Command Palette
Search for a command to run...
تم اختياره للمؤتمر الرئيسي ACL2024 | InstructProtein: مواءمة لغة البروتين مع اللغة البشرية باستخدام تعليمات المعرفة

باعتباره الأساس لبقاء الخلايا، يوجد البروتين في جميع الكائنات الحية بما في ذلك جسم الإنسان. وهو السقالة والمادة الأساسية التي تشكل الأنسجة والأعضاء، ويلعب دورا أساسيا في التفاعلات الكيميائية الضرورية للحياة.
في مواجهة تعقيد وتنوع بنية البروتين، فإن الطرق التجريبية التقليدية تستغرق وقتًا طويلاً وتتطلب جهدًا في تحليل بنية البروتين. ظهرت نماذج لغة البروتين (PLMs). تستخدم هذه النماذج الاحترافية تسلسلات الأحماض الأمينية كمدخلات ويمكنها التنبؤ بوظائف البروتين وحتى تصميم بروتينات جديدة تمامًا. لكن،على الرغم من أن PLMs رائعة في فهم تسلسل الأحماض الأمينية، إلا أنها غير قادرة على فهم اللغة البشرية.
وعلى نحو مماثل، فإن نماذج اللغة الكبيرة (LLMs) مثل ChatGPT و Claude-2، والتي تعتبر جيدة في معالجة اللغة الطبيعية، تفشل عندما يُطلب منها وصف وظيفة تسلسل البروتين أو توليد البروتينات ذات خصائص محددة. والسبب هوهناك عيبان رئيسيان في مجموعات بيانات النصوص البروتينية الحالية: الأول هو الافتقار إلى إشارات تعليمات واضحة؛ والأمر الآخر هو عدم التوازن في تعليق البيانات. باختصار، هناك فجوة لم تتم معالجتها في الأبحاث الحالية حول ماجستير القانون، وهي عدم القدرة على التحويل بسرعة بين اللغة البشرية ولغة البروتين.
لحل هذا النوع من المشاكل،واقترح الفريق بقيادة هواجون تشين وتشيانغ تشانغ من جامعة تشجيانغ نموذج InstructProtein، الذي يستخدم تعليمات المعرفة لمواءمة لغة البروتين مع اللغة البشرية.لقد استكشفنا قدرات التوليد ثنائية الاتجاه بين لغة البروتين واللغة البشرية، ونجحنا في سد الفجوة بين اللغتين بشكل فعال وأظهرنا القدرة على دمج التسلسلات البيولوجية في نماذج لغوية كبيرة.
عنوان البحث هو "InstructProtein: محاذاة اللغة البشرية والبروتينية من خلال تعليمات المعرفة".تم قبولها من قبل المؤتمر الرئيسي ACL 2024.
أبرز الأبحاث:
* InstructProtein هي دراسة لمواءمة اللغة البشرية ولغة البروتين من خلال تعليمات المعرفة
* استكشاف قدرات التوليد ثنائية الاتجاه بين لغة البروتين واللغة البشرية، مما أدى إلى سد الفجوة بين اللغتين بشكل فعال
* أظهرت التجارب على عدد كبير من مهام توليد النصوص البروتينية ثنائية الاتجاه أن InstructProtein يتفوق على برامج LLM المتطورة الحالية

عنوان الورقة:
https://arxiv.org/abs/2310.03269
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
مجموعة البيانات: مجموعة بيانات علمية شاملة
يحتوي النص الخاص بمرحلة ما قبل تدريب النموذج على تسلسلات بروتينية من UniRef100 وجمل من ملخصات PubMed.وبناءً على هذه البيانات، أنشأ الباحثون مجموعة بيانات تعليماتية تحتوي على 2.8 مليون نقطة بيانات.
خلال مرحلة الضبط الدقيق للنموذج، تم إنشاء الرسم البياني لمعرفة البروتين باستخدام التعليقات التوضيحية التي قدمها UniProt/Swiss-Prot، والتي تضمنت العائلات البروتينية الفائقة، والعائلات، والمجالات، والمواقع المحفوظة، والمواقع النشطة، ومواقع الارتباط، والمواقع، والوظائف، والعمليات البيولوجية المعنية؛ جاءت البيانات الخاصة بنمذجة المعرفة السببية من قواعد بيانات InterPro وGene Ontology.
