Command Palette
Search for a command to run...
تم إطلاق أداة معالجة البيانات مفتوحة المصدر 10k Star بنقرة واحدة! يدعم التعرف على 176 لغة؛ أول مجموعة بيانات لكشف الأجسام الساقطة من ناطحات السحاب متاحة على الإنترنت، وتتضمن ما يقرب من 2000 مقطع فيديو في 18 مشهدًا

في مجال الذكاء الاصطناعي، كانت معالجة البيانات متعددة الوسائط دائمًا مشكلة صعبة. في مواجهة ملفات PDF المعقدة وصفحات الويب والكتب الإلكترونية بتنسيقات متعددة، ليس من السهل استخراج المعلومات الرئيسية بشكل فعال.
أطلق مختبر شنغهاي للذكاء الاصطناعي وفريق OpenDataLab أداة استخراج بيانات ذكية مفتوحة المصدر - MinerU، والتي يمكنها تحويل مستندات PDF متعددة الوسائط تحتوي على عناصر مثل الصور والصيغ والجداول وما إلى ذلك إلى تنسيق Markdown سهل التحليل. كما أنه يدعم استخراج المحتوى من صفحات الويب والكتب الإلكترونية، مما يحل الحاجة إلى استخراج البيانات عالية الجودة تلقائيًا من المستندات المعقدة.
أطلق الموقع الرسمي لـ hyper.ai النسخة التجريبية من "أداة استخراج البيانات الشاملة MinerU".قم بالتمرير لأسفل للحصول على الرابط~
من 26 أغسطس إلى 30 أغسطس، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* مجموعات البيانات العامة عالية الجودة: 10
* اختيار المقالات المجتمعية: 3 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في سبتمبر: 7
قم بزيارة الموقع الرسمي:هايبر.اي
دروس تعليمية عامة مختارة
1. أداة استخراج البيانات الشاملة MinerU
MinerU هي أداة تقوم بتحويل ملفات PDF إلى تنسيقات قابلة للقراءة آليًا (مثل Markdown وJSON)، والتي يمكن استخراجها بسهولة إلى أي تنسيق، وتدعم التعرف الدقيق على 176 لغة، وتقوم بتحديد نوع اللغة بدقة. لقد تم نشر النموذج والبيئة. يمكنك استخدام النموذج الكبير لتوليد الاستدلال وفقًا لإرشادات البرنامج التعليمي.
الاستخدام المباشر:https://go.hyper.ai/MIitP
2. نشر LongWriter-glm4-9b بنقرة واحدة
LongWriter هو مشروع مفتوح المصدر تم تطويره بواسطة جامعة تسينغهوا والذي يقوم بإنشاء نصوص طويلة جدًا (أكثر من 10000 كلمة) باستخدام نموذج لغة كبير السياق الطويل (LLM). يعد هذا البرنامج التعليمي عرضًا توضيحيًا لنشر النموذج بنقرة واحدة. كل ما عليك فعله هو استنساخ الحاوية وبدء تشغيلها ونسخ عنوان API الناتج مباشرةً لتجربة استنتاج النموذج.
الاستخدام المباشر:https://go.hyper.ai/Xvktt
إن استخدام برامج التدريب البشري الرقمي التقليدية لإنشاء إنسان رقمي عالي الجودة غالبًا ما يتطلب الكثير من الوقت وموارد الحوسبة، كما يتطلب أيضًا متطلبات عالية لمواد التدريب. أدى ظهور MuseV وMuseTalk إلى تحقيق اختراقات جديدة في مجال البشر الرقميين. بعد استخدام MuseV لإنشاء مقاطع فيديو بشرية رقمية، يتم استخدام MuseTalk لمزامنة حركات الشفاه والصوت، ويمكن تحقيق إنتاج بشري رقمي كامل في بضع دقائق فقط. لقد تم تحميلها جميعًا إلى وحدة البرنامج التعليمي العامة الخاصة بـ hyper.ai، ويمكن استنساخها وتشغيلها عبر الإنترنت بنقرة واحدة!
برنامج تعليمي MuseV:https://go.hyper.ai/9fExW
دروس MuseTalk:https://go.hyper.ai/wiw8g
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الكشف عن الأجسام المتساقطة FADE حول المباني
تحتوي مجموعة بيانات FADE على 1,881 مقطع فيديو تغطي 18 مشهدًا، و8 فئات مختلفة من الأجسام المتساقطة، و4 ظروف جوية مختلفة، و4 دقة فيديو. إن تنوع وتخصص مجموعة بيانات FADE يجعلها موردًا قيمًا لدراسة اكتشاف الأجسام المتساقطة حول المباني.
الاستخدام المباشر:https://go.hyper.ai/8u8Sr
2. مجموعة بيانات خوارزمية تخطيط شريحة ChiPBench Al
ChiPBench هو معيار شامل تم تصميمه خصيصًا لتقييم فعالية خوارزميات وضع الشريحة القائمة على الذكاء الاصطناعي في تحسين مقياس PPA للتصميم النهائي. قام فريق البحث بجمع 20 دائرة من مجالات مختلفة (مثل وحدة المعالجة المركزية ووحدة معالجة الرسومات والميكروكنترولر). تسمح هذه التصاميم بتقييم تأثير خوارزمية التنسيب على التصميم النهائي لـ PPA.
الاستخدام المباشر:https://go.hyper.ai/LN4Ab
3. مجموعة بيانات الوجوه البشرية
تحتوي مجموعة البيانات على ما يقرب من 9.6 ألف صورة وجه، منها 5 آلاف صورة وجه حقيقية و4.63 ألف صورة وجه تم إنشاؤها بواسطة الذكاء الاصطناعي.
الاستخدام المباشر:https://go.hyper.ai/N5nVT
4. مجموعة بيانات معيارية للإجابة على أسئلة TableBench
تحتوي مجموعة البيانات على 886 عينة من 18 مجالاً وهي مصممة لتسهيل مهام التحقق من الحقائق والتفكير العددي وتحليل البيانات والتصور.
الاستخدام المباشر:https://go.hyper.ai/Qcs2F
5. مجموعة بيانات التعرف على مقاطع الفيديو لاكتشاف التزييف العميق
تحتوي مجموعة البيانات على أكثر من 363 مقطعًا أصليًا يضم 28 ممثلًا يؤدون 16 مشهدًا مختلفًا. توفر مقاطع الفيديو عالية الجودة هذه أساسًا قويًا لنماذج التدريب على المحتوى الحقيقي. بالإضافة إلى البيانات الأصلية، تحتوي مجموعة البيانات أيضًا على أكثر من 3 آلاف مقطع فيديو تمت معالجته باستخدام طريقة DeepFakes.
الاستخدام المباشر:https://go.hyper.ai/Jw59B
6. تصنيف المركبات مجموعة بيانات تصنيف صور المركبات
تم تصميم مجموعة البيانات هذه لمهمة تصنيف المركبات وتحتوي على 5.6 ألف صورة مقسمة إلى 7 فئات. تمثل كل فئة نوعًا مختلفًا من المركبات (عربة ركشة، دراجة، سيارة، دراجة نارية، طائرة، سفينة، قطار)، وجميع الصور بتنسيق JPEG مع امتداد .jpg. مثالي لبناء واختبار نماذج تصنيف الصور للتمييز بين أنواع المركبات المختلفة.
الاستخدام المباشر:https://go.hyper.ai/e9LNg
7. الكشف على المسارات - مجموعة بيانات الكشف عن السلوك البشري على المسارات
تحتوي مجموعة البيانات على 3766 صورة لأشخاص على مسارات السكك الحديدية بدقة 1080×1080. يتم توضيح كل صورة باستخدام مربعات محيطة تشير إلى وجود البشر وأفعالهم على مسارات السكك الحديدية.
