Command Palette
Search for a command to run...
تم اختياره لـ ACL 2024! لتحقيق تفسير متعدد الوسائط لبيانات البروتين ومعلومات النص، اقترح فريق وانج شيانج من جامعة جنوب كاليفورنيا للتكنولوجيا إطار عمل توليد النص البروتيني ProtT3

إن استكشاف أسرار البنية الديناميكية للبروتين ليس مجرد خطوة أساسية في تعزيز تطوير الأدوية الجديدة، بل هو أيضًا حجر الزاوية المهم لفهم العمليات الحيوية. ومع ذلك، فإن تعقيد البروتينات يجعل من الصعب التقاط وتحليل المعلومات البنيوية العميقة الخاصة بها بشكل مباشر. لقد كانت كيفية تحويل البيانات البيولوجية المعقدة إلى تعبيرات بديهية وسهلة الفهم دائمًا تحديًا كبيرًا في مجال البحث العلمي.
مع التطور السريع لنماذج اللغة (LM)، ظهرت فكرة مبتكرة:نظرًا لأن نماذج اللغة يمكنها تعلم واستخراج المعلومات النصية من كميات كبيرة من البيانات، فهل يمكنها تعلم "قراءة" معلومات البروتين من بيانات البروتين وتحويل معلومات بنية البروتين الديناميكية مباشرة إلى أوصاف نصية يسهل على البشر فهمها؟
لقد واجهت هذه الفكرة الواعدة العديد من التحديات في التطبيق العملي. على سبيل المثال، يتم تدريب نموذج اللغة مسبقًا على مجموعة نصية من تسلسلات البروتين. على الرغم من أن لديه قدرات قوية في معالجة النصوص، إلا أنه غير قادر على فهم "لغة" بنية البروتين غير البشرية. على النقيض من ذلك، يتم تدريب نماذج لغة البروتين (PLMs) مسبقًا على مجموعات تسلسل البروتين وتتمتع بقدرات ممتازة على فهم البروتين وتوليده.لكن هناك قيود أخرى مهمة بنفس القدر، وهي عدم وجود قدرات معالجة النصوص.
إذا تمكنا من الجمع بين مزايا PLMs و LM لبناء بنية نموذجية جديدة لا يمكنها فقط فهم بنية البروتين بشكل عميق ولكن أيضًا ربط المعلومات النصية بسلاسة، فسيكون لها تأثير عميق على تطوير الأدوية وتوقع خصائص البروتين والتصميم الجزيئي وغيرها من المجالات. لكن،ينتمي هيكل البروتين ونصوص اللغة البشرية إلى أنماط بيانات مختلفة، وليس من السهل اختراق الحواجز ودمجها.
في هذا الصدد،واقترح وانج شيانج من جامعة العلوم والتكنولوجيا في الصين، بالاشتراك مع فريق ليو تشي يوان من الجامعة الوطنية في سنغافورة وفريق البحث من جامعة هوكايدو، إطار عمل جديد لنمذجة نص البروتين يسمى ProtT3.يجمع الإطار بين PLM وLM مع اختلافات الوسائط من خلال جهاز عرض متعدد الوسائط، حيث يتم استخدام PLM لفهم البروتين ويتم استخدام LM لمعالجة النصوص. لتحقيق ضبط دقيق فعال، قام الباحثون بدمج LoRA في LM لتنظيم عملية توليد البروتين إلى النص بشكل فعال.
بالإضافة إلى ذلك، أنشأ الباحثون أيضًا مهام تقييم كمية لمهام نمذجة نص البروتين، بما في ذلك تسمية البروتين، والإجابة على أسئلة البروتين (ضمان جودة البروتين)، واسترجاع نص البروتين. حقق ProtT3 أداءً ممتازًا في جميع المهام الثلاث.
تم اختيار البحث، الذي يحمل عنوان "ProtT3: توليد البروتين إلى نص لفهم البروتين القائم على النص"، لأفضل مؤتمر ACL 2024.
