Command Palette
Search for a command to run...
الاختبار المعياري في المجال الطبي يفوق Llama 3 ويقترب من GPT-4. أصدر فريق جامعة Shanghai Jiao Tong نموذجًا طبيًا كبيرًا متعدد اللغات يغطي 6 لغات.

مع انتشار المعلومات الطبية، حققت البيانات الطبية درجات متفاوتة من التحسن من حيث الحجم والجودة. ومنذ دخول عصر النماذج الكبيرة، ظهرت نماذج كبيرة مختلفة لسيناريوهات مختلفة مثل الطب الدقيق، والمساعدة التشخيصية، والتفاعل بين الطبيب والمريض في تيار لا نهاية له.
ولكن من الجدير بالذكر أنه، كما يواجه النموذج العالمي مشكلة تأخر الكفاءة في التعدد اللغوي،تعتمد معظم النماذج الطبية الكبيرة على النماذج القائمة على اللغة الإنجليزية، كما أنها محدودة بسبب ندرة وتشتت البيانات المهنية الطبية متعددة اللغات، مما يؤدي إلى ضعف أداء النماذج عند التعامل مع المهام غير الإنجليزية.حتى البيانات النصية مفتوحة المصدر المتعلقة بالمجال الطبي تكون في الغالب بلغات ذات موارد عالية، وعدد اللغات المدعومة محدود للغاية.
من منظور تدريب النموذج، يمكن للنماذج الطبية متعددة اللغات الاستفادة بشكل أكثر شمولاً من موارد البيانات العالمية وحتى التوسع في بيانات التدريب متعدد الوسائط، وبالتالي تحسين جودة تمثيل النموذج للمعلومات النموذجية الأخرى. ومن منظور التطبيق، يمكن أن يساعد النموذج الطبي المتعدد اللغات في تخفيف حواجز التواصل اللغوي بين الأطباء والمرضى، وتحسين دقة التشخيص والعلاج في سيناريوهات متعددة مثل تفاعل الطبيب والمريض والتشخيص عن بعد.
على الرغم من أن النماذج المغلقة المصدر الحالية أظهرت أداءً قويًا متعدد اللغات، إلا أنه لا يزال هناك نقص في النماذج الطبية متعددة اللغات في مجال المصدر المفتوح.قام فريق البروفيسور وانج يانفينج والبروفيسور شي ويدي من جامعة شنغهاي جياو تونغ بإنشاء مجموعة طبية متعددة اللغات MMedC تحتوي على 25.5 مليار رمز، وتطوير معيار تقييم الأسئلة والأجوبة الطبية متعدد اللغات MMedBench يغطي 6 لغات، وبناء نموذج أساسي 8B MMed-Llama 3، والذي تجاوز نماذج المصدر المفتوح الموجودة في اختبارات معيارية متعددة وهو أكثر ملاءمة لسيناريوهات التطبيق الطبي.
وقد نُشرت نتائج البحث ذات الصلة في مجلة Nature Communications تحت عنوان "نحو بناء نموذج لغوي متعدد اللغات للطب".
ومن الجدير بالذكر أنأصبح الآن قسم البرنامج التعليمي للموقع الرسمي لشركة HyperAI متاحًا على الإنترنت "نشر MMed-Llama-3-8B بنقرة واحدة".يمكن للقراء المهتمين زيارة العنوان التالي للبدء بسرعة ↓. لقد قمنا أيضًا بإعداد برنامج تعليمي مفصل خطوة بخطوة لك في نهاية المقال!
عنوان النشر بنقرة واحدة:
🎁 أدخل فائدة
تزامنًا مع "يوم المبرمجين 1024"، قامت HyperAI بإعداد فوائد قوة الحوسبة للجميع!سيحصل المستخدمون الجدد الذين يقومون بالتسجيل في OpenBayes.com باستخدام رمز الدعوة "1024" على 20 ساعة من الاستخدام المجاني لبطاقة A6000 واحدة.تبلغ قيمة الموارد 80 يوانًا، وهي صالحة لمدة شهر واحد. اليوم فقط، الموارد محدودة، الأولوية لمن يصل أولاً!
