Command Palette
Search for a command to run...
مجموعة البيانات المرجعية الجديدة في علم الأحياء LAB-Bench أصبحت الآن مفتوحة المصدر! تغطية 8 مهام رئيسية، وأكثر من 2.4 ألف سؤال اختيار من متعدد

عندما يستقبلك صديق أجنبي بسؤال "كيف حالك؟" ما هو رد فعلك الأول؟
أليس هذا هو القول الكلاسيكي: "أنا بخير، شكرًا لك، وأنت أيضًا"؟
في الحقيقة،لا يوجد هذا النوع من أسلوب الأسئلة والأجوبة في الكتب المدرسية في تعلمنا وتواصلنا باللغة الإنجليزية فحسب، بل يوجد أيضًا في تدريب واختبار نماذج اللغة الكبيرة.
في الوقت الحاضر، أصبح استخدام نماذج اللغة الكبيرة (LLMs) وأنظمة LLM المحسنة في البحث في مجالات مثل علم الأحياء وعلوم البحار وعلوم المواد لتحسين كفاءة البحث العلمي وإنتاجه محورًا رئيسيًا للعديد من العلماء. على سبيل المثال،أطلق فريق جامعة تشجيانغ نموذج اللغة الكبيرة OceanGPT في مجال المحيط.وقد طورت شركة مايكروسوفت نموذج اللغة الكبير BioGPT في مجال الطب الحيوي، واقترحت جامعة شنغهاي جياو تونغ نموذج اللغة الكبير K2 في مجال علوم الأرض.
ومن الجدير بالذكر أنمع تزايد شعبية برامج الماجستير في القانون في مجال البحث العلمي، أصبح من الضروري إنشاء مجموعة من معايير التقييم عالية الجودة والمهنية.
ومع ذلك، هناك العديد من المعايير التي تركز على تقييم معرفة طلاب الماجستير في القانون وقدراتهم على التفكير في المشكلات العلمية الموجودة في الكتب المدرسية.من الصعب تقييمه أداء ماجستير القانون في مهام البحث العلمي العملي مثل استرجاع الأدبيات، وتخطيط البرامج، وتحليل البيانات،ويؤدي هذا إلى ظهور نقص واضح في المرونة والاحترافية في النموذج عند التعامل مع المهام العلمية الفعلية.
لتعزيز التطوير الفعال لأنظمة الذكاء الاصطناعي في علم الأحياء،أطلق الباحثون في شركة FutureHouse Inc. مجموعة بيانات معيار علم الأحياء للوكيل اللغوي (LAB-Bench).يحتوي LAB-Bench على أكثر من 2400 سؤال اختيار من متعدد لتقييم أداء أنظمة الذكاء الاصطناعي في البحث البيولوجي الفعلي مثل استرجاع الأدبيات والاستدلال (LitQA2 و SuppQA)، والتفسير الرسومي (FigQA)، وتفسير الجدول (TableQA)، والوصول إلى قاعدة البيانات (DbQA)، وكتابة البروتوكول (ProtocolQA)، وفهم ومعالجة تسلسلات الحمض النووي والبروتين (SeqQA)، وسيناريوهات الاستنساخ (CloningScenarios).
تم تقديم البحث، الذي يحمل عنوان "LAB-Bench Measuring Capabilities of Language Models for Biology Research"، إلى المؤتمر الرائد NeurlPS 2024.
* مجموعة بيانات معيارية لنموذج لغة مختبر علم الأحياء:
https://go.hyper.ai/kMe1e
وأكد صامويل جي. رودريكس، المؤلف المراسل للورقة البحثية، ما يلي:باعتبارها مجموعة التقييم الأولى التي تركز على تقييم ما إذا كانت النماذج والوكلاء قادرين على إجراء البحوث العلمية، تستخدم LAB-Bench طريقة تقييم برمجية للمهام المعقدة، والتي ستكون مهمة للغاية في المستقبل.