وفي مرحلة تقييم النموذج، اختار الباحثون مجموعة بيانات علم الجينات (GO) لتقييم قدرة النموذج على شرح وظيفة البروتين، ثم اختاروا مجموعة بيانات Hu et al. مجموعة بيانات لتقييم قدرة النموذج على التنبؤ بربط الأيونات المعدنية (MIB).
هندسة النموذج: ضبط النموذج المدرب مسبقًا من خلال بناء مجموعة بيانات تعليمات معرفة البروتين
لمنح LLM القدرة على فهم لغة البروتين، يتبنى InstructProtein نهج تدريبي من خطوتين: أولاً التدريب المسبق على البروتين ومجموعات اللغة الطبيعية، ثم الضبط الدقيق باستخدام مجموعة بيانات تعليمات معرفة البروتين الراسخة.
مرحلة ما قبل التدريب
خلال مرحلة ما قبل التدريب متعدد اللغات، استخدمت هذه الدراسة قواعد بيانات نصية كبيرة ذات صلة بالبيولوجيا لتعزيز فهم النموذج للغة وخلفية المعرفة في المجال البيولوجي. تشير التعددية اللغوية إلى القدرة على معالجة كل من اللغات الطبيعية (مثل الملخصات الإنجليزية) ولغات التسلسل البيولوجي (مثل تسلسلات البروتين).
مرحلة ضبط النموذج
أثناء مرحلة ضبط النموذج،تقترح هذه الدراسة طريقة لبناء مجموعة البيانات تسمى "تعليمات المعرفة".تعمل الرسوم البيانية المعرفية (KGs) ونماذج اللغة الكبيرة معًا لبناء مجموعة بيانات تعليمية متوازنة ومتنوعة. لا تعتمد هذه الطريقة على قدرة نموذج لغوي كبير على فهم لغة البروتين، وبالتالي تجنب المعلومات الخاطئة التي يتم إدخالها عن طريق تحيز النموذج أو الهلوسة. تنقسم عملية البناء المحددة إلى 3 مراحل رئيسية، كما هو موضح في الشكل التالي:
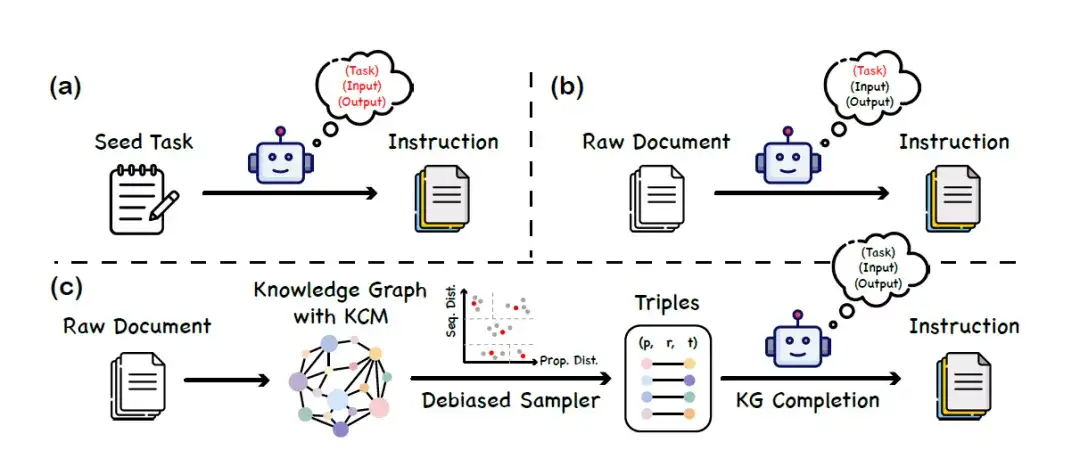
أ. نظرًا لمجموعة من المهام الأساسية، اطلب من LLM إنشاء بيانات تعليمات جديدة
ب. استخدم LLM لإنشاء بيانات التعليمات المقابلة لمحتوى المستند الخام
ج. إطار عمل توليد التعليمات بناءً على الرسم البياني للمعرفة (KG)
* بناء الرسم البياني للمعرفة:استخدم الباحثون UniProtKB كمصدر بيانات لبناء رسم بياني لمعرفة البروتين. وباستعارة مفهوم التفكير المتسلسل، أدرك الباحثون أن هناك أيضًا سلاسل منطقية في شرح البروتين. على سبيل المثال، ترتبط العمليات البيولوجية التي يمكن أن يشارك فيها البروتين ارتباطًا وثيقًا بوظيفته الجزيئية وموقعه الفرعي الخلوي، وتتأثر الوظيفة الجزيئية نفسها ببنية المجال البروتيني.
