Command Palette
Search for a command to run...
أصبحت مجموعة بيانات الضبط الدقيق الصينية Llama 3.1 متاحة الآن على الإنترنت، ويمكن نشر النماذج الكبيرة بنقرة واحدة

كانت دائرة الذكاء الاصطناعي في شهر يوليو مليئة بالنماذج الصغيرة والنماذج الكبيرة، وكان الأمر مثيرًا! يمكن لمعظم الطلاب تجربة النماذج الصغيرة مثل GPT-4o و Mistral-Nemo، ولكن النماذج الكبيرة جدًا مثل Llama-3.1-405B و Mistral-Large-2 تجعل العديد من الطلاب يشعرون بالانزعاج.
لا تقلق!يوفر الموقع الرسمي لـ hyper.ai دروسًا تعليمية في قسم الدروس التعليمية لبدء تشغيل هذين النموذجين الكبيرين باستخدام "Open WebUI" و"خدمة API المتوافقة مع OpenAI"!بالإضافة إلى ذلك، فإن مجموعة البيانات الصينية الدقيقة DPO-zh-en-emoji متاحة أيضًا على الإنترنت. قم بالتمرير لأسفل للحصول على الرابط~
من 5 أغسطس إلى 9 أغسطس، تحديثات الموقع الرسمي لـhyper.ai:
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 5
* مجموعات البيانات العامة عالية الجودة: 10
* اختيار المقالات المجتمعية: 3 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في أغسطس: 2
قم بزيارة الموقع الرسمي:هايبر.اي
دروس تعليمية عامة مختارة
1. استخدم Open WebUI لنشر Mistral Large 2 / Llama 3.1 405B بنقرة واحدة
يستخدم هذا البرنامج التعليمي OpenWebUI لنشر Mistral Large 2 / Llama 3.1 405B بنقرة واحدة. تم إعداد البيئة والتكوين المناسبين. كل ما عليك فعله هو استنساخ الحاوية وبدء تشغيلها لتجربة الاستدلال.
* تشغيل نشر نموذج Mistral Large 2 عبر الإنترنت:
* تشغيل نشر نموذج Llama 3.1 405B عبر الإنترنت:
2. نشر خدمة واجهة برمجة التطبيقات المتوافقة مع OpenAI من طراز Mistral Large 2 / Llama 3.1 405B بنقرة واحدة
يهدف هذا البرنامج التعليمي إلى نشر Mistral-Large-Instruct-2407-AWQ باستخدام واجهة برمجة التطبيقات المتوافقة مع OpenAI. تعني "واجهة برمجة التطبيقات المتوافقة مع OpenAI" أنه يمكن لمطوري الطرف الثالث استخدام نفس تنسيق الطلب والاستجابة مثل OpenAI لدمج وظائف مماثلة في تطبيقاتهم الخاصة. بعد بدء هذا البرنامج التعليمي، يمكنك الاتصال بهذا النموذج في أي SDK متوافق مع OpenAI. بالمقارنة مع البرنامج التعليمي السابق، فهو أكثر تعقيدًا وملائمًا لأولئك الذين لديهم فهم أساسي للبرمجة.
* تشغيل نشر نموذج Mistral Large 2 عبر الإنترنت:
* تشغيل نشر نموذج Llama 3.1 405B عبر الإنترنت:
3. استخدم Gibbs-Diffusion لإزالة الضوضاء العمياء من الصورة
GDiff تعني Gibbs-Diffusion، وهي طريقة إزالة الضوضاء العمياء البايزية التي تحل مشكلة أخذ العينات الخلفية لمعلمات الإشارة والضوضاء. هذا البرنامج التعليمي هو طريقة اختبار تعتمد على الورقة البحثية "الاستماع إلى الضوضاء: إزالة الضوضاء العمياء باستخدام Gibbs Diffusion". يمكنك تجربة نتائج البحث باتباع خطوات البرنامج التعليمي.
تشغيل عبر الإنترنت:https://go.hyper.ai/y2wIU
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الإجابة على أسئلة الرموز التعبيرية DPO-zh-en-emoji
تم تصميم مجموعة البيانات هذه لضبط نماذج اللغة الكبيرة. يحتوي على كمية كبيرة من أزواج الأسئلة والأجوبة. يحتوي كل سؤال على نسختين من الإجابة، الصينية والإنجليزية. وتتضمن الإجابات أيضًا عناصر ممتعة ومرحة، بما في ذلك استخدام الرموز التعبيرية. لقد استخدم فريق shareAI هذه التقنية لضبط نموذج Llama 3.1 8B.