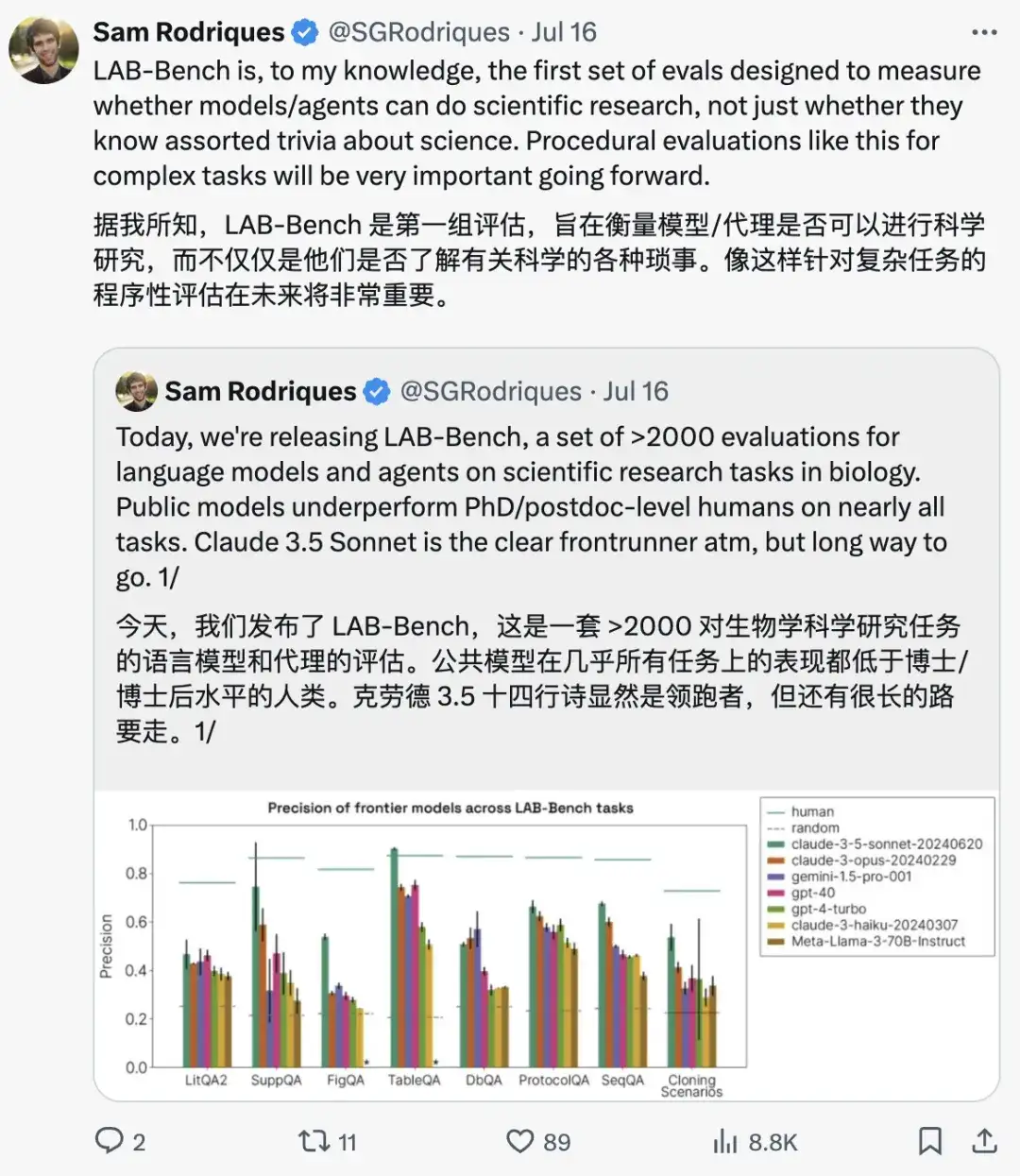
الأسئلة النموذجية من فئات مختلفة من LAB-Bench هي كما يلي:
التعدين العميق لتقييم قدرة النموذج على استرجاع الأدبيات والتفكير فيها
لتقييم قدرات الاسترجاع والاستدلال للنماذج المختلفة في الأدبيات العلمية،المجموعات الفرعية LAB-Bench التي يتم استخدامها بشكل شائع هي تلك المقابلة لمهام LitQA2 وSuppQA وDbQA. تعتبر هذه الأنواع الثلاثة مناسبة لجوانب مختلفة من توليد تعزيز الاسترجاع العلمي (RAG).
*الجيل المعزز بالاسترجاع (RAG) هو تقنية تستخدم المعلومات من مصادر بيانات خاصة أو مملوكة للمساعدة في إنشاء النص.