أبرز الأبحاث:
* يمكن لإطار عمل ProtT3 سد الفجوة بين النص والبروتين وتحسين دقة تحليل تسلسل البروتين
* في مهمة تسمية البروتين، كانت درجة BLEU-2 الخاصة بـ ProtT3 على مجموعات بيانات Swiss-Prot وProteinKG25 أعلى من خط الأساس بأكثر من 10 نقاط
* في مهمة الإجابة على سؤال البروتين، تحسن أداء المطابقة الدقيقة لـ ProtT3 على مجموعة بيانات PDB-QA بمقدار 2.5%
* في مهمة استرجاع نص البروتين، كانت دقة استرجاع ProtT3 على مجموعات بيانات Swiss-Prot وProteinKG25 أعلى من خط الأساس بمقدار 14%
عنوان الورقة:
https://arxiv.org/abs/2405.12564
عنوان تنزيل مجموعة البيانات:
https://go.hyper.ai/j0wvp
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
بناء وتحسين ثلاث مجموعات بيانات رئيسية لأبحاث البروتين
قام الباحثون باختيار ثلاث مجموعات من البيانات: Swiss-Prot، وProteinKG25، وPDB-QA.
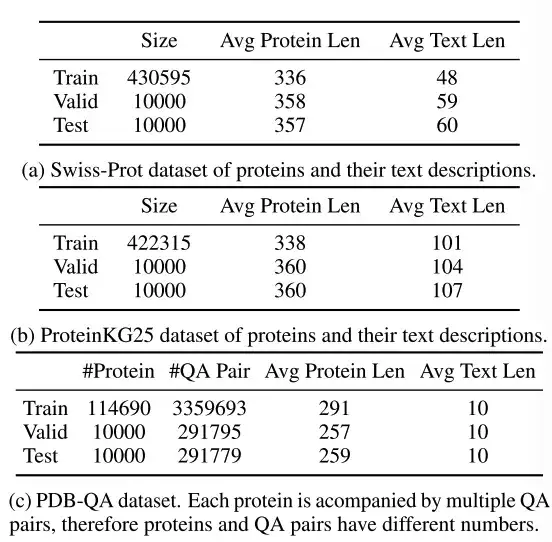
كما هو موضح في الجدول أعلاه،Swiss-Prot هي قاعدة بيانات لتسلسل البروتين مع تعليقات نصية.قام الباحثون بمعالجة مجموعة البيانات واستبعدوا أسماء البروتينات من التعليقات النصية لمنع تسرب المعلومات. يربط وصف النص الناتج بين التعليقات التوضيحية لوظيفة البروتين وموقعه وعائلته.
ProteinKG25 هو رسم بياني للمعرفة مشتق من قاعدة بيانات Gene Ontology.قام الباحثون في البداية بتجميع ثلاثيات من نفس البروتين ثم قاموا بملء معلومات البروتين في قالب نصي محدد مسبقًا لتحويل ثلاثياته إلى نص حر.
PDB-QA عبارة عن مجموعة بيانات للإجابة على أسئلة البروتين ذات الدورة الواحدة والمشتقة من RCSB PDB2.يحتوي على 30 قالبًا للأسئلة حول بنية البروتين وخصائصه ومعلومات تكميلية. وكما هو موضح في الجدول أدناه، من أجل التقييم الدقيق، قام الباحثون بتقسيم الأسئلة إلى أربع فئات بناءً على شكل الإجابة (سلسلة أو رقم) والتركيز على المحتوى (الهيكل / السمة أو المعلومات التكميلية).

ProtT3: نموذج مبتكر لتوليد البروتين إلى نص
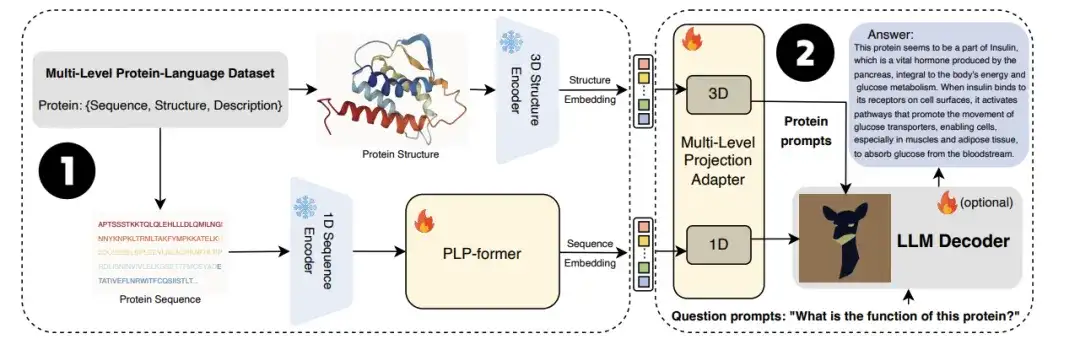
كما هو موضح في الشكل أ أدناه،يتكون ProtT3 من نموذج لغة البروتين (PLM)، وجهاز عرض متعدد الوسائط (Cross-ModalProjector)، ونموذج لغة (LM)، ووحدة LoRA.تنظيم عملية تحويل البروتين إلى نص بشكل فعال.