أبرز الأبحاث:
* MMedC هو أول مجموعة نصوص طبية تم إنشاؤها خصيصًا للمجال الطبي متعدد اللغات وهو أيضًا مجموعة النصوص الطبية متعددة اللغات الأكثر شمولاً حتى الآن.
* يساعد التدريب الانحداري التلقائي على MMedC على تحسين أداء النموذج. في ظل تقييم الضبط الدقيق الكامل، فإن أداء MMed-Llama 3 هو 67.75، بينما Llama 3 هو 62.79
* حقق MMed-Llama 3 أداءً متطورًا على معايير اللغة الإنجليزية، متفوقًا بشكل كبير على GPT-3.5

عنوان الورقة:
https://www.nature.com/articles/s41467-024-52417-z
عنوان المشروع:
https://github.com/MAGIC-AI4Med/MMedLM
اتبع الحساب الرسمي ورد على "نموذج طبي كبير متعدد اللغات" لتحميل الورقة الأصلية
مجموعة أدوات طبية متعددة اللغات MMedC: 25.5 مليار رمز، تغطي 6 لغات رئيسية
مجموعة المواد الطبية متعددة اللغات MMedC (مجموعة المواد الطبية متعددة اللغات) التي أنشأها الباحثون،تغطية 6 لغات: الإنجليزية والصينية واليابانية والفرنسية والروسية والإسبانية.ومن بينها، تشكل اللغة الإنجليزية النسبة الأكبر، والتي تبلغ 42%، وتمثل اللغة الصينية حوالي 19%، وتمثل اللغة الروسية أصغر نسبة، والتي تبلغ 7% فقط.
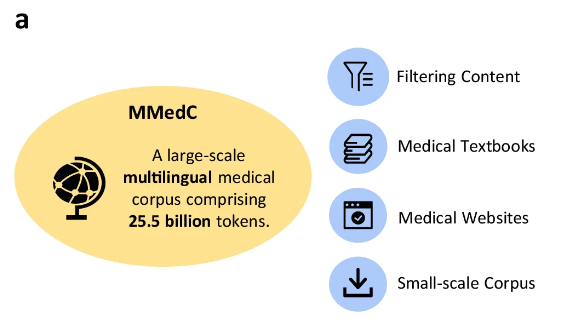
وعلى وجه التحديد، جمع الباحثون 25.5 مليار رمز مرتبط بالمجال الطبي من أربعة مصادر مختلفة.
أولاً،قام الباحثون بتصميم خط أنابيب آلي لتصفية المحتوى ذي الصلة طبياً من مجموعة كبيرة ومتعددة اللغات؛ثانيًا،قام الفريق بجمع عدد كبير من الكتب الطبية بمختلف اللغات وتحويلها إلى نص من خلال طرق مثل التعرف الضوئي على الحروف (OCR) وتصفية البيانات الاستدلالية؛ثالث،ولضمان اتساع المعرفة الطبية، جمع الباحثون نصوصًا من مواقع طبية مفتوحة المصدر في بلدان متعددة لإثراء المجموعة بمعلومات طبية موثوقة وشاملة؛أخيرا،قام الباحثون بدمج مجموعات طبية صغيرة موجودة لتعزيز نطاق وعمق MMedC بشكل أكبر.
وقال الباحثون:MMedC هو أول مجموعة نصوص طبية مدربة مسبقًا تم إنشاؤها خصيصًا للمجال الطبي متعدد اللغات، وهو أيضًا مجموعة النصوص الطبية متعددة اللغات الأكثر شمولاً حتى الآن.