يقيس معيار LitQA2 قدرة النماذج على استرجاع المعلومات من الأدبيات العلمية.وهو يتألف من أسئلة اختيارية متعددة تظهر إجاباتها عادة مرة واحدة فقط في الأدبيات العلمية ولا يمكن الإجابة عليها من المعلومات الموجودة في الملخص (أي أن الأدبيات العلمية جديدة نسبيًا). في هذه العملية، لا يحتاج الباحثون إلى أن يكون النموذج قادرًا على الإجابة على الأسئلة من خلال تذكر بيانات التدريب فحسب، بل يحتاجون أيضًا إلى أن يكون النموذج قادرًا على الوصول إلى الأدبيات والقدرات الاستدلالية.
يتطلب SuppQA من النموذج العثور على المعلومات الموجودة في المواد التكميلية للورقة وتفسيرها.وأوضح الباحثون أنه للإجابة على هذه الأسئلة، يجب على النموذج الوصول إلى المعلومات الموجودة في ملفات تكميلية معينة.
تتطلب مشكلات DbQA من النماذج الوصول إلى المعلومات واسترجاعها من قواعد البيانات العامة الخاصة بعلم الأحياء.تم تصميم هذه الأسئلة لتغطية مجموعة واسعة من مصادر البيانات، وليس من الممكن للنموذج أو الوكيل الإجابة على جميع الأسئلة باستخدام واجهة برمجة تطبيقات واحدة.
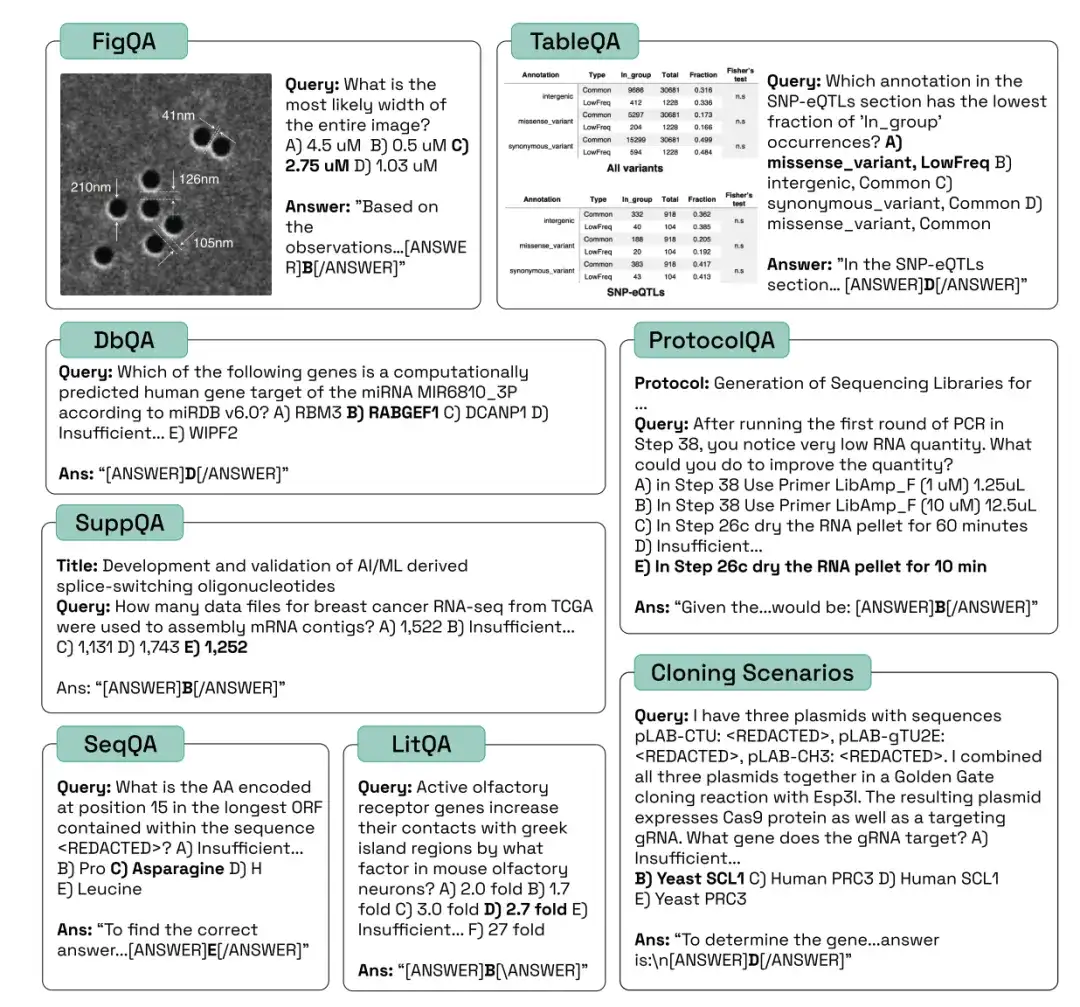
كما هو موضح في الشكل أدناه، قام الباحثون بتقييم أداء الإنسان، والعشوائي، وclaude-3-5-sonnet-20240620، وclaude-3-opus-20240229، وgemini-1.5-pro-001، وgpt-4o، وgpt-4-turbo، وclaude-3-haiku-20240307، وmetaa-3-70B-Instruct في الفئات الثلاث المذكورة أعلاه من مهام المعايير البيولوجية، وقارنوا دقتها ودقتها وتغطيتها.