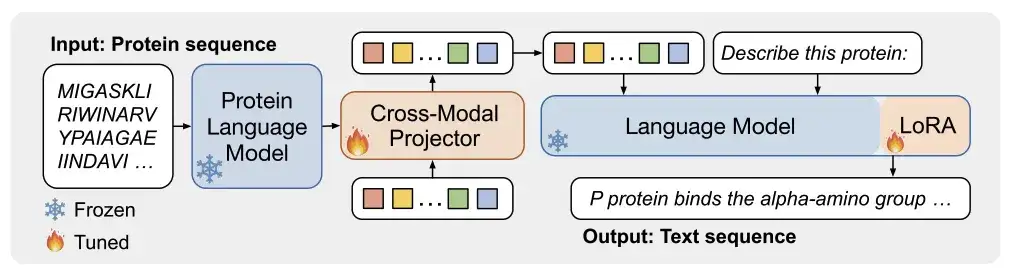
ومن بين هذه النماذج، نموذج لغة البروتين الذي اختاره الباحثون هو ESM-2150M، والذي يستخدم لفهم البروتين؛ تم اختيار جهاز العرض المتعدد الوسائط Q-Former، والذي يستخدم لربط الاختلافات النمطية بين PLM ونموذج اللغة LM، ثم تعيين تمثيل البروتين إلى مساحة النص في LM؛ نموذج اللغة المحدد هو Galactica1.3B، والذي يستخدم لمعالجة النصوص؛ ومن أجل الحفاظ على كفاءة التكيف المباشر، قام الباحثون أيضًا بدمج LoRA في نموذج اللغة لتحقيق ضبط دقيق فعال.
كما هو موضح في الشكل ب،يستخدم ProtT3 مرحلتين تدريبيتين لتعزيز النمذجة الفعالة لنصوص البروتين.وهما تدريب استرجاع النص البروتيني وتدريب توليد البروتين إلى نص.
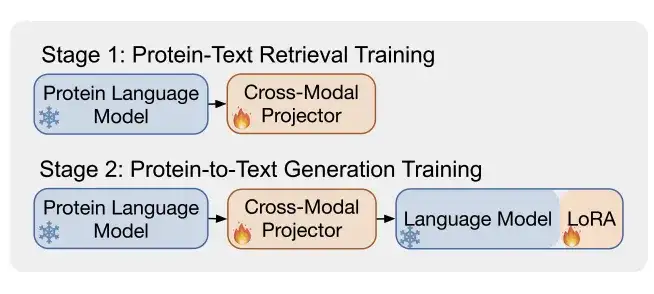
* المرحلة 1: تدريب استرجاع النص البروتيني
كما هو موضح في الشكل أ أدناه، يتكون جهاز العرض المتقاطع Q-Former من محولين: محولات البروتين لتشفير البروتين ومحولات النص لمعالجة النصوص. يتقاسم محولان الاهتمام الذاتي لتمكين التفاعل بين البروتينات والنص.