لتمثيل السلسلة السببية لمعرفة البروتين هذه،قدم الباحثون مفهومًا جديدًا يسمى النمذجة السببية المعرفية (KCM).على وجه التحديد، يتكون نموذج المعرفة السببي من ثلاثيات متعددة مترابطة منظمة في رسم بياني غير دوري موجه، حيث يمثل اتجاه الحافة العلاقة السببية. ينظم الرسم البياني الثلاثيات من المستوى المجهري (الذي يغطي ميزات تسلسل البروتين، مثل البنية) إلى المستوى العياني (الذي يغطي الوظيفة البيولوجية). يوضح الشكل أدناه عملية إنشاء تعليمات واقعية ومنطقية ومتنوعة بناءً على ثلاثية تحتوي على KCM باستخدام نموذج لغوي كبير مقترنًا برسم بياني للمعرفة لإكمال المهمة.
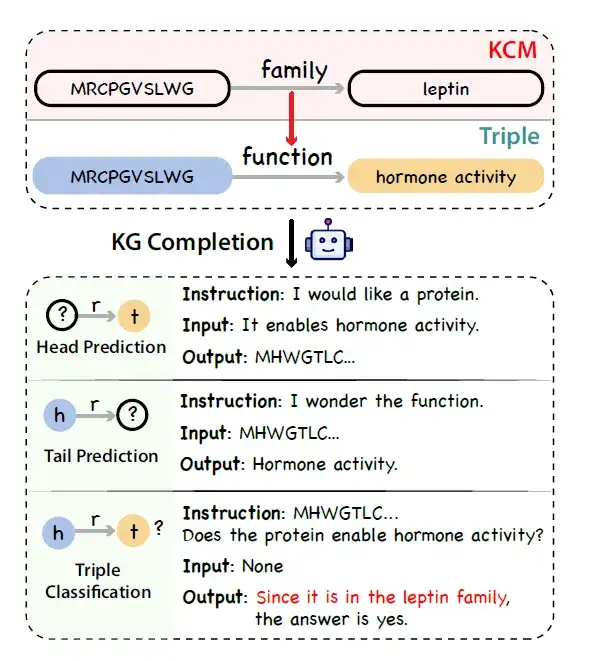
* أخذ العينات الثلاثية من الرسم البياني المعرفي:بالنظر إلى مشكلة عدم التوازن في التعليقات التوضيحية في الرسوم البيانية المعرفية، اقترح الباحثون استراتيجية أخذ عينات غير متحيزة لتحل محل أخذ العينات الموحدة كاستراتيجية بديلة لأخذ العينات الموحدة. على وجه التحديد، يقوم أولاً بتجميع البروتينات وفقًا لتسلسلها وتشابه السمات، ثم يستخرج الثلاثيات بشكل موحد في كل مجموعة.
* توليد بيانات التعليمات:قام الباحثون بمحاكاة مهمة استكمال الرسم البياني للمعرفة واستخدموا برنامج LLM عامًا (مثل ChatGPT) لتحويل ثلاثيات الرسم البياني للمعرفة باستخدام KCM إلى بيانات تعليمات.
يتيح هذا النهج إنشاء مجموعة بيانات غنية ومتوازنة من التعليمات الخاصة بوظيفة البروتين وموقعه بكفاءة دون الاعتماد على نماذج محددة مسبقًا لفهم لغة البروتين.توفير دعم بيانات أكثر موثوقية لأبحاث وظائف البروتين وتطبيقاتها اللاحقة.
ومن خلال الجمع بين التدريب المسبق والضبط الدقيق، يصبح النموذج الناتج، المسمى InstructProtein، قادرًا على أداء مهام التنبؤ والتعليق التوضيحي المختلفة التي تنطوي على تسلسلات البروتين بشكل أفضل.على سبيل المثال، التنبؤ بدقة بوظيفة البروتين أو تحديد موقعه في موقع فرعي خلوي محدد - وهو ما له آثار مهمة على هندسة البروتين، واكتشاف الأدوية، والبحوث الطبية الحيوية الأوسع.
