Command Palette
Search for a command to run...
إنجاز كبير في مجال الرقائق البصرية المحلية! يستخدم فريق تسينغهوا الشبكة العصبية لإنشاء أول بنية تدريبية للحوسبة البصرية الذكية الكاملة

منذ عام 2012، تضاعفت قوة الحوسبة المطلوبة لتدريب نماذج الذكاء الاصطناعي كل 3-4 أشهر، وزادت قوة الحوسبة المطلوبة لنماذج تدريب الذكاء الاصطناعي بما يصل إلى 10 مرات كل عام. وهذا يمثل تحديا:كيف نجعل الذكاء الاصطناعي أسرع وأكثر كفاءة؟ ربما تكمن الإجابة في عالم النور.
الحوسبة البصرية،مجال مليء بالإمكانيات والذي يدعي تسخير سرعة وخصائص الضوء لتقديم مستويات جديدة من السرعة وكفاءة الطاقة لتطبيقات التعلم الآلي. ولكن لتحقيق هذا الهدف، يتعين علينا حل مشكلة صعبة: كيفية تدريب هذه النماذج البصرية بكفاءة. في الماضي، اعتمد الناس على أجهزة الكمبيوتر الرقمية لمحاكاة وتدريب الأنظمة البصرية، ولكن قدرات الأنظمة البصرية كانت محدودة للغاية بسبب النماذج الدقيقة والكميات الكبيرة من بيانات التدريب المطلوبة للأنظمة البصرية. وعلاوة على ذلك، ومع تزايد تعقيد النظام، أصبحت هذه النماذج أكثر صعوبة في البناء والصيانة.
حديثاً،استولى فريق البحث بقيادة الأكاديمي داي تشيونغهاي والأستاذ فانغ لو من جامعة تسينغهوا على تناسق انتشار الفوتون، ومساواة الانتشار الأمامي والخلفي في تدريب الشبكة العصبية بالانتشار الأمامي للضوء، وطوروا طريقة التعلم في الوضع الأمامي الكامل (FFM).ومن خلال التعلم باستخدام FFM، لا يتمكن الباحثون من تدريب الشبكات العصبية البصرية العميقة (ONNs) بملايين المعلمات فحسب، بل يحققون أيضًا إدراكًا فائق الحساسية ومعالجة بصرية فعالة، وبالتالي تخفيف قيود الذكاء الاصطناعي على نمذجة النظام البصري.
تم نشر البحث، الذي يحمل عنوان "التدريب الكامل للوضع الأمامي للشبكات العصبية البصرية"، بنجاح في المجلة الرائدة Nature.
أبرز الأبحاث:
* تمكين التوازي الفعال لعمليات التعلم الآلي في الميدان، مما يخفف من قيود النمذجة العددية
* تم تقديم أنظمة بصرية متطورة لحجم شبكة معين، وأظهر التعلم FFM أيضًا أن تدريب أعمق الشبكات العصبية البصرية بملايين المعلمات يمكن أن يحقق دقة مماثلة للنماذج المثالية
* لا يسهل تعلم FFM عملية التعلم بشكل أسرع بكثير فحسب، بل يمكنه أيضًا تعزيز تطوير شبكات التعلم العميق العصبية، والإدراك الفائق الحساسية، والفوتونيات الطوبولوجية.

عنوان الورقة:
https://doi.org/10.1038/s41586-024-07687-4
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
7 تجميع مجموعة بيانات كبيرة لإنشاء حقول إدخال معقدة مع ضبط الطور على الصفر في تجارب التصنيف متعدد الطبقات
تم استخدام ما مجموعه 7 مجموعات بيانات في هذه الدراسة. في تجارب التصنيف متعدد الطبقات، تم استخدام كل عينة لإنشاء حقل معقد للإدخال مع ضبط الطور على الصفر:
* مجموعة بيانات MNIST.تتكون مجموعة البيانات من مجموعة من الأرقام المكتوبة بخط اليد في 10 فئات، وتتكون من 60,000 عينة تدريبية و10,000 عينة اختبار.