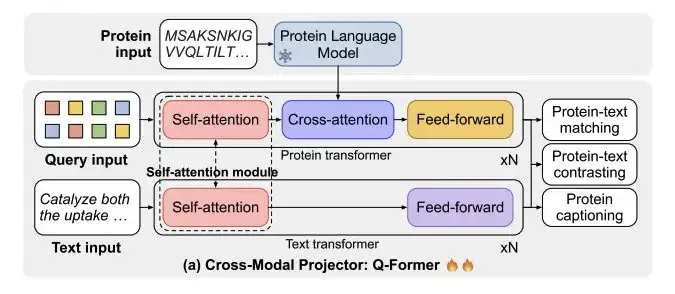
قام الباحثون بتدريب ProtT3 على مجموعة بيانات مشتركة من Swiss-Prot وProteinKG25 لاسترجاع نص البروتين.يتضمن ذلك ثلاث مهام: مقارنة البروتين بالنص، ومطابقة البروتين بالنص (PTM) وترجمة البروتين (PCap).
* المرحلة الثانية: تدريب توليد البروتين إلى نص
قام الباحثون بربط جهاز العرض متعدد الوسائط بنموذج اللغة (LM) وأدخلوا تمثيل البروتين Z إلى LM من أجل تكييف عملية إنشاء النص من خلال معلومات البروتين. ومن بينها، استخدم الباحثون طبقة خطية لإسقاط Z على نفس البعد الخاص بمدخلات نموذج اللغة، وقاموا بتدريب ProtT3 لكل مجموعة بيانات تم إنشاؤها بشكل منفصل، وأضافوا مطالبات نصية مختلفة بعد تمثيل البروتين لمزيد من التحكم في عملية التوليد.
بالإضافة إلى ذلك، قدم الباحثون LoRA وقاموا بضبطها بشكل فردي على 3 مجموعات بيانات في مهمة توليد البروتين إلى نص.
متعدد الاستخدامات في مجال البروتين، يقوم بتقييم أداء ProtT3 في 3 مهام رئيسية
لتقييم أداء ProtT3،قام الباحثون باختبار النظام في ثلاث مهام: ترجمة البروتين، وضمان جودة البروتين، واسترجاع نص البروتين.
أقرب إلى الوصف الحقيقي للبروتينات، يتمتع ProtT3 بدقة أعلى
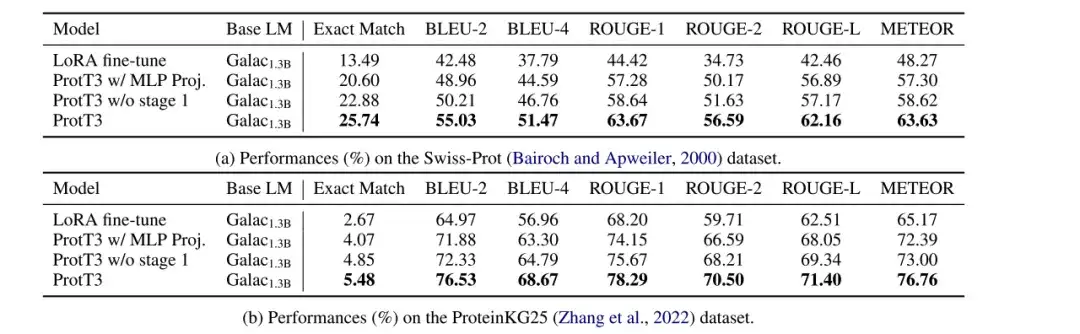
قام الباحثون بتقييم أداء النماذج LoRA fine-tuned Galactica1.3B، وProtT3 w/ MLP Proj.، وProtT3 w/o stage 1، وProtT3 في مهام تسمية البروتين على مجموعات البيانات Swiss-Prot وProteinKG25، واستخدموا BLEU، وROUGE، وMETEOR كمقاييس للتقييم.
* ProtT3 مع MLP Proj.: نسخة مختلفة من ProtT3 تحل محل جهاز العرض متعدد الوسائط الخاص بـ ProtT3 مع MLP
* ProtT3 بدون المرحلة 1: أحد أشكال ProtT3 التي تتخطى مرحلة تدريب ProtT3 1
كما هو موضح في الشكل أدناه، بالمقارنة مع Galactica1.3B المضبوطة بدقة باستخدام LoRA،يؤدي ProtT3 إلى تحسين نتيجة BLEU-2 بأكثر من 10 نقاط.تم إثبات أهمية تقديم نموذج لغة البروتين وفعالية ProtT3 في فهم مدخلات البروتين بشكل حدسي. علاوة على ذلك، يتفوق ProtT3 على متغيريه في مقاييس مختلفة، مما يوضح ميزة استخدام جهاز العرض Q-Former ومرحلة التدريب 1.