نتائج البحث: برنامج InstructProtein يتفوق على برامج الماجستير في القانون الحديثة
قامت الدراسة بتقييم قدرات InstructProtein بشكل شامل في فهم وتصميم تسلسل البروتين:
فهم تسلسل البروتين
قام الباحثون بتقييم أداء نموذج InstructProtein في مهام التصنيف الثلاثة التالية:التنبؤ بموقع البروتين، والتنبؤ بوظيفة البروتين، والتنبؤ بقدرة البروتين على ربط أيونات المعادن. تم تصميم هذه المهام لتكون مشابهة لمشكلات فهم القراءة في اللغة الطبيعية، حيث تحتوي كل البيانات على تسلسل بروتيني وسؤال، ويحتاج النموذج إلى الإجابة على سؤال من نوع نعم/لا. يتم إجراء كافة التقييمات في بيئة خالية من الأخطاء.
وتظهر نتائج التقييم في الجدول التالي:يحقق InstructProtein أداءً متطورًا جديدًا في جميع المهام مقارنةً بجميع النماذج الأساسية.
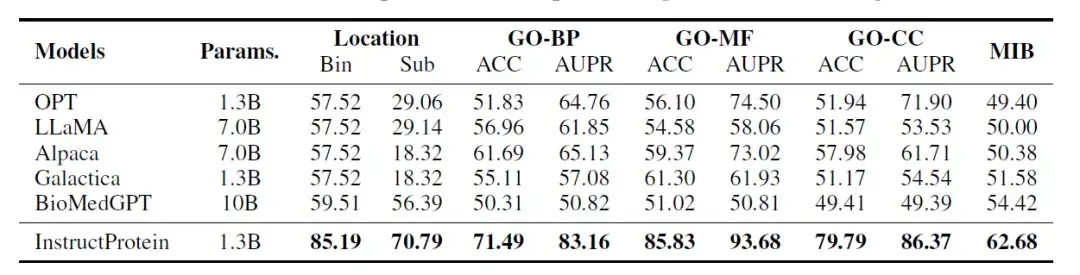
وعلاوة على ذلك، هناك نتيجتان رئيسيتان تستحقان الإشارة إليهما. أولاً، يتفوق InstructProtein بشكل كبير على برامج LLM المستمدة من مجموعات تدريب اللغة الطبيعية (أي OPT، وLLaMA، وAlpaca). وهذا يدل على أنيعد التدريب باستخدام مجموعة من البروتينات واللغة الطبيعية مفيدًا لطلاب الماجستير في القانون ويحسن قدراتهم في فهم لغة البروتين.
ثانيًا، على الرغم من أن كلًا من Galactica وBioMedGPT يستخدمان UniProtKB كمجموعة أدوات لتنسيق اللغة الطبيعية والبروتين، فإن InstructProtein يتفوق عليهما باستمرار. وقد أكدت النتائج أنيمكن لبيانات التعليمات عالية الجودة في هذه الدراسة تحسين الأداء في إعدادات اللقطة الصفرية.
بالإضافة إلى ذلك، في مهمة تحديد موقع البروتين الفرعي الخلوي (bin)، كانت بروتينات LLM (OPT، وLLaMA، وAlpaca، وGalactica) متحيزة بشدة، مما تسبب في تصنيف جميع البروتينات في نفس المجموعة، مما أدى إلى دقة 57.52%.
تصميم تسلسل البروتين
من حيث تصميم البروتين، صمم الباحثون مهمة "إقران بروتين التعليمات": نظرًا لوجود بروتين ووصفه، يحتاج النموذج إلى اختيار البروتين الأكثر ملاءمة من الوصف المقابل له و9 أوصاف غير مقابلة.
كما هو موضح في الجدول التالي:يتفوق InstructProtein بشكل كبير على جميع النماذج الأساسية في مهمة إقران التعليمات بالبروتين.