* مجموعة بيانات Fashion-MNIST.تحتوي مجموعة البيانات على 10 فئات مختلفة من منتجات الأزياء وتتكون أيضًا من مجموعة تدريب مكونة من 60000 عينة ومجموعة اختبار مكونة من 10000 عينة.
* مجموعة بيانات CIFAR-10.تُعد مجموعة البيانات هذه جزءًا من مجموعة بيانات الصور الصغيرة التي تحتوي على 80 مليون صورة، وتحتوي على 50000 صورة تدريبية و10000 صورة اختبار.
* مجموعة بيانات ImageNet.مجموعة البيانات عبارة عن قاعدة بيانات صور تتكون من تسلسل WordNet حيث يتم تمثيل كل عقدة بمئات إلى آلاف الصور، بإجمالي 120 مليون صورة للتدريب و50000 صورة للاختبار.
* مجموعة بيانات MWD.تحتوي مجموعة البيانات على صور لأربعة ظروف جوية مختلفة للمشاهد الخارجية (شروق الشمس، مشمس، ممطر، وغائم). ويحتوي على إجمالي 1125 عينة، منها 800 عينة تستخدم للتدريب و325 عينة للاختبار.
* مجموعة بيانات زهرة السوسن.تتكون مجموعة البيانات من 3 أنواع من زهور السوسن، كل منها يحتوي على 50 عينة. يحتوي كل مثال أصلي في مجموعة البيانات على أربعة إدخالات تصف شكل زهرة السوسن. في تجربة PIC، تم تكرار كل إدخال لإنشاء أربع نقاط بيانات متطابقة، مما أدى إلى إجمالي 16 قناة من بيانات الإدخال.
* مجموعة بيانات هدف الكروم.تتكون مجموعة البيانات من ألواح كروم زجاجية ذات مناطق مختلفة (عاكسة وشبه شفافة). تمثل مناطق الانعكاس المشاهد المادية نفسها (أهداف الحروف T وH وU)، وخلال التدريب، تم استخدام منطقة انعكاس واحدة ونقلها في نفس المستوى لتوليد 9 مشاهد تدريبية مختلفة.
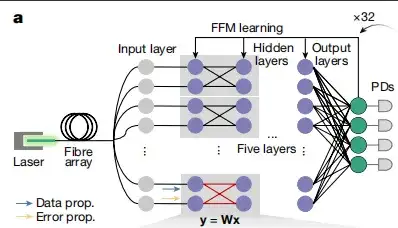
إعادة تحديد معلمات النظام البصري وبناء شبكة عصبية فوتونية مدمجة قابلة للتفاضل FFM
تقليديا، يتم تصميم الذكاء الاصطناعي المرتبط بالبصريات من خلال النمذجة والتحسين دون اتصال بالإنترنت، كما هو موضح في الشكل (أ) أدناه، مما يؤدي إلى كفاءة تصميم محدودة وأداء النظام. بالإضافة إلى ذلك، من أجل تحقيق وظائف مختلفة، تستخدم الأنظمة البصرية العامة ضبط مؤشر الانكسار.ينقسم النظام البصري إلى منطقتين مختلفتين: مناطق التعديل (الأخضر الداكن) ومناطق الانتشار (الأخضر الفاتح).كما هو موضح في الشكل ب أدناه.