الاستخدام المباشر:https://go.hyper.ai/Y90pZ
2. مجموعة بيانات معيارية لرسم خرائط الفيضانات من UrbanSARFloods الإصدار 1
UrbanSARFloods هي مجموعة بيانات مخصصة لرسم خرائط الفيضانات في المناطق الحضرية والمفتوحة، وتحتوي على 8,879 رقعة صور بحجم 512×512، تغطي 807,500 كيلومتر مربع وتغطي 18 حدثًا للفيضانات. ويحل هذا مشكلة عدم الاهتمام الكافي بالفيضانات الحضرية في دراسات رسم خرائط الفيضانات واسعة النطاق المشتقة من الرادار ذي الفتحة الاصطناعية.
الاستخدام المباشر:https://go.hyper.ai/yOXx7
3. مجموعة بيانات VRSBench المعيارية للغة البصرية عالية الجودة للاستشعار عن بُعد واسعة النطاق
مجموعة البيانات عبارة عن مجموعة بيانات مرجعية متعددة الأغراض للأغراض البصرية واللغوية مصممة لفهم صور الاستشعار عن بعد. يحتوي الكتاب على 29,614 صورة توضيحية مفصلة تم التحقق منها يدويًا، و52,472 مرجعًا للأشياء، و123,221 زوجًا من الأسئلة والأجوبة. ويهدف إلى تعزيز تطوير نماذج الاستشعار عن بعد للصور البصرية واللغوية العامة واسعة النطاق.
الاستخدام المباشر:https://go.hyper.ai/O7DtC
4. مجموعة بيانات نسيج الحروف ثلاثية الأبعاد عالية الدقة ATLAS
الاسم الكامل لهذه المجموعة من البيانات هو ArTicuLated humAn textureS (ATLAS للاختصار)، وهي أكبر مجموعة بيانات عالية الدقة (1,024 × 1,024) للنسيج البشري ثلاثي الأبعاد، وتحتوي على 50,000 نسيج عالي الدقة مع أوصاف نصية. وقد تم اختيار نتائج الورقة ذات الصلة لـ ECCV 2024.
الاستخدام المباشر:https://go.hyper.ai/Zx1nj
5. مجموعة بيانات أخبار MIND من مايكروسوفت
يحتوي MIND على ما يقرب من 160,000 مقالة إخبارية باللغة الإنجليزية وأكثر من 15 مليون سجل انطباع تم إنشاؤها بواسطة مليون مستخدم، والتي تم جمعها من سجلات سلوكية مجهولة لموقع Microsoft News. ويهدف إلى أن يكون بمثابة مجموعة بيانات مرجعية لتوصيات الأخبار وتعزيز البحث في مجال توصية الأخبار وأنظمة التوصية.
الاستخدام المباشر:https://go.hyper.ai/lVOyX
6. مجموعة بيانات تجزئة كشف الحرائق BoWFire
مجموعة بيانات BoWFire عبارة عن مجموعة بيانات صور مخصصة لاكتشاف اللهب، والتي تهدف إلى تحسين دقة اكتشاف الحرائق وتقليل الإنذارات الكاذبة. تتضمن مجموعة البيانات صور الحرائق في حالات الطوارئ المختلفة، مثل حرائق المباني، والحرائق الصناعية، وحوادث السيارات، وأعمال الشغب.
الاستخدام المباشر:https://go.hyper.ai/73AYY
7. مجموعة بيانات مقالة أخبار CNN/DailyMail
تحتوي مجموعة البيانات على أكثر من 300 ألف مقالة إخبارية كتبها صحفيو CNN وDaily Mail، وهي مصممة للمساعدة في تطوير نماذج يمكنها تلخيص فقرات طويلة من النص في جملة أو جملتين.
الاستخدام المباشر:https://go.hyper.ai/AbidL
8. مجموعة بيانات رسومات الخربشة مجموعة بيانات صور الخربشة
تحتوي مجموعة البيانات على أكثر من مليون صورة تغطي 340 فئة من فنون الجرافيتي، والتي يمكن معالجتها لمهام التعلم الآلي.
الاستخدام المباشر:https://go.hyper.ai/Ns4M4
9. مجموعة بيانات صور حركات اليوغا البشرية Yoga-16
تهدف مجموعة بيانات Yoga-16 إلى تحسين دقة تصنيف نماذج التعرف على وضعيات اليوغا. وهي مقسمة إلى ثلاثة مجلدات رئيسية: التدريب، والاختبار، والتحقق، وكل منها يحتوي على 16 مجلدًا فرعيًا يتوافق مع 16 وضعية يوغا مختلفة.