في اختبار LitQA2، كان أداء جميع النماذج مشابهًا في فئة استدعاء الأدبيات في LitQA2، مع درجات أعلى بكثير من التوقعات العشوائية، حيث وصلت إلى أكثر من 40%. ومع ذلك، فإن النماذج السائدة غالباً ما ترفض الإجابة، وبعضها يجيب بمعدل أقل من 20%، مما يجعل دقة هذه النماذج أقل بكثير من المستويات العشوائية.
*لكل سؤال، لدى النموذج خيار محدد لرفض الإجابة بسبب عدم كفاية المعلومات
في اختبار SuppQA، كان أداء جميع النماذج ضعيفًا وكان لديها أدنى تغطية إجمالية. ويرجع ذلك إلى أن النماذج يُطلب منها استرجاع المعلومات الموجودة في المواد التكميلية، مما يشير إلى أن المعلومات التكميلية للورقة قد لا تكون ممثلة مثل النص الرئيسي في مجموعة تدريب النموذج.
في أسئلة DbQA، تكون تغطية النموذج أقل من التوقع العشوائي، مما يعني أن النموذج غالبًا ما يرفض الإجابة على أسئلة DbQA، مما يؤدي إلى انخفاض الدقة.
SeqQA، معيار لاستكشاف فائدة الذكاء الاصطناعي في تفسير التسلسل البيولوجي
لتقييم قدرة النموذج على تفسير التسلسلات البيولوجية،يتم استخدام مهمة SeqQA المقابلة في مجموعة بيانات معيار LAB-Bench. ويغطي خصائص التسلسل المختلفة، والمهام العملية الشائعة في سير عمل علم الأحياء الجزيئي، وفهم وتفسير العلاقات بين تسلسلات الحمض النووي، والحمض النووي الريبي، والبروتين.
في مهمة SeqQA، يوضح تقييم النماذج البشرية والعشوائية والمختلفة أن النموذج يمكنه الإجابة على معظم أسئلة SeqQA. دقة كل نموذج تتراوح بين 40%-50%، وهي أعلى بكثير من التوقعات العشوائية. وهذا يوضح أن النموذج لديه القدرة على التفكير فيما يتعلق بالحمض النووي وتسلسلات البروتين ومهام البيولوجيا الجزيئية.
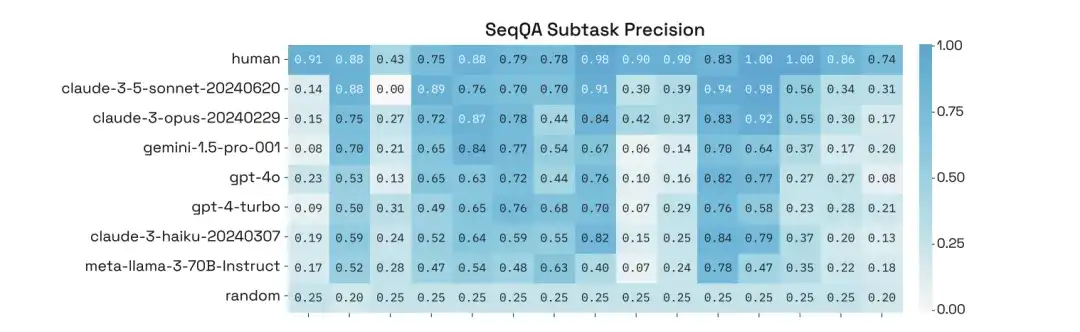
بالإضافة إلى ذلك، أجرى الباحثون تحليلاً معمقًا لأدائهم في مهام فرعية محددة من SeqQA ووجدوا أن دقة النماذج في المهام الفرعية المختلفة تباينت بشكل كبير، حيث حققت بعض المهام دقة تزيد عن 90%.