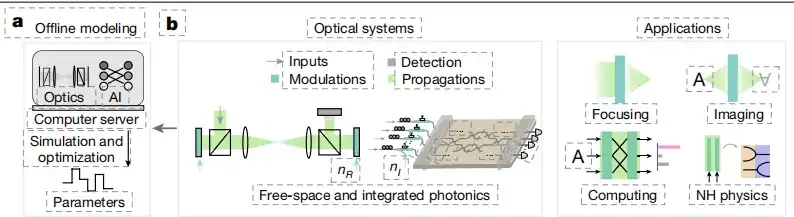
توصلت الدراسة إلى أن الأنظمة البصرية التي يتم التحكم فيها بواسطة معادلات ماكسويل يمكن إعادة معاملتها إلى شبكات عصبية فوتونية مدمجة قابلة للتفاضل، وكان تدريب الانحدار التدرجي للشبكات العصبية عاملاً رئيسيًا في دفع تطويرها. لذلك،يظهر مبدأ التعلم الآلي لـ FFM في هذه الدراسة في الشكل ج أدناه.نظرًا لأنه يمكن تعيين أجزاء من النظام البصري في شبكة عصبية وتوصيلها بالخلايا العصبية، فمن الممكن إنشاء شبكة عصبية قابلة للتفاضل في الموقع بين المدخلات والمخرجات.
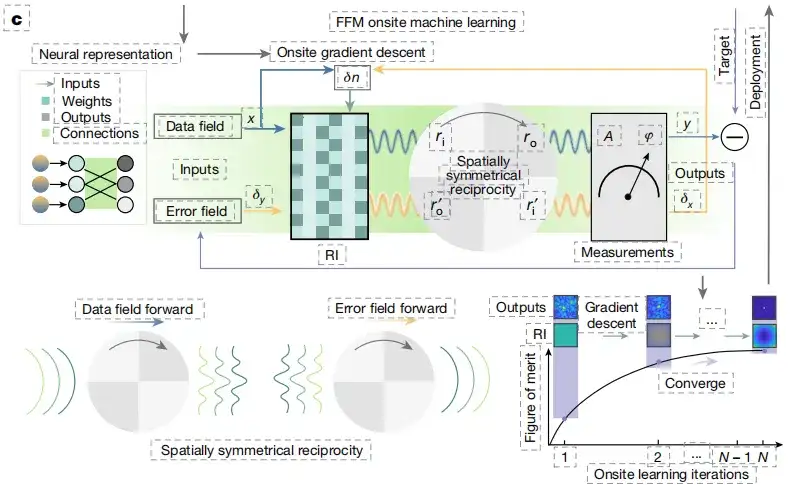
بعد ذلك، استغلت الدراسة التبادلية التناظرية المكانية، والانتشار الفيزيائي المشترك للأمام وقياس البيانات وحسابات الأخطاء، وتم حساب التدرجات في الموقع لتحديث معامل الانكسار في منطقة التصميم (المناطق العلوية اليمنى والسفلى اليسرى في الشكل ج). من خلال النزول التدرجي في الموقع، يتقارب النظام البصري تدريجيًا (المنطقة اليمنى السفلية في الشكل ج).
تدريب شبكة عصبية بصرية أحادية الطبقة لتصنيف الكائنات، يحقق التعلم باستخدام FFM دقة مماثلة للنموذج المثالي
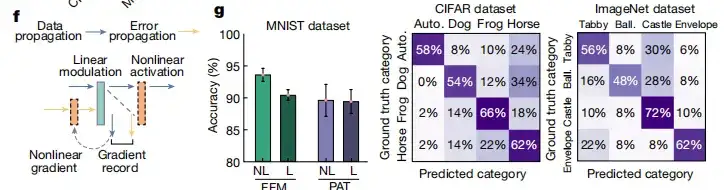
ولإثبات فعالية التعلم FFM، قامت الدراسة أولاً بتدريب شبكة عصبية بصرية أحادية الطبقة لتصنيف الكائنات باستخدام مجموعة بيانات معيارية، ثم أظهرت عملية التدريب الذاتي للشبكة العصبية البصرية في الفضاء الحر العميق باستخدام التعلم FFM في الشكل 1أ، وتصور نتائج تدريبها على مجموعة بيانات MNIST في الشكل 1ب.