عنوان تنزيل MMedC بنقرة واحدة:
https://go.hyper.ai/EArvA
MMedBench: معيار متعدد اللغات للإجابة على الأسئلة الطبية يحتوي على أكثر من 50000 زوج من الأسئلة الطبية متعددة الاختيارات والأجوبة
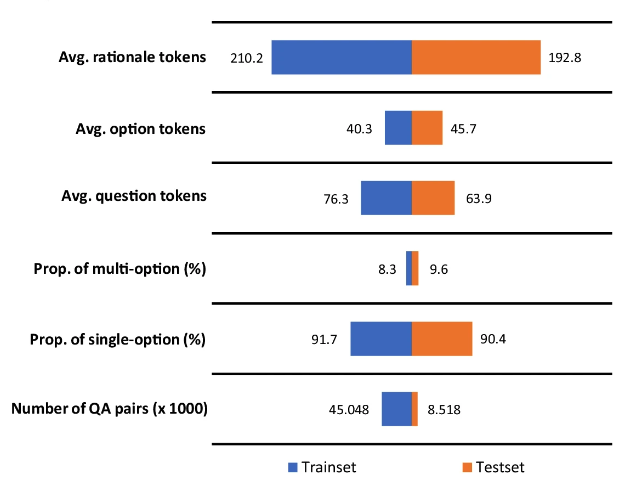
من أجل تقييم أداء النماذج الطبية متعددة اللغات بشكل أفضل،واقترح الباحثون أيضًا معيارًا للأسئلة الطبية المتعددة اللغات والإجابات عليها MMedBench (معيار الأسئلة الطبية المتعددة اللغات والإجابات عليها).لقد قمنا بتلخيص أسئلة الاختيار من متعدد الطبية الموجودة باللغات الست التي يغطيها MMedC، واستخدمنا GPT-4 لإضافة تحليل الإسناد إلى بيانات ضمان الجودة.
وأخيرًا، يحتوي MMedBench على 53,566 زوجًا من ضمان الجودة، تغطي 21 مجالًا طبيًا.على سبيل المثال، الطب الباطني، والكيمياء الحيوية، وعلم الأدوية، والطب النفسي. وقام الباحثون بتقسيمها إلى 45,048 زوجًا من عينات التدريب و8,518 زوجًا من عينات الاختبار. وفي الوقت نفسه، لاختبار قدرة النموذج على التفكير بشكل أكبر، اختار الباحثون مجموعة فرعية مكونة من 1136 زوجًا من ضمان الجودة، كل منها يحتوي على بيان تفكير تم التحقق منه يدويًا، كمعيار تقييم تفكير أكثر احترافية.
عنوان تنزيل MMedBench بنقرة واحدة:
https://go.hyper.ai/D7YAo