من الرسوم البيانية إلى البروتوكولات، تقييم القدرة على التفكير الأساسي للنماذج
لتقييم قدرة التفكير الأساسية للنموذج،يتم استخدام FigQA وTableQA وProtocolQA.
في،يقيس مقياس FigQA قدرة طلاب الماجستير في القانون على فهم الرسوم البيانية العلمية والتفكير فيها.تحتوي أسئلة FigQA فقط على صور الأشكال، دون أي معلومات أخرى مثل عناوين الأشكال أو نص الورقة. تتطلب معظم المشكلات أن يقوم النموذج بدمج عناصر متعددة من المعلومات في الرسم البياني، الأمر الذي يتطلب من النموذج أن يتمتع بقدرات متعددة الوسائط.
يقيس TableQA القدرة على تفسير البيانات من الجداول الورقية.تحتوي الأسئلة فقط على صور للجداول المستخرجة من الورقة، دون أي معلومات أخرى مثل تعليقات الأشكال، وعنوان الورقة، وما إلى ذلك. تتطلب المشكلة من النموذج ليس فقط العثور على المعلومات في الجدول، ولكن أيضًا استنتاج أو معالجة المعلومات الموجودة في الجدول، مما يتطلب أيضًا من النموذج أن يتمتع بقدرات متعددة الوسائط.
تم تصميم أسئلة ProtocolQA بناءً على البروتوكولات المنشورة.يتم تعديل هذه البروتوكولات أو حذف خطوات لإدخال الأخطاء، ثم تطرح الأسئلة نتائج افتراضية للبروتوكول المعدل وتسأل عن الخطوات التي تحتاج إلى تعديل أو إضافة "لإصلاح" البروتوكول لإنتاج الناتج المتوقع.
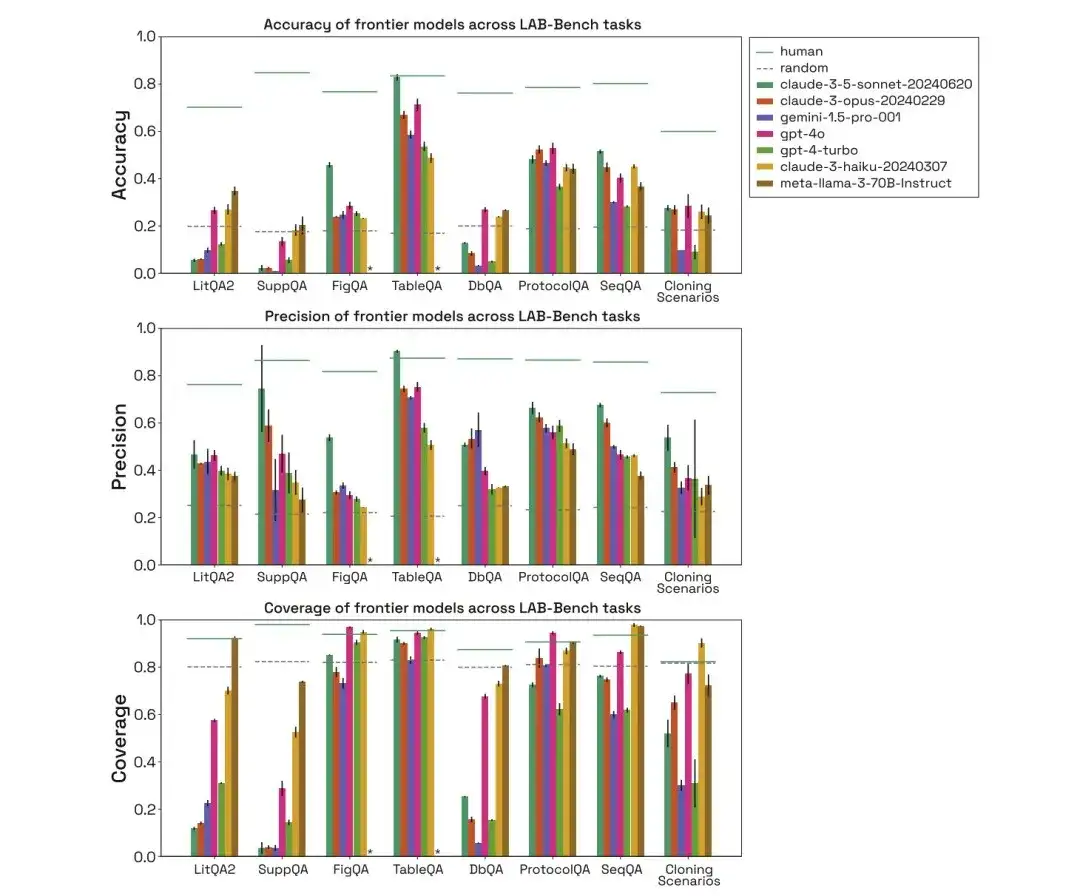
ومن خلال تقييم النماذج البشرية والعشوائية والمختلفة، يمكن إيجاد أن أداء نموذج Claude 3.5 Sonnet في اختبار FigQA أعلى بكثير من النماذج الأخرى، مما يشير إلى أنه يتمتع بقدرة أفضل على شرح وتفسير محتوى الصورة.