الاستخدام المباشر:https://go.hyper.ai/iMe0Z
10. مجموعة بيانات صور بشرية مجموعة بيانات صور بشرية للذكور والإناث
تحتوي مجموعة البيانات على مجلدين لصور فئتين للشخص: الذكر والأنثى. تتضمن الصور الوجوه والجذوع العلوية والأجسام الكاملة. يمكن استخدامه في مشاريع مختلفة مثل التعرف على الجنس، وتحديد هوية الإنسان، وتصنيف الصور.
الاستخدام المباشر:https://go.hyper.ai/6UJb7
لمزيد من مجموعات البيانات العامة، يرجى زيارة:
https://hyper.ai/datasets
مقالات المجتمع
تمت دعوة لي يوزهي، زميل ما بعد الدكتوراه في مختبر تشانغ تشيانغفينغ بجامعة تسينغهوا، إلى الحلقة الثانية من سلسلة البث المباشر "Meet AI4S". في 21 أغسطس، سيشارك الدكتور لي يوزهي المزيد من أساليب الذكاء الاصطناعي في أبحاث النسخ المكاني وأوميكس الخلية الواحدة مع الجميع في شكل بث مباشر عبر الإنترنت.
عرض تفاصيل الحدث:https://go.hyper.ai/GIzpo
تعاونت Google Research وMIT للفوز بجائزة IJCAI 2024 لأفضل ورقة بحثية! قم بالرد على IJCAI 2024 في الحساب الرسمي لـ WeChat للحصول على مجموعة من جائزة أفضل ورقة بحثية لـ IJCAI 2024 وجائزة الورقة البحثية المتميزة وجائزة AIJ Classic Paper وجائزة الورقة البحثية المتميزة.
شاهد التقرير الكامل:https://go.hyper.ai/ZGzI2
عمل الفريق بقيادة البروفيسور هوانغ تيانين، نائب رئيس الجامعة ومدير كلية الطب بجامعة تسينغهوا، والفريق بقيادة البروفيسور شنغ بين من قسم علوم الكمبيوتر، كلية الهندسة الكهربائية، جامعة شنغهاي جياو تونغ / المختبر الرئيسي للذكاء الاصطناعي التابع لوزارة التعليم، والفريق بقيادة البروفيسور جيا ويبينغ والبروفيسور لي هواتينج من مستشفى الشعب السادس التابع لكلية الطب بجامعة شنغهاي جياو تونغ، والفريق بقيادة البروفيسور تشين يوزونج من الجامعة الوطنية في سنغافورة والمركز الوطني للعيون في سنغافورة معًا لبناء أول نظام نموذجي متكامل للغة الرؤية الكبيرة في العالم DeepDR-LLM لتشخيص وعلاج مرض السكري بنجاح. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/qnzSp
مقالات موسوعية شعبية
1. التقاطع فوق الاتحاد (IoU)
2. دمج الفرز المتبادل RRF
3. التعلم التبايني
4. فهم اللغة متعدد المهام على نطاق واسع (MMLU)
5. الذاكرة طويلة المدى والذاكرة قصيرة المدى الذاكرة طويلة المدى
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
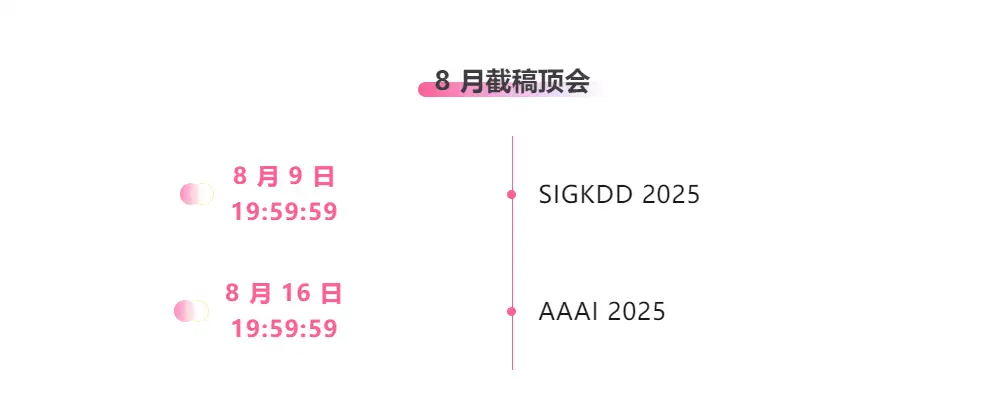
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1300 مجموعة بيانات عامة
* يتضمن أكثر من 400 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 100 حالة بحثية من AI4Science
* دعم البحث عن أكثر من 500 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