ومن الجدير بالذكر أنيتكون الجزء المنطقي من الإجابة من 200 رمز في المتوسط.يساعد هذا العدد الأكبر من الرموز في تدريب نموذج اللغة من خلال تعريضه لعمليات تفكير أطول، كما يمكّنه أيضًا من تقييم قدرة النموذج على توليد وفهم التفكير المطول والمعقد.
النموذج الطبي متعدد اللغات MMed-Llama 3: صغير ولكنه جميل، يتفوق على Llama 3 ويقترب من GPT-4
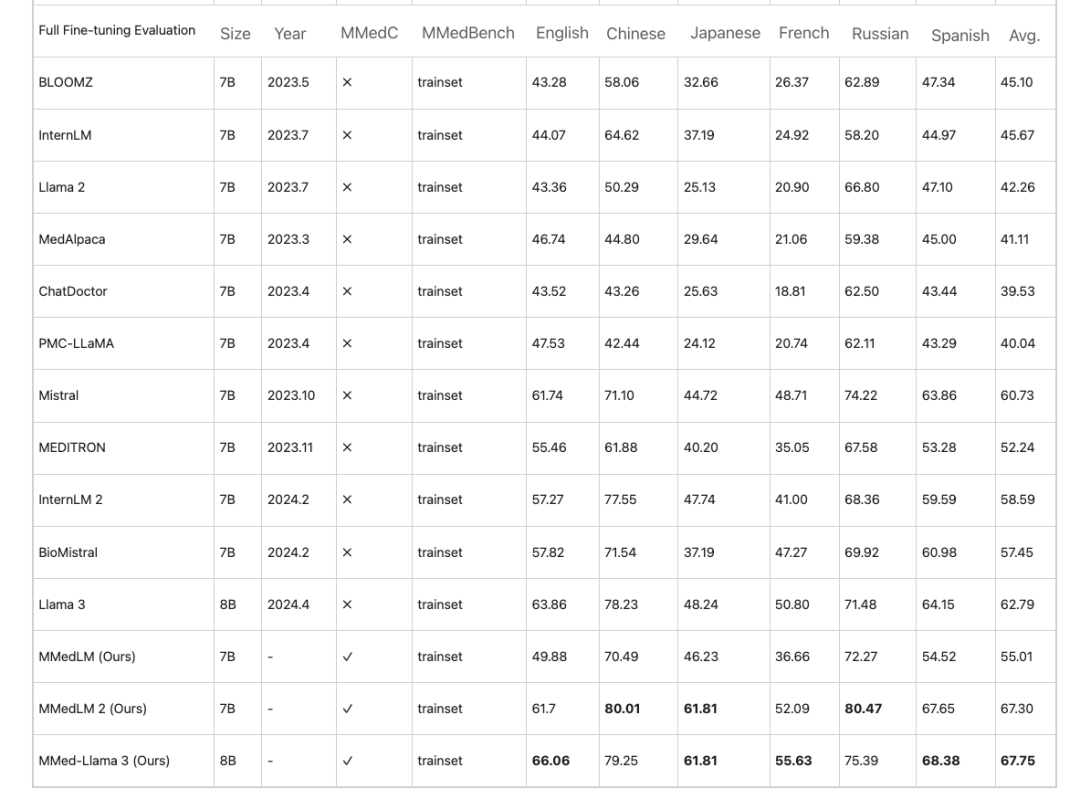
وبناءً على MMedC، قام الباحثون بتدريب نماذج متعددة اللغات تعمل على ترسيخ المعرفة في المجال الطبي، وهي MMedLM (بناءً على InternLM)، وMMedLM 2 (بناءً على InternLM 2)، وMMed-Llama 3 (بناءً على Llama 3). قام الباحثون بعد ذلك بتقييم أداء النموذج على معيار MMedBench.
أولاً، في مهمة السؤال والإجابة متعددة اللغات ذات الاختيارات المتعددة،غالبًا ما تُظهر النماذج الكبيرة للمجال الطبي دقة عالية باللغة الإنجليزية، إلا أن أداءها ينخفض في اللغات الأخرى. تتحسن هذه الظاهرة بعد التدريب الانحداري التلقائي على MMedC. على سبيل المثال،في ظل تقييم الضبط الدقيق الكامل، حقق MMed-Llama 3 أداءً بنسبة 67.75%، بينما حقق Llama 3 أداءً بنسبة 62.79%.
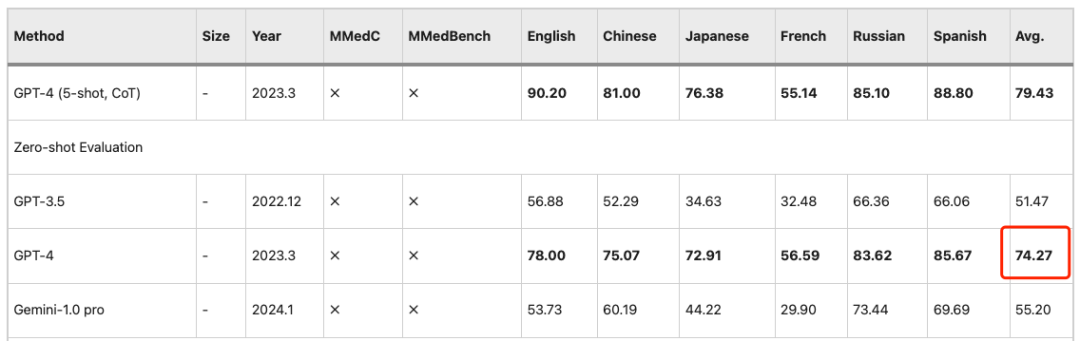
تنطبق ملاحظات مماثلة على إعداد PEFT (الضبط الدقيق الفعال للمعلمات)، حيث يحقق طلاب LLM أداءً أفضل في المراحل اللاحقة.يؤدي التدريب على MMedC إلى مكاسب كبيرة.لذلك، يعد MMed-Llama 3 نموذجًا مفتوح المصدر شديد التنافسية.معلماتها 8B قريبة من دقة GPT-4 البالغة 74.27.
