Command Palette
Search for a command to run...
قم بتنزيل Meta، أكبر مجموعة بيانات لتقسيم الفيديو، بنقرة واحدة! يحتوي على 50.9 ألف مقطع فيديو واقعي يغطي 47 دولة

في أبريل 2023، أصدرت Meta نموذج Segment Anything (SAM)، مدعية أنها قادرة على "تجزئة كل شيء". لقد أثار هذا الإنجاز المبتكر الذي يقلب مهام الرؤية الحاسوبية التقليدية نقاشًا واسع النطاق في الصناعة وتم تطبيقه بسرعة في الأبحاث في المجالات الرأسية مثل تقسيم الصور الطبية. لقد تم ترقية SAM مرة أخرى مؤخرًا.أطلقت شركة Meta نموذج Segment Anything Model 2 (SAM 2) مفتوح المصدر، مما يمثل علامة فارقة أخرى في مجال الرؤية الحاسوبية.
من تقسيم الصورة إلى تقسيم الفيديو،يظهر SAM 2 أداءً متفوقًا في تقسيم الإشارات في الوقت الفعلي.يقدم النموذج وظائف التجزئة والتتبع للصور ومقاطع الفيديو في نموذج موحد. يمكنه التعرف بدقة على أي كائن في صورة أو مقطع فيديو وتقسيمه بمجرد إدخال مطالبة (انقر أو مربع أو قناع) على إطار الفيديو. تمنح هذه القدرة الفريدة على التعلم من خلال العينة الصفرية برنامج SAM 2 قدرًا كبيرًا للغاية من التنوع.ويظهر إمكانات تطبيقية كبيرة في مجالات الطب والاستشعار عن بعد والقيادة الذاتية والروبوتات وكشف الأشياء المموهة وما إلى ذلك. تقول ميتا بثقة: "نعتقد أن بياناتنا ونماذجنا ورؤانا سوف تصبح معلمًا مهمًا في تقسيم الفيديو ومهام الإدراك ذات الصلة!"
هذا صحيح. بمجرد إطلاق SAM 2، لم يستطع الجميع الانتظار لاستخدامه، وكان التأثير لا يصدق!

بعد أقل من أسبوعين من إتاحة SAM 2 كمصدر مفتوح، استخدمه باحثون من جامعة تورنتو على الصور ومقاطع الفيديو الطبية ونشروا بحثًا!

الورق الأصلي:
https://arxiv.org/abs/2408.03322
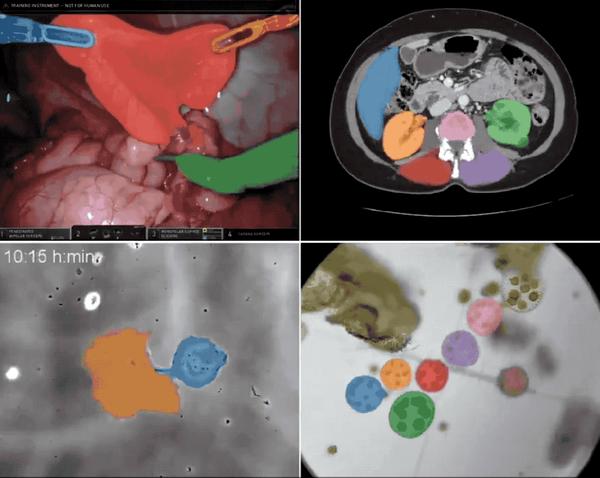
تحتاج النماذج إلى بيانات للتدريب، وSAM 2 ليس استثناءً. وفي الوقت نفسه، قامت Meta أيضًا بفتح المصدر لمجموعة البيانات واسعة النطاق SA-V المستخدمة لتدريب SAM 2.يُقال أنه يمكن استخدام مجموعة البيانات هذه لتدريب واختبار وتقييم نماذج تجزئة الكائنات العامة.أطلقت HyperAI "SA-V: Meta بناء أكبر مجموعة بيانات لتقسيم الفيديو" على موقعها الرسمي، والذي يمكن تنزيله بنقرة واحدة!