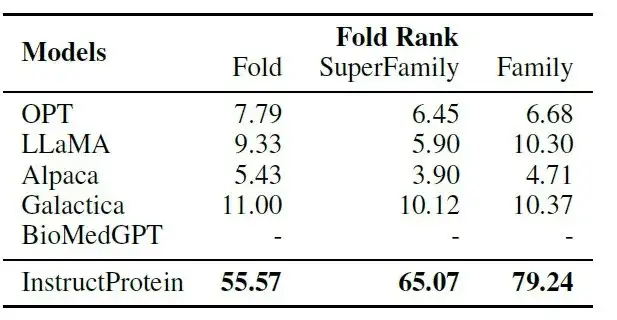
ومن بينها، يركز BioMedGPT على تحويل البروتينات إلى نص ويفتقر إلى قدرات تصميم البروتين؛ يتمتع برنامج Galactica بأداء محدود في إعداد اللقطة الصفرية لمحاذاة التعليمات مع البروتينات لأنه مدرب على مجموعة بروتينية سردية.وتؤكد هذه النتائج تفوق قدرات نموذج InstructProtein في متابعة التعليمات في إنتاج البروتين.
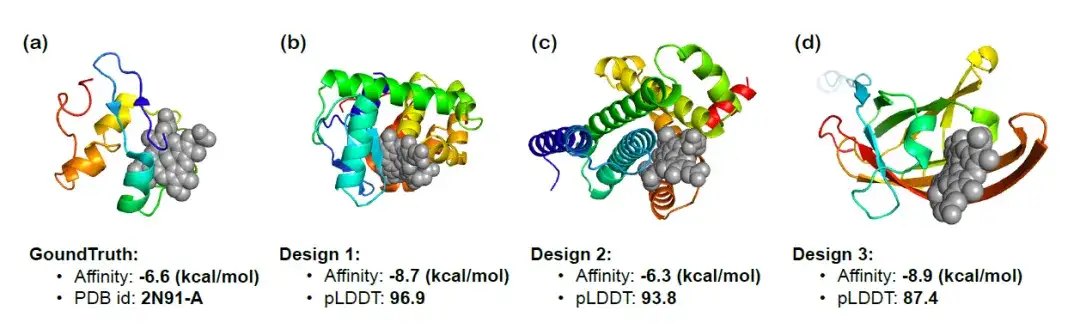
للتحقق بشكل أكبر من قدرة InstructProtein على تصميم البروتينات وفقًا للتعليمات ذات الصلة الوظيفية، استخدم الباحثون InstructProtein لتصميم بروتينات ربط الهيم التي يمكنها الارتباط بمركبات محددة وتصور الهياكل ثلاثية الأبعاد للبروتينات الثلاثة الناتجة. يوضح الشكل أدناه نتائج الالتحام، وتوقع تقارب الارتباط (كلما انخفضت القيمة كان ذلك أفضل)، ونتيجة pLDDT (كلما زادت القيمة المطلقة، كان ذلك أفضل). وقد لوحظ أن البروتين الناتج أظهر تقاربًا كبيرًا للارتباط،تم تأكيد فعالية InstructProtein في تصميم البروتينات المرتبطة بالهيم.
لقد بدأ للتو الطريق لاستكشاف نماذج البروتين
في السنوات الأخيرة، جلبت نماذج اللغة الكبيرة تغييرات ثورية في مجال معالجة اللغة الطبيعية. تُستخدم هذه النماذج على نطاق واسع في العديد من جوانب الحياة اليومية، مثل ترجمة اللغات، واكتساب المعلومات، وتوليد التعليمات البرمجية. ومع ذلك، على الرغم من أن هذه النماذج اللغوية تعمل بشكل جيد في معالجة اللغة الطبيعية ولغة الترميز، إلا أنها غير قادرة على التعامل مع التسلسلات البيولوجية (مثل تسلسلات البروتين).وفي هذا السياق، يأتي ظهور نموذج اللغة البروتينية الكبيرة في الوقت المناسب.
تم تدريب نموذج لغة البروتين الكبيرة خصيصًا للبيانات المتعلقة بالبروتين، بما في ذلك تسلسلات الأحماض الأمينية، وأنماط طي البروتين، والبيانات البيولوجية الأخرى المتعلقة بالبروتينات. لذلك، لديهم القدرة على التنبؤ بدقة ببنية البروتين ووظيفته وتفاعلاته. يمثل نموذج لغة البروتين التطبيق المتطور لتكنولوجيا الذكاء الاصطناعي في علم الأحياء. ومن خلال تعلم أنماط وهياكل تسلسلات البروتين، فإنه يمكن التنبؤ بوظيفة وشكل البروتينات، وهو أمر ذو أهمية كبيرة لتطوير الأدوية الجديدة وعلاج الأمراض والبحوث البيولوجية الأساسية.
في أبريل 2023، أظهرت دراسة نُشرت في مجلة Science أن الباحثين من فريق الذكاء الاصطناعي استخدموا نموذجًا لغويًا كبيرًا يمكنه استخراج معلومات تطورية لتطوير ESMFold متنبئ بالتسلسل إلى البنية. تجاوزت دقة التنبؤ للبروتينات ذات التسلسل الفردي دقة AlphaFold2، وكانت دقة التنبؤ للبروتينات ذات التسلسلات المتجانسة قريبة من دقة AlphaFold2، وزادت السرعة بمقدار مرتبة واحدة. وتوقع النموذج وجود أكثر من 600 مليون بروتين ميتاجينومي، مما يدل على اتساع وتنوع البروتينات الطبيعية.
في يوليو 2023، اقترحت شركة Baidu Bio وجامعة Tsinghua بشكل مشترك نموذجًا يسمى نموذج اللغة العامة للبروتين xTrimo (xTrimoPGLM) مع عدد معلمات يصل إلى 100 مليار (100B). من حيث فهم المهام، يتفوق xTrimoPGLM بشكل كبير على النماذج الأساسية المتقدمة الأخرى في مجموعة متنوعة من مهام فهم البروتين؛ من حيث مهام التوليد، فإن xTrimoPGLM قادر على توليد تسلسلات بروتينية جديدة تشبه الهياكل البروتينية الطبيعية.

رابط الورقة:
https://www.biorxiv.org/content/10.1101/2023.07.05.547496v3
يوليو 2024عمل تشو هاو، الباحث المشارك في معهد الصناعات الذكية بجامعة تسينغهوا، مع جامعة بكين وجامعة نانجينغ وفريق شويمو الجزيئي لاقتراح نموذج لغة بروتينية متعدد المقاييس ESM-AA (ESM All Atom).ومن خلال تصميم آليات التدريب مثل توسيع البقايا وترميز المواضع متعددة المقاييس، تم توسيع القدرة على معالجة المعلومات على المستوى الذري. تم تحسين أداء ESM-AA في المهام مثل ربط الربيطة المستهدفة بشكل كبير، متجاوزًا نماذج لغة بروتين SOTA الحالية مثل ESM-2، ومتجاوزًا أيضًا نماذج تعلم التمثيل الجزيئي SOTA الحالية مثل Uni-Mol. وقد تم نشر بحث ذي صلة في مؤتمر التعلم الآلي ICML تحت عنوان "ESM All-Atom: نموذج لغة البروتين متعدد المقاييس للنمذجة الجزيئية الموحدة".

عنوان الورقة:
https://icml.cc/virtual/2024/poster/35119
ومن الجدير التأكيد على أنه على الرغم من التقدم الكبير الذي تم إحرازه في البحث حول نماذج اللغة الكبيرة للبروتين، فإننا لا نزال في المراحل المبكرة من الفهم الكامل لتعقيد مساحة تسلسل البروتين. على سبيل المثال، يواجه نموذج InstructProtein المذكور أعلاه تحديات في التعامل مع المهام العددية، وهو أمر مهم بشكل خاص في مجال نمذجة البروتين التي تتطلب تحليلًا كميًا، بما في ذلك إنشاء بنية ثلاثية الأبعاد، وتقييم الاستقرار، والتقييم الوظيفي. مستقبل،سيتم توسيع نطاق البحث ذي الصلة ليشمل مجموعة أوسع من التعليمات بما في ذلك الأوصاف الكمية،تعزيز قدرة النموذج على توفير مخرجات كمية، وبالتالي تعزيز تكامل لغة البروتين واللغة البشرية وتوسيع نطاق تطبيقها العملي في سيناريوهات التطبيق المختلفة.
مراجع:
1.https://arxiv.org/abs/2310.03269
2.https://mp.weixin.qq.com/s/UPsf9y9dcq_brLDYhIvz-w
3.https://hic.zju.edu.cn/ibct/2024/0228/c58187a2881806/page.htm