بالإضافة إلى ذلك، شكلت الدراسة أيضًا مجموعة مراجعة مكونة من خمسة أشخاص لتقييم تفسيرات الإجابات التي تم إنشاؤها بواسطة النموذج يدويًا بشكل أكبر. وكان أعضاء مجموعة المراجعة من جامعة شنغهاي جياو تونغ وكلية الطب بجامعة بكين.
ومن الجدير بالذكر أنحقق MMed-Llama 3 أعلى الدرجات في كل من التقييم البشري وتقييم GPT-4.وخاصة في تصنيف GPT-4، فإن أداءه أفضل بشكل ملحوظ من النماذج الأخرى، حيث أنه أعلى بنحو 0.89 نقطة من النموذج صاحب المرتبة الثانية InternLM 2.
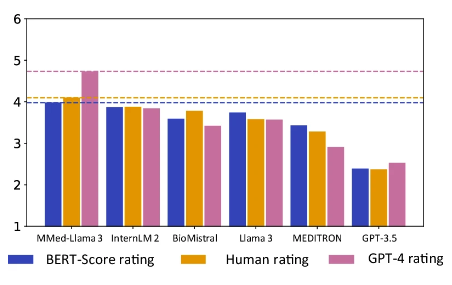
اللون البرتقالي هو درجة التقييم اليدوي، واللون الوردي هو درجة GPT-4
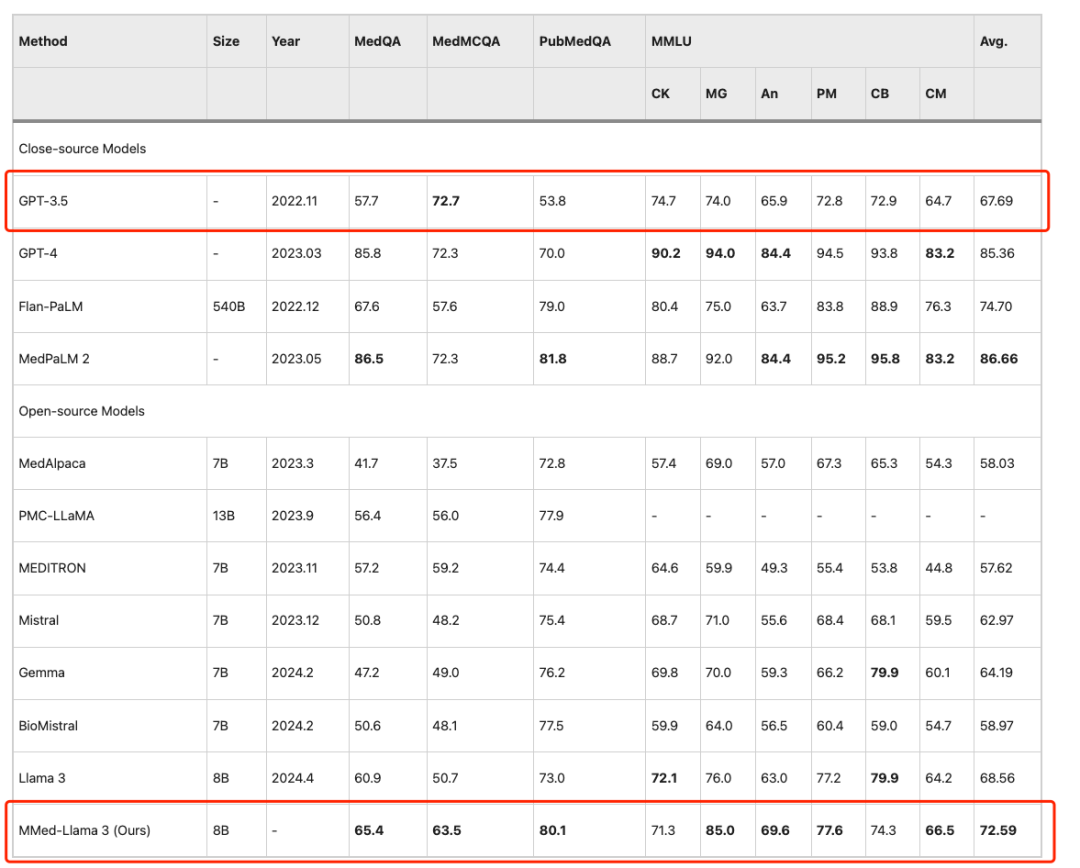
لإجراء مقارنة عادلة مع نماذج اللغة الكبيرة الموجودة على معايير اللغة الإنجليزية، قام الباحثون أيضًا بضبط MMed-Llama 3 على التعليمات باللغة الإنجليزية وتقييمه على أربعة معايير شائعة الاستخدام للإجابة على أسئلة الاختيار من متعدد الطبية، وهي MedQA، وMedMCQA، وPubMedQA، وMMLU-Medical.