التنزيل المباشر لمجموعة بيانات تجزئة الفيديو SA-V:
https://go.hyper.ai/e1Tth
مزيد من مجموعات البيانات عالية الجودة للتنزيل:
https://go.hyper.ai/P5Mtc
ما وراء مجموعات بيانات تقسيم الفيديو الموجودة! يغطي SA-V مواضيع وسيناريوهات متعددة
قام باحثو Meta بجمع مجموعة بيانات كبيرة ومتنوعة لتجزئة الفيديو SA-V باستخدام Data Engine، كما هو موضح في الجدول التالي،تحتوي مجموعة البيانات على 50.9 ألف مقطع فيديو، و642.6 ألف قناع (191 ألف مقطع تم شرحها يدويًا بمساعدة SAM 2، و452 ألف مقطع تم إنشاؤها تلقائيًا بواسطة SAM 2)،بالمقارنة مع مجموعات بيانات تقسيم كائنات الفيديو (VOS) الشائعة الأخرى، فقد نجح SA-V في تحسين عدد مقاطع الفيديو والأقنعة الصغيرة والأقنعة بشكل كبير.يبلغ عدد الأقنعة الموضحة 53 مرة عدد أي مجموعة بيانات VOS موجودة.إنه يوفر مصدر بيانات غنيًا لأعمال الرؤية الحاسوبية المستقبلية.
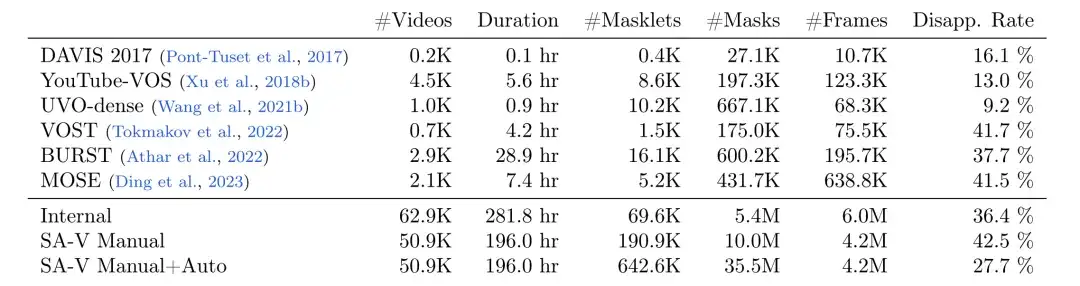
مقارنة بين عدد شظايا القناع، وعدد الأقنعة، وعدد الإطارات، ومعدل الاختفاء
* يحتوي دليل SA-V على ملصقات مُعلقة يدويًا فقط
* يجمع SA-V Manual+Auto بين العلامات الموضحة يدويًا وأجزاء القناع التي تم إنشاؤها تلقائيًا
ومن المفهوم أن عدد مقاطع الفيديو الموجودة في SA-V يتجاوز مجموعة بيانات VOS الحالية، ومتوسط دقة الفيديو هو 1401×1037 بكسل.تغطي مقاطع الفيديو المجمعة مشاهد يومية مختلفة.بما في ذلك 54% من مقاطع الفيديو للمشاهد الداخلية و46% من مقاطع الفيديو للمشاهد الخارجية، بمتوسط طول 14 ثانية. أيضًا،تختلف مواضيع هذه الفيديوهات.بما في ذلك المواقع والأشياء والمشاهد وما إلى ذلك، تتراوح الأقنعة من الأشياء الكبيرة (مثل المباني) إلى التفاصيل الدقيقة (مثل الديكور الداخلي).