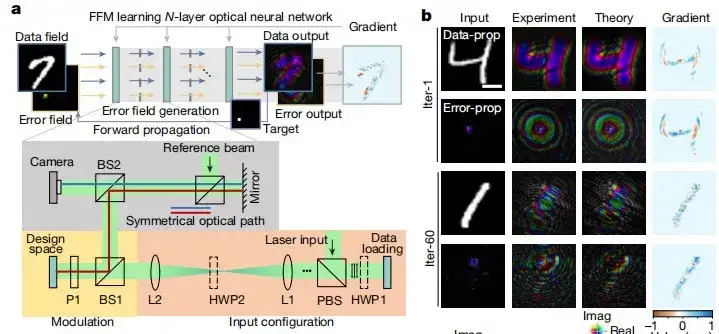
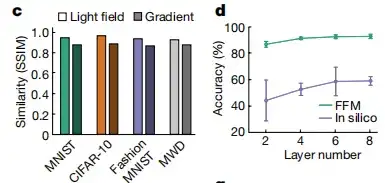
كما هو موضح في الشكل ج أدناه،يتجاوز مؤشر التشابه البنيوي (SSIM) بين المجالات الضوئية التجريبية والنظرية 0.97.وهذا يشير إلى مستوى عال من التشابه. في الشكل د أدناه، قامت الدراسة بتحليل استخدام الشبكات العصبية البصرية متعددة الطبقات لتصنيف مجموعة بيانات Fashion-MNIST. من خلال زيادة عدد الطبقات تدريجيًا من 2 إلى 8، وجدت الدراسة أن استخدام التعلم FFM،يمكن تحسين أداء الشبكة العصبية إلى 86.5%، 91.0%، 92.3% و 92.5%، وهو قريب من دقة المحاكاة الحاسوبية النظرية.
وبناءً على النتائج المذكورة أعلاه، اقترحت هذه الدراسة أيضًا التعلم غير الخطي FFM، كما هو موضح في الشكل f أدناه. أثناء انتشار البيانات، يتم تنشيط المخرجات بشكل غير خطي قبل الدخول إلى الطبقة التالية، بحيث يمكن تسجيل مدخلات التنشيط غير الخطي وحساب التدرجات ذات الصلة. نظرًا لأن الانتشار الأمامي فقط هو المطلوب، فإن نموذج التدريب غير الخطي الذي اقترحه FFM ينطبق على الوظائف غير الخطية القابلة للقياس بشكل عام وبالتالي ينطبق على الشبكات العصبية البصرية غير الخطية الإلكترونية والبصرية بالكامل. ليس هذا فقط،ارتفعت دقة تصنيف الشبكة العصبية البصرية غير الخطية من 90.4% إلى 93.0%.كما هو موضح في الشكل (ج) أدناه.
يُبسط تعلم FFM تصميم الأنظمة الفوتونية المعقدة، مما يتيح إعادة بناء المشهد البصري بالكامل وتحليل الكائنات المخفية ديناميكيًا
ووجدت الدراسة أيضًا أنيتغلب التعلم باستخدام FFM على القيود المفروضة بواسطة النمذجة الرقمية غير المتصلة بالإنترنت ويبسط تصميم الأنظمة الفوتونية المعقدة.على سبيل المثال، تُظهر الدراسة نظام تصوير التشتت بمسح النقاط في الشكلين (أ) و(ب) أدناه على التوالي، وتحلل طرق التحسين المتقدمة المختلفة باستخدام تحسين سرب الجسيمات (PSO). وتظهر النتائج أن التعلم FFM القائم على التدرج يظهر كفاءة أعلى، ويتقارب بعد 25 تكرارًا للتصميم في كلتا التجربتين مع قيم خسارة التقارب 1.84 و2.07 في نوعي التشتت على التوالي. في المقابل، تتطلب طريقة PSO ما لا يقل عن 400 تكرار تصميم للتقارب، مع قيم خسارة نهائية تبلغ 2.01 و2.15.
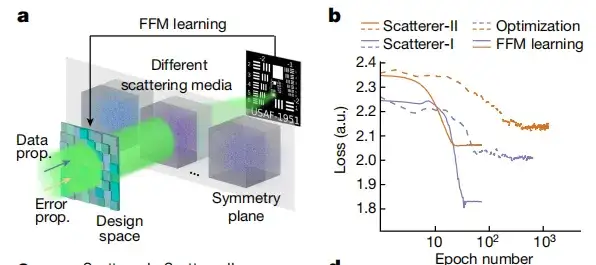
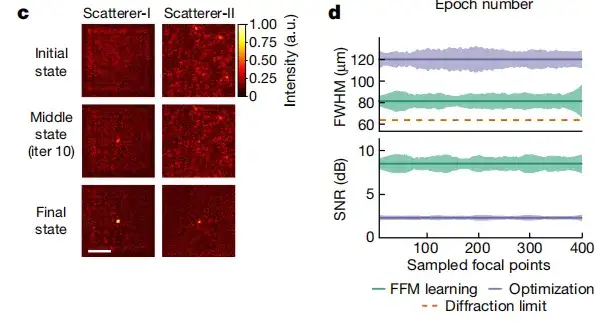
كما هو موضح في الشكل ج أدناه، قامت الدراسة بتحليل تطور التصميم الذاتي لـ FFM، مما يدل على أن ملف تعريف الكثافة الموزع عشوائيًا في البداية يتقارب تدريجيًا إلى نقطة ضيقة. في الشكل د أدناه، قامت الدراسة بمقارنة عرض كامل عند نصف الحد الأقصى (FWHM) ونسبة الإشارة إلى الضوضاء القصوى (PSNR) لتحسين التركيز باستخدام FFM وPSO. في حالة استخدام FFM، يبلغ متوسط FWHM 81.2 ميكرومتر ومتوسط PSNR 8.46 ديسيبل.
ووجدت الدراسة أيضًا أنيوفر التعلم FFM الموضعي أداة قيمة لتصميم وسائل التصوير غير التقليدية، خاصة في المواقف التي لا يكون فيها النمذجة الدقيقة ممكنة.مثل المهام غير المباشرة (NLOS) وغيرها من السيناريوهات. كما هو موضح في الشكل (أ) أدناه، يتيح التعلم باستخدام FFM إعادة بناء المشهد البصري بالكامل وتحليل الكائنات الديناميكية المخفية. يوضح الشكل ب أدناه التصوير NLOS. استعادت الموجة الأمامية التي صممها FFM أشكال الحروف الثلاثة، ووصل مؤشر التشابه البنيوي لكل هدف إلى 1.0.
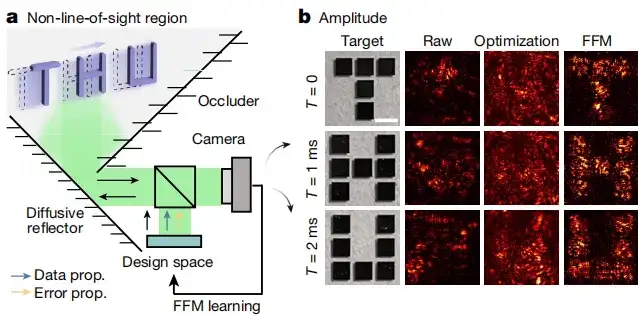
بالإضافة إلى قدرة التصوير الديناميكي، يسمح نهج التعلم FFM بالتصنيف البصري الكامل للأشياء المخفية في مناطق NLOS. قارنت هذه الدراسة أداء التصنيف لـ FFM مع أداء الشبكة العصبية الاصطناعية (ANN). وتظهر النتيجة في الشكل ج أدناه.في حالة وجود فوتونات كافية، فإن FFM وANN لهما أداء مماثل، لكن FFM يتطلب عددًا أقل من الفوتونات للتصنيف الدقيق.