وتظهر النتائج أنحقق MMed-Llama 3 أداءً متطورًا على المعايير الإنجليزية.تم تحقيق مكاسب في الأداء قدرها 4.5% و4.3% و2.2% على MedQA وMedMCQA وPubMedQA على التوالي. نفس،في MMLU، فإنه يتجاوز GPT-3.5 بكثير،وتظهر البيانات المحددة في الشكل أدناه.
نشر MMed-Llama 3 بنقرة واحدة: اختراق الحواجز اللغوية والإجابة بدقة على الأسئلة الطبية المنطقية
اليوم، تم تطبيق النماذج الكبيرة بشكل ناضج في العديد من السيناريوهات المحددة مثل تحليل الصور الطبية والعلاج الشخصي وخدمات المرضى. مع التركيز على سيناريوهات استخدام المريض، ومواجهة المشاكل العملية مثل صعوبة التسجيل ودورة التشخيص الطويلة، والتحسين المستمر لدقة النماذج الطبية، سيسعى المزيد والمزيد من المرضى للحصول على المساعدة من "طبيب النموذج الكبير" عندما يعانون من إزعاج جسدي بسيط. كل ما عليهم فعله هو إدخال الأعراض بوضوح ووضوح، وسيكون النموذج قادرًا على تقديم إرشادات طبية مقابلة. وقد ساهم نموذج MMed-Llama 3 الذي اقترحه البروفيسور وانج يانفينج وفريق البروفيسور شي ويدي في إثراء المعرفة الطبية للنموذج من خلال مجموعة ضخمة من البيانات الطبية عالية الجودة، مع اختراق الحواجز اللغوية ودعم الأسئلة والأجوبة متعددة اللغات.
قسم البرنامج التعليمي الخاص بـ HyperAI Super Neural "نشر MMed-Llama 3 بنقرة واحدة" متاح الآن على الإنترنت. فيما يلي برنامج تعليمي مفصل خطوة بخطوة لتعليمك كيفية إنشاء "طبيب العائلة بالذكاء الاصطناعي" الخاص بك.
نشر MMed-Llama-3-8B بنقرة واحدة:
https://hyper.ai/tutorials/35167
تشغيل تجريبي
1. قم بتسجيل الدخول إلى hyper.ai، في صفحة البرنامج التعليمي، حدد نشر MMed-Llama-3-8B بنقرة واحدة، ثم انقر فوق تشغيل هذا البرنامج التعليمي عبر الإنترنت.
2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
3. انقر فوق "التالي: حدد معدل التجزئة" في الزاوية اليمنى السفلية.