الاستخدام المباشر:https://go.hyper.ai/dsr49
8. مجموعة بيانات تجزئة المشهد السمعي البصري Ref-AVS
تُعد مجموعة بيانات Ref-AVS معيارًا لمهام تقسيم الكائنات في المشاهد السمعية والبصرية. تحتوي مجموعة البيانات على 48 مقطع فيديو لأشياء مسموعة، مصنفة على وجه التحديد إلى: 20 آلة موسيقية، و8 حيوانات، و15 آلة، و5 بشر.
الاستخدام المباشر:https://go.hyper.ai/pGHwm
9. مجموعة بيانات تقسيم الصور الطبية COSMOS 1050K
تتضمن مجموعة البيانات 53 مجموعة بيانات طبية عامة جمعها فريق البحث، وتغطي 18 وسيلة، و84 كائنًا، و1050 ألف صورة ثنائية الأبعاد، و6033 قناعًا.
الاستخدام المباشر:https://go.hyper.ai/nHETv
هذه المجموعة من البيانات هي مجموعة بيانات HUST-OBC عالية الجودة اقترحها وانج بينجي وآخرون من فريق البحث التابع للبروفيسور باي شيانج في جامعة هواتشونغ للعلوم والتكنولوجيا. يتم جمعها من 3 مصادر مختلفة، بما في ذلك الكتب ومواقع الويب ومجموعات البيانات الموجودة. تحتوي مجموعة البيانات على نوعين من صور عينات عظام الأوراكل. أحدها هو صور عظام الوحي التي تم الحصول عليها من عمليات المسح المعالجة لفرك عظام الوحي الأصلية، والآخر هو صور عظام الوحي المكتوبة بخط اليد استنادًا إلى عظام الوحي الأصلية، والتي تنقسم بدورها إلى صور تعتمد على الفرك وصور مكتوبة بخط اليد تعتمد على الحروف الهيروغليفية.
الاستخدام المباشر:https://go.hyper.ai/46AiA
لمزيد من مجموعات البيانات العامة، يرجى زيارة:
مقالات المجتمع
قام فريق جامعة أكسفورد بتطوير نموذج لتجزئة الصور الطبية يسمى Medical SAM 2. تم تصميم النموذج بناءً على إطار عمل SAM 2 ويعامل الصور الطبية كمقاطع فيديو. إنه لا يعمل بشكل جيد في مهام تقسيم الصور الطبية ثلاثية الأبعاد فحسب، بل يفتح أيضًا إمكانية تقسيم جديدة بإشارة واحدة. هذه المقالة عبارة عن تفسير مفصل ومشاركة لورقة البحث.
شاهد التقرير الكامل:https://go.hyper.ai/04VFX
في الحلقة الثانية من سلسلة البث المباشر "Meet AI4S"، شارك لي يوزهي، وهو زميل ما بعد الدكتوراه في مختبر تشانغ تشيانغفينج في كلية علوم الحياة بجامعة تسينغهوا، أحدث نتائج أبحاث الفريق تحت عنوان "استكشاف تطبيقات الذكاء الاصطناعي في علم الجينوم: أخذ خوارزمية توصيف بيانات النسخ المكاني SPACE كمثال". هذه المقالة هي نص خطابه، وهو مليء بالمعلومات العملية.
شاهد التقرير الكامل:https://go.hyper.ai/eRQeT
في مدرسة الذكاء الاصطناعي للهندسة الحيوية الصيفية، شارك البروفيسور هونغ ليانغ من جامعة شنغهاي جياو تونغ بطريقة سهلة الفهم تطبيق الذكاء الاصطناعي في البحث العلمي، وخاصة في تصميم البروتين، تحت عنوان "الذكاء الاصطناعي يدخل الحياة والعلم"، بالإضافة إلى نظرته إلى التطوير المستقبلي للذكاء الاصطناعي من أجل العلم. تتضمن هذه المقالة نصًا لأهم النقاط التي وردت في خطاب البروفيسور هونغ ليانغ.