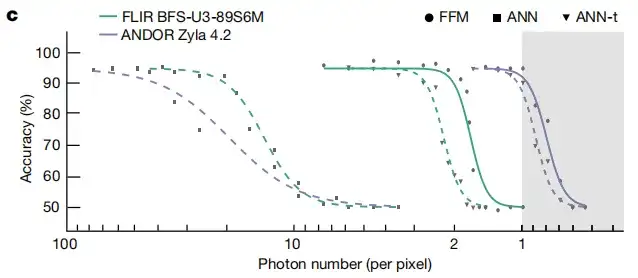
يمكن توسيع نطاق تعلم FFM ليشمل التصميم الذاتي للأنظمة الفوتونية المتكاملة. تستغرق المحاكاة حوالي 100 دورة حتى تتقارب.
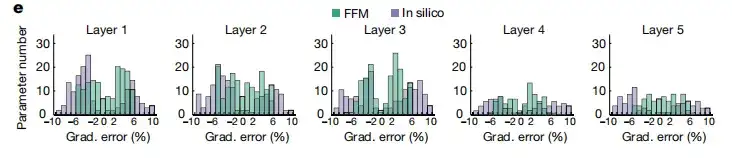
توصلت الدراسة إلى أن أسلوب التعلم FFM يمكن أن يمتد إلى التصميم الذاتي للأنظمة الفوتونية المتكاملة. كما هو موضح في الشكل أ أدناه، تستخدم هذه الدراسة شبكة عصبية متكاملة مكونة من نوى فوتونية متماثلة متصلة على التوالي وبالتوازي لتحقيق التعلم FFM. تبين أن تماثل المصفوفات يسمح لمصفوفة انتشار الخطأ ومصفوفة انتشار البيانات أن تكون متكافئة.
يوضح الشكل (هـ) أدناه خطأ الشبكة العصبية بأكملها. وتظهر النتائج أنه في التكرار الثمانين،يظهر تعلم FFM أخطاء تدرج أقل من تدريب المحاكاة الحاسوبية.
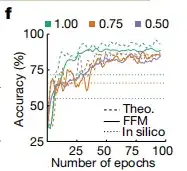
في تطور دقة التصميم، كما هو موضح في الشكل (و) أدناه،يتطلب كل من المحاكاة المثالية وتجربة FFM حوالي 100 دورة للتقارب، ولكن طريقة FFM تتمتع بأفضل دقة.
لقد نضجت سلسلة صناعة الحوسبة البصرية الذكية تدريجيًا وقد تكون على أعتاب عصر جديد
ومن الجدير بالذكر أنه بناءً على نتائج البحث في هذه الورقة،أطلق فريق البحث رقاقة التدريب البصري "تاي تشي 2".استغرق تطوير "تاي تشي 2" 4 أشهر فقط بعد الجيل السابق "تاي تشي"، وتم نشر النتائج ذات الصلة أيضًا في مجلة Science. وتظهر النتائج التجريبية للورقة أنيعتبر Tai Chi أكثر كفاءة في استخدام الطاقة بمقدار 1000 مرة من H100 من Nvidia.تعتمد هذه القدرة القوية على الحوسبة على بنية الحوسبة البصرية الذكية واسعة النطاق والموزعة التي طورها فريق البحث.