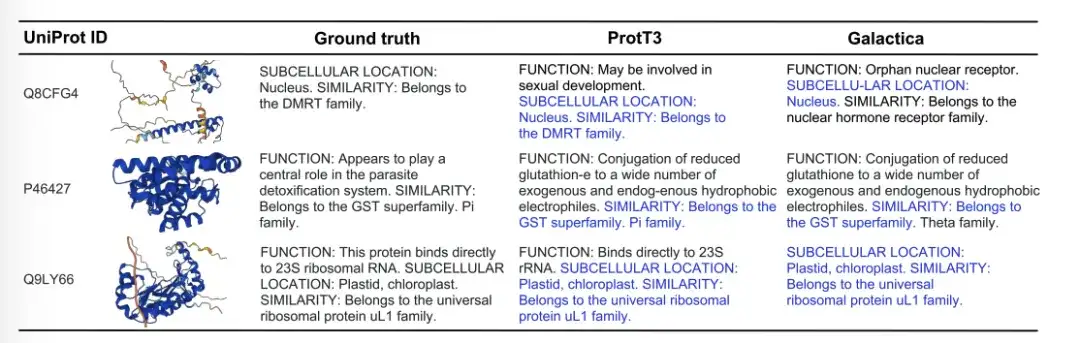
يوضح الشكل أدناه ثلاثة أمثلة لتوليد عناوين فرعية للبروتين وهي Ground Truth وProtT3 وGalactica. في مثال Q8CFG4، حدد محتوى الشرح التوضيحي لـ ProtT3 عائلة DMRT بشكل أكثر دقة، بينما لم يفعل Galactica ذلك. وفي حالة P46427، فشل كلا النموذجين في تحديد وظيفة البروتين، ولكن ProtT3 قدم تنبؤًا أكثر دقة لعائلة البروتين. في حالة Q9LY66، تنبأ كلا النموذجين بنجاح بالموقع الفرعي للخلية وعائلة البروتين. ويذهب ProtT3 إلى خطوة أبعد في التنبؤ بوظيفة البروتينات، وهو ما يقترب من الوصف الحقيقي.
الدقة أعلى بنسبة 141% من النموذج الأساسي. TP3T، يتمتع ProtT3 بقدرة أفضل على استرجاع نص البروتين
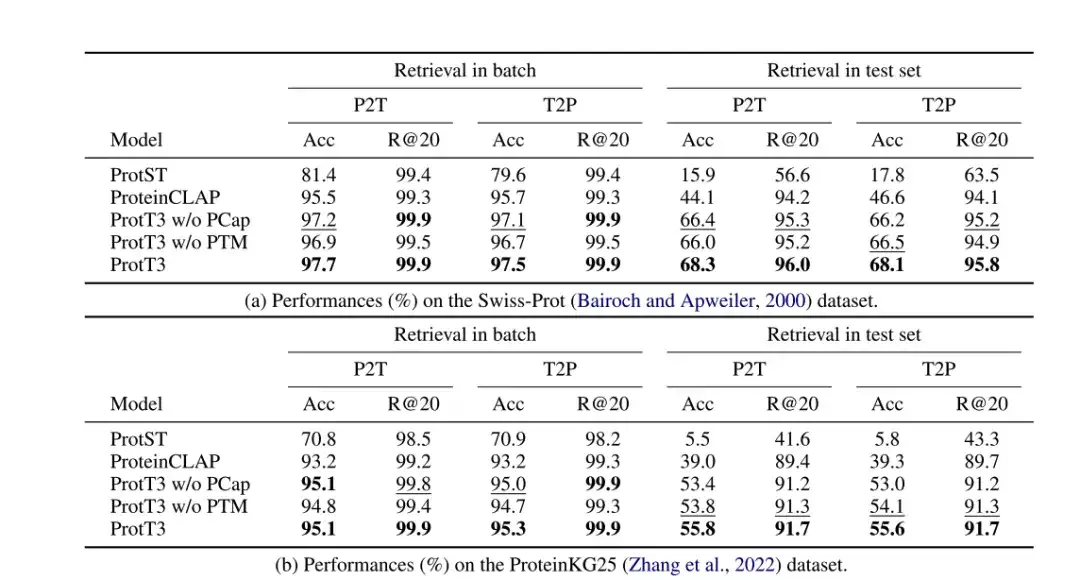
قام الباحثون بتقييم أداء ProtT3 في استرجاع النص البروتيني على مجموعات البيانات Swiss-Prot وProteinKG25، باستخدام الدقة وRecall@20 كمقاييس للتقييم، واعتمدوا ProtST وProteinCLAP كنماذج أساسية.
كما هو موضح في الجدول التالي،دقة ProtT3 أعلى بمقدار 14% من النموذج الأساسي.ويشير هذا إلى أن ProtT3 متفوق في محاذاة البروتينات مع أوصاف النصوص المقابلة لها. أيضًا،أدى مطابقة نص البروتين (PTM) إلى تحسين دقة ProtT3 بمقدار 1%-2%،يرجع ذلك إلى أن PTM يسمح لمعلومات البروتين والنص بالتفاعل في الطبقات المبكرة من Q-Former، وبالتالي تحقيق مقياس أكثر دقة لتشابه البروتين والنص.تعمل تسمية البروتين (PCap) على تحسين دقة استرجاع ProtT3 بنحو 2%.يرجع ذلك إلى أن PCap يشجع رموز الاستعلام على استخراج معلومات البروتين الأكثر صلة بإدخال النص، مما يساعد على محاذاة البروتين والنص.
* ProtT3 بدون PTM: تخطي مرحلة PTM في ProtT3
* ProtT3 بدون PCap: تخطي مرحلة PCap في ProtT3
يمكن لـ ProtT3 التنبؤ ببنية البروتين وخصائصه، ولديه قدرات أفضل للإجابة على الأسئلة
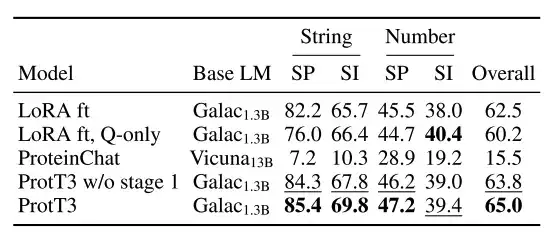
قام الباحثون بتقييم أداء الإجابة على أسئلة البروتين لـ ProtT3 على مجموعة بيانات PDB-QA، واختيار التطابق الدقيق كمقياس للتقييم واستخدام Galactica1.3B المضبوط بدقة بواسطة LoRA كنموذج أساسي (LoRA ft).
كما هو موضح في الشكل أدناه،إن أداء المطابقة الدقيقة لـ ProtT3 أعلى بنحو 2.51 من أداء TP3T الأساسي.إنه يتفوق باستمرار على خط الأساس في التنبؤ ببنية البروتين وخصائصه، مما يدل على أن ProtT3 لديه قدرات متعددة الوسائط ممتازة لفهم أسئلة البروتين والنص.
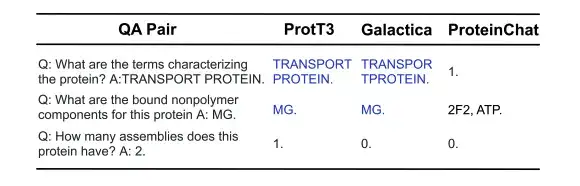
كما هو موضح في الشكل أدناه، في أمثلة الإجابة على أسئلة البروتين الثلاثة التالية، أجاب كل من ProtT3 وGalactica بشكل صحيح على السؤالين الأولين حول خصائص البروتين/بنيته، لكنهما فشلا في السؤال الثالث الذي يتطلب إجابة رقمية. واجه ProteinChat صعوبة في الإجابة على جميع الأسئلة الثلاثة ولم يتمكن من الإجابة على أي منها.
فتح لغة البروتينات، استكشاف متطور في علوم الحياة من خلال برنامج LLM
إن استكشاف الباحثين في مجال تحويل البروتين إلى نص قد يمكّن البشر من حل الظواهر البيولوجية المعقدة بطريقة يمكن للبشر فهمها. لا يوضح نموذج اللغة في الدراسة المذكورة أعلاه فهمًا عميقًا لـ "المساحة الكامنة" للبروتينات فحسب، بل يعمل أيضًا كجسر بين المهام الطبية الحيوية ومعالجة اللغة الطبيعية، مما يفتح مسارات جديدة للأبحاث مثل تطوير الأدوية والتنبؤ بوظيفة البروتين. إضافي،وإذا تم استخدام نماذج لغوية كبيرة تحتوي على مليارات المعلمات أو أكثر لمعالجة هياكل لغوية أكثر تعقيدًا، فمن المتوقع أن يؤدي ذلك إلى تعزيز الاستكشاف المستقبلي للعلوم الحياتية على مستويات متعددة.
على سبيل المثال،اقترح الفريق بقيادة Zhang Qiang وChen Huajun من جامعة Zhejiang نموذجًا لغويًا كبيرًا مبتكرًا يسمى InstructProtein.يتمتع النموذج بالقدرة على توليد كل من اللغة البشرية ولغة البروتين في كلا الاتجاهين: (أ) أخذ تسلسل البروتين كمدخل، والتنبؤ بالوصف الوظيفي النصي الخاص به؛ (ii) استخدام اللغة الطبيعية لتحفيز توليد تسلسل البروتين.

على وجه التحديد، قام الباحثون بتدريب LLM مسبقًا على البروتين ومجموعات اللغة الطبيعية، ثم استخدموا ضبط التعليمات الخاضعة للإشراف لتسهيل محاذاة اللغتين المختلفين. يؤدي InstructProtein أداءً جيدًا في عدد كبير من مهام إنشاء نصوص البروتين ثنائية الاتجاه. لقد اتخذت خطوة رائدة في مجال التنبؤ بوظيفة البروتين وتصميم التسلسل المستند إلى النصوص، مما أدى بشكل فعال إلى تضييق الفجوة بين البروتين وفهم اللغة البشرية.
تم اختيار الورقة البحثية، التي تحمل عنوان "InstructProtein: محاذاة اللغة البشرية والبروتينية من خلال تعليمات المعرفة"، لـ ACL 2024.
* الورقة الأصلية:https://arxiv.org/pdf/2310.03269
أيضًا،كما تعاون فريق جامعة سيدني للتكنولوجيا مع فريق البحث بجامعة تشجيانغ لإطلاق نموذج اللغة الكبير ProtChatGPT.يتعلم النموذج ويفهم بنية البروتين، مما يسمح للمستخدمين بتحميل الأسئلة المتعلقة بالبروتين والمشاركة في محادثات تفاعلية، مما يؤدي في النهاية إلى توليد إجابات شاملة.
على وجه التحديد، تمر البروتينات أولاً عبر مشفرات البروتين ومحول لغة البروتين المدرب مسبقًا (PLP-former) لتوليد تضمينات البروتين، ثم يتم إسقاط هذه التضمينات على LLM من خلال محول الإسقاط. أخيرًا، يجمع برنامج LLM بين أسئلة المستخدم والتضمينات المتوقعة لتوليد إجابات مفيدة. تظهر التجارب أن ProtChatGPT يمكنه توليد استجابات احترافية للبروتينات والأسئلة المقابلة لها، مما يضفي حيوية جديدة على الاستكشاف المتعمق وتوسيع نطاق تطبيقات أبحاث البروتين.
* الورقة الأصلية:https://arxiv.org/abs/2402.09649
في المستقبل، عندما تصبح نماذج اللغة الكبيرة قادرة على استخدام بيانات ضخمة وغنية لاستنتاج القوانين الأساسية أو الهياكل العميقة للبروتينات التي تتجاوز بكثير حدود الإدراك البشري، فإن إمكاناتها سوف تنطلق إلى حد كبير. نتوقع أنه مع التقدم المستمر للتكنولوجيا، فإن نماذج اللغة الكبيرة سوف تقود أبحاث البروتين إلى مستقبل أكثر إشراقا.