شاهد التقرير الكامل:https://go.hyper.ai/TWBIk
مقالات موسوعية شعبية
1. دال-إي
2. التقاطع على الاتحاد (IoU)
3. نمذجة اللغة المقنعة (MLM)
4. مجال الإشعاع العصبي (NeRF)
5. دمج الفرز المتبادل RRF
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
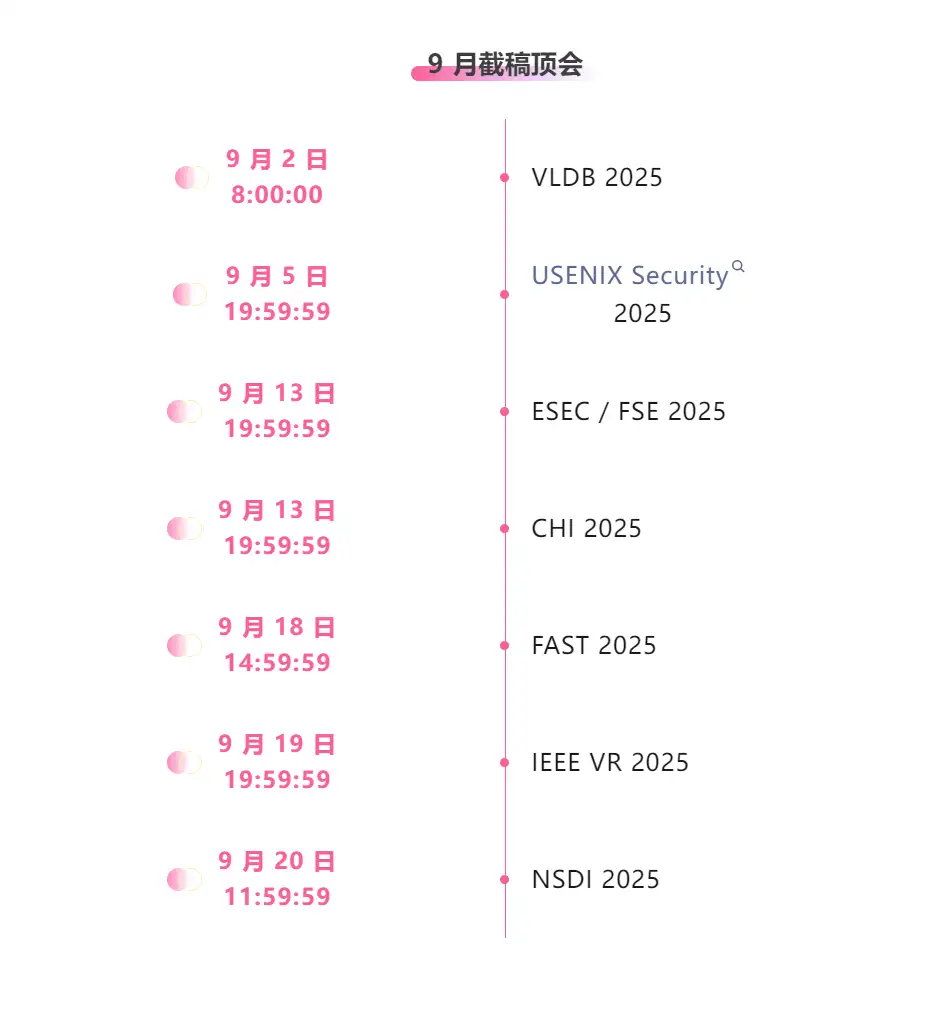
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1300 مجموعة بيانات عامة
* يتضمن أكثر من 400 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 100 حالة بحثية من AI4Science
* دعم البحث عن أكثر من 500 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