رابط الورقة:
https://www.science.org/doi/10.1126/science.adl1203
مع إطلاق منتجات سلسلة Taichi الجديدة، أشعلت الحوسبة البصرية الذكية الصناعة مرة أخرى.ولكن من منظور عملي، سواء كان الأمر يتعلق بالأجهزة المادية أو تطوير البرمجيات أو التطبيقات، فإن الحوسبة البصرية الذكية لا تزال بحاجة إلى مزيد من التحسين والاستكشاف. في الواقع، أصبح نظام البحث في الحوسبة البصرية الذكية ناضجًا بشكل متزايد. وقد شاركت العديد من المؤسسات والجامعات مثل جامعة بكين وجامعة تشجيانغ وجامعة هواتشونغ للعلوم والتكنولوجيا في هذا البرنامج، وأصبحت التبادلات الأكاديمية ذات الصلة متكررة بشكل متزايد. ومع ذلك، من حيث اتجاهات التطبيق المحددة، فإن فرق البحث التي يمثلها شخصيات بارزة من جامعات مختلفة تركز على مجالات مختلفة. على سبيل المثال:
* فريق الأكاديمي داي تشيونغهاي من جامعة تسينغهوا:هذا الفريق هو مؤلف هذه الورقة. وقد أكملت شريحة الاندماج البصري الإلكتروني من الجيل التالي التي طوروها تجارب في سيناريوهات التطبيق مثل التعرف الذكي على الصور، ومشاهد المرور، والاستيقاظ على الوجه. وتشير التقارير إلى أنه بنفس الدقة، أدت نتائج أبحاث الفريق إلى زيادة قوة الحوسبة لوحدات معالجة الرسومات الحالية بمقدار 3000 مرة وكفاءة الطاقة بمقدار 4 ملايين مرة، ومن المتوقع أن تعمل على تقويض أفكار الحوسبة التقليدية في مجالات مثل القيادة الذاتية، ورؤية الروبوت، والأجهزة المحمولة.
* فريق دونغ جيانجي من جامعة هواتشونغ للعلوم والتكنولوجيا:تمكنت الشريحة الهجينة البصرية الإلكترونية التي طورها الفريق من استكمال تطبيق التعرف على التعبير البشري.
* فريق شو شاوفو من جامعة شنغهاي جياو تونغ:تم تطبيق سلسلة رقائق الاندماج الضوئية الإلكترونية التي طورها الفريق في الذكاء الاصطناعي ومعالجة الإشارات وغيرها من المجالات، وأكملت التجارب الحسابية في إعادة بناء الصور الطبية وغيرها من الجوانب.
والخبر السار هو أنه بفضل الجهود المتواصلة التي يبذلها الباحثون، أصبح تقدم شرائح الحوسبة البصرية الذكية في بلدي مساوياً بشكل أساسي لتقدمها في البلدان الأجنبية. على مدى السنوات الخمس الماضية، ارتفع عدد الشركات العاملة في مجال الحوسبة البصرية بسرعة من بضع شركات إلى عشرات الشركات في جميع أنحاء العالم. وعلى الصعيد الدولي، تعد شركة Luminous Computing، التي تلتزم ببناء الحاسوب العملاق للذكاء الاصطناعي الرائد في العالم، وشركة Lightmatter، التي تستخدم التكنولوجيا الفوتونية لتحسين الأداء وتوفير الطاقة في أحمال عمل الذكاء الاصطناعي والحوسبة عالية الأداء. وقد حصلت الشركتان على تمويل يزيد عن 100 مليون دولار أمريكي.
وفي الصين، انضمت أيضًا الشركات الممثلة بشركتي Xizhi Technology وPhotonic Arithmetic إلى المنافسة الدولية لصناعة الحوسبة البصرية.تُركز جميع هذه الشركات الناشئة على الحوسبة البصرية، مع التركيز على مسرعات الحوسبة البصرية القائمة على الرقائق البصرية، كما تقوم أيضًا بدعم البحث والتطوير في مجال البرمجيات والأنظمة والآلات الأساسية. باختصار، نضجت سلسلة صناعة الحوسبة البصرية في بلدي تدريجياً، وأصبح نظام الصناعة والجامعات والبحث ذي الصلة يعمل بفعالية وكفاءة. ونتوقع أيضًا أنه في هذا العصر الجديد، يمكن للحوسبة البصرية الذكية أن توفر زخمًا قويًا لتطوير الاقتصاد الرقمي والإنتاجية الجديدة.