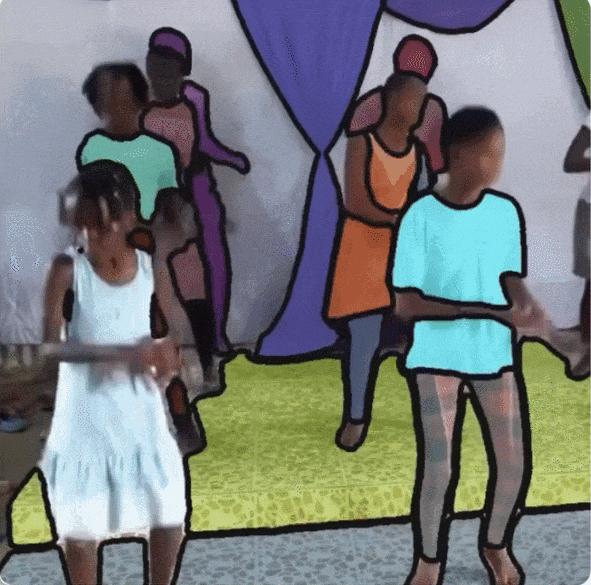
كما هو موضح في الشكل أدناه،تغطي مقاطع الفيديو في SA-V 47 دولة.وبأخذ عينات من المشاركين المختلفين، يمكن ملاحظة من الشكل (أ) أنه بالمقارنة مع توزيع حجم القناع لـ DAVIS وMOSE وYouTubeVOS، فإن مساحة القناع الطبيعية (مساحة القناع الطبيعية) لـ SA-V أقل من 0.1 تتجاوز 88%.
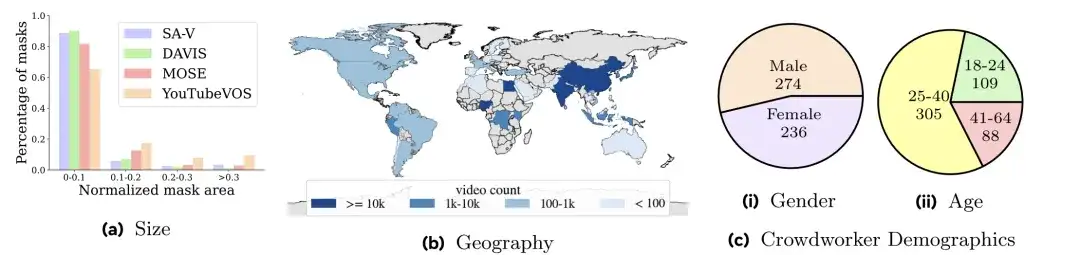
قام الباحثون بتقسيم مجموعة بيانات SA-V استنادًا إلى مؤلفي الفيديو ومواقعهم الجغرافية.تأكد من أن الكائنات المتشابهة في البيانات لها أدنى حد من التداخل.ولإنشاء مجموعات التحقق من صحة SA-V واختبار SA-V، ركز الباحثون على المشاهد الصعبة عند اختيار مقاطع الفيديو، مما يتطلب من المعلقين تحديد الكائنات التي تتحرك بسرعة، أو التي تحجبها كائنات أخرى، أو التي لديها أنماط اختفاء/ظهور. أخيرًا، يوجد 293 قناعًا صغيرًا و155 مقطع فيديو في مجموعة التحقق من صحة SA-V، و278 قناعًا صغيرًا و150 مقطع فيديو في مجموعة اختبار SA-V. بالإضافة إلى ذلك، استخدم الباحثون بيانات الفيديو المرخصة المتوفرة داخليًا لتوسيع مجموعة التدريب بشكل أكبر.
التنزيل المباشر لمجموعة بيانات تجزئة الفيديو SA-V:
https://go.hyper.ai/e1Tth
ما ورد أعلاه هو مجموعات البيانات التي أوصت بها HyperAI في هذا العدد. إذا رأيت مصادر بيانات عالية الجودة، فنحن نرحب بك لترك رسالة أو إرسال مقال لإخبارنا بذلك!
مزيد من مجموعات البيانات عالية الجودة للتنزيل:
https://go.hyper.ai/P5Mtc








