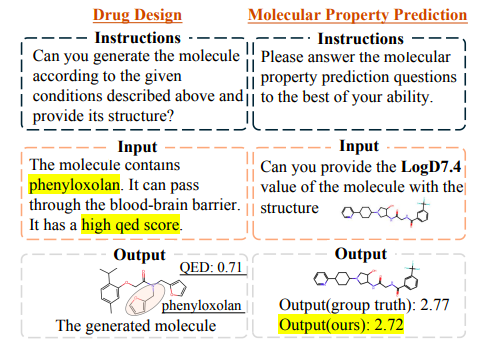
كما هو موضح في الشكل أدناه،إن الأدوية التي صممتها شركة Y-Mol تلبي بشكل فعال القيود التي طرحها الاستفسار. وبالمثل، يمكن لـ Y-Mol التنبؤ بدقة بـ LogD7.4 لجزيء معين، والنتيجة المتوقعة قريبة جدًا من القيمة الفعلية.وهذا يوضح فعالية Y-Mol في حل مهام تطوير الأدوية.
تكنولوجيا الذكاء الاصطناعي: محرك جديد في تطوير الأدوية
في الواقع، خلال الرحلة الطويلة لتطوير الأدوية، كان العلماء يبحثون عن تقنيات جديدة يمكنها تسريع العملية. وفي السنوات الأخيرة، أظهرت تقنيات الذكاء الاصطناعي إمكانات تطبيقية كبيرة في هذا المجال. إنهم لا يستطيعون فقط فهم آليات المرض بشكل عميق، بل يلعبون أيضًا دورًا مهمًا في المراحل الرئيسية مثل اكتشاف الأدوية والتجارب السريرية.
في عالم الأعمال،وقد حققت بعض الشركات نتائج ملحوظة في تطوير الأدوية باستخدام الذكاء الاصطناعي. على سبيل المثال، أعلنت شركة تطوير الأدوية القائمة على الذكاء الاصطناعي Insilico Medicine في وقت سابق من هذا العام أنها اكتشفت دواءً سريريًا جديدًا مرشحًا بآلية جديدة لعلاج التليف الرئوي مجهول السبب، والذي تم التحقق منه في العديد من التجارب على الخلايا البشرية ونماذج الحيوانات. بالإضافة إلى ذلك، تعاونت شركة هواوي كلاود مع معهد شنغهاي للمواد الطبية، التابع للأكاديمية الصينية للعلوم، لإطلاق نموذج جزيء الدواء بانجو، والذي يمكنه تحقيق تصميم الأدوية بمساعدة الذكاء الاصطناعي لكامل عملية الأدوية الجزيئية الصغيرة وتحسين كفاءة ودقة البحث والتطوير الدوائي.
وفي مجال البحث العلمي،كما قام أحد مؤلفي هذه الدراسة، وهو فريق البروفيسور زينج شيانجشيانج في جامعة هونان، بتصميم نموذج لغوي كبير لتسلسلات الببتيد، وقام بتدريب النموذج عن طريق إضافة شروط الحساب والفحص تدريجيًا. في غضون ثلاثة أشهر فقط، نجح النموذج في تصميم وتوليف 29 ببتيدًا مضادًا للميكروبات، أظهر 26 منها نشاطًا مضادًا للميكروبات واسع النطاق. وفي التجارب التي أجريت على الفئران، أظهرت ثلاثة ببتيدات مضادة للميكروبات تأثيرات مضادة للبكتيريا مماثلة للمضادات الحيوية المعتمدة من قبل إدارة الغذاء والدواء، ولم يتم ملاحظة أي مقاومة واضحة للأدوية أثناء الثقافة المستمرة والمراقبة لمدة تصل إلى 25 يومًا. وقد تم قبول هذه النتيجة رسميًا من قبل Nature Communications.
رابط الورقة:
https://www.nature.com/articles/s41467-024-51933-2
بالإضافة إلى ذلك، قام مؤلف آخر لهذه الدراسة، البروفيسور كاو دونغ شنغ من جامعة سنترال ساوث، بالتعاون مع البروفيسور هو تينغجون والبروفيسور شيه تشانغيو من جامعة تشجيانغ، بتطوير أداة التحسين الجزيئي Prompt-MolOpt مؤخرًا. تستخدم الخوارزمية استراتيجية تدريب التعلم السريع لتحقيق تطبيق التعلم بدون طلقة والتعلم بعدد قليل من اللقطات في تحسين الخصائص المتعددة.
رابط الورقة:
https://www.nature.com/articles/s42256-024-00916-5
من الفهم العميق لآليات المرض إلى تسريع اكتشاف الأدوية وتحسين تصميم التجارب السريرية، أصبحت تقنية الذكاء الاصطناعي محركًا جديدًا لأبحاث وتطوير الأدوية. ومع استمرار التقدم التكنولوجي، فإنه سيلعب دورا متزايد الأهمية في الأبحاث الطبية المستقبلية.