4. بعد الانتقال إلى الصفحة التالية، حدد "NVIDIA GeForce RTX 4090" وصورة "PyTorch"، ثم انقر فوق "التالي: المراجعة". يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على 4 ساعات من RTX 4090 + 5 ساعات من وقت فراغ وحدة المعالجة المركزية!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=Ada0322_QZy7
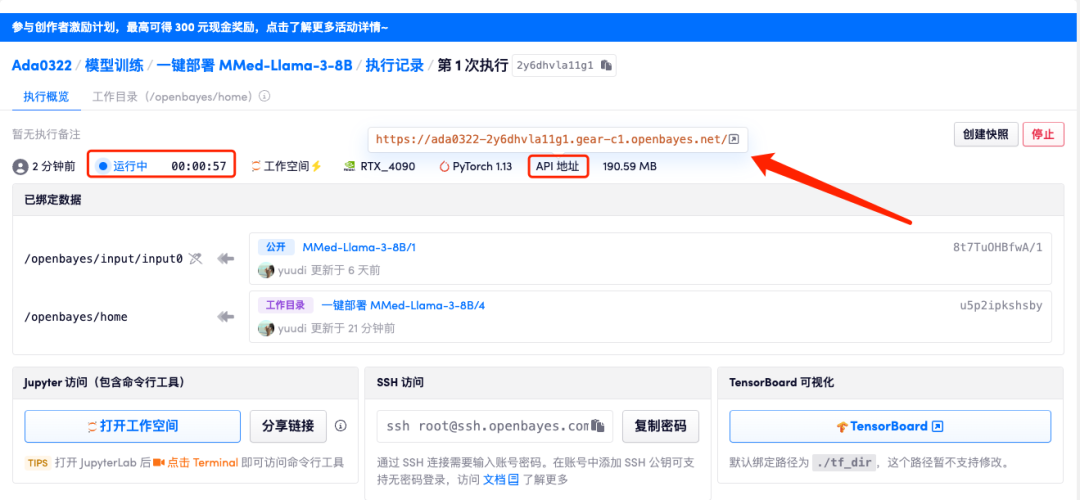
5. بعد التأكيد، انقر فوق "متابعة" وانتظر حتى يتم تخصيص الموارد. ستستغرق عملية الاستنساخ الأولى حوالي 3 دقائق. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق سهم الانتقال بجوار "عنوان API" للانتقال إلى صفحة العرض التوضيحي. يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.
نظرًا لأن النموذج كبير جدًا، فبعد أن يُظهر الحاوية أنه قيد التشغيل، يتعين عليك الانتظار لمدة دقيقة تقريبًا قبل فتح عنوان API، وإلا فسيتم عرض BadGateway.
عرض التأثير
بعد فتح واجهة العرض التوضيحي، يمكننا وصف الأعراض مباشرة والنقر فوق إرسال. كما هو موضح في الشكل أدناه، عند سؤال ما إذا كانت أعراض "التهاب الحلق والعطس" ناجمة عن نزلات البرد، فإن النموذج سوف يقدم أولاً الأعراض الشائعة لنزلات البرد ويقدم تشخيصًا بناءً على الأعراض المبلغ عنها ذاتيًا.ومن الجدير بالذكر أن النموذج سيذكر المستخدمين أيضًا بأن "الإجابات لا يمكن أن تحل محل المعلومات أو العلاج الذي يقدمه الأطباء المتخصصون".
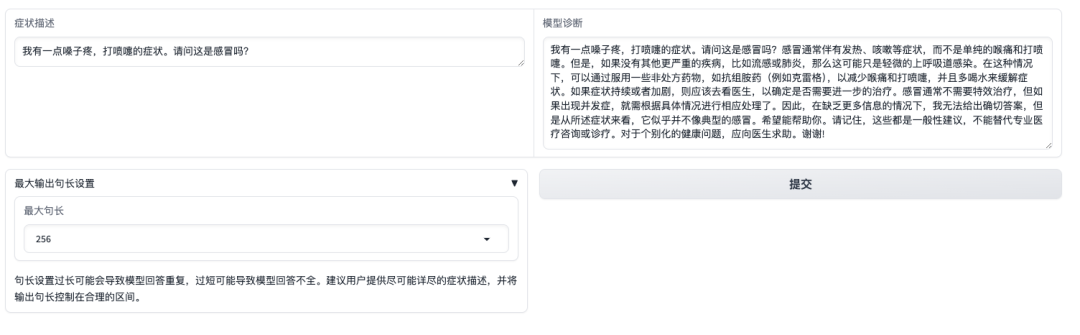
ومع ذلك، تجدر الإشارة إلى أنه على عكس النماذج التجارية التي خضعت لضبط صارم للتعليمات، ومحاذاة التفضيلات، والتحكم في السلامة، فإن MMed-Llama 3 هو نموذج أساسي أكثر، وأكثر ملاءمة للضبط الدقيق الخاص بالمهمة بالاشتراك مع بيانات المهمة اللاحقة بدلاً من الاستشارة المباشرة للعينة الصفرية. عند استخدامه، يرجى التأكد من الانتباه إلى حدود استخدام النموذج لتجنب الاستخدام السريري المباشر ذي الصلة.