في اختبار TableQA، تتمتع جميع النماذج بتغطية عالية، مما يشير إلى أن TableQA هي المهمة الأسهل. علاوة على ذلك، فإن أداء Claude 3.5 Sonnet جيد جدًا مرة أخرى، حتى أنه يتفوق على الأداء البشري في الدقة ويطابق الدقة البشرية.
في مهمة ProtocolQA، تعمل النماذج بشكل قابل للمقارنة، مع تركيز الدقة حول 50-60%. تجيب النماذج على أسئلة البروتوكول بتغطية عالية إلى حد ما لأن النماذج لا تحتاج إلى إجراء عمليات بحث صريحة ولكنها ببساطة تقترح حلاً بناءً على بيانات التدريب.
41 مجموعة اختبار سيناريوهات الاستنساخ، وعلماء الأحياء بمساعدة الذكاء الاصطناعي في الاستكشاف المستقبلي
لمقارنة أداء النموذج مع البشر في المهام الصعبة،قدم الباحثون مجموعة اختبار مكونة من 41 سيناريو استنساخ، بما في ذلك البلازميدات المتعددة، وشظايا الحمض النووي، وسير العمل متعددة الخطوات، وما إلى ذلك.هذه السيناريوهات عبارة عن مشاكل متعددة الخطوات ومتعددة الاختيارات والتي تشكل تحديًا للبشر.إذا حقق نظام الذكاء الاصطناعي دقة عالية في اختبار سيناريو الاستنساخ، فيمكن اعتبار أن نظام الذكاء الاصطناعي يمكن أن يصبح مساعدًا ممتازًا لعلماء الأحياء الجزيئية البشرية.
من خلال تقييم النماذج البشرية والعشوائية والمختلفة، يمكن ملاحظة أن أداء النموذج في سيناريو الاستنساخ أقل بكثير من أداء البشر، وأن تغطية Gemini 1.5 Pro وGPT-4-turbo منخفضة. وعلاوة على ذلك، حتى عندما تكون النماذج قادرة على الإجابة على الأسئلة بشكل صحيح، فمن المفترض أنها وصلت إلى الإجابة الصحيحة من خلال إزالة المشتتات ثم التخمين.
باختصار، في مهام LAB-Bench، تعمل النماذج المختلفة بشكل مختلف للغاية، وغالبًا ما ترفض الإجابة على الأسئلة بسبب نقص المعلومات، وخاصة في المهام التي تتطلب صراحةً استرجاع المعلومات. علاوة على ذلك، فإن أداء النماذج ضعيف في المهام التي تتطلب معالجة تسلسلات الحمض النووي والبروتين، وخاصة التسلسلات الفرعية أو التسلسلات الطويلة. في مهام البحث الفعلية، يؤدي البشر أداءً أفضل بكثير من النماذج.
* مجموعة بيانات معيارية لنموذج لغة مختبر علم الأحياء:
ما ورد أعلاه هو مجموعات البيانات التي أوصت بها HyperAI في هذا العدد. إذا رأيت مصادر بيانات عالية الجودة، فنحن نرحب بك لترك رسالة أو إرسال مقال لإخبارنا بذلك!
مراجع:








